基于深度学习的高分辨率食管测压图谱鉴别
2024-01-04吕志贤侯木舟
吕志贤,侯木舟,曹 聪
(中南大学 数学与统计学院,湖南 长沙 410083)
0 引 言
医学影像分析技术在医疗诊断中发挥着越来越重要的作用,基于传统机器学习算法的医学影像识别主要包括图像特征提取和图像识别两个步骤,需要人工提取医学影像特征,识别准确率偏低[1-2]。分割任务是检测病变的位置和边界,而分类任务是诊断病变的类型,但由于医学图像数据特征不明显,分类的效果并不好。深度学习算法省去了传统机器学习算法的图像特征提取步骤,利用网络结构自动提取图像特征并分类,识别准确率较高。2013年,Cruz-Roa等[3]利用卷积神经网络来自动检测基底细胞癌; 2016年,Kawahara等[4]利用卷积神经网络来识别皮肤癌图像; 2018年,Harangi等[5]利用CNN网络对皮肤癌影像进行诊断分类; 2019年,周进凡[6]利用改进的VGG16网络对肺部X光图像进行识别预测,取得了优异的效果; 2021年,Zhou等[7]提出一种集成深度学习模型,完成了对新冠肺炎患者、肺部肿瘤患者和正常三种类型图像的识别; 2022年,Demir等[8]提出一种基于MRI图像自动检测脑肿瘤的深度学习方法,对两个互相独立的数据集进行评估,准确率分别为98.8%和96.6%。此外,还有越来越多的深度学习模型被运用到了医学图像的辨别诊断中。
近年来,食管动力障碍性疾病的患病率呈逐年上升的趋势,对其诊断主要采用高分辨率食管测压方法,该方法是一种固态的测压方法,可以实现从食管到胃的所有高精度数据的采集,并且可以实时监测整个食管的收缩功能。高分辨率食管测压图谱(HRM)的分类对诊断结果有非常大的影响,当前,主要采用芝加哥分类诊断标准[9-10]进行高分辨率食管测压图谱分类。2021年,Kou等[11]利用 32 000个多原始吞咽数据,建立了基于变分自动编码器(VAE)方法的生成模型,具备对食管收缩活力类型进行进一步评估判别的能力,对测试数据集判别的总体精确度为64%; 同年,Kou等还提出了基于长短期记忆神经网络(LSTM)的HRM图谱食管收缩活力自动分类模型[12],其总体分类精确度为83%。2022年,贺福利等[13]提出了PoS-ClasNet深度学习模型,可以实现食管收缩活力HRM图像的自动分类,这些研究仅把图谱分为三类,且在分类网络前用了分割网络,训练成本更高。而高分辨率食管测压图谱成像的特殊性[14-16]、诊断的复杂性和疾病的多样性使得深度学习在这类图谱分类的研究中应用较少。