基于原型与主动学习的天波雷达干扰检测方法
2023-12-18唐洪涛罗忠涛李史灿
唐洪涛,罗忠涛,李史灿,曹 健
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.南京电子技术研究所,江苏南京 210013)
0 引 言
天波超视距雷达(Over-the-Horizon Radar,OTHR)利用电离层反射高频电磁波,可以探测到视距以外的目标,有效作用距离可达3 500 km[1]。由于其工作频段(3~30 MHz)常有突发性干扰,天波雷达一直面临干扰分析与处理问题。外部干扰可对距离-多普勒(Range-Doppler,RD)图造成不同形态的污染,其中最为典型和严重的是瞬态干扰与射频干扰,因为它们能污染整幅RD 图,严重降低天波雷达的目标检测能力。
传统干扰检测主要是基于统计信号处理方法,研究重点在于干扰特性所在的时频域[2-4],而非与目标检测直接相关的RD 图。罗忠涛等人于2021 年提出将干扰检测问题转换为RD 图分类的新思路,研究了基于RD 图的瞬态干扰和射频干扰识别方法[5-6]。最近,东松林等人使用深度学习模型框架实现基于RD图像的射频干扰识别[7]。不同于在传统信号域做干扰检测,基于RD 图识别干扰可以只筛选严重干扰,忽略对目标检测不构成威胁的微弱干扰。
不过,现有的干扰检测方法对于OTHR实际运用仍有待改进。1)利用实测数据的未标记RD 图,应能有效提升干扰检测性能,但检测方法应该如何设计;2)现有的RD 图训练集及实测图集难免存在冗余样本,既会降低算法运行速度,又影响干扰检测精度。为此,本文引入原型数据与主动学习策略,为OTHR优化设计RD图干扰检测方法。
主动学习策略通过引入专家知识,利用待测样本价值来提升分类性能[8]。主动学习策略会查询难以判决的测试样本,交由专家标记后再加入训练样本集。龙军等人根据获取测试样本的形式不同,将主动学习算法分为基于池或基于流的两种类型[9],前者的选择引擎是从未标记样本集合中查询要标注的样本;后者的选择引擎则按先后次序查询未标记样本并决定是否标注。本文通过分析OTHR工作场景,认为基于流的主动学习策略适合检测干扰。
考虑样本冗余问题,本文采用原型学习方法来精简训练集。“原型”表示样本空间中具有代表性的数据点[10],原型选择的目标是从原始训练集中选择一个具有代表性的集合,其规模比原始训练集更小,但测试分类精度相近甚至更高[11]。原型选择方法可分为剪辑法、压缩法以及混合法。压缩方法通过去除冗余样本保留原型数据集[12];剪辑方法旨在滤除内部噪声,平滑分类边界[13];混合法通常使用剪辑法滤除噪声样本,然后使用压缩法保留代表性的实例[14]。本文针对OTHR 工作场景,研究基于压缩法的数据流原型学习过程,实现逐个样本的原型学习与更新。最后,结合原型数据与主动学习策略,设计天波雷达干扰检测方法。
1 问题描述
