基于多目标调节的东庄水库运行可靠性研究
2024-01-06孙军平许建建张飞儒
孙军平,许建建,张飞儒
(陕西省水利电力勘测设计研究院,陕西 西安 710001)
为了发挥水库综合效益,对以防洪、发电、供水、航运、生态等综合利用运行的水库,实施多目标调度逐渐替代传统单目标调度模式、制定具有可靠性的调度规则,已成为实现水库高效调度运行、优化水资源配置的重要手段[1]。国内外研究学者以黄河小浪底梯级水库、溪洛渡-向家坝梯级水库等为研究对象,构建了考虑供水-发电-生态效益的多目标调度模型[2-6]。朱金峰等[7]采用混合整数多目标优化模型,研究了黑河中游生活、工业、农业、生态用水的调配方案;丁伟等[5]使用两阶段多目标水库优化调度模型,分析了决策者对水源保护的偏好和水库入库预测的不确定性对防洪和节水之间权衡影响。调度规则是水库优化调度成果的重要表现形式,通常包括调度图或者调度函数,调度图因其直观、简明的优点在实际调度中得到了广泛应用[8],但当决策因子数目增多时,调度图表征难度较大,而调度函数通过函数关系表征水库状态量与决策变量之间关系,最初常利用具有结构简单、直观特点的回归方程确定,后随着机器学习的发展,极限学习机[9]、支持向量机[10]、神经网络[11]、随机森林[12]等方法为水库调度函数拟合提供了新思路。
陕西省东庄水库是以防洪减淤为主,兼顾供水、发电、改善生态的综合利用水库,也是关中渭北地区水资源配置网络中的关键节点性水库,为最大化发挥综合效益,亟需开发一套系统的调度规则,构建调水调沙情景下考虑供水-发电-生态需求的东庄水库多目标调度模型,基于随机森林算法提取东庄水库调度规则。研究成果可丰富东庄水库调度体系,为未来东庄水库运行提供参考。
1 工程概况
东庄水利枢纽工程位于泾河干流最后一个峡谷段出口(张家口水文站)以上29 km,左岸为陕西省淳化县王家山林场,右岸为陕西省礼泉县叱干镇,坝址距泾河入渭河口约87 km,距西安市约90 km,是黄河水沙调控体系的重要支流水库,东庄水库位置及供水系统示意图如图1所示。
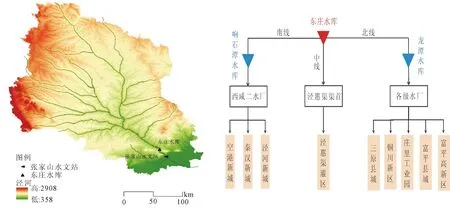
图1 东庄水库位置及供水系统示意图
工程开发任务为以防洪减淤为主,兼顾供水、发电和改善生态等综合利用。水库正常蓄水位789 m,死水位756 m,汛期限制水位780 m,设计洪水位799 m,校核洪水位803 m。水库总库容32.76亿m3,防洪库容4.30亿m3,调水调沙库容3.27亿m3,拦沙库容20.53亿m3,调节库容5.78亿m3。水电站装机容量110 MW,多年平均发电量2.85亿kW·h。结合堤防工程建设可将泾河下游防洪标准提高到20年一遇,显著减轻渭河下游河道淤积,可提高泾惠渠灌区灌溉保证率,为三原县城、西咸新区、富平县城及工业园区等城镇生活和工业供水,并承担陕西电网发电任务。
2 多目标调度模型构建与求解
重点考虑供水-发电-生态需求,按照“模型构建—优化求解—规则提取”的研究思路展开,首先分别选取供水量最大、发电量最大和生态供水量最大为目标函数构建东庄水库多目标调度模型,其次通过加权法和遗传算法求解获取调度过程,最后采用随机森林算法提取调度函数。