因此,本文对基于深度学习的食管动力障碍性疾病鉴别诊断进行了研究,且将高分辨率食管测压图谱分为正常收缩、全段增压、弱收缩、无效收缩四大类。本文对传统VGG网络模型进行改进,优化其结构,增大卷积核,并添加Batch Normalization层和Dropout层,可以提高识别的速度与精度,并能够在较低性能计算机上快速完成高分辨率食管测压图谱的特征自学习与训练。基于改进VGG网络模型构建的高分辨率食管测压图谱分类器可以应用于临床辅助医生进行图像鉴别与分析,在降低医生工作量的同时,可以提升其工作效率,降低误诊和漏诊的风险。
1 数据预处理
本文的HRM数据来自湘雅医院消化内科,其中,训练集、验证集、测试集的比例为7∶1∶2。正常收缩、全段增压、弱收缩、无效收缩这4种类型的HRM图像如图1 所示,首先需要对图像进行预处理。为了适应本文的NFWIC模型,将像素大小为831×544的原始图片调整为180×180。从高分辨率食管测压图谱中可以观察到,图片上有许多便于人眼分类的线,这些线对计算机没有实际意义,还会影响到计算机对高分辨率食管测压图谱分类的精度,本文采取用高斯去噪方法和高斯核卷积去噪滤波平滑处理消除此类影响,图2 为预处理前后的图片。
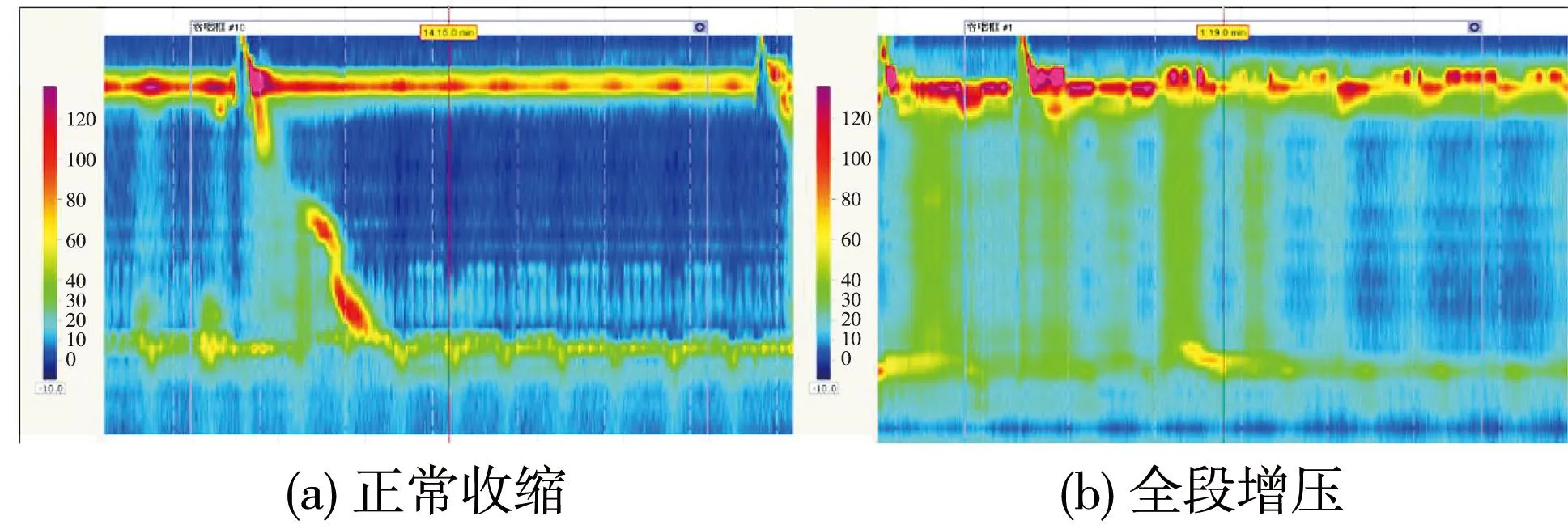
图1 高分辨率食管测压图谱
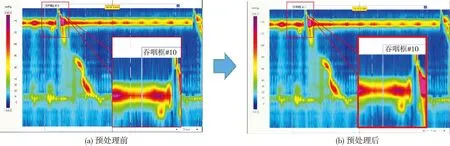
图2 预处理前后的高分辨率食管测压图谱
由于数据中全段增压图像仅有278张,影响模型对其特征的学习,但由于高分辨率食管测压图谱的特殊性,传统的数据增强方法对其增强的效果不佳。为了解决该问题,本文将预处理后的278张图片以及预处理前的278张图片都放入训练集以增加训练样本数。
2 基于深度学习的NFWIC分类模型
2.1 传统的VGG网络模型
卷积神经网络(CNN)作为一种应用广泛的深度学习框架,在特征提取、图片分割和分类方面都具有优异的性能。1943年,Mcculloch提出了MP模型[16],Fukushima提出了神经认知机[17],1990年,Lecun提出了现代CNN框架的原始版[18],并于1998年提出了改进的CNN模型——LeNet-5[19],这为CNN的发展奠定了基础。2006年以来,研究者提出了许多方法来改进CNN算法,其中,由Krizhevsky等提出的AlexNet框架的性能比之前的模型有了显著提升[20]。