基于语义分割的视频鱼类特征提取方法研究
2024-01-01李潇洋陈健常剑波







摘要:从视频图像中快速、准确提取水生生物(如鱼类)的特征信息,是信息科学与水生态研究结合的热点。基于Transformer的视觉模型,采用一种基于弱监督语义分割的视频鱼类特征提取方法,在无需预训练或微调的条件下,可以实现对鱼的身体、头部和鱼鳍3类形态区域标签的分割提取。采用DeepFish分割数据集构建计算机视觉自注意力模型(vision transformer,ViT),通过对水下拍摄的鱼类视频进行实验,结果实现了鱼体形态主体特征的有效提取,对拟定的3类形态标签区域进行了良好的分割标记。研究方法具有较高的效率、分割准确度和标记区域的连续平滑性,可提供良好的语义特征,为人工智能技术在鱼类等水生生物监测实践中提供了一种低成本、高效率的新方法。
关键词:弱监督学习;语义分割;视觉自注意力模型;鱼类特征提取
中图分类号:S931.1" " " " 文献标志码:A" " " " 文章编号:1674-3075(2024)05-0204-09
人工智能技术,如深度学习、计算视觉自注意力模型等,在水生态视频图像监测中展现出了强大潜力。相较于依靠延绳钓探捕、拖网探捕等捕捞技术的传统方法,利用水下拍摄的鱼类视频并辅以深度学习方法提取鱼类特征可以节省探测的时间与成本,同时这种非接触测量方式不会使鱼类产生应激反应,能够更真实地反映鱼类在环境中的活动状态。随着深度学习技术的发展和神经网络模型的深化,视频水生生物特征获取的准确性和效率得到了显著提高(Yang et al,2021)。在鱼类表型分割方面,Dong等(2023)基于关键点检测技术提取了鱼体轮廓形状,并分析了鱼类形态特征,但关键点的标记存在一定主观性,限制了模型成果的泛化能力。Zhang等(2021)应用Fish 4 Knowledge(F4K)数据集进行训练,提出了一种深度学习方法,可以对鱼类进行识别和分类。李健源等(2024)基于改进的DeepSORT算法,采用YOLOv5模型作为目标检测模型,对监测视频中目标鱼实现了动态识别和自动计数。此外,如卷积神经网络(CNNs)等深度学习模型,也可以高精度地识别和分类图像数据,如鱼类物种、藻类繁殖等,但也存在训练深度学习模型需要大量数据,可解释度弱等不足。
计算机视觉自注意力模型(vision transformer,ViT)是一种基于Transformer的视觉模型,与传统的深度学习模型(如CNN)相比,ViT使用自注意力机制来处理图像数据,能够提供更微观的图像分析,从而捕捉图像中的长距离依赖关系,提升监测的精度和细节丰富度(Dosovitskiy et al,2020)。语义分割利用神经网络分析图像中每个像素所代表的真实物体,对图像进行像素级分类,从而分割出物体轮廓,可更有效提取水生生物,如鱼体形态区域的特征并开展量化分析。Yu等(2020)基于Mask R-CNN实现了鱼体形态特征测量,Li等(2023)基于ResNet50为编码器的UNet模型实现了对8类鱼体形态区域的精准分割。计算机视觉技术的应用不仅可以提高鱼类跟踪、计数和行为分析的效率,也可以提高鱼类形态测量的准确率和效率。然而现有的研究主要基于有监督学习的模式,其对有效标记样本的需求量较大,训练模型所需的算力成本大,模型参数优化过程复杂(田志新等,2022;李健源等,2024)。
