基于信息熵的明密文识别算法*
2024-01-02石元兵张运理苏攀西
籍 帅,石元兵,明 爽,张运理,苏攀西
(中电科网络安全科技股份有限公司,四川 成都 610041)
0 引言
随着加密技术的广泛应用,加密数据呈现爆炸式增长,尤其随着加密技术的演进和推广,全加密时代悄然来临。加密技术在保护用户隐私的同时也深刻改变了网络安全的威胁形势。
明密文识别技术属于网络安全、商密监管等领域的细分方向,近几年逐步受到国内外相关企业的重视和关注。
加密的本质是使用加密算法对数据进行加密处理,生成一组无意义的数据,由此产生的数据是人们无法辨识和篡改的密文。针对明密文识别的研究,需要分析密文数据区别于明文数据的特征。从密码学角度看,经过加密得到的密文消除了统计特征,近似为随机数[1]。
目前明密文识别方法主要有两种:一种基于美国国家标准与技术研究所发布的随机性检测标准(National Institute of Standards and Technology,NIST),一种基于信息熵。
文献[2]基于NIST 随机性检测标准[3],统计了密文与明文的随机性特征值,得出密文文件与未被加密的文件在频率检验、块内频数检验、非重叠模板检验、游程检验、近似熵检验和离散傅里叶变换检验上的特征分布存在着明显区别,即从随机性分布出发,可有效识别与区分加密数据和非加密数据。但是随机性检测有16 项之多,效率差,准确率也只有90%,而且不能处理较短的数据。
基于信息熵的方法主要使用数据的信息熵作为特征,根据不同信息熵计算方法,可以将其分为基于连续若干字节的信息熵计算方法、基于滑动窗口的信息熵计算方法和基于采样的信息熵计算方法[4-5]。文献[6]提出了一种基于信息熵的加密判断算法应用于木马检测系统,但该算法最多只能识别1 500 个字节的数据。
本文提出一种基于信息熵的明密文识别算法,采用基于连续若干字节的信息熵计算方法和基于滑动窗口的信息熵计算方法,通过计算数据的信息熵,并和对应数据长度的置信区间进行比较,来判断数据是否加密。该方法可以识别任意长度的数据,并且具有很高的准确率。同时,该方法实用性强,可以运用在任何需要判断数据是否加密的领域。
本文内容分为相关技术、方案设计和实验结果3 个部分。
1 相关技术介绍
1.1 信息熵
信息熵[7]是信息论的基本概念,用于度量信息量,由信息论之父香农提出。信息熵的定义如下文所述。对于一个有m种可能的事件A1,A2,…,Am,并且这些事件发生的概率为p1,p2,…,pm,其信息熵计算公式为:
式中:K为一个正整数,一般情况下K=1。由于要事先知道每个事件发生的概率,才能计算信息熵,这是相当困难的,因此通常计算信息熵的估计来代替计算信息熵。文献[8-11]介绍了几种估计熵值的方法,但是这些方法需要大量的样本,而且计算复杂。本文采用Monte-Carlo 方法计算一致分布条件下的信息熵的估计值。
1.2 Monte-Carlo 方法
Monte-Carlo 方法也称统计模拟法,是把概率现象作为研究对象的数值模拟方法,是按抽样调查法求取统计值来推定未知量的计算方法,适用于对离散系统进行计算仿真试验。在计算仿真中,通过构造一个和系统性能相近似的概率模型,并在数字计算机上进行随机试验,可以模拟系统的随机特性。它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法。
一个简单的例子可以解释Monte-Canlo 方法。假设需要计算一个不规则图形的面积,首先把图形放到一个已知面积的方框内;其次假想有一些豆子,把豆子均匀地朝这个方框内撒,撒好后数这个图形之中有多少颗豆子;最后根据图形内外豆子的比例来计算面积。当豆子越小,撒的越多的时候,结果就越精确。
设数据流F的长度为N,随机产生10 万条样本,分别计算每个样本的熵值,然后取平均值,得到长度为N的信息熵的估计。
1.3 评价指标
基于机器学习的评价指标包括准确率、查准率、召回率、误报率、漏报率等。本文采用准确率作为评价指标。
准确率反映了分类器对整个样本的判定能力,即能将正的判定为正,负的判定为负。
假设原始样本中有两类,总共有P个正例,N个负例。经过分类后,有TP个属于该类的样本被系统判定为该类,FN个属于该类的样本未被系统判定为该类,FP个不属于该类的样本被系统误判定为该类,TN个不属于该类的样本被系统判定为不属于该类。准确率定义如下:
2 方案设计
