基于YOLOv5-Eff 网络的织物疵点检测算法
2023-12-19石玉文林富生宋志峰余联庆
石玉文 林富生 宋志峰 余联庆
(1.武汉纺织大学,湖北武汉,430200;2.三维纺织湖北省工程研究中心,湖北武汉,430200;3.湖北省数字化纺织装备重点实验室,湖北武汉,430200)
目前,从织物疵点目标检测的实现技术来分,可分为传统的机器视觉识别方法和深度学习两大类。传统的机器视觉疵点识别方法主要依赖于颜色或亮度、纹理等表层可辨特征,同时对于灯光或检测背景要求苛刻,因此检测局限性较大,算法性能存在诸多不稳定因素,这就会导致算法的检测准确率低、小目标漏检等问题,同时对于不同背景、不同种类织物的泛化能力较弱。随着工业智能化快速发展,利用人工智能技术[1-3]迅速准确地完成对织物疵点的自动识别,已经成为智能装配领域研究的热点。
近年来,随着深度学习技术的快速发展,上述问题得到一定程度的解决。罗俊丽等[4]提出将YOLOv5 的特征金字塔网络模块替换为双向特征金字塔网络来增强算法对不同尺度特征提取的泛化能力;蔡兆信等[5]提出改进Faster RCNN 网络的RPN 结构,融合多层不同尺度特征图,增加了图像细节提取的能力;黄汉林等[6]提出了以MobileNet 网络结构代替SSD 算法中的特征提取部分的方法,提高了SSD 算法的运行效率;李杨等[7]提出了一种基于深度信念网络的织物疵点检测方法,用改进的受限玻尔兹曼机模型对深度信念网络进行训练,完成模型识别参数的构建,完成了在复杂环境下织物疵点检测的任务;胡越杰等[8]提出了用ResDCN 替代YOLO 网络中的残差单元来增强网络模型的特征提取能力,使得YOLOv5 网络的准确率提高了4.99 个百分点。
尽管许多学者已经提出了各种不同的织物疵点检测方法,并取得了一定的成果,但仍存在两个主要问题。首先,由于织物疵点的类型多样并且分布不均匀,导致检测难度增大;其次,织物疵点通常为小目标且形状多变,使得识别较为困难。本研究提出了一种改进的YOLOv5 织物疵点检测算法,即YOLOv5-Eff。在算法中引入了改进的EfficientNet[9]模块来替换原有的特征提取网络,同时结合了Swish 动态激活函数来优化模型,设计了ACmix 注意力模块,使得网络能够捕获更多疵点的特征信息以提高对小目标疵点的敏感度。
