基于改进YOLOv7 的织物疵点检测算法
2023-12-19郭殿鹏柯海森李孝禄施庚伟
郭殿鹏 柯海森 李孝禄 施庚伟
(中国计量大学,浙江杭州,310018)
在纺织品的生产过程中,织物疵点是难以避免的,而制造过程中的意外因素是其产生的主要原因之一[1]。这些疵点可能以不同的形状、颜色和大小出现在织物表面,导致产品价格缩水一半左右[2],从而直接影响企业的盈利情况。因此,织物疵点检测在纺织行业中非常重要。目前,较多的纺织车间是通过人工的方式来分拣疵点产品。但人工分拣效率低、容易受到主观因素的干扰,而且长时间工作疲劳、眼花容易导致漏检、误检的发生[3],不能满足流水线日益增长的生产需求。为使工艺流程更加自动化和智能化,提升检测效率与准确率,基于机器视觉的检测方法开始进入大众的视野[4]。
现阶段,传统视觉检测有统计法[5]、频域法[6]、模板法[7]等方式。由于传统视觉受制于光照视角的依赖性、疵点形态的多样性等因素,其泛化能力和适应新场景的能力被严重限制,在检测领域中仍存在一定的局限性。随着检测算法的不断发展,诸 多 深 度 学 习 分 类 网 络 如VGG[8]、Inception[9]、ResNet[10]等,凭借其强大的学习能力、优秀的数据处理能力以及较优的鲁棒性和适应性在检测领域中大放异彩[11]。
相比于其他算法,YOLO[12]算法因能在保证一定精度的情况下大幅提升检测速度,因而在织物疵点的实时检测中获得众多青睐。JIN R 等[13]在YOLOv5 中引入多任务学习,通过优化焦点损失函数和加强中心约束来提高识别性能。YUE X 等[14]在YOLOv4 的 主 干 特 征 提 取 网 络 中 融 入卷积块注意力模块,并创新性地将CIoU 损失函数替换为CEIoU 损失函数,实现对疵点的准确分类和定位。LIN G J 等[15]提出一种滑动窗口多传感头自注意力机制,并引入Swin Transformer模块代替原YOLOv5 算法中的主模块,提高对小目标疵点的感知。
