基于图像处理的桥梁橡胶支座剪切病害检测方法
2023-12-30张少杰周印霄王莲香刘跃飞
梁 栋 , 张少杰 , 周印霄 , 王莲香 , 张 强 , 刘跃飞
(1.河北工业大学 土木与交通学院,天津 300401;2.邢台路桥建设集团有限公司,河北 邢台 054000;3.天津市公路事业发展服务中心,天津 300170;4.天津公路工程设计研究院有限公司,天津 300171)
支座作为桥梁结构中重要的受力构件,其作用是将桥梁上部结构承受的荷载传递至下部结构,当支座出现损伤但未及时发现时,易导致桥梁损伤,严重时甚至危及桥梁的运营安全.所以对支座开展定期检测工作以保证桥梁的安全性是必要的[1].板式橡胶支座具有性能可靠、造价低、安装和使用方便等特点,目前已成为国内中小跨径桥梁最为常见的一种支座形式[2].随着服役年限的增加,橡胶支座本身结构设计、生产质量、施工不当和长期受疲劳荷载作用等问题导致大量以剪切变形超限、老化开裂等为主的病害也开始凸显.支座剪切变形病害普遍存在于桥梁工程中,而且支座的剪切病害会进一步加速老化开裂并引发其他次生危害[3].因此,支座剪切病害是研究者们应该重点关注的课题.
目前支座的病害检测主要是人工现场测量来完成,但由于支座本身处于大梁与盖梁之间,空间狭小,很难进入,再加上服役时间增加,其本身裸露于外部环境之中,周边多有碎石遮挡甚至部分深入混凝土之中,严重影响了检测效率和检测精度,给检测人员带来了很大困扰.结合利用计算机视觉检测结构损伤案例[4],建立基于计算机视觉评估支座状态的方法是非常必要的.
在传统检测手段的基础上,目前基于图像处理的桥梁结构损伤识别正朝向智能化、自动化检测方向发展,但其中对支座病害的研究较少.参考混凝土裂缝的研究方法[5],裂缝在图像中像素占比极少,学者们通常先对图像中裂缝分割提取后再进行参数如长度、宽度等计算.最初基于边缘检测[6]、阈值大小[7]或聚类技术[8]等完成对图像中裂缝的分割提取,但将上述方法运用至支座图像时,虽然支座本身在图像中像素占比较多,但背景复杂多变,处理时常常会包含大量噪声[9],影响检测结果,导致支座剪切病害程度评估较为困难.
随着计算机科学的发展和计算能力的指数级增长,深度学习方法能够对人为标记的大量数据集进行学习并自动寻找最佳的特征提取器和分类模型[10],显示出优于传统检测方法的能力,在桥梁损伤检测中已有广泛应用[9],并向远程、自动化方向发展.余加勇等[11]基于无人机技术对裂缝图像采集并利用Mask R-CNN 网络分割提取裂缝图像后进行参数计算.在支座病害识别方面,Cui 等[12-13]首先利用卷积神经网络(Convolutional Neural Network,CNN)完成了对于支座病害分类的初步尝试,并利用注意力机制和尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)及支持向量机(Support Vector Machines,SVM)等技术对网络进行改进提升了识别准确率.但对支座病害仅进行了定性分析,为使评估结果更加准确,需开展定量研究.
语义分割技术[14]能够完成像素级的类别判断,对目标图像分割更加精确.利用此技术能更好地分割提取图像中支座部分,保证后续支座剪切病害定量计算的准确性.相较于全卷积神经网络(Fully Convolution Network,FCN)和U-Net+++等语义分割网络,由Ronneberger 等[15]提出的U-net 网络在增强边缘等细节信息获取的同时,还能有较高的效率.它采用卷积神经网络结构,并且在网络中加入了跳跃连接的机制,能够在数据集较少的情况下更好地解决像素级别的分割任务,在医学图像分割领域[16]有良好的表现.在使用U-Net 的基础上,为满足工业化需要,Liu 等[17]通过选用新的评价函数和应用Adam 算法优化使得U-Net 在裂缝检测上更加准确;梁栋等[18]通过优化网络结构,融合深度可分离卷积搭建了轻量化的MU-Net,能够在不丢失精度的同时快速进行裂缝识别.虽然已有利用U-Net对桥梁结构损伤检测的研究,但在支座病害评估方面鲜有涉及.因此,本文通过对U-Net 网络进行改进,融合深度可分离卷积来减小计算量的同时,加入多尺度注意力模块(Multi-scale Attention Module,MAM)以提升支座分割的精度,并运用边缘提取、凸包检测和线性拟合等操作完成了对桥梁板式橡胶支座剪切病害的智能检测.
