基于改进YOLOv5的小目标交通标志检测算法
2023-12-28徐鑫方凯
徐鑫,方凯
(湖北汽车工业学院 电气与信息工程学院,湖北 十堰 442002)
交通标志检测是高级驾驶辅助系统[1]和智能交通系统[2]的重要组成部分。常用的交通标志检测算法包括以Faster R-CNN[3]系列为代表的二阶段目标检测算法和以YOLO[4-5]系列、SSD[6]为代表的单阶段目标检测算法。在传统目标检测中,被检测对象通常占据整个图像较大区域,而实际驾驶环境中捕获的交通标志通常占据整个图像的很小区域,可提取的像素特征不足,检测难度大。针对小目标检测,学者通常采用增加目标检测层、引入注意力机制、改进损失函数等方法。江金洪等[7]在YOLOv3 中引入深度可分离卷积,在损失函数中用GIOU替换原始IOU,平均精度提升了6.6%,但检测速度仅为12FPS,不适用于实时检测。Wang等[8]在YOLOv4-Tiny 算法引入改进的K-Means 聚类算法并提出大规模特征图优化策略,小目标检测的均值平均精度为52.07%,虽然比YOLOv4-Tiny 算法提升了5.73%,但不满足实际驾驶环境检测精度要求。孟繁星等[9]以YOLOv5算法为基础加入通道注意力机制、增加小尺度检测层、使用蓝图可分离卷积替代主干网络的标准卷积,算法平均精度提高了4.7%,但速度有所降低。为了解决小目标交通标志检测精度低的问题,文中在YOLOv5 算法基础上,调整了主干网络下采样倍数,将MobileViT Block融合到颈部网络进行全局建模。采用离线增强方法对训练集进行扩充,同时采用Mosaic-9 在线增强方法进行训练。
1 YOLOv5算法与改进
1.1 YOLOv5算法
YOLOv5 算法结构主要由输入、主干网络、颈部网络、预测层组成。主干网络由Conv、C3、SPPF等模块组成,用于提取图片中的特征信息。根据网络深度倍数和宽度倍数的不同,YOLOv5算法由小到 大 分 为YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x。交通标志检测的实际应用需要同时考虑模型的实时性和准确性,YOLOv5s 模型的尺寸较小,计算推理速度快,部署起来更方便,所以选用YOLOv5s 版本作为改进模型,文中YOLOv5算法皆指YOLOv5s版本。
1.2 微小目标检测层
卷积神经网络进行特征提取时,随着卷积层数的增加,特征图的分辨率逐渐减小,感受野不断扩大,深层网络更倾向于关注全局信息,不利于对小目标的检测。相反,浅层网络的特征图大,细节特征丰富,感受野重叠区域比较小,携带更多的小目标信息,可以弥补深层网络的不足。YOLOv5算法的FPN和PAN结构中同时融合了主干网络的8倍、16倍、32倍特征图,背景以及噪声信息会覆盖小目标信息,导致检测精度较低。
文中采用1 个微小目标检测层替换YOLOv5算法的大目标检测层,降低主干网络下采样倍数为4 倍、8 倍、16 倍,一方面可以减少深层网络的背景和噪声信息,另一方面改进后FPN 和PAN 结构可以充分融合浅层网络信息,将更多浅层特征传递到深层特征,强化小目标特征。改进后的FPN 和PAN结构如图1所示。

