基于欠采样和源代码图表征的以太坊庞氏骗局检测
2024-01-04龚晓元刘冬明师自通
龚晓元,刘冬明,高 峰,师自通
(中北大学 计算机科学与技术学院,山西 太原 030051 )
0 引 言
自2008年中本聪首次提出去中心化的支付方案,并发行了第一种加密货币比特币[1]以来,区块链作为一种新兴技术,得到了蓬勃的发展。以太坊[2]作为区块链领域的大型金融交易平台之一,因其智能合约的存在而被广泛应用。由于其匿名性和监管困难,以太坊的健康发展仍然面临诸多难题,欺诈问题也日益频发,庞氏骗局便是其中之一。以太坊庞氏骗局是一种利用智能合约投资活动进行非法集资的诈骗行为,该骗局通常会以种种宣传术语来掩盖其真实目的,以高额的回报率不断地吸引投资者投入资金,来维持自身运转,当后来的投资者试图取回他们的投资时,通常会发现他们的资金已经被骗取。TRM Labs发布的2022年非法加密生态系统报告[3]显示加密货币庞氏骗局已经给投资者造成将近78亿美元的损失。因此,智能合约庞氏骗局的检测对于以太坊区块链的健康发展和投资者的财产安全至关重要。
当前,针对智能合约庞氏骗局的检测研究仍然非常有限,且基本都是从字节码层面和交易信息层面提取合约特征。Bartoletti等[4]提出基于标准化Levenshtein距离的方法来检测以太坊网络中的庞氏骗局。该方法通过蒙特卡洛算法[5]估算以太坊网络中两个任意智能合约的标准化Levenshtein距离,并作为智能合约相似度的判断依据,但是,临界值的设置缺乏科学证明,误报率很高。Chen等[6-7]利用以太坊区块链公开透明的特点,从用户账户和智能合约操作码两方面提取特征,基于数据挖掘的思路,充分利用区块链上的信息,使用随机森林(Random Forest,RF)和极端梯度提升(eXtreme Gradient Boosting,XGBoost)的方式大幅度提升了检测精度,并通过人工检查的方式贡献了一个庞氏骗局合约数据集XBlock。但是,前者的缺陷是由于从操作码中提取特征而无法获取智能合约丰富的语义结构信息和程序依赖信息,并且诈骗者可以通过调整合约编写方式来控制操作码的频率,从而绕过检测; 后者的缺陷是由于缺乏交易信息而无法在骗局合约部署伊始就进行主动检测。为了在智能合约全生命周期内有效检测庞氏骗局,Peng等[8]基于操作码的功能,通过系统化的建模逐步实现了智能庞氏骗局的高效自动检测模型,并且可以在智能合约部署初期进行检测工作。Shen等[9]将庞氏骗局检测问题转化为异常检测问题,将字节码转化为高维矩阵,使用孤立森林(Isolation Forest,Iforest)算法来识别智能合约中的庞氏骗局。Zhang等[10]创新地提取了字节码特征,并将其与用户交易和操作码频率相结合,获取了更全面的特征,提出一种基于改进LightGBM算法的智能合约庞氏骗局识别方法,对模型训练速度与模型性能均有显著提升。
在深度学习领域,Liang等[11]提出了一个数据驱动的庞氏骗局检测系统DSPSD,根据操作码和交易数据,直接预测合约是否为庞氏骗局。Jin等[12]提出了一个通用的异构特征增强模块,通过学习辅助异构交互图中基于元路径的行为特征,并将异构特征聚合到执行检测方法的同构图中的对应账户节点,进而捕获与账户行为模式相关的异构信息。He等[13]提出的Ethereum-CTRF方法,提取了合约代码的词特征、序列特征以及交易特征,并对数据进行了简单随机过采样处理,并构造了多粒度的网络模型,但这样容易过度拟合。Wang等[14]使用N-gram算法来提取更全面的操作码特征,同时引入自适应合成采样处理类别不平衡的数据,最终使用AdaBoost分类器进行骗局合约检测。
