一种可学习的跨域鲁棒说话人识别方法
2023-12-28郑靓张友兵周奎付瑞
郑靓,张友兵,周奎,付瑞
(1.湖北汽车工业学院 汽车工程师学院,湖北 十堰 442002;2.内蒙古自治区能源局综合保障中心 考务科,内蒙古 呼和浩特 010000)
随着智能网联汽车的飞速发展,人们对车载环境下语音技术的开发利用提出了更高的要求,说话人识别技术逐渐应用于车载语音交互。目前说话人识别技术主要基于深度神经网络(deep neural network,DNN)[1],如Xu 等[2]提出了i-vector 技术,通过DNN 简化i-vector 的类内协方差,允许i-vector在更多场景中使用;Variani E等[3]提出了d-vector模型,引入嵌入式信息,适用于大规模说话人识别和说话人验证任务;Snyder D 等[4]提出了x-vector算法,较基于统计学的i-vector 算法有更好的识别性能,并衍生出了许多变体[5-6]。此后,基于卷积神经网络(convolutional neural network,CNN)[7]、循环神经网络(recurrent neural network,RNN)[8]等架构的说话人声学特征提取网络被逐步提出。此外,合理的声学特征提取器对说话人识别系统性能起着至关重要的作用。为提高系统在不同场景下的识别性能,研究者提出了声学特征提取器的不同改进方法。刘丽岩等[9]提出了逆梅尔频率倒谱系数特征;Dongre V等[10]进一步提出了线性频率倒谱系数(linear frequency cepstral coefficient,LFCC),与梅尔频率倒谱系数(Mel frequency cepstral cofficient,MFCC)组合可以创建更好的输入特征表示;童强等[11]提出了韵律特征是说话人识别中的有效特征,利用高层特征参数,结合高斯混合模型,来提高系统识别性能;Sadjadi 等[12]提出了均值希尔伯特包络系数,提高系统在嘈杂和混响条件下的鲁棒性。这些方法不同程度上提高了系统的性能,但都是通过固定参数或静态操作实现,存在跨域鲁棒性较差的问题。综上所述,文中结合深度神经网络优化声学特征提取器,以MFCC 为基线,引入每通道能量归 一 化 技 术(per-channel energy normalization,PCEN)[13],设 计 了 声 学 特 征 提 取 器Mel-fixed-PCENs 和Mel-learnable-PCENs,实验验证了文中方法可以在车载跨域场景下显著提高系统性能,不会降低域内条件的性能。
1 MFCC声学特征提取器
MFCC是经典的声学特征提取器,由一系列线性和非线性变换组成[14],这些变换最初由信号处理和人类听觉系统驱动。MFCC特征提取流程如下:1)将信号进行预加重、分帧和加汉明窗处理,然后进行短时傅里叶变换(STFT)得到其频谱;2)求频谱平方,即能量谱,将每个滤波频带内的能量进行叠加,第k个滤波器输出功率谱为
3)将每个滤波器的输出取对数,得到相应频带的对数功率谱,并进行反离散余弦变换(DCT),得到L个MFCC系数:
2 改进MFCC声学特征提取器
