基于有效载荷和数据包长度的多模态加密流量分类*
2024-01-02丁要军
田 鑫,丁要军
(甘肃政法大学,甘肃 兰州 730070)
0 引言
流量分类研究领域的一个极为重要的方向是加密流量检测,这也是网络安全领域的基础要素之一。随着网络流量的急剧增长,安全监控系统面临着巨大的挑战。传统的深度包检测(Deep Packet Inspection,DPI)技术在准确识别未加密的网络流量方面表现优秀,但对于加密流量的识别却显得无能为力。
与传统的流量分类方法相比,机器学习算法具备多重优点。首先,它们能够有效处理加密流量的分类,并且在这方面表现出高度准确的性能。此外,机器学习算法还具备适应复杂多变的网络环境的能力,能够识别未知的样本类别,因此它们可以有效地应对不断升级的加密协议和新兴网络应用的分类需求[1]。基于机器学习的加密流量检测方法通过对加密流量原始数据的统计分析,构建统计属性组合作为指纹,从而实现对加密流量的分类识别。这种方法还可以灵活调整特征结构,但需要专业人员进行特征矩阵的分析和构建,因此对知识和经验的依赖较高。
深度学习在流量分类领域已经取得了显著的成果,例如Wang 等人将卷积神经网络(Convolutional Neural Networks,CNN)运用在未加密流量数据集上,准确率、召回率和F1 值均达到89%以上[2]。文献[3]中使用了长短期记忆网络(Long Short-Term Memory,LSTM)和2D-CNN 的组合模型,并在REDIDIS 数据集上进行了实验,平均准确率和F1 值分别达到了96.32%和95.74%。文献[4]使用了LSTM 和门控循环单元网络(Gated Recurrent Unit Networks,GRU)等模型组成的分类器进行流量分类,取得了95.82%的平均F1 值。