以上文献大多基于以太坊虚拟机层面的字节码特征、操作码特征和交易特征,但是,以太坊庞氏骗局作为使用Solidty高级语言[15]人为编写的以太坊智能合约,在高级语言层面包含丰富的语义语法信息、控制依赖关系和数据依赖关系,而字节码和操作码不能充分体现智能合约庞氏骗局的关键特征,且交易信息依赖合约的运行积累,阻碍了合约检测的时效性。同时,现有的检测方法在处理类别不平衡的数据空间方面存在不足,骗局合约在所有智能合约中的比例很低,在数据不平衡时,分类器模型更倾向于多数类样本,对少数骗局合约的敏感度较低,从而导致骗局合约检测的召回率较低。针对类别不平衡问题,Modha等[16]利用K-Means算法将多数类的样本进行聚类,合并聚类中心,以替换多数类样本,这种方法可以达到平衡数据集并且保留多数类样本特征的目的。
综上所述,针对现有方法存在类别不平衡、特征来源单一且不能完整表达智能合约语义语法信息和程序依赖信息的问题,本文提出了一种基于欠采样和源代码图表征的检测方法:首先使用基于代码相似度的聚类算法在数据层面解决智能合约类别不平衡问题,再通过改进构图算法从Solidty源代码层面挖掘能够区分庞氏骗局的关键特征,最后使用图神经网络模型提高对智能合约庞氏骗局的检测效果。
1 庞氏骗局检测方法
1.1 总体框架
本文提出的智能合约庞氏骗局检测方法的整体框架如图1 所示,首先根据数据集中的合约地址,使用爬虫工具从以太坊浏览器(etherscan.io)中爬取智能合约源代码和字节码,将所爬取源代码和字节码按照7∶3的比例分为训练集与测试集,其次使用Levenshtein算法和K-Means算法对字节码训练集中的正常合约进行欠采样处理,得到重组后的合约编号,使用合约编号重组源代码训练集,再利用重组后的源代码训练集和测试集进行合约图构建并对合约图进行标准化处理,然后训练图神经网络模型,并使用训练好的模型对测试集合约进行检测分类。
1.2 基于代码相似度的欠采样方法
本文基于代码相似度的欠采样方法,利用Levenshtein算法计算训练集中多数类智能合约之间的距离,进而通过K-Means算法对多数类智能合约进行聚类,有选择地丢弃多数类合约,保证了训练集骗局合约和正常合约类别的相对平衡。
1.2.1 Levenshtein算法
Bartoletti等[4]使用Levenshtein距离来计算以太坊网络中两个任意智能合约的相似度。1965年,俄国科学家Vladimir Levenshtein率先提出了Levenshtein算法,它采用动态规划思想来计算两个字符串之间的编辑距离,即对于给定的两个字符串S和T,由S转换为T,需要的最小编辑次数。该算法允许的编辑操作有:1) Insert,在被编辑的字符串中插入一个字符; 2) Delete:在被编辑的字符串中删除一个字符; 3) Swap,在被编辑的字符串中替换一个字符。Levenshtein算法的实现步骤如下:
算法 1:Levenshtein算法
输入:长度为a的字符串A,长度为b的字符串B。
输出:字符串A与字符串B之间的距离distance。
步骤 1:初始化一个(a+1)×(b+1)阶的编辑距离矩阵,记为DA,B(i,j),初始化第一行[0,b],第一列[0,a]。其计算公式为
DA,B(i,j)=
(1)
式中:A[i]≠B[j]是一个指示函数,当A[i]≠B[j]时,其值为1,否则为0。
步骤 2:比较字符串A和字符串B的字符。
步骤 3:根据式(1)填充距离矩阵。
步骤 4:重复步骤2和3直到DA,B[a+1,b+1]被填充。
