面向铁路周界防护的多源图像目标检测研究综述
2023-12-30余祖俊周杏芳郭保青白丁元
余祖俊, 周杏芳 , 郭保青, 白丁元
(北京交通大学a.机械与电子控制工程学院,b.智慧高铁系统前沿科学中心,北京 100044)
随着我国铁路建设规模的不断扩大,列车时速不断提高,铁路沿线环境安全问题日益凸显.根据国家铁路局发布的《2019 年铁路安全情况公告》[1],行人非法上道仍是铁路交通事故造成人员伤亡的主要原因,公铁交汇区段机动车肇事撞击铁路桥梁、侵入线路等影响铁路运行安全的问题时有发生,因此加强铁路周界安全防护十分必要.
铁路周界安全主要防范对象是人员、动物等非法侵入铁路限界的事件和行为,为此,我国铁路线路已建有铁路综合视频监控系统,并且随着深度学习的飞速发展,铁路综合视频监控系统已具备初步视频分析和自动识别入侵行为及事件的能力.针对恶劣天气条件、夜晚及光线较差情况下误报率高检出率低的问题,以及小目标检测、多场景适应性及实时性等难题,很多学者对基于视频图像的周界入侵检测算法进行了研究[2-5],但由于视频监控设备根据物体的光反射成像,在夜间低照度和恶劣天气情况下,图像成像质量差,即使应用深度学习算法,基于视频的周界入侵检测技术也无法完全克服光照和天气变化的影响.所以为实现全天候且有效的铁路周界安全防护,周界防护手段需从单一化、人员防护向组合化、技术防护转变.
近年来,基于雷达与视频图像协同的铁路周界入侵监测方法[6-8]、利用激光摄像机与红外热成像摄像机高精度联动开发的铁路安全视频监控和智能分析系统[9]、以振动光纤传感和视频相结合的复合型周界安全监测系统[10-11]等相关研究成果不断涌现,将视频图像与其他手段相结合,利用不同技术间的优势互补,精确识别周界入侵目标已然成为铁路周界防护研究的主流趋势.
在众多铁路周界防护手段组合中,红外热成像根据物体自身热辐射成像,其不受光线变化和恶劣天气的影响,在针对行人、动物等能自身产生热辐射的防范对象进行全天候监测方面具有天然优势,而视频监控可以获取目标清晰的纹理轮廓等细节信息,因此红外热成像与可见光视频监控组合既能够全天候有效工作,同时又能有效提高夜间及恶劣光线条件下目标检测的准确率、检出率和可靠性.与雷达和视频图像协同的方式相比,红外图像与可见光视频图像均是二维平面成像,可视化效果好,二者结合能够提升铁路监测场景的直观性和可理解性,便于进一步智能分析.
本文在分析现有铁路周界防护技术的基础上,以红外与可见光图像结合实现铁路周界防护的角度出发,从异源图像配准和目标检测的研究重难点、图像配准和目标检测的一般方法及流程、研究进展及铁路场景下的相关研究现状几方面进行了综述,最后对未来发展方向进行了展望.
1 铁路周界防护技术现状分析
目前铁路周界技术防护手段主要有振动光纤探测、电子围栏探测、对射探测、雷达探测、红外热成像、视频监控等[8,12-13],如表1 所示.任意单一技防手段都各有劣势,无法全天候工作,所以多种技防手段结合是实现铁路周界全天候防护的发展趋势.由于目前视频监控手段以直观性强、监测范围广、安装架设方便等优点被广泛应用,而将红外与可见光视频监控结合不仅可以实现远距离、全天候的目标检测,同时能提高检测结果在夜间等恶劣光线条件下的可视化效果,所以本文进一步研究铁路场景下基于红外与可见光图像的目标检测技术.

表1 铁路周界技术防护手段对比Tab.1 Comparison of technical protection measures for railway perimeter
2 铁路多源图像目标检测难点
面向铁路周界防护的多源图像目标检测目的是保证全天候条件下目标检测的准确性和实时性.多源图像目标检测首先需要确定红外与可见光图像目标间的映射关系,研究可以分为图像配准和目标检测2 个重点阶段.铁路周界防护具体应用场景为:红外相机负责检测运动目标,固定拍摄大场景;可见光相机负责实时跟踪定位目标的具体位置,拍摄场景随检测目标的大小和位置进行切换.因此在保证目标检测准确性和实时性的同时,设计快速有效的自动化配准算法非常必要,但该研究目前存在一定的难点与挑战.
2.1 红外与可见光图像配准的难点与挑战
与一般图像配准不同,铁路周界防护场景下的红外与可见光图像配准还要考虑异源图像特征不一、图像间较大几何变化以及场景纵深差异的问题.
1) 异源图像间的配准.
红外与可见光相机因成像原理及机制不同,图像间具有强度分布相关性小、特征信息表示不一致、图像分辨率大小有差异的特点,使得红外与可见光图像配准与单一的可见光图像配准相比更有挑战.
2) 较大几何变化的图像配准.
由于红外与可见光相机任务分工不同,红外相机拍摄大场景,可见光相机跟踪目标的具体位置.相机间位姿、视场不同,使得红外与可见光图像间存在较大的平移、旋转、缩放和尺度等几何变化,而目前具有几何不变性的特征检测算子多是基于可见光图像设计,对于异源图像还需要考虑其模态差异,不能直接适用.
