基于属性描述的多单元过程零样本故障诊断
2024-01-05易永率赵海涛
易永率, 赵海涛
(华东理工大学信息科学与工程学院, 上海 200237)
随着化工过程复杂化和集成化程度越来越高,故障诊断技术已成为保障工业生产安全、可靠与平稳运行的重要组成部分[1-2]。目前,故障检测与诊断技术可以分为三类:基于知识驱动的方法、基于模型驱动的方法和基于数据驱动的方法。基于知识驱动的方法包括有向图、故障树等,该方法依赖大量的经验和专家知识,且泛化能力较差。基于模型驱动的方法根据过程机理建立残差监测模型,代表性的方法有状态估计、参数估计、等价空间等。文献[3]利用状态和参数估计粒子滤波器组成的联合估计模型实现故障隔离。文献[4]利用奇异值分解法对等价空间矩阵进行优化,在增强残差对于未知输入的鲁棒性的同时,保持对故障信号敏感。虽然基于模型驱动的方法在机械、航天领域得到了许多成功的应用,但难以建立多单元化工过程的精确数学模型,限制了该方法的应用。
近年来,得益于数据采集、存储设备以及大数据技术的快速发展,大量过程数据得以记录、保存[5-6]。因此基于数据驱动的故障诊断方法逐渐成为研究的热点,并被广泛应用于化工过程。基于数据驱动的故障诊断方法可以分为多元统计分析(Multivariate Statistical Analysis, MVSA)和深度学习方法。常见的MVSA 方法包括主成分分析(Principal Component Analysis, PCA)[7]、偏 最 小 二 乘 分 析(Partial Least Squares, PLS)[8]和 典 型 相 关 性 分 析(Canonical Correlation Analysis, CCA)[9]等。由于现代多单元化工过程通常具有强非线性的特点,基于MVSA 的方法难以提取有效特征。近年来,深度学习凭借多层非线性变换结构,能够挖掘高维复杂数据中的隐藏特征,而受到越来越多的关注。比如,卷积神经网络(Convolutional Neural Network, CNN)[10]和 循 环 神 经网络(Recurrent Neural Network, RNN)[11]等深度学习框架已被应用于多单元化工过程的故障诊断。然而,上述方法需要大量完备的历史故障样本和标签,考虑到许多故障不易采集,且标记故障样本需要高昂的成本,因此,如何依靠现有类别固定的可见类故障数据(历史故障),识别没有历史数据可供训练的未见类故障(目标故障)是本领域的难题。
