Deep learning-based automated grading of visual impairment in cataract patients using fundus images①
2023-12-15JIANGJiewei蒋杰伟ZHANGYiXIEHeGONGJiaminZHUShaominWUShanjunLIZhongwen
JIANG Jiewei(蒋杰伟), ZHANG Yi, XIE He, GONG Jiamin, ZHU Shaomin,WU Shanjun,LI Zhongwen
(∗School of Electronic Engineering, Xi’an University of Posts and Telecommunications, Xi’an 710121, P.R.China)
(∗∗School of Ophthalmology and Optometry and Eye Hospital, Wenzhou Medical University, Wenzhou 325000, P.R.China)
(∗∗∗Ningbo Eye Hospital, Wenzhou Medical University, Ningbo 315000, P.R.China)
Abstract
Key words:deep learning, convolutional neural network (CNN), visual impairment grading,fundus image, efficient channel attention
0 Introduction
Cataract is a typical visual disorder disease with lens opacity caused by various factors such as genetics,infection, trauma, and aging[1].According to reports[2-3], cataract is the leading cause of reversible blindness and visual impairment globally.It is estimated that there are approximately 208 million cataract patients in China[4], who suffer from poor visual acuity in varying degrees.Clinically, two alternative treatment strategies are available for cataracts according to the severity of visual impairment[5].Conservative treatment with drug intervention can be used for cataract patients with the best corrected visual acuity (BCVA) greater than or equal to 0.3.On the contrary,early surgery is an appropriate choice to prevent the deterioration of visual acuity for mature cataract patients with BCVA lower than 0.3[6].Correspondingly,the degree of visual impairment caused by cataracts can be categorized into two groups: mild visual impairment caused by cataracts (MVICC), and moderate to severe visual impairment caused by cataract (MSVICC).Therefore, it is necessary to grade visual impairment in cataract patients to determine specific treatment strategies.
Clinically, the assessment of BCVA for cataract patients usually relies on the manual inspection by ophthalmologists, which is a time-consuming and labor-intensive process[7].In particular, the large-scale screening of BCVA is limited by the sparse and uneven distribution of ophthalmologists, and many suspicious patients may not be accurately diagnosed in a timely manner[8].To cross the chasm of manual diagnosis defects in ophthalmology,it is therefore essential to develop a diagnostic algorithm for the automatic grading of visual impairment in cataract patients.
Recently, artificial intelligence has attained remarkable performance for the automatic diagnosis of various diseases based on medical images, such as skin cancer[9], diabetic retinopathy[10], glaucoma[11],and age-related macular degeneration[12].Also, several studies developed artificial intelligence-based systems for the cataract diagnosis.Guo et al.[13]employed a wavelet transform method to extract features from fundus images and performed the automatic screening and grading of cataract, in which the accuracies reached 90.9% and 77.1%, respectively.A hybrid global convolutional neural network (CNN) was applied to learn high-level semantic features from original images, in which the principle of characterizing cataracts was analyzed using a layer-by-layer deconvolution technique[14].A 16-layer lightweight CNN was proposed to improve the classification performance of cataract diagnosis and reduce the number of parameters, so that it has the potential to be deployed on mobile terminals[15].Zhang et al.[16]employed a superimposed multi-features fusion method for a six-categories grading system of cataracts.Moreover, an artificial intelligence platform for the multihospital collaborative management of congenital cataracts was proposed by our team, providing diagnosis, risk grading, and treatment recommendations for patients with congenital cataract[17].In addition, there have been several researches on cataract diagnosis based on smartphone and slit-lamp images.Askarian et al.[18]achieved satisfactory experiment results based on ocular images captured by smartphones, using a luminance transformation algorithm for feature extraction and support vector machines ( SVM) for cataract identification.Young et al.[19]combined several deep learning algorithms and proposed an automatic grading system of cataract based on slit-lamp and retro-illuminated images, which is effective in recommending appropriate treatments to cataract patients.
Although the aforementioned studies have investigated the automatic screening and grading of cataracts,they didn’t involve the automatic grading of visual impairment for cataract patients.Along with the cataract diagnosis, the accurate grading of visual impairment is an important clinical reference for assessing the severity of cataract and implementing individualized treatment.However, there are many similarities among different visual impairment categories, and their small blood vessels are somewhat different but blurred.This poses a high challenge for the design of high-accuracy diagnosis algorithms based on deep learning.Moreover,the fundus image of cataract used in this study is an imbalanced dataset, the number of MSVICCs is less than the number of normal samples or MVICCs.The imbalanced dataset easily causes classifiers to produce a relatively high false-negative rate and weak generalization ability.