3) 纵深差异下的图像配准.
铁路场景下相机监控区域基本沿着铁轨方向,在较近距离范围内,拍摄场景中存在的纵深差异不容忽视,该情况下图像间变换关系更为复杂,单一的参数模型无法适用.
2.2 红外目标检测及融合目标检测的难点与挑战
在目标检测阶段,由于红外热成像能够全天候探测,不受光线及天气变化的影响,因此以红外检测为主,或者将红外与可见光图像融合进行目标检测,是实现全天候目标检测可行的思路,但还需要解决一些难点问题.
1) 红外图像对比度和分辨率较低问题.
虽然红外相机能够捕捉夜间和恶劣光线条件下的目标,但是在白天,周围环境或其他物体的温度可能比行人或动物的目标温度更高,对比度低使得背景和关注的目标变得不易区分;而且受相机传感器器件发展水平限制,红外相机成像分辨率低,图像整体较为模糊,目标检测识别难度大.
2) 红外图像目标遮挡与小目标检测问题.
红外目标检测同样存在可见光目标检测面临的小目标、远距离目标以及目标遮挡等难题,加上红外图像本身缺乏对比度,目标缺少纹理细节等信息,使得这些难题更具挑战.
3) 多源图像融合目标检测的融合策略制定.
利用红外与可见光图像特征融合来提升目标检测性能是可行的,但如何实现不同模态间特征的充分融合,尽可能大地提升目标检测性能,是红外与可见光融合目标检测研究的一大趋势和挑战.
在保证算法准确性的基础上,还需要考虑算法的实时性、对不同场景的适应性和可靠性.此外,实际人员或动物入侵铁路周界的样本少,而且红外图像目标标注难度大,这些与深度学习算法效果相关的外在因素也是需要考虑的.
3 图像配准算法现状与分析
图像配准是将不同成像设备、不同条件下(拍摄位置、时间、角度、环境光照、气候变化)获取的两幅或多幅图像进行匹配的过程.面向铁路周界防护的红外与可见光图像配准其意义在于两点,一是将红外图像中检测到的目标通过求得的图像间几何变换模型参数直接映射到可见光图像中对应位置,二是配准好的红外与可见光图像可以用于后续的多源图像融合目标检测.
3.1 图像配准一般方法及流程
图像配准算法主要根据灰度信息、变换域和特征3 类信息实现配准[14-15],各类配准算法原理、特点及代表算法如表2 所示.

表2 图像配准算法分类汇总Tab.2 Classification and summary of image registration algorithms
由于红外与可见光图像配准除了要处理图像之间存在的平移、旋转、缩放、拉伸等几何变化,还要解决因不同光谱成像造成的灰度、梯度和结构差异,基于特征的图像配准算法更适用于红外与可见光图像配准,其配准流程一般包括特征提取、特征匹配和图像变换3 个步骤,如图1 所示.

图1 基于特征的图像配准流程Fig.1 Flowchart of feature-based image registration
3.1.1 特征提取
特征提取包括关键位置检测与特征描述两部分.关键位置检测关注的是图像中突出或独特的属性,比如角点、边缘、轮廓区域等;特征描述使用特征向量来描述该关键位置的邻域特性,通常考虑局部邻域的边缘方向、强度和尺度信息等.在特征提取阶段,点特征、直线特征和区域特征应用最为普遍.
最具代表性的点特征提取算子是尺度不变特征变换算子(Scale-Invariant Feature Transform,SIFT)[16],对尺度、光照和旋转变化具有强鲁棒性.后来随着配准需求的增加,诞生了加速稳健特征算子(Speeded-Up Robust Features, SURF)[17]、基于主成分分析的尺度不变特征变换算子(Principal Component Analysis-SIFT, PCA-SIFT)[18],以及具有更快特征检测速度的基于加速分割测试的特征算子(Features from Accelerated Segment Test,FAST)[19]和面向FAST 的旋转二进制鲁棒独立初等特征算子(Oriented FAST and Rotated Binary robust independent elementary features, ORB)[20].但上述点特征算子是为具有线性强度变化的可见光图像设计,而可见光和红外图像间存在非线性强度变化,图像间特征点的表示与描述有差异,所以对于红外与可见光图像配准需要进一步改进与优化.
典型的传统直线提取算法有霍夫变换(Hough Tranform)[21]、线段检测器(Line Segment Detector,LSD)[22].Hough 变换在直线特征明显的情况下检测效果良好,具有很好的抗噪性,但是计算量大;LSD是一种“感知聚类”方法,其精度、算法复杂度要优于Hough 变换.但是这类传统的直线特征提取方法调参比较费时、缺乏鲁棒性,基于深度学习的直线特征提取网络方法后来居上,如直线检测网络线框图(Wireframe)[23]、面向直线的卷积神经网络(Line-Convolutional Neural Network, LCNN)[24]、基于三点的线段检测器(Tri-Points based Line Segment Detector, TP-LSD)[25]等方法,对直线的检测精度和鲁棒性提升显著.