由于织物疵点的小尺度性、不规则性和分散性等特点,现阶段的YOLO 算法还是存在检测精度较低等问题。本研究基于YOLOv7[16]算法进行改进,通过新设计的DR-SPD 结构增强模型强化对复杂形态的表征能力;修改网络结构并引入注意力机制,提升对于小目标的检测精度,减少背景信息对识别带来的负面影响,使改进后的模型能够满足工业实际生产需求。
1 YOLOv7 模型概述
YOLOv7 是一种单阶检测算法,相比于其他YOLO 算法,它在检测效率与精度之间取得了非常好的平衡。YOLOv7 模型整体结构如图1 所示,主要由输入模块(Input)、主干网络(Backbone)和头部(Head)组成。
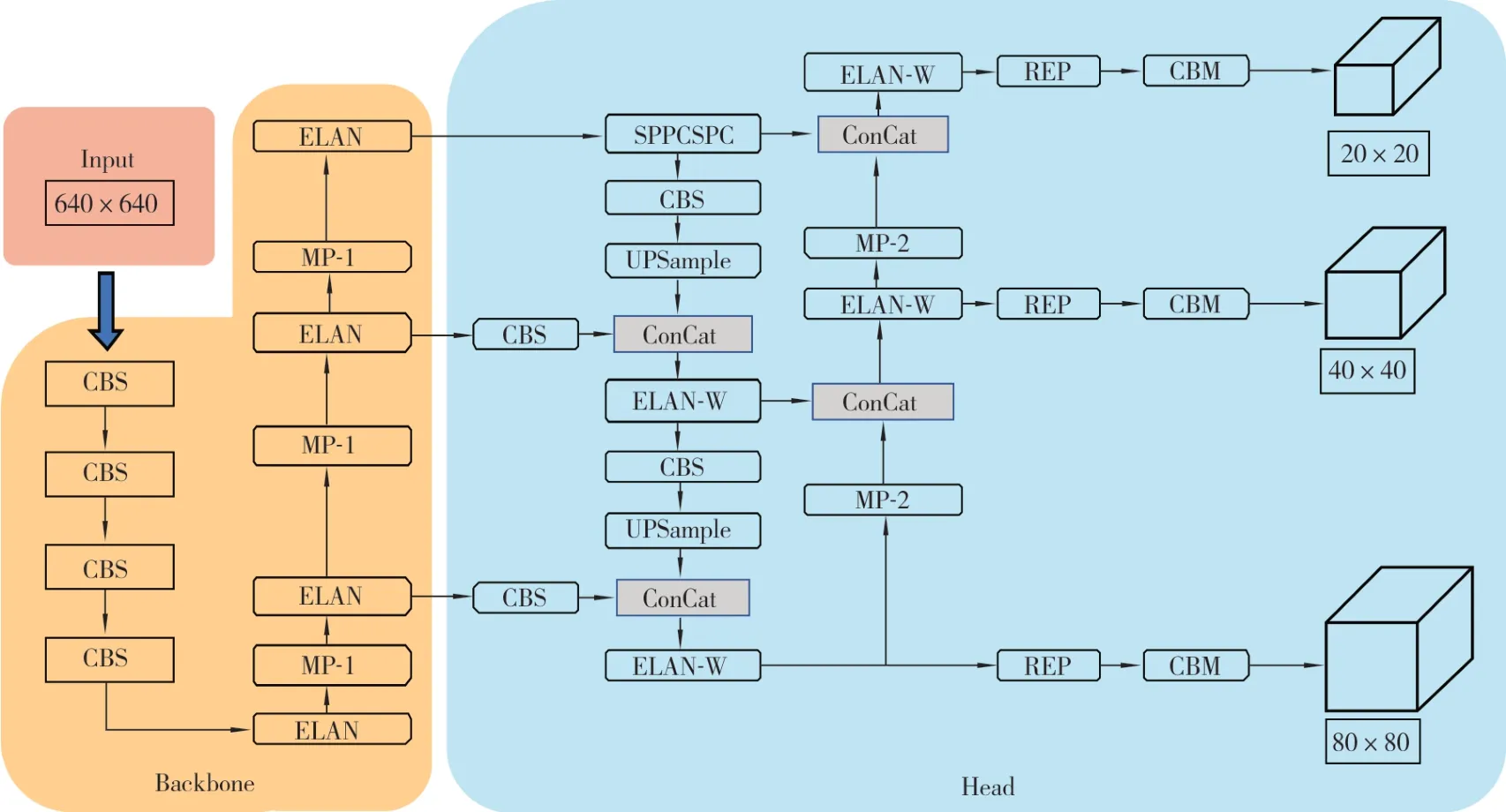
图1 YOLOv7 模型整体结构图
Input 的主要作用是调整图片格式以适应后续流程,主要包括数据增强、调整锚框和放缩图片等操作。
Backbone 是YOLOv7 的特征提取器,主要由CBS 模块、ELAN 模块和MP-1 模块构成。它负责从输入图像中提取多尺度的特征图,其特点是具有较大的感受野和较高的特征表达能力,可以捕获图像中的语义信息。
Head由SPPCSPC模块、ELAN-W模块、MP-2模块、Cat 模块以及后续输出的RepConv 模块组成。Head 通过利用上述模块进行跨层级上采样和特征拼接的方式实现特征融合,以获得多尺度的上下文信息。然后根据融合后的特征图进行目标预测,用于提取目标的位置和类别信息。预测头的特点是具有较小的感受野和高分辨率特征图,能够准确地定位和分类目标。
对于织物疵点检测,当前YOLOv7 在特征提取与融合的过程中还是会发生关键信息遗漏,从而导致模型对疵点位置和类型判断错误。下面将会对特征提取网络与特征融合网络进行针对性地改进。
2 YOLOv7 模型的改进
2.1 设计DR-SPD 结构
2.1.1 DRes 单元
神经网络强大的表征能力源于不同过滤器对不同级别信息的提取。对于织物中复杂不规则的疵点形状,如果想要获取更全面的图像信息,可以通过增加卷积的数量来实现。但当结构中卷积的数量已经趋近于饱和时,再一味地增加卷积则会导致参数量冗杂、收敛性变差、网络优化困难等负面问题。为解决上述局限性,利用动态区域感知卷积(DRConv)[17]设计DRes 单元,使其能有效处理复杂多变的图像信息。
