基于混合深度学习的原油价格预测
2023-12-19牛东晓崔曦文
牛东晓,崔曦文
(1. 华北电力大学 经济与管理学院, 北京 102206;2. 新能源电力与低碳发展研究北京市重点实验室, 北京 102206)
能源是经济发展的基础,当前全球面临着能源短缺的问题,如何保持可持续发展成为了热点问题。为保证经济健康发展,各个国家制定了许多货币、财政等经济政策,导致世界各国经济政策不稳定性提高,原油价格受此影响进而影响股票市场[1]。由于国际原油价格大幅波动,中国面临很大的原油价格风险,因此准确预测原油价格将会对稳定原油金融衍生品市场、减少油价大幅波动对风险对冲经济的影响、制定合理的石油进口监管体系等方面有重要的现实意义[2]。
一、文献综述
目前,学者们对原油价格预测研究的常用方法包括传统计量预测方法、机器学习预测方法以及深度学习预测方法等单一模型价格预测以及多种预测方法相结合的混合模型价格预测。
计量经济模型将数学、统计学与经济学相结合,根据历史数据来预测石油价格走势,许多学者都用其进行原油价格的预测[3-5]。然而通常利用计量经济学模型进行建模时,对原始数据的检验、差分等要求较高,数据处理过程中可能出现信息数据丢失等问题,且在预测过程中,整个流程存在一定的主观因素。
近年来,得益于计算机的发展,机器学习迅速发展,作为一门多个领域互相交叉的新学科,在原油价格预测领域得到广泛的利用[6]。张明昊和卓翔芝利用支持向量机方法对原油价格进行了有效的预测[7]。王珏等人验证了极限学习机算法在原油等大宗商品价格预测中的可行性[8]。Cen Z.等人通过数据进行滑动窗口处理、降低历史数据的权重和增加当前数据的权重等方法,基于长短期记忆网络(Long Short-Term Memory,LSTM)对WTI原油价格和Brent原油价格进行了短期的预测,认为减重和加权相结合的数据预测效果更好[9]。Busari G A.等人运用门循环单元(Gate Recurrent Unit,GRU)对比单个LSTM模型的预测结果,认为GRU能更加有效地预测原油价格[10]。
由于原油价格具有非平稳、非线性等特征,原油价格数据的预处理就显得尤为重要[11]。传统计算模型往往难以捕捉时间序列的不规则特征,这在一定程度上使得单一模型难以满足预测的需求,因此组合模型的方法越来越多地被众多学者采用。张金良等人针对非线性、复杂且无规律分布的数据,基于互补集成经验模态分解模型(CEEMD)对原油价格进行了预测[12]。Abdollahi H.等人构建了分解-预测混合模型,有效捕捉了时间序列的非线性和波动性特点并进行了数据的鲁棒性测试[13]。Lin H.等人提出了CEEMDAN和多层门控递归单元神经网络混合的方法,有效地解决了模态混合的问题,大大降低了数据重构误差,并对非线性数据进行了拟合[14]。
