基于文本语音混合模式的家庭生活垃圾分类的研究
2024-01-02王维虎刘嘉成
王维虎,刘嘉成
(湖北工程学院 计算机与信息科学学院,湖北 孝感 432000)
随着居民生活条件的不断改善,我国居民所产生的生活垃圾数量也持续增长,在不少地区居民生活垃圾处理已经成为了一个难题。社区作为人们日常居住生活的聚集性区域,是生活垃圾产出的主要场所,也是进行生活垃圾分类的前端源头[1]。垃圾分类投放也越来越成为人们生活中的一部分,实行垃圾分类也越来越受人们的关注[2]。
垃圾分类和处理设施是城市环境基础设施的不可或缺的一部分,为推动生活垃圾分类制度的实施,实现垃圾减量化、资源化和无害化处理提供了必要的基础支持,同时也是促进生态文明建设的重要支持。《“十三五”发展规划纲要》(2016—2020年)中明确要求:“健全再生资源回收利用网络,加强生活垃圾分类回收与再生资源回收的衔接”[3]。南京市十六届人大常委会更是首次审议《南京市生活垃圾管理条例(草案)》,将生活垃圾管理条例纳入立法程序[4]。
针对上述存在的问题,本文提出了一种决策树模型,能够客观、快速地对居民对垃圾分类了解情况进行分析和评判。首先,本文以居民调查问卷方式为基础,获得被测居民垃圾分类语料数据,邀请环保专家,对获取到的垃圾分类语料数据进行去噪与清洗,得到高质量垃圾分类语料库;其次,从垃圾分类语料库和专家背景知识分析,进一步选取有效的垃圾分类识别特征并优化处理;最后,构建基于Python的决策树算法构建决策树模型,进行文本识别和语音识别。通过该模型实现对居民对垃圾分类了解的情况快速地分析判断,做到对居民们的及时分析和判断,给出是否存在欠缺垃圾分类观念问题。
1 文本语音混合模式研究框架
1.1 本文总体框架
根据研究目标和内容,基于文本语音混合模式的家庭生活垃圾分类框架图,如图1所示。该框架主要包括构建垃圾分类模型和垃圾分类测试两个过程。在构建模型阶段,分为3个步骤:1) 根据结合专家指导,制定居民垃圾分类情况健康问卷调查表,通过微信、QQ、电子邮件Email、小区内纸质调查表、垃圾分类测试系统等不同方式邀请居民们进行填写,收集居民垃圾分类调查问卷数据,同时邀请环保专家对问卷数据进行人工分析和标记语料是否健康、分类、量化、去噪与清洗数据,构建得到高质量垃圾分类语料库,将语料库分为训练数据与测试数据两个部分;2) 根据环保专家和环境学专业知识结合,获得的高质量垃圾分类语料库,选取居民垃圾分类的数据的有效特征并优化;3) 在已构建的训练语料库和选取有效特征的基础上,采用决策树算法进行构建居民垃圾分类情况分析模型,得到基于决策树算法的居民垃圾分类分析模型。在垃圾分类测试阶段,将测试语料输入到已构建的居民垃圾分类分析模型中,得到垃圾分类预测结果。

图1 居民垃圾分类情况分析框架图

图2 决策树算法垃圾分类分析模型图
2 构建居民垃圾分类情况分析模型
本文构建居民垃圾分类情况分析模型,主要包括居民垃圾分类语料库的构建、特征选取、模型构建三个基本过程,下面详细介绍。
2.1 构建语料库
语料库质量的好坏对后续的分析与模型构建至关重要。本文结合环保专家指导,制定居民垃圾分类情况问卷调查表,通过网络(微信、QQ、电子邮件Email和垃圾分类测试系统)或纸质(纸质调查表)等不同方式邀请居民(湖北某些小区)进行填写,邀请环保专家对调查问卷数据进行分类、量化和人工标记语料判断是否健康,形成规模为8400条语料库;采用Python相关工具包对语料库进行去噪声和清洗处理,对数据标准化处理,得到高质量垃圾分类语料库,并将该语料库进行划分为训练语料和测试语料,数据以Excel、utf-8编码格式进行存储。随着深度学习的发展和人工智能技术的不断进步,由此催生了一系列针对语音识别技术的研究与开发[5]。
2.2 垃圾特征选取
特征选取的质量直接决定机器学习模型性能的好坏。本文根据垃圾分类分析专家指导、常用重要评判的特征以及结合高质量垃圾分类语料库选取有效特征,选取了居民垃圾分类分析的4个垃圾分类特征维度,分别是可回收垃圾(A)、厨余垃圾(B)、有害垃圾(C)、其他垃圾(D),并且这些特征维度之间相互独立,在特征贡献度实验中,已经验证4个特征维度线性非相关。
根据垃圾分类专家经验和居民对垃圾分类了解维度,将每一个特征维度的取值分别进行等级量化处理,分别转化为明确了解、较了解、有点印象和完全不了解四个不同等级,如表1所示。