1 YOLOv5 网络结构
在现有的目标检测算法中,YOLOv5 因其速度高和准确率较高等特点而得到广泛应用。YOLOv5 目标检测模型如图1 所示。在输入端,采用了mosaic 数据增强方式,将包含目标的4 张图片拼接成1 张图片。这样新的图片中包含了4 种具有相同背景的目标,大大丰富了被检测物体的背景,加快了图片的读取速度,并且增强了网络的鲁棒性。在特征提取部分,引入了Focus 结构,将原始的512×512×3 输入图像切片后生成256×256×12 特征图,在不丢失任何信息的情况下获得了两倍的下采样特征图。特征融合部分结合了路 径 聚 合 网 络(PAN)[10]和 特 征 金 字 塔 网 络(FPN)[11]。FPN 网络从顶部向下传递并与主干特征提取网络的特征图进行融合,传递深层次的语义信息。PAN 网络从底部向上传递目标位置信息。这种方式更利于模型学习目标特征,减少了底层特征信息的丢失,并增强了模型对小目标的敏感度。
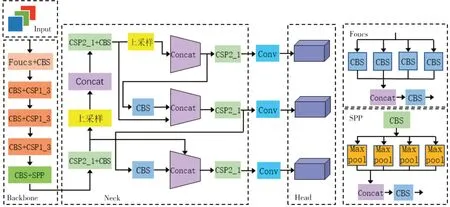
图1 YOLOv5 网络结构
2 YOLOv5 模型改进
2.1 嵌入Swish 激活函数
本研究采用两种激活函数,在保持原有YOLOv5 网络Neck 层和Head 层SiLU 激活函数的基础上引入改进版Swish 激活函数。传统的YOLOv5 网络结构使用的是SiLU 激活函数,与RELU[12]激活函数类似,都属于静态函数,对所有输入数据都执行相同操作,并产生大量的冗余数据。在输入负值越大的情况下,其对结果的影响逐渐增加。为了避免负样本对训练精度的过大影响,引入可学习参数β的Swish 激活函数,如式(1)所示。
与LeakyReLU[13]激活函数相比,Swish 函数在负无穷方向上更加平滑,在保持有负样本输入的前提下,减弱了其对整个网络的影响。这样不仅允许信息更深入地传播到网络中,同时也提高了网络的效率。
2.2 设计ACmix 注意力模块