图1 改进后FPN和PAN结构
1.3 MobileViT Block
MobileViT Block[10]的结构见图2,输入特征图的尺寸为W×H×C,其中W和H分别表示特征图的宽的高,C表示通道数。输入的特征图经过Conv模块、Transformer Block[11]和特征融合模块后,与原始特征图进行叠加,系统输出叠加后的特征图。

图2 MobileViT Block结构
具体操作流程:将输入张量X通过1 个n×n卷积进行局部特征建模,再将其通过1个1×1卷积映射到高维空间中得到张量XL,最后将XL展开成N个扁平化且互不重叠的Patch 得到XU。Patch 中的像素p输入Transformer Block,提取特征图的全局空间信息得到XG,然后将其折叠复原至XU,再通过1×1标准卷积复原回特征图XL,最后与X进行类似于shortcut拼接,使用n×n卷积做通道融合得到W×H×C特征图作为输出。其中:
式中:N为Patch个数;w和h为Patch宽度和高度。
卷积神经网络(convolutional neural networks,CNN)的归纳偏置可以很好地学习视觉表征信息,然而由于卷积核大小的限制,CNN 只能对特征局部建模,存在感受野有限的问题。MobileViT Block集成了卷积和Transformer Block,以卷积中局部建模为基础进行全局建模,同时具有CNN 和ViT 特性。将MobileViT Block融入微小目标检测层可以增加全局感受野,更好地表示小目标交通标志特征。
2 数据集
2.1 实验数据集
TT100K[12]数据集共有100 000张分辨率为2 048×2 048高清图像,包含了30 000个交通标志实例,覆盖国内5 个不同城市道路的真实交通场景。在TT100K数据集中筛选出道路上常见且实例个数大于100 的类别,共45 类交通标志,9 170 张图片,按照6∶2∶2 随机划分训练集、验证集和测试集,其中训练集5 503张,验证集1 833张,测试集1 834张。
2.2 数据增强
划分后的数据集存在不同种类交通标志的样本数量差异过大的问题,导致数量多的样本训练效果较好,而数量少的样本训练效果不佳。文中采用离线增强和在线增强相结合的方式进行样本训练来解决该问题。为了保证实验有效性,离线增强只对训练集的5 503张图片进行0.8~1.5倍随机缩放、长和宽的扭曲和随机色域变换处理,将不足500个的交通标志类别实例个数,扩充至500 个以上,离线增强后的训练集有13868 张图片。在线增强使用Mosaic-9数据增强方法,训练时随机选取9张图片进行随机裁剪、缩放,将处理后的图片随机分布后拼接成1张新的训练样本,增加样本背景信息的多样性,丰富了交通标志实例。
3 实验结果与分析
3.1 实验环境配置