现有基于RD 图识别的天波雷达干扰检测方法,采用基于监督学习的图像分类原理,主要有“RD 灰度图生成-纹理特征提取-模式识别算法分类”三步。干扰检测器的设计思路是:使用干扰信号建模的仿真RD 图像组成训练图库,使用纹理特征算子提取不同干扰类别的纹理特征,再使用支持向量机等模式识别算法,组建成RD 图像分类器,完成干扰检测任务。目前,在现有RD图库中该分类器的干扰检测准确率可以达到90%以上[15]。
不过,考虑将上述方法用于OTHR工作场景的实测数据处理,发现了新的问题。首先,实测RD图尺寸多变,而原有仿真RD 图尺寸固定。原有仿真图像的尺寸为一般数据,分辨率为256×256。但是,实测RD 图像尺寸变化多样,可能为长条形,分辨率更低,如图1所示。使用原有方法对此类实测图的检测准确率达不到预期效果,为此需设计更贴合实际OTHR工作场景的检测算法。

图1 仿真与实测RD灰度图
其次,现有方法是基于监督学习,结合OTHR实际工作可以采用新的方法。1)为减少错误检测,希望用实测图补足训练集。将难以判决的样本交给专家标注并加入到训练集,是提高干扰检测准确率的重要思路。2)训练图库样本存在冗余问题,主动学习样本也会引起冗余,冗余样本的存在会直接影响检测效率。
为此,本文结合原型数据与主动学习策略设计干扰检测方法。首先,引入原型数据学习方法,去除训练集中冗余样本,并在主动学习过程中进行原型学习与更新。其次,引入基于流的主动学习策略进行干扰检测工作。基于流的学习策略不对未标记样本作排序比较,而是对流入样本逐一作评估,将满足条件的样本进行专家标注。
2 原型数据集学习与更新
RD 图集由训练集与测试集两部分组成,其标签分为有/无干扰两种。训练集可采用仿真图库,其生成是基于信号模型的仿真数据。无干扰建模为复高斯白噪声,干扰信号模型及图库建设方法可见文献[5]与文献[15]。实测数据则来源于某OTHR实验数据。
通过信号模型和参数调整,仿真图库的样本数量已近2 000,且明显存在图片冗余。实测图像数据是不断积累的过程,雷达只要工作就能搜集。因此,图库精简是很有必要的。
2.1 原型数据集介绍
原型数据学习的主要原理是基于数据密度与初始半径生成原型数据,其学习过程是无参数、无迭代过程且完全由数据驱动的[16]。当给定训练集有C个类别时,与之相应的就会产生C个原型数据集,每个原型数据集由同一类别的图像特征构成。不同类别的原型数据集之间互不影响,且能独立完成数据更新。针对本文任务,干扰情况分为有、无两类,故C=2。图2展示了RD图库的原型数据学习方法。

图2 训练集原型数据学习
图2的干扰样本原型集中,每个圆圈表示一个数据云,红点表示流入的特征向量。以(c,n)表示第c类别的第n个数据云,每个数据云的数据结构包括:一个具有代表性的原型数据Pc,n;数据云中心pc,n,即数据云中所有特征向量的均值;数据云半径rc,n,由初始半径与云中数据密度所决定;数据云中的数据数目Sc,n。
2.2 原型数据结构生成
本节介绍单个原型数据集学习过程,共分3步。各原型数据集之间彼此独立。
步骤1:参数初始化
第c个原型数据集由c类训练样本中第1 幅图像Ic,1进行初始化,由xc,1表示图像Ic,1的特征向量,维数为d,首先对全局特征向量进行向量归一化,即
向量归一化操作有助于克服“维度灾难”,因为两个归一化数据之间的欧氏距离可以转换为向量之间的余弦不相似度[17]。