1 支座剪切病害评估方法
1.1 支座图像分割
基于U-Net 进行改进,本文提出了融合深度可分离卷积和MAM 的改进U-Net 网络,结构如图1所示.改进后的U-Net 网络继续沿用U-Net 的“U”型结构,主要由编码器和解码器两部分组成,是一个端到端的分割模型.在编码器中,为了使模型保证分割精度的同时还能加快速度,使用深度可分离卷积[18]代替传统卷积操作进行特征提取,并引入MAM 提取更多的特征信息.输入的图像经过4 次MAM 并进行最大池化来实现下采样操作;在解码器中,设置上卷积层完成上采样工作,获得一个更高分辨率的特征图;然后,使用跳跃连接层连接对应的编码区和解码区,跳跃连接层将MAM 提取到的特征与上采样过程中对应相同尺寸的特征图进行拼接,得到被分割物体多尺度的特征信息.最终,融合了多方面特征信息的分割结果以输入图片同样的尺寸被输出.
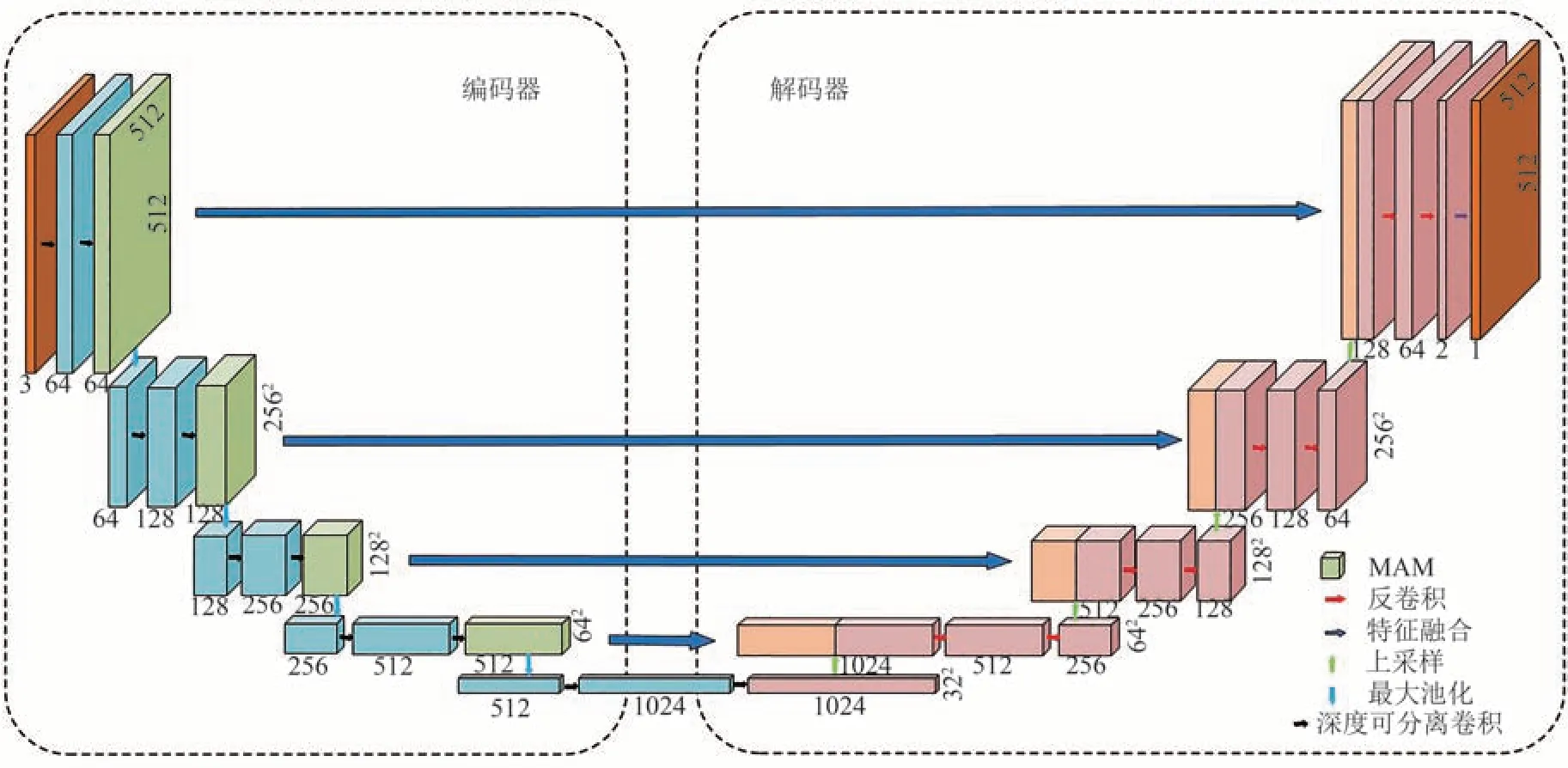
图1 改进U-net 分割模型结构图Fig.1 Schematic diagram of segmentation model for the improved U-net structure
1.1.1 深度可分离卷积
由于U-Net 有较深的网络结构和较多的卷积层,计算时包含大量参数且像素级的处理导致了计算量的大幅增加.深度可分离卷积包含对每个通道应用单独卷积核的深度卷积和能将所有通道不同位置进行组合的1×1 的点卷积两部分,原理如图2 (a)所示.由于深度可分离卷积中每个卷积核只负责自己的通道,所以参数计算量减少,计算复杂度降低,计算效率大幅增加.其结构如图2 (b)所示,包含深度卷积、1×1 逐点卷积、批归一化和线性整流函数(Rectified Linear Unit,ReLU)等.

图2 深度可分离卷积Fig.2 Depthwise separable convolution
在输入通道数C、输出通道数Q、卷积核大小DK×DK、特征大小DF×DF的情况下,标准卷积的参数量为