考虑到MFCC 取对数操作的奇异性会造成说话人识别系统跨域鲁棒性低的问题,文中设计了2个基于MFCC 改进的声学特征提取算法,如图1所示。初始处理部分,2 个特征提取算法与MFCC 特征提取算法步骤相同;后端处理阶段,在MFCC 的基础上引入PCEN,得到Mel-fixed-PCENs,在Melfixed-PCENs 的基础上,使用Learnable PCEN 替代PCEN,得 到Mel-learnable-PCENs。 Mel-fixed-PCENs 是参数固定的声学特征提取器,Mel-learnable-PCENs 是数据驱动、可学习的,适用于跨域场景的声学特征提取器。

图1 改进MFCC的特征提取流程
2.1 PCEN和Learnable PCEN
作为动态压缩技术,PCEN 主要解决对数压缩在零点处的奇异性问题,计算公式为
式中:t和f为时间帧数和频率通道数;E[t,f]为输入功率谱。Learnable PCEN 的计算公式为式(3),由自动增益控制(automatic gain control,AGC)和动态范围压缩(dynamic range compression, DRC)组成。自动增益控制为式(4)~(5),由平滑系数s 和指数α进行控制,其中ε取1×10-6,是为了防止分母为0。对自动增益控制功率谱进行动态范围压缩,得到PCEN的谱图,表示为
式中:δ为正偏置项;r为主要的控制参数。Melfixed-PCEN 中,PCEN的参数α取0.98、δ取2.0、r取0.5、s取0.025[15]。为进一步提高说话人识别系统的性能,用Learnable PCEN 替代PCEN,作为数字信号处理组件联合后端的神经网络一起学习,而不是依赖于固定参数的选择。Wang 等[15]将平滑系数设置为固定的超参数,α、δ和r由学习自适应获得。Mel-learnable-PCENs 中Learnable PCEN 的 所有参数都参与学习。
2.2 倒谱均值归一化
倒谱均值归一化(cepstral mean normalization,CMN)在降低附加环境噪声的影响方面有一定效果,是广泛应用的补偿技术。计算公式为
式中:μ[t,f]为具有滑动窗口长度为(N+1)的EPCEN平均值,N取300。
3 声纹建模与说话人识别系统
采用ECAPA-TDNN[16]进行声纹建模,基于传统的x-vector 架构进行改进,更加强调局部多尺度特征表达和全局多层次特征融合。整个ECAPATDNN 的网络结构如图2 所示:首先将声学特征提取器的输出进行1 层Conv1D+ReLU+BN(等同于1个TDNN 模块)处理;其次融合3 个SE-Res2Net 模块的输出特征映射,并送入ASP(attention statistics pooling)层块;最后接入全连接层调整维度,得到192 维说话人嵌入码。以ECAPA-TDNN 为声纹嵌入码提取器,余弦相似度作为后端相似度判别器,分别构建5 个以MFCC、LFCC、FBank、Mel-fixed-PCENs和Mel-learnable-PCENs 为声学特征提取器的说话人识别系统。
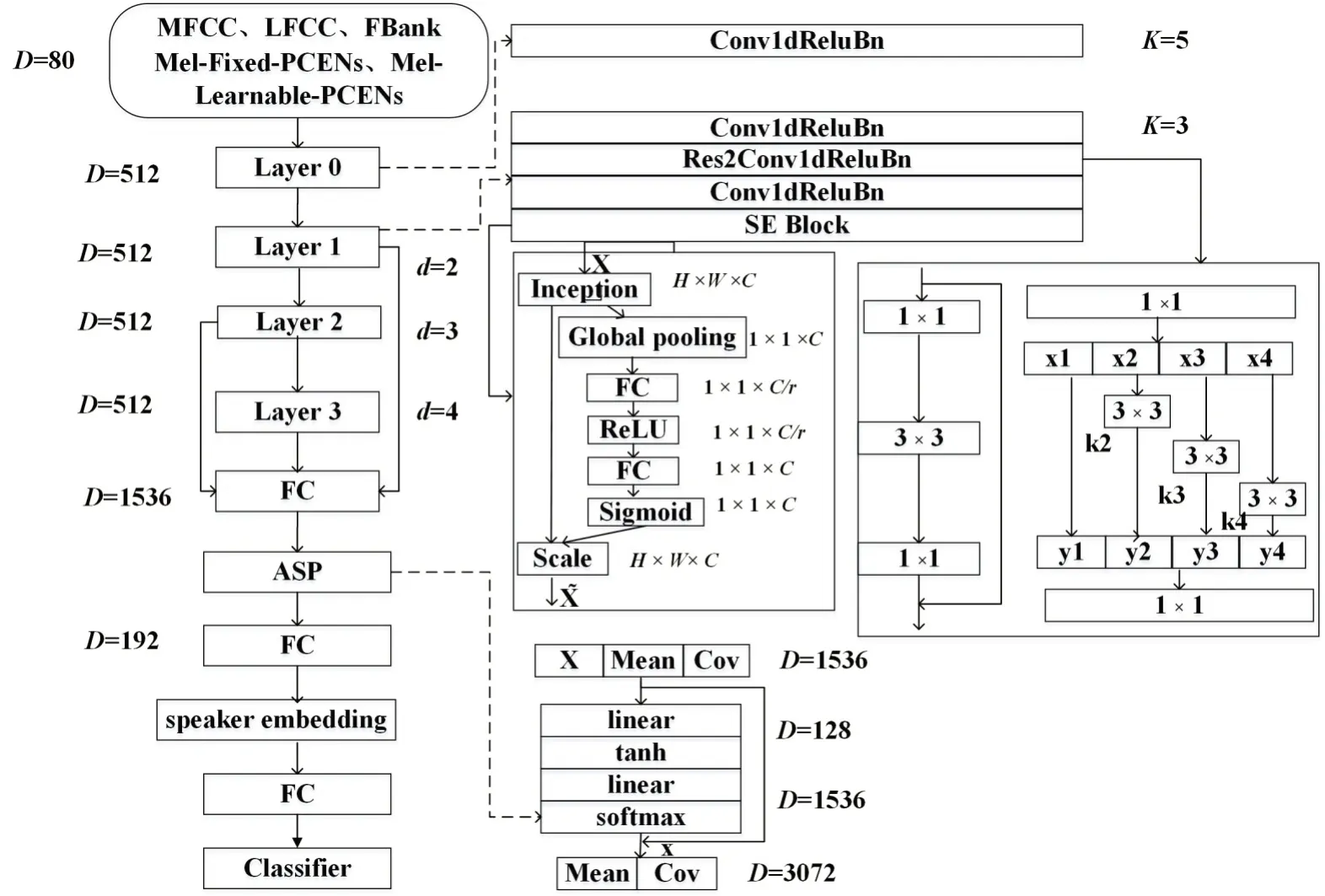
图2 ECAPA-TDNN网络结构图
4 实验配置与结果
采用VoxCeleb1-dev 数据集[17]进行训练,并在VoxCeleb-O 和VoxMovies[18]评估集上提取语音声纹嵌入码,对说话人识别系统进行评估,同时分析MFCC-SV、 LFCC-SV、 FBank-SV、 Mel-fixed-PCENs-SV 和Mel-learnable-PCENs-SV 在 域 内 和跨域场景下的性能。
