基于增强层次注意熵和极限学习机的轴承故障检测方法*
2023-12-20朱文轩张书维
朱文轩,张书维,王 琳
(江苏安全技术职业学院 机械工程学院,江苏 徐州 221011)
0 引 言
滚动轴承是旋转机械中最为常见的零部件,大约有40%的机械故障是由滚动轴承故障引发的[1]。滚动轴承发生故障后,轻则会加剧设备的振动噪声,影响工作人员的操作舒适性和加工精度,重则造成设备无法工作并引发安全事故。因此,研究滚动轴承的故障诊断方法对确保安全稳定生产具有重大意义。
滚动轴承在运行时受到负载、摩擦和阻尼等非线性因素的影响,导致采集的振动信号表现出强烈的非线性和非平稳性,如何从非线性的时间序列中提取出高质量的故障特征,成为滚动轴承故障诊断的关键[2-3]。
目前,由于理论解释性好,特征提取性能优异,基于熵理论的特征提取方法被广泛应用于滚动轴承的故障诊断领域[4]。HAN Ming-hong等人[5]将局部均值分解和样本熵相结合,进行了故障特征提取,有效分辨了轴承的不同故障状态;但是,样本熵在分析长时间序列时,故障特征提取效率较为低下。随后,杨云等人[6]提出了一种基于变分模态分解和排列熵的滚动轴承故障诊断模型,借此模型有效识别了轴承的故障;然而排列熵忽视了数据振幅之间的区别,导致了轴承故障信息的丢失。为此,陈剑等人[7]提出了基于改进固有时间尺度分解和模糊熵的滚动轴承故障诊断模型,借此模型对滚动轴承不同故障进行了准确分类;然而模糊熵的特征提取效率非常低下。为缓解上述熵的缺陷,ROSTAGHI M等人[8]提出了一种新的测量时间序列复杂度的方法——散布熵,其不仅能准确区分信号的幅值差异,而且可以显著提高故障分析的效率。叶震等人[9]将模糊信息粒化和散布熵相结合,用于滚动轴承的故障诊断,有效识别了轴承的不同故障类型。
无论是排列熵、模糊熵还是散布熵,在特征提取阶段均需要设置2个及以上的超参数,削弱了算法的泛化性。为此,YANG Jia-wei等人[10]提出了一种新的测量时间序列复杂性的工具——注意熵(attention entropy,ATE)。与传统熵值关注信号中全部数据的频率分布不同,ATE仅关注了信号峰值点间隔的频率分布情况,因此ATE具有参数少、运行效率高和对数据长度不敏感的优点。
然而,ATE只提取了信号的单个尺度特征,滚动轴承的振动包含多个模态特征,仅开展单一尺度分析,无法全面提取滚动轴承的故障特征频率信息[11]。为此,陈飞等人[12]359-360提出了多尺度注意熵(multiscale attention entropy,MATE)和时移多尺度注意熵(time-shifted multiscale attention entropy,TSMATE),并将其用于水电机组的故障诊断,有效提取了多个尺度的故障特征,从而准确区分了不同故障状态;然而MATE的粗粒化处理存在较大的缺陷,丢失了大量故障信息,且造成了较大的偏差。CHEN F等人[13]对粗粒化进行了改进,提出了改进多尺度注意熵(improved multiscale attention entropy,IMATE),其有效区分了旋转机械的故障状态;但是,上述基于粗粒化处理的注意熵指标只能提取振动信号中的低频故障特征,却忽略了信号中同样重要的高频故障特征[14]。
为提取滚动轴承振动信号的低频和高频特征信息,朱可恒等人[15]通过层次分析进行了多尺度计算,提出了基于层次样本熵的滚动轴承故障诊断方法,对滚动轴承故障进行了准确识别;然而传统的层次分析面临着和传统粗粒化处理类似的缺陷,即随着分解层数的增加,层次序列的长度会显著减少,使得分析误差增大且丢失特征信息[16]。为此,柏世兵等人[17]对传统的层次分析方法进行了改进,提出了一种改进的层次分析方法,并采用轴承的诊断结果验证了改进方法的有效性;但其采用的熵值指标需要设置较多的超参数。
