基于LSTM的电池组工作状态预测
2023-12-28李轩谊赵慧勇
李轩谊,赵慧勇
(湖北汽车工业学院 汽车工程学院,湖北 十堰 442002)
电压、电流和SOC[1]是检测电池正常工作状态的关键技术参数,驾驶员行为影响车载电池的状态,造成有关参数波动。为提高电动汽车运行的安全性,准确监测车载动力电池的运行状态,结合驾驶行为进行多参数的电池组工作状态预测尤为重要[2-3]。目前对电池系统的预测主要采用模型或数据驱动的方法[4-5]。基于模型的方法易于解释和定性分析,通常很难根据环境改变电池模型,模型的准确性会降低。数据驱动技术则更加优化电池的建模过程,可以完全基于数据本身所包含的信息进行分析。近年来机器学习逐步发展,Tobar 等[6]提出的自适应多输入核滤波器表明,在电池电压演变方面,加入外部变量可以提高预测性能。对于电流引起的过热现象,Hong等[7]提出了基于熵的方法来预测电动汽车电池系统的热量释放。支持向量机[8]和前馈神经网络(FNN)[9]等机器学习方法用于SOC 预测。Hong 等[10]通过调研实际驾驶情况,提出了新的电压故障诊断与预警方法,但只考虑了1个影响因素,单一的监测指标难以全面反映电池组工作状态的变化[11]。为此,文中通过考虑驾驶员行为对电池工作状态的影响,定义了多参数LSTM预测模型,并验证了模型的优越性。
1 模型结构
1.1 LSTM长短期记忆神经网络
LSTM是循环神经网络RNN的变体形式,[12]采用遗忘门、输入门和输出门处理由于长期依赖导致梯度消失和梯度爆炸的现象,在时间序列预测领域有着广阔的应用。网络结构如图1所示,遗忘门用于决定上一时刻的单元状态有多少保留到当前状态;输入门处理并传递输入数据,单元状态从Ct-1更新到Ct;输出门最终生成输出并更新隐藏状态ht-1。
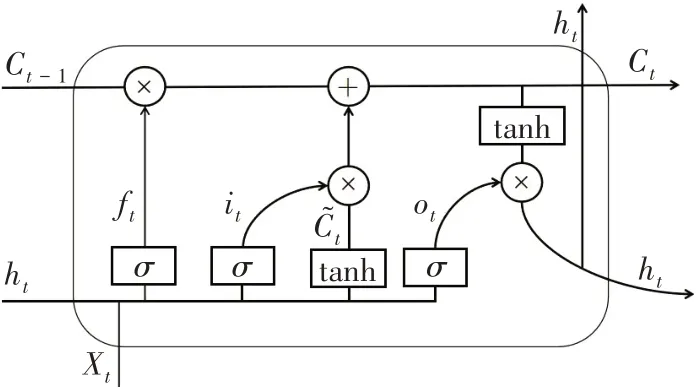
图1 LSTM模型的网络结构
式中:xt为t时刻神经元输入向量;ht为神经元输出向量;Ct-1为(t-1)时刻神经元状态;ft、it、gt和ot分别为内部激活变量;σ和tanh是可将输入压缩到-1~1的激活函数;W为权重矩阵;b为偏移向量。
1.2 Adam优化器
优化器是决定模型编译效果的重要组件之一,目前常用Adam[13],将动量和自适应学习率结合起来,代替梯度下降,有效更新网络权重[14]。调整偏移后,每次迭代学习率都固定在一定范围内,参数相对平衡,网络参数θ(权重和偏置)的更新原理为
