基于大数据驱动技术的媒体风险感知模型研究①
2024-01-06鲁贻锦
鲁贻锦, 吴 蕾
(安徽警官职业学院,安徽 合肥230000)
0 引 言
随着信息技术的不断发展,各种媒体风险发生的可能性不断增强。如何对媒体风险做好统计分析成为亟待解决的问题。目前针对这一问题,很多学者已经确定了一些相应的风险感知模型。最初的媒体风险感知模型通过对历史数据进行分析,结合经验以及分析结果对媒体风险进行评级。这种方式存在运行成本较高,风险感知时间较长以及精确度较低的问题,对媒体风险评级不够客观精确。后期出现的基于线性回归或者BP神经网络的媒体风险感知模型,仍然存在感知误差较大,普适性较低的问题[1-2]。结合大数据驱动,通过最小二乘支持向量机进行建模,建立新的改进媒体风险感知模型,通过粒子群算法对参数进行了优化,同时转变了运算方式,在提高媒体风险感知效率的同时,进一步提高了精确性以及普适性。
1 媒体风险感知模型设计
1.1 预处理风险数据
媒体风险主要表现为一定的混沌性,即在不同因素的影响之下,它是非线性以及不确定的。因此在进行媒体风险感知的过程,主要的工作是对媒体风险的数据序列所表现出的混沌性,做出更为精确和高效地识别。媒体风险所表现出的历史数据序列可以表示为{ai,i=1,2,…,q},通过设定延迟时间τ,对历史数据的序列进行重构,该序列为m维,变化规律与之前的历史数据序列相同,如公式(1)。
(1)
公式(1)中,历史数据序列在重构之后,对应的相数量为N,在相空间当中,相点的表示如公式(2)。
X(p)=[x(p),x(p+τ),…x(p+(m-1)τ)],
p=1,2,…,N
(2)
公式(2)中可看出,决定对媒体风险如何变化进行精准描述的关键在于延迟时间τ以及维度m的选取。
1.2 延迟时间τ的确定
对延迟时间τ通过互信息法进行选取。设定时间序列X和时间序列Y,其对应的信息熵可以表示为公式(3)和公式(4)。
(3)
(4)
公式(3)和公式(4)中,P(xi)和P(yi)分别表示在时间序列X中事件xi和在时间序列Y中事件yi对应的发生概率。时间序列X和时间序列Y的联合熵可以表示为公式(5)。
(5)
公式(5)当中,时间序列X中事件xi和时间序列Y中事件yi同时发生的概率用Px,y(xi,yp)表示。对应的条件熵可以表示为公式(6)。
H(X|Y)=
(6)
公式(6)中,Px,y(xi|yp)表示时间序列X中事件xi的条件下,时间序列Y中事件yi发生的概率。