在执行注意力机制时,卷积注意力模块优先处理输入与输出之间的交互关系,而自注意力模块则着重于输入间的内部关联。本研究受CoAt-Net[14]网络的启发,融合自注意力和卷积注意力的优势,设计ACmix 注意力模块,旨在提高网络对微小目标的敏感度。ACmix 注意力模块如图2所示。
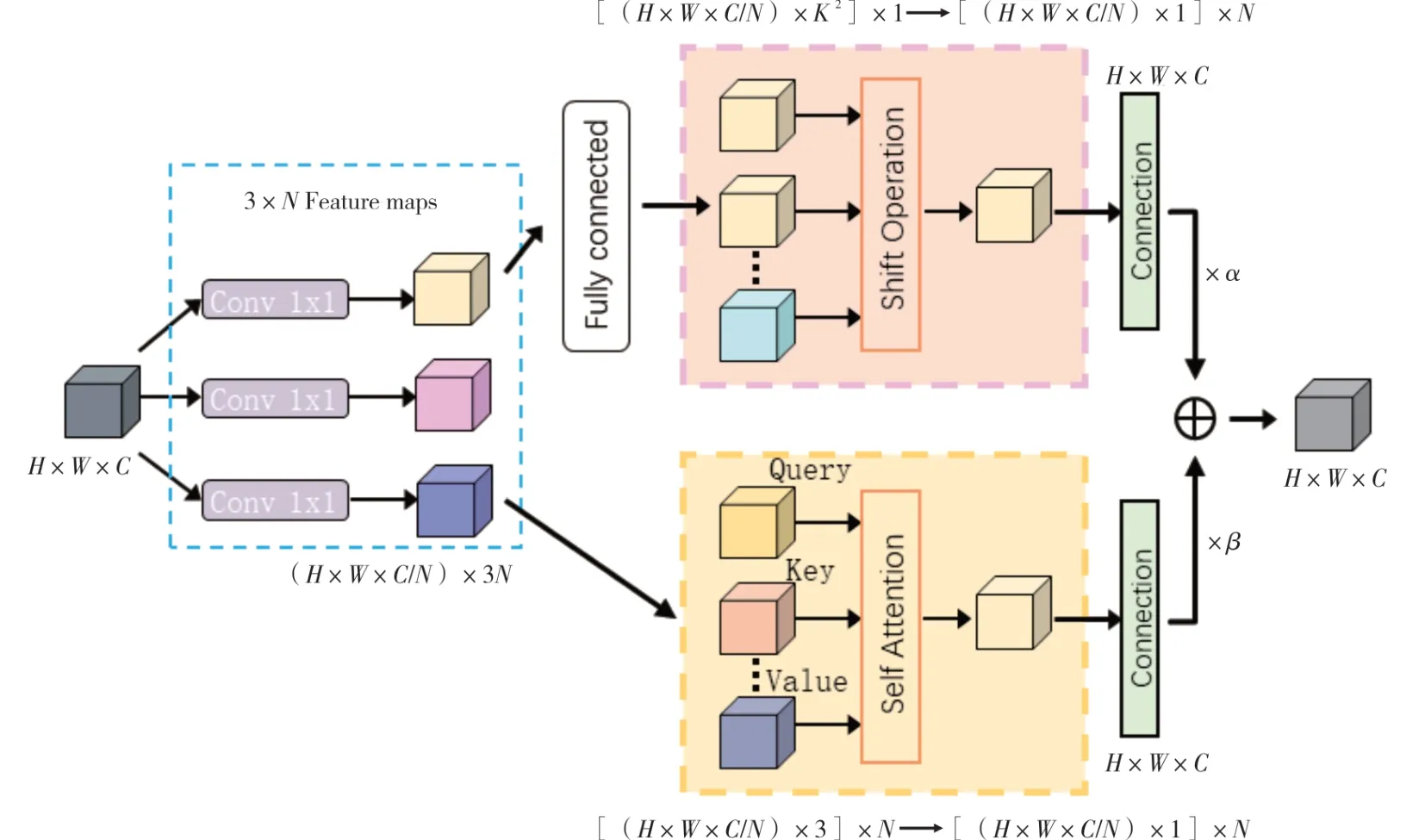
图2 ACmix 注意力模块
ACmix 注意力模块由卷积注意力和自注意力两个模块并行构建,原理如下。先将H×W×C的特征通过3 个1×1×C的卷积进行映射,分割为N个部分,得到3×N个尺寸为H×W×C/N的子特征。在上半部分(以K为内核的卷积路径),网络如同传统的卷积注意力模块,从局部感受野中抽取信息,子特征通过3N×K2N的全连接层,对生成的特征进行位移、融合和卷积处理,从而得到H×W×C/N的特征,共N组。而在下半部分(自注意路径),网络在全局信息的考量下,同时关注关键区域。3N个子特征对应的3 个H×W×C/N尺寸的特征图各自充当查询、键和值的功能,严格遵从传统的多头自注意力模型。通过位移、聚合和卷积处理后,得到H×W×C的特征。接着,两条路径的输出经过Concat 操作,其强度由两个可学习的标量控制,如公式(2)所示。
式中:Fout指代路径的最终输出;Fatt指代自注意力分支的输出;Fconv代表卷积注意力分支的输出;参数α和β的值均设为1。两个分支的输出在合并之后,全局特征与局部特征得到了平衡的考虑,从而增强网络对微小目标的识别能力。
2.3 网络结构的改进
YOLOv5 的特征抽取网络主要基于CSPDarknet 结构,该框架在输入图像上进行下采样处理,这可能导致小目标的信息遗失,因此对于小尺寸疵点的检测YOLOv5 可能表现出一些局限性。此外,YOLOv5 的特征抽取网络采用了深度卷积层设计,使得感受野逐步扩大。然而,这样的扩大感受野可能会使得目标检测算法对目标的局部精细特征敏感性降低,特别是对于具有精细纹理特征的目标。
为了解决这些问题,本研究在特征提取阶段引入了优化后的EfficientNet 网络结构作为YOLOv5 的检测网络。EfficientNet 的基础卷积模块称为移动倒置瓶颈卷积(MBConv)模块,包含1×1 升维卷积层(Conv)、批量归一化(BN)、随机失活(Dropout)、深度卷积(DWConv)、1×1 降维卷积层(Conv)以及残差连接等,结构如图3所示。