2.1 多目标调度模型构建
(1) 基本调度原则
东庄水库调度过程中,需要兼顾协调东庄水库生产生活及灌溉用水、生态用水、发电用水的矛盾,主要围绕以下基本原则构建调度模型:
a) 生态基流保障
为确保水库工程下游河道内需水,需优先保障生态基流5.33 m3/s。
b) 供水顺序
在满足生态基流的前提下,分灌溉期(灌溉期主要集中在每年7月—8月中旬、11月—12月以及3月—4月)与非灌溉期进行供水。灌溉期优先保证农业供水,城镇生活及工业用水次之;非灌溉期,优先供给城镇生活及工业用水,农业用水次之。
c) 发电模式
发电采取“以水定电”模式,即利用中线灌溉流量发电。
d) 调水调沙
除考虑供水、生态以及发电外,在正常运用期还考虑调水调沙问题。调沙期(7月—9月),当水库入库流量大于等于400 m3/s,水库提前敞泄,开启排沙底孔泄流,减少水库淤积;当水库入库流量小于400 m3/s,正常供水部分泄放,非调沙期正常供水。
(2) 目标函数
根据基本调度原则和系统需求,制定兼顾生态、发电和供水多目标优化调度模型为:
F=Max{F1,F2,F3}
(1)
式中:F、F1、F2、F3分别代表系统优化总目标、生态供水、发电和供水目标值。
其中生态供水、发电量和供水量目标函数为:
(2)
(3)
(4)
式中:q生态、q发电、q供水分别为生态供水流量、发电流量和供水流量;k为发电系数;h(i)为第i时段的发电水头;T为调度周期;Δt为调度步长;i为调度时段;j为供水路线编号。
选用加权法[13],将上述3个运行目标转化成综合目标的调度模型,形式如下:
F4=Max{w1F1+w2F2+w3F3}
(5)
式中:F4代表采用加权法表征后的系统优化总目标;w1、w2、w3分别为优化模型中赋予生态、发电、供水的权重系数。
考虑到水库任务重要程度,本文选用生态、发电和供水的权重系数组合为0.3、0.2和0.5。
(2) 约束条件
东庄水库调度模型主要受水库的水量平衡条件、水库水位上下限、库容上下限、死库容、机组容量、需水过程、变量非负约束等条件约束。
2.2 调度模型求解方法
运用遗传算法[14]求解,将目标函数对应的模型指标设置为适应度函数,如生态供水量、发电量、供水量,每个个体所携带的解都能计算出一个相应的适应度值,而每一代种群最佳适应度值就是用于定量评价种群进化效果的指标。若下一代的最佳适应度值超过历时最佳适应度值,则说明种群进化成功,替换历史最佳适应度值后再进行交叉变异进化;反之,下一代最佳适应度值不及历史最佳适应度值,则不进行替换,直接进行交叉变异进化。
以出库流量为决策变量,染色体长度为660,种群规模为1 000,交叉概率和变异概率分别为0.8和0.1,迭代次数为5 000次。
2.3 基于随机森林算法的调度规则提取
2.3.1 随机森林算法