如图2 所示,DRConv 通过k×k的标准卷积,从输入特征图X中生成具有m个通道的引导特征,再根据引导特征将空间维度划分为相对应的区域,使引导掩码中具有相同颜色的像素附着到对应区域。同时滤波器生成模块G(X)会根据每个区域的图像特性生成对应的定制滤波器W=[W0,…,Wm-1],进行卷积运算。最后,将所有区域融合在一起便得到输出特征图Y。由于需要优化的参数主要在G(X)中,所以DRConv 几乎不会增加模型的大小。
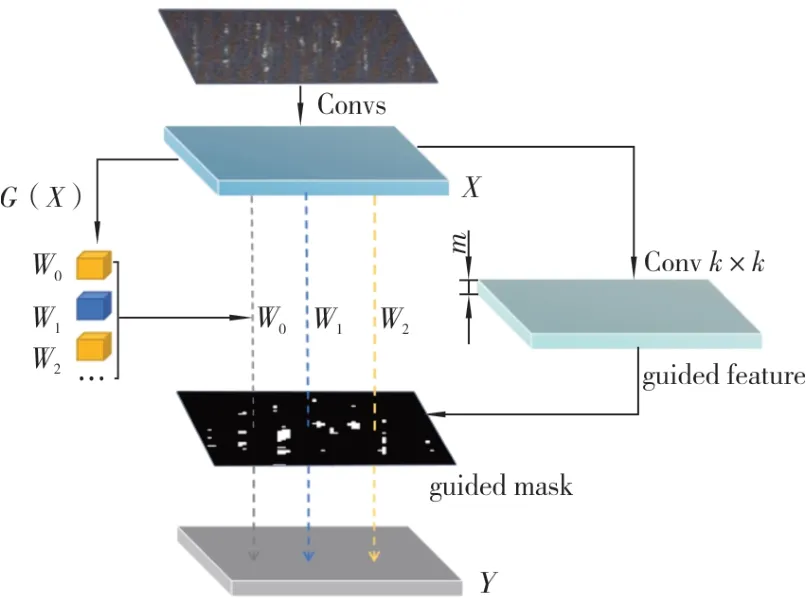
图2 动态区域感知卷积
设计的DRes 单元如图3 所示。该单元使用卷积核为3 的DRConv 和CBS 进行特征提取,再加入一条跳跃连接,直接将原输入与卷积层的输出相加形成残差结构。与同等数量的普通卷积块相比,DRes 单元能在几乎不增加模型大小的基础上增强对于不规则疵点的表征能力。

图3 DRes 单元
2.1.2 SPD 卷积
当点状疵点与织物颜色相近时,同色像素沉淀的特性容易导致DRes 对该类疵点的检测准确率下降。为降低上述问题带来的影响,利用SPD[18]卷积充当末尾卷积,对其他卷积层的输出集合进行最终处理,以增强网络对图像细节的提取能力。
SPD 由空间深度层和非跨步卷积层组成,对于任何尺度为S×S×C1的特征图X,SPD 可将其切为如下公式的子特征序列。
将这些特征子图沿着通道维度连接起来便使特征 图X(S,S,C1)转换成 中间特征 图X′(S/scale,S/scale,scale2C2)。如图4 所示,当scale=2时通过降采样得到大小为(S/2,S/2,C1)的4 个特征 子 图f0,0、f1,0、f0,1、f1,1。其 中X′的 空 间 维 度 减 少了1/2,通道维度增加了4 倍。
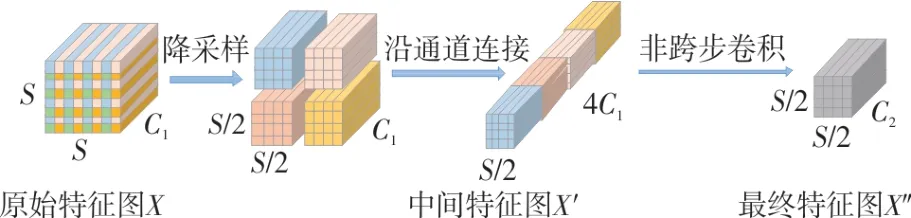
