机器学习方法预测可燃性粉尘最小点火能的应用研究*
2023-12-16沈晓波张智玮汪圣华李学盛牟杰包其富
沈晓波 张智玮 汪圣华 李学盛 牟杰 包其富
(1.华东理工大学资源与环境工程学院,上海 200237;2.浙江省应急管理科学研究院浙江省安全工程与技术研究重点实验室,浙江 杭州 310012)
0 引言
粉尘爆炸是工业生产过程中较容易出现的危险情况之一[1]。了解粉尘以及其他易燃材料的性质对于粉尘事故防控具有重要意义。然而,通过实验方法来了解材料的特性不仅存在一定的危险性,且成本较高。随着医药、化工和新材料行业的发展,新的化学品被不断地合成和生产出来,面对这些未知化学品的粉尘爆炸危险性,寻找一种快速对样品的燃爆敏感度进行预测,实现未知化学品粉尘爆炸风险的快速评估,同时也能作为实验测试前粉尘危险特性预筛的方法非常重要。定量构效性质关系QSPR(Quantitative Structure Property Relationship)描述了化学或生物特性与结构属性之间的数学关系。在安全和爆炸领域,QSPR 模型被证明对目标特性(如分子单点能、偶极矩和分子极化指数等)具有良好的预测能力。QSPR 方法也经常被用于药物、材料和表面活性剂的制造以及安全性调查和其他的研究之中。
SHEN S 等[2]通过遗传算法以及多元线性回归方法建立了燃料混合物可燃性上限的QSPR 模型,该模型可以稳定地预测燃料混合物的可燃性上限;朱晓等[3]基于QSPR 原理,利用遗传-偏最小二乘(GA-PLS)方法筛选出相关描述符,采用多元线性回归建立了链烷烃辛烷值的预测模型,为有效预测辛烷值提供了一种新方法。
针对可燃性粉尘,REYES O J 等[4]收集了31 种不同的化学粉尘,利用Material Studio 5.0 软件以及遗传算法(GFA)建立了最大超压(Pmax)以及粉尘燃爆指数(Kst)的数学预测模型;CHAUDHARI P 等[5]利用随机森林、人工神经网络和遗传函数等数学方法建立了最小点火能预测模型并进行优化,使得随机森林算法的测试集R2达到0.85,人工神经网络和遗传函数逼近模型的测试集R2则为0.79 和0.71。