深度可分离卷积参数量为
深度可分离卷积参数减少量为
1.1.2 多尺度注意力模块
桥梁板式橡胶支座在长时间服役后,由于持续经受疲劳荷载、温度变化共同作用,其本身变形无法预测,再加上周围碎石等杂物干扰,支座边缘不明显且极易与周围环境相混淆,而支座分割结果的边缘线与后续角度计算精度密切相关.因此,提出一种如图3 所示的MAM 来融合多尺度特征增加模型识别分割支座的能力,提高图像分割的准确性和鲁棒性.
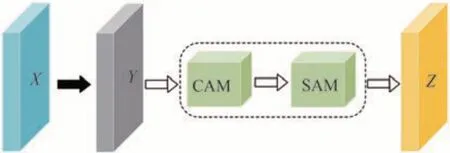
图3 MAM 结构图Fig.3 MAM structure diagram
经过深度可分离卷积得到的特征通过通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM),实现全局和空间不同尺度特征的融合,保证最终输出的特征图能最大化地包含特征.
假设输入特征图X=RC×H×W,其中C、H和W分别代表特征图的通道数、高和宽,经由深度可分离卷积后得到Y,Y通过CAM 后得到特征Y′,然后经过SAM 得到融合了整体多尺度包括空间位置信息的新特征图Z.计算式为
1.1.3 通道注意力模块
CAM 结构如图4 所示,其中包含全局平均池化(Global Average Pooling, GAP)和全局最大池化(Global Max Pooling, GMP).两者均是将特征图单个像素点划分为单个区域,通过计算区域内特征值的平均值和最大值,生成单一特征用于下一层计算,两者融合使用可以捕捉到更多图像中关于支座的信息,提高分割精度和模型的泛化能力.图4 中,1×1卷积、ReLU 激活函数和1×1 卷积共同组成CAM的网络连接层,⊕表示加和.经CAM 得到特征图Y′的计算式为

图4 CAM 结构图Fig.4 CAM structure diagram
式中:S代表Sigmoid 激活函数;K11×1代表大小为1×1 且步长为1 的卷积.