步骤 5:得到Ldistance=DA,B[a+1,b+1]。Levenshtein距离可以作为智能合约相似度的表征,距离越小,合约特征越相近,反之,合约特征差异越大。
1.2.2 K-Means算法与多数类样本筛选
多数类样本筛选是指在多数类智能合约欠采样过程中,对不同智能合约的字节码进行聚类,距离相近的合约成为一类,去掉相似度高的合约样本,使得被选择的样本仍然能够很好地表征正常合约的多数特征。
K-Means算法的核心思想是将智能合约字节码划分为多个聚类,使得每个聚类中智能合约到该聚类中心的Levenshtein距离的平方和最小。K-Means算法的评价准则是误差平方和准则,计算公式为
(2)
式中:SSE为误差平方和;k为簇的数量;Ldistance为算法1中提出的Levenshtein距离。
以下为多数类样本选择算法的过程:
算法 2:多数类样本选择算法
输入:多数类智能合约样本,
输出:重组后的多数类智能合约样本。
步骤 1:随机选择k个样本作为智能合约的初始聚类中心;
步骤 2:使用算法1计算其余合约到各聚类中心的Levenshtein距离,并将其分配到Levenshtein距离最近的簇中;
步骤 3:通过计算各簇的距离均值,更新聚类中心;
步骤 4:计算SSE;
步骤 5:重复步骤2,3,4,直到SSE收敛(不再变化);
步骤 6:从每个簇中随机抽取单个样本,构造重组后的多数类智能合约样本。
1.3 源代码图表征
图作为计算机科学中的一种复杂数据结构,以抽象的方式表现了数据或实体间某种多对多的复杂关系。这些数据或实体被称为节点,而不同节点间的相关关系被称为边。Zhuang等[17]提出了一种能够保存程序语义语法信息、控制依赖关系和数据依赖关系的智能合约构图方法,把智能合约中的某些函数和变量抽取为节点,把程序执行可能穿过的路径设置为边,将智能合约源代码提取为合约图。
1.3.1 构图方法改进
智能合约庞氏骗局检测问题的关键在于如何对智能合约源代码进行特征提取。Zhuang等[17]的方法应用于漏洞检测时,庞氏骗局合约与漏洞合约的不同之处在于,前者在程序规则上合法,程序行为完全符合语义语法规则,而后者会利用程序漏洞使程序产生语义语法规则以外的结果。因此,本文结合人工分析骗局合约源代码,在前人的基础上改进了合约图构图算法,让图神经网络捕获并学习图的拓扑结构关系、节点间的控制依赖和数据依赖等信息,进而在保留源代码语义信息的同时对蕴藏其中的行为特征进行充分挖掘,提高模型对骗局合约的识别能力。改进后的构图算法有如下变化:
1) 去除回退节点。因为Fallback()函数作为智能合约定义的安全默认函数,尽管其作为节点特征在智能合约漏洞检测中极其重要,但是庞氏骗局合约本质上是一种特征的欺诈合约模式,在程序规则上是合法的。因此,骗局合约与漏洞合约并非同一层面的安全问题,故本文方法取消设置回退节点,同时取消与其相连的回退边。
2) 将账户(用户)余额这一关键变量设置为核心节点。通过人工分析骗局合约源代码,可以发现用于表示合约账户余额的变量在用户投资和返利方面比较活跃,所以本文方法将其设置为核心节点,让神经网络可以自行学习其变化特征。
3) 删除向前边。考虑到向前边实质上并不包含语义语法信息,而且这种冗余的特征还会干扰神经网络的学习效果,故将其取消。
1.3.2 节点表征
合约图包含两类节点:核心节点(Core Node,简称C)和普通节点(Normal Node,简称N)。
核心节点C代表对骗局合约检测具有重要影响的关键函数调用和关键变量:
1) 用来发送以太币的call.value()、send()和transfer()三个内置函数。