语义分割是计算机视觉中的重要领域,它通过标注出图像中每个像素所属的对象类别,实现图像区域的划分和理解。对于面向语义分割的鱼类相关视觉任务,由于其存在因数据标注规模以及深度学习模型预训练微调导致的算力资源需求大的问题,本文试图引入弱监督语义分割技术来快速提取水生态监测视频中鱼类的特征信息,通过使用不完整的监督信息(如图像级别的标签、掩码或大致的边界框)来进行提示性的语义分割,从而在较低的算力需求和少量标记工作量的条件下实现有效的图像理解(Zhi et al,2021)。
1" "材料与方法
1.1" "数据来源
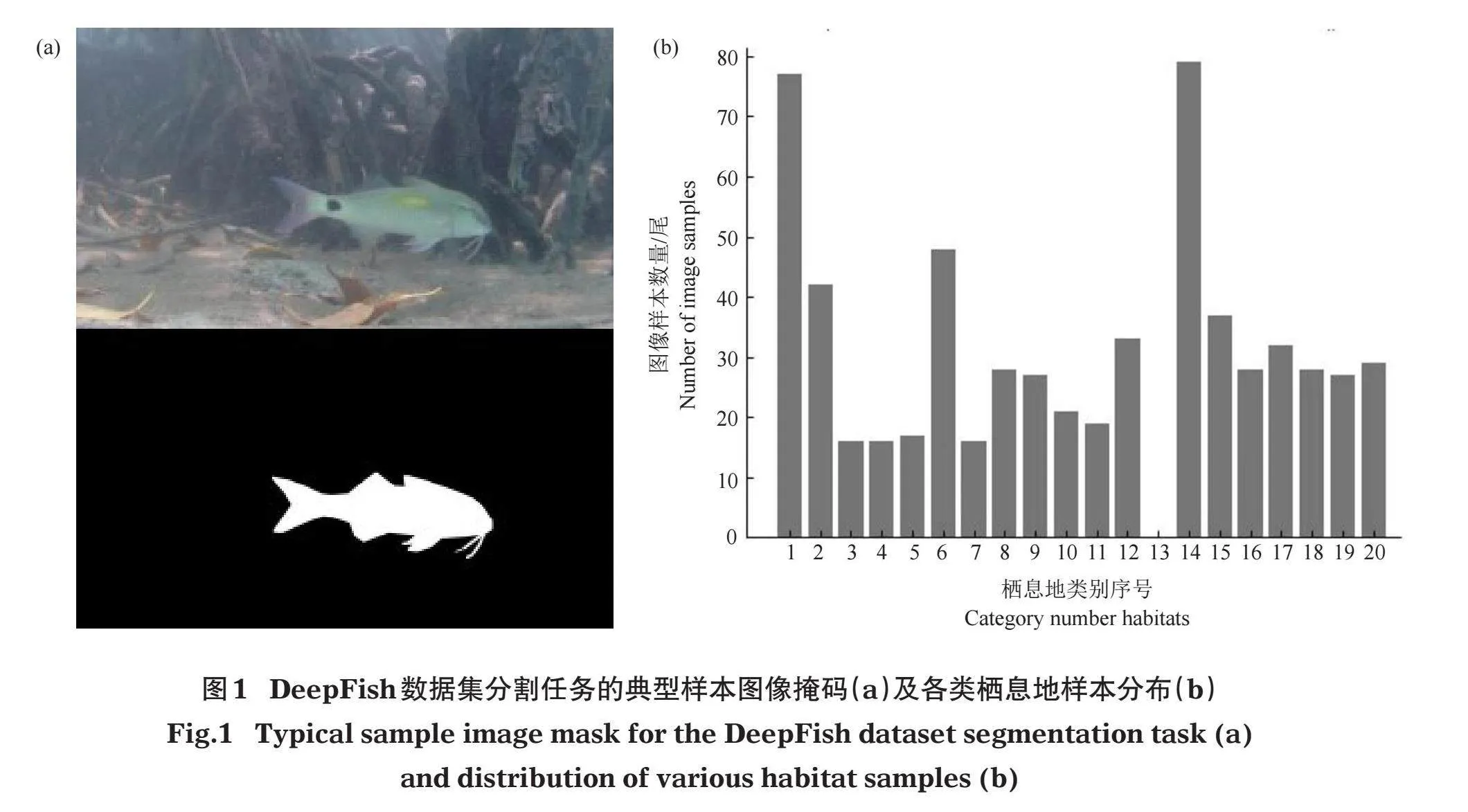
采用DeepFish数据集(Saleh et al,2020)进行建模,从620张标注好的图像中选取310张进行模型训练、124张进行模型验证、186张进行模型测试。DeepFish数据集是一个用于评估水下视觉分析算法的真实鱼类栖息地数据集,该数据集是从澳大利亚热带海洋环境20个栖息地水下收集的约4万张图像经人工处理标注而来。该数据集的原始视频是将摄像机放置于海底,并在水体浑浊度相对较低的时间段内采集获得,原始图像以全高清分辨率(1 920×1 080像素)剪辑导出。其典型样本图像的分割掩码图及不同栖息地的样本分布见图1,涵盖了水下成像的复杂环境,有助于训练和测试模型在不同环境下对鱼体特征学习的能力。
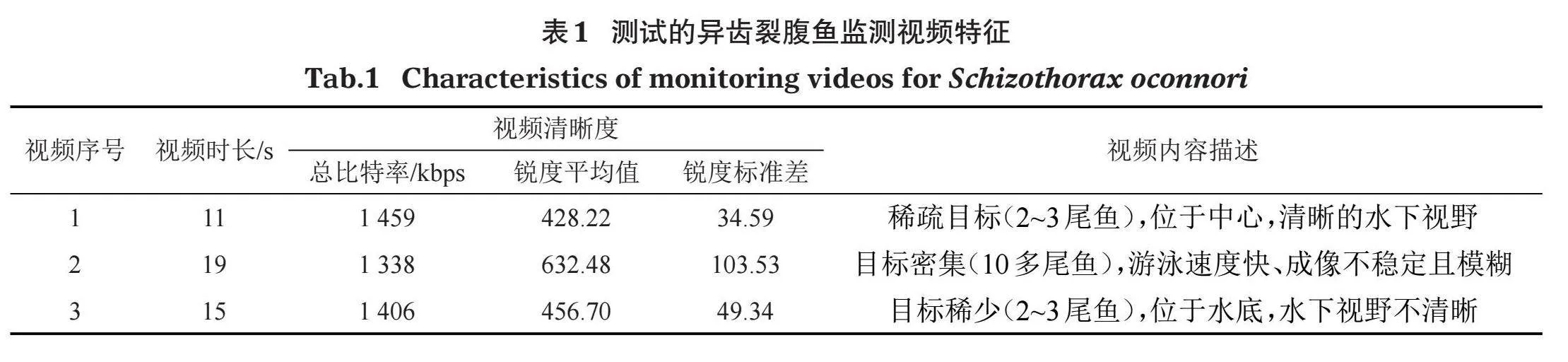
采用实拍水下鱼群监控视频的方式进行推广应用测试。选用由中国水利水电科学院在雅江某鱼道内定点拍摄的3段异齿裂腹鱼(Schizothorax oconnori)(体长30~50 cm)视频,视频帧尺寸为1 280×720像素,帧率均为30帧/秒,视频文件参数见表1。3段视频在清晰度、鱼类个体数量和成像位置上存在差异,用于检验弱监督语义分割方法的鲁棒性。
1.2" "鱼体轮廓与形态区域分割
1.2.1" "鱼体轮廓语义标记" "参考鱼类关键点数据集(Yu et al,2023),考虑实际水下成像条件,将鱼体形态测量区域分割为3个语义标记:头部、身体和鱼鳍(图2)。
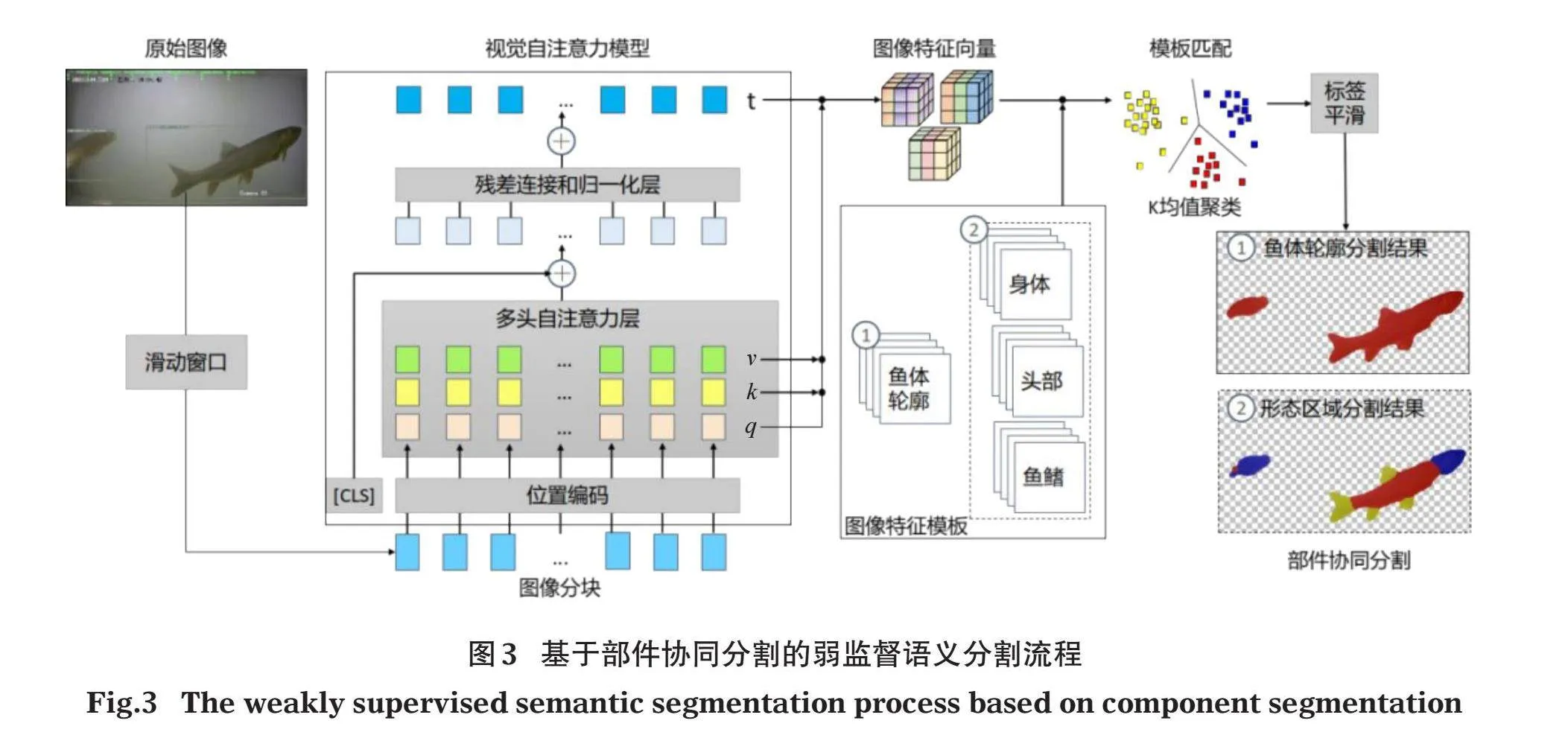
1.2.2" "鱼类语义分割特征提取流程" "采用基于部件协同分割的弱监督语义分割方法进行语义分割特征提取,具体流程见图3。使用FFmpeg工具(Tomar,2006)逐秒提取视频关键帧图像,通过加载预训练权重的ViT模型从待分割图像提取特征向量,首先加载鱼体轮廓分割的模板图片集进行聚类分组,基于模板匹配的方法,实现待分割图像各像素点的区域判定,得到鱼体轮廓分割的区域掩码,然后加载鱼体形态区域分割的模板图像集进行模板匹配,实现鱼体特定形态区域的提取分割。
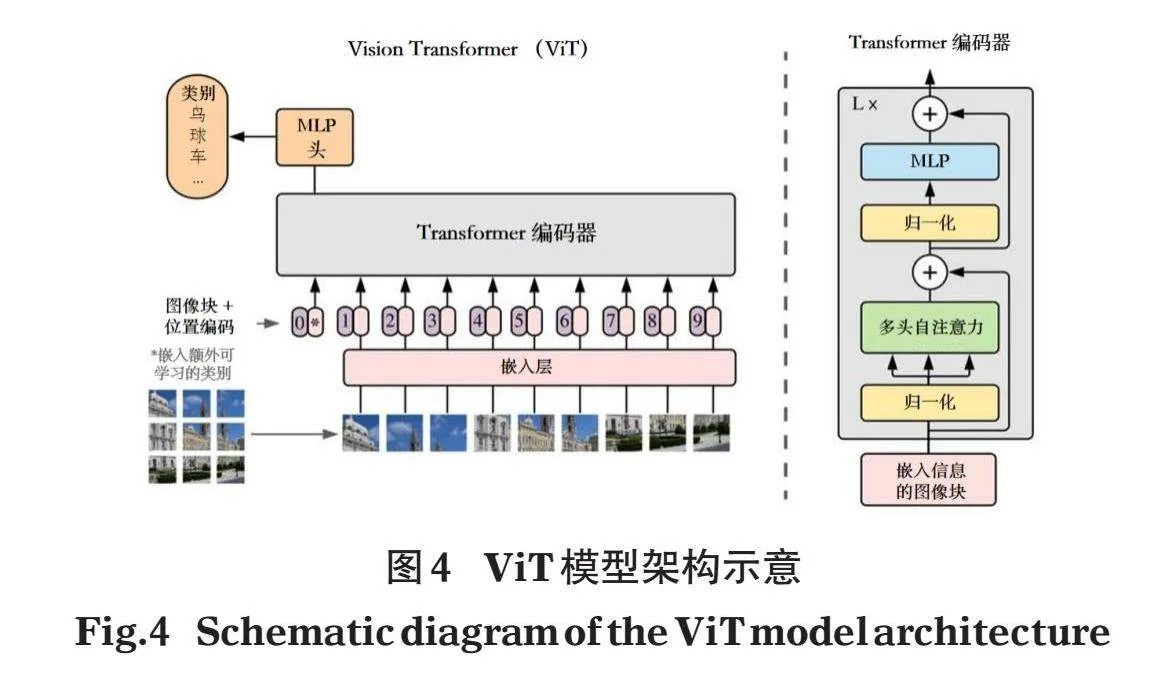
采用基于ViT模型实现在图像块粒度表征图像特征的方法,ViT模型架构见图4。
提取特征的步骤如下:
(1)将输入的图像分成一系列的图像块,构建成一个序列,直接将图像块拉伸为一维向量序列,转化为词嵌入向量;ViT模型构建图像块一般按像素划分,各块之间不存在重叠,为了提升特征提取的分辨率并有效提取块边界信息,采用滑动窗口的方式生成部分重叠的图像块序列。分块数(N)的计算公式如下:
N = NH [×] NW = ([H+S-PS][×][W+S-PS]) ①
式中:NH和NW分别为高度和宽度上切分块的数量,H为图像高度,W为图像宽度,S为滑窗步长,P为图像分块大小。
(2)对图像块序列中的每个元素添加一个用于表示序列元素位置信息的位置编码。
