Magnetic Field-Based Reward Shaping for Goal-Conditioned Reinforcement Learning
2023-12-22HongyuDingYuanzeTangQingWuBoWangChunlinChenSeniorandZhiWang
Hongyu Ding, Yuanze Tang, Qing Wu, Bo Wang,,, Chunlin Chen,Senior,, and Zhi Wang,,
Abstract—Goal-conditioned reinforcement learning (RL) is an interesting extension of the traditional RL framework, where the dynamic environment and reward sparsity can cause conventional learning algorithms to fail.Reward shaping is a practical approach to improving sample efficiency by embedding human domain knowledge into the learning process.Existing reward shaping methods for goal-conditioned RL are typically built on distance metrics with a linear and isotropic distribution, which may fail to provide sufficient information about the ever-changing environment with high complexity.This paper proposes a novel magnetic field-based reward shaping (MFRS) method for goal-conditioned RL tasks with dynamic target and obstacles.Inspired by the physical properties of magnets, we consider the target and obstacles as permanent magnets and establish the reward function according to the intensity values of the magnetic field generated by these magnets.The nonlinear and anisotropic distribution of the magnetic field intensity can provide more accessible and conducive information about the optimization landscape, thus introducing a more sophisticated magnetic reward compared to the distance-based setting.Further, we transform our magnetic reward to the form of potential-based reward shaping by learning a secondary potential function concurrently to ensure the optimal policy invariance of our method.Experiments results in both simulated and real-world robotic manipulation tasks demonstrate that MFRS outperforms relevant existing methods and effectively improves the sample efficiency of RL algorithms in goal-conditioned tasks with various dynamics of the target and obstacles.
I.INTRODUCTION
REINFORCEMENT learning (RL) [1] is a general optimization framework of how an autonomous active agent learns an optimal behavior policy that maximizes the cumulative reward while interacting with its environment in a trialand-error manner.Traditional RL algorithms, such as dynamic programming [2], Monte Carlo methods [3], and temporal difference learning [4], have been widely applied to Markov decision processes (MDPs) with discrete state and action space [5]–[8].In recent years, with advances in deep learning,RL combined with neural networks has led to great success in high-dimensional applications with continuous space [9]–[13],such as video games [14]–[16], the game of Go [17], robotics[18], [19], and autonomous driving [20].
While RL has achieved significant success in various benchmark domains, its deployment in real-world applications is still limited since the environment is usually dynamic, which can cause conventional learning algorithms to fail.Goal-conditioned reinforcement learning [21]–[23] is a typical dynamic environment setting where the agent is required to reach everchanging goals that vary for each episode by learning a general goal-conditioned policy.The universal value function approximator (UVFA) [22] makes it possible by letting the Qfunction depend on not only a state-action pair but also a goal.In this paper, we treat the obstacle as an opposite type of the goal in goal-conditioned RL, i.e., “anti-goal” that the agent should avoid.Following UVFA [22], we can naturally give a positive reward when the agent reaches the target, a negative one when hitting on the obstacles, and 0 otherwise.However,the resulting sparse rewards make it difficult for the agent to obtain valid information and lead to poor sample efficiency[24], [25].Especially in the dynamic environment, the problem is more severe since the inherently sparse reward is constantly changing over time [23].
Reward shaping [26]–[29] effectively addresses the sample efficiency problem in sparse reward tasks without changing the original optimal policy.It adds an extra shaping reward to the original environment reward to form a new shaped reward that the agent applies to update policy, offering additional dense information about the environment with human domain knowledge.Potential-based reward shaping (PBRS) [26]defines the strict form of the shaping reward function as the difference between the potential functions of the successor and the current state.It ensures that the optimal policy learned from the shaped reward is consistent with the one learned from the original reward, also known as the optimal policy invariance property.
The shaping reward in existing methods is typically set according to a distance metric for goal-conditioned RL, e.g.,the Euclidean distance between the agent and goal [30].However, due to the linear and isotropic properties of the distance metrics, it may fail to provide adequate information about a dynamic environment with high complexity.Specifically, the derivative of the linear distance-based shaping reward is a constant, which cannot provide higher-order information on the optimization landscape.In this case, the agent only knows“where” to go, rather than “how” to go.On the other hand, the isotropic property also exacerbates this problem.Considering a 2D plain with an initial state and a target, the points with the same Euclidean distance from the target will share a same value of potential or shaping reward under distance-based setting.However, the points between the initial state and target should be given higher values since the optimal policy is supposed to be the steepest path from the initial state to the target.Consequently, it is necessary to develop a more sophisticated reward shaping method that can provide sufficient and conducive information for goal-conditioned tasks.
Intuitively, the agent should be attracted to the target and repelled by the obstacles, which is similar to the physical phenomenon that magnets of the same polarity repel each other while those of different polarities attract each other.Inspired by this, we propose a magnetic field-based reward shaping(MFRS) method for goal-conditioned RL tasks.We consider the dynamic target and obstacles as permanent magnets, and build the reward function according to the intensity values of the magnetic field generated by these magnets.The nonlinear and anisotropic properties of the generated magnetic field provide a sophisticated reward function that carries more accessible and sufficient information about the optimization landscape than in the distance-based setting.Besides, we use several normalization techniques to unify the calculated values of magnetic field intensity and prevent the value exploding problem.Then, we define the form of our magnetic reward function and transform it into a potential-based one by learning a secondary potential function concurrently to ensure the optimal policy invariance of our method.
In summary, our main contributions are as follows.
1) We propose a novel MFRS method for goal-conditioned RL tasks with dynamic target and obstacles.
2) We build a 3-D simulated robotic manipulation platform and verify the superiority of MFRS on a set of tasks with various goal dynamics.
3) We apply MFRS to a physical robot in the real-world environment and demonstrate the effectiveness of our method.
The rest of this paper is organized as follows.Section II introduces the preliminaries of goal-conditioned RL and related work.In Section III, we first present the overview of MFRS, followed by specific implementations in detail and the final integrated algorithm.Simulated experiments on several robotic manipulation tasks with the dynamic target and obstacles are conducted in Section IV.Section V demonstrates the application of our method to a real robot, and Section VI presents our concluding remarks.
II.PRELIMINARIES AND RELATED WORk
A. Goal-Conditioned Reinforcement Learning
We consider a discounted infinite-horizon goal-conditioned Markov decision process (MDP) framework, defined by a tuple 〈 S,G,A,T,R,γ〉, where S is the set of states, G is the set of goals which is the subset of states G ⊆S, A is the set of actions, T :S×A×S →[0,1] is the state transition probability,R:S×A×G →R is the goal-conditioned reward function, and γ is a discount factor γ ∈(0,1].