2) 对前述三个转账函数调用的函数W和对W进行调用的函数V。
3) 用于表示合约账户余额的变量,Balance[msg.sender],players[wating]等。
普通节点N代表函数W和函数V中没有被提取为核心节点的变量。
1.3.3 边表征
合约图包含两类有向边:控制流边(Control Edge,CE)和数据流边(Date Edge,DE)。表1 详细记录了两种有向边的类型及其语义信息。控制流边来源于控制合约执行路径的程序语句,例如循环控制和条件判断。数据流边来源于赋值语句和控制访问,例如赋值、比较和运算语句。

表1 有向边的分类和表示
按照上述节点表征方式和边表征方式,对智能合约源代码进行静态扫描,生成合约图,如图2 所示。

(a) 庞氏骗局合约片段
1.4 合约图标准化
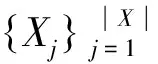

(3)
图3 是对图2(b) 合约图进行聚合优化后的标准化合约图。

图3 合约图标准化
2 实验分析
2.1 数据集
本文使用Chen等[6]给出的智能合约庞氏骗局数据集XBlock,该数据集具体包括3 793个智能合约地址及其标签。其中:共有200个庞氏骗局合约地址和3 593个非庞氏骗局合约地址,在这3 593个非庞氏骗局合约里,有2个废弃合约和3个错误标签合约,将这些合约排除后,剩下3 788个可用合约,骗局合约与正常合约的比例接近1∶18; 庞氏骗局的标签为1,非庞氏骗局合约的标签为0。
2.2 实验模型与评价指标
本文实验选用图卷积神经网络(Graph Convolutional Network,GCN),采用one-hot编码,并为每一类特征都维护一个one-hot字典,将最终提取到的合约图特征与其字典对照,然后将离散特征的取值扩展到欧氏空间,最后进行拼接,实现对合约图特征的向量化表示,将其作为GCN模型的输入。实验环境参数如表2 所示。

表2 实验环境参数
实验采用XBlock数据集,迭代次数epoch=30,学习率设置为0.002,dropout设置为0.7,批大小为32,GCN模型参数如表3 所示。

表3 GCN模型参数
表4 为智能合约庞氏骗局检测混淆矩阵。

表4 智能合约庞氏骗局检测的混淆矩阵
智能合约庞氏骗局检测时,由于骗局合约的数量很少,如果模型认定测试集中所有合约都为正常合约,那么模型的准确率指标也会很高。所以,本文在选取智能合约庞氏骗局检测的评价指标时,放弃使用准确率(Accuracy),最终选取了精确率、召回率和F1值来评价模型的分类性能,计算过程如下:
(4)
(5)
(6)
式中:NTP为实际骗局合约被检测为骗局合约的数量;NFP为实际正常合约的合约代码被检测为骗局合约的数量;NFN为实际骗局合约被检测为正常漏洞的数量;P为精确率,反映了模型所预测的骗局合约是否准确;R为召回率,反映了模型是否能够检测出所有骗局合约;F1综合了骗局合约检测的精确率与召回率,全面反映了模型对于智能合约的分类效果。对于骗局合约检测,本文的预期效果是在保证精确率的前提下提高召回率,找出更多骗局合约,以减少其带来的危害。
2.3 欠采样倍率选择实验
重组后训练集的类别比例取决于欠采样倍率,并且会最终影响模型的性能,因为欠采样会造成信息缺失,即将正常合约丢弃可能会导致模型丢失正常合约的重要信息。
在不同欠采样倍率下,不同类别比例的重组训练集对本文方法所得P、R和F1的影响如图4 所示。

图4 不同采样倍率的实验结果