式中:st和wt分别为梯度的一次指数衰减均值和二次指数衰减均值;ŝt、ŵt为偏置矫正;ε、η、μ和v为超参数,分别为0.1、0.001、0.9 和0.999。梯度估计为不同参数产生明确的动态学习率约束。
1.3 LSTM多参数预测模型
基于LSTM 预测实际驾驶过程中电池组的工作状态时,使用Adam优化器的训练过程是梯度下降的迭代过程,每次训练输入的样本数量以及预测结果的大小都会影响模型的预期性能。另外,对电池组中单参数进行状态监测会使预测精度受到训练参数特征的限制。因此需要对电池组多个参数进行同步监测,对采集到的数据采用滑动窗口的方法加以分析。把每次录入的数据划分为1个窗口,随着时间的推移,窗口中不断舍弃旧数据同时纳入新数据,进而实时更新网络结构,避免因多参数输入导致网络拥塞。如图2所示,将输入数据划分为训练集和验证集,每次抓取的训练样本数量为1个窗口大小,时间步长表示每次训练的时间序列长度。如滑动窗口大小为64,时间步长为20,预测大小为1,则表示第1次训练选用前64个时刻的输入数据进行训练,每次给模型20 个连续时间序列的数据。用1~20时刻的历史数据预测第21时刻,用2~21时刻的历史数据预测第22时刻,以此类推;第2次训练则输入第65时刻到第128时刻的数据,用65~84 个时刻的历史数据预测第85 个时刻……直到训练集中最后1次训练用最后1组时间序列的历史数据预测出下一时刻的数据。

图2 滑动窗口进行LSTM预测方法
2 驾驶行为对电池组工作状态影响
2.1 基于汽车动力学模型
构建车辆纵向动力学模型,分析车辆驱动行驶时的受力情况。考虑驾驶行为对电池组工作状态的影响,对加速度、电机转速、车轮半径等参数之间的相关性进行分析。车辆加速度与电池系统的功率关系为
式中:a为车辆加速度;T电机为电机转矩;I为电流;K为电机转矩系数;T车轮为车轮转矩,i为电机对于车轮的角传动比;F为车辆驱动力;m为整车重量;R为轮胎半径。忽略其他车载用电设备的电功率变化对电池系统参数的影响,可得到电池系统与整车行驶状况的关系。
2.2 考虑驾驶行为的电池预测模型
利用驾驶行为与电池组工作状态之间的映射关系,与驾驶行为和电池有关的参数作为学习指标,最终确立LSTM模型的11个参数,依次为电压、电流、SOC、车速、车辆状态、充电状态、里程、温度、内阻、挡位和加速度。在LSTM的基础上建立基于实车运行数据采样下的多参数预测模型,利用损失函数检测前向传播结束时模型的预测值f(x)与真实值yi之间的偏离。均方误差MSE 用于评价电池组工作状态预测的准确性,代表真实值和预测值差平方的期望值。通常情况下MSE 越小,说明预测模型对实测数据的评价越精确。