然后对系统的元参数初始化,即
其中:k为目前已流入的实例数;μc为第c类中所有样本的特征平均值;Nc为已识别的原型数量;r0是一个较小的值来稳定新形成数据云的初始状态,本文使用定义数据云边缘相似度。
数据云非常类似于集群,但它是非参数的,没有预先确定的规则形状,而是直接表示观测数据样本的局部集成性质。数据云中原型数据Pc,n是特征空间中数据局部密度的峰值。
步骤2:准备工作
将新到达的第c类第k个训练图像表示为Ic,k,首先对其特征向量进行向量归一化则全局均值μc更新为
随后计算所有现有原型Pc,n及新图像Ic,k的数据密度,分别是
步骤3:更新原型及其参数
本阶段更新系统结构和元参数以适应新到达的图像。检查密度条件判断Ic,k是否成为一个新的原型,密度判别条件为
若满足密度判别条件,则图像Ic,k被设置为一个新的原型,并初始化为一个新的数据云,有
若不满足密度判别条件,需判断是否建立新的原型。查找距离图像Ic,k的最近原型,为
使用邻域条件判断Ic,k是否位于Pc,n的影响区域。邻域判别条件为
若满足条件式(8),则Ic,k归为原型Pc,n所属的数据云,其数据结构更新如下:
然后,重复步骤2,读取下一幅图像。在所有训练样本处理完毕后,生成原型数据集。
原型数据集生成过程如图3 所示。在本文方法中,不仅原始训练集会作原型学习,主动学习过程中加入的测试样本及其标签也会加入原型学习,因此原型数据集及其参数会随着学习过程持续更新。

图3 原型数据集生成与更新算法(算法1)
3 主动学习策略与干扰检测方法
3.1 基于原型数据的图像分类准则
RD 图库中标签为有/无干扰两种类别,经训练阶段生成彼此独立的两个原型数据集,使用原型数据集对待测图像进行逐个测试。基于原型数据的RD 图像分类过程如图4 所示,分为图像处理与图像分类两个阶段。

图4 基于原型数据的RD图像分类过程
1)图像处理
本阶段首先完成图像预处理工作。信号模型所仿真RD图尺寸为256×256,但实测RD图尺寸比例有所差别,导致原有分类器精度急剧降低[15]。为使实测RD 图特征更接近于仿真RD 图,将不同尺寸大小的实测RD 图复制拼接,达到仿真RD 图尺寸大小。RD 图干扰分类的根本依据在于纹理特征不同,将不同尺寸大小的实测RD 图进行复制拼接对整幅RD 图像的纹理特征形态影响较小,进而对干扰检测的影响可忽略不计。
因为RD图像有/无干扰时具有不同纹理,因此纹理特征可用于分类器设计。已有工作经验发现,局部二值模式(Local Binary Pattern, LBP)特征算子对RD图干扰检测具有较好效果[6]。因本文研究重点在于分类算法的设计,所以采用表现较优异的LBP 特征算子完成特征提取,其参数圆形领域半径R设为1,领域内像素点个数Q设为8。设待测图像I经图像处理过程后,得到对应的特征向量x。
2)图像分类
特征向量x针对每类原型数据集,生成对应的置信度分数,再比较各类置信度分数,判决得出预测标签。
图像I的特征向量x在第c类原型数据集中的置信度分数λc(I)计算式为