加密数据具有机密性,经过加密的数据和完全随机的数据非常相似,也就是说,经过加密的数据比明文的数据表现出了更大的不确定性,即熵值更大。本文将一条数据当作一系列事件的集合,将数据的各个字节作为一个独立事件,由于每个字节有256 个可能的取值,而且经过加密的数据各个字节数值近似服从一致分布,因此当数据的长度足够长时,整个数据流的熵值会趋近于log2(256)=8。但是明文数据不具有随机性,也就是说,明文数据的熵值会小很多,这是因为由式(1)可知,每个事件的概率分布服从一致分布时,信息熵取最大值。
定义有N个字节的数据流F的字节熵为:
式中:m为字节所有可能的取值数,即m=256;fi是某一确定的字节取值在整条数据中出现的频率。式(3)计算的熵值就是熵的最大似然估计值。
2.1 截断熵的计算
要实现加密数据的识别,首先需要计算有一系列特定长度的加密数据的熵值作为算法的阈值。直接计算熵值是不现实的,因此本文不直接计算一条数据的真实熵,而是计算概率分布p=(pi)i∈∑的N-截断熵(N-truncated entropy)[12-13]HN(p)。HN(p) 被定义为所有长度为N的根据概率分布p产生的数据流F的简单熵的平均值。可以通过下式进行求和计算:
当p服从一致分布u时,可以得到服从一致分布的N-截断熵的计算公式为:
2.2 置信区间的确定
2.1 节虽然计算了HN(u)的值,但是当一个具体的文件数据的与HN(u)进行比较时,它们之间具体相差多少被认为是加密数据,因此还是未知。本节将确定这一置信区间。
2.3 算法描述
用Monte-Carlo 方法计算长度为16~1 000的随机数据流的N-截断熵HN(u)和标准差并将其与长度一一对应填入表里,这样就可以很轻易地计算出置信度为99.9%的置信区间对于一条待检测数据,若数据长度大于或等于16 字节,小于或等于1 000 字节,只需要计算待检测数据的并且将其与相应长度为N的置信区间比较,就可以在置信度99.9%的条件下判断该数据是否加密。若数据长度大于1 000 字节,则将数据长度除以1 000 得到商和余数。分别判断各个1 000 字节及余数字节是否加密,若某一段数据未加密,则整段数据判定为未加密;若所有段数据为已加密,则整段数据为已加密。之所以从长度16 开始才能判断,是因为上文的实验结果显示,只有在N≥16 的情况下,置信区间才有效,在实际情况中数据长度小于16 的情况很罕见。具体算法如下文所述。
(1)载入已经计算好的与长度对应的N-截断熵HN(u)和标准差
(2)输入要判断的数据文件名。
(3)判断待检测文件的长度是否大于或等于16字节,若是则转入步骤(4);反之,本算法无法判断。
(4)将数据按照每1 000 字节进行划分,则数据长度为1 000n+m(n≥0,0 ≤m<1 000)。分别对n+1 段数据计算并判断是否在其长度对应的置信区间内。若有一段数据不在置信区间内,则判断该数据未加密;若所有数据均在置信区间内,则判断数据已加密;若m<16,则该段不进行判断。
(5)输出判断结果。
3 算法测试
3.1 测试环境
本次测试在实验室现有环境下进行,总体环境设置如表1 所示。

表1 实验环境
3.2 测试方法
为了测试本文所述算法识别明密文的准确性,在实验中选择了不加密的数据(base64、zip 压缩、rar 压缩、hash)和加密的数据(AES、DES、sm2、sm4)。
测试算法见第2 节,此处不再赘述。本文所用的数据集源于实验室网络环境,测试数据组成情况如表2 所示。

表2 算法可行性检测结果
3.3 测试结果
测试结果如表3 所示。
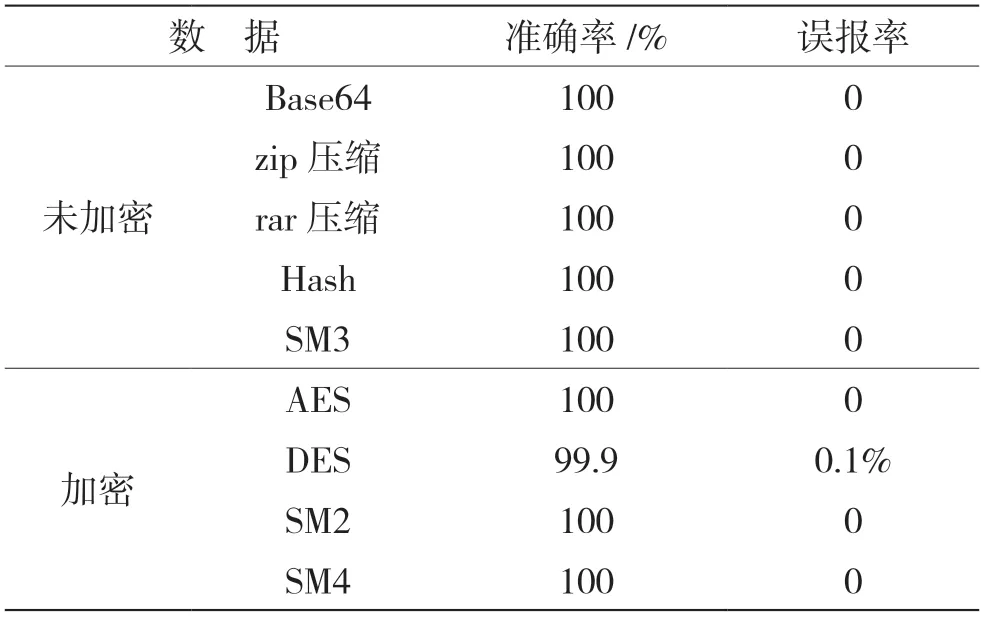
表3 算法可行性检测结果
通过上述实验可以看到,对于明文或经过编码的明文数据,该方法均能准确识别为明文;对于对称加密或非对称加密的密文数据,该方法识别率超过99%。总体来说,本文所提算法具有很高的准确率和时间效率,可以区分加密数据和未加密数据。
4 结语
本文介绍了一种基于信息熵的明密文识别算法。该算法只需要输入待检测数据的文件名即可判断文件数据是否加密。通过实验可知,该算法具有很高的准确率和很低的误报率,可以运用在任何需要明密文识别的场景中。
本文所提算法中,针对一条待检测数据是每1 000 个字节进行一次判断,所以数据越短效率越高。在将来的研究中,需要研究如何提高算力,每2 000 个字节或更多字节判断一次,从而提高大数据的时间效率。