图4 SPD 特征提取
为尽可能保留所有的判别性特征信息,在SPD 特征转换层之后再添加一个带有滤波器的非跨步卷积层,得到最终特征图X″(S/scale,S/scale,C2),这样可以有效减少细粒度信息的丢失。
2.1.3 结构整体设计
本研究提出了一种新的聚合网络结构DRSPD,该结构将DRes 的动态感知和SPD 卷积的细节提取结合在一起,以增强对各类型疵点的语义捕捉能力,提升检测精度。DR-SPD 结构如图5所 示,CBS 由1×1 卷 积(Conv)、数 据 归 一 化(Batch Normalization)和激活函数SiLU 组成,Cat表示连接操作。DR-SPD 通过控制最长和最短的梯度路径使网络能够学习更多的特征,最后引入残差结构的思想将特征信息进行叠加后输送到SPD 卷积中,从而具有更好的泛化能力。
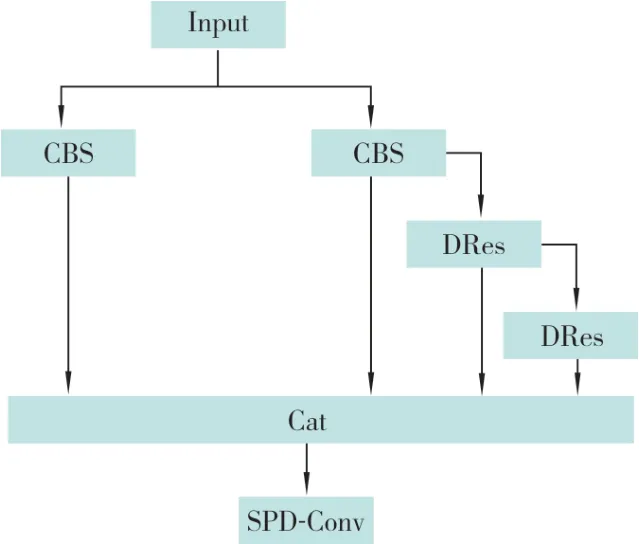
图5 DR-SPD 结构
2.2 引入GAM 注意力机制
在检测过程中,当疵点的颜色、形态与织物纹理相似时也会对检测结果造成较大的影响。GAM[19]能在减少信息丢失的同时扩大全局交互性,在多个维度获取特征信息,以达到提升网络性能的目标。GAM 在CBAM 注意力的基础上加以改进。如图6 所示,通道注意力子模块使用3D 序列来保存每个维度上的信息,然后通过两层的编码-解码器结构(MLP)增强跨维度通道的空间相关性。为更好地聚焦于空间信息,空间注意力子模块使用两个卷积层进行空间信息融合。由于最大池化操作容易造成信息丢失从而影响整体性能,所以省略池化操作以达到更优的映射特性保留。空间注意力子模块如图7 所示。

图6 通道注意力子模块
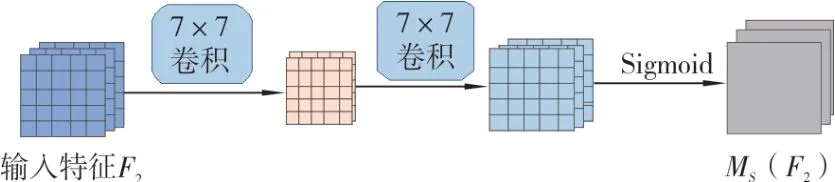
图7 空间注意力子模块
GAM 整体计算过程如图8 所示。将上述两个子模 块进行融合,当输入特征映射F1∈RC×H×W时,中间状态F2和输出结果F3的计算公式如下。
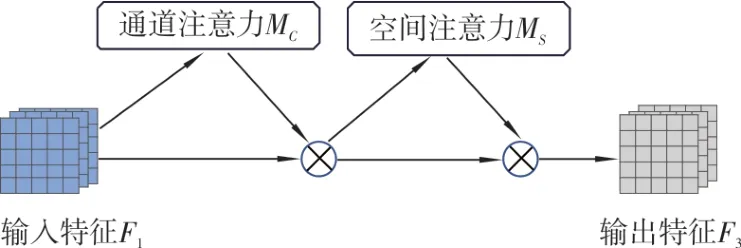