1.1.4 空间注意力模块
SAM 用于增强模型识别分割时对图像中支座空间位置信息的关注度.对于输入特征,首先基于通道中的平均池化和最大池化得到两个单通道的结果,两结果拼接后经过卷积操作得到二维的特征图,最终经过Sigmoid 函数得到空间注意力特征图.经过CAM 的特征图Y′输入SAM,可以得到融合了全局和空间信息的特征图Z,计算式为
式中:MP 表示最大池化;AP 表示平均池化;[MP(Y′):AP(Y′)]表示两者的拼接操作.
1.1.5 损失函数
在训练过程中,设置合适的网络参数,能够帮助优化模型更好处理像素个数庞大的图片,使得模型预测结果与真实的标签之间误差最小.使用交叉熵损失函数(Loss)来计算每次迭代的向前计算结果和真实值差距,从而指导下一步训练方向.计算式为
式中:y为真实值,取值为0(非支座部分)或1(支座);ŷ为预测值,ŷ∈[0,1].
1.1.6 评价指标
由于支座本身目标与背景相比,面积较大,传统如选择像素准确率(Pixel Accuracy,PA)作为评价指标时,即使识别效果不好,但最终准确率仍在90%以上,不能准确地反映模型的识别能力.因此采用F1 值和交并比(Intersection over Union,IoU)以及识别效率t作为评价指标对本文模型支座识别分割性能进行评价.计算式分别为
式中:TP 代表标识为支座,且被模型正确识别为支座的像素;FP 代表标识为背景,但被模型错误识别为支座的像素;FN 代表标识为支座,但被模型错误识别为背景的像素,TN 代表标识为背景,且被模型正确识别为背景的像素.
1.2 剪切角度计算及分级
由于碎石等遮挡物的影响,支座本身往往在图像中不能完全暴露,导致分割后的支座图像并不完整,边缘常常是锯齿状甚至沟壑状.支座剪切角度的计算方法如图5 所示,首先模型分割输出的支座二值图像利用改进的Alpha Shapes 算法提取轮廓线,对支座轮廓线运用凸包检测生成凸包并提取凸包点,对这些凸包点根据其在像素坐标系中的位置,在筛选剔除偏差较大的点后对剩余点利用最小二乘法拟合得出支座各边直线并计算各直线间夹角.
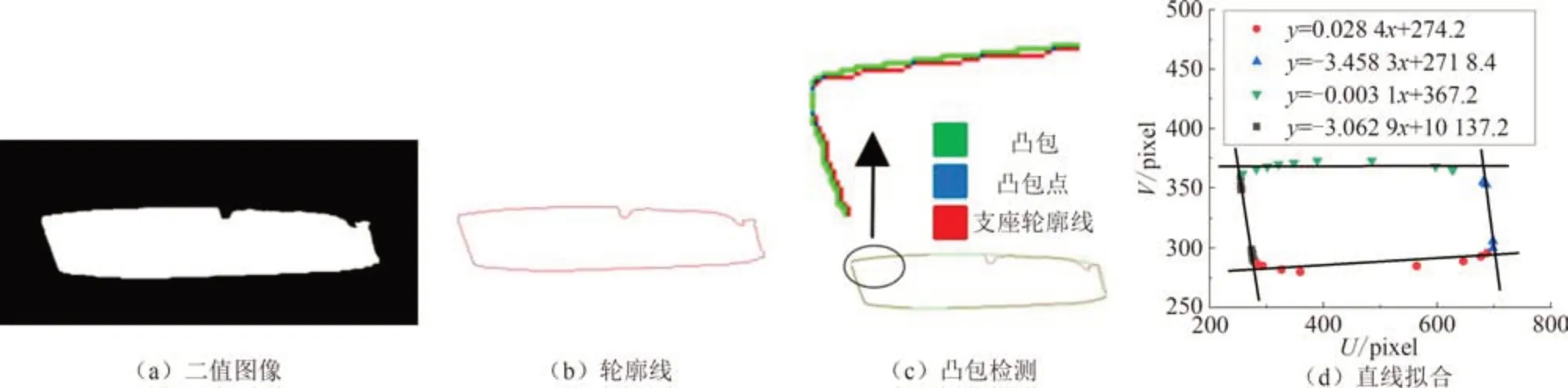
图5 角度计算原理Fig.5 Principle of angle calculation
1.2.1 轮廓提取
Alpha Shapes 算法最早由Edelsbrunner 等[19]提出,它是一种简单高效的边界提取算法,主要应用于点云轮廓边界线的提取[20].Alpha Shapes 算法边界提取原理如图6 (a)所示,对于任意形状的集合,存在一个半径为α的圆,绕其进行滚动.若半径过小,则会将集合内部的点视为边界点,当半径适当增大到一定程度时,则其只会在集合边界滚动,所有滚动点集便构成了边界轮廓.因此需要设置适当的阈值,达到边界提取的目的.具体计算示例如图6 (b)所示,计算过程如下.