在损伤识别方面,极限学习机(ELM)具有较高效率,同时还具有较强的分类性能,因此被广泛应用于滚动轴承的故障识别领域[18]。但是ELM的输入层权重和隐含层偏置需要人为设定,为此,笔者引入基于灰狼算法(GWO)优化的极限学习机(GWO-ELM)代替原始的ELM,进行特征样本的识别。
综上所述,为了实现在较少参数下提取非线性、非平稳振动信号的故障特征,笔者将增强的层次分析和注意熵相结合,提出增强层次注意熵(EHATE);并在此基础上,提出一种基于EHATE和GWO-ELM的滚动轴承故障诊断方法(其中,EHATE方法用于提取滚动轴承振动信号的低频和高频特征信息,而GWO-ELM用于进行滚动轴承的故障识别);利用3组滚动轴承数据集对该方法进行实验验证和分析,并开展多个方面的对比研究。
1 增强层次注意熵
目前,排列熵、模糊熵、散布熵等指标被广泛用于轴承的故障诊断领域,但这些方法的多个参数需要预先设置,算法的泛化性较差。同时,为了实现信号的多维度分析,以粗粒化处理为代表的多尺度方法及其改进方法应用广泛,但这些方法无法提取信号的高频特征,遗漏了大量故障信息。
为此,笔者充分考虑了这些方法的缺陷,提出了增强层次注意熵(EHATE),其不仅避免了算法在特征提取过程中需要设置大量参数的缺陷,而且能够提取信号的高频特征。
1.1 注意熵
和传统的熵值方法相比,注意熵(ATE)对分析数据的长度不敏感,且不需要设置任何的超参数,优势较为显著,其实现过程如图1所示。
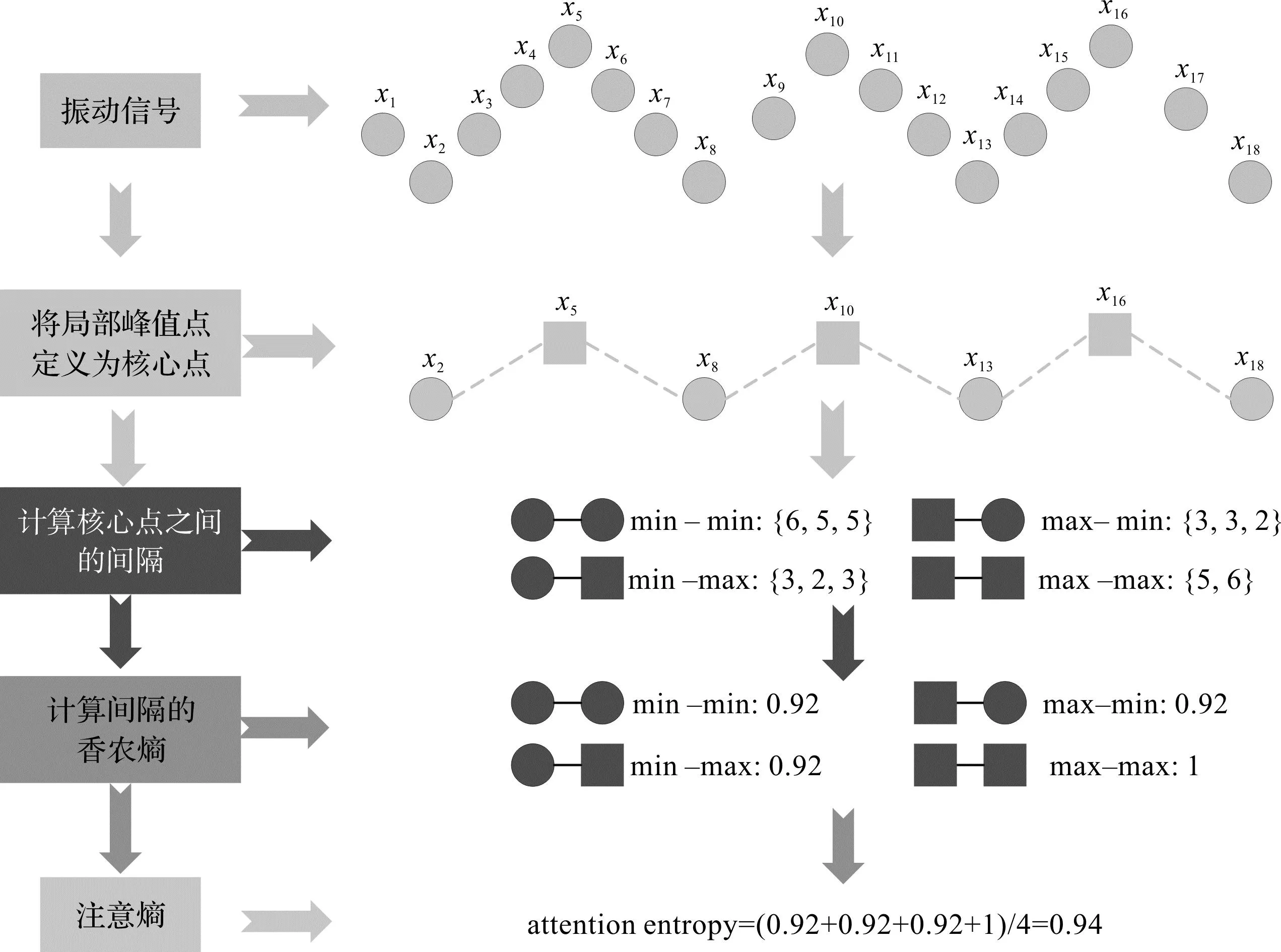
图1 注意熵的示意图Fig.1 The diagram of attention entropy
ATE的计算过程可总结如下:
1)若振动信号中的每个数据点都被假定为一个系统,其状态的变化可以视为系统对环境的调整。峰值点可以准确反映局部状态的上下边界的变化情况,因而将局部峰值点定义为核心点;
2)按照{min-min}、{min-max}、{max-min}和{max-max}4种不同策略给定核心点,并获取相邻核心点的间隔;
3)求解相邻核心点间隔香农熵,公式如下:
(1)
式中:p(x)为x出现的概率;b为间隔点种类个数;
4)将4种不同策略求解得到的香农熵均值定义为该振动信号的注意熵。
1.2 增强层次注意熵
ATE只是从单个尺度描述信号的复杂性,无法全面地表征信号的固有特性。为此,COSTA M等人[19]提出了多尺度熵的概念,将时间序列分割为多个长度较短的子序列,实现了从多个尺度分析信号的固有特性目的。然而,基于粗粒化处理的多尺度计算方法只是提取信号的低频特征,忽略了信号的高频特征。为此,JIANG Ying等人[20]对时间序列进行层次化处理,提出了平均算术符和差分算术符的概念,对信号进行多尺度分析的同时还提取了信号的低频和高频特征。但随着分解层数的增加,信号的长度会缩短,导致其可靠性下降。此外,传统层次分析对信号长度有特殊要求,限制了算法的广泛应用。
为此,笔者将层次熵和注意熵相结合,使用移动平均和移动差分过程来取代原始的层次分解过程,提出增强层次注意熵(EHATE),以缓解传统层次熵层次分解不彻底和参数难以准确设置等问题。
EHATE的原理如下:
1)对于信号{x(i),i=1,2,…,L},定义平均算术符Q0和差分算术符Q1如下:
(2)