此后,越来越多的CNN模型被提出,如VGGNet[21]、GoogLeNet[22]等,这些模型的结构也变得越来越复杂。为了防止过拟合等问题,本文对比了当前的几种主流网络,最终根据HRM数据的特性选取了由Simonyan等提出的VGG模型[21]。VGG的卷积核大小均为3×3的小卷积核,这有利于细节变化的学习,池化核为2×2,而且由于卷积层通道数的扩大,池化层尺寸的缩小,使得VGG模型变得更深更宽的同时,计算量的增加幅度变小。
2.2 改进的VGG模型
2.2.1 Batch Normalization层的添加
卷积神经网络的学习过程是为了学习数据的分布,如果前面通过卷积得到的数据分布不同,那么就会降低模型的泛化能力。为此,本研究将在每个最大池化层后加入一个Batch Normalization层,如图3 所示。Batch Normalization层将一个batch数据转化为平均值为0,方差为1的数据。加入Batch Normalization层对数据进行标准化时,减小了内部协变量对训练速度的影响,使训练速度加快[23],同时,可以在一定程度上防止过拟合,并减小对初始数值的依赖性。

图3 VGG模型中Batch Normalization层的添加
Batch Normalization层的处理算法如下:
1) 假设输入数据的Batch=n,输入的样本为x1,…,xn,则输入数据的平均值μ和标准差σ为
(1)
(2)
2) 将数据归一化为
(3)
式中:ε=10-5,可以保证等式的成立。
3) 通过尺度变换和偏置来恢复原始数据的特征分布。
(4)
βi=E(xi),
(5)
yi=γixi+βi,
(6)
式中:Var为方差函数;E为均值函数;yi为最终输出。
2.2.2 Dropout层的添加
在卷积神经网络训练中,训练样本数量过少而用于提取特征的参数过多时,很多样本特有的特征也被提取,因而会产生过拟合现象。通过添加Dropout层可以降低过拟合,本研究在所有线性层后都加入了Dropout层,设置Dropout比率为0.5,如图4 所示。每次训练时将舍弃50%的输出结果,即将50%的输出结果设置为0,其余结果不变,如图5 所示。添加Dropout层能够提高模型的泛化能力,从而增强模型的高分辨率食管测压图谱分类能力。

图4 VGG模型中Dropout层的添加
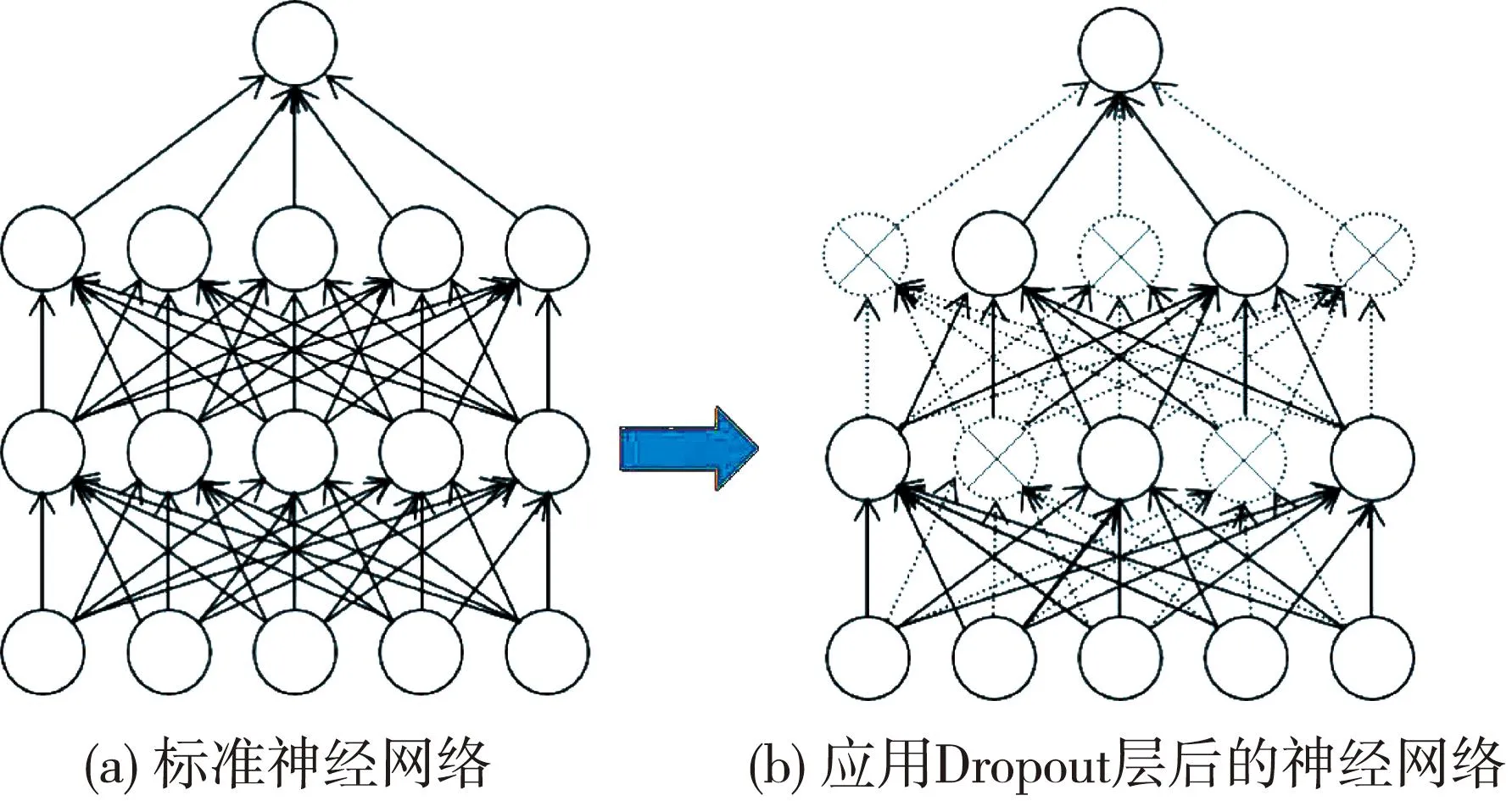
图5 应用Dropout层前后的神经网络对比