We aim to learn a goal-conditioned policy that can achieve multiple goals simultaneously.Considering a goal-reaching agent interacting with the environment, in which every episode starts with sampling an initial states0∼ρ0and a goalg∼ρg, where ρ0and ρgdenote the distribution of the initial state and goal, respectively.At every timesteptof the episode,the agent selects an action according to a goal-conditioned policyat∼π(·|st,g).Then it receives an instant rewardrt=r(st,at,g)that indicates whether the agent has reached the goal, and the next state is sampled from the distribution of state transition probabilityst+1∼p(·|st,at).
Formally, the objective of goal-conditioned RL is to find an optimal policy π∗that maximizes the expected return, which is defined as the discounted cumulative rewards
under the distribution
where τ=(s0,a0,s1,a1,...) is the learning episode.Based on UVFA [22], goal-conditioned RL algorithms rely on the appropriate estimation of goal-conditioned action-value functionQπ(s,a,g), which describes the expected return when performing actionain states, goalgand followingπafter:
whereEstands for the environment.
In this work, we follow the standard off-policy actor-critic framework [31]–[35], where a replay bufferDis used to store the transition tuples (st,at,st+1,rt,g) as the experience for training.The policy is referred as the actor and the actionvalue function as the critic, which can be represented as parameterized approximations using deep neural network(DNN) πθ(s,g) andQϕ(s,a,g), whereθandϕdenote the parameters of the actor-network and critic-network, respectively.
Actor-critic algorithms maximize the expected return by alternating between policy evaluation and policy improvement.In the policy evaluation phase, the critic estimates the action-value function of the current policy πθ, and the objective for the critic is minimizing the square of the Bellman error [2]
Hereafter, a gradient descent step ϕ ←ϕ-β∇ϕL(ϕ) and a gradient ascent step θ ←θ+α∇θJ(θ) can be taken to update the parameters of the critic network and actor network, respectively, whereβandαdenote the learning rates.The minimizing and maximizing strategies continue untilθandϕconverge [18], [36].
B. Related Work
Goal-conditioned RL aims to learn a universal policy that can master reaching multiple goals simultaneously [37].Following UVFA [22], the reward function in goal-conditioned RL is typically a simple unshaped sparse reward, indicating whether the agent has reached the goal.Therefore, the agent can gain nothing from the environment until eventually getting into the goal region, which usually requires a large number of sampled episodes and brings about the problem of sample inefficiency, especially in complex environments such as robotic manipulation tasks.
A straightforward way to alleviate the sample efficiency problem is to replace the reward with a distance measure between the agent’s current state and goal.References[38]–[42] propose different distance metrics to provide the agent with an accurate and informative reward signal indicating the distance to the target.However, they cannot guarantee that the optimal learned policy with the shaped reward will be the same as the original reward, which yields an additional local optima problem [30].In contrast, our method holds the property of optimal policy invariance and preserves a fullyinformative dense reward simultaneously.
For the local optima problem generated by directly replacing the reward function, reward shaping is a popular way of incorporating domain knowledge into policy learning without changing the optimal policy.Nget al.[26] propose the potential-based reward shaping (PBRS), which defines the strict form of shaping reward function with proof of sufficiency and necessity that the optimal policy remains unchanged.Wiewioraet al.[27] extend the input of potential function to state-action pair, allowing the incorporation of behavioral knowledge.Devlin and Kudenko [28] introduce a time parameter to the potential function, allowing the generalization to dynamic potentials.Further, Harutyunyanet al.[29] combine the above two extensions and propose the dynamic potentialbased advice (DPBA) method, which can translate arbitrary reward function into the form of potential-based shaping reward by learning a secondary potential function together with the policy.All these methods hold the theoretical property of optimal policy invariance.However, they typically calculate the shaping reward based on simple distance metrics in goal-conditioned RL, which may fail to provide sufficient information in a highly complex dynamic environment.In contrast, we establish our shaping reward function according to the magnetic field intensity with nonlinear and anisotropic distribution, carrying more informative and conducive information about the optimization landscape.
For the local optima problem, apart from the reward shaping methods, learning from demonstration (LfD) is also considered as an effective solution that introduces a human-inthe-loop learning paradigm with expert guidance.Reference[43] proposes a human guidance-based PER mechanism to improve the efficiency and performance of RL algorithm, and an incremental learning-based behavior model that imitates human demonstration to relieve the workload of human participants.Reference [44] develops a real-time human-guidancebased DRL method for autonomous driving, in which an improved actor-critic architecture with modified policy and value network is introduced.On the other hand, the local optima problem also exists when performing gradient descent to solve the ideal parameters in RL, especially in the field of control systems.To obtain the global optimal solution, [45]exploits the current and some of the past gradients to update the weight vectors in neural networks, and proposes a multigradient recursive (MGR) RL scheme, which can eliminate the local optima problem and guarantee a faster convergence than gradient descent methods.Reference [46] extends MGR to the distributed RL to deal with the tracking control problem of uncertain nonlinear multi-agent systems, which further decreases the dependence on network initialization.
Another line of research that tackles the sample efficiency problem due to sparse reward in goal-conditioned RL is the hindsight relabeling strategy, which can be traced back to the famous hindsight experience replay (HER) [23].HER makes it possible to reuse unsuccessful trajectories in the replay buffer by relabeling the “desired goals” with certain “achieved goals”, significantly reducing the number of sampled transitions required for learning to complete the tasks.Recently,researchers have been interested in designing advanced relabeling methods for goal sampling to improve the performance of HER [47]–[52].However, HER and its variants only focus on achieving the desired goal but fail to consider the obstacles.In contrast, our method can handle tasks with multiple dynamic obstacles and learn to reach the desired goal while avoiding the obstacles with high effectiveness and efficiency.
III.MAGNETIC FIELD-BASED REwARD SHAPING
In this section, we first introduce the overview of MFRS that considers the target and obstacles as permanent magnets and exploits the physical property of the magnetic field to build the shaping reward function for goal-conditioned tasks.Then, we illustrate the calculation of the resulting magnetic field intensity for different shapes of permanent magnets in detail and use several normalization techniques to unify the intensity distribution and prevent the value exploding problem.Finally, we define the form of our magnetic reward function and transform it into a potential-based one by learning a secondary potential function concurrently to ensure the optimal policy invariance property.
A. Method Overview
For the sample inefficiency problem due to the sparse reward in goal-conditioned RL, reward shaping is a practical approach to incorporating domain knowledge into the learning process without changing the original optimal policy.However, existing reward shaping methods typically use distance measures with a linear and isotropic distribution to build the shaping reward, which may fail to provide sufficient information about the complex environments with the dynamic target and obstacles.
Therefore, it is necessary to develop a more sophisticated reward shaping method for this specific kind of task.For a goal-conditioned RL task with the ever-changing target and obstacles, our focus is to head toward the target while keeping away from the obstacles.Naturally, the agent is attracted by the target and repelled by the obstacles, which is analogous to the physical phenomenon that magnets of the same polarity repel each other while those of different polarities attract each other.Motivated by this, we model the dynamic target and obstacles as permanent magnets and establish our shaping reward according to the intensity of the magnetic field generated by these permanent magnets.The magnetic field with a nonlinear and anisotropic distribution can provide more accessible and conducive information about the optimization landscape, thus introducing a more sophisticated shaping reward for goal-conditioned RL tasks with dynamic target and obstacles.Fig.1 visualizes an example comparison of the shaping reward distribution between the traditional distancebased setting and our magnetic field-based setting.