在国内,赵琳[6]首次采用线性回归方法计算了可燃气体及蒸气的分子描述符,建立了最佳多元线性回归与启发式回归方法的最小点火能预测模型,并取得了预期的研究成果;国际上,CHAUDHARI P 等[7]首次利用随机森林和决策树算法建立了芳香族化合物的最小点火能二分类预测模型,并证明随机森林是应用于QSPR 中分子描述符约简的重要工具。
然而,在多数文献中针对燃爆参数特性预测的研究对象多采用气体、烃类化合物及芳香族化合物,并且多局限于使用回归方法进行预测,本文采用链式有机化合物,由于链式化合物多为脂肪族化合物,并且大多数情况下是由碳氢结构组成,体现出了极高的易燃性。通常情况下对于脂肪族化合物的研究只考虑了其毒性而未考虑其粉尘爆炸危险性,本文利用机器学习算法进行二分类预测,建立此类化合物分子结构特征参数与最小点火能(MIE)之间的构效关系模型,并开展模型预测能力评估和验证,以弥补此方面研究的不足,研究成果可为同类化合物MIE的快速筛选提供有力工具。
1 研究方法
1.1 数据集
各类可燃性有机化合物粉尘的燃爆参数的实验数据从GESTIS-DUST-EX 数据库[8]中获得。本文从数据库6 973 条现有数据中选择出了有最小点火能(MIE)记录的37 种链式有机化合物进行研究,以上述37 种链式有机化合物粉尘的最小点火能(MIE)作为目标特性进行预测。表1 为化合物的最小点火能(MIE)分布。MIE 较小的物质点火敏感性较低,相对来说更加易燃甚至易爆。根据美国消防协会行业标准NFPA 652 和NFPA 77 规定,由于人体是良好的电导体,在正常活动中,人体电位可达10 ~15 kV,产生的火花能量可达20 ~30 mJ,从而导致静电放电事件的发生,因此点火敏感材料的MIE 为30 mJ或更低。