To address these issues, in this study, a MECA_CNN (multi-scale efficient channel attention convolutional neural network) is proposed for the automatic grading of visual impairment in cataract patients.First,the contrast-limited adaptive histogram equalization algorithm is used to enhance the contrast of fundus images for highlighting blurred small blood vessels.Second, the MECA_CNN is employed to extract high-level semantic features to classify visual impairment into three grades: Normal, MVICC, and MMSVICC.In MECA_CNN, an efficient channel attention mechanism is utilized to extract multi-scale features of fundus images and focus on lesion-related regions to the greatest extent.To avoid information loss of fine-grained fundus features during the feature extraction process, the asymmetric convolutional modules are embedded in the residual unit.Moreover, the asymmetric loss function is applied to solve the problem of a higher false-negative rate and weak generalization ability caused by the imbalanced dataset.Third, the generalization ability of MECA_CNN is explored for visual impairment grading based on an external clinical dataset.Using this automatic grading strategy, the severity assessment of the visual impairment could potentially help ophthalmologists to perform an individualized treatment strategy for a cataract patient.
1 Methods
1.1 Overall grading framework of MECA_CNN
The framework of the automatic grading system of visual impairment is shown in Fig.1, consisting of three main parts: pre-processing, feature extraction,and grading result output.In pre-processing, the contrast-limited adaptive histogram equalization algorithm is applied to enhance the contrast of fundus images.The data augmentation techniques, including random cropping, random rotations around the image center,and horizontal and vertical flips, are adopted to enlarge the original training dataset by 6 times, which increases the diversity of the dataset and prevents overfitting and bias problems during training.During the feature extraction process, the shallow network is deepened to improve the feature extraction capability of model, the efficient channel attention mechanism is introduced into the residual module, and the 3 ×3 conventional convolution is replaced with asymmetric convolution to form a MECA_CNN Block.Finally, the softmax classifier with asymmetric loss function is performed to output the grading results.
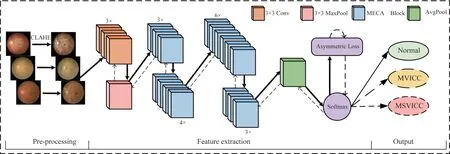
Fig.1 Framework of automatic visual impairment grading in cataract patients using MECA_CNN
1.2 Pre-processing
According to the examination result of visual acuity card, the visual impairment can be classified into three grades: MVICC, MSVICC, and normal sample.For MVICC and MSVICC, the blurred color and texture features are presented in fundus tissues such as blood vessels, optic disc, and macula.To improve these blurred features, the contrast-limited adaptive histogram equalization (CLAHE) algorithm[20]is employed to enhance the contrast of the fundus image in pre-processing stage, thus the features of blood vessels can be easily distinguished from background features,which is beneficial for visual impairment grading.Specifically, the local histogram of fundus image is first calculated, and then its contrast is adjusted by redistributing brightness of image.In addition, the contrast clipping technique is introduced to avoid the amplification noise.Using the CLAHE algorithm, small blood vessels are enhanced to improve the performance of the visual impairment grading.The typical original fundus images and the corresponding pre-processed results using CLAHE are presented in Fig.2.It is not difficult to notice that CLAHE algorithm not only enhances the features of large blood vessels, optic disc, and macular tissue, but more importantly improves the clarity of the blurred small blood vessels.
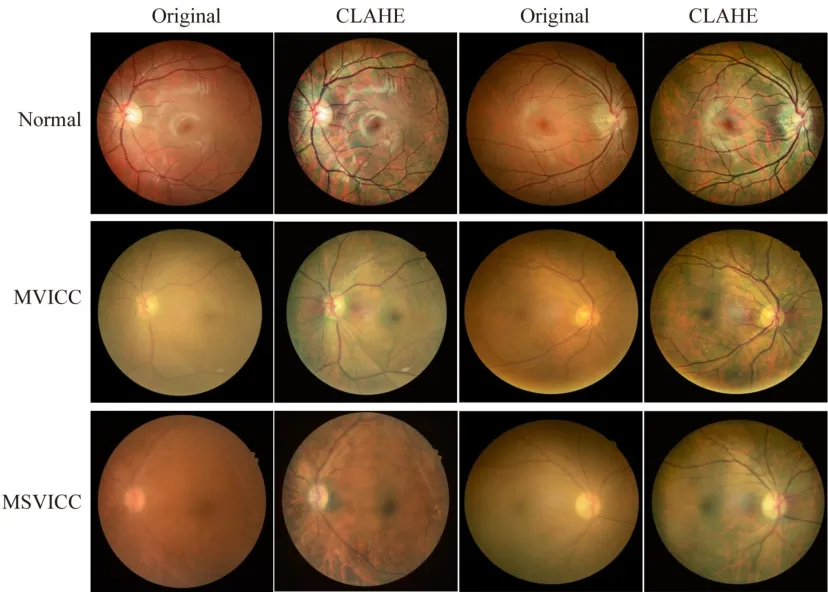
Fig.2 Representative original and enhanced fundus images using CLAHE pre-processing algorithm.