则可以将互信息函数表示为公式(7)。
I(X,Y)=H(X)+H(Y)-H(X|Y)
(7)
公式(7)中,I(X,Y)即为对应的互信息函数,当互信息函数首次出现最小值时,此时的延迟时间τ即为时间序列当中的延迟时间最优[3]。
1.3 最佳嵌入维数m的确定
对最佳嵌入维数m的确定,借助Cao法完成。对相点Xi以及相点Xp之间的欧氏距离,进行相应无穷范数定义,如公式(8)。
(8)
并进行如下定义:
(9)
(10)
(11)
公式(9)-(11)中,时间序列X以及时间序列Y,定义变量E1(m)的值随着嵌入维数m的不断增加而相应增加,当m超过某一特定值m0时,定义变量E1(m)饱和,此时的嵌入维数m为时间序列当中的嵌入维数最优。
1.4 最小二乘支持向量机
媒体风险感知需要对大量的数据进行甄别处理,其本质上是对海量的数据进行分类筛选。支持向量机(SVM)作为二分类模型的一种,其特点是特征空间间隔最大,对凸二次规划问题求解方便,但支持向量机具有相对较高的训练复杂度。在进行媒体风险感知时,其数据训练的时间同样本数量作指数形式变换。相较而言,最小二乘支持向量机(LSSVM)将凸二次规划问题进行转化,变为求解线性方程组的问题,在对支持向量机数据训练进行了简化的同时,也使得运行更为高效快捷。在设计的媒体风险感知模型中,通过最小二乘支持向量机进行数据分类。
样本数据的数量设定为i,由i个样本数据进行组合,得到相应的训练集如公式(12)。
Q={(x1,y1),(x2,y2)…(xi,yi)}
(12)
针对训练集Q,应当存在超平面能够满足最优分类需求,其要求如公式(13)。
(13)
公式(13)中,法向量用α表示,转置运算用T表示,偏置量用γ表示。
依据最小二乘支持向量机,可以将分类决策形式表示为公式(14)。
f(xj)=sgn(αTxj+γ)
(14)
同时,定义函数φmin(α,ξj)为相应的优化函数,其具体的定义如公式(15)。
s.t.yj(αTφ(xj)+γ)=1-ξj
(15)
公式(15)中,正则化参数用β表示,预测值及输出实际值之间的回归误差用ξj表示,非线性映射函数用φ(xj)表示,其映射原理如图1。
图1 非线性映射原理示意图