随机森林算法[15]是一种常用的机器学习算法,是由Breiman在2001年提出的一种集成学习方法。它的基本原理是将多个决策树合成一个强大的分类器或回归器。该算法不仅对于异常值不敏感,而且在处理高维数据时表现良好,具有强大的数据特征挖掘能力,同时可以处理分类及回归问题。该算法实现步骤如下:
(1) 随机抽取训练样本,通过Bootstrap法随机地有放回地进行抽样,选择一部分样本,构成一个训练集。
(2) 随机筛选一部分特征变量,构成一个候选特征集合,候选特征集合的大小是随机森林模型的一个重要参数。
(3) 决策树的构建,用选定的特征变量和训练集来训练一个决策树模型。
(4) 重复上述过程,可以生成多棵决策树,最终组成随机森林。
(5) 针对分类问题,采用投票法来决定最终的分类结果,即让每个决策树投票,选择得票最多的类别作为最终结果;对于回归问题,采用平均法来确定最终预测值。
选用优化调度模型的输出结果的数据样本,利用随机森林拟合数据样本之间的关系,拟合调度函数,作为东庄水库的调度规则。
2.3.2 相关性分析
采用Pearson相关系数分析方法。Pearson相关系数[16]分析方法是最常用的线性相关系数方法,主要用于表征线性相关性,最适用于相差不大的线性、连续且符合正态分布的数据。
相关系数r的绝对值越接近于1,说明这两个变量的相关程度越高,即这两个变量越相似。如果r为正数,说明两个因子之间的关系为正相关,反之为负相关。
2.3.3 调度规则拟合效果评价
选用平均绝对误差MAE、平均偏差MBE和确定性系数R2作为评价指标量化调度规则拟合效果。平均绝对误差衡量了预测值与真实值之间平均误差幅度,均方根误差用来模拟预测值与真实值之间的偏差,前三者均为越小越好;确定性系数衡量了模型拟合成果的优劣程度,其值越大,精度越高。
3 案例应用与结果分析
将收集到张家山站1956年—2010年月尺度径流资料作为东庄水库的入库径流,拟定水库起调水位为死水位756 m,结果分析从优化模型调度结果和规则提取结果两个方面展开。
3.1 多目标调度结果分析
基于遗传算法获取的调度结果从供水、发电和生态三个角度依次展开。
3.1.1 供水过程
(1) 水量关键指标
经验证,模型调度结果满足水量平衡方程,结果正确,其中调度过程的多年平均值统计结果如表1所示、弃水变化过程如图2所示。

表1 东庄水库调度关键指标统计结果 单位:亿m3

图2 东庄水库月平均弃水量统计图
如图2所示,东庄水库弃水主要发生在夏季,夏季弃水占比为57.5%,由于汛期来水量较大,且水库在满足正常供水任务以外,无法满足汛限水位的约束,因此产生大量弃水,多年平均弃水率约为16.94%。建议可以在汛期增大机组出力,提高弃水利用效率。
(2) 三线供水过程
如图3所示,中线、北线和南线多年平均缺水量分别约为0.33亿m3、0.21亿m3、0.07亿m3,中线缺水量最大,但是考虑中线需水基数最大,计算得各线的缺水率分别约为8.87%、12.48%、15.04%。长系列的供水过程中,各线最大年缺水量分别约为1.87亿m3(1981年)、1.11亿m3(1956年)和0.33亿m3(1956年),由于1956年来水较少,北线和南线出现了年最大缺水,而中线最大年缺水量出现在1981年,是因为1981年年内进行了调水调沙,大量的水参与了水库的冲沙减淤,剩余水量无法满足供水需求。若参与调水调沙的水量过多,造成大量缺水,建议考虑此时调水调沙是否具有较高价值,应选择性地进行调水调沙。