因此,在RD 图测试过程中每幅图像I可以得到一个置信度分数向量:λ1×2(I)=[λ1(I),λ2(I)],对置信度分数向量作比较,得到预测标签。
简言之,预测标签为测试图像在不同原型数据集中最高置信度分数对应的类别。
3.2 基于原型数据与主动学习的干扰检测方法
主动学习侧重于查询信息量大的样本,将测试样本中容易判错的实例交由专家标注,即通过一个互动交互过程引入额外专家知识[18]。本文将基于原型数据集,采用置信度衡量来检测干扰,并引入主动学习策略,查询信息量大的测试样本作人工标记后再加入训练集。
本文采用基于流数据的主动学习方法,源于对OTHR 实际工作考虑。天波雷达常常是每隔数秒接收1帧,每帧可有数十幅RD图像,干扰随时可能出现在任意一帧,具有很大的随机性。因此,基于流的主动学习可以直接处理当前帧当前图像,无需等待后续数据跟进,适合OTHR 的实时处理需要。
本文设计的主动学习分类器的工作思路是:针对每帧各幅RD 图像,查询是否满足学习条件;如是,则将其加入缓冲池,专家每隔K帧对缓冲池样本作人工标注,并对其结果进行原型学习与更新;否则,对该幅图像进行标签预测。
设U为测试样本集,P为待标记样本缓冲池,k为当前测试图像帧序号,基于流的主动学习步骤如下:
步骤1:以第k帧第m张图像Ukm为当前待测图像,提取其特征x,根据公式(10)计算置信度分数λ1(Ukm),λ2(Ukm)。
步骤2:判断置信度分数是否满足判别公式
式中γ是一个超参数,γ>1。置信度分数相差越小,表示该图像不确信程度越高,信息量越大。若待测图像满足置信度判别条件,则加入到缓冲池P中;否则读取下一幅图像,并返回步骤1。
步骤3:查询当前检测帧数k是否为K的整数倍。如是,则将缓冲池P样本集交由专家标注,并作原型学习,之后将缓冲池清零。否则,读取下幅图像,并返回步骤1。
最终,基于原型数据集与主动学习的干扰检测流程如图5 所示。首先对原始训练集作原型学习,生成原型数据集,再基于原型数据进行测试集的主动学习与干扰检测工作。由式(12)判断待测图像是否值得学习;不学习的待测图直接根据式(11)作干扰检测标签预测;要学习的图像经过人工标记后进行原型数据学习更新。
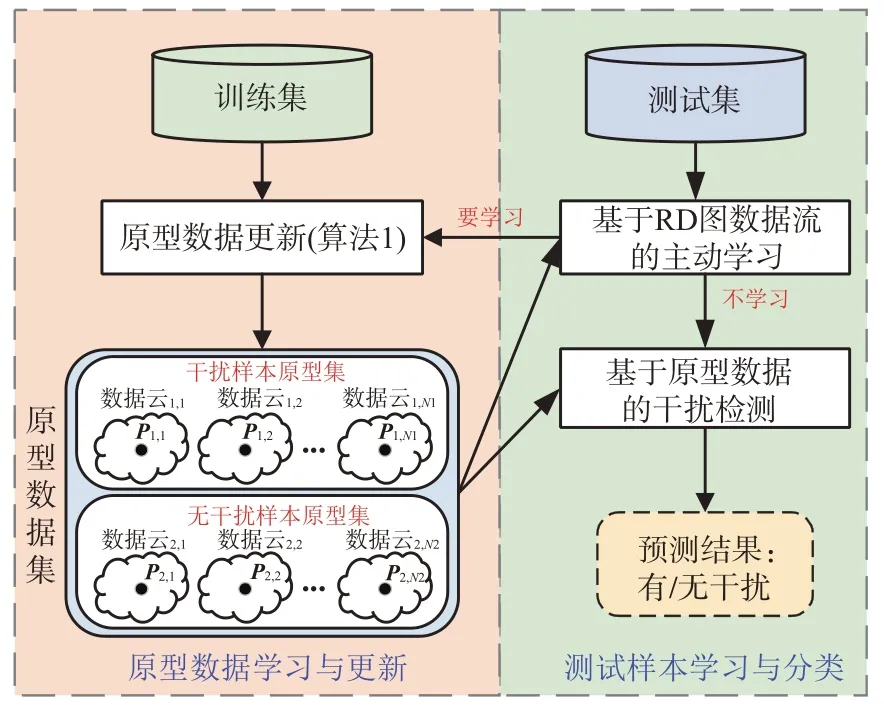
图5 基于原型数据与主动学习的干扰检测流程
4 仿真对比
4.1 数据集介绍
本文实验的RD 图库由训练图库与测试图库两部分组成,样本数量如表1 所示。其中,训练图库采用仿真RD 图,实测图库采用OTHR 的1 658帧实测RD图。

表1 RD图库样本数量
4.2 实验设计与结果
对于天波雷达来说,错误检测可能是干扰的漏检或虚警。本文以干扰检测准确率与检测概率作为性能评价标准。
检测准确率反映全体样本分类精度,定义为:正确分类样本数除以测试样本总数。
检测概率针对每个类别单独计算,定义为:某类别正确分类数除以该类别测试样本总数。
为验证原型和主动学习方法的有效性,本文采用相同特征算子参数、训练集与测试集,对5 种干扰检测方案作对比分析。
本文方法:作原型学习,且引入主动学习策略,即本文所设计基于原型与主动学习的干扰检测方法,其中参数设置为γ=1.01,K=100。