Lin 等人[5]提出了一种基于预训练模型BERT 的加密流量表征模型,在大规模无标记流量中使用多层注意力来学习流量上下文关系和流量间传输关系,在多个公开数据集上都取得了优异的结果。Sun 等人[6]把Inception 与Vision Transformer 两个模型结合起来,在恶意加密流量数据集上进行了实验,平均召回率和平均F1值指标分别达到了99.42%和99.39%。
虽然深度学习在流量分类领域取得了显著进展,但在不断演进的网络流量环境中,目前的深度学习流量分类器仍存在一些限制。这些分类器通常采用端到端深度学习方法处理单一模态的流量数据,未能充分利用流量数据的多样特性,因此这种方式可能导致结果产生一定的偏差[7]。
自然语言处理领域的多模态方法在解决这个问题方面表现出良好的潜力。Zhang 等人[8]提出了一种基于原始流量的前784 字节和统计信息的多模态深度学习模型。文献[9]利用GRU 和堆叠自编码器(Stacked Auto-Encoder,SAE)提取长度序列和字节序列这两个模态特征,得到了良好的分类性能。
本文提出了一种基于多模态特征的混合神经网络,使用数据包长度序列和有效载荷作为两个模态特征,然后分成两条路径使用神经网络分析双模特征,最后将两个模型提取的高维特征进行融合,并输出最终的分类结果。通过在多个公开可用的加密流量数据集上进行训练和实验,验证了该模型具有更好的预测效果。
1 相关工作
本文使用了加密流量数据的有效载荷和数据包长度序列特征。这两种特征分别作为加密流量数据的数据包级模态特征和流级模态特征。
1.1 数据包级模态
加密网络流量通常以每一层的协议头部和其对应的有效载荷来表示。针对网络加密流的内容类型分析关注的是数据流实际传输的内容是什么类型,因此许多学者考虑利用加密后的有效载荷来进行分类识别。然而,确定从哪一层开始分析是一个重要的问题。在本文中,考虑到网络层相关字段信息容易导致分类器过拟合,所以本研究提取的有效载荷特征完全来自被加密的传输层数据内容,也就是说,只关注包含传输层数据的数据包。如图1 所示,在网络流量的封装过程中,用户应用数据即为有效载荷。