为了提高预测精度,不同的重构方法被应用于线性和非线性数据分解后的重构过程中。通常来说,对线性集成的方法是简单地对模型的预测进行线性求和。但这种方法缺乏支持基础,不适用于原油价格等非线性数据,因此目前常用智能模型进行序列的非线性重构。
原油价格的预测可以帮助参与市场的能源主体进行决策,同时可以指导政府制定相关的能源政策。与现有的点预测相比,区间预测更能准确捕捉价格动态变化范围,有效提高预测的准确性[15,16]。
以上内容讨论了目前在预测领域中各种模型的应用。分解-重构方法可以提高预测精度。然而,通过对原油价格预测有关文献的回顾,可知目前的研究仍存在许多不足:
1.目前原油价格相关的文章缺乏对原始序列进行二次分解的应用;2.不同分量对于预测模型的适配度缺乏研究;3.预测原油价格区间预测的研究很少,不能保证预测的稳定性。
基于以上,本文构建了一套混合深度学习预测模型。首先运用CEEMD进行一次分解,计算样本熵后将样本熵较大的序列进行VMD二次分解,得到更加平稳的序列;将序列根据样本熵进行重构后,运用随机森林进行分量筛选,来减少预测的计算量;接着,运用L-Z复杂度进行分量分类,将复杂度高的序列运用GRU进行预测,复杂度低的序列运用LSTM进行预测;预测之后,运用CNNLSTM进行序列重构。最后,选择了核密度估计完成区间预测,提高模型的现实意义。
二、方法介绍
(一) 随机森林算法
随机森林算法(Random Forest,RF)是基于在训练过程中集成了 bagging 的决策树,进一步引入了随机特征选择。它可以用来降低数据的维数。首先,构建分类和回归树以生成袋外(OOB)样本数据。然后,基于OOB数据,随机森林可以验证输入数据的重要性,得到每个特征的重要性分数[17]。特征的重要性排序可以用来排除不够重要的信息,减少后续计算复杂度。
(二) Lempel-Ziv复杂度算法
Lempel-Ziv复杂度算法可以通过计算不同分量的复杂度完成分量复杂度分类,从而选择不同模型对不同分量进行预测[18]。
识别过程如下:Ci
步骤1:计算IMFi,i=1,2,…,m的复杂度。
步骤2:设置临界值λ0(≥0.8),求出满足,k∈m条件的k的最小值。
步骤3:从IMF1到IMFk的Imf被识别为HFs,从IMFk+1到IMFm的Imf被识别为LFs。
(三) 互补集成经验模态分解
针对经验模态分解会有残余白噪声等缺点,CEEMD这一分解方法被提出[19]。CEEMD算法对原始信号分别加减白噪声,从而来抵消白噪声干扰。