式中:Q0(x)为信号x(i)的低频分量;Q1(x)为信号x(i)的高频分量;
(3)
3)构造向量{γ1,γ2,…,γk},则整数e可以定义如下:
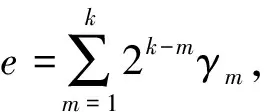
(4)
式中:γm为第m层的平均或差分运算符;
4)基于向量{γ1,γ2,…,γk},则信号x(i)的层次分量定义为:
(5)
5)求解每个层次分量的注意熵,则增强层次注意熵可以定义为:
EHATE(x,k)=ATE(Xk,e)
(6)
1.3 参数分析和仿真对比
在EHATE中,需要预先输入的参数是层次分解层数k,同时信号x(i)的长度L也需要合理的设置。通常来说,参数k设定为3或4,当小于3时,所提取的特征数量太少,无法体现信号在多个尺度上的复杂性,导致信号固有特性表征的不够全面;反之当k大于4时,会导致特征的数量过多,如k=5时,特征的数量达到了32个,这不仅增加了特征提取时间,而且增加了特征冗余度[21]。
因此,笔者将k设置为3,后续将就k的取值对算法性能的影响做进一步分析。
信号长度L对EHATE性能的影响较小,但长度通常不小于1 024,否则样本中包含的峰值点较少,无法准确表征信号的趋势和固有特性。
在陈飞等人[12]361-362的研究中,对不同长度1/f噪声的TSMATE和MATE性能进行了研究,结果表明TSMATE对数据长度不敏感。
为此,笔者在前人工作的基础上,对不同长度白噪声(white gaussian nosie,WGN)和1/f噪声的EHATE、层次注意熵(hierarchical attention entropy,HATE)和MATE进行了分析。
3种方法的噪声分析结果随长度的变化如图2所示。
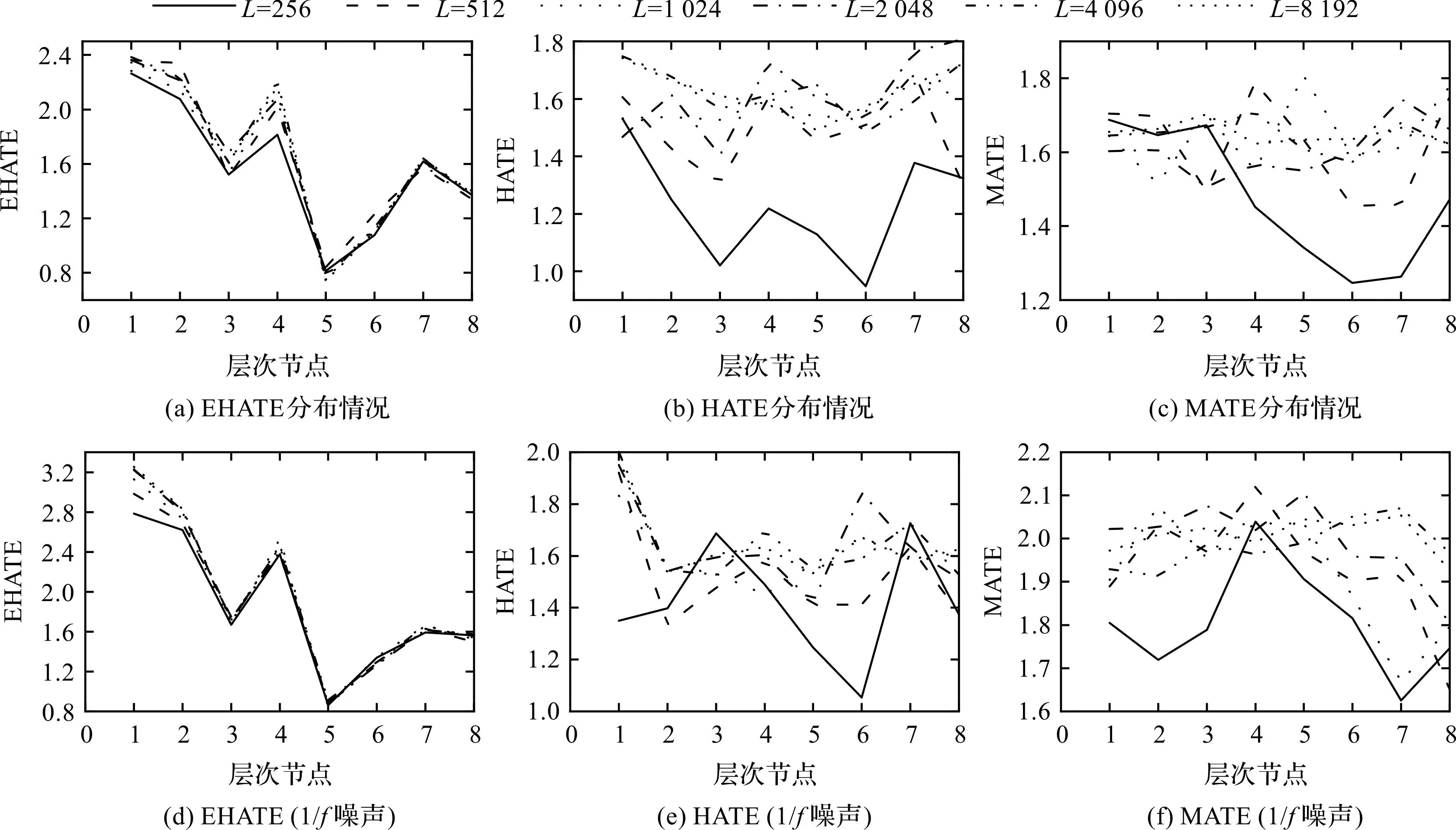
图2 EHATE、HATE和MATE的分布情况Fig.2 Distribution of EHATE, HATE and MATE
在图2中,对比2种不同长度噪声的EHATE、HATE和MATE的结果发现,随着数据长度的减小,HATE和MATE的波动逐渐变大,特别是在节点较大的时候熵值发生了突变(以数据长度L=256的WGN噪声信号为例,在层次节点为5、6和7时,HATE熵值变化非常剧烈)。
此外,不同长度噪声信号的HATE和MATE值分布的差异过大,对于同一节点,WGN和1/f噪声的HATE和MATE波动的最大幅值分别达到了0.626、0.481、0.790和0.445。
以上结果证明,在分析同一种信号时,短信号的分析结果和长信号的HATE和MATE分析结果存在较大的差异。
而不同长度噪声信号的EHATE的分布差异较小,在各个节点上仅存在较小的波动,WGN和1/f噪声的EHATE的最大波动幅值仅为0.393和0.471,说明EHATE在分析不同长度的信号时能产生一致的熵值分布;并且,随着节点的增加,EHATE值重叠得更加紧密,表明EHATE对信号长度有着较强的鲁棒性。
为了进一步评估EHATE、HATE和MATE的分析稳定性,笔者首先构造了50组长度为2 048的WGN和1/f噪声信号,随后利用3种方法计算这50组噪声信号的熵值,并提取其标准差,结果如图3所示。
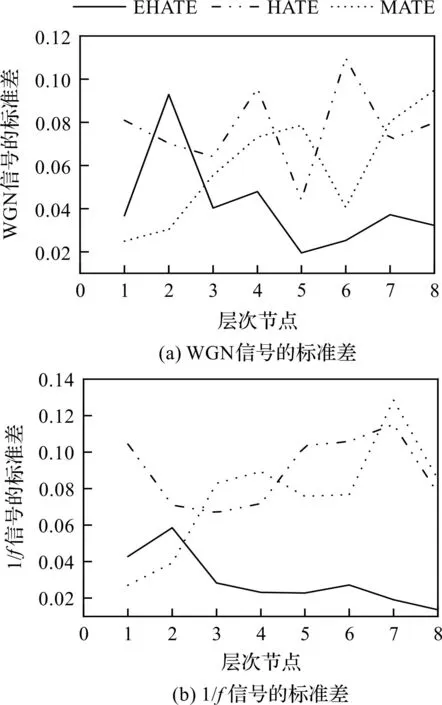
图3 WGN和1/f信号的EHATE,HATE和MATE分析标准差Fig.3 Analysis standard deviations of EHATE, HATE and MATE for WGN and 1/f signals