图3 MBConv 结构
本研究选用EfficientNet B1 进行改进作为特征提取网络,通过融入ACmix 注意力机制来弥补YOLOv5 在特征抽取细节方面的不足。假设输入图像的维度为H×W×C,首先,通过全局平均池化和全连接层将其转换为1×1×C的形状,然后将其与原始图像进行逐元素乘法,以赋予每个通道相应的权重,因此通过嵌入ACmix 注意力机制,使得网络可以了解到更多疵点的特征信息。此外,EfficientNet B1 网 络的MBConv 模 块 中 在两个完整的连接层之间增加了Swish 激活函数,以加快算法的收敛速度,改进MBConv 结构如图4 所示。本研究改进的YOLOv5 网络结构如图5所示。

图4 改进MBConv 结构
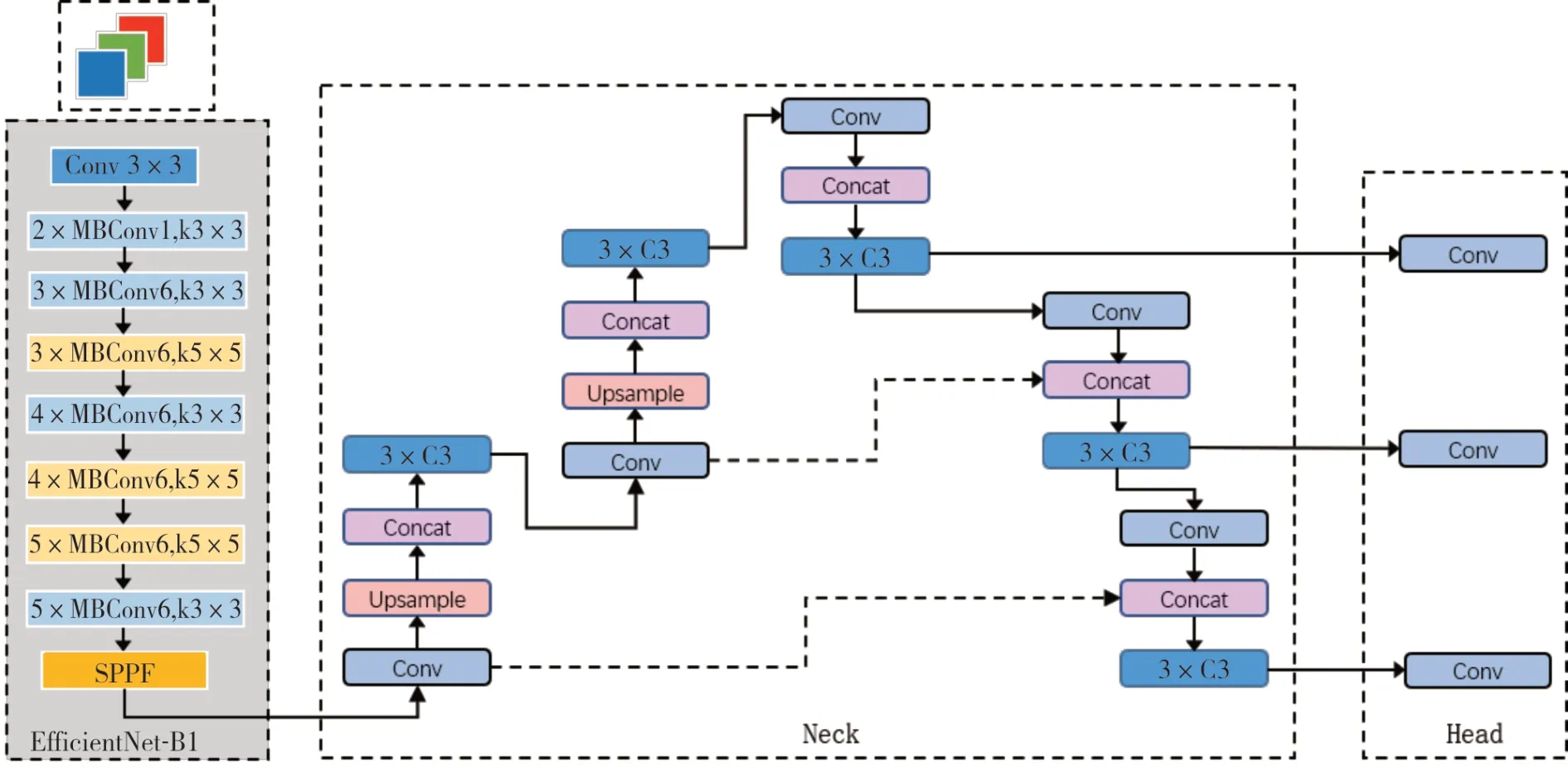
图5 改进的YOLOv5 网络结构
3 试验材料与方法
3.1 数据集
本研究样本来自于阿里云天池数据集和江苏某纺织企业,融合两个数据集构成一个包含1 780张540 pixel×450 pixel 彩色图像的数据集。针对疵点数据量少的问题,本研究采取数据翻转、数据旋转、数据缩放和增加颜色4 种处理的方法对织物疵点数据集进行扩容处理,以增加样本数量,扩充后的数据集共7 120 张。在扩充后根据疵点的长度面积以及出现的频率,将织物疵点分为2个大类6个小类,缺纱、断纱、错纱为线类疵点;污渍、磨花、结头为点类疵点。本试验按照9∶1 划分训练集和验证集。
3.2 试验环境及参数设定
本研究试验环境为64 位Win10 操作系统,NVIDIA GeForce RTX3080 显 卡,CPU 为Inter(R)Core(TM)i7-7700。编程语言为Python,深度学习框架为Pytorch。