在没有目标故障类别样本的条件下,零样本学习(Zero-Shot Learning,ZSL)能够把历史故障类别的属性知识迁移到目标故障中,实现对目标故障的识别。这种诊断范式下,用于模型训练的历史故障和用于测试的目标故障在类别上没有交集,摆脱了对完备故障类型样本的依赖,通过属性迁移的方式,增加了模型的泛化能力,更契合实际的工业应用场景。文献[12]首次提出了ZSL 并应用于动物图像识别,通过非线性支持向量机来实现属性迁移。文献[13]提出了语义自编码器(Semantic Autoencoder,SAE)模型,通过施加约束来重构原始视觉特征,赋予隐层特征语义信息。ZSL 通过迁移学习[14]、语义歧义消除[15]、跨模态迁移[16]等方法在图像识别领域得到进一步发展。近年来,ZSL 思想在工业领域得到广泛关注,文献[17]基于属性描述实现了零样本条件下对滚动轴承的故障诊断,文献[18]通过多标签属性学习网络来预测目标故障的属性,再通过余弦相似度实现故障诊断。文献[19]定义了化工过程故障属性,实现了化工过程的零样本故障诊断。文献[20]借助一致性约束,从故障样本中提取了更为有效的特征,改善了零样本学习在化工过程中的诊断表现。但文献[19-20]这两种方法在面对多单元化工过程时,都无法考虑到单元间的相关关系。
针对上述问题,本文结合SAE 模型和自注意力机制,提出了基于属性描述的多单元自注意力机制(Attribute description based multi-unit self-attention mechanism, AMSM)的零样本故障诊断方法。首先,预训练SAE,使其从历史故障样本中提取故障属性的语义信息;其次,利用前馈神经网络提取各个单元的特征,然后自注意力机制根据语义信息自适应调节单元间的相关关系;最后,计算与目标故障类的属性标签的欧式距离(Euclidean Distance)实现故障诊断工作。以田纳西-伊斯曼(Tennessee-Eastman, TE)化工过程为研究对象验证了AMSM 的可行性和有效性,并对实验结果进行分析与对比。
1 相关工作
1.1 ZSL 故障诊断的定义

1.2 语义自编码器(SAE)
SAE 采取编码器-解码器的范式,编码器旨在将故障样本映射到属性空间,解码器用于重建原始样本。SAE 只有一层隐藏层,且隐藏层的维度要小于输入层的维度,其结构如图1 所示,其中X是输入故障样本,X︿是重建样本。

图1 语义自编码器结构Fig.1 Architecture of semantic autoencoder