CEEMD的分解步骤具体如下:
Step1:添加N输入信号的正负号高斯白噪声对,以及 2N信号集可以表示为:
式中:x(t)为原始信号;x+(t),x-(t)分别为加入正负成对噪声后的信号;u(t)为辅助噪声。
Step2:将EMD应用于新信号,第i个信号的第j个模态分量(Intrinsic Modal Function,IMF)为Mij。
Step3:计算所有固有模态函数(IMF)的集合平均值,得到CEEMD的分解结果为:
(四) 变分模态分解算法
变分模态分解(Variational Modal Decomposition, VMD)是一种新的分解算法[20]。它从频域角度将原始信号从低频到高频分解为若干个信号,不仅可以对信号进行降噪,还可以保留高频特征用于数据分析。
VMD分解过程是在固有模态函数(IMF)上构造变分问题,并通过求解该变分问题的最优解来确定IMF。VMD的变分约束为:
其中,∂t为狄拉克函数,δ(t)为脉冲函数。uk(t)为分解得到的模态分量,ωk为各模态分量相应的中心频率,j为虚数,t为取样时间,e-jωkt为中心频率指数,*为卷积运算;f(t)为未分解的主信号。
(五) 长短期记忆网络算法
LSTM网络是递归神经网络(RNN)的改进之一[21]。与 RNN 相比,LSTM 既可以处理长期依赖问题,又可以降低梯度消失的可能性。因此,LSTM已成功地应用于许多时间序列问题。LSTM结构的优点是它包含三种类型的门,包括输入、忘记和输出。
(六) 门控循环单元算法
GRU是一种特殊类型的基于优化LSTM的循环神经网络,类似于LSTM,其内部单元具有更强的收敛性[22]。LSTM有3个门,GRU没有细胞状态,门减少到两个,为更新门和重置门,在计算量上比LSTM小很多。
(七) 卷积神经网络算法
在分量重构方面我们依旧选择LSTM模型来进行预测,同时使用CNN模型来提取特征,加强模型的预测能力。
卷积神经网络(CNN)在多维序列的提取特征方面很出色[23]。模型使用一维卷积层结构来提取时间轴特征,其输出结果如下:xiωjbk
其中,指输入时间序列,指卷积核权重矩阵,指偏差值,指卷积核数量。
(八) 核密度估计算法
非参数核密度估计(Kernel Density Estimation,KDE)是一种用于估计概率密度函数的非参数方法。利用KDE求得的概率密度函数为:
式中:N为样本数量;h为窗宽;K(u)为核函数,u=h-1(e-ei);ei为功率预测误差的第i个样本值。
(九) 评价指标
1. 平均绝对百分比误差MAPE(Mean Absolute Percentage Error)