由图3可知:在尺度大于2后,EHATE的标准差就小于HATE和MATE方法的标准差,趋于一个较小的水平。对于1/f信号而言,HATE和MATE的标准差随着节点的增加而逐渐增大,特别是在节点为7时,HATE和MATE的标准差达到了最大,表明这2种方法的分析误差在节点数较大时会比较大,结果不够稳定。
虽然,在节点数小于2时,EHATE的标准差大于MATE方法的标准差,但总体上,通过构造平均和差分算术符,使得EHATE具有提取信号低频和高频特征的能力,因而优于MATE。
2 基于EHATE和GWO-ELM的诊断方法
2.1 灰狼算法优化的极限学习机
2.1.1 极限学习机
极限学习机(ELM)为单隐层的神经网络,若有N个随机样本(xi,yi)|xi∈Rm,yi∈Rn,则包含L个隐藏层节点的ELM模型可表示如下:
(7)
式中:βj为链接第j个隐藏层节点与模型输出节点的输出权重矢量;g(x)为隐藏层神经元的激活函数;ωj为链接模型输出节点与第j个隐藏层节点的输入权重矢量;bj为第j个隐藏层节点的偏置;yi为样本的模型输出,yi=[yi1,yi2,…,yin]T。
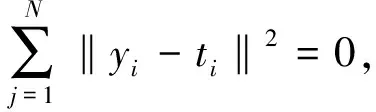
(8)
上式变为矩阵形式,如下:
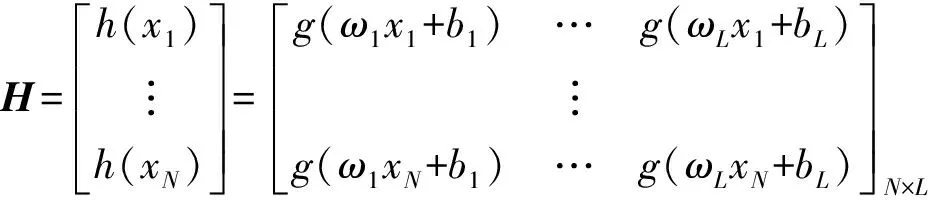
(9)
此时,输出权重矩阵β=[β1,β2,…,βL]T可定义如下:
β=H+T
(10)
式中:H+为隐藏层输出矩阵H的广义逆矩阵。
2.1.2 优化流程
极限学习机的分类性能优异,并且效率高,但是其2个核心参数需要人为设置,这导致算法容易过拟合或欠拟合,降低算法的性能。为此,笔者引入了基于灰狼算法优化的极限学习机,进行特征的识别。
其优化流程如下:
1)对原始数据进行归一化预处理,并将样本随机地划分出训练样本和测试样本;
2)设置GWO算法的种群规模和迭代次数,将ELM的输入权重和隐藏层阈值设置为优化目标,适应度函数设置为故障识别的平均错误率,通过不断地迭代,以搜索错误率最小时所对应的参数;
3)计算灰狼个体的适应度函数,并不断更新参数,如果迭代过程中符合终止条件,则输出对应的最优参数,否则继续执行迭代;
4)将迭代得到的最优参数代入至ELM模型中,并利用样本对ELM进行训练和测试,输出测试样本的故障识别结果。
GWO-ELM的详细理论以及参数设置可参考栾孝驰等人[22]的研究。
2.2 故障诊断流程
基于前面的分析,EHATE只需要输入2个参数,分别是信号数据长度L和分解层数k。对于信号数据长度,分析结果表明EHATE的鲁棒性较强,对于数据长度不敏感,为此笔者设置数据长度L=2 048。在该数据长度下,2种噪声信号的EHATE、HATE和MATE分析结果表明,EHATE的分析稳定性优于另外2种方法。
因此,鉴于EHATE所需参数少、性能优异的优点,结合已被证明具有优异性能的GWO-ELM分类器,笔者提出一种基于EHATE和GWO-ELM的滚动轴承故障诊断方法。
具体诊断流程如下所示:
1)利用振动加速度计采集滚动轴承的不同工况下的振动信号,将其作为原始的数据样本;
2)将每个工况的振动信号样本平均分割成长度为2 048的50组样本,其中25组样本作为训练样本,剩余25组样本作为测试样本;
3)利用EHATE提取训练和测试样本的前8个熵值,构造故障特征;
4)将训练样本的故障特征输入至GWO-ELM模型进行训练,待训练完毕后输入测试样本,以进行故障识别;
5)根据GWO-ELM的输出标签对滚动轴承样本的故障类型和故障程度进行诊断,并进行模型有效性的评估。