在 训 练 阶 段,X=Xs,D={ai|g:(xsi)→ai,xsi∈Xs,ai∈As},即由历史故障样本对应的属性标签所组成的描述矩阵。假设输入层到隐藏层的映射为W,隐藏层到输出层的映射为W∗,由于编码器和解码器是对称的,为了简化模型,利用参数共享(tied weights)[21],可以令W∗=WT。有效的样本重建,可以使模型具备更好的泛化能力,因此目标函数为
式(1)所示的优化过程详见文献[13]。在测试阶段,利用训练好的W将目标故障样本xui∈Xu映射到属性空间,可以得到具有故障属性信息的潜在表征︿ai=Wxui。
2 基于属性描述的AMSM 故障诊断方法
针对实际工程应用场景中目标故障样本难以获取,以及多单元化工过程中复杂非线性的问题,提出了一种基于属性描述的AMSM 零样本故障诊断方法。
2.1 AMSM 模型结构
AMSM 模型分为三个阶段:第一阶段是采用SAE 从故障样本中提取含有故障属性信息的潜在表征;第二阶段是自注意力机制借助SAE 提取的潜在表征,自适应调节各个单元特征间的相关关系进行属性学习。第三阶段是通过比较模型预测的属性向量与属性矩阵的相似度实现目标故障的识别。AMSM模型结构如图2 所示,其中,Q是包含故障属性信息的描述矩阵,K和V是从各个单元提取的样本特征矩阵。
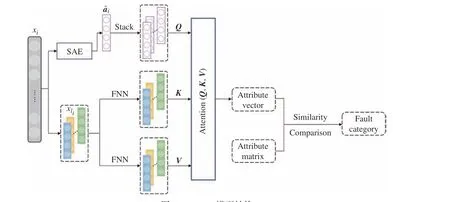
图2 AMSM 模型结构Fig.2 Architecture of AMSM model
在模型训练阶段,根据预测的属性向量a˜i和真实的属性向量ai计算交叉熵损失:
使用Adam 优化器最小化损失函数。在模型测试阶段,对故障样本xi∈Xu的识别,可以通过比较预测的属性向量和定义的各目标故障属性标签的欧氏距离实现:
其中:Auj是第j个目标故障定义的属性标签,D是求欧氏距离的函数, Φ (·) 表示返回样本类别标签。
2.2 自注意力机制
自注意力机制的输入由Q,K和V构成。在训练阶段,自注意力机制通过Q矩阵,不断动态调节特征矩阵K和V,使得提取的特征尽可能含有清晰的语义信息。本文自注意力机制的计算Attention(Q,K,V)采取的是缩放点积注意力,其计算方式如图3 所示,具体计算步骤如下:
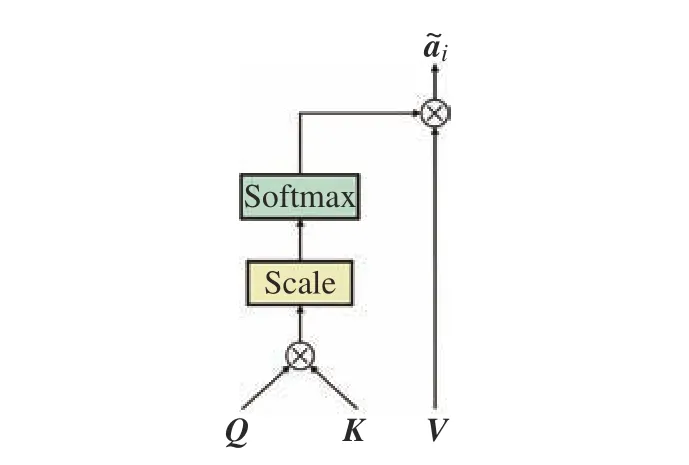
图3 缩放点积注意力的计算Fig.3 Calculation of the scaled dot-product attention