(3)将图像块的嵌入向量和位置编码向量作为输入,使用多层的Transformer编码器进行处理。其中编码器由多个Transformer模块构成,每个模块包含多个自注意力层和前馈神经网络。编码器层的堆叠使得模型能够更好地捕捉图像的高级特征。
(4)Transformer模块由自注意力层、全连接前馈层、残差连接和层归一化操作等基本单元组成,其中自注意力层是核心组成部分,由可学习的查询矩阵WQ、键矩阵WK及值矩阵WV组成,图像块向量的输入i分别经过上述3个矩阵的变换得到查询向量q,键向量k,值向量v,最后经过自注意力机制的公式得到层的输出向量t,计算公式如下:
[k,q,v=WK,WQ,WV×i]" " ②
[t=Softmax(qkTd)×v]" " ③
式中:Softmax为归一化指数函数,d为输入向量i的嵌入维度,T为k向量的转置。
自注意力机制的实现基于查询向量q,键向量k,值向量v。对于输入序列中的每个元素,模型都会计算它与所有其他元素的相似度(通过q和k的匹配来实现),而后根据相似度加权求和,得到当前元素与邻近元素的关系。关系相近的元素即为同一语义的集合,由此可以提取出相同语义的区域,即鱼类的特征形态区域。
由于q,k,v,t向量都是输入向量i的线性变换,逐层传递的编码信息即可反映图像块的特征。本文直接利用预训练模型进行特征提取,图像以256的短边长度输入到ImageNet数据集预训练的ViT模型(Caron et al,2021)提取图像特征,模型自主力层计算的向量集作为编码高级语义信息的特征向量。研究对比了模型在不同分块大小、嵌入维度、滑窗步长、特征向量类型及提取层数深度参数下鱼体轮廓分割结果,以优选适用于鱼体形态区域分割的模型参数。本文研究的推理模型结构参数如表2所示,DeiT(data efficient image transformer)是指通过知识蒸馏方法训练的ViT小模型,其通过大的预训练模型传递知识信息训练,而非像ViT模型从头训练。因此,DeiT在保持与ViT模型结构相同且性能同等条件下压缩了模型体积,有助于减轻对算力的需求,实现更高效的部署。实验环境基于ubuntu22.04操作系统,CPU为12线程i5-12400,RTX3060(12GB)显卡,内存32GB,CUDA版本为11.7,编程语言为python3.8,深度学习框架为Pytorch1.13,设置了固定的随机种子,确保实验结果的复现性。
1.2.3" "模板匹配" "为了实现自动分割标记,采用模板匹配方法对图像的特征向量进行聚类分析。在鱼体轮廓分割处理中,选择数据集中鱼体掩码最大的5张图像作为模板,对鱼体形态分割处理,筛选鱼类形态特征显著和清晰的4视频帧作为模板。
模板图像的特征向量集以余弦相似度来度量,计算公式如下:
[cos(θ)=i=1n(xi×yi)i=1n(xi)2×i=1n(yi)2]" " "④
式中:xi,yi为对比的2个图像特征向量。
通过K均值聚类算法得到多个聚类中心,从而获得水下场景的语义标签聚类簇。K均值聚类算法选取与类型总数相同的点作为初始化聚类中心,计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去。之后计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心。重复上述2个步骤,直到每个类的聚类中心不再变化,完成聚类。根据聚类中心的相对位置判定语义标记的鱼体轮廓,从而实现水下鱼体图像区域的自动分割。