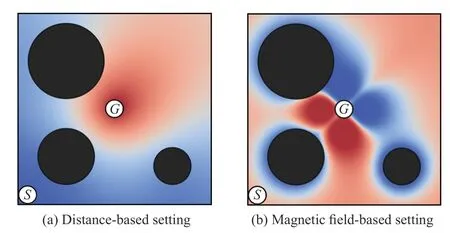
Fig.1.An example comparison of the shaping reward distribution between the traditional distance-based setting and our magnetic field-based setting.S and G are the start point and goal.Black circles indicate the obstacles in different sizes.Since the shaping reward is positively related to the magnetic field intensity, areas painted with warmer color possess a larger shaping reward.
According to the physical property of permanent magnets,the agent will sense a higher intensity value in the magnetic field when getting closer to the target or away from the obstacles.The shaping reward varies more intensively in the near region of the target and obstacles.The target area uses a far larger shaping reward to facilitate its attraction to the agent,while the area around obstacles will receive a far smaller shaping reward as a “danger zone” to keep the agent at a distance.The nonlinearity of the magnetic field reinforces the process that the agent is attracted by the target and repelled by the obstacles.Being different from the distance-based setting,the derivative of the magnetic field intensity value with respect to the agent’s position will also increase when approaching the target or moving away from the obstacles.This property makes the shaping reward vary more intensively when the agent explores the environments, especially in the near regions around the target and obstacles, as illustrated in Fig.1(b).Under this setting, the agent can be informed of an extra variation trend of the reward function together with the reward value itself.Thus it knows “how” to approach the target in addition to “where” to go.Therefore, the nonlinear characteristic of the magnetic field can provide more useful position information for the algorithm to improve its performance.
For a goal-conditioned RL task, the optimal policy should be the steepest path from the initial state to the target while avoiding the obstacles.Considering the points with the same Euclidean distance to the target, the distance-based reward shaping methods assign the same shaping reward (or potential) value to these points according to the isotropic distribution of the distance function.However, the points between the initial state and the target should be preferred than the others since they can eventually lead to a shorter path to the target.It is intuitive and rational to assign higher values to those points,which can more explicitly embed the orientation information of the target into the shaping reward.Our magnetic fieldbased approach can realize this consideration by adjusting the target magnet’s magnetization direction towards the agent’s initial state.As shown in Fig.1(b), the shaping reward distribution of the target area is anisotropic, where the part between the initial state and the goal exhibits a larger value than the other parts.Accordingly, the agent will have a clear insight of the heading direction towards the target.In brief, the anisotropic feature of the magnetic field can provide more orientation information about the goal-conditioned RL tasks.
Based on the above insights, we propose a MFRS method for goal-conditioned RL tasks, which can provide abundant and conducive information on the position and orientation of the target and obstacle due to the nonlinear and anisotropic distribution of the magnetic field.To this end, an additional dense shaping reward according to the magnetic field intensity is added to the original sparse reward with the guarantee of optimal policy invariance.As a result, the agent can enjoy an informative reward signal indicating where and how far the target and obstacles are in each timestep, and maintain the same optimal policy under the sparse reward condition.Therefore, the sample inefficiency problem caused by the sparse reward can be alleviated.We consider the target and obstacles as permanent magnets, and calculate the intensity values of the resulting magnetic field using physical laws.
B. Calculation of Magnetic Field Intensity
For permanent magnets in regular shapes, we can directly calculate the intensity function analytically, using different formulas for different shapes.We take the spherical and cuboid permanent magnets as examples to calculate the distribution of magnetic field intensity in three-dimensional (3-D)space for illustration.As for the permanent magnets in irregular shapes, the intensity distribution of magnetic field can be obtained by analog platforms using physics simulation software such as COMSOL [53].
We assume the spherical and cuboid magnets are both saturatedly magnetized along the positive direction of thez-axis,and Fig.2 presents the magnetic field coordinate systems of the spherical and cuboid magnets, respectively, for intensity calculation.To obtain the magnetic field intensity at an arbitrary given point in the field of spherical and cuboid magnets,we first need to transfer the point from the environment coordinate system to the magnetic field coordinate system of the spherical and cuboid magnets.Deakin [54] has introduced the form of 3-D conformal coordinate transformation that combines axes rotation, scale change, and origin shifts.Analogously, our coordinate system transformation of points in space is a Euclidean transformation that only consists of rotation and translation, which can be defined as
where the positive sense of rotation angle is determined by the right-hand screw rule.

Fig.2.Magnetic field coordinate systems of the spherical and cuboid magnets, in which P s(xs,ys,zs) and P c(xc,yc,zc) are arbitrary given points.
Now we have implemented the 3-D conformal coordinate transformation.Then we will illustrate how to calculate the magnetic field intensity of the points in the magnetic field coordinate system.For the spherical permanent magnet, given an arbitrary point (xs,ys,zs) in its magnetic field coordinate system, we first need to convert the point from Cartesian coordinates to Spherical coordinates by the formulae we defined below:
wherers, θs, and ϕsdenote the radius, inclination, and azimuth in Spherical coordinates, respectively, andϵis a small constant.Letasdenote the radius of the spherical magnet, then the magnetic field intensity of the spherical magnet at given point (rs,θs,ϕs) can be calculated analytically as
whereMsis the magnetization intensity of the spherical magnet.,andare thecalculatedintensitiesofthe magneticfield alongthex-axis,y-axis,andz-axisforaspherical magnet, andHsis the required value of magnetic field intensity for the given point (xs,ys,zs) in the field of the spherical magnet.
For the cuboid magnet, letlc,wc,hcdenote the length, width,and height of the cuboid magnet along thex-,y-, andz-axis,respectively.Then the magnetic field intensity at a given point(xc,yc,zc)can be calculated as
whereMcdenotes the magnetization intensities of the cuboid magnet.andare the calculated intensities of the magnetic field along thex-axis,y-axis, andz-axis for a cuboid magnet, andHcis the required value of the magnetic field intensity for the given point (xc,yc,zc) in the field of the cuboid magnet.Γ(γ1,γ2,γ3) and Ψ(φ1,φ2,φ3) are two auxiliary functions to simplify calculations as defined by
With these analytical expressions, we are now able to obtain the specific value of magnetic field intensity at any given point in the field of spherical magnet and cuboid magnet.For simplicity, we letMs=Mc=4π as the value of magnetization intensity only determines the magnitude of magnetic field intensity, rather than its distribution.Fig.3 visualizes the distributions of magnetic field intensity generated by the spherical and cuboid magnets in 3-D space, where the sphere’s radius is 0.02, the length, width, and height of the cuboid are 0.1, 0.4, 0.05, respectively.Areas with warmer colors have a higher intensity value in the magnetic field.It can be observed that the surfaces of the sphere and cuboid magnets exhibit the highest intensity value, and the intensity decreases intensively as the distance to the magnet increases.