2.2.3 卷积核大小的调整
传统VGG网络模型中的卷积核大小均为3×3,这是为了提取更细微的特征,而高分辨率食管测压图谱的鉴别诊断不需要太多细微特征。为此,本研究调整了卷积核大小,其中把第二模块的卷积核调为5×5,第三模块的卷积核调为7×7,第四模块的卷积核调为5×5。研究发现,在相同卷积步长和同等卷积深度的情况下,5×5的卷积核相对于3×3的卷积核能获取更大的感受野。经过卷积计算后,更大的卷积核得到了更小的计算结果,计算公式为
(7)
(8)
式中:W为图像宽度;H为图像高度;P为图像增加的边界层数;K为卷积核大小;S为卷积核步长。相应地,为了体现卷积运算后显示的图片大小,用输出维数表示输入维数,计算公式可变为
Winput=(Woutput-1)*S+K-2*P,
(9)
Hinput=(Houtput-1)*S+K-2*P。
(10)
若取图像增加的边界层数P为0,卷积核步长S为1,输出图片的长度和宽度均为1。
Winput=Hinput=(1-1)*1+K-2*0=K。
(11)
2.3 改进VGG网络的NFWIC分类模型
基于改进的VGG网络模型和本文提出的NFWIC分类模型结构分别如图6 和图7 所示。首先,基于原始的HRM训练数据,进行高斯滤波去噪的预处理,再基于改进的VGG网络来训练数据,采用交叉熵的损失函数和Adam优化器,基于训练的模型和参数对测试集进行预测分析,输出最终的正常收缩、弱收缩、全段增压、无效收缩四分类结果。改进的VGG网络模型一共有4个特征提取模块,每个模块都是由卷积层ReLU激活函数卷积层ReLU激活函数最大池化层构成,区别在于4个模块的卷积层中卷积核的大小是不同的,其中,第一模块为3×3,第二模块为5×5,第三模块为7×7,第四模块为5×5。每个模块都会把特征通道数乘2,再通过一个2×2的最大池化层,最后再由Batch Normalization层标准化数据。通过这4个特征提取模块之后,数据进入分类模块,先由Flatter层将数据转化成一维数据,经过3个线性层,并在线性层前先经过Dropout层,避免过拟合。最后一个线性层不再采用ReLU激活函数,而是用softmax得到每一类图片的预测概率。

图6 改进的VGG网络模型
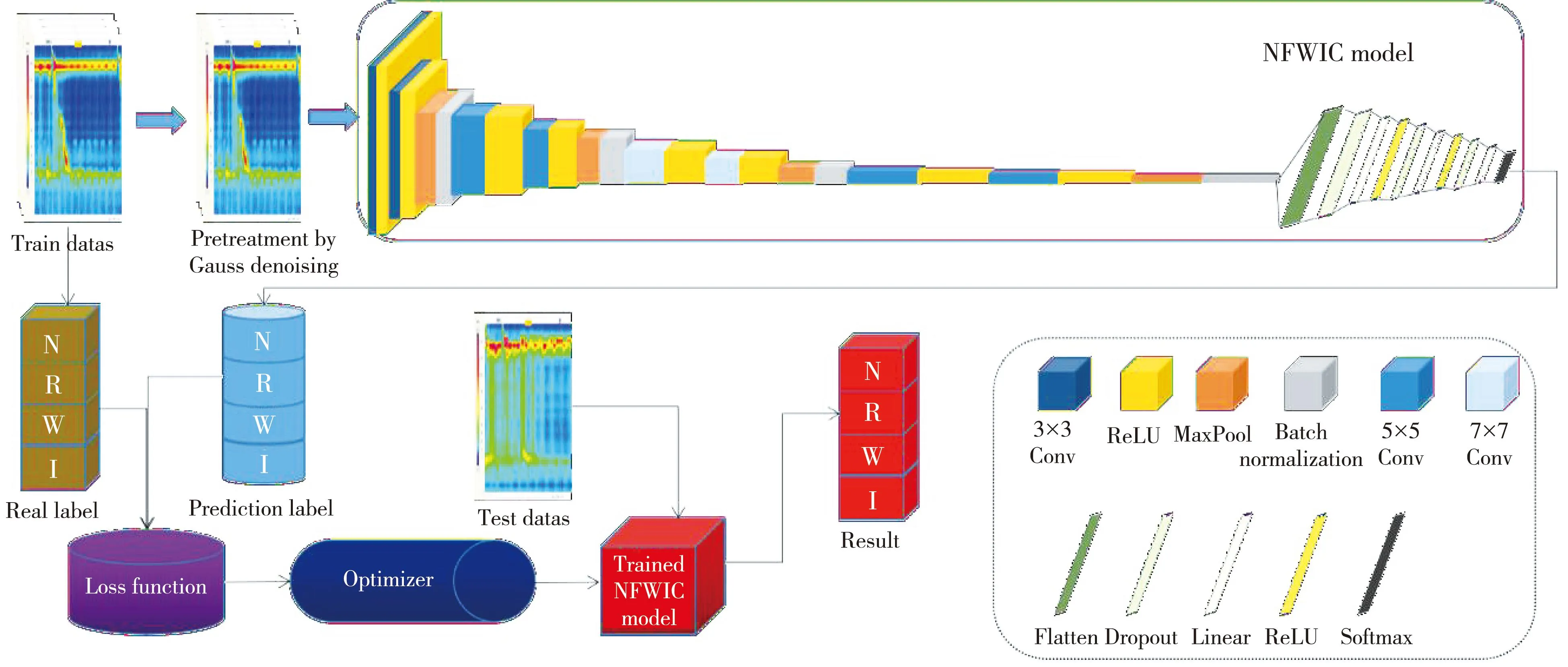
图7 改进VGG的NFWIC分类模型结构
3 验证实验
3.1 数据来源