2. 均方根误差RMSE(Root Mean Square Error)
3. 平均绝对误差MAE(Mean Absolute Error)
4. 均方误差MSE(Mean Squared Error)
5. 拟合优度(R2)
各公式中,yi表示真实值,表示真实值的预测值,表示真实值的均值,n代表样本数。(7)-(10)指标值数值越小,代表模型预测性能越好。(11)的值越大,代表模型拟合度更好。
6. 区间指标
PICP(PI Coverage Probability)指真实值落在预测区间上下界的比率。基于置信水平的满意度,PICP值越大,属于预测区间的值数越大,预测效果越好。PIAW(PI Averaged Width)表示区间的上下边界之间的平均宽度。在同一置信水平下,该值越小,预测区间就越窄,预测效果越好。
当yi∈[Li,Ui]时,ci=1否则ci=0。Li和Ui指第i个数据的上下界。100(1-α)%为预测区间名义置信度。
本文提出的三阶段混合预测模型框架如图1所示。
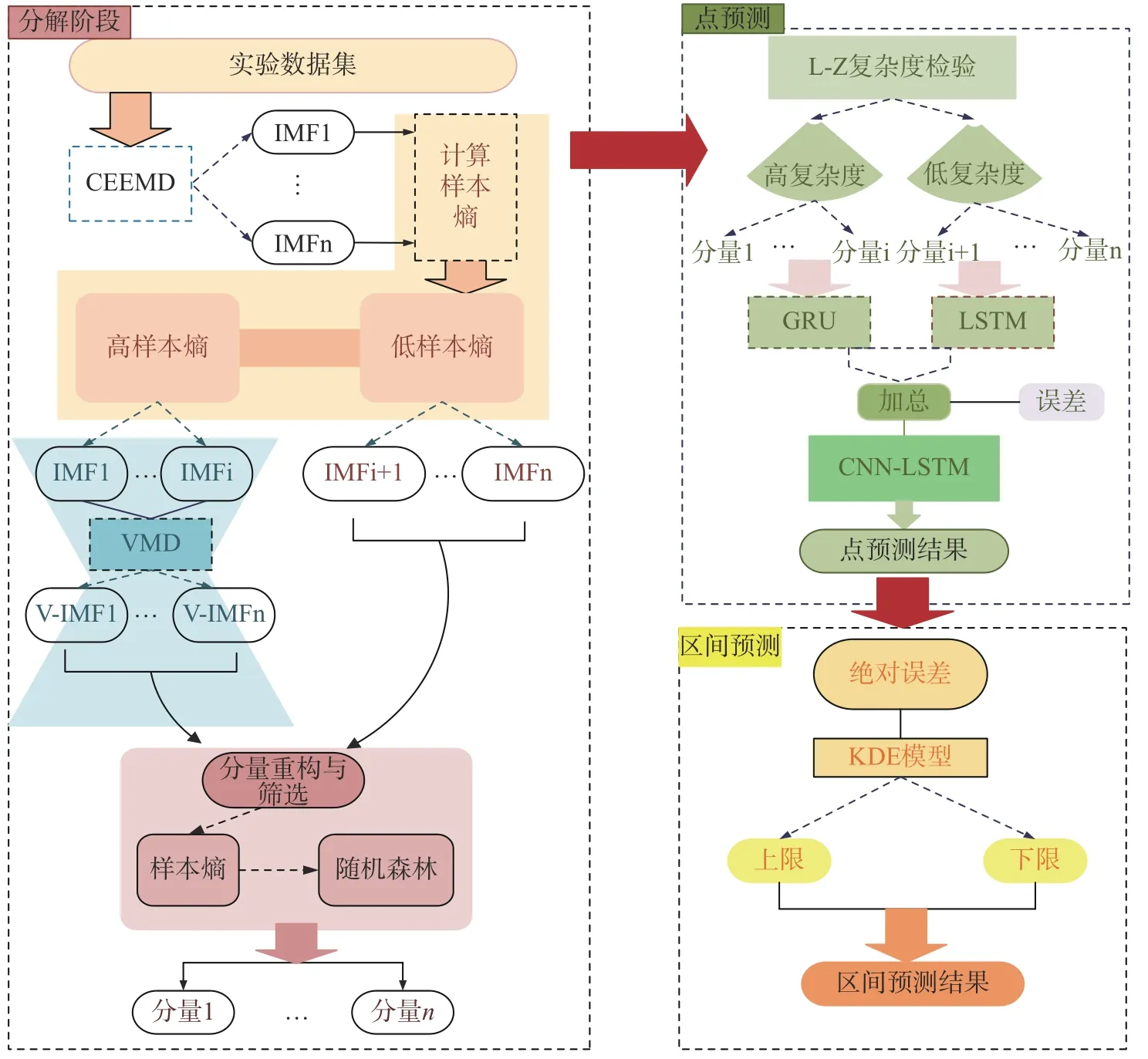
图1 三阶段混合预测模型框架图
其基本过程如下:
1.选择CEEMD进行第一次分解,将分解后的序列进行样本熵值计算,将熵值高的分量进行二次分解。
2.选择VMD对CEEMD中样本熵值最高的分量进行二次分解。
3.运用样本熵和随机森林进行分量重构与筛选。
4.将分量进行L-Z复杂度检验,将高复杂度分量通过GRU进行预测,低复杂度分量通过LSTM进行预测。将所有分量预测值加总后计算误差,输入到CNN-LSTM进行非线性重构得到点预测结果。
5.基于点预测结果进行基于核密度估计的区间预测。
三、预测结果
本文选择原油价格作为能源期货价格的代表来进行模型性能的检验。其中,布伦特原油价格又是原油价格的代表,因此本文选取了欧洲布伦特现货价格,时间跨度为1987年5月20日到2019年12月9日的日价格。数据来源于美国信息能源署。
针对原始序列,本文首先采用CEEMD进行一次分解。经过CEEMD分解后的序列结果如图2所示。

图2 CEEMD一次分解
样本熵(Sample Entropy,SE)可以衡量序列的复杂性,因此我们计算序列的样本熵来衡量算法的分解效果。通过CEEMD分解后的分量的样本熵如表1所示。原始序列的样本熵为1.6,而分解后的分量中样本熵最大的为IMF1的0.96,可见分解后的分量相比于原始序列复杂度有着大幅度的降低。但从样本熵的趋势中看,IMF1的样本熵远大于其他分量的样本熵。因此为了之后预测的准确性,将IMF1序列进行二次分解,以降低其复杂度。