1.3 Improved multi-scale deep residual network
As we all know, three-scale features exist simultaneously on the same fundus image, including largescale features such as optic disc and macula, mesoscale features such as arterial vessels, and smallscale features such as capillaries.To utilize the twoscale features, a multi-scale deep residual network(Res2Net50)[21]was chosen as the backbone network to construct residual - like connections with hierarchy in a single residual block, replacing the 3 ×3 convolution kernel in the residual unit of the traditional Res-Net50[22].Specifically, the features of input image were divided into four subsets:xi(i=1,2,3,4).Each subset contains the features with the same size and a channel number that is 1/4 of the input features.Except forxi, eachxiis processed using a 3 × 3 convolution,denoted asKi().The output ofKi() are denoted byyi.The output ofKi-1() was added to the subsetxi, and then fed intoKi().To reduce the number of parameters and increase the subsets, omitted the 3× 3 convolution forxi.Thus,yican be formalized as Eq.(1).
Due to the combinatorial explosion effect, the output of the Res2Net module contains different combinations of receptive fields.Finally,yiis cascaded and fed into a 1 × 1 convolution to obtain convolutional combinations of Res2Net residual units.By expressing multi-scale features at a fine-grained level, this technique significantly expands the receptive field of the model, thereby enabling the module to effectively extract fine-grained features from fundus images.
Fig.3(a) shows the detailed structure of the MECA_CNN Block, and Fig.3(b) and Fig.3(c) are two sub-blocks of Fig.3(a), which are the asymmetric convolution block and the efficient channel attention block in the MECA_CNN Block.Specifically, to avoid the problem of information loss during fine-grained features extraction process, instead of three 3 × 3 convolution modules, an asymmetric convolution block(ACB)[23]is applied in the Res2Net residual unit.The ACB module enhanced the network’s expression ability to extract high-level features of fundus images through three parallel convolutional kernels of 3 ×3, 1×3,and 3 ×1,as shown in Fig.3(b).After convolution operations, the features were merged and normalized.In addition, the ACB module is beneficial to reduce the number of model’s parameters and improve computational efficiency, which can be applied in the scenario of lightweight model.Furthermore, because of the similarities between MVICC and MSVICC, it is not easy to distinguish them.To address this problem, the first convolutional layer with a 7 ×7 kernel size in the Res2Net50 network was replaced with three convolutional layers with a 3 ×3 kernel size, the fine-grained local features therefore were extracted from fundus images, as shown in Fig.1.The ACB module not only maintains the same receptive field, but also enhances the capability of feature extraction.