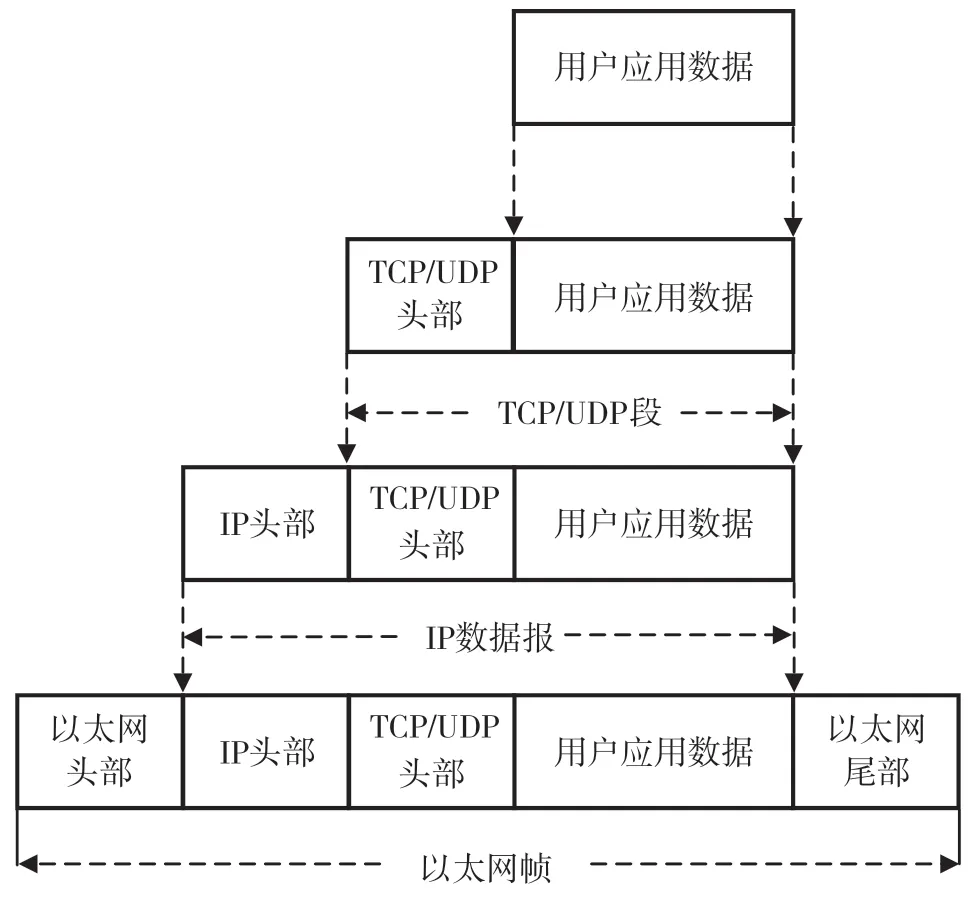
图1 应用数据封装过程
1.2 流级模态
尽管网络流量是加密的,但数据包的长度以及时间间隔等信息仍然可以从未加密的数据包头部获得。需要考虑到时间特征的重要性。时间特征指的是加密数据流在被捕获时所处的网络环境和条件,与当时的网络大环境密切相关,对于同一应用程序而言,不同时间捕获的数据流很难保证具有相同的环境,因此时间特征可能会存在较大的差异性。在本文实验中,应用程序的识别不考虑时间因素。
与时间特征不同的是数据包长度,它本质上反映了数据包承载的传输层数据及其头部信息的大小。因此,数据包长度反映了数据包本身携带的信息量,不同应用程序之间往往具有较大的长度差异,而同一应用程序下的数据包长度通常具有较高的相似性。例如,视频流的数据包通常较大,而网页流的数据包通常较小。因此,数据包长度序列可以被看作是另一个模态进行的加密流量分类任务。
2 基于多模态的加密流量分类
2.1 融合inception 模块的1D-CNN
目前,流量分类领域的大部分研究采用将流量数据直接转换成二维图像的方法,然后利用二维卷积神经网络的图像分类能力进行流量分类。然而,需要考虑的是,网络流量本质上是一种时序数据,它按照层次化结构组织,形成一维字节流,从低层次到高层次包括字节、帧、会话、整个流量。这种结构与自然语言处理中的字母、词语、句子、段落等结构非常相似。
Wang 等人[2]的研究也证实了一维卷积神经网络更适合处理网络流量这样的序列数据,因此本文决定应用一维卷积神经网络来处理有效载荷特征。