3 故障诊断实验和结果分析
为了验证EHATE+GWO-ELM方法的有效性,并评估该模型对2个参数的敏感性,笔者分别利用江南大学[23]、东南大学[24]和印度某大学的滚动轴承数据集[25]进行实验验证。
3.1 江南大学轴承数据
江南大学的滚动轴承数据集包含4种不同的工况,分别是健康(Nor)、内圈故障(IR)、外圈故障(OR)和滚动体故障(BA);数据的采样频率为50 kHz;轴承的转速包含600 r/min、800 r/min和1 000 r/min 3种,笔者选择800 r/min下的数据进行实验。训练样本为100组,测试样本为100组。
4种轴承样本的振动信号的时域波形如图4所示。
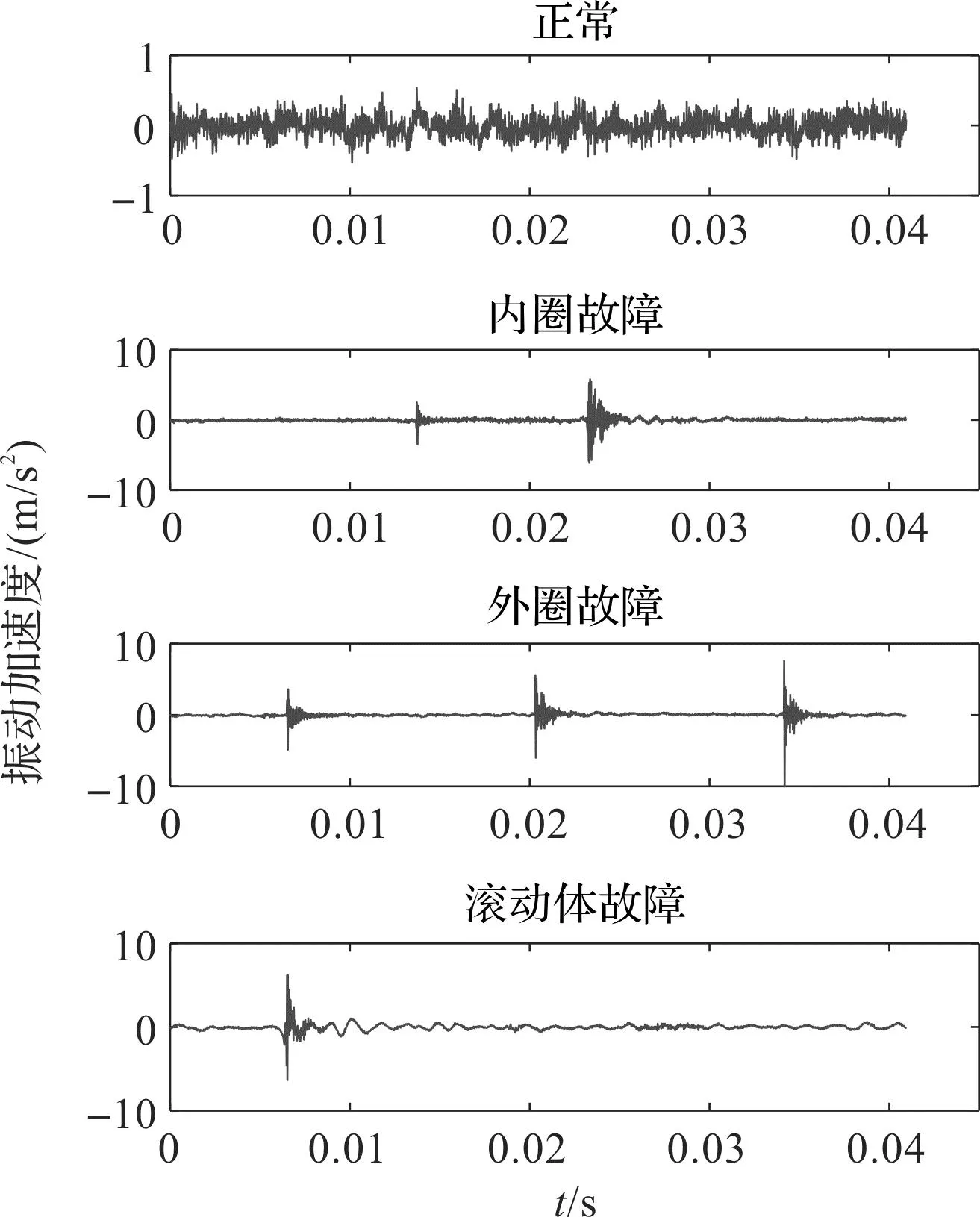
图4 滚动轴承振动信号的波形Fig.4 Waveform of vibration signal of rolling bearing
由图4可以发现:不同振动信号中所包含的冲击成分不一致,具有较大的差异性,但无法直接根据波形确定区分准则。
笔者利用EHATE提取滚动轴承振动信号的故障特征,随后将故障特征输入至GWO-ELM模型中,进行故障识别,得到滚动轴承故障诊断结果,如图5所示。
从图5(a)可以发现:EHATE特征曲线在各个节点都具有相同的趋势,无法直接根据特征曲线来分辨样本的故障类型。

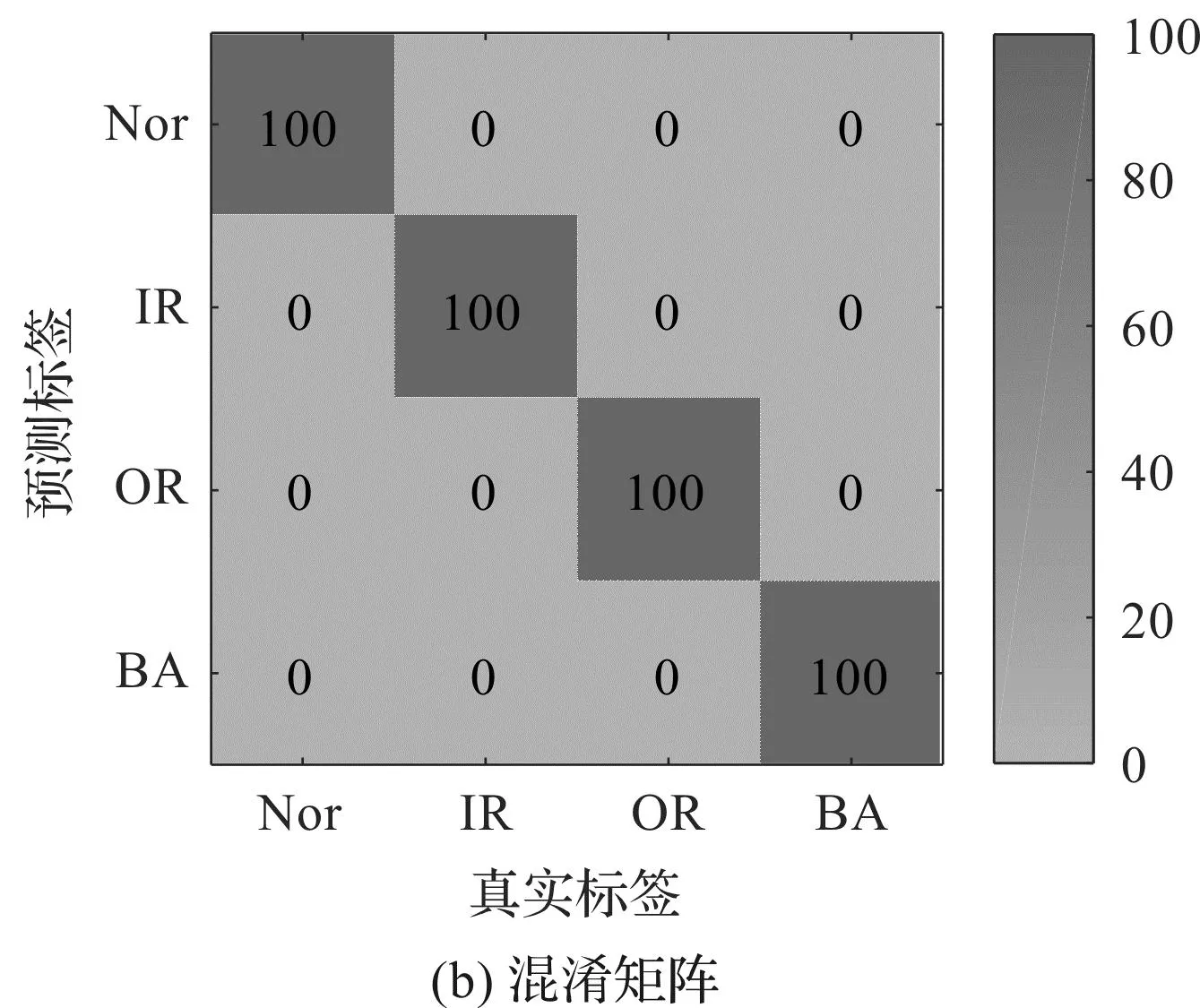
图5 EHATE故障特征和对应的故障识别结果Fig.5 EHATE fault characteristics and corresponding fault identification results
而从图5(b)可以发现:EHATE+GWO-ELM方法取得了100%的识别准确率,证明该方法可以有效地识别滚动轴承的不同故障类型。
随后,为了验证EHATE方法的特征提取性能对数据长度L和分解层数k2个不同参数的敏感性,笔者对不同参数组合下EHATE+GWO-ELM方法的分类结果进行了评估,结果如图6所示。
由图6可知:随着数据长度和分解层数的增加,EHATE+GWO-ELM方法的分类准确率也随之增加,表明这2个参数对算法的性能影响是正向的。当数据长度大于2 048后,即使分解层数为1,准确率也能够达到90%以上;当分解层数为2时,准确率也达到了98%;当分解层数为3时,准确率达到了100%,证明该方法仅需要常规的参数设置(L=2 048,k=3)即可获得较为可靠的故障识别结果。
为了评估EHATE+GWO-ELM方法的优越性,笔者利用HATE、MATE、TSMATE、精细复合多尺度样本熵(refined composite multiscale sample entropy,RCMSE)、精细复合广义多尺度模糊熵(refined composite generalized multiscale fuzzy entropy,RCGMFE)、层次排列熵(hierarchical permutation entropy,HPE)、增强层次散布熵(enhanced hierarchical dispersion entropy,EHDE)进行对比,将上述方法提取的故障特征输入至GWO-ELM中进行故障识别,并重复10次,同时统计每种方法的特征提取时间和平均分类准确率,结果如表1所示。
表1 不同故障特征提取方法的诊断结果对比
Table 1 Comparison of diagnosis results of different fault feature extraction methods