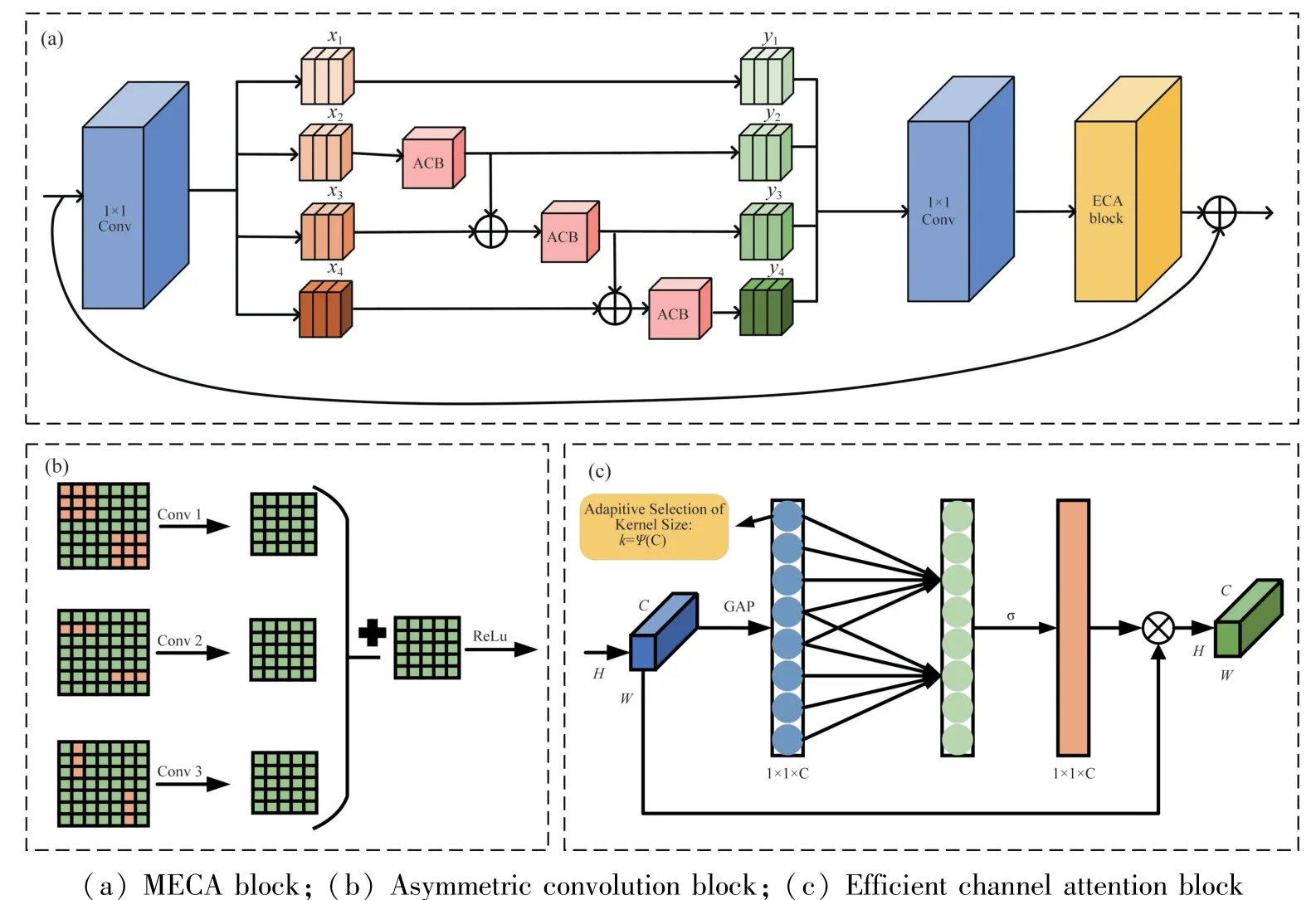
Fig.3 Structure diagram of the multi-scale efficient channel attention block
1.4 Attention mechanism
In recent years, the employment of attention mechanisms has gained widespread usage in the field of computer vision.The squeeze-and-excitation network(SE) is the first channel attention mechanism.Based on the SE,the efficient channel attention (ECA) module[24]is proposed, which removed the FC layer of original SE and introduced an adaptive 1D convolution.As shown in Fig.3(c),HandWdenote the height and width of the input image, respectively,Crepresents the number of channels,krepresents the size of the 1D convolution.The non-linear function ofkis defined as shown in Eq.(2).
where, |t|oddrepresents the nearest odd number oft,and the values ofband γare set to 1 and 2, respectively.Thekvalue is determined using an adaptive method, which is used to reduce computing resources.In this study, after extracting fine-grained features in the Res2Net residual unit, an efficient channel attention module is applied to adjust the MECA_CNN to focus on the lesion characteristics of cataracts.First, on the basis of the output of the previous convolutional layer,the global average pooling operation is carried out for each feature graph channel.Then the local dependence between channels is established using one-dimensional convolution operation.After one-dimensional convolution, the Sigmoid activation function is applied to map the output values to a range of 0 to 1.This allows the output to be interpreted as the attention weight for each channel.Finally, the attention weight is multiplied with the original feature map to achieve channel-level attention weighting.The structure of a multi-scale efficient channel attention (MECA) block is presented in Fig.3(a).Multiple MECA blocks are stacked to form a multi-scale efficient channel attention convolutional neural network, as shown in Fig.1.This design fully considers the lesion feature of the cataracts, enhancing the expression of lesion features while suppressing the expression of noise information, so that the detailed features of blood vessels and optic disc on the fundus image can be learned, which is helpful for the visual impairment grading.
1.5 Asymmetric loss function
The fundus image of cataract used in this study is an imbalanced dataset.In Table 1, the number of normal samples is equal to the number of MVICC samples.However, the number of MSVICCs is less than the number of normal samples or MVICCs.This imbalanced dataset can easily increase the risk of higher false-negative rates and weak generalization problem for classifiers.To solve this problem, the asymmetric loss(ASL_Loss)[25]function is applied in the training process, as shown in Eq.(3).
where,pmdenotes the shifted probability as shown in Eq.(4).L+andL_represent the loss of positive and negative samples, respectively.γ+and γ_are the positive and negative focus parameters, respectively.