根据美国劳工部所著的《职业安全与健康管理局技术手册》的第6 部分《可燃性粉尘》规定,低MIE 可燃粉尘是MIE≤30 mJ 的粉尘,如果任何化学品制造商的数据、雇主委托的MIE 测试结果或公布的数据显示,材料的MIE为≤30 mJ或可能为≤30 mJ,CSHO 应根据本协议将粉尘视为危险采样。所以通常情况下30 mJ 被认为是判断粉尘点火敏感性与危险性的重要指标。因此本文以30 mJ 作为MIE的分类界限,将上述37 种粉尘分成“最小点火能小于30 mJ”和“最小点火能大于30 mJ”二大类,模型中的输出代号分别为“0”和“1”。为开展机器学习建模和验证,随机选择其中的70%用于模型开发(即训练集),30%用于模型验证(即测试集)。

表1 链式化合物最小点火能分布
1.2 几何优化及分子描述符筛选
通过Pubchem 数据库获取了本文所考察的37种链式化合物的分子结构。在计算分子描述符之前应进行几何优化以获得具有最低能量的分子结构,以保证模型开发的可靠性。本文选择在B3LYP 密度泛函理论以及6-31G(d)基组的条件下,利用Guassian 16(G16)程序对分子结构进行优化。该方法被证实具有较佳的优化效率[9]。随后,将优化后的分子结构导入Material Studio 2019 软件进行分子描述符计算,初步筛选出352 个分子描述符。
特征分子描述符的筛选对减小模型开发规模和提高计算效率非常关键。首先进行预筛选,筛除恒为0 的常数及描述符之间相关系数大于0.95 的分子描述符,初步筛选后分子描述符数量降至108 个。然后应用随机森林算法对分子描述符开展进一步筛选。当随机森林算法应用于特征选择时,会在每个决策树中计算每个特征的置换特征重要性得分。在计算出每个特征的重要性得分后,随机森林算法会根据重要性得分从大到小对所有特征进行排序,删除重要性得分较低的特征。由此,最终得到9 个特征重要度较高的分子描述符,如表2 所示。