4.1 数据集
1)网络训练 采用VoxCeleb1-dev训练ECAPTDNN 说话人嵌入码提取器,包含1211 个说话人,共148 642个wav文件(16k采样率)。使用MUSAN语料库[19]的多个声源(噪声、嘈杂声和音乐)模拟嘈杂的环境场景。
2)网络评估 采用VoxCeleb-O 作为测试集,表示域内场景(训练和评估数据集均来自采访视频),包含40个说话人、18 802个真实实验和18 809个假冒实验。使用最新的VoxMovies 语料库创建有趣的跨域说话人验证场景(训练数据集来自采访视频,评估数据集来自电影剪辑),并进行评估。VoxMovies 语料库有5 个不同的评估列表,统计数据汇总在表1 中,语音材料来源于采访视频(D-I)和电影剪辑(D-M)。其中,D-M(same)和D-M(diff)分别表示注册和测试文件来自同一部或不同的电影,说话人失配程度和确认难度从E-1增加到E-5。由于E-2、E-3、E-4与训练集有重合,所以只选择E-1和E-5作为说话人识别系统的评估列表。Pooled的评估列表是E-1和E-5的合集。
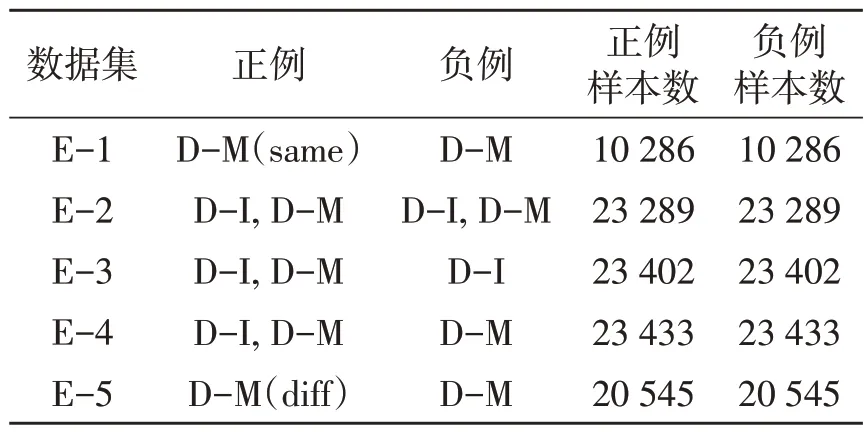
表1 VoxMovies评估集实验结果
4.2 超参数设置
所有实验中,随机截取数据集中每句话语,截取长度为3.015 s的固定片段。输入的声学特征维数均设置为80,窗长为25 ms,帧移为10 ms。PCEN模块固定参数值和Learnable PCEN参数初始值均设置为α取0.98、δ取2.0、r取0.5、s取0.025。以AAMSoftMax(m取0.2,s取30)为模型的后端分类器,用Adam优化器[20]进行训练,将batchsize设置为300,初始学习率设置为0.001。同时采用间隔学习率调整策略,设置步长为1,每轮学习率为
从ASP 池化层之后的第1 个全连接层中提取说话人嵌入码,最终输出512 维的说话人特征向量。通过计算等错误率(EEER)和最小检测代价函数(minDCF)来评估说话人识别系统的性能,设置风险系数为1.0。
4.3 实验结果
在域内和跨域2 个场景下,对基于5 个声学特征提取器构建的说话人识别系统进行对比实验。
1)VoxCeleb-O 评估集实验结果 在域内环境下的说话人识别系统性能评估结果如表2所示。在EEER方 面,Mel-learnable-PCENs-SV 与MFCCSV、LFCC-SV 和FBank-SV 相 比 分 别 降 低 了8.35%、5.73%、7.18%,Mel-fixed-PCENs-SV 较MFCC-SV、LFCC-SV和FBank-SV分别降低了7.59%、4.95%、6.41%,说明Learnable PCEN 为说话人识别系统提供了更优的性能;在minDCF 方面,Mellearnable-PCENs-SV 和Mel-fixed-PCENs-SV 的minDCF 均 比MFCC-SV、LFCC-SV 和FBank-SV小。当Pt为0.1 时,Mel-learnable-PCENs-SV 的minDCF 达 到 最 小;当Pt为0.01 和0.001 时,Melfixed-PCENs-SV 的minDCF 最小,原因是高维参数进行神经网络迭代训练时,不如固定参数稳定。