在传统的GoogLeNet 网络中,其独特的Inception结构与传统方法不同,它不仅通过增加网络深度和卷积层数量来提高性能[10],而且这一结构通过多尺度卷积核来提取图像的不同尺度特征,从而为图像分类任务提供更广泛的信息视野。因此,本文将Inception 结构引入模型,并对原有的Inception 结构进行了改进。这些改进包括使用一维卷积替代二维卷积,并在保持特征不变性的前提下引入池化层以去除部分冗余信息[11],以防止过拟合。图2 展示了改进后的Inception 结构。
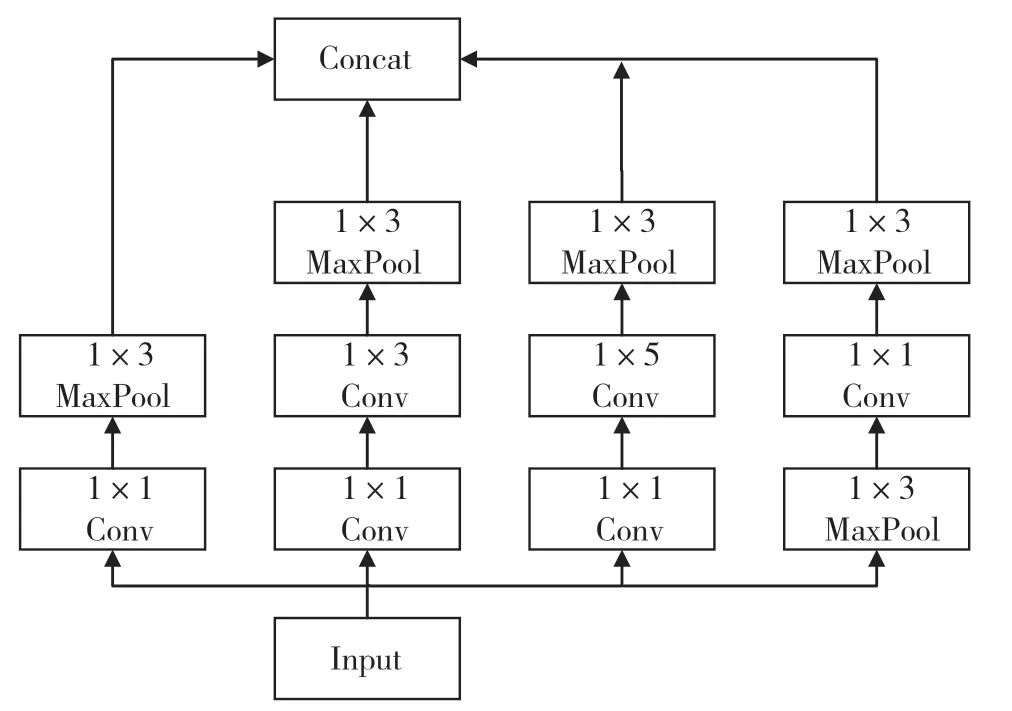
图2 一维Inception 结构
2.2 BiLSTM 特征提取模块
数据包长度序列特征是指一系列网络数据包的长度值,这些值通常被视为时间序列数据,因为它们可以按照时间顺序排列。因此,本文决定使用LSTM 模型来处理数据包长度序列模态特征。
LSTM模型是一种特殊的循环神经网络(Recurrent Neural Network,RNN),它通过引入“门控机制”对传送过来的信息进行筛选,这在一定程度上缓解了传统RNN 非常容易出现的梯度消失和梯度爆炸问题。LSTM 模型内部结构如图3 所示。
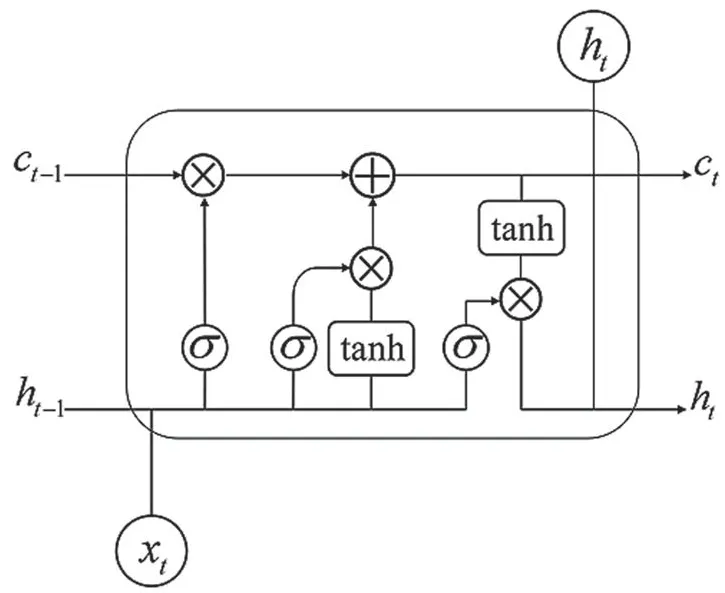
图3 LSTM 结构
可以看出,LSTM 模型主要由3 个不同的“门”和1 个“记忆细胞”构成。3 个不同的“门”指“遗忘门”“输入门”和“输出门”。
“遗忘门”决定了什么信息应该被删除,不能够继续传送下去,其表达式为:
式中:ht-1为上一时刻隐藏层传入的信息,xi为当前时刻输入的信息。
“输入门”决定了什么信息应当留下继续传递给“记忆细胞”,其计算式为:
经过“输入门”的筛选,此时“记忆细胞”会进行更新,其计算式为:
式中:Ct-1为上一时刻的记忆细胞所存储的信息。
“输出门”决定了什么信息应当保留并被输出,其计算式为:
当前时刻隐藏状态的信息需要输出传送给下一时刻的LSTM 单元,由ot和记忆细胞共同决定,该过程可表示为:
LSTM 模型通过设计能够对信息进行选择性的“记忆”与“更新”,但其在当前时刻只考虑到了上文信息,并没有考虑到下文信息。Bi-LSTM 模型[12]通过将一个前向的LSTM 模型和一个后向的LSTM模型进行叠加,实现了上下文信息的同时获取,从而提高模型的预测精度。Bi-LSTM 模型结构如图4所示。
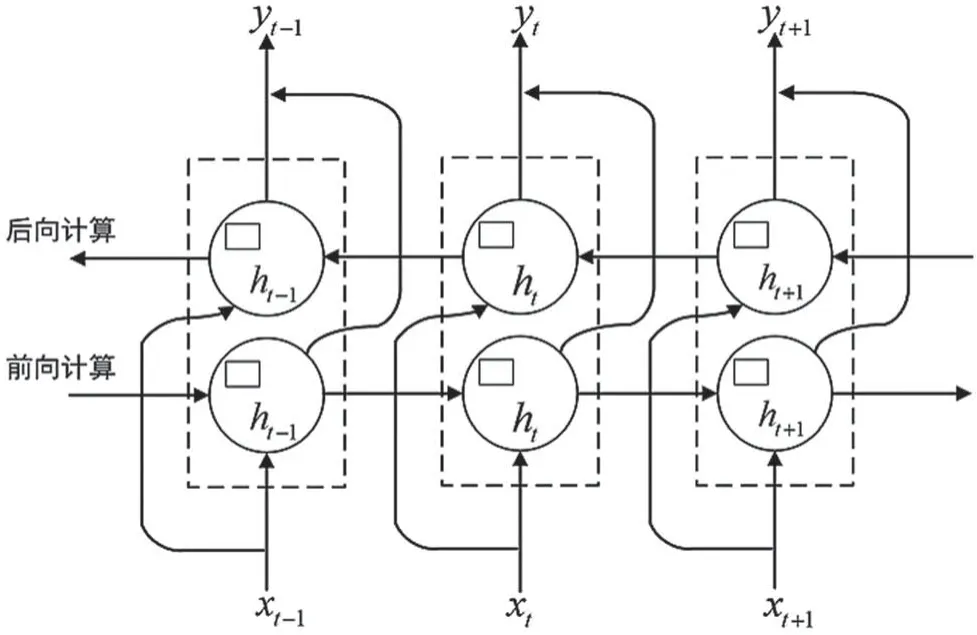
图4 Bi-LSTM 结构
2.3 模型架构
本文模型架构如图5 所示,其使用了两种模态的混合神经网络的方式实现加密流量分类。

图5 模型架构
首先,对原始流量数据进行预处理,预处理过程包括会话切分、数据清洗、统一大小等步骤,通过预处理将数据转换成模型所需要的格式。其次,模型使用两条路径分别处理不同模态的流量。路径I 为传输层有效载荷模态特征提取,由两个改进的Inception 模块组成。每个Inception 模块后均连接一个1D 池化层,其步长和大小均为3。然后是全连接层。路径Ⅱ为包长度序列模态特征提取,由一个BiLSTM 神经网络和一个全连接层组成。在路径I 和Ⅱ后通过特征融合层将两个分支的中间特征进行拼接,例如,两个中间特征x和y的维数若为p和q,则输出特征z的维数为p+q。最后,在softmax 分类之前连接一个全连接层,从而得到输出结果。
3 实验结果及分析
3.1 数据集
本文使用ISCX-VPN[13]和ISCX-nonTor[14]这两个数据集。两个数据集的详细信息见表1 和表2。
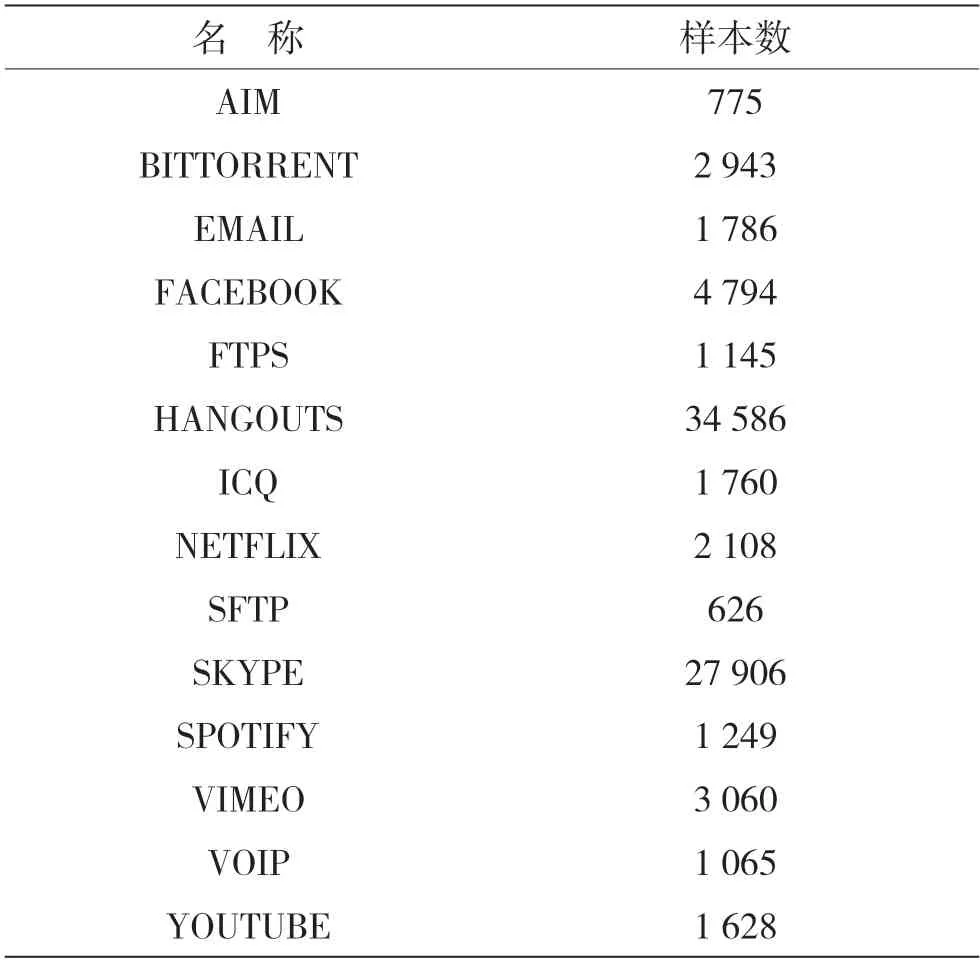
表1 ISCX-VPN 数据集
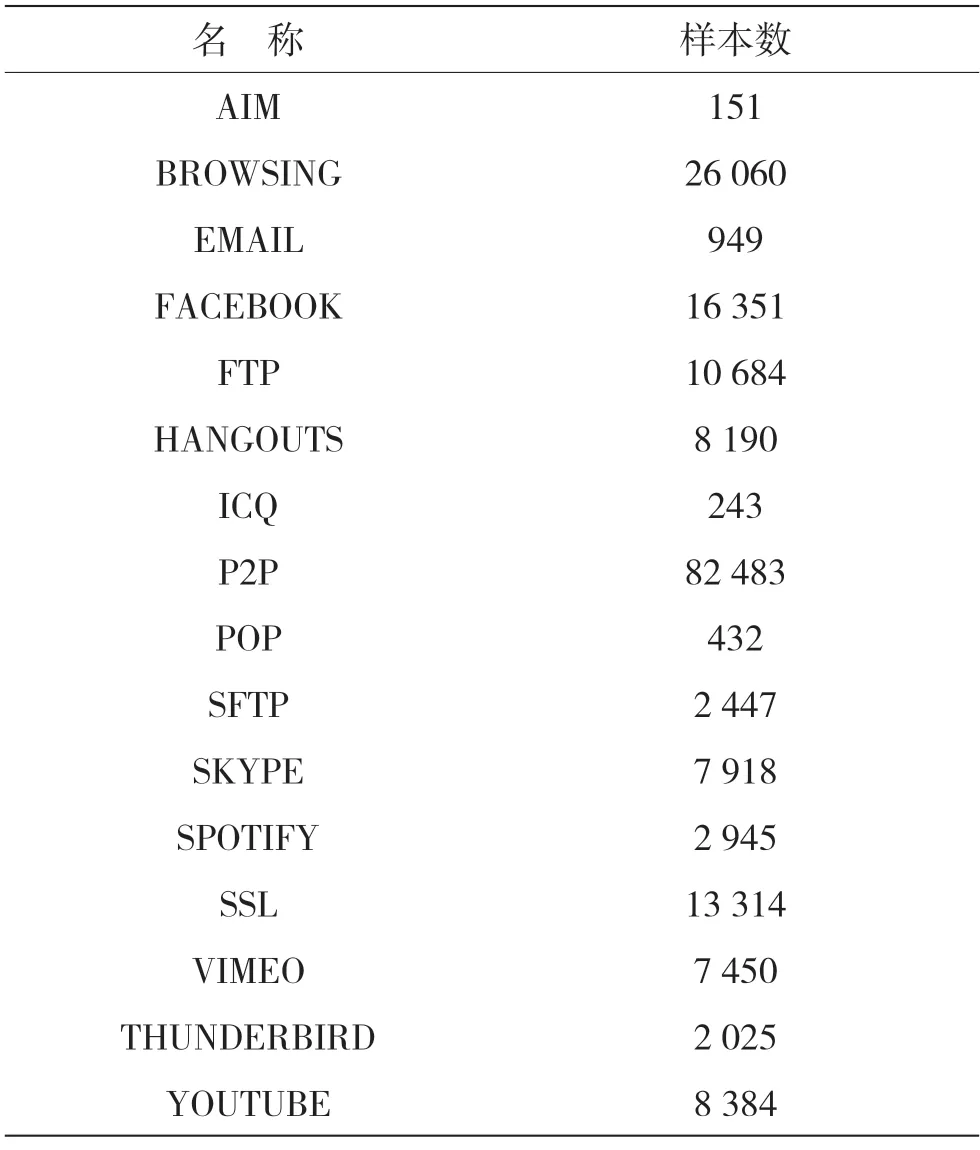
表2 SCX-nonTor 数据集
3.2 评价指标
由于本文主要对加密流量进行多分类检测,为了更好地衡量模型对加密流量的检测效果,主要选取精确率(Precision)、召回率(Recall)、F1 值(F1-Score)作为评价指标,具体计算公式为:
式中:TP为被模型预测为正类的正样本的数量;FP为被模型预测为正类的负样本的数量;FN为被模型预测为负类的正样本的数量。
3.3 实验环境
实验平台使用的软件框架是Pytorch 1.7.1,运行在Windows11 系统环境下,16 GB 内存,GPU 为NVIDIA GeForce RTX 3060。
3.4 数据预处理
网络流量的切分方式可分为5 种[15]。本文对原始PCAP 文件以会话的方式进行切分,相较于其他切分方式,会话能够保存通信双方之间的交互流量,携带更多的信息。数据预处理的具体步骤如下:
(1)会话切分。使用SplitCap 将原始PCAP 文件以会话方式切分成小单元。
(2)数据清洗。首先去除重复和空白的无效数据包,将切分后每条会话流中的脏数据,包括地址解析协议(Address Resolution Protocol,ARP)数据包、域名系统(Domain Name System,DNS)数据包、重传数据包等清除,以减少其对检测效果的影响。
(3)统一大小。因为不同会话的持续时间不同,不同协议的包头不同,导致相同应用的会话中,数据包的个数都不同,并且不同数据包中包含的字节多少也截然不同。但是在模型识别时,需要统一长度的数据作为输入,因此需要对数据包个数和每个数据包的有效载荷字节数进行截取。
3.5 实验参数确定
3.5.1 数据包级模态参数确定
通过实验可以发现,ISCX-nonTor 数据集中的数据包长度和数据包数目变化很大,实验结果如图6、图7 所示。而使用卷积神经网络模型则需要使用固定大小的输入,因此需要选取固定的数据包数目和长度。在文献[7]和文献[16]的经验基础上,使用全部的有效载荷长度和数据包会增大算法所需的空间和时间复杂度。此外,文献[17]研究发现,一个会话流量的主要特征大部分存留在靠前字节中,后面字节包含的信息对识别准确率的提升贡献较小。因此本研究选取前4 个数据包,选择每个数据包有效载荷的前256 字节,对于有效载荷小于256 字节的数据包在末尾处做补零操作。