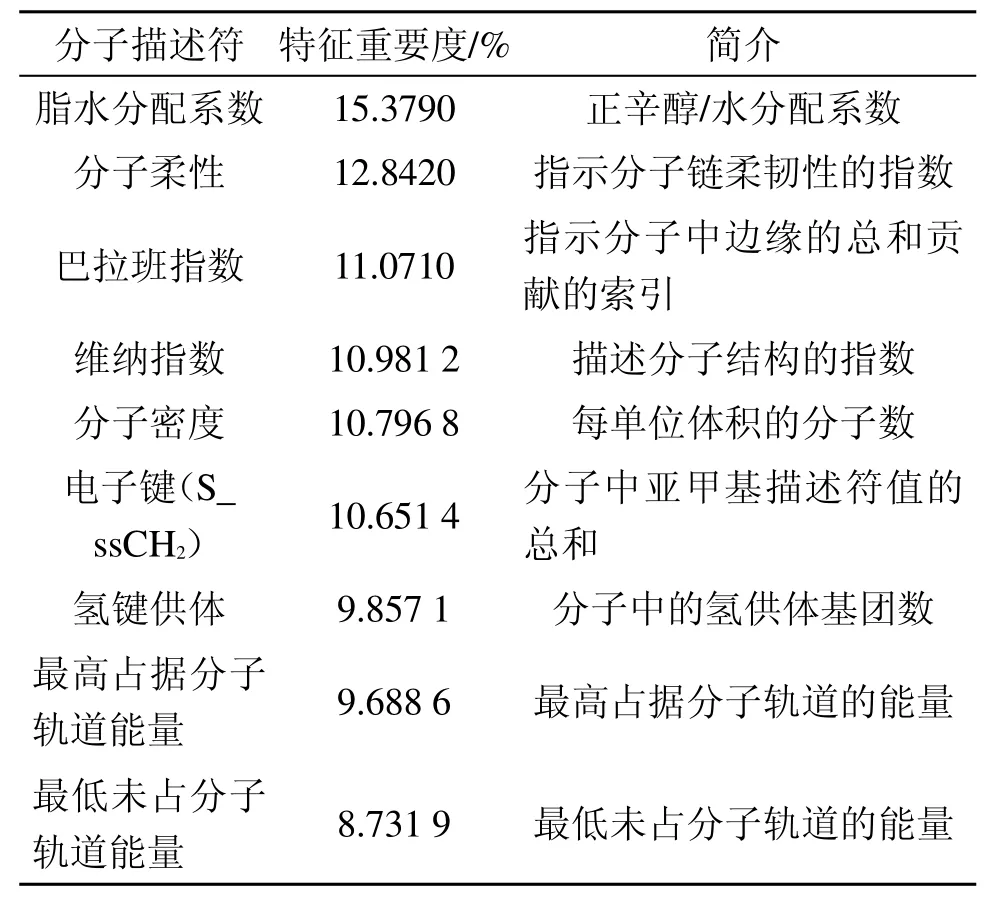
表2 分子描述符特征重要度
1.3 模型可靠性指标
对于二分类问题,一般用精确率、准确率、召回率、F1值以及PR曲线来评估二分类模型的预测结果质量。
TP(True Positive)指正类预测为正类,FP(False Positive)指负类预测为正类,FN(False Negative)指正类预测为负类,TN(TrueNegative)指负类预测为负类。
PR 曲线是指在二分类任务中,根据学习器(分类器)的预测结果对样例进行排序,按此顺序逐个将样本作为正例进行预测,每次计算出准确率作为纵坐标,召回率作为横坐标,得到PR 曲线(Precision-Recall Curve)。
2 结果与讨论
2.1 二分类算法优异性对比
2.1.1 不同算法的PR 曲线对比
本文中将最小点火能以30 mJ 为界限,对37种链式化合物的最小点火能为对象进行二分类预测。为了选出较适合粉尘燃爆数据集二元分类的算法,首先将10 种常用的二分类算法用于数据集的学习和预测,以PR 曲线结果作为初步评价标准(图1)。
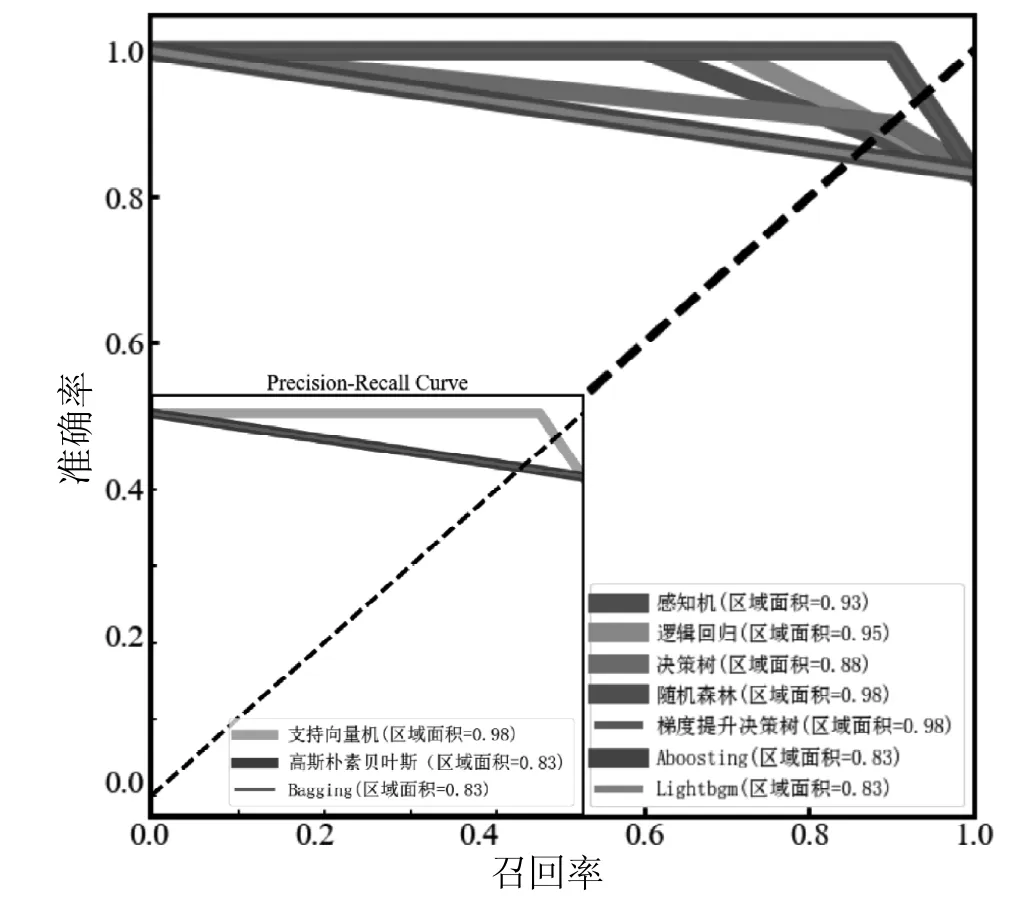
图1 二分类模型PR 曲线
在10 种不同算法中,逻辑回归、支持向量机、随机森林以及梯度提升决策树的PR 曲线的区域面积在95%以上,而其他的6 种算法在该数据集上的表现欠佳。
2.1.2 模型评估指标对比
上述4 类算法PR 曲线评估较佳的二分类模型详细比较如表3 所示。
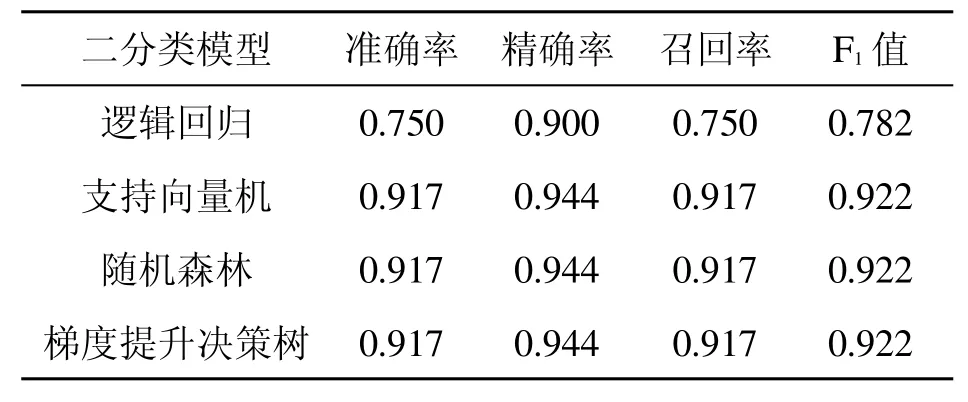
表3 二分类模型评估分数
二分类模型的混淆矩阵见图2。
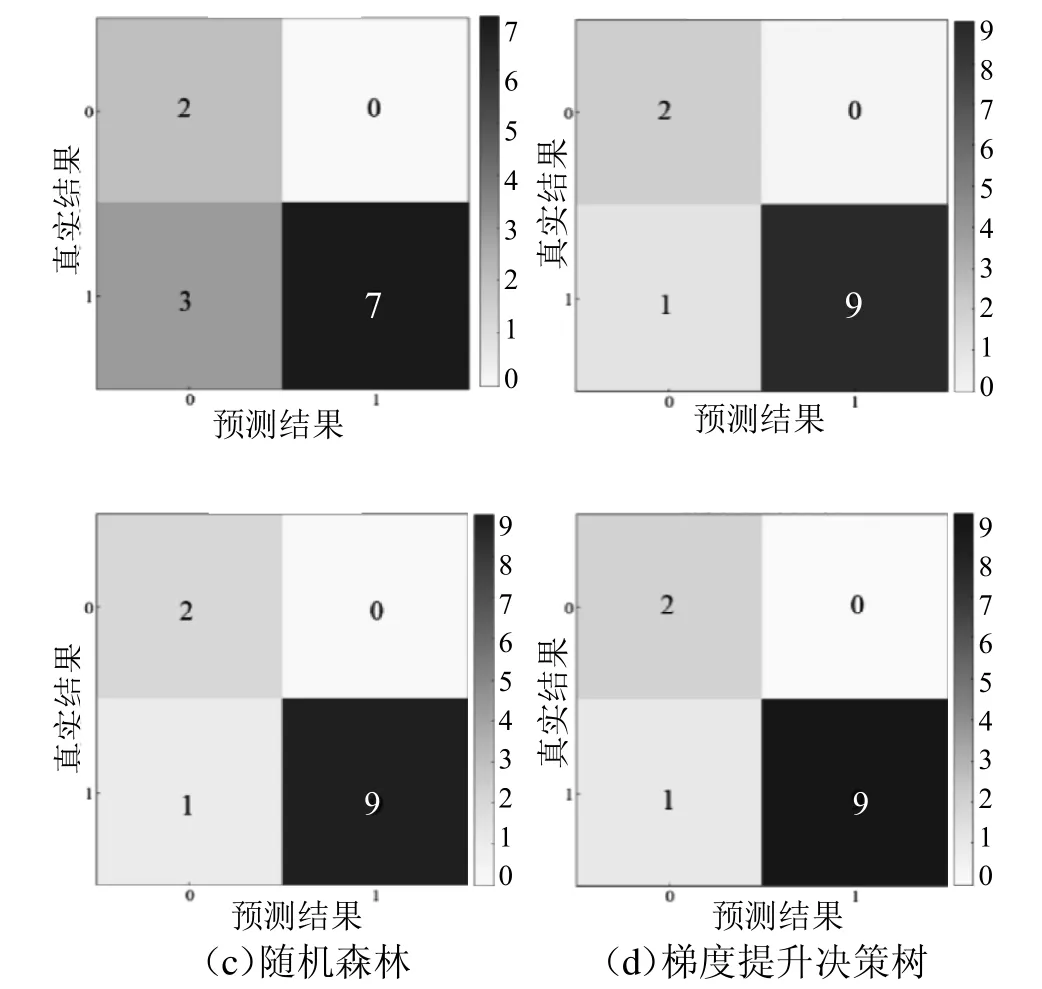