Towards the environments with higher dimensions (e.g.,more than three dimensions), though we cannot directly calculate the magnetic field intensity since the target/obstacles are not physical entities and thus can not be considered as permanent magnets in the physical sense, the concept and properties of the magnetic field can still be extended to the scenario with a high-dimensional goal in a mathematical sense.For instance,the magnetic field intensity of a spherical permanent magnet along the axis of magnetization (taking thez-axis as an example) can be calculated as below:
whereM0is the magnetization intensity,ris the radius of the spherical magnet, andzdenotes the coordinate on thez-axis in the magnetic field coordinate system.As we can see, the intensity value is inversely proportional to the third power of the distance to the origin of magnetic field coordinate system along the magnetization axis outside the magnet.This property of the spherical magnets can be extended to high-dimensional goals by simply replacing |z| with a distance metric(e.g., L2-norm) between the current state and the target state,which can still maintain a nonlinear and intensively-varying distribution of shaping rewards that provides sufficient information about the optimization landscape.
C. Magnetic Reward Function
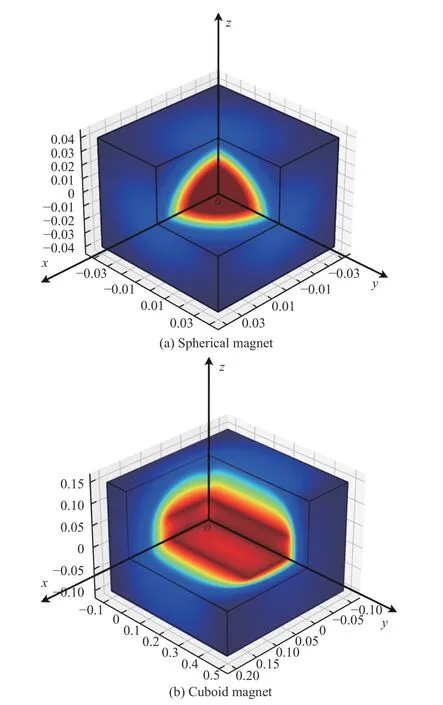
Fig.3.Distributions of the magnetic field intensity in 3-D space generated by the spherical and cuboid magnets.Areas painted with warmer color possess a larger intensity value of the magnetic field.
Considering a goal-conditioned task with 1 target andNobstacles.Letdenote the functions that calculate the intensity valuesHTandHOiof themagneticfieldsgeneratedby thetargetmagnetandobstaclemagnets,respectively, whereandParetheagent’s positions in the magnetic field coordinate system of target and obstacle magnets.Taking the spherical target and cuboid obstacle as an example, the intensity functions MTandMOcan be defined as (9) and (10) in Section III-B, respectively.The intensity values cannot be directly combined since the scales of magnetic field intensity for various magnets are different using separate ways of calculation.It may amplify the effect of one or some magnets and give an incorrect reward signal to the agent if the intensity scales of these magnets are much larger than others.Therefore, we need to standardize the calculated intensity valuesHTandHOi.
Intuitively, we use thez-score method to unify the unevenly distributed intensity values into a standard Gaussian distribution for the target and obstacles magnets as
whereϵis a small constant, µTand µOidenote the means of magnetic field intensity for the target and obstacles magnet,and σTand σOidenote the standard deviation.Unfortunately,the actual values of the mean and standard deviation cannot be obtained directly since the agent knows nothing about the specific intensity distribution at the beginning of training.Hence,we turn to estimate these values by introducing an extra magnet buffer DMthat stores the calculated intensity valuesHTandHOi.During the learning process, we concurrently update thevaluesof themeanand standarddeviationforHTandHOiusing theup-to-date buffer DM, which are usedtostandardize the values of calculated magnetic field intensity in the next learning episode.According to the law of large numbers, as the number of collected data in DMincreases, the estimated values of the mean and standard deviation will converge to their actual values.
After implementing the standardization of the magnet field intensity, the unified intensity of the target and obstacles magnets can be combined to a value that represents the overall intensity of the magnetic field generated by the target and obstacles together, which can be expressed as
Recall our motivation in Section III-A, we want the agent to be attracted by the target and repelled by the obstacles when exploring the environment.In addition, we consider that the target’s attraction has the exact extent of the effect as all obstacles’ repulsion.Accordingly, we take the mean of unified intensity values among all the obstacles in the calculation and give a positive value towhile a negative value to the mean ofto define the combined intensity valueHcom.
Due to the physical property of magnets, the intensity values will be tremendous in the near region of the target, as shown in Fig.1.Therefore, regardingHcomas the magnetic reward could probably lead to a phenomenon that the value of the magnetic reward is orders of magnitude larger than the original reward.To address the value exploding problem, we employ the Softsign function to normalize the combined intensity value within a bounded range of [-1,1] and use the output of the Softsign function as the magnetic rewardRm

Algorithm 1 Magnetic Reward Function Input: state s; goal g;intensity calculation functions ;µT,σT,µOi,σOi (i=1,2,...,N)MT,MOi Output: magnetic field intensity ;Rm HT,HOi magnetic reward 1 Obtain agent’s position according to s PT POi Pa 2 Obtain target’s position and obstacles’ positions according to g Pa PTa,POi 3 Transfer to using (6) according to HT ←MT(PTa),HOi ←MOi(POia )4 HNT HNOi µT,σT,µOi,σOi 5 Calculate and using (13) according to a PT,POi 6 Calculate using (14)Rm ←Softsign(Hcom)7 Hcom
Algorithm 1 shows the calculation process of the magnetic reward function in our method.Since we consider the obstacles as a part of the goal in goal-conditioned RL together with the target, we define the goal in our setting asg:=[PT,PO1,PO2,...,PON],wherePTis thetarget’s position andPO1,PO2,...,PONare obstacles’positions.
D. Magnetic Field-Based Reward Shaping
After calculating the magnetic rewardRmthat represents the overall intensity generated by the target and obstacles magnetswithnormalization techniques, we needtoguaranteethe optimal policyinvarianceofourmethod when usingRmasthe shaping reward.PBRS [26] defines the shaping reward function asF(s,a,s)=γΦ(s)-Φ(s) with proof of sufficiency and necessity that the optimal policy remains unchanged, where Φ(·)denotes the potential function carrying human domain knowledge, and γ ∈[0,1] is the discount factor.In this paper,we employ the DPBA [29] method to transform our magnetic rewardRminto the form of potential-based reward shaping in the goal-conditioned RL setting.To be specific, we need to achieveF≈Rm, where the potential function inFcan be learned in an on-policy way [55] with a technique analogous to SARSA [56]
whereηis the learning rate of this secondary goal-conditioned potential function Φ, and δΦtdenotes the temporal difference (TD) error of the state transition
whereat+1ischosenusingthe current policy.According to DPBA[29], thevalueofRΦequalsthe negationof the expertprovided reward function, which is the magnetic reward in our method:RΦ=-Rm, and thusrtΦ=-rtm.