本文使用了中南大学湘雅医院于2019年至2020年采集的实验数据集。该数据集包含2 520幅高分辨率食管测压图谱,由固态高分辨率测压系统ManoScan 360TM(Sierra Scientific Instruments)检测,并由采集和分析软件Mano View ESO3.0生成[24]。每位病人有10张图片,通过对这些高分辨率食管测压图谱进行分类整理,得到最终有效的数据集,其中,正常收缩图片890幅,弱收缩图像561幅,全段增压图像278幅,无效收缩图像791幅,得到的每张HRM原始图片的尺寸为831×544像素。所有图像的真实标签由中南大学湘雅医院消化科专家基于CCv3.0标准和Mano View ESO3.0的分析报告对每幅高分辨率食管测压图谱图像的食管收缩活力类型进行深入探讨后给出。实验数据采集自全国各地的患者,代表性较强。
3.2 实验环境设置
实验中使用联想IdeaPad720s-14IKBR,CPU为第八代智能英特尔酷睿i5-8250U。在python环境的pytorch框架和Tensorflow后端中实现。本研究将尺寸为831×544的原始图片调整为180×180,这两个尺寸的图片只是分辨率有所不同,内容上无任何差距。缩小尺寸可以让改进的VGG模型更好地处理图像,减少运算量,加快运算速度。实验随机选取70%作为训练图片来训练模型,10%作为验证图片来得到最佳的模型参数,20%作为测试图片来测试模型的分类准确性及可靠性。训练神经网络时,设置batchsize=10,每一批都放入10张图片进行模型训练。
改进的VGG模型的4个模块中都加入了批标准化Batch Normalization以加快训练速度,在全连接层加入了以0.5的概率失活的Dropout来防止过拟合。除最后分类的激活函数为softmax(x)外均采用ReLU(x)为激活函数。训练的轮数设置为epoch=50,每个epoch结束后会将最优的模型储存下来以方便后续的测试。损失函数为多元交叉熵函数,用来确定模型的最佳性能。参数优化器为Adam优化器,初始化学习率设为0.001,权重衰减为0.000 5。
3.3 训练结构

(12)

参数优化器:卷积神经网络在更新参数时都需要优化器逐步优化参数,常见的优化器有SGD、Adam、Adagrad等。本研究中采用Adam优化器,设置学习率为0.001,权重衰减为0.000 5。Adam的计算公式[26]为
mt=β1mt-1+(1-β1)gt,
(13)
(14)
(15)
(16)