常见的区域特征检测方法包括最大稳定极值区域特征算子(Maximally Stable Extremal Regions,MSER)[26]、基于边缘的区域检测器(Edge-Based Region detector, EBR)[27]和显著性区域算法[28].区域特征检测主要提取图像中均匀区域的范围和形状等信息,由于红外图像比可见光图像分辨率低、边缘更加模糊,图像间区域强度分布不一致,因此难以保证区域特征提取方法的稳定性.
3.1.2 特征匹配
寻找特征间的对应关系是对齐图像的关键.特征匹配一般是基于提取到的特征及特征描述子,利用相似性度量表征特征点间的匹配程度,通过搜索策略匹配图像特征点对.特征描述子的相似性度量通常定义为某种代价函数或者距离函数,浮点型描述子采用欧式距离,二进制描述子采用汉明距离.
最常用的特征匹配方法是暴力匹配和快速近似最近邻(Fast Library for Approximate Nearest Neighbors, FLANN)[29].暴力匹配遍历计算每一个待匹配特征与目标特征集合的相似度后返回相似度最高的项,算法原理简单但搜索效率低.FLANN 相比暴力匹配,在搜索策略上有所改进,先建立索引再进行搜索,索引方式包括线性索引、K 维二分查找树(K-Dimensional binary search Tree, KD-Tree)索引、K 均值索引等,搜索方式有搜索K 近邻和半径近邻,在特征数量较多的情况下,搜索效率更有优势.上述匹配方法虽然能获得足够多的匹配对,但同时掺杂着大量的误匹配情况.通常使用交叉验证或者利用先验知识进行匹配对筛选,以及用随机抽样一致性(Random Sample Consensus, RANSAC)[30]剔除误匹配对,获得精确匹配结果.
3.1.3 图像变换
图像变换包括模型变换参数估计和图像重采样.模型变换参数估计首先需要根据应用场景选择合适的变换模型,然后利用特征匹配结果估计模型变换参数.常见的图像变换模型从简单到复杂包括欧式变换、相似变换、仿射变换、投影变换以及非刚性变换.对于研究场景仅存在刚性运动的情况,当平面拍摄或者超远距离拍摄时,通常选用仿射变换或者投影变换这类单一的参数模型;而对于近距离场景无法忽视纵深差异的情况,多选择非刚性变换模型或者对单一的参数模型进行改进.
在完成模型变换参数估计后对图像进行变换及重采样.具体包括像素坐标变换和亮度插值,像素坐标变换是将输入图像像素映射到输出图像,然后在原图像中找到变换后像素的最佳匹配点,并利用邻域中点的亮度插值计算该点的亮度值作为变换后的亮度值.
3.2 红外与可见光图像配准研究进展
由于基于单一特征的图像配准算法无法满足铁路场景下红外与可见光图像配准在精度、效率、稳定性和泛化性等方面的要求,近年来相关研究多是针对特征及配准流程改进、利用深度学习算法辅助、基于目标模型优化迭代等方式来实现红外与可见光图像配准.
3.2.1 基于特征的改进图像配准
基于特征的改进图像配准算法大都是对特征提取、特征描述子构造以及整个配准框架进行调优.
在改进特征提取或特征描述子方面,文献[31]利用视觉显著性具有良好鲁棒性和不变性的特点,提出一种融合视觉显著性和SIFT 的红外与可见光图像配准方法,以提高红外和可见光图像之间配准的稳定性.文献[32]考虑到形态梯度可以同时突出可见光图像和红外图像的边缘,将形态梯度和联合尺度不变特征变换算子(Combined SIFT, C_SIFT)结合来实现可见光和红外图像的实时自适应配准.文献[33]设计一种基于剪切波的模态鲁棒描述子(Shearlet-based Modality Robust Descriptor, SMRD),以克服多模态图像间非线性强度变化对特征点匹配的影响.上述改进在一定程度上提升了红外与可见光图像配准的精度.
在优化整体配准框架方面,文献[34]提出改进的SURF 算法(Modified-SURF, M-SURF),优化特征提取后,引入匹配点的空间关系和加强图变换匹配(Weighted Graph Transformation Matching,WGTM)来消除错误匹配.为实现不同视场角、不同分辨率下的红外与可见光图像准确匹配,文献[35]提出一种尺度不变的部分强度不变特征描述子(Scale Invariant-Partial Intensity Invariant Feature Descriptor, SI-PIIFD)和强鲁棒性的特征匹配方法,采用Harris 角点检测提取特征点,利用SI-PIIFD对特征点进行描述,在特征匹配后引入鲁棒贝叶斯框架来保证图像变换模型的准确估计.文献[36]提出一种基于多尺度Harris 部分强度不变特征(Multi Scale-Harries-PIIFD, MS-Harris-PIIFD)的图像配准框架,构建了一种新的多尺度部分强度不变特征描述符(Multi-Scale PIIFD, MS-PIIFD).文献[37]针对红外与可见光图像配准时间长等问题,提出一种改进曲率尺度空间角点检测(Curvature Scale Space, CSS)算法,引入Freeman 链码提高特征提取精度,利用SURF 算法获得特征描述子,并采用双边FLANN 匹配和RANSAC 获得正确的匹配点对.文献[38]提出一种基于轮廓角方向(Contour Angle Orientation, CAO)由粗到细的配准框架,也是利用CSS 提取轮廓中的特征点,将得到的各特征点轮廓角方向作为主方向,并改进SIFT 描述子进行特征点描述,然后进行双向匹配及由粗到细的精配准.以上优化整个配准框架的研究,在较大程度上提升了配准精度或速度.