(1)缩放点积注意力函数将属性描述矩阵Q和特征矩阵K矩阵相乘,再归一化后通过 so ftmax 函数得到矩阵B∈RC×L:其中scale 操作借助缩放注意力,避免了梯度消失或梯度爆炸,保障模型误差反向传播可以更新全部参数。B矩阵表示C个属性和L个单元之间的相关性矩阵。
(2)将相关性矩阵B和V相乘得到输入故障样本的预测属性向量a˜i∈RC:
其中矩阵V表示各个单元的权重,也即单元间的相关关系。在将多单元化工过程分组后,模型通过矩阵V重新将各个单元的局部信息以不同的权重聚合起来,得到最终的预测属性向量a˜i。
2.3 基于AMSM 的零样本故障诊断流程
基于AMSM 的零样本故障诊断方法分为离线建模和在线诊断两部分,其流程图如图4 所示,其中离线建模分别训练SAE 和AMSM。

图4 基于AMSM 的零样本故障诊断流程Fig.4 Flow chart of zero-shot fault diagnosis based on AMSM
离线建模阶段:(1)对输入历史故障样本数据进行标准化处理,使其服从标准正态分布;(2)训练SAE 模型,使其能够产生有效的含有故障属性信息的潜在表征;(3)将故障样本的变量按物理单元分组,并根据训练好的SAE 的输出,通过Adam 优化器最小化损失函数 L 训练AMSM 模型。
在线诊断阶段:(1)对输入目标故障样本数据进行标准化处理;(2)将数据输入到训练好的SAE 模型中,得到含有故障属性信息的潜在表征;(3)将故障样本分组后的变量输入到AMSM 模型,得到预测的属性向量,最后通过计算其与各故障属性标签的欧氏距离完成对目标故障的诊断。
3 实验与分析
3.1 TE 过程
TE 过程是由Downs 等根据实际化工过程提出的仿真数据集,已被广泛应用于过程控制、监测和故障诊断[22]。如图5 所示,TE 过程主要由进料单元、反应器、分离器、汽提塔和压缩机5 个典型操作单元组成,各单元相应的变量如表1 所示。数据集提供了21 种故障,每种故障采集了480 个样本,每个样本由41 个测量变量和11 个操纵变量组成。由于最后6 种故障在过程中的描述较少,所以本文选择前15 种故障进行零样本故障诊断实验,这15 种故障类型如表2 所示。

表1 TE 过程的典型操作单元和对应变量Table 1 Operation units and corresponding variables in the TE process

表2 TE 过程的故障描述Table 2 Fault description of TE process
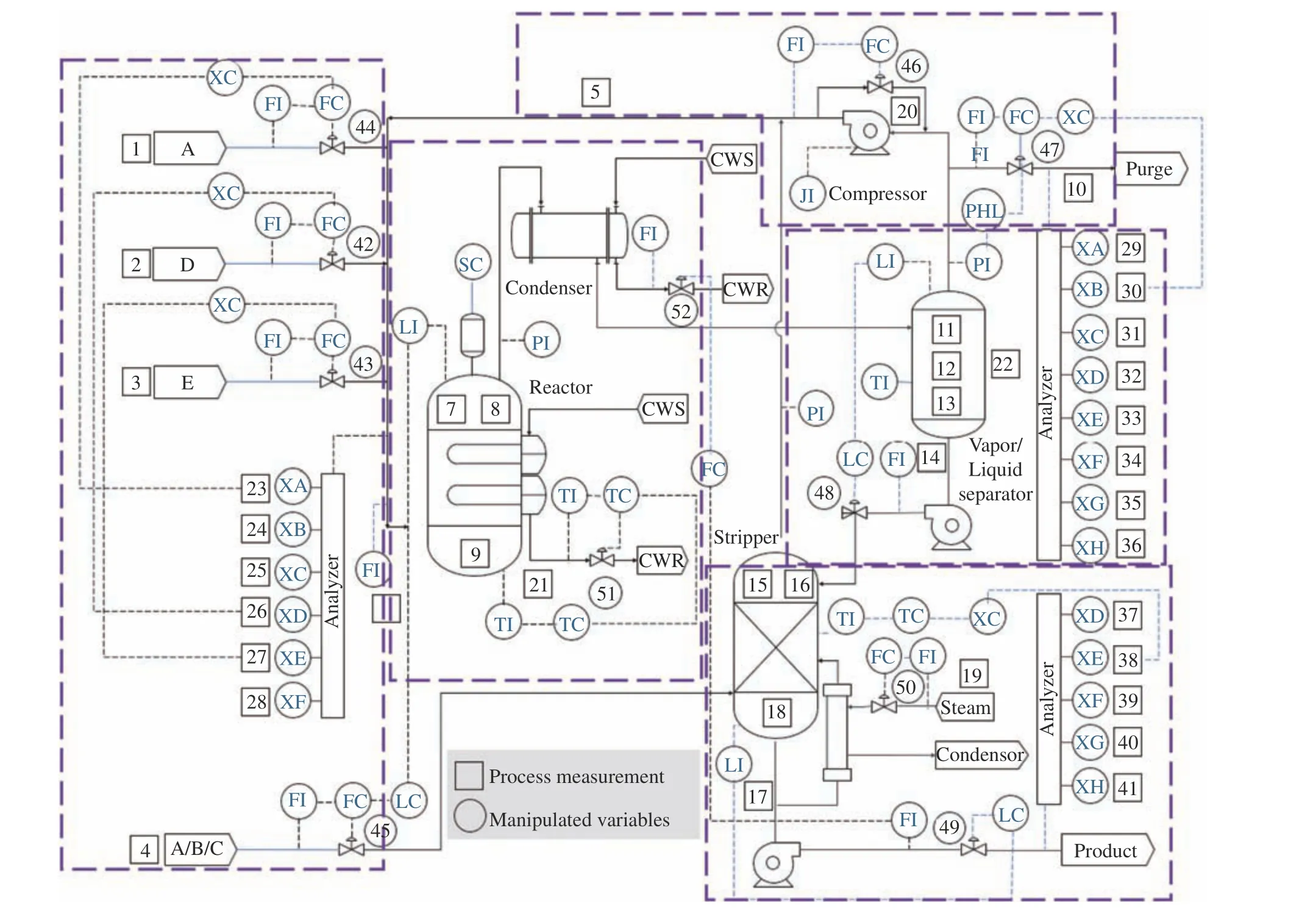