由于环境特征变化,通过K均值聚类算法推理得到的鱼体形态区域分割存在一定的噪点,造成分割区域边缘不平滑,因此需要进行适当的后处理技术实现标签平滑。本文使用多标签条件随机场技术实现语义分割标签的区域平滑连续(Krähenbühl amp; Koltun,2012)。由于视频图像和鱼类特征位置变化的连续性,本方法并没有采用深度学习视觉任务常用的数据增强和图像增强技术,以保持模板与目标图像在水下成像环境的一致性。
1.3" "评价指标
采用语义分割任务中常见的平均交并比(mean intersection over union,mIoU)和平均像素准确率(mean pixel accuracy,mPA)作为鱼体轮廓分割实验的模型精度评价指标,采用推理速度评价鱼体形态区域分割模型的计算效率,单位为帧/s。其中平均交并比(mIoU)通过计算预测区域和真实区域之间的交集与并集的比值来评估模型性能,值越高,表示模型预测的区域与真实区域的重叠程度越高。平均像素准确率(mPA)是计算模型对每个类别的像素预测正确的比例,将所有类别的像素准确率取均值即得到mPA,mPA越高,说明模型对像素级别的分类越准确。推理速度是一秒钟完成推理的画面数量,数值越高,模型的计算效率越高。
2" "结果与分析
2.1" "鱼体轮廓分割
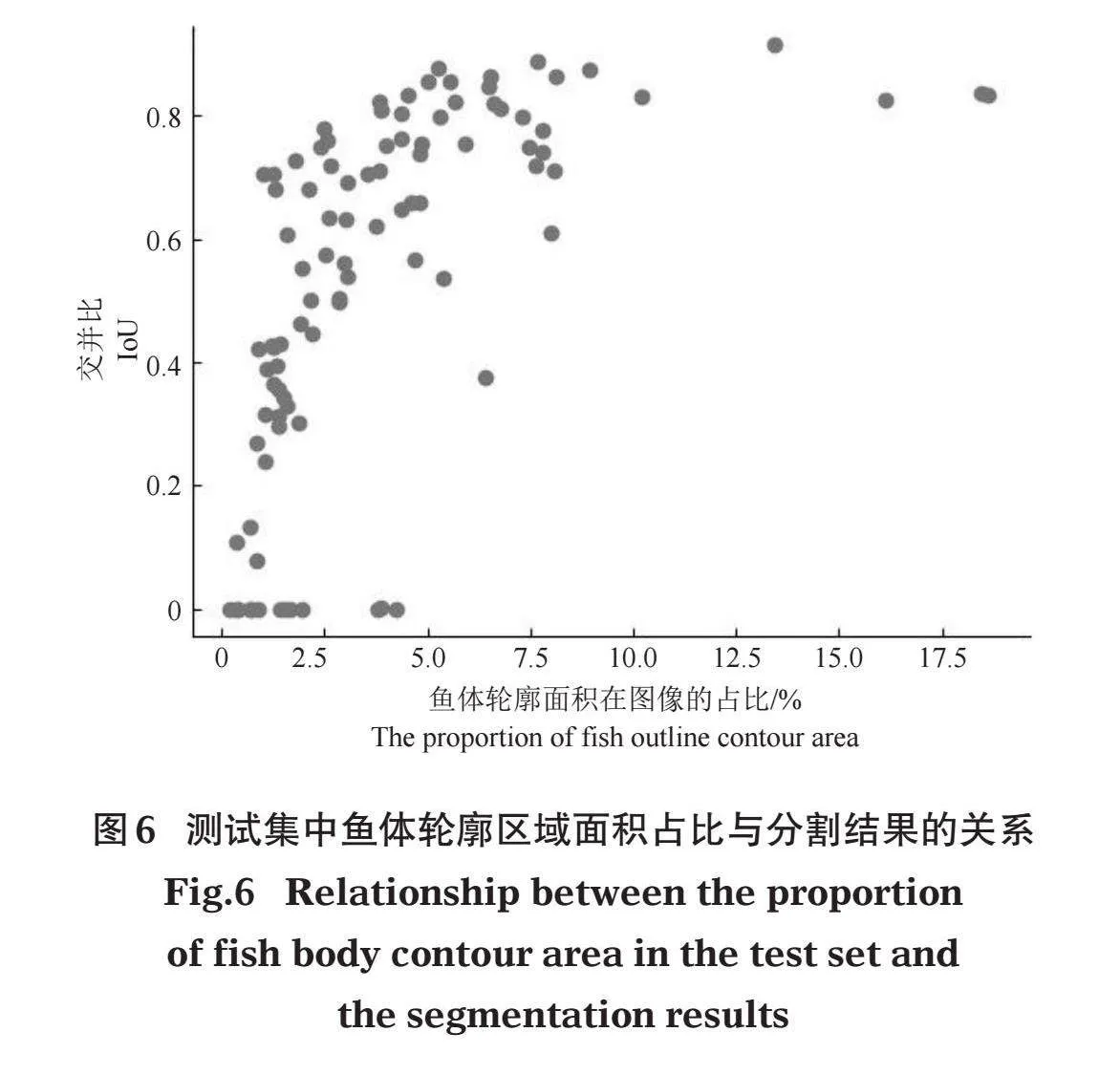
在DeepFish数据集选择的5张模板图像的聚类及分割效果如图5所示,模型分割结果比较理想,5张模板图像的mIoU达到0.83,186张测试图像的mIoU达到0.54,测试集图像鱼体面积与模型分割预测效果的关系如图6所示,62.5%的测试图像mIoU超过0.5。
2.2" "鱼体形态区域分割
在本文测试的3段水下鱼群监控视频中,典型关键帧的部件协同分割结果如图7所示,鱼体形态区域能被准确分割。在分割准确度上,当视野中的鱼类比较稀疏时,更容易获得较好的形态区域语义分割效果。在推理速度上,单张RTX3060显卡推理鱼体形态区域分割处理过程为1.2帧/s,单张V100显卡的推理速度为3.1帧/s,结合视频关键帧提取,本方法的推理效率可以满足实践需求。
3" "讨论
3.1" "ViT模型参数优化与比选
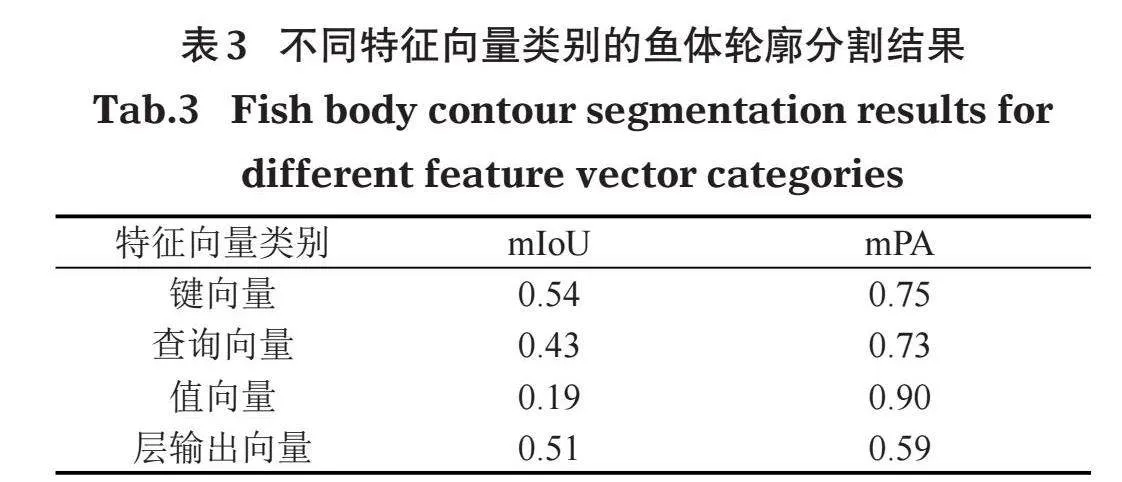
本文以嵌入维度为384、分块大小为8、滑动步长为4的DeiT-S/8模型作为基准模型参数,研究第11层自注意力模块中特征向量类别对分割效果的影响,结果如表3所示,键向量的特征提取实现的分割效果最佳,值向量的分割存在较大的背景假阳性,本文实验均选用键向量作为特征提取的向量类型。
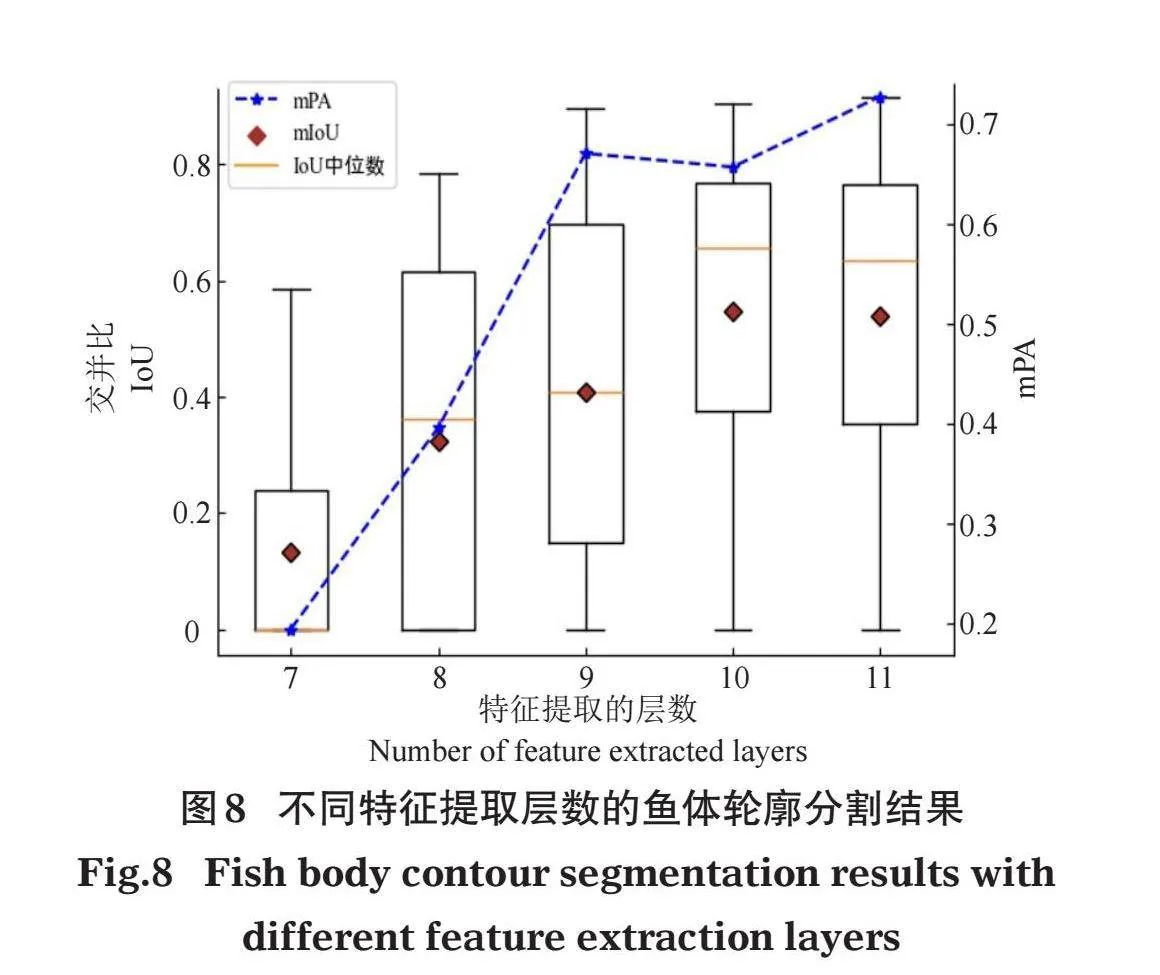
以基准模型为例,研究特征提取的层数对分割结果的影响,结果如图8所示。提取的特征层数越深,平均像素精度和平均交并比越高,分割效果越好。本文实验均选用11层即最后一层进行模型特征提取。
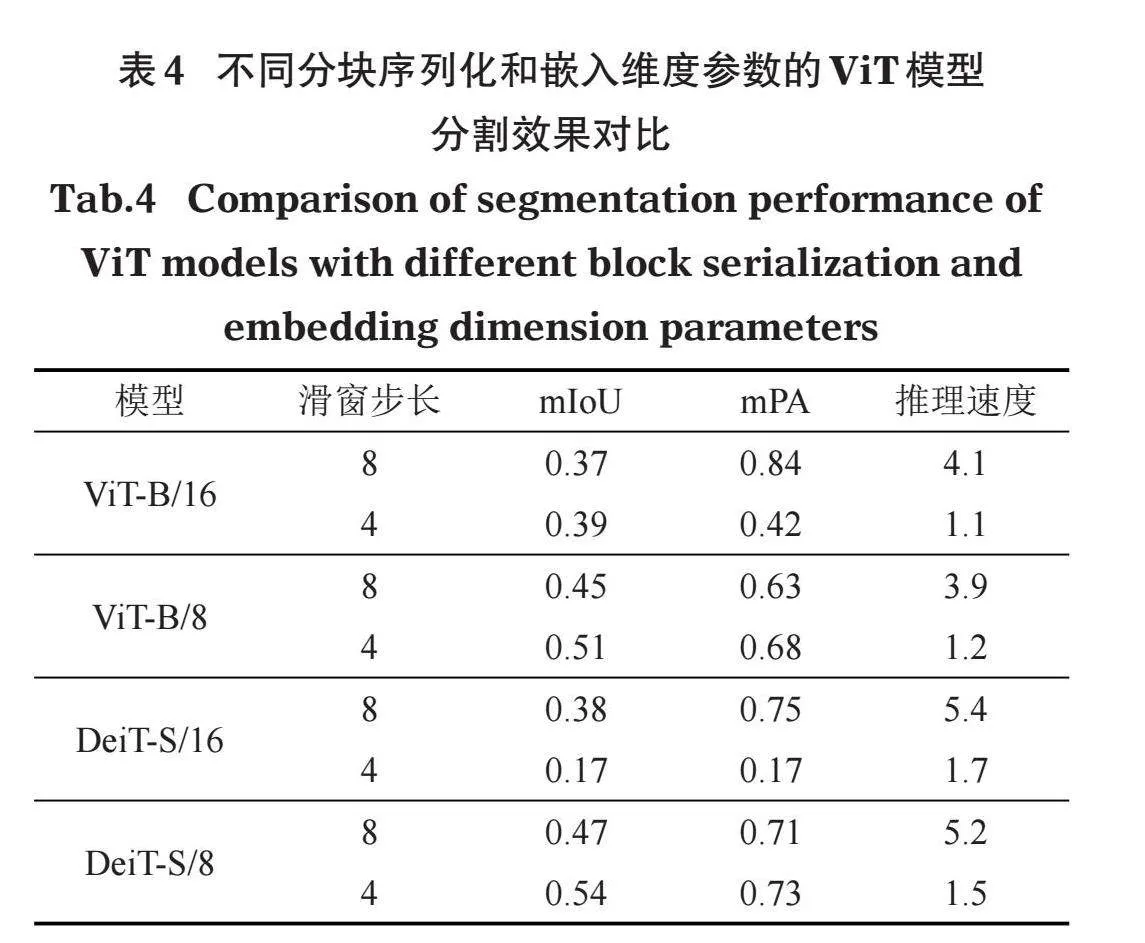