3.2.2 基于深度学习的图像配准
近两年,利用深度学习方法实现红外与可见光图像配准的研究逐步兴起,其中,生成对抗网络因其可以实现跨域图像映射被频繁应用于多模态配准,利用卷积神经网络提取异源图像特征的相关方法也在同步探索.
生成对抗网络在红外与可见光图像配准研究中通常被用来生成可见光图像的伪红外图像.文献[39]设计一种利用生成对抗网络的两级Transformer 结构,包括一个域转换网络和一个几何变换模块,第一阶段将可见光图像转换为伪红外图像,第二阶段对伪红外和真实红外图像实现图像配准变换.文献[40]提出模态转换与鲁棒特征相结合的配准算法,得到生成对抗网络转换的伪红外图像后,利用传统基于特征的图像配准方式实现配准.文献[41]提出一种跨空间感知风格转换网络(Cross-modality Perceptual Style Transfer Network, CPSTN)来生成以可见光图像作为输入的伪红外图像,由于CPSTN具有良好的几何保存能力,生成的伪红外图像具有清晰的结构,更利于将交叉模态图像对齐转换为单模红外图像配准,同时还引入一个多层次重构配准网络(Multi-level Refinement Registration Network,MRRN)来预测失真和伪红外图像之间的位移矢量场,重建配准红外图像.上述方法一定程度上降低了异源图像配准的难度.
与生成伪红外图像的思路不同的是,文献[42]利用对抗性学习和单模态相似性度量解决了跨模态图像配准相似性度量的泛化性问题,提出一种具有几何不变性的图像转换网络来消除模态差异的影响,再使用空间对齐网络实现图像配准,该方法不受模态种类限制,适用于多种模态图像间的配准.基于此研究,文献[43]将该几何保持图像转换网络应用于红外与可见光图像配准,并进行了改进,提升了红外与可见光图像配准的精度.
除了生成对抗学习,基于卷积神经网络的红外与可见光图像配准也在创新探索阶段.文献[44]基于卷积神经网络提出一种梯度信息引导的图像配准网络(Gradient Guided Multispectral Image Registration using CNN, RegiNet),利用Sobel 算子获取可见光图像的梯度图像并与红外图像一同输入到RegiNet 网络,实现端到端配准.文献[45]利用卷积神经模型计算出图像间的局部匹配点对,然后利用移动直接线性变换(Moving Direct Linear Transformation,MDLT)估计图像间的局部单应性矩阵,实现红外与可见光图像配准.文献[46]通过卷积神经网络模型判断红外与可见光图像特征匹配的程度,并利用边缘结构信息和注意力模块来提高红外与可见光图像特征的匹配率.这些方法均在尝试利用卷积神经网络提取红外与可见光图像的共同特征,也取得了一定突破.
3.2.3 基于目标模型优化迭代的图像配准
上述基于特征的改进图像配准和基于深度学习的图像配准方法在一定程度上克服了红外与可见光图像的模态差异,取得了良好的配准效果,但是这些算法多针对特定的平面场景或较远距离目标,利用仿射变换或透视投影变换等相对简单的几何变换,难以适应景深差异较大的情况.为提高红外与可见光图像对场景的适应能力和泛化性,许多研究引入了非线性变换模型,并将红外与可见光图像特征点间的匹配问题转化为目标函数模型优化问题,估计变换模型最优参数的同时输出最佳的特征点对匹配关系.
文献[47]提出了基于混合特征的红外与可见光图像非刚性配准算法,利用多特征辅助高斯混合模型对轮廓点和角点混合的特征点集进行建模,使用期望最大化算法求解模型,由于采用了非刚性变换模型,该算法在室内和室外近距离非平面场景拍摄存在较大视差的场景下均实现了良好配准.为克服场景景深的多变性、红外与可见光图像的差异性,文献[48]提出了自适应增强仿射变换(Adaptive Enhanced Affine Transformation, AEAT)方法,将仿射模型从线性情况推广到非线性情况.首先从红外和可见光图像的边缘图中提取特征点集,并设计高斯加权形状上下文特征描述符(Gaussian Weighted Shape Context, GWSC)来测量多模态图像之间的结构相似性,然后通过分段优化策略,估计出AEAT 模态的最优参数实现全局图像配准.与之类似,文献[49]提出的自适应混合多项式变换(Adaptive Polynomial Mixture Transformation,APMT),可以准确地描述待配准红外与可见光图像之间形变的全局非线性规律.上述方法在不同的场景下具有较好的全局配准鲁棒性和泛化性.
3.3 铁路场景下红外与可见光图像配准研究现状
铁路周界防护应用场景下的红外与可见光图像配准问题,在工程实际中通常采用相机联动方式,预先对大场景图像划分网格,然后人工操作可见光相机记录相应的俯仰旋转等姿态角度并制作成表,再通过查表控制可见光相机来保证联动过程中匹配到大致准确的范围以及联动效率.但是该方式下目标联动准确性依赖于网格划分的精细程度,而且变换场景后需要再次进行网格划分,前期需要投入较大的人力成本,自动化程度低,而且不能实现目标的精确关联与匹配,还需要人工做二次判断.