图8 GAM 整体计算过程
式中:MC表示通道注意力图;Ms表示空间注意力图;⊗表示按元素进行乘法操作。
将GAM 模块添加到模型Backbone 与Head的连接处,可以有效抑制干扰信息,提升对于小目标的敏感性,使Head 部分能够进行更好的特征融合,以提高检测精度。
2.3 改进特征融合网络
在原YOLOv7 特征融合过程中为了能获得多尺度信息,对输入的特征图进行多次上下层采样。由于检测目标尺度较小,在不断上下采样的过程中很容易导致图像细节的丢失,影响检测精度。所以,本研究在保留其原始融合路径的同时,加入3 条横向跳跃路径,如图9 所示。将同一层的输入和输出节点跨层连接起来,使模型中各个检测层均多加了一条特征融合通道,缩短深浅层之间信息传递的距离,加速模型收敛,强化不同层级的细节特征。
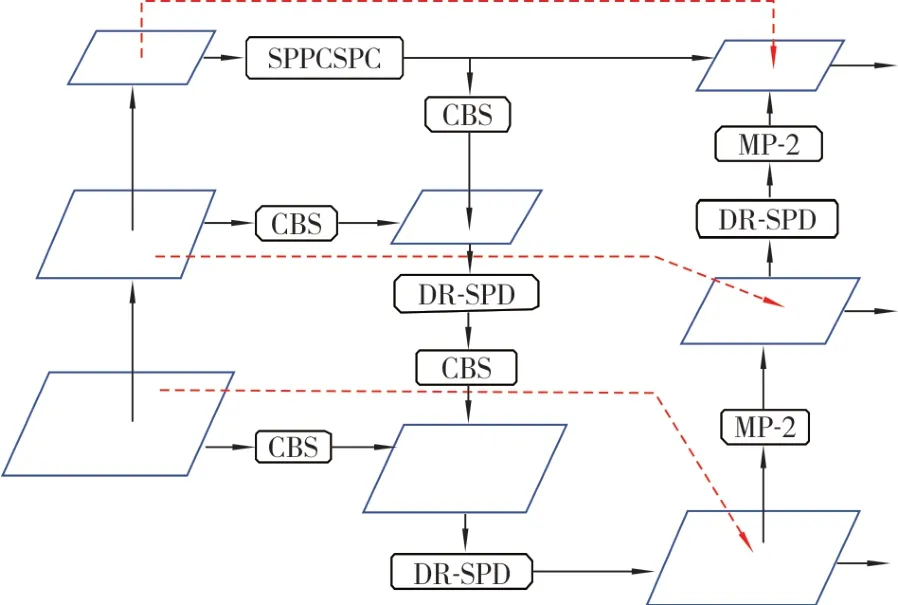
图9 特征融合网络改进
2.4 改进后的模型结构
改进后的YOLOv7 整体网络结构如图10所示。
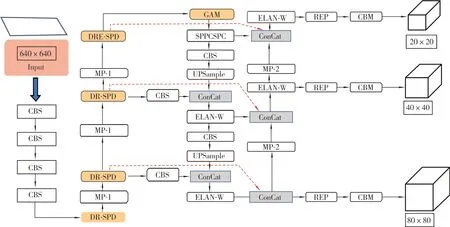
图10 改进后的YOLOv7 模型
3 试验测试及分析
3.1 数据集的构建
数据集采自浙江义乌某纺织车间,共计3 514张含有疵点的图片,其中每张图片中包含1 种及以上的疵点类型。根据厂家实际检测需求,本研究选取的疵点类型及图片数量为脏渍822 张、结头738 张、浆 斑537 张、松经776 张、三丝641 张。将数据集按照8∶2 的比例作为训练集和测试集。
在实际应用场景中,根据公式(7)计算后得出的rs值若小于3%,则称该疵点为小目标。
式中:Sbox表示疵点标注框的面积;Simage表示图像的总面积。
经计算,该数据集中的大部分对象都符合小目标的定义。为能清晰展示疵点类型,将图像中的疵点部分进行裁剪并放大处理,如图11 所示。

图11 疵点类型
3.2 模型训练及评价标准