表1 居民垃圾分类了解情况的等级量化
2.3 构建决策树模型
2.3.1 决策树 ID3 算法
已有的数据集以 7:3 或 8:2 比例进行划分成测试集和训练集,测试集用于测试模型的准确率,训练集是用于模型训练。首先,计算出训练数据集的信息增益(或基尼指数) 最大的特征来建立决策树的当前节点,不断递归计算,建立垃圾分类的决策树模型;然 后,将测试集数据用以模型测试,得出准确率,再根据准确率进行决策树的“剪枝”,最 后得到最合适的垃圾分类决策树的模型。
对于一个给定的数据集,具体计算方法如下:
设训练集为D, D的样本个数为N ,D的数据有m个分类,分别为C1,C2,C3…,Cm,分类Cm的数据个数为|Cm|,那么D的信息熵为,如公式(1)所示。
(1)
设任一个特征的n个不同取值,记为Dn。根据特征的n个取值将D划分的n个子集为D1,D2,D3…,Dn。对于任意的子集Di∈{a1,a2,a3,…,an},设Di的样本个数为Ni,Di中属于类Ci∈{C1,C2,C3,…,Cm}的样本个数为|Ci|,那么特征 A对数据集的条件熵为,如公式(2)所示。
(2)
那么,特征 A 对数据集 D 的信息增益,如公式(3)所示。
G(D,A)=H(D)-H(D|A)
(3)
2.3.2 决策树模型
决策树是基于树状结构来进行决策的,一般地,一棵决策树包含一个根节点、若干个内部节点和若干个叶节点。
2.3.3 基于Python的语音识别成文本的方法
在使用Python进行语音识别时,一些部分通过使用第三方库来实现,因此开发人员很容易就可以得到不错的效果。主要过程有库函数的使用、显著特征值的收集、模型的构建,最后来实现文本语音混合模式。
1)显著特征值的收集。本文应用MFCC为语音的显著特征值的指标。最先要收取多人读同一内容文件的语音来进行语音采样,这些实验的结果形成文本语音混合的测试集和训练集,并存放为wav文件。原有的手段取得的MFCC属性是相对繁琐复杂,在Python中用于第三方库函数能够更为易于的获取到MFCC变化。该变量的值会将从交互入中得的MFCC原理以离散高、低,数值的正负数的数组的模式存放在文件系统中。
2)语音深度学习(DDN)模型建立。深度学习使用多层隐层节点,较浅层学习拥有更多的优势,深度学习成为研究机器学习的热点问题[6]。将得到的MFCC作为特征向量进行训练,进而得到训练文件。在神经网络的输入层,数据被传递,而在卷积层中,利用卷积核进行特征提取和特征映射。在激励层中,考虑到卷积操作本身是一种线性运算,于是需要引入非线性映射,也就是激活函数,以增加网络的表达能力。接着,在池化层进行下采样,以对特征图进行稀疏化处理,减少数据的计算量。Flatten操作的目的是将原始的二维特征图张量转化为一维向量的形式,以便将其传递给随后的全连接层进行处理[7]。最后,在CNN的尾部的全连接层进行重新调整,以最小化特征信息的损失。
3)语音识别。首先,对于获得的MFCC特征和神经网络模型,在语音识别领域,MFCC是最为广泛采用的声学特征之一,其基础是建立在人耳听觉生理学原理的基础上,即人耳对不同频率声波的听觉灵敏度存在差异。为应对掩蔽效应这一现象,我们采用了一系列带通滤波器,按照频率的临界带宽从低频到高频有序排列,用以对输入信号进行滤波处理。因此相较于基于声道模型的LPCC特征,具备更强的稳健性。最终,这些特征被用于进行语音比对和识别任务。
3 实验过程及分析
本文实验所用实验数据主要来自于垃圾分类语料,将其分为训练语料和测试语料。目前,由于居民垃圾分类结合机器学习方法研究资源匮乏,所以这里需要构建语料库。垃圾分类语料库是经过人工处理得到,包含5600条不同的垃圾数据;制定居民垃圾分类问卷调查表,通过网络或纸质等不同方式邀请居民(湖北某些小区)进行采集,邀请环保专家对调查问卷数据进行分类、量化和人工标记语料判断是否健康,所有字段保存为“UTF-8”格式;实验采用Python语言与机器学习库sklearn工具包。
为了综合方面衡量本文构建的分析模型,实验主要从三个方面进行评估模型性能:1) 特征贡献度实验;2) 语音识别结果评估实验;3) 开放与封闭测试实验。
3.1 特征贡献度实验
为了考察本文选取的4个特征维度——可回收垃圾(A)、厨余垃圾(B)、有害垃圾(C)、其他垃圾(D),对本文构建模型的贡献度,分别将4种特征单独融入分析模型中,并分别比较文本识别、语音识别和文本语音混合识别三种方法的正确率。实验结果如表2所示。