式中:yi为真实值;ŷi为预测值;n为样本点的个数。采用LSTM 模型进行电池组工作状态预测的整体算法流程如图3所示。
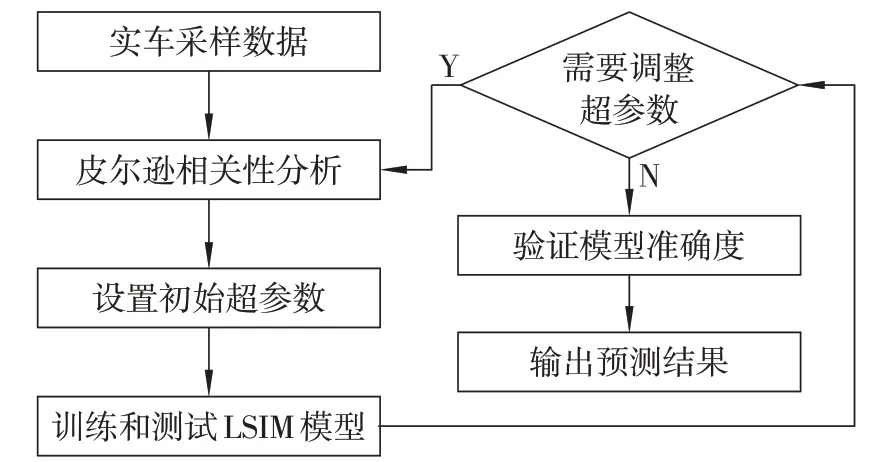
图3 LSTM电池组工作状态预测流程
3 实验结果与分析
3.1 实验环境及数据集
采用Windows11 系统,内存为16 G,处理器为酷 睿 i5-11400H,显 卡 为 NVIDIA GeForce RTX3060,开发环境为python3.7,深度学习框架为PyTorch1.11.0。
实验数据为北京亿维新能源汽车大数据应用技术研究中心提供的某品牌10辆纯电动乘用车的数据。为提高模型的准确性,对数据进行时间排序、单体电池电压/温度提取和异常数据清洗剔除等一系列预处理。采集数据的规格满足GB/T32960的规定,其中电池单体数量为95个,温度探头数量为34个。
数据处理后得到的总样本数为700 633,将原始数据集对训练集、验证集和测试集按照0.8∶0.15∶0.05 比例进行划分。由于参数具有量纲差异,为降低极端数据产生的干扰,同时提升LSTM模型的计算速度,将输入神经网络的全部数据映射到同一尺度进行归一化处理。映射方式为
式中:k为数据维度;Xmin和Xmax分别为数据的最小值和最大值。
3.2 各参数间的相关性分析
在LSTM模型的训练过程中,对选用的11个参数同时训练会增加过拟合的概率,因此建模之前进行相关性分析,挑选出最合适的输入参数。为了判断电池组状态参数之间的关联性,对选取的特征进行了皮尔逊相关性分析。皮尔逊相关系数用来度量2个变量间的相关程度,计算公式为
式中:cov为协方差;SX、SY为X和Y的标准差;E(X)、E(Y)为X和Y的期望值。相关系数取-1~1,1表示正线性相关,-1 表示负线性相关,0 表示无线性关系。相关系数绝对值越大,相关性越强。参数组成的相关系数矩阵见图4。相关系数绝对值大于0.8时,一般认为有强相关性;0.3~0.8,认为有弱相关性;小于0.3,认为没有相关性。由图4可看出,SOC与电压相互匹配;与电流匹配的参数为加速度、车辆状态和充电状态;与车速匹配的参数为车辆状态。在分析了现有匹配参数的相关性后,只有7个输入参数可用于训练LSTM 模型,分别是电流、电压、车辆状态、充电状态、SOC、加速度和车速。

图4 相关系数矩阵图
3.3 超参数的选择与调试