工作流程:先将高分辨率食管测压图谱预处理,将预处理后的图片输入到NFWIC模型中进行训练,得到预测标签,利用预测标签与输入图片的真实标签计算损失函数。通过优化器更新改进NFWIC模型中的VGG网络中的参数更新模型,经过多次训练得到性能最优的模型。将用于测试的高分辨率食管测压图谱输入到训练好的NFWIC模型中得到图片的分类结果。具体的NFWIC模型工作流程如图8 所示。
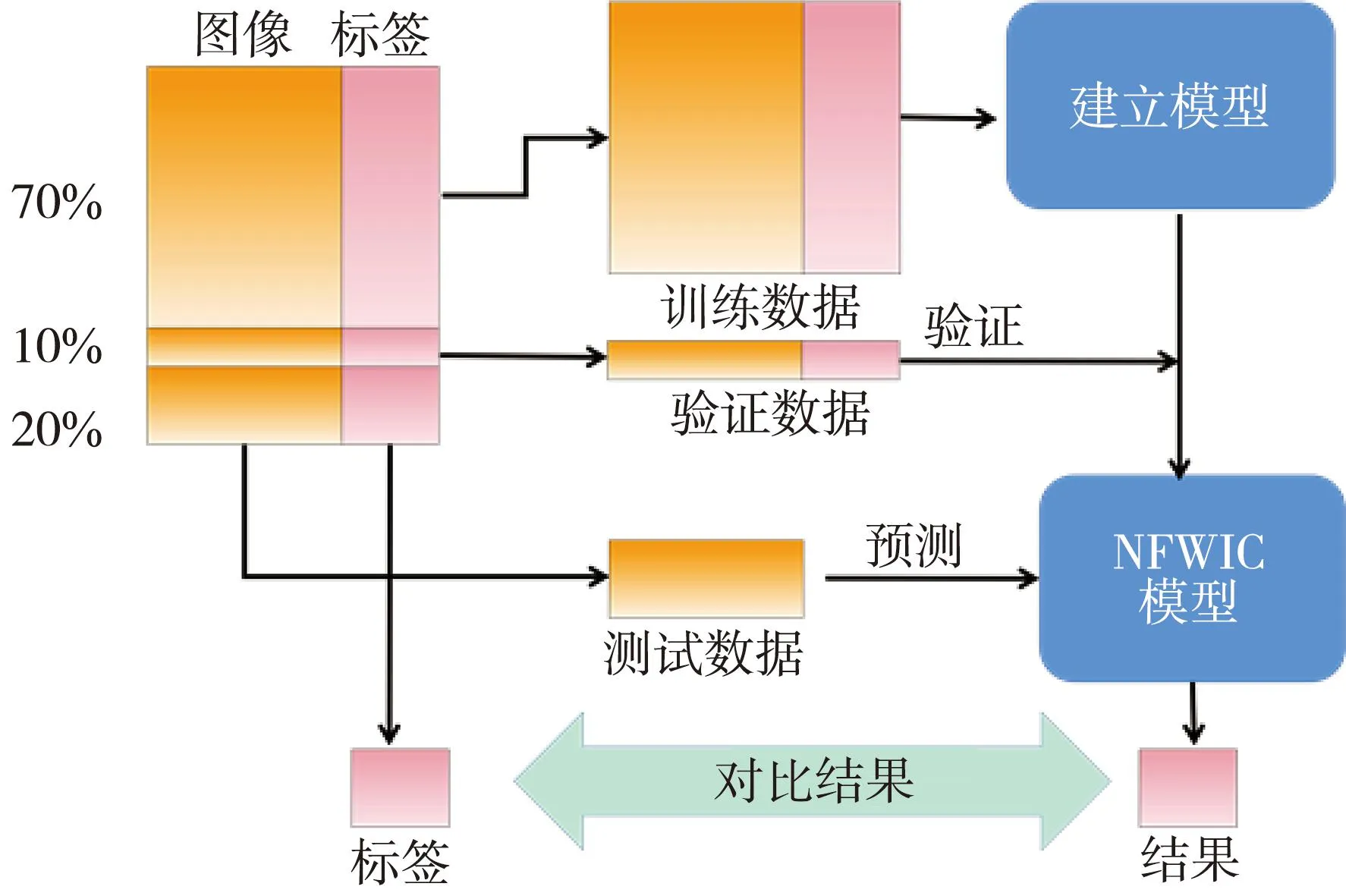
图8 NFWIC模型训练流程图
3.4 评价指标
对于分类问题,用TP,TN,FP,FN分别表示真阳性、真阴性、假阳性、假阴性的预测值。对于多分类问题可以取其中一种为阳性,其余三种为阴性来获取实验数据。本研究中采用典型的性能指标:准确率Racc(Accuracy)是对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。精度Rpre(Precision)是指在预测为正类的样本中真正类所占的比例。召回率Rrec(Recall)是指在所有的正类中被预测为正类的比例。F1得分(F1-Score),作为评价标准来衡量分类器的综合性能。灵敏度Rsen(Sensitivity)即为真阳性是正确预测为正类的比例,特异度Rspe(Specificity)是正确预测为非正类的比例。计算公式为
(17)
(18)
(19)
(20)
(21)
除此之外,以真阳性率Rsen为y轴,假阳性率(1-Rspe)为x轴绘制了ROC(Receiver Operating Characteristic)曲线并计算ROC曲线下方的面积AUC,来评估本文的分类模型。ROC曲线图中,越靠近左上角(0,1)的点对应的模型性能越好。
3.5 实验结果
3.5.1 各模型的图像分类性能比较
实验中,改进的VGG模型训练每一个epoch需要的平均时间为1 242.914 4 s,而传统的VGG模型需要的平均时间为1 861.196 4 s,即改进的VGG模型训练时间缩短。本研究将改进的VGG模型与VGGNet、ResNet50、Inception-v3等几种常见的用于医学影像分类的卷积神经网络所得训练结果进行比较。表1 和图9 为4种模型的定量分析结果,可以看出测试集中改进VGG模型的各项指标均优于VGG模型,其中,图片分类的平均准确率达到97.20%,平均精度达到93.97%,平均召回率达到93.97%,平均F1得分达到0.939 5,平均特异度达到98.05%。除改进的VGG模型外,其他模型都出现了过拟合现象,这是后续研究中需要改进的。