特征提取方法参数设置平均准确率/%标准差特征提取时间/sEHATEk=398.201.1493.52HATEk=372.102.9231.17MATEs=896.002.113.92TSMATEs=896.700.9512.71RCMSEm=2;r=0.2;t=1;s=885.803.9966.10RCGMFEm=2;r=0.2;n=2;t=1;s=872.802.20122.55HPEm=5;t=1;k=368.402.6857.13EHDEm=3;c=6;t=1;k=398.501.08108.88
由表1可知:在准确率方面,EHDE的平均准确率最高,达到了98.50%,EHATE的准确率次之,为98.20%,相差较小;在特征提取时间方面,MATE的效率最高,为3.92 s,对应的平均准确率为96%;在标准差方面,TSMATE的标准差最小,为0.95,对应的准确率为96.70%。虽然EHDE的准确率高于EHATE,但其特征提取效率低于EHATE,同时其需要额外设置3个参数,该算法对参数的敏感性较强。而MATE和TSMATE方法不仅具有较高的准确率,同时特征提取的效率也较高。
综合上述对比结果,虽然EHATE的特征提取时间增加了,但在准确率和稳定性等多个指标上都优于其他方法。此外,最关键的是EHATE设置的参数少,这提高了该方法的泛化性。虽然MATE、TSMATE、HATE方法都只需要设置一个参数,但EHATE方法的准确率明显高于这几种方法。
综合来看,该方法的性能是比较优秀的。
3.2 东南大学轴承数据
为了进一步验证EHATE+GWO-ELM方法的有效性,笔者利用东南大学提供的滚动轴承数据进行实验。实验平台如图7所示。

图7 东南大学滚动轴承故障模拟实验台Fig.7 Rolling bearing fault simulation test bench in Southeast University
在该实验平台中,振动传感器布置在行星齿轮箱表面,以5 120 Hz的频率采集滚动轴承的振动信号,笔者利用模拟器将系统的转速和负载调整至20 Hz和0 V,将健康轴承(NOR)分别替换为存在滚珠故障(BA)、内圈故障(IR)、外圈故障(OR)、内圈&外圈故障(IO)的轴承,以此来模拟系统不同状态下的运行情况。
训练样本为125组,测试样本为125组,5种轴承样本的振动信号的时域波形如图8所示。
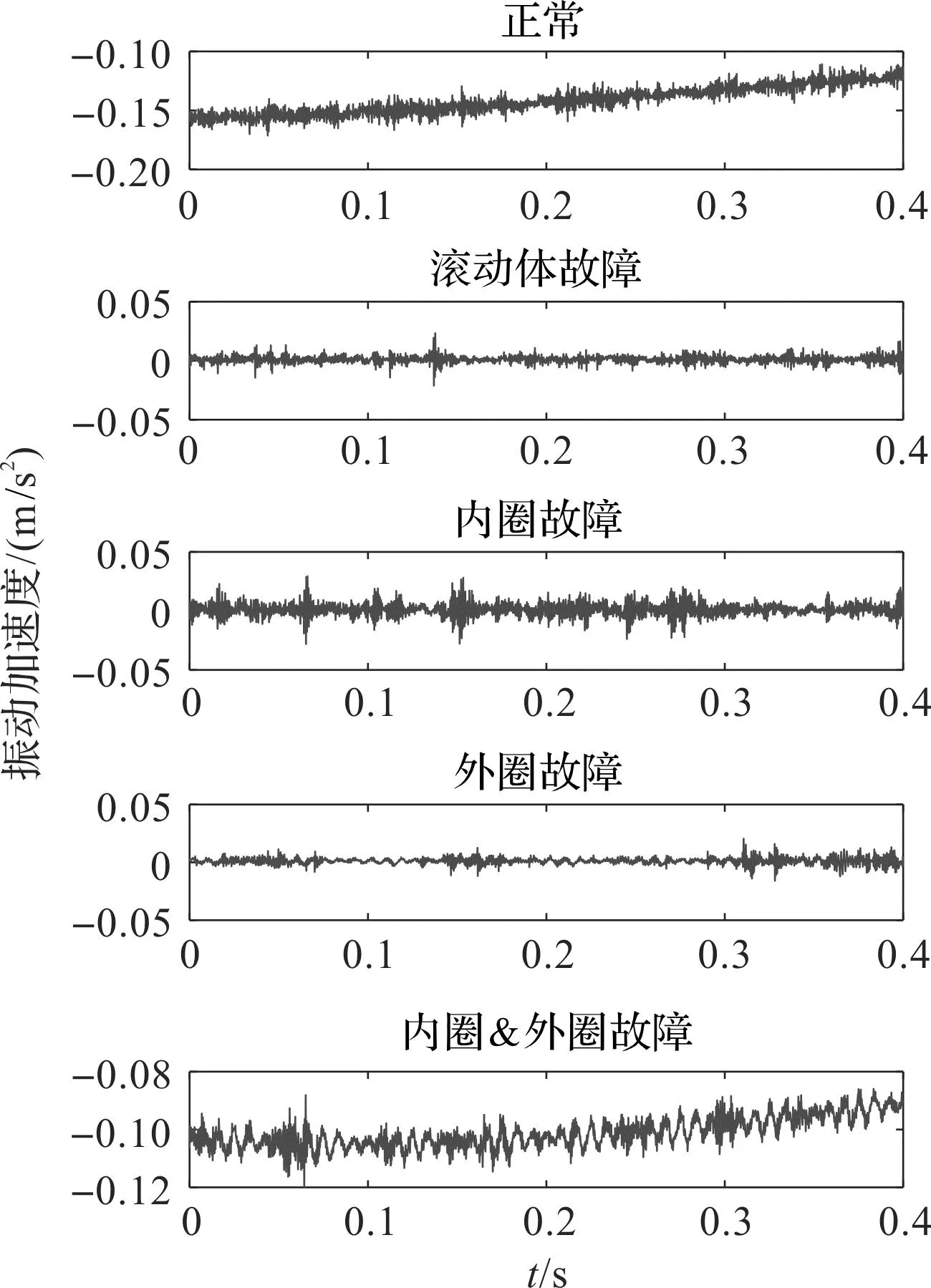
图8 滚动轴承振动信号的波形Fig.8 Waveform of vibration signal of rolling bearing
由图8可以发现:振动信号波形比较复杂,缺乏显著的规律,有必要采用EHATE+GWO-ELM方法进行样本的故障识别。
笔者利用EHATE提取滚动轴承振动信号的故障特征,随后,将故障特征输入至GWO-ELM模型中进行故障识别,诊断结果如图9所示。
由图9可知:EHATE熵值特征在各个节点上具有比较好的区分度,证明利用EHATE提取振动信号的低频和高频故障特征,能够较好地区分滚动轴承的不同故障状态。
图9(b)的GWO-ELM故障识别结果也验证了EHATE+GWO-ELM方法的良好性能,仅IO样本出现了一个被错误识别的样本,其他样本都被准确地识别出来,总的准确率为99.2%,证明该方法能够准确地识别滚动轴承样本的故障类型。
为了进一步验证EHATE方法的性能对数据长度L和分解层数k的参数敏感性,笔者对不同参数组合下EHATE+GWO-ELM方法的性能进行了评估,如图10所示。