Algorithm 2 MFRS for Goal-Conditioned RL Input: potential function ; replay buffer ; magnet buffer ;number of obstacles N; discount factor γ; off-policy RL algorithm Φψ DR DM A Output: optimal goal-conditioned policy πθ Φψ ←0 π∗θ 1 Initialize arbitrarily,DR DM 2 Initialize replay buffer and magnet bufferµT,µOi ←0 σT,σOi ←1(i=1,2,...,N)3 ;4 for episode = 1, E do 5 Sample an initial state and a goal g 6 for t = 0, H - 1 do at ←πθ(st,g)s0 7 8 Execute , observe and HT,HOi rmt st+1,g µT,σT,µOi,σOi at st+1 rt 9 Calculate and using Algorithm 1 according to and HT,HOi DM 10 Store in at+1 ←πθ(st+1,g)11 12 Update ψ using (19)ft 13 Calculate using (20)r′t ←rt+ft 14(st,at,st+1,r′t,g) DR 15 Store transition in 16 end πθ A 17 Update usingµT ←mean(HT),σT ←std(HT)18 19 20 endµOi ←mean(HOi),σOi ←std(HOi)
Since we focus on the tasks with continuous state and action space, the goal-conditioned potential function can be parameterized using a deep neural network Φψ(s,a,g) with the weightsψ.Akin to the temporal-difference learning, we use the Bellman error as the loss function of this potential network as
Hereafter, the weights of Φψ(s,a,g) can be updated using the gradient descent as
As the secondary goal-conditioned potential function Φ is updated every timestep, the potential-based shaping rewardFat each timestep can be expressed as
Algorithm 2 presents the integrated process of MFRS for goal-conditioned RL.Next, we give a theoretical guarantee of optimal policy invariance in the goal-conditioned RL setting of our method in the Appendix, and a convergence analysis that the expectation of shaping rewardFwill be equal to our magnetic rewardRmwhen the goal-conditioned potential function Φ has converged in Theorem 1 below.
Theorem 1: Let Φ be the goal-conditioned potential function updated by (16) with the state transition matrix T, whereRΦequals the negation of our magnetic rewardRm.Then, the expectation of shaping rewardFexpressed in (20) will be equal toRmwhen Φ has converged.
Proof: The goal-conditioned potential function Φ follows the update rule of the Bellman Equation [2], which enjoys the same recursive relation when the potential value has converged to the TD-fixpoint Φ∗.Thus, we have
According to (20), we have the shaping rewardFwith respect to the converged potential valueΦ∗
To obtain the expected shaping reward F(s,a,g), we take the expectation with respect to the state transition matrixT
Hence, the expectation of shaping rewardFwill be equal to our magnetic rewardRmwhen the goal-conditioned potential function Φ converges to the TD-fixpoint.■
IV.SIMULATION ExPERIMENTS
To evaluate our method, we build a 3-D simulated robotic manipulation platform based on the software CoppeliaSim,formerly known as V-REP [57], and design a set of challenging goal-conditioned RL tasks with continuous state-action space.Being analogous to the FetchReach-v1 [58] task in OpenAI Gym [59], our tasks require the agent to move the end-effector of a robotic arm to dynamic targets with different positions, but differ from FetchReach-v1 in additional dynamic obstacles that the agent should avoid.
A. Environment Settings
Sections IV-B and IV-C present the results and insightful analysis of our findings.In the experiments, we evaluate MFRS in comparison to several baseline methods as follows:
1)No Shaping(NS): As the basic sparse reward condition, it trains the policy with the original reward given by the environment without shaping.

4)HER[23]: As the famous relabeling strategy in goal-conditioned RL, it relabels the desired goals in the replay buffer with the achieved goals in the same trajectories.In our experiments, we adopt the default “final” strategy in HER that chooses the additional goals corresponding to the final state of the environment.
5)Sibling Rivalry(SR)[30]:It samples two sibling episodes for each goal simultaneously and uses each others’ achieved goals as anti-goalsg.Then, it engineers an additional reward bonusd(s,g) to encourage exploring and avoid local optima,wheredis the Euclidean distance.
6)Adversarial Intrinsic Motivation(AIM)[42]: It aims to learn a goal-conditioned policy whose state visitation distribution minimizes the Wasserstein distance to a target distribution for a given goal, and utilizes the Wasserstein distance to formulate a shaped reward function, resulting in a nonlinear reward shaping mechanism.
We use Dobot Magician [60] as the learning agent in our experiments, which is a 3-degree of freedom (DOF) robotic arm in both CoppeliaSim simulated environment and realworld industrial applications.Dobot Magician has three stepper motors to actuate its jointsJ1,J2, andJ3, as shown in Fig.4,which can achieve rotation angles within the range of[-90◦,90◦],[0◦,85◦],[-10◦,90◦], respectively.Therefore, we consider the action as a 3-dimensional vector clipped to be in the range of [-1◦,1◦], representing the rotation velocity of these three joints.Being analogous to FetchReach-v1, the observations include the Cartesian positions of the “elbow”,“finger”, and the rotation angles of the three joints.
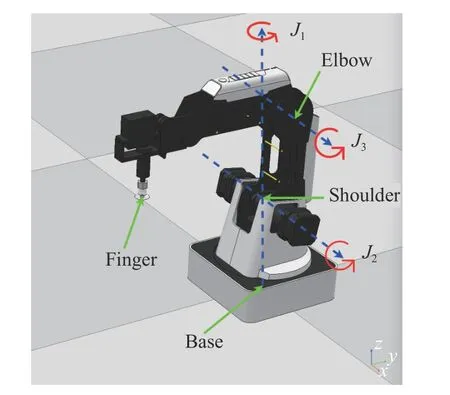
Fig.4.The configuration of Dobot Magician, where “base”, “shoulder”,and “elbow” represent three motors with the joints denoted by J1, J2, and J3,respectively, and “finger” represents the end-effector.