图5 TE 过程流程图[22]Fig.5 Flowchart of the TE process[22]
根据表2 中的故障描述,为每种故障定义了20 个细粒度属性,属性定义如表3 所示。每个故障定义的20 维的属性标签ai∈RC共同构成零样本故障诊断中的属性矩阵,用“1”表示故障具有该属性,用“0”表示不具有该属性,如图6 所示。依据零样本学习原则对数据集进行划分,在15 种故障中,选取12 种历史故障类用于训练,3 种目标故障类用于测试。TE 过程被划分为4 组数据集A,B,C,D,表4 示出了各个数据集下的训练类和测试类。每个数据集中有5760 个训练样本和1440 个测试样本。
表4 TE 过程的属性信息Table 4 Attributes information of TE process
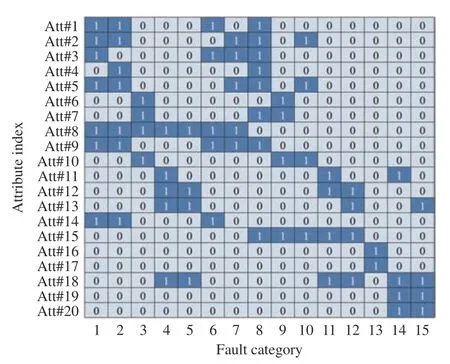
图6 TE 过程的属性矩阵Fig.6 Attribute matrix of TE process
3.2 零样本故障诊断结果
在数据集A、B、C、D 下,对比AMSM 方法和其他4 种零样本学习方法的识别准确率,如表5 所示,其中最好的结果加粗显示。ALE 方法[23]将故障从样本特征空间映射到语义属性空间后,学习一个兼容函数,用于衡量该样本与每个类别属性之间的匹配度,通过比较匹配度来预测测试样本的标签,识别效果较差,平均识别准确率最低,仅为39.78%。ESZSL 方法[24]将样本特征、属性和类之间的关系作为一个双层线性模型进行建模,用新的映射连接起属性空间和特征空间,最后做内积相似度识别测试样本类别,其平均识别准确率略高于ALE 方法,为43.42%。SJE 方法[25]利用多种模态的语义信息和构建兼容函数实现细粒度零样本分类,不同类别嵌入信息互补提升了分类性能,平均识别准确率达51.38%。FDAT 方法[19]采用监督主成分分析法提取属性相关特征,再对属性学习器进行训练,最后使用最近邻搜索确定最终的故障类别。该方法针对工业传感器信号提供了更有效的辅助信息,因此拥有较高的平均识别准确率,为68.57%。AMSM 充分学习了过程中不同单元间的相关性,利用注意力机制匹配样本特征和属性信息,在A,B,C,D 4 个数据集中都取得了最好的识别效果,准确率分别为85.21%,72.99%,61.88%和80.56%。AMSM 方法的平均识别准确率为75.16%,比FDAT 高了6.59%。