表1 CEEMD分解后的分量样本熵
针对于IMF1的二次分解,我们选择了VMD分解方法。使用VMD分解之前需要预先确定分解个数。本文通过计算不同分解个数下的中心频率来确定最佳分解数量K[24]。经过计算,本文设置K=5。分解后的V-IMF的样本熵如表2所示。

表2 VMD分解后的分量样本熵
与IMF1的样本熵相比,分解后的分量样本熵值更小,趋势也更加平缓。这有利于之后预测准确性的提高。
我们根据分解后的序列进行分量重构。首先根据样本熵大小进行重构,其次根据随机森林筛选重要程度,将重要度小的分量进行筛除,来减少计算量。最终结果如表3所示。

表3 分量重构结果
从结果来看,SUBIMF1的重要程度远低于其他分量,因此我们选择将SUBIMF1筛除,选择剩下的分量进行预测。
重构后各分量如图3所示。
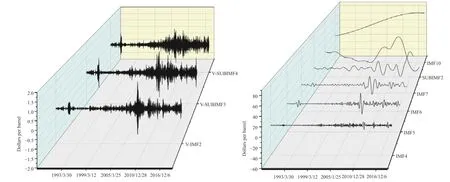
图3 重构后各分量示意图
在模型进行预测之前,首先要对于分量进行分析,匹配合理的预测模型,以免获得预测精度低的结果。我们选择了L-Z复杂度来作为模型匹配的指标。
L-Z复杂度的计算结果按降序如表4所示。

表4 L-Z复杂度计算结果
本研究将其中的临界值λ0设为80%,计算结果图如图4所示。
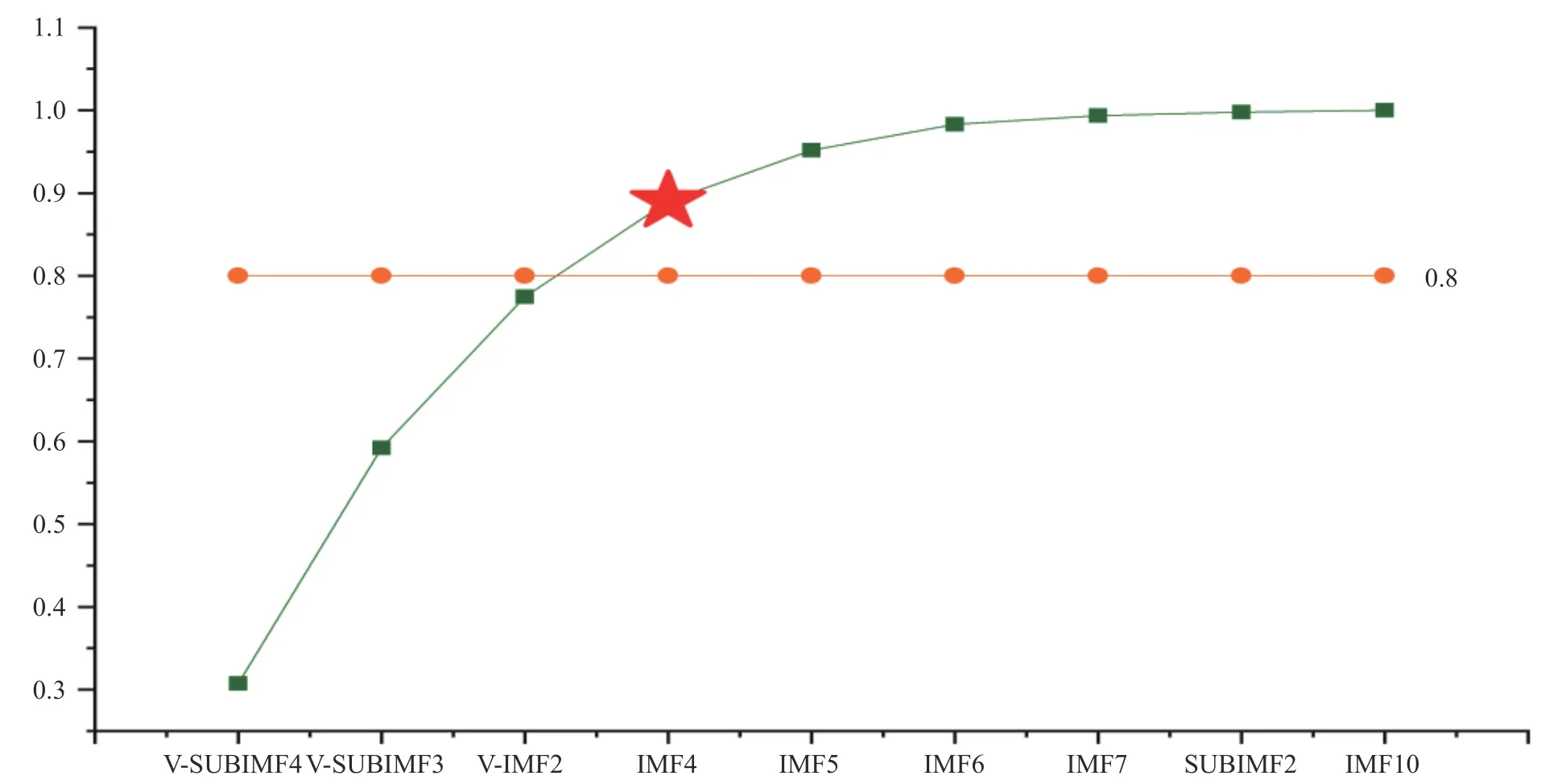
图4 L-Z复杂度计算结果
从图4中可见,K=3时η值小于80%,当k为4时,η的值为89.01%。因此,我们将V-SUMIMF4,V-SUMIMF3,V-IMF2和IMF4认定为高复杂度分量,其余为低复杂度分量。
高复杂度的序列具有波动率高、随机性强的特点。我们采用GRU来学习预测高复杂度序列。GRU是一种特殊类型的基于优化LSTM的循环神经网络,其内部单元类似于LSTM,但其具有更强的收敛性,适合预测时间特征较为明显的数据。
低复杂度的非平稳序列具有较为清晰的变化模式。LSTM能够学习历史信息的特征和长期依赖性,得到高精度的预测结果。我们采用LSTM模型来预测低复杂度序列。
本文按照7:3的结构划分数据集为训练集和测试集。LSTM和GRU的参数设置如表5所示。

表5 参数表
为了检验本文提出的混合模型预测性能是否良好,我们针对模型的每一阶段进行了模型对比。在分解阶段,选择不分解、一次分解以及二次分解进行了比较;分量预测阶段选择只用传统预测方法自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,ARIMA),只用LSTM或只用GRU和用LSTM-GRU组合方法进行对比;重构阶段将简单加和重构与智能重构进行比较。