造成这种情况的原因有:1) 高分辨率食管测压图谱成像的临床操作中,很容易出现噪声污染,且不同的图片污染程度不同,这加大了特征提取的难度。2) 采集实验数据并赋标签的工作较为繁琐,导致采集的实验数据量较少,从而加大了训练模型的难度。与PoS-ClasNet模型[13]相比,本文的模型在实验中各项指标都有明显的提升。综上分析,虽然改进的VGG模型还有许多局限性,但是各项指标均有提升,因此,所得结果具有一定的参考价值。
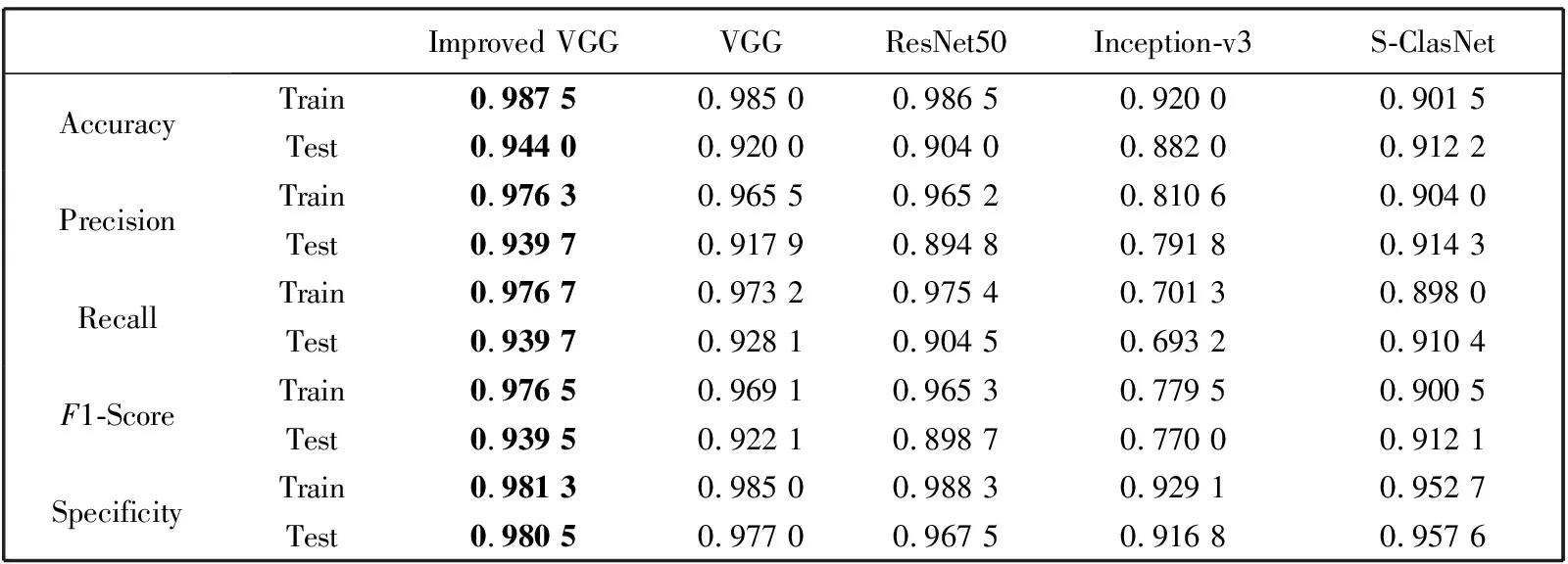
表1 不同模型对高分辨率食管测压图谱分类的结果比较
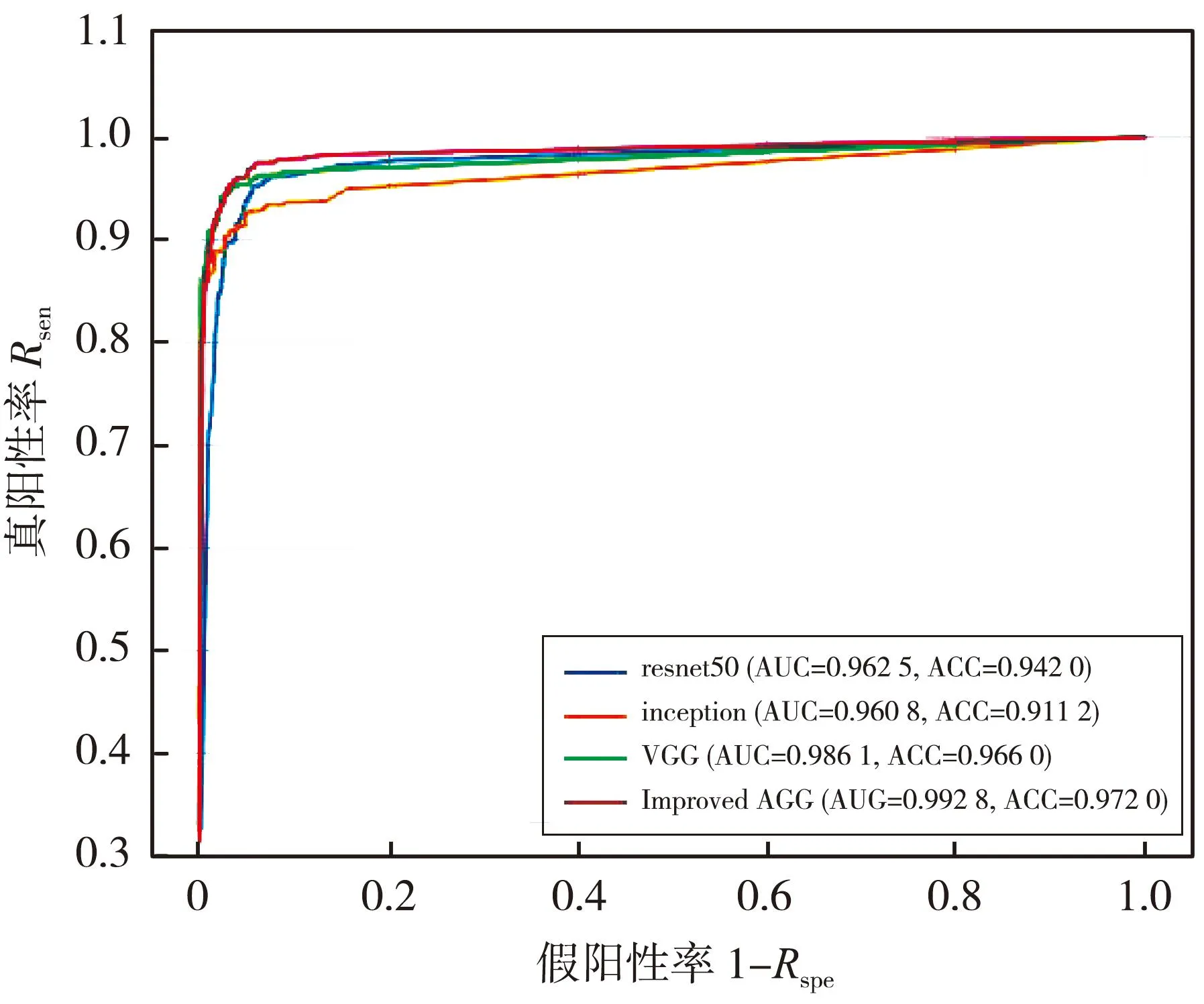
图9 4个网络模型的ROC曲线图
由图9 可以看出,本文提出的改进的VGG模型最靠近点(0,1),AUC值达到了0.992 8,是全部模型中最大的,这说明本文的改进VGG模型在高分辨率食管测压图谱的分类中性能更好。
3.5.2 改进VGG模型的图像识别性能
为了进一步说明本研究中的改进的VGG模型的优越性能,绘制了4类收缩活力分类的ROC曲线和混淆矩阵,如图10 所示。由图10(a) 可知,本文的改进VGG模型鉴别高分辨率食管测压图谱4类收缩活力的性能相差不大,其中,正常收缩的AUC值为0.995 6,全段增压的AUC值为0.994 2,无效收缩的AUC值为0.993 0,弱收缩的AUC值为0.992 2。为了更好地考察改进VGG模型对每个类别样本的预测标签与真实情况的差异,本研究对测试集上的混淆矩阵进行了可视化。由图10(b) 的混淆矩阵可以看出,实际标签为无效收缩的图片分类结果最好,其余图片分类的准确率也都超过90%。表2 所示的定量指标也显示了改进的VGG模型性能的优越性,除了正常分类的精准度略差外其余各项指标都达到了最优,并且分类的平均精度和平均特异度也较为优异,分别达到了97.20% 和98.05%。同时,除正常分类的精准度指标略差外,本文的改进VGG模型的其余所有各项指标都高于目前性能最好的Pos-ClasNet三分类模型。另外,本研究中各类样本的数量不相等,其中,全段增压仅为正常收缩的1/3,可能会影响改进VGG模型对特征的学习。但是,全段增压的图片分类效果比较好,说明全段增压特征明显,模型容易学习。相比之前的研究,本文模型能够多辨别一类图片,从而使临床诊断更准确。

表2 4类收缩活力分类的结果比较

(a) ROC曲线