图1中,通过非线性映射函数,将样本空间X当中的值映射到特种空间Y当中。当对优化函数φmin(α,ξj)进行求解之后,可以进而对分类决策进行求解[4]。在此过程中,进行相应的拉格朗日函数的构造,引入拉格朗日乘数λj,可得相应的拉格朗日函数如公式(16)。
(16)
对α,γ,ξj,λj的导数进行设定,其值为0,那么当求得问题最优解时,满足如下几个条件。
(17)
(18)
(19)
(20)
将α及ξj消除,可将线性问题进行简化,如公式(21)。
(21)
公式(21)中,yT=[y1,y2,…yk],P=yjypφT(xj)φT(xp)yjypK(xj,xp),p=1,2,…,k,λ=[λ1,λ2,…,λk]T,Ik=[1,1,…,1]T。其中,K(xj,xp)为对应的核函数,如公式(22)。
(22)
公式(22)中,核宽度用σ表示。由此可以得到针对媒体风险感知的分类决策函数,如公式(23)。
(23)
在公式(23)中,存在两个超参数即σ和β。进行媒体风险感知的过程当中,这两个超参数对最小二乘支持向量机的高性能构造起着关键性的作用。如何对这两个超参数寻优至关重要。借助粒子群算法,通过公式(24)以及公式(25)对两个超参数进行更新寻优。
(24)
(25)
1.5 媒体风险感知执行步骤
基于最小二乘支持向量机的媒体风险感知大致可以分为以下五个步骤:
(1)对媒体风险的数据进行采集,采集过程,只通过媒体风险的等级进行数据采集记可。
(2)通过互信息法,进行延迟时间τ的选取,通过Cao法,进行最佳嵌入维数m的选取。
(3)选定延迟时间τ以及最佳嵌入维数m之后,通过相空间重构的方式,将采集所得历史数据进行多维化处理。
(4)对超参数σ和β进行取值寻优,通过粒子群算法做出更新。
(5)超参数σ和β取得最优值之后,依据最小二乘支持向量机,进行最优感知模型的建立。
2 模型性能实测与分析
2.1 确定模型数据
媒体风险感知模型的数据选取通过爬虫工具完成。具体模型测试中,选取抓取工具Gooseeker进行网页信息的抓取,收集媒体风险感知模型所需要的原始数据。原始数据的收集包括媒体使用的动机、媒体使用的频率、媒体的信任度、媒体使用的时间以及风险事件的采集(如债券市场、外汇市场、货币市场以及股票市场等)[7]。同时,对采集到的风险数据通过5分量表的测量方式进行测定。以媒体信任度的原始数据为例,通过5分量表测试所得的结果如图2所示。

图2 媒体风险感知测试数据