实验训练和测试平台均使用Windows10 操作系统,硬件主机CPU为Intel Core i5-10500,显卡为NVIDIA GeForce GTX 3070,显存为8G,内存为32GB RAM+100GB Virtual Memory。深度学习框架为Python3.8.15、Pytorch1.10.0、TorchVision0.11.0、CUDA11.3、CuDNN8.2.0。
训练时使用YOLOv5默认低版本超参数配置,输入图像分辨率为640×640,初始学习率设置为0.01,使用余弦退火调整学习率,关闭Fliplr左右翻转增强,默认使用SGD 优化器,批量大小为16,迭代轮次为200次。
3.2 性能评估指标
文中采用精确率P、召回率R、mAP@0.5、FPS及参数量NP作为算法性能评估指标,相关表达式为
式中:TP为真正例;FP为假正例;TN为真反例;FN为假反例;PmA为mAP@0.5 的值;PA为平均精度值。FPS为画面每秒传输的帧数,用来衡量模型的检测速度,当FPS越大时,模型每秒处理的图像数越多,实时目标检测的最低要求是FPS需达到30。
3.3 改进算法消融实验结果分析
为了加速模型收敛,节约算力成本,实验前采用K-Means++聚类初始锚框,并使用WIoU 作为边界框损失函数。在TT100K 测试集上进行了消融实验,依次引入数据增强(data augmentation, DA)、微小目标检测层(tiny target detection layer,TTDL)和融合模块MobileViT Block 与原始YOLOv5 算法作对比,实验结果如表1 所示。实验方法中,D、T、M分别表示DA、TTDL、MobileViT Block方法。
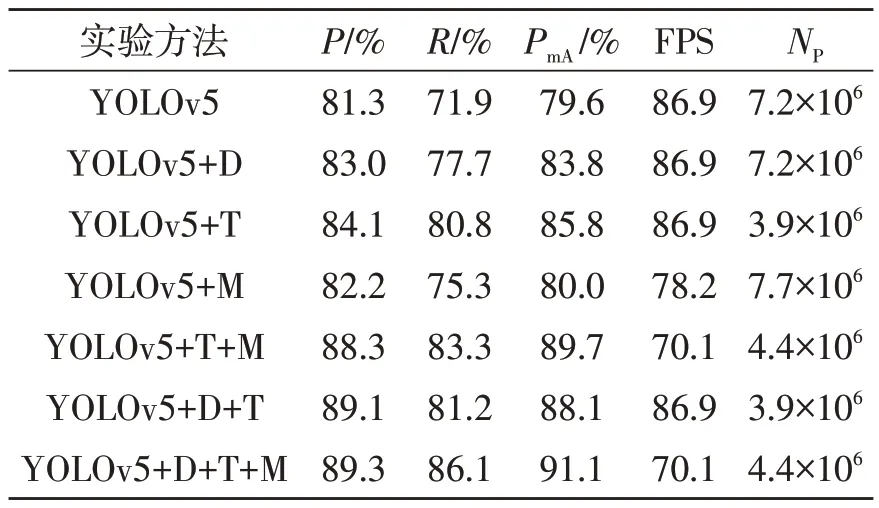
表1 消融实验结果
根据表1 可知,YOLOv5 算法的精确度为81.3%,召回率为71.9%,mAP@0.5为79.6%,表现一般。YOLOv5算法引入DA后,扩充了交通标志实例数量少的样本,训练效果变好,表明确保充足且均衡的训练样本能有效提升算法性能。YOLOv5 算法引入TTDL 后,精确度、召回率和mAP@0.5 都有提升,模型参数量降低到3.9×106,有效增强了算法对于小目标的特征提取能力。YOLOv5 算法引入MobileViT Block 后的检测效果一般,FPS 下降至78.2,模型参数量增加到7.7×106,整体提升不大。分析MobileViT Block原理可知,与8倍下采样的小目标检测层融合后,MobileViT Block会执行卷积下采样操作,进一步增大感受野,导致MobileViT Block 的全局感受野无法充分发挥作用,因此应将MobileViT Block与TTDL结合进行改进。YOLOv5+TTDL+MobileViT Block与YOLOv5+TTDL相比显著提升了模型的精确率和mAP@0.5,充分发挥了MobileViT Block 全局建模能力的优势。YOLOv5+DA+TTDL 的模型参数量最小,速度最快。YOLOv5+DA+TTDL+MobileViT Block 与YOLOv5 算法相比,精确率、召回率、mAP@0.5 分别提升了8%、14.2%、11.5%,模型参数量降低了39%,FPS虽然有下降幅度不大,但仍然超过了实时目标检测的最低要求,保证了交通标志检测的实时性。