训练LSTM模型之前,需要设置和优化模型参数。首先设定所有可能的超参数,构成超参数取值的网格空间;然后初始化神经网络的超参数取值,计算训练样本输入神经网络后的均方误差。选取最优的超参数更新神经网络,直至目标函数最小,神经网络收敛,则训练完成。神经网络进行超参数优化的变化过程如图5所示。由图5a可以看出,经过训练后,神经网络在训练集和验证集上的损失函数不断降低,20 次迭代后训练集和验证集的损失函数均停止降低,训练效果较好,因此训练迭代次数设定为20。由图5b 可知,验证集损失随着批抓取的训练样本数量BS的增加呈现先减少后增大的趋势,当BS 为64 时损失函数最小,且在迭代次数为20 时收敛速度基本稳定。以此类推,经过训练后的各超参数取值如表1所示。

表1 LSTM模型训练后的超参数
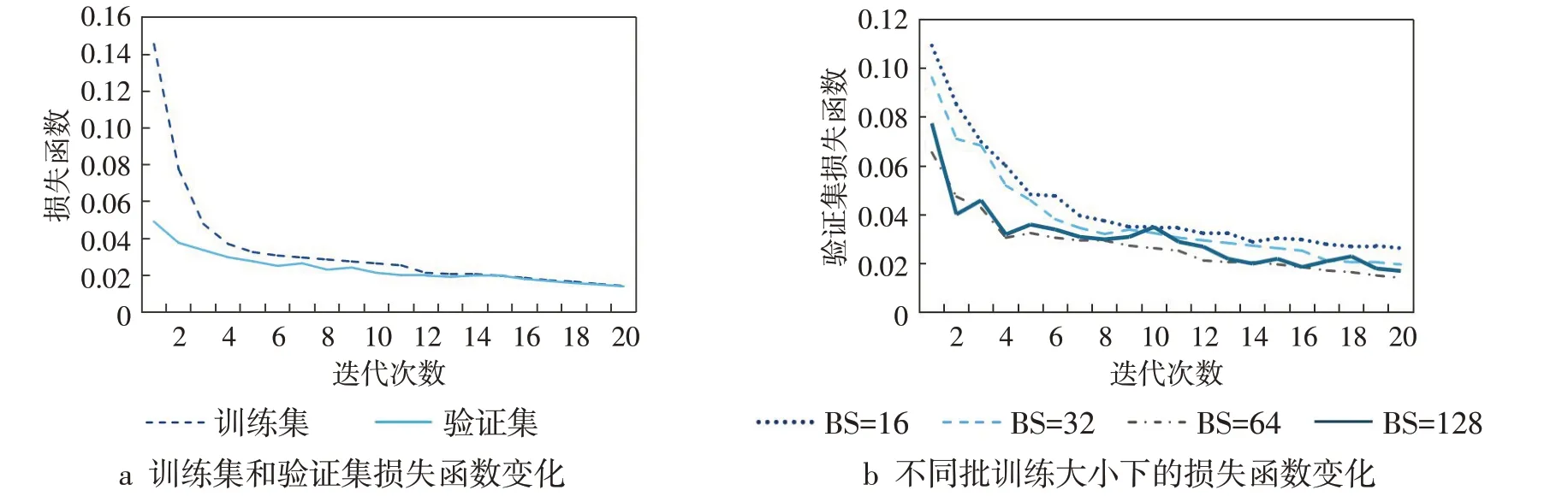
图5 神经网络超参数优化
3.4 实验结果
根据选择的超参数进行测试,得到不考虑驾驶行为和考虑驾驶行为状态下的电池SOC、电流、电压和车速预测结果,如图6~7所示。电池组工作状态参数预测的均方误差如表2 所示。结果表明:LSTM 模型取得了较好的预测精度,考虑驾驶行为前后的电压、SOC和车速均方误差均小于2%,这些参数的稳态变化受驾驶行为影响较小;而电流在考虑驾驶行为的情况下比不考虑驾驶行为情况下的均方误差由14.848%下降到3.192%,降低了超10%的误差。说明在建立LSTM 电池组参数预测模型过程中,除了电池本身特性参数,驾驶行为对电池组工作状态的影响也不容忽视。
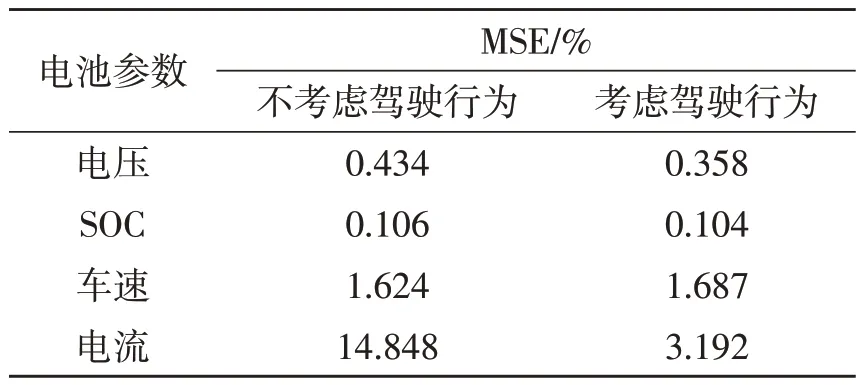
表2 电池组工作状态参数预测结果

图6 不考虑驾驶行为前后的电池组工作状态参数预测图

图7 考虑驾驶行为前后的电池组工作状态参数预测图
4 结论
结合LSTM与电池系统多参数,建立车辆动力学模型,考虑驾驶行为对电池的影响,建立包含多个特征参数在内的LSTM 模型对电池组工作状态进行预测。添加Adam优化器的LSTM模型能快速找到最优解,有效降低过拟合和梯度爆炸。多参数预测更全面地反映电池组特征参数之间的相关性,增强模型的准确度和收敛速度。考虑驾驶行为的LSTM 模型在预测电池组多参数方面表现更佳且更稳定。文中提出的方法能更好地适应实车运行的复杂工况,实现电池组工作状态的精准预测。未来将对动力电池内部机理进行更深入的分析,同时考虑周围环境温度对电动汽车运行的潜在影响,不断更新输入数据,进一步提升模型的预测效果。