In our experiment, we use deep deterministic policy gradient (DDPG) [61] as the base algorithm to evaluate all the investigated methods under the same configurations in the goal-conditioned RL setting.Specifically, the goal-conditioned policy is approximated by a neural network with two 256-unit hidden layers separated by ReLU nonlinearity as the actor, which maps each state and goal to a deterministic action and updates its weights using Adam optimizer [62] with a learning rate of α=3×10-4.The goal-conditioned Q-function is also approximated by a neural network that maps each state-action pair and goal to a certain value as the critic, which has the same network structure and optimizer as the actor with a learning rate of β=10-3.The target networks of actor and critic update their weights by slowly tracking the learned actor and critic with τ=0.001.We train the DDPG whenever an episode terminates with a minibatch size of 128 for 100 iterations.In addition, we use a replay buffer size of 106, a discount factor of γ=0.99 , and a Gaussian noise N(0,0.4) to each action for exploration.For MFRS and DPBA methods,the goal-conditioned potential function Φ is approximated by a neural network with the same structure and optimizer as the critic network and a learning rate of η=10-4, which is updated for each timestep in an on-policy manner.For MFRS in particular, we set the magnet buffer size of 106and the small constant of ϵ =10-7.
For each report unit, we define two performance metrics.One is the success rate in each learning episode, where success is defined as the agent reaching the target without hitting on the obstacles.The other is the average timesteps for each trajectory over all learning episodes, defined aswhereEis the number of learning episodes andTkis the terminal timestep in thekth episode.The former is plotted in figures, and the latter is presented in tables.Moreover, due to the randomness in the update process of the neural network, we repeat five runs for each policy training by taking different random seeds for all methods, and report the mean regarding the performance metrics.Our code is available online1https://github.com/Darkness-hy/mfrs.
B. Primary Results
To evaluate our method in different scenarios, we develop four goal-conditioned tasks with various dynamics configurations of the target and obstacles, on which we implement MFRS and baseline methods.All four tasks require the agent to move the “finger” into a target region without hitting the obstacles in each episode.Accordingly, we define the original reward function as:r(s,a,g)=100 if the “finger” successfully reaches the target,r(s,a,g)=-10 if the agent hits the obstacle or the floor in CopperliaSim, andr(s,a,g)=-1 otherwise.Each episode starts by sampling the positions of the target and obstacles with the rotation angles of the agent’s three joints reset to zero, and terminates whenever the agent reaches the target or at the horizon ofH=1000.
1)Goal-Conditioned Tasks With Different Goal Dynamics:In the first two tasks, the obstacle is a cuboid rotator revolving around a fixed cylindrical pedestal, where the length,width, and height of the rotator are 0.1, 0.4, 0.05 along thexaxis,y-axis,z-axis, and the radius, height of the pedestal are 0.04, 0.13, respectively.The rotator’s axis coincides with the pedestal’s axis, and the top surfaces of the rotator and pedestal are on the same plane.We represent the obstacle position by the center point coordinate of the rotator determined by its rotation angle from an initial position, where the positive direction of rotation is defined to be anticlockwise, with the rotator’s initial position being parallel to they-axis.In the other two tasks with higher complexity, the agent has to handle three dynamic spherical obstacles with a radius of 0.02,0.04 , and 0.06, respectively.We represent the obstacles’ positions by the center point coordinates of their own spheres.Besides, the target is a sphere with a radius of 0.02 in all four tasks where the target position is the center point coordinate.
i)Task I: As shown in Fig.5(a), the dynamic of the goal is determined by randomly changing the target position, which is sampled uniformly from the space both in the reachable area of “finger” and below but not under the lower surface of the single static obstacle.
ii)Task II: As shown in Fig.5(b), the dynamic goal is created by changing the positions for both the target and the single obstacle.The change of obstacle position can be converted into sampling rotation angles of the rotator, which is defined as a uniform sampling within [-60◦,60◦].The change of target position is consistent with the one in Task I.
iii)Task III: As shown in Fig.5(c), the goal dynamics is determined by changing the positions of multiple obstacles while holding the target still, and all the target and obstacles are ensured to be not intersectant.
iv)Task IV: As shown in Fig.5(d), this kind of dynamic goal is created by sampling the positions of all the target and multiple obstacles simultaneously, which is considered the most complex of the four tasks.Also, we need to ensure that all the target and obstacles are not intersectant.
2)Results of MFRS: We present the experimental results of MFRS and all baselines implemented on the four goal-conditioned tasks.Fig.6 shows the success rate in each learning episode, of which the mean across five runs is plotted as the bold line with 90% bootstrapped confidence intervals of the mean painted in the shade.Table I reports the numerical results in terms of average timesteps over 10 000 learning episodes of all tested methods.The mean across five runs is presented, and the confidence intervals are corresponding standard errors.The best performance is marked in boldface.
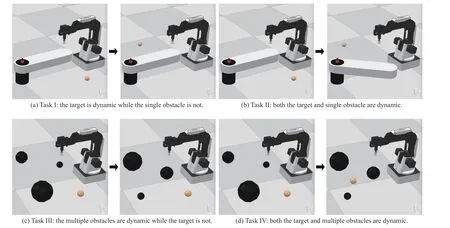
Fig.5.Examples of four goal-conditioned tasks with different dynamics of the target and obstacles.The spherical targets in all the tasks are shown in yellow,the single cuboid obstacles in Tasks I and II are shown in white, and the multiple spherical obstacles in Tasks III and IV with various sizes are shown in black.

Fig.6.Success rate in each learning episode of all investigated methods implemented on four different goal-conditioned tasks.

TABLE I NUMERICAL RESULTS IN TERMS OF AVERAGE TIMESTEPS OVER ALL LEARNING EPISODES OF TESTED METHODS IN FOUR DIFFERENT GOAL-CONDITIONED TASkS
Surprisingly, HER obtains the worst performance and even gets a lower success rate than NS.We conjecture that the relabeling strategy may mislabel the obstacles as the targets when considering the obstacles as a part of the goal.PBRS achieves a slightly higher success rate than NS since it incorporates additional distance information into the potential function.DPBA obtains better performance than PBRS, indicating that directly encoding the distance information as the shaping reward and learning a potential function in turn can be more informative and efficient.AIM has similar performance compared to DPBA and performs better in complex tasks (Tasks II and IV), which is supposed to benefit from the estimated Wasserstein-1 distance between the state visitation distribution and target distribution.SR performs best among the baseline methods on account of its anti-goals mechanism that encourages exploring and avoids local optima, while it suffers from large confidence intervals since SR fails to consider obstacles and can not guarantee the optimal policy invariance property.
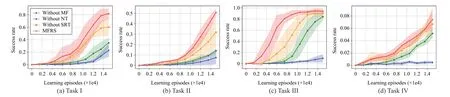
Fig.7.Success rate in each learning episode of the three variants together with MFRS implemented on four different goal-conditioned tasks.
In contrast, it can be observed from Fig.6 that MFRS outperforms all the baseline methods with a considerably larger success rate in all the four tasks, which is supposed to benefit from the explicit and informative optimization landscape provided by the magnetic field intensity.The performance gap in terms of success rate at the end of training varies in different tasks.For instance, in Task I, MFRS achieves a success rate of 79.66%at the last learning episode while the baseline methods have only increased the success rate to no more than 61.32%, which is 29.91% improved performance at least.Likewise, the performance in terms of success rate is improved by 100.38% in Task II, 52.85% in Task III and 18.59%in Task IV.In addition, being different from the research efforts on goal-conditioned RL, our method aims at using reward shaping method to solve sparse reward problems for goal-conditioned RL, which is capable of extending the goal setting to not only dynamic target but also dynamic obstacles while holding the optimal policy invariance property at the same time.Moreover, from the large performance gap in terms of success rate between MFRS and AIM, we can deduce that MFRS has the potential to maintain the superiority over other nonlinear reward shaping mechanisms.