ViT模型的图像分块序列化和嵌入维度参数,既影响了模型参数的规模,也影响着模型对图像特征信息提取的分辨率,进而影响模型开展精细化区域分割的性能和效果,本文在固定模型特征提取的向量类型和层数固定的条件下,对不同图像分块序列化和嵌入维度参数的模型在鱼体轮廓分割上的效果进行对比分析,结果如表4所示。本文选择的基准模型结构分割的效果表现最佳,模型性能主要受分块大小影响,由于使用的均是预训练权重模型进行推理,对于水下环境通用特征的提取会干扰鱼体分割的效果,模型规模最大的ViT-B/8模型的分割效果反而不如参数规模较小的Deit-S/8模型。在同等参数规模的模型中,分块数越小,分割效果越好,主要原因是提取的图像特征细节更多,但同时模型推理速度会变慢。滑窗步长可补充模型分块边界区域的图像特征,实现在不额外投入模型训练资源的条件下,提取更细致的图像特征,理论上具备提升模型性能的可行性(Amir et al,2021)。但实验结果表明其影响效果因模型的结构参数规模而异,对于模型规模小、特征提取能力相对弱的DeiT-S/16模型,滑窗步长减少,分割效果反而越差;而对于其他更大规模的模型而言,滑窗步长越小,分割效果越好。说明滑窗处理的有效性受主干模型本身特征提取能力的制约,此外缩小滑窗步长会增加模型对图像的计算量,因此未来在开展水下鱼类特征提取模型的训练和优化中,需要权衡滑窗处理与模型参数规模,以满足模型性能与推理速度的需求。
3.2" "ViT模型提取的语义特征
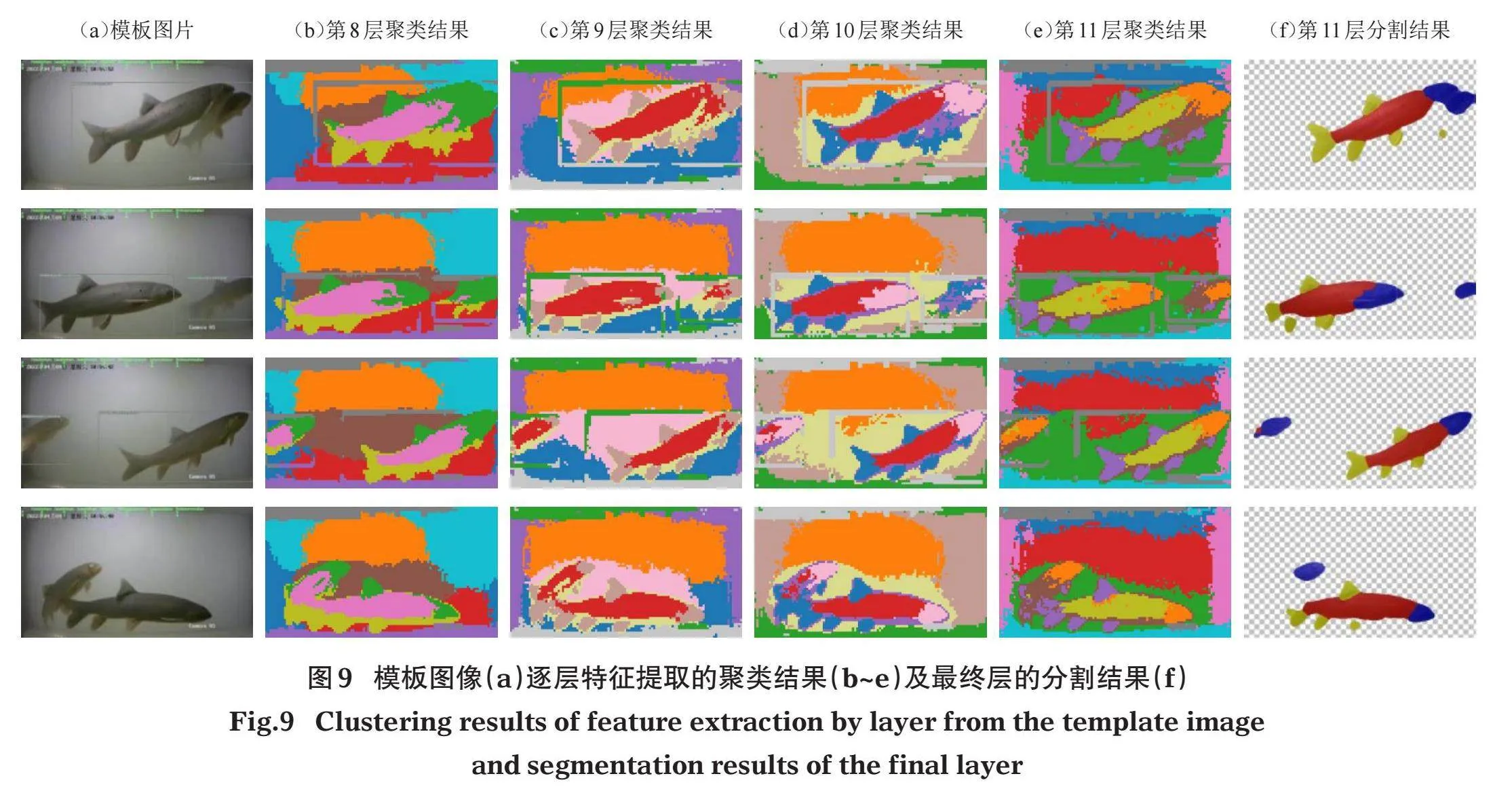
在鱼体形态区域分割实验中,根据实际观测视频的成像条件,本文选择4张视频关键帧作为模板,研究模板图像在不同层之间的匹配聚类结果,以分析ViT模型最后4层特征向量的表征特点(图9)。深层的特征向量聚类结果可以区分鱼体形态细部特征,而浅层则主要区分鱼体的空间位置,本文采用最后一层模型的聚类结果作为特征匹配的模板,从最后一层(第11层)的分割结果来看,本文提出的3个鱼体形态标记区域之间的差异显著,提取的掩码分割效果较为平滑和连续。
本文的结果验证了ViT模型提取的特征在自注意力层之间传递的特点,即浅层特征更多侧重于位置嵌入的相似度,深层特征侧重语义信息(Amir et al,2021)。由于本文的K均值聚类算法中的距离定义采用的是余弦相似度,在稠密、多目标图像识别上有一定的局限性,K均值聚类算法本身对于离群值和非连续特征的提取效果不佳,因此实现高效鱼体形态区域信息聚合和分割的聚类算法有待进一步研究。
3.3" "弱监督语义分割方法的优势
在模板聚类阶段,本文的方法不仅鱼体轮廓区域可识别提取,水草等水下环境要素也可以通过模板进行聚类分割识别;在聚类分割阶段,由于模板的聚类结果中鱼体轮廓边缘存在部分噪点,因此分割区域标签的平滑处理会适当聚集压缩分割区域。本文选择的5张模板图像中鱼体区域在图像像素面积占比均超过10%(图5),模板图像集与小尺寸鱼体图像特征之间存在一定的差距,因此对于测试集图像中部分小尺寸鱼体轮廓的分割效果有待改进提升。由于本文采用的是预训练的ViT模型,没有更改特征提取模型结构和参数,未来在开展针对性的水下鱼类特征提取模型研究中,可采用移位窗口(Liu et al,2021)等多尺度特征提取方法提升ViT模型对多尺度图像特征提取的适应性。
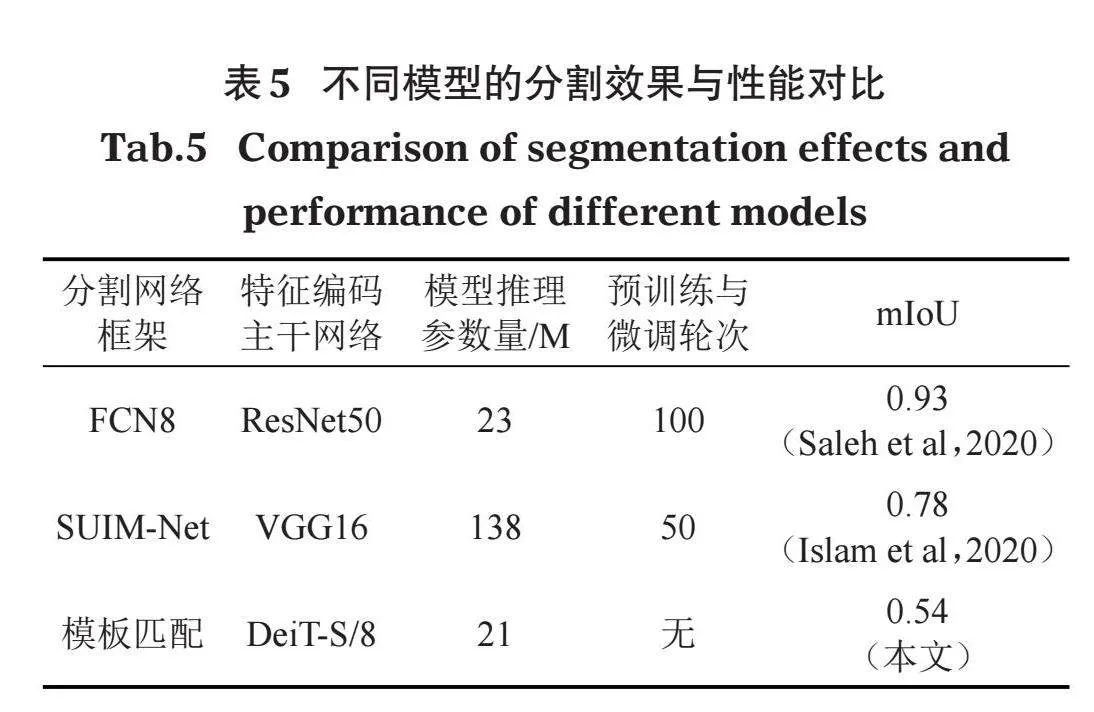
本文方法与文献公开的预训练或微调模型的精度对比如表5所示,本文方法在相对较低的推理模型参数量条件下,实现了实用化的分割效果。本文基准ViT模型与ResNet50卷积网络的推理参数量相当,ViT模型的优势在于基于自注意力机制构建的序列化关联性能够捕捉到图像中不同区域之间的语义关系,从而无需过多依赖显式的位置编码,因此从预训练的神经网络提取中间层的特征可被广泛用于各类视觉任务。本方法无需对ViT模型预训练或微调,对推理算力需求较低,因此相较于有监督学习方法,本文提出的弱监督学习方法在推理效率上更有优势,而且对分割标注的样本需求量极低,可极大降低数据预处理成本,降低ViT模型应用落地的难度。