为了保证模型训练的精度,防止训练过程中过拟合的现象发生,训练时采用YOLOv5 原始网络提供的预训练权重来训练本研究网络,以加快网络的收敛速度。在训练过程中采用标签平滑技术,将整个训练过程分为两个阶段。第一阶段采用冻结训练的方式,将学习率设置为0.001,批处理大小为6,并进行10 个epoch 的训练。第二阶段进行解冻训练,使用了SGD(随机梯度下降)[15]方法,以防止模型陷入局部最优解。此外采用了余弦学习率衰减方法,将最大学习率改为0.01,最小学习率改为0.000 1,批处理大小设置为3。
3.3 评价指标
为量化改进YOLOv5 模型对小目标疵点和复杂背景下检测的优越性,本研究采用3 个常用的目标检测评价指标:精确率(P)、召回率(R)和平均精度均值(mAP)。
4 结果与分析
4.1 消融试验
选 用EfficientNet B1、ACmix、Swish 方法 分别作为独立的变量模块,在相同的环境及训练技巧的前提下,研究各个模块在YOLOv5 网络的改进效果。表1 为消融试验结果。
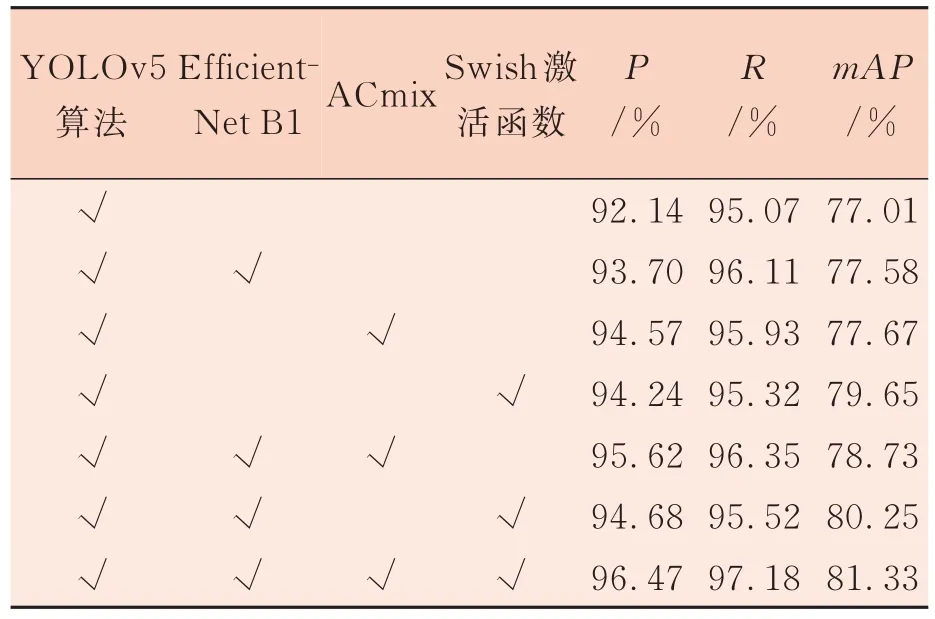
表1 消融试验
由表1 可看出,选用EfficientNet B1、ACmix、Swish 单个模块均能达到预期的效果,将EfficientNet B1 作为检测头后模型的精确率P、召回率R、平均精度均值mAP相比原始YOLOv5 算法分别提升了1.56 个百分点、1.04 个百分点、0.57个百分点;加入ACmix 后模型的P、R、mAP相比原始YOLOv5 算法分别提升了2.43 个百分点、0.86 个百分点、0.66 个百分点,说明加入注意力机制后,模型加强了疵点目标区域检测,增加了模型对疵点目标的准确率。加入Swish 激活函数后mAP相比原始YOLOv5 提升了2.64 个百分点,也表明Swish 在引入了较少的参数情况下有效地提升了模型性能。
4.2 模型对比试验
为验证本研究算法的实用性和先进性,在同一试验环境下对比了YOLOv5、SSD、Faster RCNN和EfficientNet B1 4 种模型,结果如表2 所示。
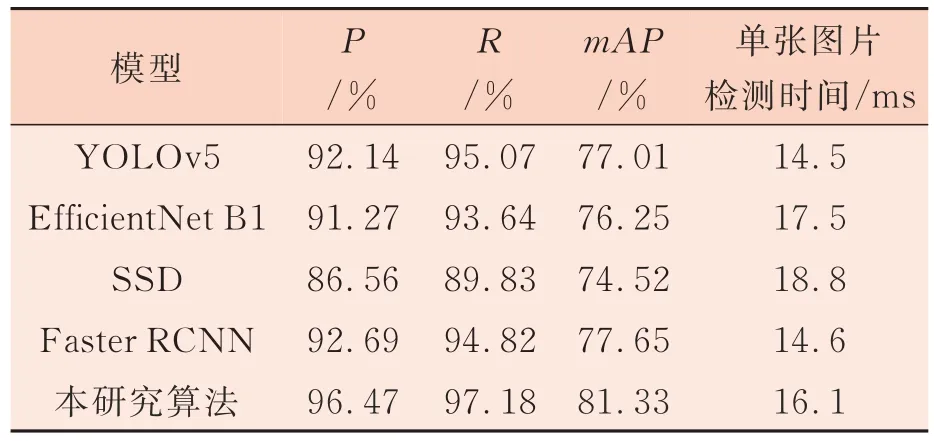
表2 不同模型的试验结果对比