本次试验中的硬件平台选用搭载了6×Intel Xeon E5-2680 v4、Nvidia RTX 3080 GPU、内存26 GB 的服务器。环境配置为PyTorch2.0.0、Python3.8、Cuda11.8。选择随机梯度优化器,使用迁移学习的方法加载预训练权重,使用模型主干冻结的训练策略,开启多线程训练,并开启Mosaic 图像增强,学习率随着训练世代的增加而减少。为了更好地评价模型,选定精确率(Precision,P)和召回率(Recall,R)作为基础指标,通过这两个基础指标可以进一步整合成更综合的检测指标:平均精度(Average Precision,AP)和平均精度均值(mean Average Precision,mAP)。
3.3 消融试验
针对本研究中对YOLOv7 算法提出的几处改进,通过逐一增加改进模块的方法设计了消融试验,以验证其有效性,试验结果如表1 所示。将DR-SPD 结构中的SPD 卷积换为普通卷积即对应表1 中的DR 结构。可以看出DR 结构对浆斑、三丝的提升效果最明显,其AP值分别提升了2.14 个百分点和1.83 个百分点,但也导致脏渍、结头的检测精度有所下降。这说明设计的DRes单元虽然使模型对不规则疵点有了更为动态的视野,但同时也容易对点状疵点产生误判,而加入SPD 卷积后解决了上述问题,这也验证了DRSPD 结构的有效性。加入GAM 注意力机制后,脏渍、结头和松经的AP值分别提升了1.46 个百分点、1.23 个百分点和1.65 个百分点,反映出模型对于织物纹理的抗干扰能力增强,也能对分散性的疵点给予更多的关注度。在加入改进的特征融合网络后,脏渍和结头精度的提升最为明显,而这两种疵点的尺度相比于其他疵点类型都更小,这表明该网络能更好地保留细节特征。模型对小目标疵点的检测精度得到了有效提升。
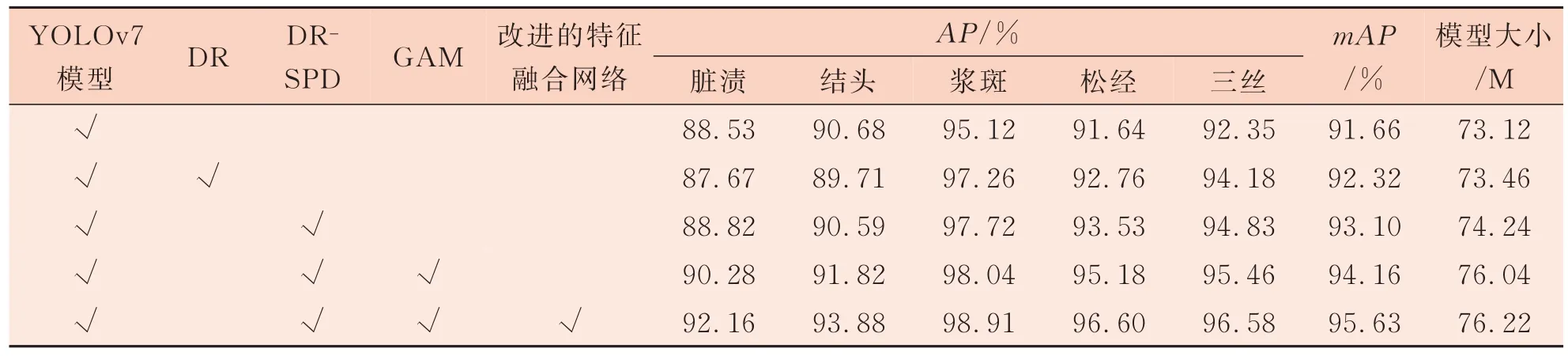
表1 消融试验结果
3.4 与其他主流算法对比
在目标检测领域,其他主流算法也占据着相当重要的地位。为了更好地展示改进效果,将改进的YOLOv7 与其他算法进行对比试验,结果如表2 所示。可以看出,Faster RCNN 在检测速度上花费时间较长,不满足对实时性的要求,而YOLOv5s 在实时性上表现良好但精度较低。改进的YOLOv7 模型虽然检测速度有所下降,但其在满足实时性要求的同时提升了检测精度,在整体表现上相比其他模型更加优秀。