文献[11]利用激光摄像机与红外热成像摄像机联动开发了一款全天候工作的铁路安全视频监控和智能分析系统,通过相机空间位置匹配标定解算算法,将目标在红外视频画面中的相对位置解算为激光摄像机的物理方位及镜头焦距参数,以此控制激光摄像机伺服系统响应来实现具体目标的识别确认.该套设计利用仿射变换模型实现空间位置对应,适合远距离大场景的监控,对于近距离或相机间位姿差异较大的情况难以适用.文献[50]提出了改进的SURF 算法,结合先验知识通过逐级匹配策略实现了铁路场景下不同视场的红外与可见光图像配准,但是该算法针对特定的铁路场景设计,缺少鲁棒性和泛化性,而且算法实时性有待考证.文献[51]利用铁路场景下钢轨明显的直线特征实现了可见光与红外图像配准,该算法对于直线特征明显的场景具有一定的鲁棒性,但由于采用的是单一的透视变换模型,对于近距离无法忽视场景纵深差异的情况,配准精度还有待提高.
目前铁路场景下红外与可见光图像配准的研究还不是很多,而且配准精度和速度有很大的提升空间.在铁路周界防护应用中随着目标在图像中的位置和距离不同,可见光图像和红外图像存在一定的景深变化,而且可见光图像场景可能只是红外图像场景的一部分,所以为提高配准的稳定性和可靠性,可以依赖铁路场景中钢轨、立杆等显著的直线特征,并根据不同场景变化选择合适的图像变换模型,复杂情况下可以尝试泛化性较好的点集与模型迭代优化配准方法.
4 目标检测算法现状与分析
4.1 目标检测一般方法及流程
目标检测是利用多源图像实现铁路周界入侵检测的另一大研究重点.目标检测根据算法发展阶段来划分,主要分为早期目标检测算法和基于深度学习的目标检测算法.
4.1.1 早期目标检测算法
目标检测的目的是在视频图像中对感兴趣目标进行分类并标记出对应位置.早期的目标检测算法按照利用的特征信息分类,可以分为利用目标与背景差异性进行检测的方法和利用目标本身特征进行检测的方法.
利用目标与背景差异性进行检测的方法,包括经典的运动目标检测算法,如静态背景下应用的帧差法[52]、背景差分法[53-54]、光流法[55]、视觉背景提取器(Visual Background extractor,ViBe)算法[56]等,还有运动背景下应用的块匹配[57]和光流估计方法[58],该类方法不关注目标类别.
利用目标本身特征进行检测的方法,早期几乎都是手工设计特征,主要包括方向梯度直方图(Histogram of Oriented Gradient, HOG)特征[59]、Haar 特征[60]、局部二值模式(Local Binary Pattern,LBP)特征[61]等.该方法包括区域选择、特征提取、分类器分类3 个步骤.
步骤1:区域选择.采用滑动窗口策略,提取图像不同大小的滑动窗口作为目标检测候选区域.
步骤2:特征提取.对候选区域提取梯度方向、灰度变化、纹理细节等视觉特征.
步骤3:分类器分类.将提取到的特征送入训练完成的分类器进行分类,分类器通常采用支持向量机(Support Vector Machines, SVM)模型[62],自适应增强学习(Adaptive Boosting, AdaBoost)[63]、可变形部件模型(Deformable Parts Model, DPM)[64]、随机森林(Random Forest classifier, RF)模型[65]等.
但是该方法存在2 个问题:一是滑动窗口数量和大小的选取缺少针对性的设计,会产生较多冗余的窗口,降低算法效率;二是手动设计的特征对于多目标检测、复杂背景以及远距离等场景缺乏鲁棒性.DPM 模型虽然在HOG 结合SVM 方法的基础上进行了改进并实现了性能提升,但模型算法复杂度较高,目标检测的实时性较差.
4.1.2 基于深度学习的目标检测算法
现在主流的目标检测算法多基于深度学习实现,利用卷积神经网络学习自动提取特征.根据检测算法处理阶段的不同,可以分为两阶段和单阶段算法,分别对应的处理流程如图2 所示.
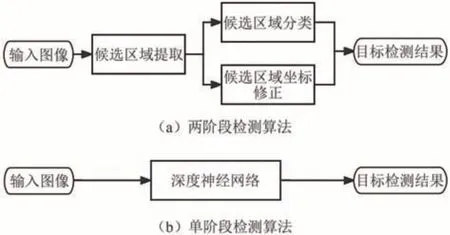
图2 深度学习主流目标检测算法流程Fig.2 Flowchart of mainstream object detection algorithms based on deep learning
两阶段算法包括候选框提取和目标分类.第一步在特征提取后会生成一个有可能包含待检测物体的候选区域,第二步通过卷积神经网络对候选区域进行分类和定位回归.常见的两阶段算法有区域卷积神经网络(Region-based CNN, RCNN)[66]、空间金字塔池化网络(Spatial Pyramid Pooling Networks, SPP-Net)[67]、快速区域卷积神经网络(Fast RCNN)[68]、更快区域卷积神经网络(Faster RCNN)[69]等,此类算法以准确率高为特点.