由表2 可知,与EfficientNet B1、SSD 算法相比,本研究算法mAP值分别提高了5.08 个百分点、6.81 个百分点。Faster RCNN、YOLOv5 网络虽然P、R均达到了90%以上,但和本研究算法相比仍有一定差距。综合衡量不同的检测算法,本研究算法在无明显影响检测速度的前提下,具有较大的优势图6 展示了5 种算法在同一环境下分别进行疵点识别的部分检测结果。可以看出,Efficient-Net B1 网络虽可以检测到较小疵点以及多个疵点目标,但对于疵点区域的定位精度不高,容易造成较高的错误率。SSD 网络对于检测环境要求较高,容易受到灯光影响,所以对于线类疵点和小疵点这种与图片背景对比度不高的疵点容易漏检。Faster RCNN 网络在检测单一疵点时可表现出良好的检测效果,但受锚框固定的参数影响不能完全适应多个疵点目标,降低了模型检测效果。YOLOv5 网络算法对于小疵点目标不够敏感,并且在多个疵点同时出现时定位不准。本研究算法在织物疵点检测方面有显著效果,特别是在疵点分类和检测准确率方面,相比于原始YOLOv5 算法,虽牺牲了1.6 ms 的检测时间,但解决了网络对小疵点不敏感、多目标定位不准的问题,满足了工业要求。

图6 模型检测对比试验
5 结论
本研究提出了一种基于改进后的YOLOv5织物疵点检测算法,通过将原网络的检测头替换为EfficientNet B1 来增强特征提取能力;将注意力机制ACmix 模型嵌入YOLOv5 模型中,显著提高了模型在多种场景下的疵点检测性能;使用Si-LU 和Swish 两种激活函数,使得预测框回归更精准,并提高网络的鲁棒性;在疵点目标检测这一单一场景下,过滤了分类损失,提高了网络的抗干扰能力;为了降低过拟合风险,采用了几何变换等数据增强技术;采用了余弦学习率衰减法和随机梯度下降法,以防止模型陷入局部最优解并确保模型精确收敛。试验结果表明:本研究模型在对小目标的提取能力和精确率方面取得了显著提升。本研究算法的P、R和mAP值分别为96.47%、97.18%和81.33%,相比于原始YOLOv5,本研究算法的P、R和mAP分别提升了4.33 个百分点、2.11 个百分点和4.32 个百分点,可满足实际部署中小目标和检测的实时性等需求。