在训练过程中,不同模型的mAP@0.5 变化曲线如图3a 所示,总损失变化曲线如图3b 所示。从图3 可以看出每项改进方法对模型的性能都有一定的提升,其中总损失是边界框回归损失、置信度损失以及类别损失之和。改进算法在mAP@0.5和总损失上都优于基础模型,其收敛速度快,损失曲线震荡波动小且更加平滑,训练效果更好。
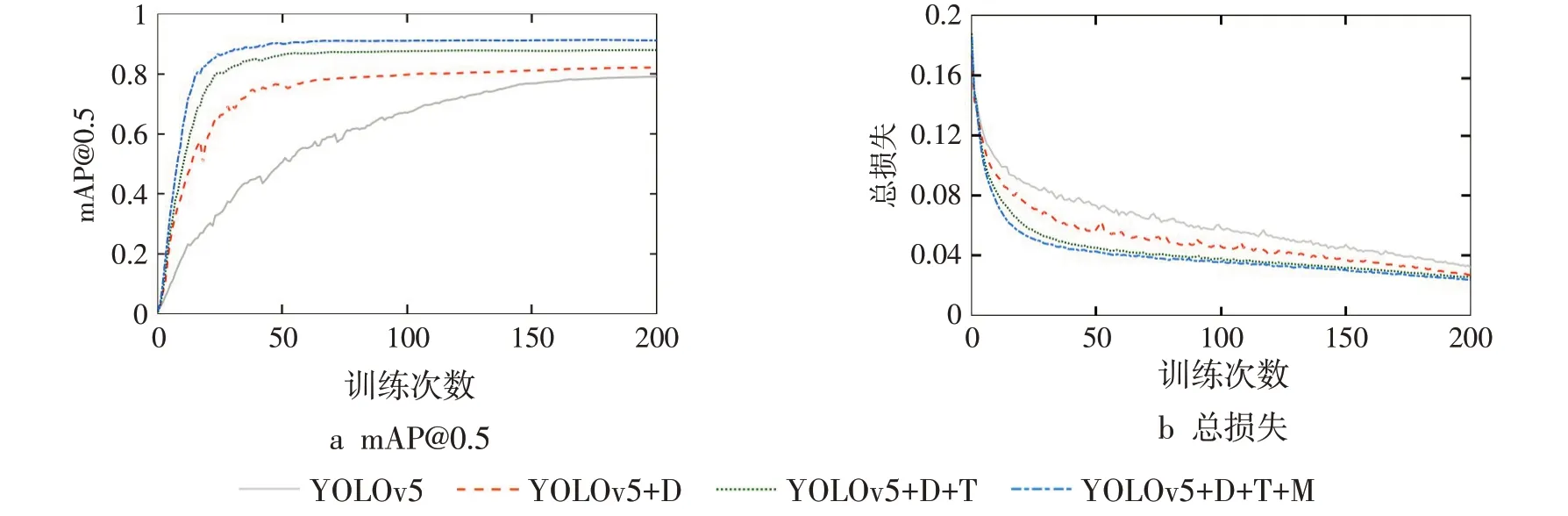
图3 训练时不同模型的mAP@0.5和总损失变化
3.4 改进算法与其他算法实验结果对比分析
为了进一步验证改进算法对于小目标交通标志检测的有效性,进行对比实验。按照MS COCO数据集[13]对小目标的定义在测试集的1 834张图片中提取出806张含有小目标交通标志的图片,图片中至少有1个或多个区域面积的分辨率小于32×32个像素点的交通标志。选取的对比算法为具有代表性的单阶段目标检测算法SSD、YOLOv3 以及最新提出的YOLOv7目标检测算法,测试时输入图像尺寸统一为640×640,实验结果如表2所示。
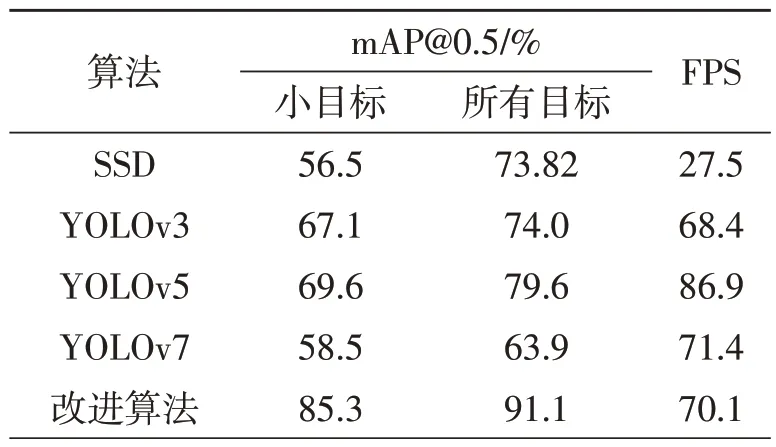
表2 不同算法检测性能实验结果
表2 中,SSD 算法在小目标交通标志上的检测精度为56.5%,FPS为27.5,没有达到实时目标检测的最低要求。YOLOv3 算法无论在精度和速度上都不如YOLOv5 算法,而YOLOv7 算法在小目标交通标志检测上也不如YOLOv5算法,检测效果表现一般,但检测速度上要略高于YOLOv3算法。改进算法在小目标和所有目标交通标志上的检测精度分别达到了85.3%和91.1%,检测速度虽然略低于YOLOv5和YOLOv7算法,但仍具有很好的实时性。
不同算法在小目标交通标志测试集上的部分检测结果如图4~6所示。从图4可以看出,当检测远距离小目标交通标志时,改进算法很好地检测出所有交通标志,其他算法均有漏检。图5中改进算法可准确地检测出被遮挡的交通标志,预测框也有较高的置信度分数。图6中SSD和YOLOv3算法均有漏检现象,YOLOv5算法有误检现象,YOLOv7算法和改进算法都检测出所有交通标志,但改进算法预测框的置信度得分更高,具有更好的检测效果。

图4 不同算法对远距离小目标的检测效果

图5 不同算法对被遮挡目标的检测效果

图6 不同算法对侧面目标的检测效果
4 结论
对YOLOv5算法进行改进,通过消融实验和检测效果对比实验,证明了改进算法可以提高小目标交通标志的检测精度,同时保证了交通标志检测的实时性。改进算法通过对主干网络结构的优化减少了模型参数量,但浮点运算量没有降低。模型训练和测试时只选取了常见的45类交通标志,没有覆盖所有类别的交通标志,接下来将从扩展其他不常见的交通标志类别及降低模型浮点运算量方面开展研究。