单阶段算法不用生成候选区域,而是通过端到端的网络提取特征并预测目标分类和位置,即在特征提取后直接分类加定位.常见的单阶段算法有单发多框检测(Single Shot multibox Detector,SSD[70]、一次性检测(You Only Look Once,YOLO)系列的YOLOv3[71]、YOLOv5[72]等.此类算法以计算速率快为特点.
上述主流的目标检测算法都将目标检测问题建模成对一些候选区域进行分类和回归的任务.在单阶段检测算法中,这些候选区域就是通过滑窗方式产生的锚框;在两阶段检测算法中,候选区域是由区域提议网络(Region Proposal Network, RPN)生成的,但是RPN 本身仍然是对滑窗方式产生的锚框进行分类和回归.这些基于锚框的检测器存在一些缺点:一是检测性能对锚框的大小、长宽比和数量都很敏感,对最终预测结果有较明显的影响;二是预置的锚框大小、比例在检测差异较大的物体时不够灵活;三是大量的锚框会导致运算复杂度增大,产生较多的参数.
考虑到上述存在的问题,无锚框的目标检测算法在近几年大量涌现,如基于角点的检测网络(CornerNet)[73],基于中心点的检测网络(CenterNet)[74]、基于极值点的检测网络(ExtremeNet)[75]等,这类方法不需要预设锚框,只需要对不同尺度特征图的目标中心点和宽高进行回归,极大减少了耗时和需要的算力,在检测速度上具有优势,但是在精度上还不能和最先进的基于锚框算法相媲美.
4.2 红外目标检测研究进展
考虑到目前单独依靠可见光图像实现目标检测的算法在夜间或恶劣光线条件下的效果并不理想,而红外相机无论白天还是夜间都能捕捉到比周围环境温度更高的目标,理论上更适用于全天候目标检测,所以在铁路场景下以红外图像目标检测为主.
早期的红外视频序列运动目标检测多采用帧差法[76]、背景差分法[77-78]、高斯混合模型[79]、ViBe[80]等传统算法,这类算法利用图像帧之间像素点的灰度变化来分离出前景目标和背景区域,原理简单,但当背景有异动、目标停留或者相机抖动时,其检测效果参差不齐,难以应用到实际场景中.
近年来由于深度学习技术在目标检测领域发展飞速,红外目标检测研究也逐步转向深度学习.与通用深度学习目标检测算法相比,基于深度学习的红外目标检测优化改进主要集中于优化骨干网络、引入注意力机制、结合生成对抗网络的设计,同时与多尺度融合、损失函数优化等细节相结合.
4.2.1 优化骨干网络的红外目标检测
基于深度学习的目标检测算法都需要骨干网络作为目标的特征提取器,为提升红外目标检测的精度、效率和鲁棒性,以及小目标检测效果,有相关研究对骨干网络进行了调整改进.
文献[81]提出了一种基于卷积神经网络的红外与可见光图像目标检测网络(Thermal Infrared image object detection based on CNN, TIRNet),采用深度卷积神经网络模型VGG 作为轻量级特征提取器,为得到精确的盒回归和分类的鲁棒性和鉴别特征,引入残差分支,同时提出连续信息融合策略来解决背景复杂、遮挡等问题,提升了红外图像目标检测的效率和鲁棒性.文献[82]对YOLOv3 网络模型进行了优化,使用轻量级网络MobileNetv2 取代YOLOv3 中传统的特征提取模块,用焦点损失代替YOLOv3 网络中的原始损失函数来解决负样本的数量不平衡问题,降低网络模型大小的同时提高了红外目标检测的速度. 文献[83]设计了一种以YOLOv5 为核心的改进红外目标检测网络(Improved YOLOv5 for Infrared image object detection,YOLO-FIRI),特征提取网络部分,对浅层的跨阶段部分连接(Cross Stage Partial connections, CSP)模块进行扩展和迭代以最大限度地利用浅层特征,并且在残差块中引入改进的注意力模块以聚焦对象和抑制背景,同时增加多尺度检测以提高小目标检测精度,改善了红外目标检测因长距离、弱对比度和低分辨率导致的低识别率和高误报率问题.
4.2.2 引入注意力机制的红外目标检测
针对红外因图像模糊、分辨率低、对比度低导致目标特征不明显以及远距离小目标检测的问题,引入注意力机制可以聚焦目标特征等关键信息,降低背景的关注度,同时提高模型效率.
文献[84]提出了基于注意力机制的多尺度红外目标检测算法,引入注意力机制提升对红外图像的特征提取能力,通过多尺度模块不同尺度的特征图获取来提高小目标检测效果.文献[85]提出了基于聚焦和注意力机制的YOLO 模型,通过在训练过程中使用负样本聚焦机制,减轻复杂的背景信息和遮挡的影响,从而使模型更准确地区分目标和背景,此外为增强红外小目标的特征,在YOLOv4 模型添加了扩展的卷积注意力模块,该方法对目标遮挡及小目标检测性能有较大的提升.文献[86]针对红外图像因对比度低、缺乏细粒度和纹理信息而影响目标检测性能的问题,提出了2 种轻量级注意机制,即切片拼接和多感受野空间组增强模块(Sliced Concatenate and Multi Receptive-field Spatial Group-wise Enhance module, SCMR-SGE)和联合注意力模块.SCMR-SGE 模块利用分组特征操作,通过在每个语义组的各个位置生成注意因子来增强子特征,并抑制不相关信息;联合注意力模块通过不同的池化层产生的注意因子,选择性地增强或抑制信道信息,然后将这2 种模块嵌入到特征金字塔网络(Feature Pyramid Network, FPN)中.与主流的注意力模块(Squeeze-and-Excitation,SE)、基于卷积神经网络的注意力机制(Convolutional Block Attention Module,CBAM)相比,该轻量级注意机制可以更加有效地提高红外目标的检测性能.