4" "结论
鱼类图像形态的几何和语义特征高度相关。本文基于Transformer的视觉模型,提出了一种基于弱监督语义分割的视频鱼类特征提取方法,通过加载预训练权重的ViT模型从待分割图像提取特征向量,然后进行模板匹配,实现鱼体特定形态区域的提取分割。主要结论如下:
(1)本文在DeepFish测试集共186张测试图像的平均交并比(mIoU)指标达到0.54,62.5%的测试图像mIoU超过0.5,提取速度高于1帧/s。因此本方法能快速准确实现无接触式分割、提取鱼类特征。
(2)本文基准ViT模型与ResNet50卷积网络的推理参数量相当,同时无需对ViT模型预训练或微调,即可实现实用化的分割效果。因此本方法拥有相对较低的推理算力需求与分割标注的样本需求量,可降低数据预处理成本,降低ViT模型应用落地的难度。
本文提出的方法在无需预训练或微调的条件下实现了对鱼的身体、头部和鱼鳍3类形态区域标签的分割提取并进行良好的标记,具有较高的效率和标记区域的连续平滑性,为形态测量等鱼类行为研究提供了良好的语义特征表示。
参考文献
李健源, 柳春娜, 卢晓春, 等, 2024. 构建VED-SegNet分割模型提取鱼类表型比例[J]. 农业工程学报, 40(3):175-183.
田志新, 廖薇, 茅健, 等, 2022. 融合边缘监督的改进Deeplabv3+水下鱼类分割方法[J]. 电子测量与仪器学报, 36(10):9.
Amir S, Gandelsman Y, Bagon S, et al, 2021. Deep vit features as dense visual descriptors[J]. arXiv:2112.05814.
Caron M, Touvron H, Misra I, et al, 2021. Emerging properties in self-supervised vision transformers[J]. arXiv:2104.14294.
Dong J, Shangguan X, Zhou K, et al, 2023. A detection-regression based framework for fish keypoints detection[J]. Intelligent Marine Technology and Systems, 1(1):9.
Dosovitskiy A, Beyer L, Kolesnikov A, et al, 2020. An image is worth 16x16 words: transformers for image recognition at scale[J]. arXiv:2010.11929.
Islam M J, Edge C, Xiao Y, et al, 2020. Semantic segmentation of underwater imagery: dataset and benchmark[J]. arXiv:2004.01241v3.
Krähenbühl P, Koltun V, 2012. Efficient inference in fully connected crfs with gaussian edge potentials[J]. arXiv:1210.5644.