图6 改进的Alpha shapes 算法Fig.6 Improved Alpha shapes algorithm
1)选取目标点集N中的任意一点ni(xi,yi),根据预先设置半径α的滚动圆,从点集中搜寻距离小于2α的所有点,记为邻域点集M;
2)选取点集M中任意一点nr(xr,yr),根据两点ni、nr的坐标和半径α,可确定两个以O1(xo1,yo1)和O2(xo2,yo2)为圆心的圆;
3)分别计算点集M中除nr之外的其他点至圆心O1,O2的距离di1和di2,若存在所有的di1或所有的di2均大于半径α,说明ni,nr为边界线段,否则不是边界线段;
4)重复1)~3)步,直至遍历完点集M、N中的所有点.
对于支座二值图像来说,支座区域的像素格即为目标点集N,由于支座本身面积很大,全部像素格计算需要花费大量时间,因此为了减少计算量,提高算法对支座边缘线提取的计算效率,利用像素格八连通原理对Alpha Shapes算法进行了以下约束改进.
1)因支座边缘线一般不会存在于支座区域中部位置,因此在点集N中,删除所有周边八连通全部为支座区域的像素格,如图6 (c)所示,若P1 周边的P2~P9 均为支座区域,则P1 不参与点集N的计算;
2)选取与点ni(xi,yi)八连通相连的像素点作为点集M中任意一点nr(xr,yr)的选取原则,能够排除不连通的支座像素点.
利用改进的Alpha Shapes 算法对支座二值图像提取,最后得到的是一个封闭的连续单位像素点的支座边缘线,支座边缘线效果如图5 (b)所示.
1.2.2 凸包检测
凸包检测是计算机视觉和几何图形处理领域中的一项技术,能够很好地解决图像中支座部分被碎石等遮挡导致提取出的支座边缘线出现锯齿状或者沟壑状的问题,利用边缘线中更具有代表性的凸包点拟合直线会更加迅速与准确.
假设支座边缘线共包含6+1 个像素点,记作点集P,如图7 所示,基于Graham 扫描法寻找点集P凸包的过程如下.
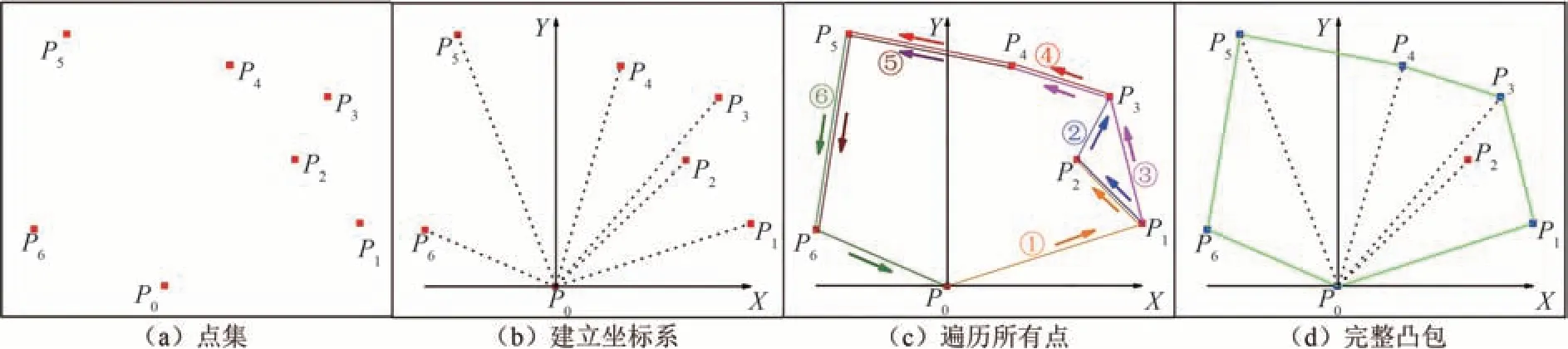
图7 Graham 扫描法示例图Fig.7 Example diagram of Graham scan method
1)找到点集P中像素坐标值最小的点,记作P0,并以P0为原点建立坐标系;
2)对剩余点按P0的逆时针方向进行排序,排序结果记作(P1,P2,…,P6),极角相同时保留极径最大的点;
3)创建一个栈E,3 个点一组,按①~⑥的顺序,作左转判断,满足入栈,不满足则出栈.如图7 (c)所示,点集P中只有P2不满足,其他点全部入栈;
4)形成完整凸包.