由图4 可得,当重组训练集比例为1∶3时,模型的召回率和F1值最高,而精度略低,主要原因是丢弃掉太多的正常合约样本,使得模型将正常合约误判为骗局合约,并且随着比例的增大,模型的性能会快速下降,因为在数据极度不平衡时,模型受到权重的影响而对骗局合约的敏感度降低,从而使检测性能下降。
由于在真实以太坊网络中骗局合约远少于正常合约,所以本文选择较低的精确率,而选择更高的召回率,最终使用了重组后比例为1∶3的训练集所对应的网络模型,提高了智能合约庞氏骗局的检测效果。
2.4 消融实验
为了验证本文方法对于智能合约庞氏骗局检测的有效性,进行了消融对比实验,主要是将本文方法与以下两种方法进行了比较:① 重组前训练集和改进构图算法相结合的方法; ② 重组后训练集和原始构图算法相结合的方法。
如图5 所示,本文方法与方法①的对比证明了本文基于代码相似度的欠采样方法的有效性,通过采用Levenshtein距离算法+K-Means算法对特征相近的正常合约进行了聚类,丢弃一部分正常合约,使得重组后的训练集相对平衡,提高了模型对骗局合约的关注度,从而显著提高了骗局合约的召回率; 本文方法与方法②的对比证明了本文针对庞氏骗局合约改进的智能合约构图方法的有效性,通过去掉冗余的节点和有向边,将源代码中表示合约余额的关键变量设置为新的核心节点,改进了源代码表征方式,使得网络模型能够更好地学习骗局合约的关键特征,提升了对于骗局合约的关注度和敏感程度,因此可以找出更多的骗局合约,将召回率提高了33%,从而极大地提升了模型的性能。
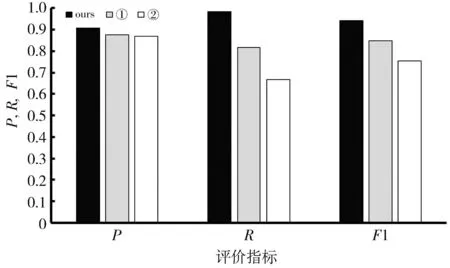
图5 消融实验结果
2.5 智能合约庞氏骗局检测的对比实验
为了进一步验证本文方法对智能合约庞氏骗局检测的有效性,综合认可度,分别选取传统机器学习方法、改进机器学习方法和深度学习方法,将本文方法与SVM,XGBoost,RF[7],IForest[9],DSPSD[11],Ethereum-CTRF[13],AdaBoost[14]进行实验对比,结果如表5 所示。
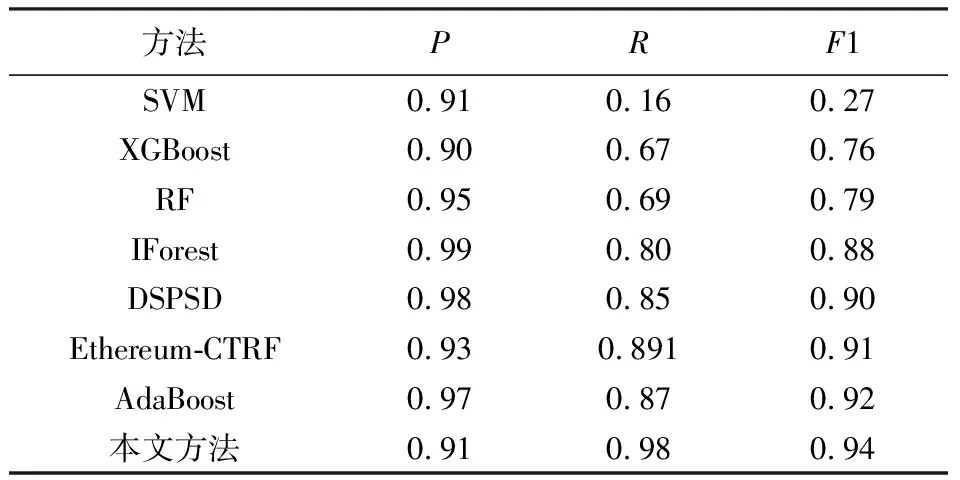
表5 不同分类方法的结果对比
通过对比表5 中各分类方法的评价指标,可以看出,在前4种机器学习方法中,孤立森林(IForest)方法对智能合约庞氏骗局检测的性能最优,精确率为99%,召回率为80%,F1值为88%,仅次于深度学习方法DSPSD。本文方法的精确率为91%,非常接近其余5种方法; 本文方法的召回率和F1值分别为98%和94%,明显优于其余5种方法。在骗局合约识别中,本文方法期望在保证精确率的前提下提高召回率,尽可能多地找出更多骗局合约,以减少其带来的危害。综上所述,本文方法对智能合约庞氏骗局的检测效果有所提升。
3 结 论
本文针对以太坊庞氏骗局合约检测进行了研究,通过分析源代码的特点,提出了一种基于欠采样和源代码图表征的智能合约庞氏骗局检测方法,使用Levenshtein算法和K-Means算法,在数据层面解决了智能合约类别不平衡的问题,避免了模型的过度拟合。本文首次引入了高级语言构图方法用于庞氏骗局合约的源代码构图,同时改进了构图算法,以便于从Solidty源代码层面挖掘能够区分庞氏骗局的关键特征,从而提升了网络模型对庞氏骗局合约的敏感程度。实验结果表明,本文方法在XBlock数据集上,在牺牲少许精度的情况下,显著提升了智能合约庞氏骗局的召回率和F1值。本文方法在进行智能合约类别不平衡处理时,只关注了字节码之间的编辑距离,没有考虑其具体含义,今后的研究工作应在智能合约聚类时关注其语义语法信息,引入更加严格的量化指标来进行核心节点选取,并将合约类别和交易信息等特征引入模型训练,以进一步提高模型的检测性能。