图2 二分类模型的混淆矩阵
从上述评估结果可以看出,以线性函数拟合决策边界的逻辑回归在多特征的情况下表现欠佳,而核函数为(高斯)径向基函数核(Radial Basis Function Kernel)的支持向量机在多特征的情况下预测性能良好,它与集成算法中的随机森林和梯度提升决策树的评估分数都在90%以上,表现出了极好的预测能力与稳定性。
从上述9 类特征中选出重要度最高的分子柔性和脂水分配系数作为二特征二分类模型评估的输入数据,结果如表4 所示。
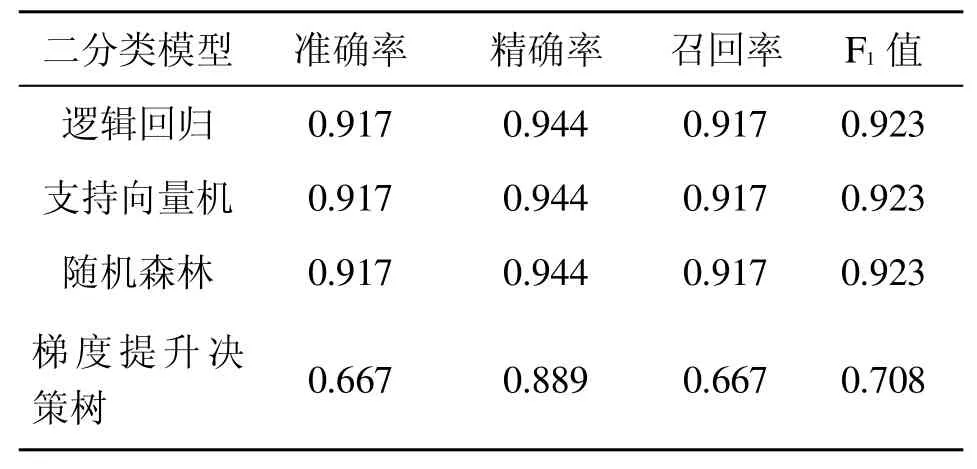
表4 二分类模型评估分数
不同模型的二分类结果见图3。
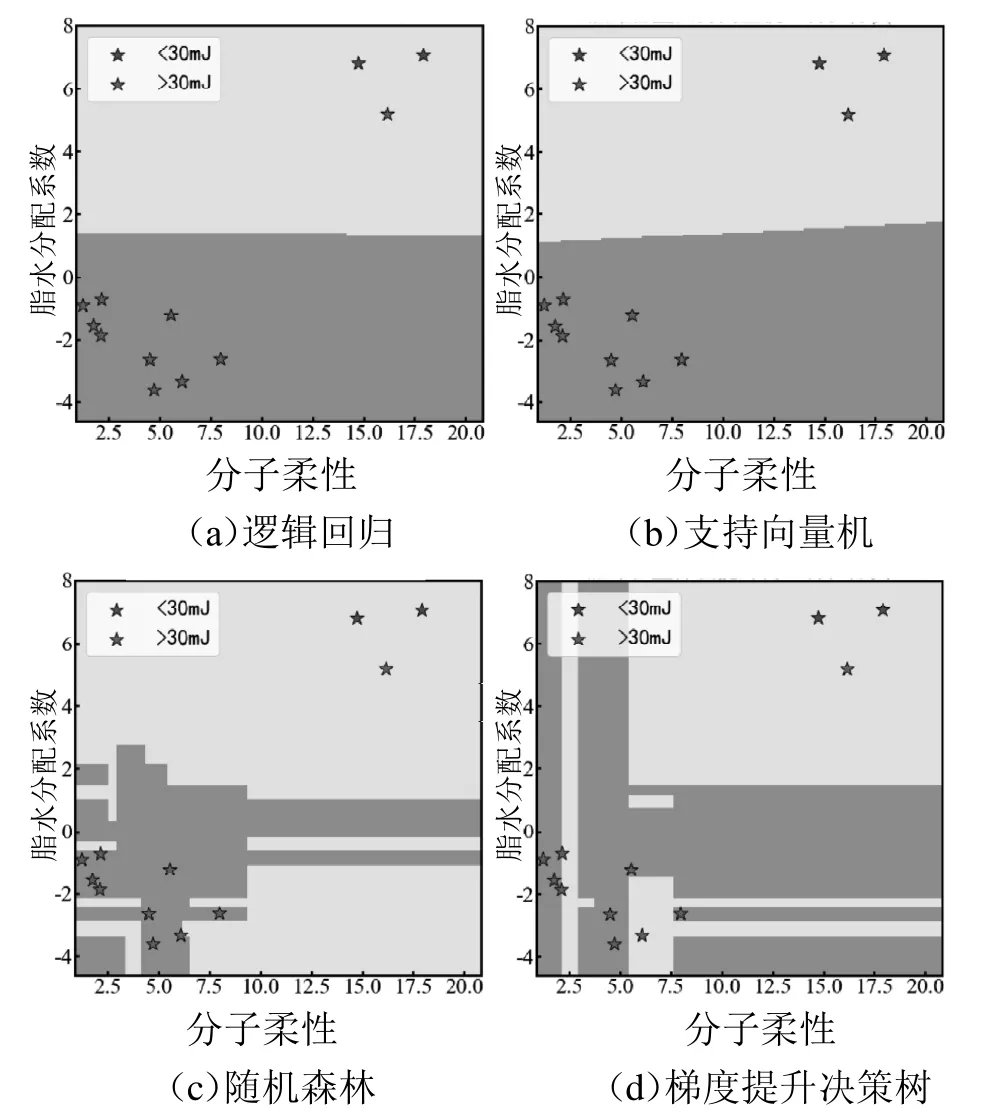
图3 不同模型的二分类结果
从上述结果可以看出,在二特征二分类的情况下,不同算法因决策边界不同而对预测结果产生影响。决策边界是一个将属于不同类别标签的数据点分开的表面,决策边界对整个数据集的特征空间进行了划分。决策边界可以表现出每个特定模型对数据集中每个数据点的敏感程度。
在上述4 个PR曲线评分较高的模型中,逻辑回归和核函数为线性核(Linear kernel)的支持向量机的决策边界是一条直线,这是因为二特征的数据分布呈现出良好的线性可分性,所以在此种情况下由线性函数创建的线性决策边界进行预测点分割体现出了良好的性能。而在进行多模型比较时由于数据特征参数存在多维分布且具有非线性特征,使得逻辑回归表现较差,而核函数为(高斯)径向基函数核(Radial basis function kernel)的支持向量机在非线性数据分布中同样体现出较好的稳定性。