各模型的对比拟合图如图5所示。为了直观地比较所采用的模型的性能,实际数据用红色粗体线表示,本文提出的模型用蓝色粗体线表示。从图中可以清楚地看出,这两条线更加突出,本文模型的预测线几乎接近原始数据的线。然而,其他模型并没有如此接近原始序列。这也证明了本文的混合模型比其他比较模型具有更好的预测能力。

图5 各模型预测结果拟合图
我们选择用MSE,RMSE,MAE和MAPE四个指标作为指标进行预测性能对比。除此之外,拟合优度R2也被用来作为指标进行对比。预测指标评价结果如表6所示。本文所构建的混合模型在MSE,RMSE,MAE,MAPE四个指标上的表现均优于其他模型,分别为0.11824,0.34385,0.30199,0.444750032。而R2为99.74%,显示出了优越的拟合程度。针对于是否需要分解阶段,我们选择了LSTM,GRU,ARIMA对原始序列进行了预测。从指标结果可见,单独预测的方法的预测性能不如本文构建的模型;针对于重构方式,我们选择了CEEMD-VMD-LSTM-GRU-Addition模型进行对比,CEEMD-VMD-LSTM-GRU-Addition的指标分别为1.029376068,1.014581721,1.167934537,1.774795191,97.79%,相比之下,本文的混合模型性能更加优越,这证明了非线性重构的优越性;针对分量预测阶段,本文选择了CEEMD-VMD-LSTM-CNN-LSTM,CEEMD-VMD-ARIMA-CNNLSTM和CEEMD-VMD-GRU-CNN-LSTM,其核心预测方法与单独预测的方法相一致,结果显示其性能不如本文所构建的模型,证明了本文所构建的混合模型的优越性,也证明了混合模型比单一模型拥有更好的预测结果;针对二次分解阶段,我们选择了CEEMD-LSTM-GRU-CNN-LSTM模型作为对比,结果显示其相关指标不如本文模型,证明了二次分解的必要性。
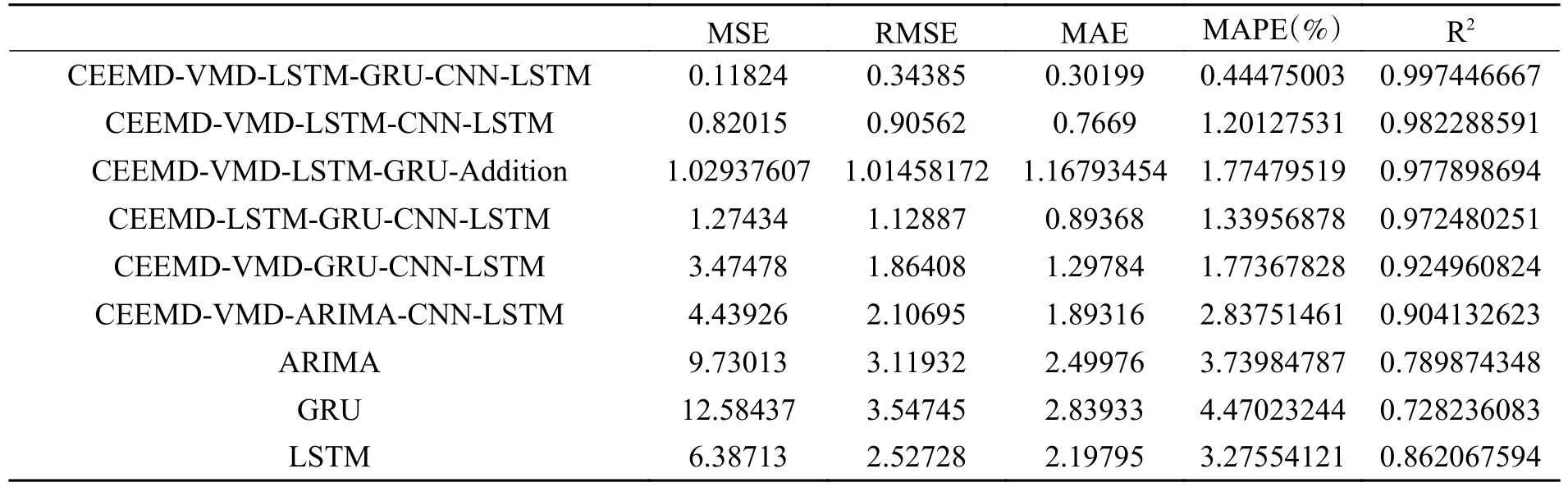
表6 各模型评价指标对比
基于点预测结果,我们进行区间预测。高斯函数是最常用的核函数,本文选择高斯函数作为核密度估计的核函数。针对区间预测,我们选择了各自最优窗宽下的Triangle函数和Epanechnikov函数作为对比。同时选择了高斯函数的不同窗宽下的取值作为对比。
通过计算,我们运用PICP和PIAW指标作为性能衡量的指标。最终得出的结果如表7所示。

表7 区间预测指标计算结果