表5 TE 过程的零样本故障诊断结果Table 5 Result of zero-shot fault diagnosis on the TE process
为了更清晰地展示AMSM 方法对测试集故障的识别效果,绘制了4 个数据集故障诊断结果的混淆矩阵,如图7 所示,其中横坐标表示故障的预测类别,纵坐标表示故障的真实类别,图7(a) 示出了数据集A 中目标故障类1,6,14 的识别准确率,分别为96%,74%,86%。图7 结果表明基于属性描述的零样本故障诊断的可行性,即在没有目标故障类训练样本的条件下,基于属性描述可以对不同类型的故障进行诊断识别。
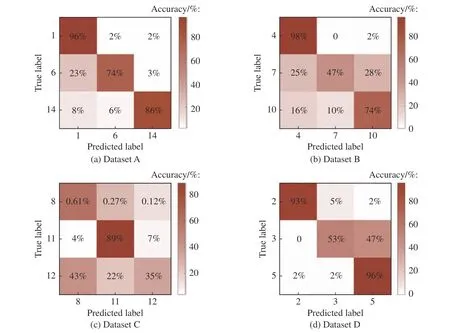
图7 TE 过程4 组数据集实验结果的混淆矩阵Fig.7 Confusion matrix of the results of four datasets in TE process
为了进一步说明AMSM 模型在零样本条件下的故障诊断效果,以数据集A 为例,对零样本条件下的AMSM 模型(AMSM(ZSL))和有监督条件下AMSM模型以及其他经典方法(有线性支持向量机(LSVM)、非线性随机森林(NRF)、朴素贝叶斯(NB)、XGBoost(XGB)和AdaBoost(ADA)) 进行比较。从TE 过程每个目标故障类的训练集中随机挑选1、10、50、200 和500 个样本用于训练,测试集各方法保持一致。这些有监督学习方法通过Scikit-learn 方法[26]中的默认参数实现,数据集A 的故障诊断结果如表6 所示。在有监督条件下,AMSM 模型在不同训练样本数量下其识别结果都是最优的,当训练样本为200 个时,AMSM模型已经实现对故障的精确识别,而其他方法达到相似的精度需要500 个故障样本。在零样本条件下,AMSM模型的表现与其他有监督学习方法相比依然具有竞争力,其识别准确率甚至比其他有监督学习方法在200 个训练样本条件下的结果更优。零样本故障诊断是在没有目标故障类样本可供训练的前提下,通过对历史故障类样本的训练和故障的属性描述实现对目标故障类的识别,因此更具有现实意义,难度更大。
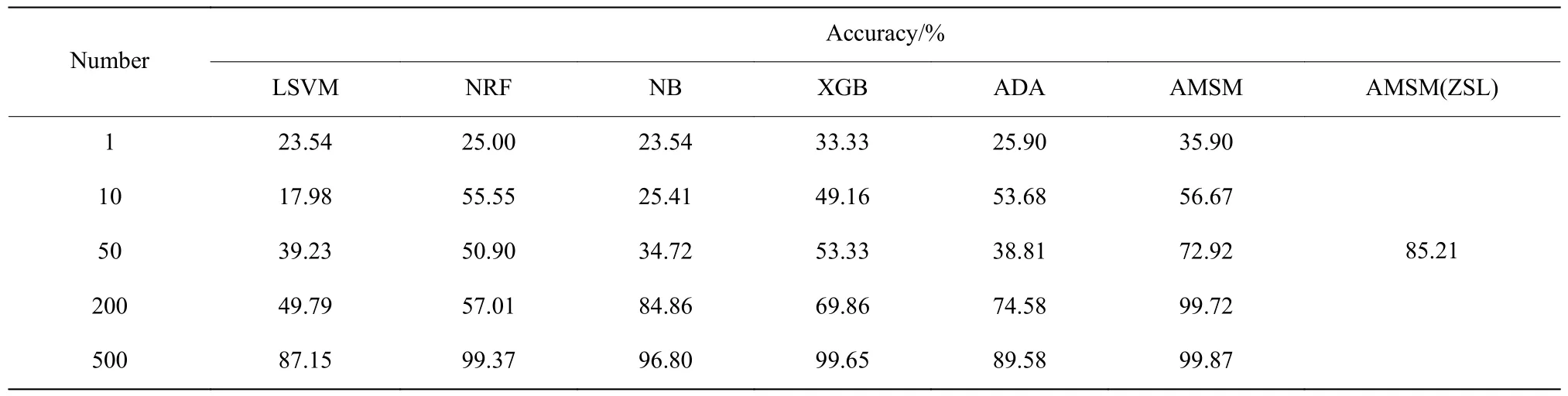
表6 AMSM 模型和有监督学习方法在数据集A 上的故障诊断结果比较Table 6 Comparison of the fault diagnosis results between AMSM and supervised learning methods on dataset A