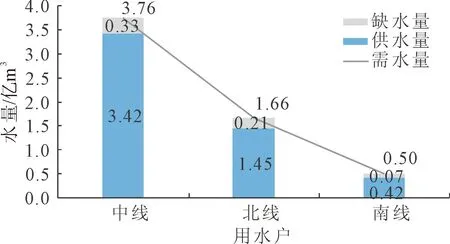
图3 东庄水库多年平均供水量与缺水量统计图
(3) 调沙与供水关系
东庄水库1956年—2010年调沙水量与缺水量对比情况如图4所示,红色表示存在调水调沙期的年份的缺水量,蓝色表示无调水调沙年份的缺水量。东庄水库存在调沙期的年份,缺水量相对较大。图4调度数据显示:(a)调沙水量为0的年份,即不调沙年份,缺水量较小,多年平均缺水量为0.31亿m3;(b)存在调沙期的年份,多年平均缺水量为1.16亿m3,调沙年份缺水量约为不调沙年份缺水量的4倍。同时,由于调沙期水库水位消落较大,水位回升较慢,此时若天然来水相对较少,还会影响后续年份的供水,产生连续供水不足年份,不利于正常生产生活。

图4 东庄水库1956年—2010年缺水量统计图
因此,东庄水库调水调沙期对水库正常供水影响十分显著,侧面反映出调沙水量与供水量之间的矛盾较为突出。
3.1.2 发电量
东庄水电站的发电量主要与天然来水过程和水库是否调沙有关。模型所得多年平均发电量为 2.50 亿kW·h,略低于水库设计多年平均发电量2.58 亿kW·h。如图5所示,若当年参与调沙的水量多,则用于发电的水量相对较少,从而导致发电量降低,影响水库的发电效益。调沙水量与发电量之间存在竞争关系。不调沙年份,多年平均发电水量为7.79亿m3;调沙年份,多年平均发电水量为5.31亿m3;不调沙年份多年平均发电水量约为调沙年份的1.47倍。

图5 东庄水库1956年—2010年调沙水量与发电水量对比图
统计长系列结果发现1958、1995等年份发电量急剧下降,导致此问题发生的原因是:(1)在调水调沙期间,水库泄水,导致水量无法储存,水位库容降低,影响后续发电;(2)调沙期水中含沙量过高,下泄水流不能通过水轮机,无法用于发电;(3)在不调沙的年份,天然水量相对较少,水库需要动用兴利库容进行灌溉、生活和生态供水,导致水库水位消落较大,影响发电效率。
3.1.3 生态供水
根据东庄水库调度原则,优先满足生态基流,模型多年平均生态供水量为1.66亿m3,生态供水保证率98%,基本保证生态基流。
3.2 基于Pearson相关性分析的调度函数决策因子筛选
隐随机优化调度的核心是建立起时段输入因子与决策变量之间的映射关系[12]。因此,调度规则提取的关键是选取恰当的决策变量和输入因子。研究东庄水库的调度问题,需要预测未来出库水量,故选取t+1时段的出库流量Q作为决策因子;为了分析输入因子对调度决策的影响,考虑了t时段入库流量q_int、t+1时段入库流量q_int+1、t+1时段总需水量q_xst+1、t时段初水位Zt初、t时段末水位Zt末、t时段末库容Vt末作为初选输入因子集。调水调沙的结果受基本模型原则影响,出库流量波动很大,因此选择不调沙的年份做调度规则提取样本,累计41年。利用随机森林方法建立东庄水库调度函数,其形式为:
Q=f(q_int,q_int+1,q_xst+1,Zt初,Zt末,Vt末)
(6)
对初选输入因子集和决策变量进行Pearson相关性分析,计算二者的相关项系数并加以分析,计算结果如表2所示。

表2 Pearson相关性系数计算表
对初选输入因子进行P值检验,检验六种输入因子的P值均小于0.01,表明相关性结果显著;六种决策因子的相关系数均大于0.3,其中,t+1时段入库流量相关系数最大为0.4852,t时段初水位相关系数最小为0.3296,因而都可作为随机森林模型的输入因子。
3.3 基于随机森林算法的调度函数训练与验证
利用随机森林模型对决策因子进行排序,该模型最小叶子数设置为5,决策树树木设置为100。本文设置前300个数据序列样本做训练集,后192个数据作为验证集。图6展示了训练集和测试集预测结果对比图,表3统计了样本拟合指标评价结果。
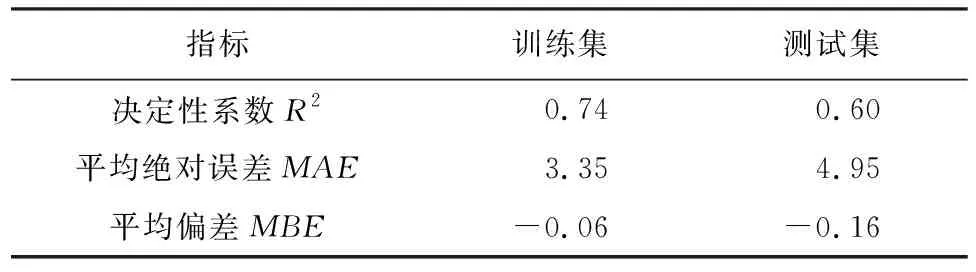
表3 调度规则拟合效果评价表
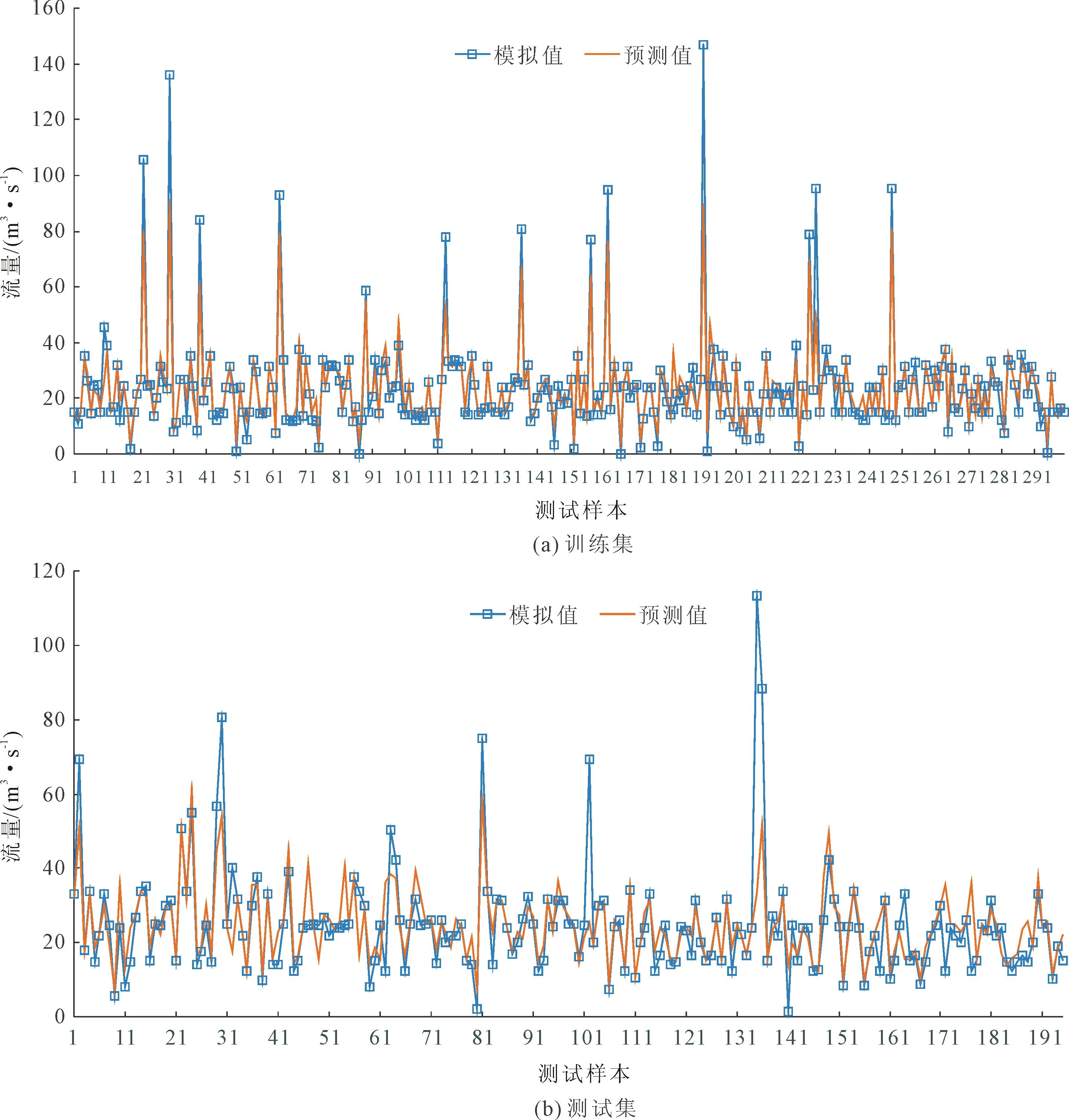
图6 模型训练和测试结果
由图6可知: 在测试集预测结果中可以看到,拟合出现了8次较大偏差,这是因为调度策略是根据历史信息做出最优决策,而径流不确定性很大程度上会影响预测的精度;同时模型在调度函数进行拟合的过程中,由于仅仅考虑了对样本给出的调度过程进行研究,而并未结合实际调度运行过程的中的约束来考虑调度运行,使得最终拟合出现偏差较大的情况。
由表3可知:相比训练集,测试集预测指标R2、MAE和MBE指标相对较差,是因为由于样本容量和模型复杂程度不匹配,出现了训练集过拟合现象,但测试集确定性系数R2为0.6,说明该模型提取的调度规则拟合效果较好。
整体而言,预测结果与模拟过程总体趋势一致,利用随机森林提取的调度规则可有效预测东庄水库出库径流过程。
4 结论与展望
以东庄水库为研究对象,开展了调水调沙情景下考虑供水-发电-生态需求的多目标调度研究,主要研究结论与成果如下:
(1) 东庄水库基本可以保障下游河道的生态基流,生态供水保证率98%,多年平均生态供水量为1.66亿m3,满足生态需求任务;考虑东庄水库供水受调水调沙的影响,中线、北线和南线多年平均缺水量分别约为0.33亿m3、0.21亿m3、0.07亿m3,各线的缺水率分别约为8.87%、12.48%、15.04%。
(2) 通过Pearson相关系数分析方法以及随机森林算法提取了东庄水库的调度规则。选取了t时段入库流量、t+1时段入库流量、t+1时段总需水量、t时段初水位、t时段末水位、t时段末库容作为随机森林模型的输入因子,选定t+1时段的出库流量作为决策变量,基于随机森林理论的调度函数可作为调度规则指导水库运行。
(3)通过缺水频率分析,解决东庄水库供水可持续问题,需增加相应调蓄水库,在满足生态、发电效益的同时,满足供水保证率。