图2中,媒体风险感知按照5分量表法分为5个等级,当等级为1时,代表几乎没有风险;当等级为2时,代表风险较少;当风险为3时,代表风险一般;当等级为4时,代表风险较重;当等级为5时,代表风险严重[5-6]。在同一个测试数据样本当中,设定包含变量的个数为30个,对应一维的时间序列的数据表示为如{3,5,2,…,4}的形式。媒体风险数据的样本总量巨大,在进行风险感知之前,要对数据样本做出预处理。
2.2 延迟时间以及嵌入维数的确定
针对图2所得的测试数据,通过Cao法,计算选定最佳嵌入维数m;通过互信息法,计算选定延迟时间τ。在样本数据当中选定甲时间序列,信息熵为0.03,选定乙时间序列,信息熵为0.02,则甲乙时间序列联合信息熵的值为-0.012,计算所得互信息函数的值为0.062。依法对所有样本当中的互信息函数进行计算,进行最小值的选取,并确定相应的延迟时间。同时,在进行最佳嵌入维数m的计算时,欧氏距离的计算中欧氏距离的值是0.7。延迟时间τ选取结果如图3,最佳嵌入维数m的选取结果如图4。
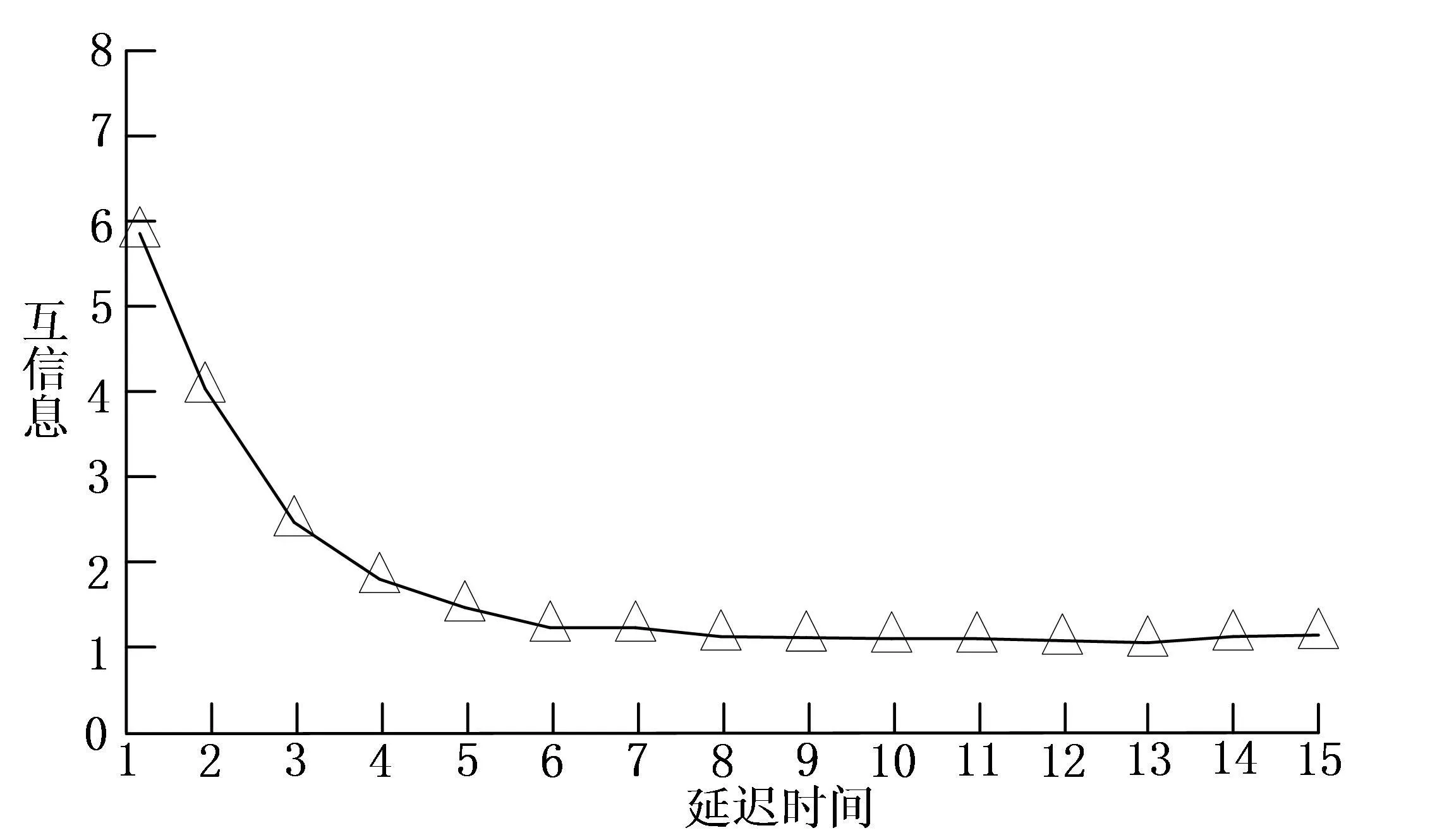
图3 互信息法选取延迟时间τ
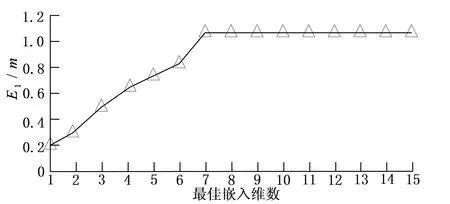
图4 Cao法选取最佳嵌入维数m
图3中,可以通过分析得出媒体风险感知实验中对应的最佳延迟时间的值为7;图4中,可以通过分析得出媒体风险感知实验中对应的最佳嵌入维数m的值为7。那么在重构媒体风险感知的数据时,可以选定τ=7,m=7。同时,通过上述结合的粒子群算法,能够对超参数σ和β的寻优计算,得出σ=0.58,β=0.26。将以上数据应用于最小二乘支持向量机,进行建模并迭代计算。
2.3 媒体风险感知的敏锐度
媒体风险感知的敏锐度代表了系统是否能够及时准确的对媒体面临的风险做出感知[8]。在对媒体风险感知的数据做出重构的处理之后,对其进行简单的算术平均合成,从而得到相应的媒体风险感知敏锐度的折线走势图。系统实验统计分析了2007年-2021年的媒体风险感知水平,如图5所示。

图5 历年媒体风险感知水平折线走势
图5中,历年媒体风险感知水平总体上是上下波动的趋势,且均值大致在0.424左右。但是在A,B,C,D,E五个区间内,媒体风险感知水平的均值在0.778左右,远远大于总体均值。其中,A区间为2008年爆发的全球性金融危机;B区间为2012年发生的欧债危机;C区间为2015年到2017年这个时间段内发生的大规模的股灾;D区间为2018年时发生的中美贸易战;E区间为2020年开始并时间较长规模较大的全球性疫情。