最近邻监督(简称“近邻监督”)方法:基于初始训练集,直接使用最近邻算法做干扰检测工作[15]。
原型监督(简称“原型监督”)方法:对初始训练集作原型学习,但不作主动学习,对测试图作干扰检测。
原型半监督(简称“原型半监督”)方法,对初始训练集和学习样本作原型学习与半监督学习,半监督学习策略是将式(12)的条件更改为λ1(Ukm)/λ2(Ukm)>γ'或λ2(Ukm)/λ1(Ukm)>γ',其中超参数γ'设为1.1。
原型随机采样(简称“原型随机”)方法:依然采用原型学习,在干扰检测过程中随机抽选部分图像加入缓冲池,最终所选样本数与本文主动学习样本数相接近,每隔K帧作人工标记并加入训练集,K值设为100。本实验可验证本文主动学习策略对干扰检测的性能提升程度。
图6 展示了5 种方案工作累计的检测准确率与检测概率,表2比较了它们的两类样本学习数量与训练样本量(原型数据保留量)。

表2 5种方法的学习样本量与训练集样本量
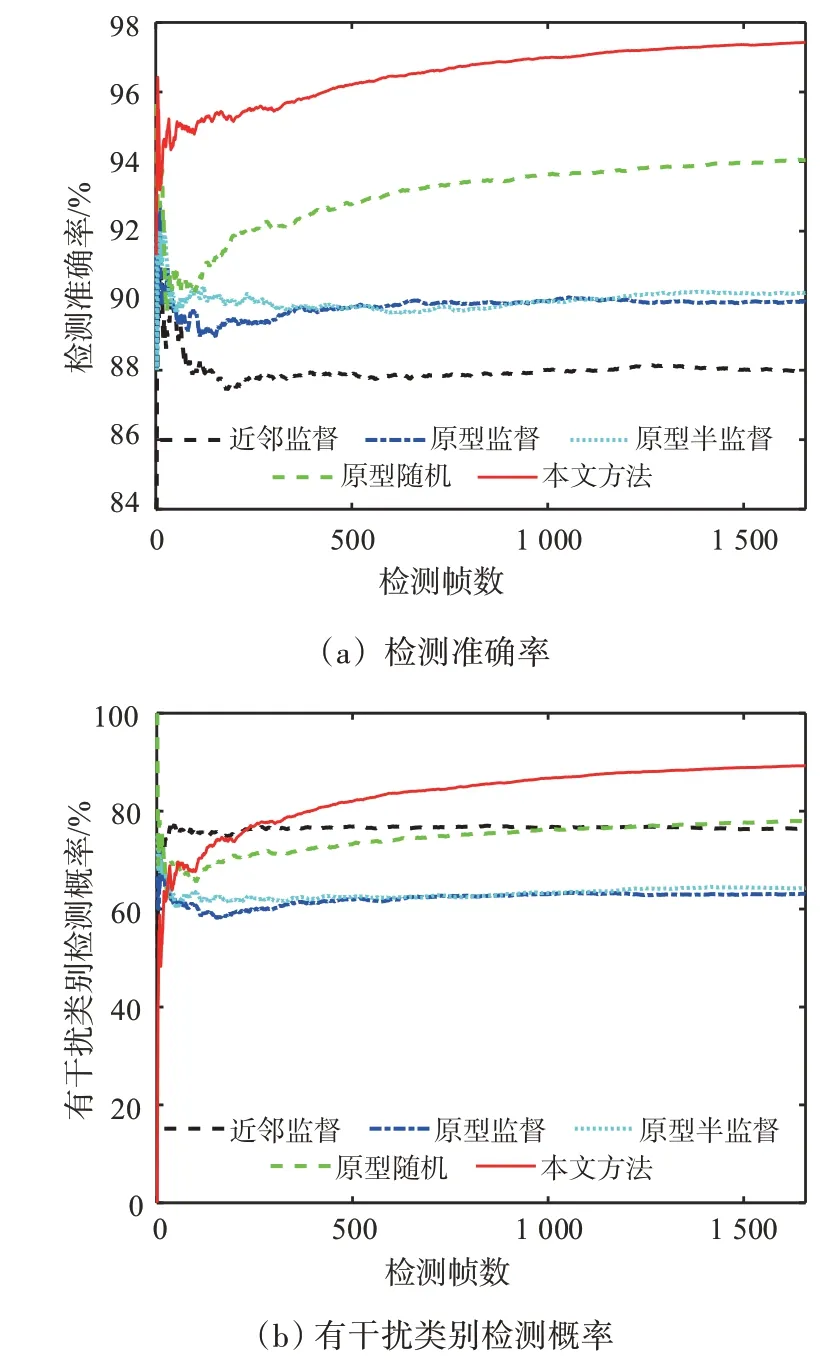
图6 干扰检测准确率与检测概率
4.3 结果分析
分析图6与表2数据,可知:
1)原型监督与近邻监督方法相比,原型学习将训练样本量由1 968 缩减至463,同时检测准确率由87.96%提升至89.97%。说明了原型学习方法在减少训练集冗余样本上的有效性。
2)与原型监督相比,原型半监督方法虽然自主学习了部分高置信度样本,但检测准确率与检测概率无明显改变。
3)与近邻监督方法相比,本文方法在测试过程中学习2 243 个未标记样本,但最终训练集原型量为847,仍小于近邻监督方法的训练集样本量。并且,检测准确率由87.96%提升至97.42%,干扰检测概率由76.43%提升至89.31%,无干扰类别检测概率由91.18%提升至99.34%。
4)与原型监督方法对比,本文方法通过主动学习,只多了384 个原型保留量,但检测准确率和干扰检测概率均有大幅提升,无干扰类别检测概率有小幅提升。
5)原型随机标记方法也能提高检测准确率和干扰检测概率,但是效果不如本文方法。这说明,在干扰检测工作中,样本越是难以判决,所含信息量越大,人工标记带来的帮助越大。
综上所述,本文引入主动学习方法,通过人机交互过程提升干扰检测准确率,并使用原型学习方法保证训练集的精简性。在天波雷达实际工作中,雷达工作者可在累积标注一定数量的实测样本后停止标记,因为此时的算法模型已具备较优的检测性能。
5 结束语
RD 图像识别是天波雷达检测干扰的一个新思路。为了使天波雷达能够有效利用实测RD 图像,本文结合原型数据设计了一种具有主动学习能力的干扰检测方法。原型数据学习不仅能够大幅减少原有仿真训练集样本量,而且在主动学习过程中进行持续更新,最终保持一个较小的训练原型数量。实测数据的实验表明,本文引入原型和主动学习策略后,所设计干扰检测方法相比传统最近邻监督学习方法,检测准确率提升约10%,其中干扰检测概率提升约13%,无干扰检测概率提升约8%。本文方法可对RD 图像进行逐帧逐样本检测,适用于天波雷达的实际工作场景。