From Table I, it can be obtained that MFRS achieves significantly smaller average timesteps over 10 000 learning episodes than all the baselines in all the tasks, which means fewer sampled transitions will be required for the agent to learn the policy.Specifically, in Task I, MFRS achieves 513.1 timesteps in average over all learning episodes while the NS method acquires 939.9 timesteps.It indicates that MFRS obtains a 45.4% reduction of sampling transitions.The decrease of timesteps is 21.6% in Task II, 61.3% in Task III, and 4.3%in Task IV.Hence, our method successfully improves the sample efficiency of RL in the goal-conditioned setting.In summary, being consistent with the statement in Section III-A,it is verified that MFRS is able to provide sufficient and conducive information about the complex environments with various dynamics of the target and obstacles, achieving significant performance for addressing the sparse reward problem in different scenarios.
C. Ablation Study
To figure out how the three critical components of our method affect the performance respectively, we perform additional ablation studies using a control variables approach to separate each process apart as the following variants of MFRS.
1)Without MF(Magnetic Field): The shaping reward is calculated based on Euclidean distance, instead of the magnetic field, with normalization techniques and converted into the form of potential-based reward shaping.
2)Without NT(Normalization Techniques): The shaping reward is calculated based on the magnetic field without normalization techniques and directly converted into the potential-based form.
3)Without SRT(Shaping Reward Transformation): The shaping reward directly follows the form of potential-based reward shaping, with the potential value calculated according to the magnetic field with normalization techniques.
The learning performance in terms of success rate per episode of the three variants as well as MFRS is shown in Fig.7.
First and foremost, the variantwithout MFis compared to MFRS to identify how magnetic field-based shaping reward improves the sample efficiency against distance-based setting.We can observe that MFRS outperforms the variantwithout MFwith a considerably larger success rate per episode in all four tasks.Specifically, in Task III, it takes the variantwithout MF15 000 episodes to achieve a success rate of around 80%, while MFRS only needs 8000 episodes to do that.It verifies that magnetic field-based shaping reward is able to provide a more explicit and informative optimization landscape for policy learning than the distance-based setting.It is consistent with the statement in Section I that the nonlinear and anisotropic properties of the generated magnetic field provide a sophisticated reward function that carries more accessible and sufficient information about the optimization landscape,thus resulting in a sample-efficient method for goal-conditioned RL.
Next, the variantwithout NTis compared to MFRS to verify the effectiveness of normalization techniques.Obviously,when taking no account of any normalization in our method,the algorithm performs terribly in all four tasks, which is worse as the task gets more complex.It verifies the assumption in Section III-C that if the intensity scales of some magnets are much larger than others, it may amplify the effect of these magnets and give an incorrect reward signal to the agent.On the other hand, the tremendous intensity value in the very near region of the target will also exacerbate this problem by inducing the agent to slow down the steps to the target,so that it can obtain higher cumulative rewards than directly arriving at the target and terminating the episode.
Finally, the variantwithout SRTis compared to MFRS for verifying the contribution of Shaping Reward Transformation to the performance of our method.From Fig.7, it can be observed that MFRS outperforms the variantwithout SRTwith improved performance in terms of success rate per episode to some extent, and the performance gap is increasing along the learning process, especially in complex tasks.It verifies that the magnetic reward is more informative and effective when approximated by the potential-based shaping reward instead of being regarded as the potential function for the guarantee of optimal policy invariance.On the other hand, one may alternatively select this simplified form of thewithout SRTvariant to achieve similar effects of MFRS, which avoids learning a secondary potential function at the cost of some performance loss in practice.
V.APPLICATION TO REAL ROBOT
To further demonstrate the effectiveness of our method in the real-world environment, we evaluate the performance of MFRS and baselines on a physical Dobot Magician robotic arm.The robot integrates a low-level controller to move the stepper motor of each joint and provides a dynamic link library (DLL) for the user to measure and manipulate the robot’s state, including the joint angles and the position of the end-effector.Due to the cost of training on a physical robot,we first train the policies in simulation and deploy them on a real robot without any finetuning.The video is available online2https://hongyuding.wixsite.com/mfrs (or https://www.bilibili.com/video/BV1784y1z7Bj).
A. Training in Simulation
From the real-world scenario, we consider a goal-conditioned task with a dynamic target and a dynamic obstacle, as shown in Fig.8(b), and build the same simulated environment accordingly using CoppeliaSim as shown in Fig.8(a).Both the target and obstacle are in the shape of cuboid.The target cuboid has the length, width, and height of 0.03, 0.045,0.02 along thex-axis,y-axis,z-axis in simulation, and 0.038, 0.047,0.12for obstacle cuboid, respectively.The dynamic of the goal is generated by randomly changing the positions of both the target and obstacle in each episode, which are ensured to be not intersectant.The observations, actions, and reward function are consistent with the ones in Section IV, and all the hyper-parameters are set to be the same as those in Section IV-C.
We present the success rate of MFRS and all the baseline methods training on the real-world task in Fig.9, of which the mean across 5 runs is plotted as the bold line with 90% bootstrapped confidence intervals of the mean painted in the shade.Being consistent with the experimental results in Section IV-B, MFRS outperforms all other baselines with a significantly larger success rate on the real-world task in simulation.
B. Validation in the Real-World
To figure out whether MFRS performs well and beats the baseline methods on the real robot, we evaluate the success rate and average timesteps over 20 different testing episodes for each run of each method in the training phase, in which the positions of the dynamic target and obstacle are randomly generated and set accordingly.That is, for each involved algorithm in real-world experiments, we have conducted 1 00 random testing episodes with different settings of the target and obstacle in total.
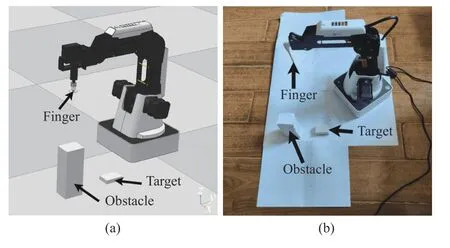
Fig.8.Illustration of the real-world task in (a) simulation environment; and(b) real-world environment.
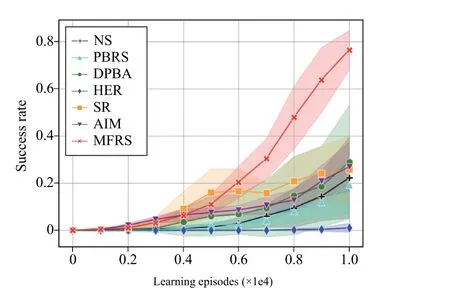
Fig.9.Success rate in each learning episode of all investigated methods training on the real-world task in simulation environment.