对支座边缘线凸包检测完成后的结果如图5 (c)所示.
1.2.3 直线拟合
最小二乘法具有普遍的实用性,其计算简洁、精度可靠且容易实现,是很实用的数据分析方法.
假设栈E中共包含m个凸包点,凸包点坐标分别为(x1,y1),(x2,y2),…,(xm,ym),利用最小二乘法对凸包点拟合直线y=ax+b,其中a为回归系数,b为截距,具体拟合过程如下.
1)首先计算凸包点的均值.
2)计算回归系数.
3)计算回归截距.
4)最终得到目标直线.
根据凸包检测得到的凸包点集进行直线拟合,共拟合得到4 条直线分别对应图像中支座的4 条边,结果如图5 (d)所示.
1.2.4 剪切病害分级
通过计算拟合得到的不同直线间夹角即可得到支座的剪切角度.若拟合得到直线l1和l2斜率分别是k1、k2,夹角θ为
计算直线夹角时,取θ∈[0°, 90°]的角作为支座该位置的剪切角,并在4 个角中选取最大角作为该支座最终剪切程度判定依据.支座剪切病害程度评定标准如表1 所示.

表1 剪切病害程度评定标准Tab.1 Assessment criteria of shear damage degree
2 精度验证试验
2.1 分割精度实验
2.1.1 实验数据
从天津市周边以往桥梁检测留存的支座照片中共筛选880 张,包括但不限于支座前有碎石遮挡、轮廓不明显、底部被锈蚀钢板污染等图像,如图8 (a)所示.为了使训练的模型在后续的识别中有更好的准确性与实用性,首先使用Labelme 软件进行数据集制作,利用Create Polygons 工具对支座本身轮廓进行描点,区分支座前遮挡的碎石或者蜘蛛网等,如图8 (b)所示;然后将生成的json 文件转换为训练所用的标签,如图8 (c)所示.

图8 数据集制作Fig.8 Dataset production
由于数据集的大小能直接影响网络模型学习的效果,结合支座识别实际要求,利用Augmentor 工具选择其中的图像旋转180°、垂直或水平方向平移一段距离以及在修改亮度、颜色或者对比度三者中随机选取一种的方法来丰富数据量.增强过后的数据集中共有2 640 张照片,同时数据集按照7:2:1 划分为训练集、验证集和测试集.
2.1.2 实验环境
本文的实验模型在服务器中进行训练,利用Anaconda 软件建立虚拟环境,使用的语言为Python3.6.5 并基于PyTorch1.7.1 进行搭建,服务器操作系统为Windows 10 专业版64 位,处理器为Intel® Core™ i9-11900k CPU @ 3.50GHz.测试时利用CUDA 和CUDNN 来进行GPU 加速训练,所用GPU 为NVIDIA GeForce GTX 3070.
2.1.3 实验分析
为验证本文算法模型对支座的识别效果,利用测试集264 张支座照片对U-net 模型和融合深度可分离卷积与MAM 的FCN 模型结果进行对比.
对比结果如表2 所示,虽然在图像识别效率方面,改进的FCN 模型识别较快,但是在F1 值方面,本文算法较U-Net 高4.3%,较改进的FCN 高2.8%;在IoU 方面,本文算法较U-Net 高7.9%,较改进的FCN 高3.3%;测试集中的桥梁板式橡胶支座图像识别效果如图9 所示.