表2 VoxCeleb-O评估集不同SV系统性能
2)VoxMovies 评估集实验结果 在跨域场景下,VoxMovies 评估集上说话人识别系统性能评估如表3 所示。与VoxCeleb-O 数据集相比,VoxMovies 数据集具有域不匹配的特点。根据表1 可知,E-1 包含的域失配最少,E-5 包含的域失配最多,Pooled 是E-1 和E-5 的合集,因此E-5 具有较大的挑战性。在跨域场景下,Mel-fixed-PCENs-SV 和Mel-learnable-PCENs-SV 的性能相比MFCC 均有不同程度的改善。Mel-learnable-PCENs-SV 实现了在E-1、E-5 以及合并集Pooled 评估集上的最佳系统性能。
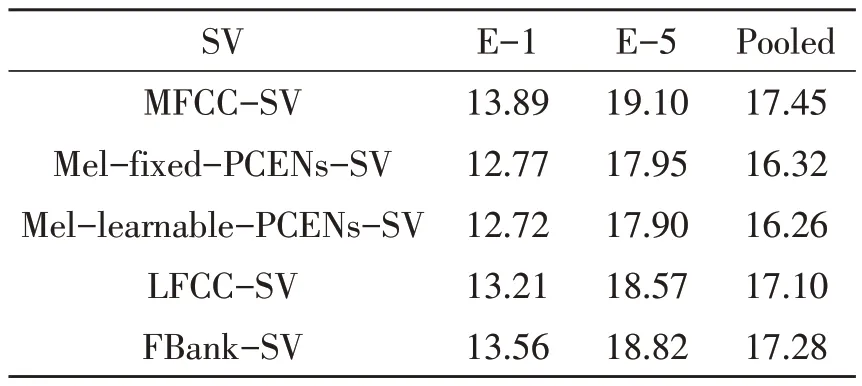
表3 VoxMovies评估集不同SV系统性能
3)DET 曲线分析 如图3 所示,在VoxCeleb-O 评估集(域内)和VoxMovies 的评估集指代E-1,E-5 和pooled(跨域)下,分析了含有不同声学特征提取器的说话人识别系统的性能。可以观察到,在域内以及跨域场景下,Mel-fixed-PCENs-SV 和Mel-learnable-PCENs-SV 系统性能均比MFCCSV、LFCC-SV 和Fbank-SV 性能更好。Mel- learnable-PCEN的系统性能最优,与表2~4中数据呈现的结果一致。

图3 评估集上不同SV系统的DET图
4.4 说话人识别系统验证
采用Sharing-VAN 2.0 为实验平台,麦克风安装在车门内外侧,如图4a 所示,将采用Mel-learnable-PCENs 声学特征提取器训练得到的说话人识别模型布署到车载硬件平台Jetson AGX Xavier上,如图4b所示。测试人员共10名,男女比例为1:1,分别在车外较安静的环境进行声纹录入,在车内多媒体、排风扇、发动机、氛围灯等开启状态下进行说话人识别验证。每人分别测试15 次,测试总次数为150 次。统计“未识别/识别错误”次数的情况,结果如表4所示,未识别次数为3次,识别错误次数为4 次,识别错误率为4.7%。因此,文中方法可以较好地满足车载跨域场景的说话人识别要求。

表4 Mel-learnable-PCENs-SV实验结果

图4 实验平台
5 结论
针对车载跨域场景说话人识别模型鲁棒性低的问题,提出了可学习的跨域鲁棒说话人识别方法。在传统MFCC基础上,引入Learnable PCEN 代替对数运算,联合ECAPA-TDNN 实现参数自动优化。在域内场景评估集VoxCeleb-O和跨域场景评估集VoxMovies 上进行了评估,Mel-learnable-PCENs-SV 相较MFCC-SV 的EEER分别有8.35%和8.42%的最大改进,并在Sharing-VAN 2.0 车载硬件平台Jetson AGX Xavier验证了该方法的有效性。这项工作可以在其他基于DNN 的模型上进行扩展,如在使用更大数据扩充的情况下,使用可学习的声学特征提取器与TDNN 或ResNet 网络进行联合优化学习。