以决策树为基础的随机森林和梯度提升树的决策边界,则更加灵活。由于决策树的决策边界是由训练样本推断的简单阈值规则组合构成的,因此经常是以平行于x 轴和y 轴的线条通过决策树不同分枝上的随机属性进行投票而划分出的区域。随机森林和梯度提升树的决策边界则是集成学习下不同决策树叠加而产生的分割区域。而相比梯度提升树,随机森林的优越性在于,随机森林仅通过随机选择的决策树,利用随机特征进行多数投票来划分类别。每个决策树互相独立且互不影响,而梯度提升树的决策树是串行迭代过程,每一次的提升都是靠上次的预测结果与训练数据的差值作为新的训练数据进行重新训练,预测结果为所有决策树的累加值,因此决策树之间互相影响,并且因为分类标签数据是离散的,梯度提升树无法直接从输出类别去拟合类别输出的误差,所以分类结果会略差于随机森林。
综上,支持向量机和随机森林在对上述37 种链式化合物最小点火能分类预测中表现出较优异的预测效能和稳定性。
2.2 分子描述符与MIE 相关性的机理分析
在所筛选出的2 种算法中,脂水分配系数和分子柔性具有较高的相关性,见图4。脂水分配系数(LogP)描述了化合物在脂质和水不相容的双相体系中的溶解倾向,它可以衡量溶质在水与脂质中的溶解程度。主要溶于水层的溶质表现为亲水性,而主要溶于脂质的溶质表现为疏水性。极性大、亲水性化合物的LogP较低(可以为负),非极性疏水化合物则具有更高的LogP。典型值范围从-3(极性)到7(非极性)。因此,LogP 可以用于反映分子的极性。随着极性的不断增强,分子间作用力亦不断增强。分子间作用力将物质紧密地结合在一起。当外部受热平均动能不断增加超过分子间作用力的束缚物质即会发生相变,所以分子间作用力更低的非极性物质会更容易发生相变,其物质也更易点燃。
分子柔性即分子链的链柔性,通常指大分子有机物分子链内骨架,如C—C键发生内旋转使高分子链卷曲的能力,这会对分子链的性质产生影响。分子间作用力亦会对分子链段的柔性产生限制,分子间作用力越强,对链段的柔性影响越大,分子柔韧性不断减小,其物质状态也更加稳固,从而使物质更不容易点燃并具有更高的最小点火能值。