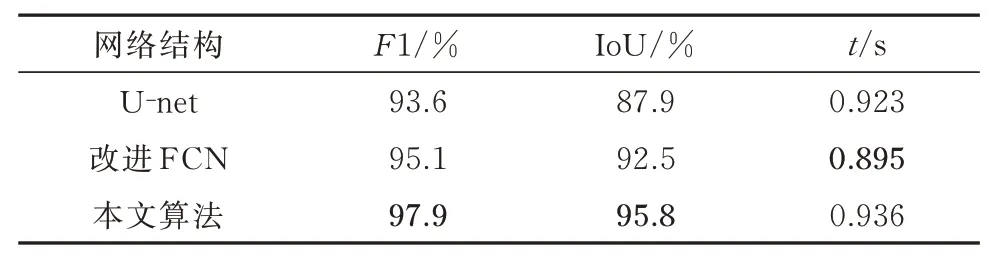
表2 不同模型数据统计Tab.2 Data statistics for different models

图9 支座部分特征提取效果对比Fig.9 Comparison of partial feature extraction effects of bearings
由图9 可知,本文算法对图像中的支座识别分割效果优于U-Net 和相同改进的FCN 模型,且当支座周边在被碎石等遮挡时,本文算法在支座边缘轮廓部分的识别上更加准确.
2.2 实桥试验
2.2.1 试验场地和图像采集
某分离立交桥位于天津市,结构如图10 (a)所示,桥梁总长60.0 m,总宽为18.0 m,共2 孔,跨径布置为2×30 m,上部结构为30.0 m 混凝土小箱梁和板式橡胶支座,支座规格为Φ275×60 mm,全桥共64 个支座.

图10 场地概况及人工测量工具Fig.10 Site overview and manual measurement tools
支座图像使用佳能80D 相机进行采集,拍摄时相机和被拍摄支座不需要控制距离,注意相机和支座水平竖直拍摄即可.考虑到圆形板式橡胶支座的特殊性,在对支座尤其是明显有剪切病害的支座拍照时,变换角度共拍摄3 张图像,最终同一支座以3 张图像中计算得到的最大角度作为其剪切病害程度的判定依据.
根据规范要求,对于支座的检测在目测的基础上要辅以必要的检测工具[1].考虑到支座位置的特殊性,人工现场使用思蜀邦护床头角度仪S20M 进行支座剪切角度测量,如图10 (b)所示.测量时只需将其直边贴在圆柱形支座母线即可读出剪切角度.图像采集作业如图10 (c)所示.
2.2.2 实验结果对比
编号原则为“跨-墩-梁-支座”,梁和支座号在图10 (a)中均从左到右、从上到下计数.
选取明显具有剪切病害支座,利用本文算法计算,可视化结果如图11 所示.根据拟合得到的直线计算夹角并同人工测量结果进行对比,结果如表3所示,两者得到的剪切角度基本一致,最大误差为1.3°,支座剪切病害分级基本相同,证明本文算法对板式橡胶支座健康状况的评估具有良好的可靠性.

表3 结果对比Tab.3 Comparison of results
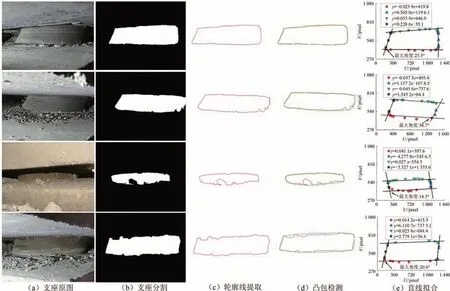
图11 支座剪切病害计算的可视化结果Fig.11 Visualization results for bearing shear damage calculations
3 结论
1)融合深度可分离卷积和MAM 的U-Net 模型,分割支座图像有效去除了碎石等杂物的干扰,测试F1 值和交并比均在95%以上,在F1 值方面,本文算法较U-Net 高4.3%,较同样改进的FCN 模型高2.8%;在交并比方面,本文算法较U-Net 高7.9%,较同样改进的FCN 模型高3.3%.
2)构建基于轮廓线提取、凸包检测和直线拟合等算法的支座剪切角度自动测量程序.在天津市某桥梁进行的实桥验证中,本文方法计算角度和剪切病害分级结果与传统人工测量结果一致,证明本文方法对支座剪切病害评估具有良好的可靠性.
数据量的大小会影响模型的整体性能表现.由于支座位置深入,图像采集较为困难,本文所构建数据集中支座图像较少,后续还需通过不断进行桥梁检测积攒支座照片并进行模型训练,提高模型分割的准确率和鲁棒性.