4.2.3 结合生成对抗网络的红外目标检测
生成对抗网络包括生成模块和判别模块,通过2 个模块间的互相博弈学习产生最终输出.在红外目标检测任务中,由于红外图像存在标注数据稀缺、收集困难,以及图像模糊、对比度低等问题,生成对抗网络最常用于图像增强和提高图像分辨率.
文献[87]为提高环境可解释性并解决红外图像目标样本标注困难问题,提出一种基于自上而下注意力机制和梯度对齐的生成对抗网络(Top-down attention and gradient alignment based Generative Adversarial Network, PearlGAN),利用自上而下的引导注意力模块和相应的注意力损失函数,来减少转换过程中的语义编码歧义和几何失真,引入结构化的梯度对齐损失以改进伪模态图像和原始图像之间的边缘一致性.该算法在模态转换任务中表现优异,而且在目标检测任务中能够更好地保留行人结构.文献[88]提出一种无监督图像生成增强自适应方法,包括基于循环生成对抗网络(CycleGAN)的图像到图像转换和强度反转变换.首先将生成的伪红外图像作为更新的源域,然后利用域自适应更快的RCNN 来减少生成的中间域和红外目标域之间的差距,该方法对于缺乏标注数据的红外目标检测具有一定的有效性和优越性.文献[89]提出一种用于将可见光图像转换为红外图像的域自适应框架,该框架使用基于生成对抗网络的多风格迁移网络将曲率和边缘等低级特征从可见光谱域转移到红外域,从头开始对多风格转换后的图像进行训练,提高了红外目标检测的鲁棒性.文献[90]针对红外图像模糊的问题,提出一种用于红外图像重建的去模糊-超分辨率重建生成对抗网络(Super-Resolution Reconstruction GAN, SRRGAN)算法和用于红外目标检测的加权掩膜区域卷积神经网络(Mask RCNN)方法,红外图像恢复和目标检测均取得了不错的效果.
4.3 红外与可见光图像融合目标检测研究进展
在全天候目标检测任务中,由于红外图像和可见光图像的特征具有互补性,将红外与可见光图像融合有助于增强目标检测算法的鲁棒性,提升夜间目标检测的准确率,甚至增强目标检测结果的可视性.根据融合策略的不同,目前利用红外与可见光图像融合来进行目标检测的研究可以大致分为基于通用融合策略的融合目标检测、结合模态特性的融合目标检测2 类.
4.3.1 基于通用融合策略的融合目标检测
红外与可见光图像的通用融合策略可以分为像素级融合、特征级融合与决策级融合.文献[91]提出了早期融合和晚期融合2 种模型融合方式,其中早期融合也是像素级融合,即直接将像素级的红外与可见光图像通道信息叠加输入到模型中进行特征提取和目标检测,晚期融合对应于特征级融合,使用单独的特征提取分支分别对红外与可见光图像进行特征提取,最后用全连接层将特征组合再输入到检测器中.文献[92]采用像素级融合、特征级融合以及决策级融合策略,并引入早期、中期、晚期融合和置信度融合4 种不同的网络融合方法用于多光谱行人检测任务.文献[93]为解决红外和可见光图像中小目标检测难的问题,提出一种基于中心和尺度预测网络(Center and Scale Prediction Network,CSPNet)的红外与可见光融合方法,采用特征级融合策略,将红外与可见光特征提取模块的3 个深层卷积层进行特征融合,再输送到无锚框的目标检测器.该算法对小目标有较好的检测性能,而且检测效率很高.文献[94]为提取红外与可见光图像的互补特征,利用2 个卷积神经网络分别从多个卷积层中提取红外图像和可见光图像的多尺度特征,并利用Kullback-Leibler 散度定义差异最大损失函数来进一步指导2 个网络的学习方向,以提取更多的互补和多样化特征,然后通过通道连接分别将每个阶段的红外特征和可见特征进行组合.此外还设计了一个聚焦特征增强模块并在深层卷积层添加了级联语义扩展模块,分别提高了小目标和大目标的检测精度.上述融合检测方法虽然取得了一定效果,但是融合策略通用化、模式化,没有充分考虑红外与可见光图像的特质,理论上在性能方面还能有更大的提升和突破.