电子键反映了所连接的电子键基团的影响,该电子键的分子描述符表现出了所连接的甲基(—CH2)。巴拉班指数是一类拓扑描述符,它可以用来描述分子的结构与形态,将链式化合物的分子结构看作是一个有n 个节点、m 条边和c 个连接部件的图来说,其定义为:
式中,y=m-n+c 是图的等级,E(G)是边集,Di是图距离矩阵第i 行(或列)的所有条目之和。维纳指数也是一个拓扑描述符,将链式化合物看作有n 个节点的分子结构,其定义为:
式中,d(ij)是图的距离矩阵。拓扑描述符一定程度上反映了分子结构对分子反应的影响以及和最小点火能之间的相关性。
分子密度是单位体积分子的个数,单位体积内的分子个数越多,分子间作用力越大,分子结构也越为紧密,则其也越难被点燃,分子密度与最小点火能也表现出了较高的相关性。最高占有分子轨道(HOMO)的能量、最低未占有分子轨道(LUMO)的能量和也是影响最小点火能预测精度的重要因素。由于最高占有分子轨道和最低未占有分子轨道构成分子轨道,这些描述符与分子的反应性有高度相关性,因此可能也与可燃粉尘的最小点火能大小密切相关。
3 结论
1)本文从GESTIS-DUST-EX燃爆特征数据库中筛选了37 种可燃性链式有机化合物粉尘,筛选出与最小点火能相关的分子描述符并进行重要度排序,结果表明,链式有机化合物的脂水分配系数和分子柔性是2 个与最小点火能相关重要度较高的分子描述符。
2)利用常见的10 种二分类机器学习算法,对37种可燃性链式有机化合物粉尘的最小点火能进行二分类预测应用和比较分析发现,支持向量机和随机森林表现出较优异的预测效能和稳定性。
3)从分子间作用力的角度,对脂水分配系数和分子柔性是2 个重要度较高的分子描述符与MIE之间的影响进行机理分析解释,为相关QSPR 模型分子描述符的选择提供指导。
4)目前同类物质的MIE 数据还非常有限,因此下一步将进一步挖掘文献数据,并开展实验测试,获得更多的MIE 数据用于构建预测模型和模型验证。