In practice, we read the stepper motors’ rotation angles and the end-effector’s coordinate by calling the DLL provided by the Dobot Magician, which are then concatenated to form the agent’s state.The agent’s action in each timestep is obtained by the trained policy, and employed on the real robot as incremental angles to move the three joints using the point-to-point(PTP) command mode of Dobot Magician.During validation,each testing episode starts with the joint angles reset to zero and manually setting the positions of the target and obstacle in the real-world environment that are sampled randomly in simulation, and terminates whenever the “finger” reaches the target, or the robot hits the obstacle or at the horizon ofH=200.To prevent unsafe behaviors on the real robot, we restrict the target’s sample space to half of the reachable area of the “finger”.Computation of the action is done on an external computer, and commands are streamed over the radio at 10Hz using a USB virtual serial port as communication.
We report the numerical results in terms of success rate and average timesteps over 20 testing episodes for each investigated method in Table II, where the mean across five runs using the corresponding policy trained in simulation is presented, and the confidence intervals are the standard errors.From Table II, it can be observed that MFRS achieves a significantly larger success rate and smaller average timestepscompared to all the baselines on the real robots, which is consistent with the results in the simulation experiment.In addition, our method obtains relatively smaller confidence intervals and standard errors than the baselines.It indicates that MFRS can provide stable learning results when employed on a real robot.In summary, it is verified that MFRS is able to handle the goal-conditioned tasks in the real-world scenario using the policy trained in the corresponding simulation environment, providing better performance and successfully improving the sample efficiency of the RL algorithm.
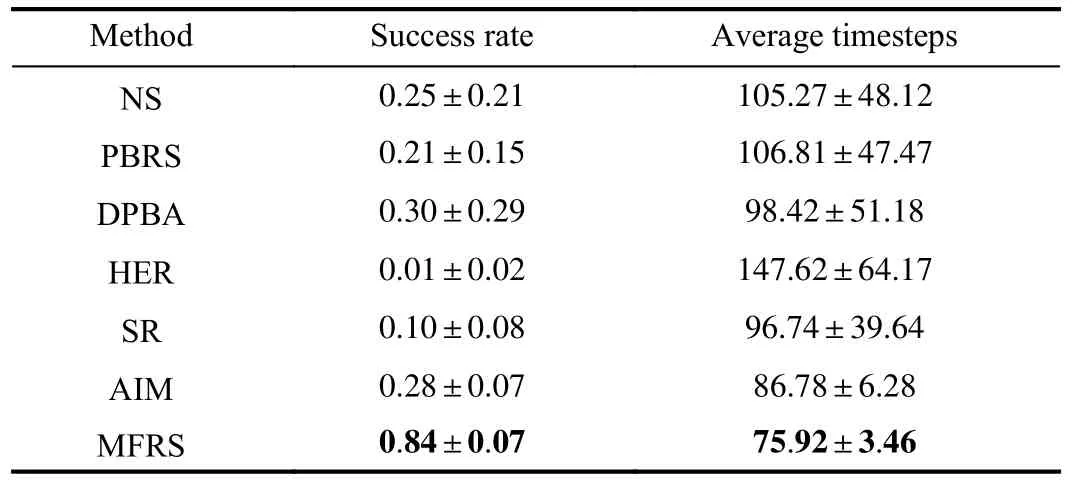
TABLE II NUMERICAL RESULTS IN TERMS OF SUCCESS RATE AND AVERAGE TIMESTEPS OVER 20 TESTING EPISODES OF ALL INVESTIGATED METHODS IN THE REAL-WORLD ENVIRONMENT
VI.CONCLUSION
In this paper, we propose a novel magnetic field-based reward shaping (MFRS) method for goal-conditioned RL tasks, where we consider the dynamic target and obstacles as permanent magnets and build our shaping reward function based on the intensity values of the magnet field generated by these magnets.MFRS is able to provide an explicit and informative optimization landscape for policy learning compared to the distance-based setting.To evaluate the validity and superiority of MFRS, we use CoppeliaSim to build a simulated 3-D robotic manipulation platform and generate a set of goal-conditioned tasks with various goal dynamics.Furthermore, we apply MFRS to a physical robot in the real-world environment with the policy trained in simulation.Experimental results both in simulation and on real robots verify that MFRS significantly improves the sample efficiency in goalconditioned RL tasks with the dynamic target and obstacles compared to the relevant existing methods.
Our future work will focus on extending MFRS to the scenario with high-dimensional goals using the concept and properties of the magnetic field, and further generalizing to more diversified real-world tasks apart from the area of robotic control.Another significant direction would be incorporating some perception abilities with the decision-making RL, e.g.,equipping the robot with additional sensors to obtain the pose of the dynamic target and obstacles, to fuse MFRS into an end-to-end integrated pipeline for more practical real-world validation of robotic systems.
APPENDIx PROOF OF THE OPTIMAL POLICY INVARIANCE OF MFRS
Theorem 2: LetM=(S,G,A,T,R,γ) be the original MDP with the environment rewardR, andM′=(S,G,A,T,R′,γ)be the shaped MDP with the shaped rewardR′=R+F, where

Proof: According to UVFA [22], the optimal goal-conditioned Q-function inMshould be equal to the expectation of long-term cumulative reward as
Likewise, the optimal goal-conditioned Q-function inM′can be denoted as
According to (20), we have

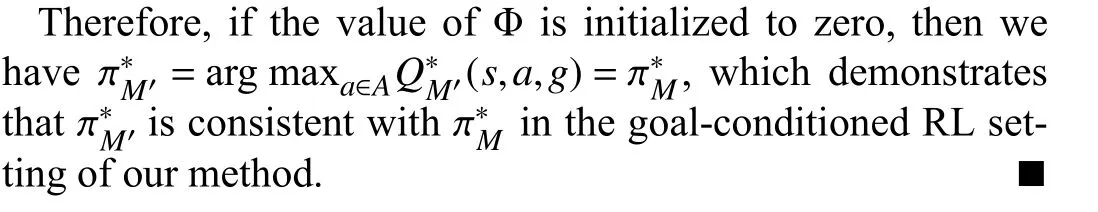
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Game Theoretic Approach for a Minimal Secure Dominating Set
- Knowledge Transfer Learning via Dual Density Sampling for Resource-Limited Domain Adaptation
- Subspace Identification for Closed-Loop Systems With Unknown Deterministic Disturbances
- Multi-Blockchain Based Data Trading Markets With Novel Pricing Mechanisms
- GenAI4Sustainability: GPT and Its Potentials For Achieving UN’s Sustainable Development Goals
- Resilient Event-Triggered Control of Connected Automated Vehicles Under Cyber Attacks