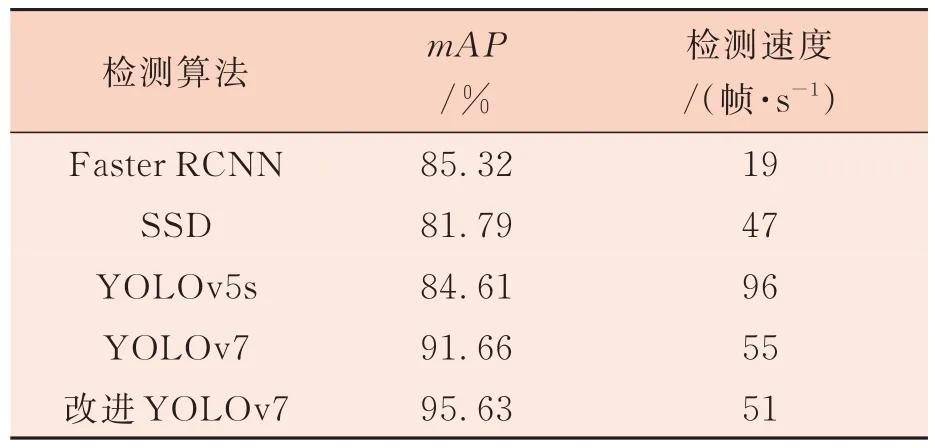
表2 主流算法对比表
YOLOv7 模型改进前后检测效果对比如图12 所示。可以看出,当疵点特征与背景相似或疵点尺寸较小时,改进YOLOv7 由漏检、误检变为可以准确地检测出其位置及大小,并给出更高的置信度;对于不规则形状的疵点,改进YOLOv7模型的预测框长宽都会更加贴近疵点形状,并通过多预测框的方式来精准表示各部分疵点。

图12 检测效果对比图
3.5 实际应用测试
为验证本研究算法在实际工业场景中的有效性,在工厂现有平台上搭建一个视觉采集模块后,将改进模型部署到设备中进行实际测试。测试环境如图13 所示。

图13 测试环境
将130 个无疵点与65 个有疵点的织物作为一组测试对象,对该组对象进行20 次无序测试,试验mAP值94.85%,检测速度43 帧/s。由于检测过程中受传送带、相机振动等环境因素的影响,导致mAP略有下降。同时,上位机在检测时也消耗了系统资源,所以检测速度下降到43 帧/s,但仍能较好地满足实际生产需求。
4 结语
对于因织物疵点尺寸小、形状复杂而导致检测精确率较低等问题,本研究在YOLOv7 的基础上加入新设计的DR-SPD 结构,并在模型主干网络与头部的连接处添加GAM 注意力模块;最后,通过加入3 条横向跳跃路径对特征融合网络进行改进。试验结果表明:改进后YOLOv7 模型相较于 原 始YOLOv7 模 型,mAP值 提 升 了3.97 个 百分点,其特征提取能力和抗干扰能力都得到增强,能聚焦于更为关键的图像细节,综合性能也优于其他主流算法。将改进YOLOv7 模型部署到车间设备上进行测试,其mAP值达到94.85%,检测速度为43 帧/s,验证了其在实际工业场景中的有效性。后续工作将研究如何使该模型更轻量化,以更大程度降低部署时对于硬件设备的要求。