在AMSM 模型中,SAE 从故障样本中学习的潜在属性信息构成了自注意力机制中的Q,通过不断训练K和V使得样本特征和属性信息相匹配。为了探索SAE 和自注意力机制在AMSM 模型中的作用,在数据集A,B,C,D 上进行了如下消融实验:(1)仅采用SAE 模型,将其提取的包含属性信息的潜在表征用于零样本故障诊断;(2)仅采用自注意力机制(SAM),用于获得K和V相似的FNN 结构来学习Q,最后实现零样本故障诊断。
图8 展示了SAE、SAM、AMSM 3 个模型在4 组数据集下的故障识别准确率,水平横线表示模型在A、B、C、D 4 组数据集上的平均准确率。无论是在各个数据集上的诊断性能,还是在平均指标上,都呈 现 出AMSM 效 果 最 好,SAM 次 之,SAE 最 差。SAE 模型结构最为简单,但是忽略了多单元过程中单元间复杂的相关关系,而且把样本直接映射到语义属性空间,缺少对样本特征的提取和利用。SAM模型虽然先从样本中提取了特征,但是由于Q矩阵也是借助FNN 结构生成的,并没有具体的包含故障属性的语义信息。而AMSM 模型将SAE 和SAM 相结合,借助SAE 进行预训练,使得学习到的Q矩阵包含了属性信息,而自注意力机制又考虑到了多单元之间的相关性,又促使特征矩阵K、V与Q的匹配,最终实现了最好的结果。
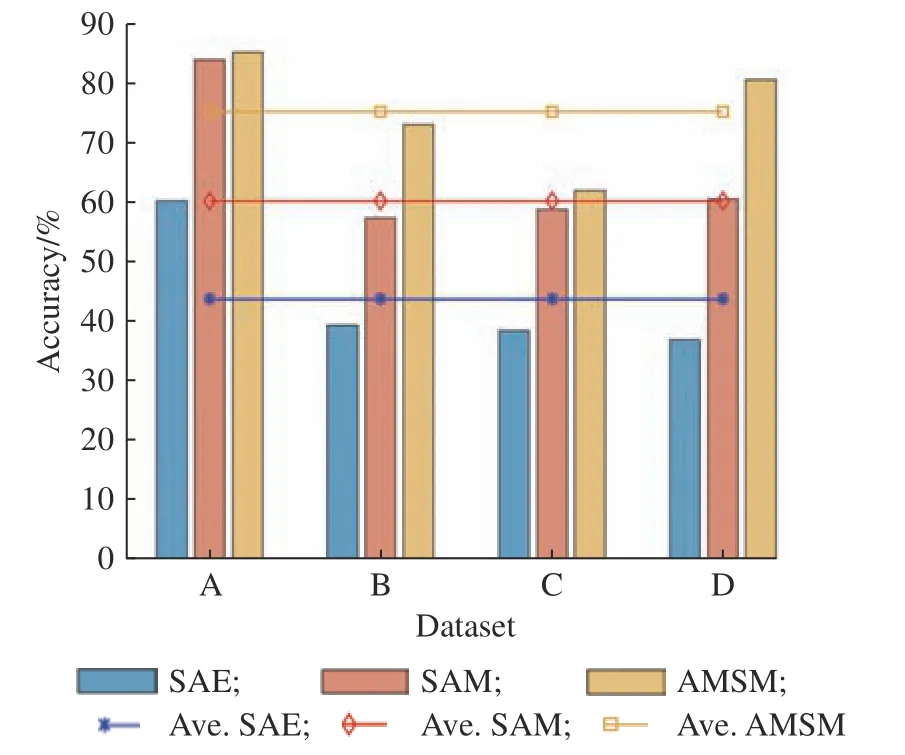
图8 SAE、SAM 和AMSM 模型的零样本故障诊断结果Fig.8 Zero-shot fault diagnosis results of the SAE, SAM and AMSM
通过与其他零样本学习方法的比较,说明AMSM 方法的可行性与优越性;通过消融实验,说明AMSM 方法中的SAE 和SAM 结构在零样本故障诊断任务中都起了重要作用。
4 结束语
本文针对多单元化工过程中目标故障类样本缺乏的问题,提出了基于属性描述的零样本故障诊断模型AMSM。该方法结合了SAE 和SAM,利用预训练的语义自编码器提供含有故障属性的语义信息,并通过自注意力机制在匹配语义信息不断学习更有效样本特征的同时,考虑了单元间的相关关系。以TE 过程为案例,通过与ALE、ESZSL、SJE 和FDAT 4 种零样本学习方法的比较进行性能评价;通过消融实验说明AMSM模型中SAE 和SAM 结构的重要性。但目前的工作仅限于故障识别,下一步工作重点将放在分析自注意力机制中单元和属性的相关性,在实现故障识别的前提下,将故障定位到具体的单元,实现故障定位。