容易看出,在一些大型危机性事件发生时,金融风险的危机进一步增加,同时也导致媒体风险感知水平更加敏锐,能够对风险事件的感知更加明显和强烈。另外,从图5所示的折线走势上观察,当风险事件开始发生之前,媒体风险感知水平就开始逐渐上升。
2.4 媒体风险感知的精确度
通过与基于BP神经网络的媒体风险感知模型、传统的媒体风险感知模型以及基于最小二乘支持向量机的改进模型对比实验,对基于大数据驱动的媒体风险感知模型的精确度进行测验。各类实验分别进行5次,其对于媒体风险感知的精确度如图6。
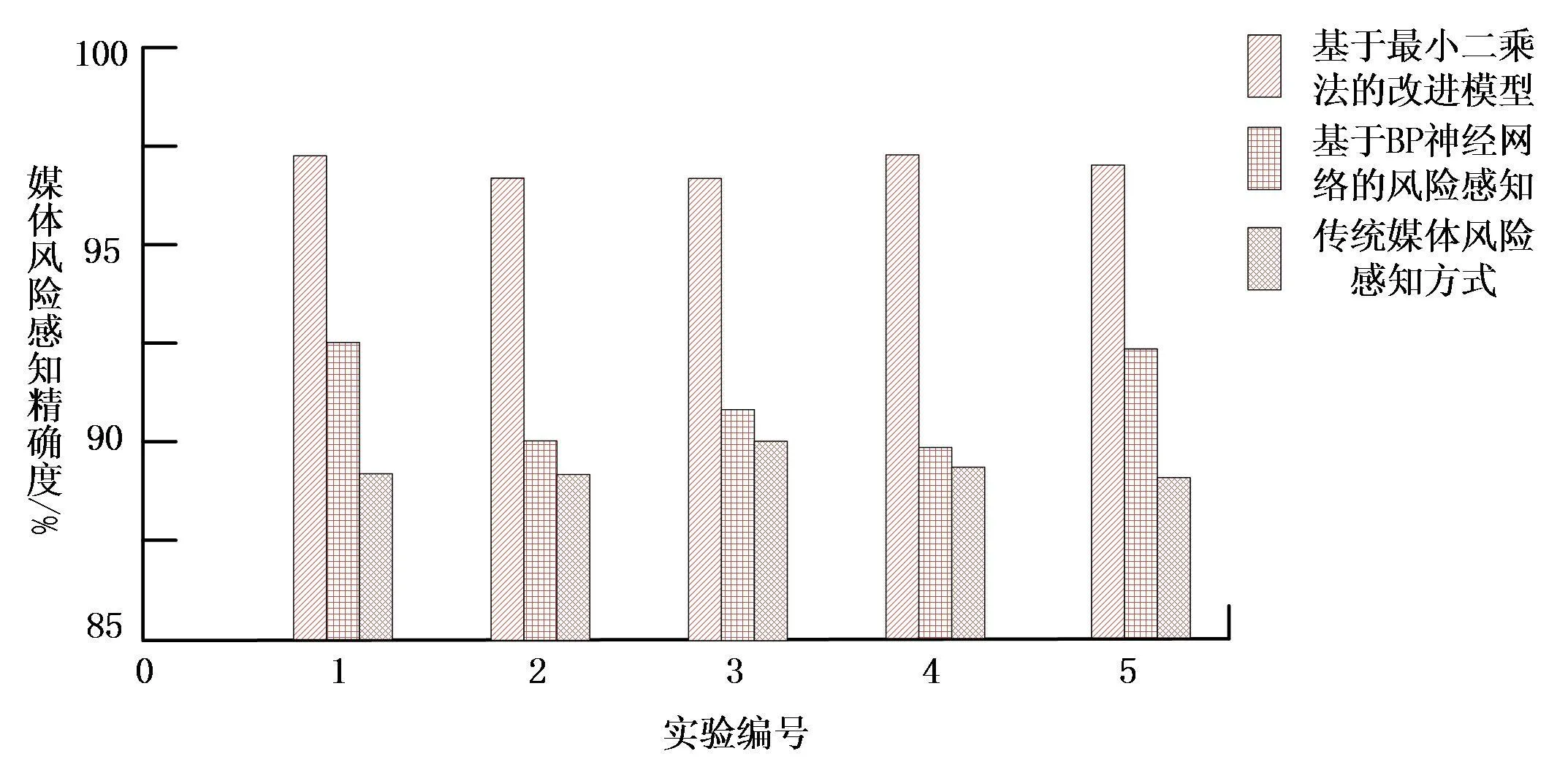
图6 媒体风险感知的精确度对比
图6中,基于最小二乘支持向量机的改进模型在5次实验中,精确度的均值在97%左右,基于BP神经网络的媒体风险感知模型的精确度均值在91%左右,传统的媒体风险感知方式的精确度在88%左右。其中,基于最小二乘支持向量机的改进模型精确度都高于其他风险感知方式。由于改进模型在进行初始数据预处理时,对延迟时间τ以及最佳嵌入维数m分别采用了交互信息以及Cao法进行了确定,可以保证媒体在进行风险感知时产生的误差更小。同时在处理数据分类时,采用了最小二乘支持向量机的方式,使运算量得到了极大简化,且由高维运算转变为低维运算,数据运算量减少的同时,也使得数据特征的提取更加精确[9]。
2.5 媒体风险感知模型的普适性
媒体风险感知模型针对不同媒体类型进行感知,是否能够保证程度相同的精确性,是考验媒体风险感知模型的关键。实验测试选取20种媒体类型为实验的测试对象,通过基于最小二乘法支持向量机的媒体风险感知模型进行实验,其风险感知精确度的对比如图7。

图7 不同类型媒体数据风险感知对比
图7中,针对不同媒体类型的数据,改进媒体风险感知模型的精确度均在95.20%往上,部分类型媒体数据的精确度甚至能够达到96.7左右。该精确度能够满足实际应用时的要求,也证明了基于最小二乘支持向量机的媒体风险感知模型对于不同类型媒体数据具有更好的普适性[10]。
3 结 语
以最小二乘支持向量机为依据的媒体风险感知模型克服了以往模型精确度较低,普适性不强的问题。通过对数据的预处理以及参数的进一步优化,保证了风险感知模型的可靠性。经测试模型的媒体风险感知具有更好的敏锐度、精确度及普适性。