表2 特征贡献度实验
在表2中,第3组实验使用“文本语音混合识别”等级,本模型的预测正确率最高,正确率达到99%;其次是文本识别,正确率达到96%,语音识别相比其他两组实验较低,现语音识别只能识别出普通话,方言识别不出,故正确率达到83%。其他重要的等级分别是文本识别、语音识别,其他主要等级特征之间相互独立,呈非线性关系。
3.2 语音识别结果评估实验
语音识别的识别率大多采用词错误率和句错误率进行评估。本文采用词错误率进行评估,公式如下:
WER=100%×Insertions+Substitutions+
DeletionsT
(4)
式中:Insertions:插入错误,Substitutions:替换错误,DeletionsT:识别语音中的总词数。
根据图3中标识的错误类型,可以计算出WER=0.2+0.2+71×100%=71.4%。

图3 错误统计
由于在该方法中插入的词汇也算入错误率中,所以WER的值可能大于1[8]。
图3为错误率统计示例。
3.3 开放与封闭实验
为了评估本文构建模型的鲁棒性,本实验对已构建的基于决策树算法的居民垃圾分类分析模型进行开放与封闭测试。实验结果如图4和图5所示。在图5中,封闭测试实验正确率达到84.136%,开放测试实验的正确率为82.107%,开放测试比封闭测试仅低2.029%,因此本文构建的模型鲁棒性强。
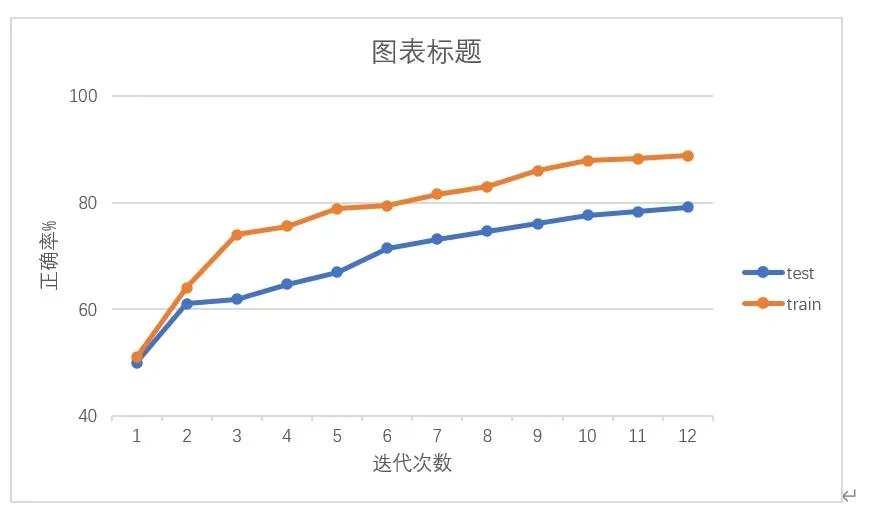
图4 迭代次数与正确率
4 结束语
传统垃圾分类采用人工分析,整套分析流程复杂、受心理专家主观意识影响、工作耗时耗力等问题,这无疑增加管理者等各层的工作负担。本文针对该问题提出基于文本语音混合模式的家庭生活垃圾分类,根据调查问卷结果进行自动化判断居民对垃圾分类的了解,有利于居民们对垃圾分类知识的理解,且有语音识别、文字识别混合识别功能,实验证明该方法有效可行。下一步研究中,本文将进一步扩展语料库规模,针对不同社区进行细化构建分析模型。