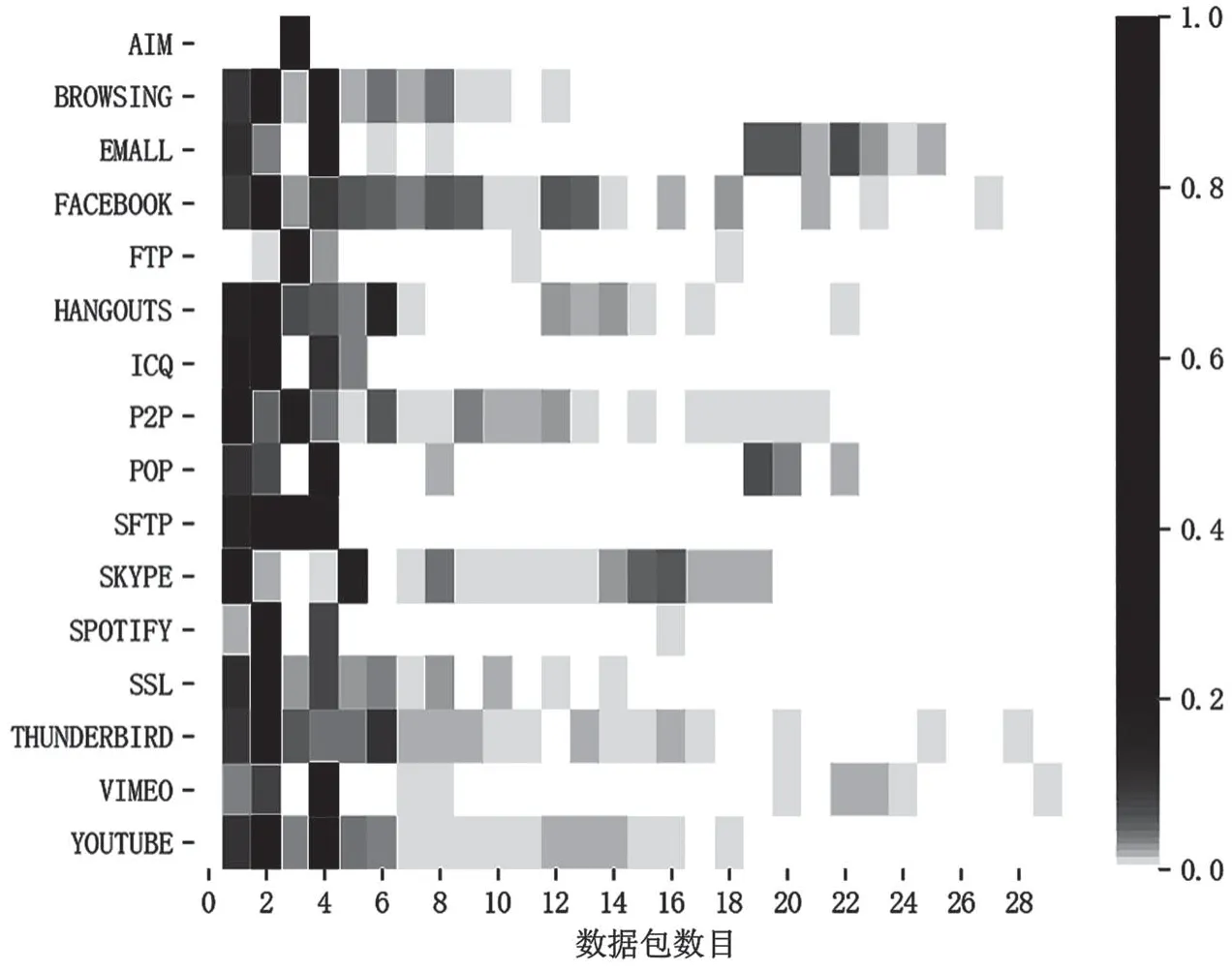
图6 数据包数目统计
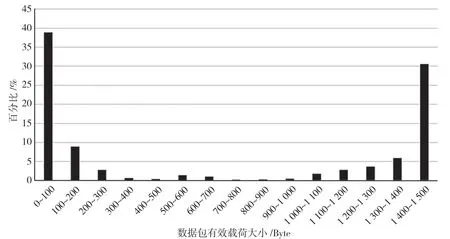
图7 有效载荷大小概率密度分布
3.5.2 流级模态参数确定
分别选取前8,16,24,32,40,48,56,64,72,80,88,96,104 个数据包,然后使用Bi-LSTM网络进行对比实验,实验结果如图8 所示。从实验结果可以得出,当取前64 个包的长度序列时,F1值收敛,考虑到时间开销问题,选取每个会话的前64 个数据包的包长序列作为第2 个模态。
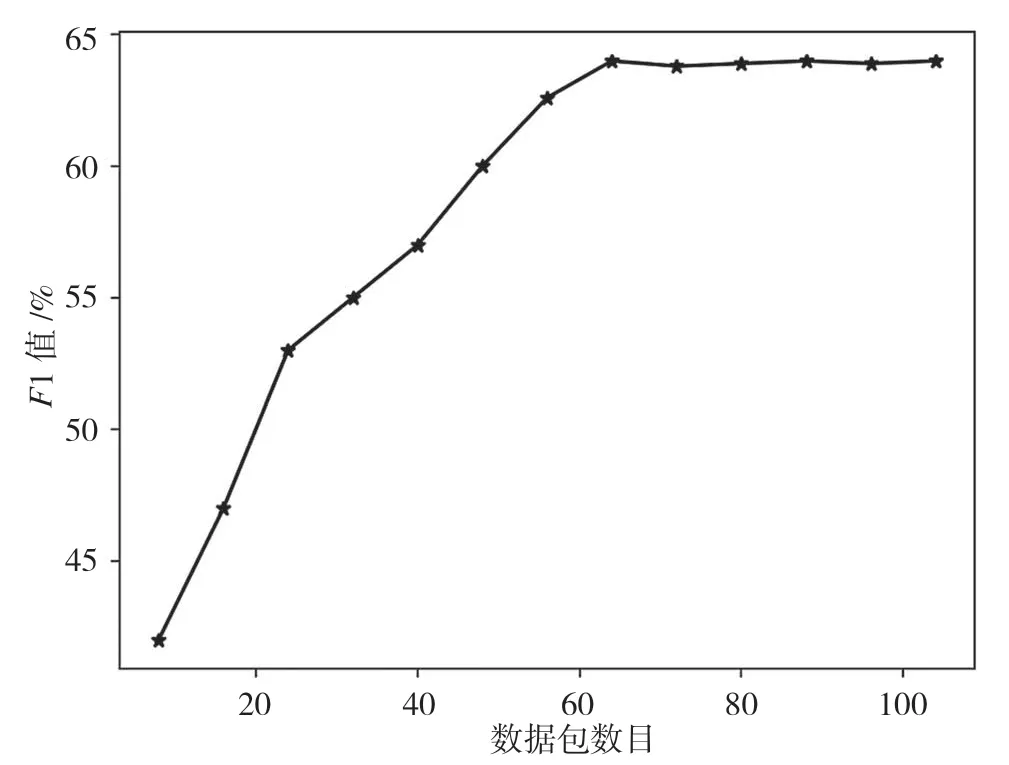
图8 流级模态包数目确定
3.6 消融实验
为了深入了解本文提出的模型如何影响任务性能,本文在ISCX-noTor 数据集上进行了3 组实验,实验结果如图9 所示。
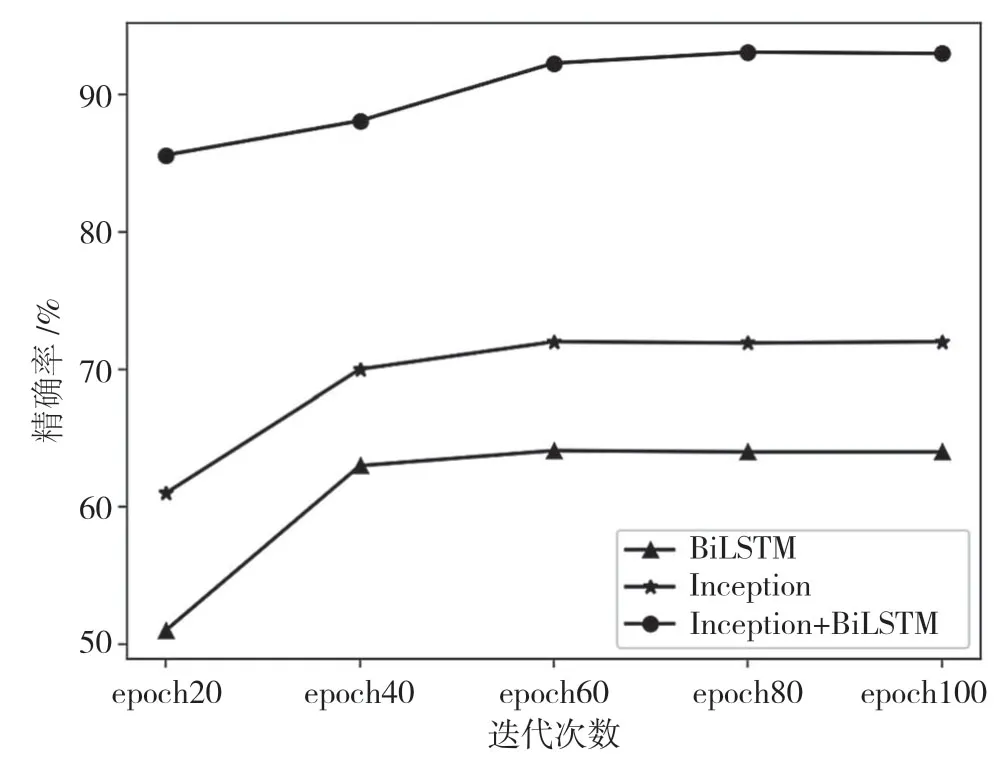
图9 单模态和多模态融合精确率对比
从图9 中可以看出,使用改进Inception 模型对有效载荷模态进行训练时,实验的精确率达到72%;使用BiLSTM 模型对包长度序列模态进行训练时,实验的精确率达到64%;而使用两种模态进行训练时,实验的精确率达到了93%。可以证明,使用多模态方法的结果优于使用单模态方法的结果。
3.7 对比实验
为了充分验证本文提出的方法的有效性和效率,将基线简单地分为两种。首先,将本文的模型与3 种单一模态流量分类方法进行比较,其中,一种是广泛使用的方法——CNN,另外两种是名为DeepPacket[7]和FlowPic[18]的方法。其次,本文还使用了DM-HNN[9]作为基线之一,它也使用了多模态架构进行加密流量分类任务。