从表可见,三个不同的核函数的指标差距不大,但在60%置信度下,高斯函数的PICP最大,而区间平均宽度却相差无几,我们可以认为高斯函数相比其他两种函数更加适合本文的数据集。
而对于高斯函数设置的不同窗宽可见,当窗宽过小时,会导致PICP指标下降,同时区间宽度会变窄;当窗宽过大时,区间宽度会变宽;当窗宽取最优数值时,PICP和PIAW指标是最合适的。
四、结论
近年来,能源价格不断变动,对整个经济社会的影响剧烈。通过对能源价格进行预测,把握未来价格趋势,为政策制定以及规划的执行提供支持,对未来的经济发展有利无害。本文选择具有代表性的原油价格来验证模型的有效性。
本文提出了CEEMD-VMD-LSTM-GRU-CNN-LSTM混合预测模型。从图5可见,模型的预测结果与真实值拟合得很好。当前阶段,原油价格变动较大,具有强烈的波动特点,我们的模型可以更好地适应当前的价格特征,从而提高预测的准确性。
本文得到的结论如下所示:
1.本文构建了一套能够获得优秀预测结果的混合深度学习模型,提出的混合深度学习十分有效,为原油预测等相关的能源领域预测提供了科学的预测模型。
2.单个模型的预测误差都大于所有的分解-重构模型。分解-重构方法的原理在原油价格预测方面是卓有成效的。同时用组合模型GRU和LSTM进行预测时,预测效果强于其他模型。
3.非线性重构是十分有必要的。根据表6结果可知,将序列直接加和产生的误差更大,通过非线性重构能够获得更加精准的预测结果。
4.本文构建的CEEMD-VMD二次分解模型对于预测结果有促进作用。对比指标结果可知,未经过二次分解的序列预测误差更大。
5.本文基于点预测形成了基于核密度估计的区间预测,并选取不同的核函数和窗宽进行了对比,结果显示在PICP和PIAW两个指标的比较中,高斯函数和最优窗宽所形成的区间预测具有最优秀的性能,其准确度和区间宽度皆为最优。
总的来说,本研究的主要贡献在于引入一种混合深度学习模型,来更准确地进行原油价格预测。同时引入区间预测,增强预测的现实意义和准确性。本文提出的预测方法有利于能源供应商把握未来价格趋势。同时,原油价格作为期货,其价格变动影响着股市等风险投资,及时反应其变动,可以帮助能源公司对冲风险,改变投资方向。最后,原油价格的准确预测也为政府将来的政策性决定作出指导,帮助其及时应对环境污染以及能源短缺问题。
但是,本文还存在一些不足之处。首先本文选择的数据中,前期数据波动不大,处于较为平稳状态,后期波动太大,处于距离波动状态。针对这一问题,未来可将数据集拆分成两套数据分别进行预测,其预测特点将更加准确,更加具有现实意义。同时,本文选择了原油价格来预测,未来,我们将选择更多的能源组合进行预测,来考察模型对能源价格的适应性。