4.3.2 结合模态特性的融合目标检测
与基于通用融合策略的融合目标检测方法不同,结合模态特性的融合目标检测相关研究深入探讨了红外与可见光图像的模态差异、照明条件变化以及红外图像的温度特性,设计了较为充分的特征融合方法,并取得了理想的效果.文献[95]发现白天和夜间光照条件的差异以及目标在红外与可见光图像中特征表示不一致会影响目标检测的性能,为此提出了一种模态平衡网络,首先在特征提取阶段嵌入差分模态感知融合模块来融合红外与可见光模态信息,然后在进入提取锚框阶段之前引入光照机制解决光照模态不平衡的问题,在提取锚框后进行2 种模态特征的自适应对齐.该网络检测效果突出并且检测速度也很快.文献[96]考虑了照明条件、不同数据源以及红外图像的温度特性对目标检测结果的影响,首先利用FLIR 红外与可见光数据集训练光照条件分类模型,然后提出通道注意和先验温度掩模模块(the Channel Attention and a Priori Temperature Mask module, CAPTM),利用温度信息作为先验知识,采用2 个嵌入CAPTM 的分支网络分别提取可见光图像和红外图像的特征,再根据分类结果融合特征输入特征金字塔网络,最后输入预测器得到目标检测结果.该方法较大提升了在夜间及其他弱光照条件下的目标检测精度.文献[97]考虑到红外与可见光图像隐含互补信息的模态差异对于融合和后续检测任务的重要性,针对融合与检测联合问题提出了一个两层优化模型,并将其展开到目标感知双对抗学习(Target-aware Dual Adversarial Learning network,TarDAL)融合网络和目标检测网络.融合网络通过生成器和双鉴别器,从差异中学习的同时寻求共同点,保留了来自红外的目标结构信息和来自可见光的纹理细节.该算法既提高了目标检测精度,也增强了检测结果的可视性效果.
4.4 铁路场景下多源图像目标检测研究现状
铁路场景下利用红外与可见光图像实现全天候目标检测的研究还处于探索阶段.文献[98]采用红外与可见光图像像素级融合的方式实现铁路异物目标检测,在完成图像配准的基础上,基于总变差和Contourlet 变换结合的融合策略实现图像像素级融合,然后利用背景差分和帧差法结合的目标检测算法对融合视频图像序列实现运动目标检测,然而整个实现过程计算量较大、耗时较长.文献[99]基于改进ViBe 的目标增强算法对像素级加权融合的图像进行铁路异物入侵目标检测,提升了目标检测的鲁棒性和效率,同时为提升融合图像的质量和可理解性,利用相位一致性和非下采样轮廓波变换(Nonsubsampled Contourlet Transform, NSCT)实现了目标检测结果图像的融合后处理.该研究在一定程度上提升了配准和目标检测的效率,但是对于满足实时性要求还有一定差距.文献[100]为增强红外图像在夜间的目标检测性能,提出了一种基于CycleGAN 图像转换的数据增强策略.首先根据白天的铁路场景图像和夜间的非铁路场景图像生成合成图像,然后使用生成的合成样本训练SSD 目标检测模型,最后将训练好的SSD 模型用于夜间红外图像的目标检测,该数据增强策略和目标检测方法具有一定有效性.
当前不论是利用红外图像、还是利用红外和可见光图像融合来实现铁路周界入侵检测的研究都比较少,而且还不太成熟,距离实现全天候实时有效的目标检测还有很大差距.但是铁路场景下目标检测面临的都是领域内的共性问题,完全可以从当前红外目标检测、红外与可见光图像融合目标检测相关研究中学习到有用的研究思路、方法和手段.
5 铁路多源图像目标检测发展趋势
铁路周界防护场景下将红外与可见光图像相结合既能实现全天候有效地入侵目标检测,又能保证入侵目标的可视化效果,便于后续智能分析.基于红外与可见光图像配准和目标检测2 个关键任务,根据当前研究基础和相关技术发展现状,分析铁路场进行多源图像目标检测未来的发展趋势主要有以下3 个方面.
1) 充分利用铁路场景特有的直线特征实现红外与可见光图像配准.铁路场景下的钢轨和立柱等直线特征比较突出,而且通常出现在图像中的主要位置,所以以直线特征为主,结合其他特征信息或者是利用深度学习方法辅助实现铁路场景异源图像配准是未来的一大发展趋势.
2) 无锚框的目标检测方法与融合策略相结合实现铁路场景下的全天候目标检测.对同时注重实时性和准确性的应用场景,可以利用无锚框的目标检测算法检测速度快的特性来达到实时性要求;同时深入探索适合铁路场景全天候检测的多模态融合策略,能够从源头上辅助提升检测的准确性,这种结合方式值得尝试和探索.
3) 建立铁路场景红外与可见光数据集.当下绝大多数算法都是在公开数据集上进行算法性能测试和比较,由于目前缺少基于红外与可见光图像的铁路场景数据集,将算法直接迁移到铁路场景后效果并不理想.为实现铁路场景下的异源图像配准以及验证铁路周界入侵目标检测的效果,建立铁路场景红外与可见光数据集是必不可少的.
6 结论
本文在充分探讨现有铁路周界防护技术的基础上,研究了红外与可见光图像结合实现铁路入侵检测的问题.重点围绕图像配准和目标检测阶段,分别从异源图像配准、红外目标检测以及多源融合目标检测等方面进行了论述,研究结果表明,将多类特征信息结合实现异源图像配准、无锚框算法与深度融合策略结合实现多源目标检测、建立铁路场景下的红外与可见光图像数据集是今后的研究方向.考虑到远距离全天候目标可靠检测的应用需求,以及铁路场景下红外图像与可见光图像具有较大视场差异的实际情况,大视场差异和恶劣光线条件下的异源图像配准以及远距离小目标检测的实现具有一定复杂性,铁路场景下的多源图像目标检测研究还需要不断摸索改进.