图10 不同参数组合下EHATE+GWO-ELM方法的诊断准确率Fig.10 The diagnostic accuracy of the EHATE+GWO-ELM method under different parameter combinations
由图10可知:在数据长度较小时,EHATE+GWO-ELM方法的准确率较低,即使特征数量增加到32个,准确率也仅为85.6%。
而当数据长度为4 096时,即使特征的数量只有2个,准确率也达到了84%,这证明数据长度是影响算法性能的主要因素,若同时增加数据长度和特征的数量,则准确率会得到显著提高。
当数据长度为2 048,分解层数为3时,该方法的准确率已经可以达到99.2%,证明此时该方法能够有效地识别滚动轴承的故障类型,同时进一步证明了该方法在常规的参数设置下能够获得较为可靠的故障识别结果。
为了进一步评估EHATE+GWO-ELM方法的优越性,笔者利用前面的7种方法进行同样的对比,结果如表2所示。

表2 不同故障特征提取方法的诊断结果对比
由表2可知:TSMATE的平均准确率最高,达到了99.28%,同时标准差也只有0.79,优于EHATE方法,证明时移粗粒化处理也能够有效地提取滚动轴承振动信号中的故障信息。除了TSMATE方法之外,EHATE方法的准确率最高,同时稳定性也较高,证明了该方法的有效性。
综合来看,EHATE+GWO-ELM方法的准确率比较高,虽然效率不高,特征提取的时间仅少于EHTE和RCGMFE,但由于其对参数不敏感,因此具有相对均衡的性能。
3.3 印度大学轴承数据
为更进一步验证EHATE+GWO-ELM方法在诊断滚动轴承不同故障类型和不同严重程度中的有效性,笔者利用印度Sant Longowal工程技术学院提供的滚动轴承数据集进行实验。
滚动轴承实验平台如图11所示。

图11 滚动轴承实验平台Fig.11 Rolling bearing test platform
实验中,滚动轴承的型号为NU205E的滚子轴承,笔者利用加速度计,以70 kHz的频率采集其在运行时的振动信号(其中,滚动轴承的转速为2 050 r/min,负载为200 N)。
为了模拟存在不同轴承故障时系统的运行状态,笔者将正常轴承替换为不同故障类型和不同故障程度的轴承,进行振动测量实验。
实验中,共有4种类型的轴承,分别是正常轴承、滚珠故障轴承、内圈故障轴承和外圈故障轴承。对于3种故障类型的轴承,存在4种故障程度,分别是轻度、中度、重度和超重度,因此,总共有13种故障类型的轴承样本。
样本的详细信息如表3所示。

表3 滚动轴承样本的故障信息
13种轴承样本的振动信号的时域波形如图12所示。
由图12可以发现:由于故障状态较多,且波形成分复杂,缺乏显著的规律,无法通过人为观察来判断样本的状态,有必要采用EHATE+GWO-ELM方法进行样本的故障识别。

图12 滚动轴承振动信号的波形Fig.12 Waveform of vibration signal of rolling bearing
笔者利用EHATE提取滚动轴承样本的故障特征,随后将故障特征输入至GWO-ELM中,进行故障识别,结果如图13所示。

图13 EHATE故障特征和对应的故障识别结果Fig.13 EHATE fault characteristics and corresponding fault identification results
由图13(a)可知:不同样本的熵值特征曲线具有类似的趋势,并且由于样本类型较多,曲线互相重叠,难以直接根据波形判断样本的状态。