Li J, Liu C, Yang Z, et al, 2023. RA-UNet: an intelligent fish phenotype segmentation method based on ResNet50 and atrous spatial pyramid pooling[J]. Frontiers in Environmental Science, 11:1201942.
Liu Z, Lin Y, Cao Y, et al, 2021. Swin transformer: hierarchical vision transformer using shifted windows[J]. arXiv:2103.14030.
Saleh A, Laradji I H, Konovalov D A, et al, 2020. A realistic fish-habitat dataset to evaluate algorithms for underwater visual analysis[J]. Scientific Reports, 10(1):14671.
Tomar S, 2006. Converting video formats with FFmpeg[J]. Linux journal, (146):10.
Yang L, Liu Y, Yu H, et al, 2021. Computer vision models in intelligent aquaculture with emphasis on fish detection and behavior analysis: a review[J]. Archives of Computational Methods in Engineering, 28(4):1-32.
Yu C, Fan X, Hu Z, et al, 2020. Segmentation and measurement scheme for fish morphological features based on mask R-CNN[J]. Information Processing in Agriculture,7(4):523-524.
Yu Y, Zhang H, Yuan F, 2023. Key point detection method for fish size measurement based on deep learning[J]. IET Image Processing, 17(14):4142-4158.
Zhang Y, Zhang F, Cheng J, et al, 2021. Classification and recognition of fish farming by extraction new features to control the economic aquatic product[J]. Complexity, (1):5530453.
Zhi S, Laidlow T, Leutenegger S, et al, 2021. In-place scene labelling and understanding with implicit scene representation[J]. arXiv:2103.15875.
(责任编辑" "熊美华)
A Semantic Segmented Framework for Extracting Fish Features from Videos
LI Xiao‐yang1, CHEN Jian1, CHANG Jian‐bo2
(1. Electronic Information School, Wuhan University, Wuhan 430072, P.R. China;
2. School of Water Resources and Hydropower Engineering, Wuhan University, Wuhan 430072, P.R. China)
Abstract:Fast and accurate extraction of information on features of aquatic organisms from video images is a research hotspot that draws from information science and ecological research. In this study, we developed a fish feature extraction method based on weakly supervised semantic segmentation and the vision transformer. Our aim was to realize the segmentation and extraction of three types of fish morphological regions (body, head, and fins) without the need for pre-training or fine-tuning. First, a self-attention model was created using a DeepFish segmentation dataset, and then applied to extract information from underwater videos of Schizothorax oconnori. Results show that the method we proposed effectively extracted the three morphological features of the test fish, appropriately segmenting, marking and labeling the three features. In general, the process is highly efficient, accurate, and smoothly labeled the semantic features. It is a low-cost, highly efficient method for the practical application of artificial intelligence technology in the monitoring of fish and other aquatic organisms.
Key words: weakly supervised learning; semantic segmentation; vision transformer; fish feature extraction