综上所述,本文提出的改进VGG模型比传统的VGG模型以及其他常见的医学影像分类模型具有更为优异的性能。
3.5.3 VGG改进前后性能的消融实验比较
为了评估本文提出的网络的各个改进模块,对数据进行消融实验。实验中比较了传统的VGG模型、先加入Dropout的模型、再加入Batch Normalization的模型以及修改了卷积核的改进的VGG模型。修改卷积核后的VGG模型中第一模块的卷积核为3×3,第二模块的卷积核调为5×5,第三模块的卷积核调为7×7,第四模块的卷积核调为5×5。由表3 消融实验的结果可以看出:与传统的VGG模型相比,加入Dropout后模型的各项指标都有所提升; 再加入Batch Normalization后模型的准确率提升了1.85%,精度提升了0.89%,召回率提高了1.12%,F1-Score提高了1.25%,特异度提升了0.33%; 进一步修改卷积核后各项指标再次提升,其中,准确率提升了2.40%,精度提升了2.18%,召回率提高了1.18%,F1-Score提高了1.74%,特异度提升了0.35%。图11 直观展示了消融实验中前30个epoch验证集的精度,可以看出,改进的VGG模型精度曲线在其他三条曲线的上方,并且改进的模型未出现过拟合现象。以上结果表明,本文提出的方法具有良好的性能,模型识别图片的能力得到了提高。

表3 消融实验的结果比较
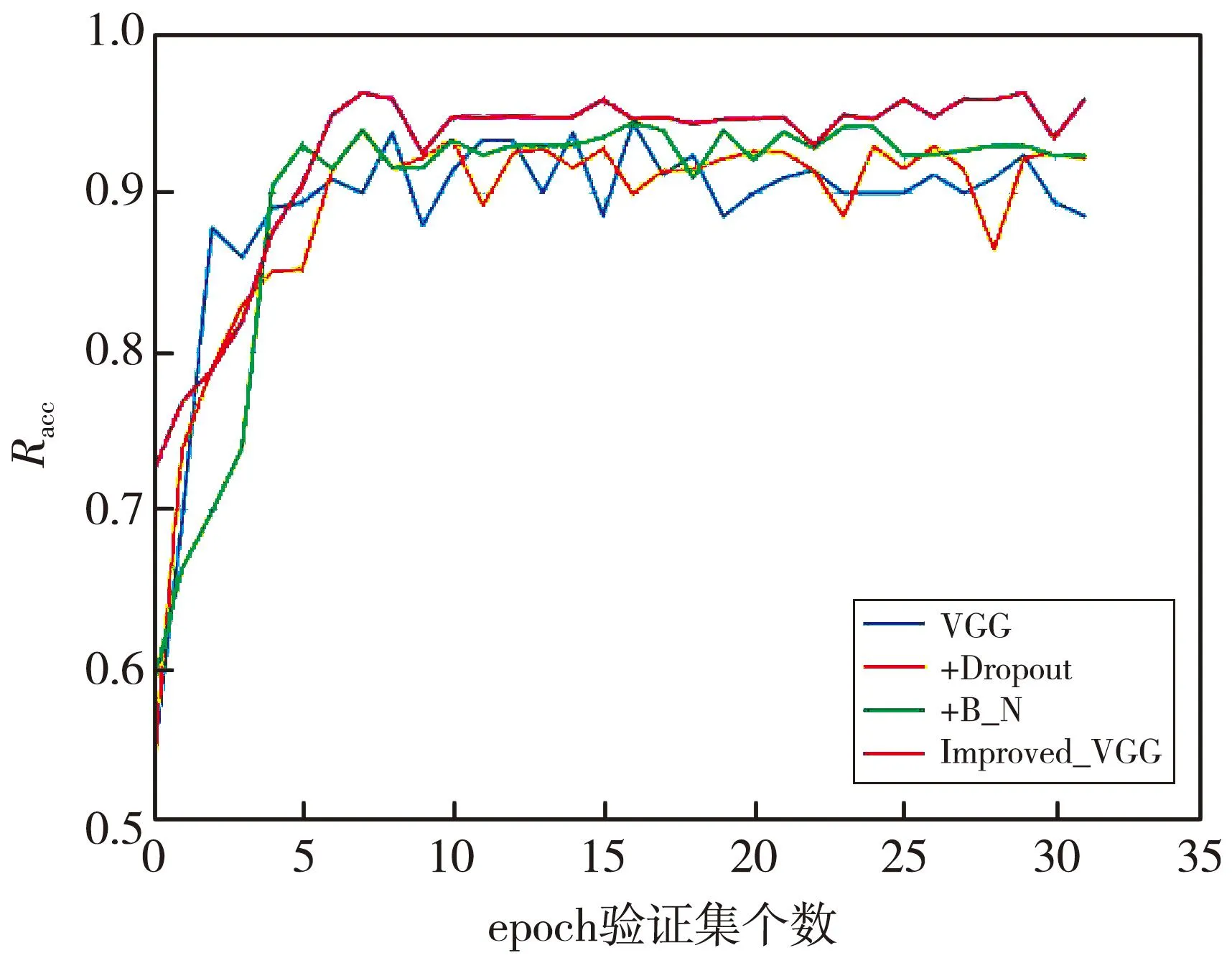
图11 消融实验中前30个epoch验证集的精度
4 结 论
本文在传统的高分辨率食管测压图谱鉴别方法的基础上,提出了改进的VGG网络模型,其中,添加了Batch Normalization层以及Dropout层,并增大了卷积核的大小,从而提升了高分辨率食管测压图谱分类的训练速度,避免出现过拟合现象。以改进的VGG网络为核心的NFWIC模型实现了正常收缩、全段增压、弱收缩、无效收缩的细化分类,在四分类问题中的准确率达到97.20%,且各项指标性能都是最优异的。受限于食管动力障碍性疾病的诊断复杂性与数据集样本数量的有限性,本文仅通过实现食管收缩活力的自动鉴别踏出了第一步,但距离完全实现人工智能诊断疾病还有漫长的道路。下一步将研究具有可解释性的食管动力障碍性疾病的智能诊断算法,进一步结合最新的芝加哥分类建立食管的完整收缩模式以及食管完整松弛压力的鉴别模型,最终形成一套完整的食管动力障碍辅助评估系统,实现食管动力障碍性疾病的快速精准的分类和高效诊断。