表3 和表4 列出了3 个单模态的流量分类器和一个最近提出的双模态分类器在ISCX-VPN 数据集和ISCX-noTor 数据集的精确率、召回率和F1 值。
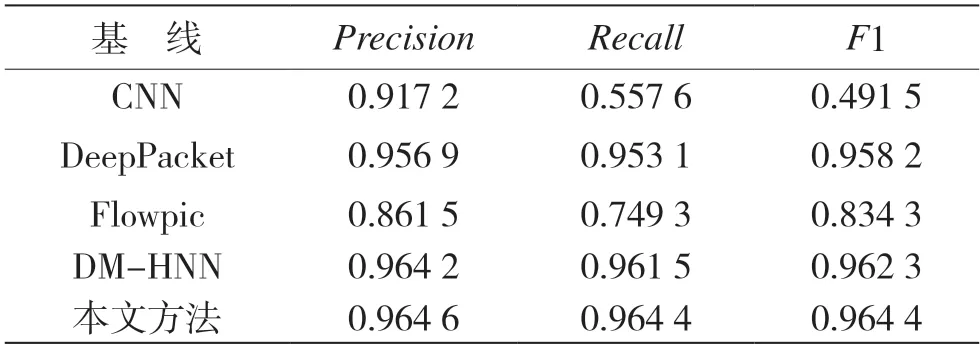
表3 ISCX-VPN 数据集在不同基线下的分类结果
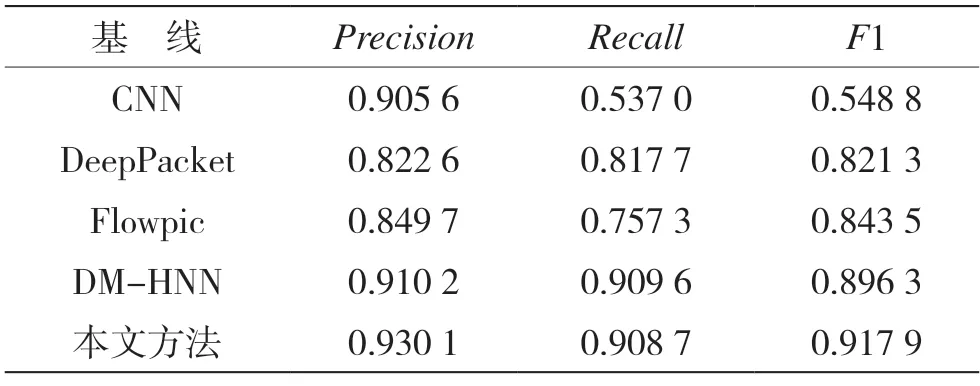
表4 ISCX-noTor 数据集在不同基线下的分类结果
在ISCX-VPN 上,本文提出的方法的精确率、召回率和F1 值均高于其他方法,具体为:与DeepPacket相比,分别提高了0.77%、1.13%、0.62%;与Flowpic相比,分别提高了10.31%、21.51%、13.01%;与DM-HNN 相比,分别提高了0.04%、0.29%、0.21%。在ISCX-noTor 上,本文提出的方法的精确率、召回率和F1 值均高于其他单模态方法,具体为:与DeepPacket 相比,分别提高了10.75%、9.1%、9.66%;与Flowpic 相比,分别提高了8.04%、15.14%、7.44%;与DM-HNN 相比,精确率提高了1.99%,F1 值提高了2.16%。
上述对实验结果的分析验证了本文提出的基于有效载荷和数据包长度的多模态加密流量分类方法的可行性。
4 结语
本文提出了一种基于多模态特征的加密流量分类方法,使用有效载荷和数据包长度序列作为两个模态特征,然后分成两条路径使用神经网络分析双模态特征,最后将两个模型提取的高维特征进行融合,并输出最终的分类结果。为了评估模型的有效性,本文在两个公开数据集上进行了模型训练,同时,与现有的加密流量检测模型进行了对比,实验结果表明,本文提出的方法相比于传统的使用单模态的方法,对加密流量具有更好的检测能力。