由图13(b)可知:EHATE方法的GWO-ELM诊断准确率为96.92%,出现了10个被错误识别的样本,有5种类型的样本出现了错误样本(即:4个BA2样本被错误识别为BA4,2个BA3样本被错误识别为BA2,1个BA4样本被错误识别为BA2,1个IR3样本被错误识别为IR4,1个OR3样本被错误识别为IR3,1个OR3样本被错误识别为IR4),剩余8个类型的样本都被准确地分类。
根据该诊断结果,可以验证EHATE+GWO-ELM方法能够较为有效地识别滚动轴承不同故障类型和故障程度,具有一定的应用潜力。
同样地,笔者对EHATE方法在不同参数设置下的特征提取性能进行了研究,结果如图14所示。
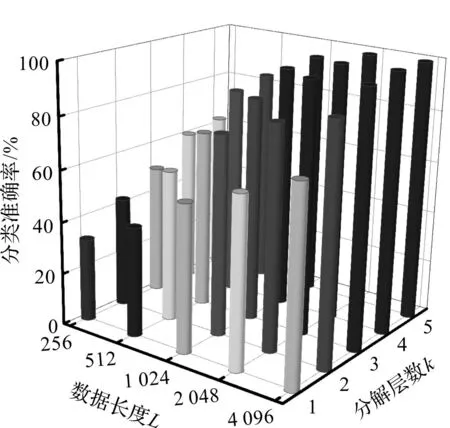
图14 不同参数组合下所提方法的诊断准确率Fig.14 The diagnostic accuracy of the proposed method under different parameter combinations
由图14可知:当数据长度不小于1 024,分解层数不小于3层时,EHATE+GWO-ELM方法能够取得了不低于90%的分类准确率;同时随着参数的增加,准确率随之增加,但特征提取的时间也随之显著提高,因此需要在效率和性能之间进行综合考虑。
当数据长度为2 048,分解层数为3时,该方法的准确率为96.92%;而当数据长度为4 096,分解层数为4时,准确率达到了100%,然而此时特征提取时间是前者的7倍。
因此,该方法只需要采用常规的参数组合,即可以获得较高的性能和效率。
同样的,笔者对前述7种方法进行了多次实验,取平均准确率和特征提取时间进行对比,结果如表4所示。

表4 不同故障特征提取方法的诊断结果对比
由表4可知:EHATE的平均分类准确率最高,达到了95.26%,其次是TSMATE方法,为89.23%;而EHATE方法的标准差也最小,为0.88;特征提取效率最高的是MATE方法,为15.39 s,而EHATE方法的效率为370.07 s。
综合准确率、稳定性和效率3个方面而言,EHATE+GWO-ELM方法的综合性能最优。因此,该方法能够稳定且有效地诊断滚动轴承的不同故障类型和故障程度。
此外,EHATE方法由于仅需设置较少的参数,更适合用于故障特征提取阶段。
4 结束语
鉴于常规滚动轴承故障诊断方法面临准确率不高、稳定性差和参数设置较多的缺陷,笔者提出了一种基于EHATE和GWO-ELM的滚动轴承故障诊断方法,并利用3种滚动轴承故障数据集对该方法进行了实验和分析。
研究结论如下:
1)EHATE方法由于仅需要设置数据长度和分解层数2个参数,其相较于其他方法对参数不敏感,采用常规的参数设置即可以获得良好的故障识别结果;当样本的数据长度为N=2 048,而分解层数k=3时,准确率能够达到95%以上;
2)EHATE的性能优异,能够有效地反映信号的复杂度特性,仿真信号的分析结果验证了EHATE优于HATE和MATE;
3)基于EHATE和GWO-ELM的故障诊断方法能够有效地诊断滚动轴承的不同故障类型,识别准确率分别达到了100%、99.2%和96.92%,而多次实验的平均识别准确率分别为98.2%、99.12%和95.26%,在识别稳定性和识别准确率方面优于其他7种对比方法,更适合用于滚动轴承的故障诊断。
虽然EHATE方法取得了不错的故障识别结果,但是其特征提取效率有待提高。后续笔者将对粗粒化方式进行优化,以进一步提高特征提取的效率。