By assigning large weight factor to minority category, the ASL_Loss function can focus on the minority category.

Table 1 Distribution of fundus images for visual impairment grading
2 Experiments and results
2.1 Dataset
All fundus images were derived from the routine follow-up consultations for cataract patients between November 2017 and March 2022 at School of Ophthalmology and Optometry and Eye Hospital of Wenzhou Medical University.Each image was described and labeled by two experienced ophthalmologists in a doubleblind fashion according to the examination result of visual acuity card, and a third ophthalmologist was consulted in the case of disagreement.The distribution of fundus dataset is shown in Table 1, including 3058 normal images (Normal),2582 mild to moderate visual impairment caused by cataract images with BCVA greater than or equal to 0.3 (MVICC), and 1358 severe visual impairment caused by cataract images with BCVA less than 0.3 (MSVICC).In this study, the dataset was randomly divided into a training set(Train), a validation set (Val),and a test set (Test)according to the ratio of 70%, 15%, and 15%.The external test set used in this study was obtained from Ningbo Eye Hospital, in which each image was also labeled using the same double-blind annotation method.
2.2 Experimental environment
The MECA_CNN was developed in this study using the PyTorch deep learning framework (Torch 1.7.1, Torchvision 0.8.2) and trained with four NVIDIA TITAN RTX GPUs in parallel.To accelerate parameter convergence, a batch size of 64 was used on each GPU, and the initial learning rate and number of iterations were set to 1e-03 and 80, respectively.The learning rate was then adjusted to 1/10 of the original value at intervals of 20 epochs.During training, the model’s performance was evaluated using the validation set, and the model with the highest accuracy on the validation set was saved as the optimal model.
2.3 Evaluation indicators and statistical analysis
The performance of the MECA_CNN for discriminating Normal, MVICC, and MSVICC is evaluated by calculating the confusion matrix, accuracy, sensitivity,specificity, receiver operating characteristic curve(ROC), and area under the ROC curve (AUC), as shown in Eqs (5) -(7).
In this study, statistical analyses are conducted using Python 3.8.0 and the Scikit-learn package.TP,FP, TN, and FN are used to denote the numbers of true positives, false positives, true negatives, and false negatives, respectively.The Wilson Score Approach is used to calculate the 95% confidence intervals (CI)for accuracy, specificity, and sensitivity, while Empirical Bootstrap with 2000 is used for AUC.
2.4 Performance of the MECA_CNN in the internal and external test datasets
To validate the performance and generalization ability of the MECA_CNN, the model is evaluated based on internal and external test datasets.In the internal test dataset, the MECA_CNN achieves accuracy, sensitivity, and specificity indicators for MVICC(91.3%, 89.9%, and 92%), MSVICC (93.2%,78.5%, and 96.7%), and normal sample (98.1%,98.0%, and 98.1%) as shown in Fig.4(c).The performance of the MECA_CNN on the external test dataset was comparable to that on the internal dataset:MVICC (88.7%, 91.3%, and 87.4%), MSVICC(92.0%,75.8%, and 99.0%), and normal sample(96.0%, 96.3%, and 95.8%) as shown in Fig.4(d).The detailed confusion matrixes are calculated in the internal and external test datasets as shown in Fig.4(a) and (b).
2.5 Exploring the impact of different modules on the performance of the MECA_CNN
To explore the impact of different modules of the MECA_CNN on the overall performance, a set of ablation experiments are conducted under the condition that the same basic network Res2Net50 is included.By sequentially adding different modules to the basic network, five groups of ablation experiments are constructed and their differences are compared.Specifically,Model_1 represents the basic network Res2Net50;Model_2 represents the model with the first 7 ×7 convolutional layer replaced by three 3 × 3 convolutional layers; Model_3 represents the model with the 3 ×3 convolutional layer replaced by an asymmetric convolution in the residual unit; Model_4 represents the model with the ECA module adopted; Model_5 represents the model with the ASL_Loss function used; MECA_CNN represents the model that included the four improvements mentioned above.The results of the ablation experiments are shown in Table 2.Ablation experiments demonstrate that the proposed MECA_CNN outperformes the other five models.It is worth noting that the MECA_CNN is specifically suitable for the task of visual impairment grading.All of the above improvements and ablation experiments are performed based on the same dataset of fundus images.
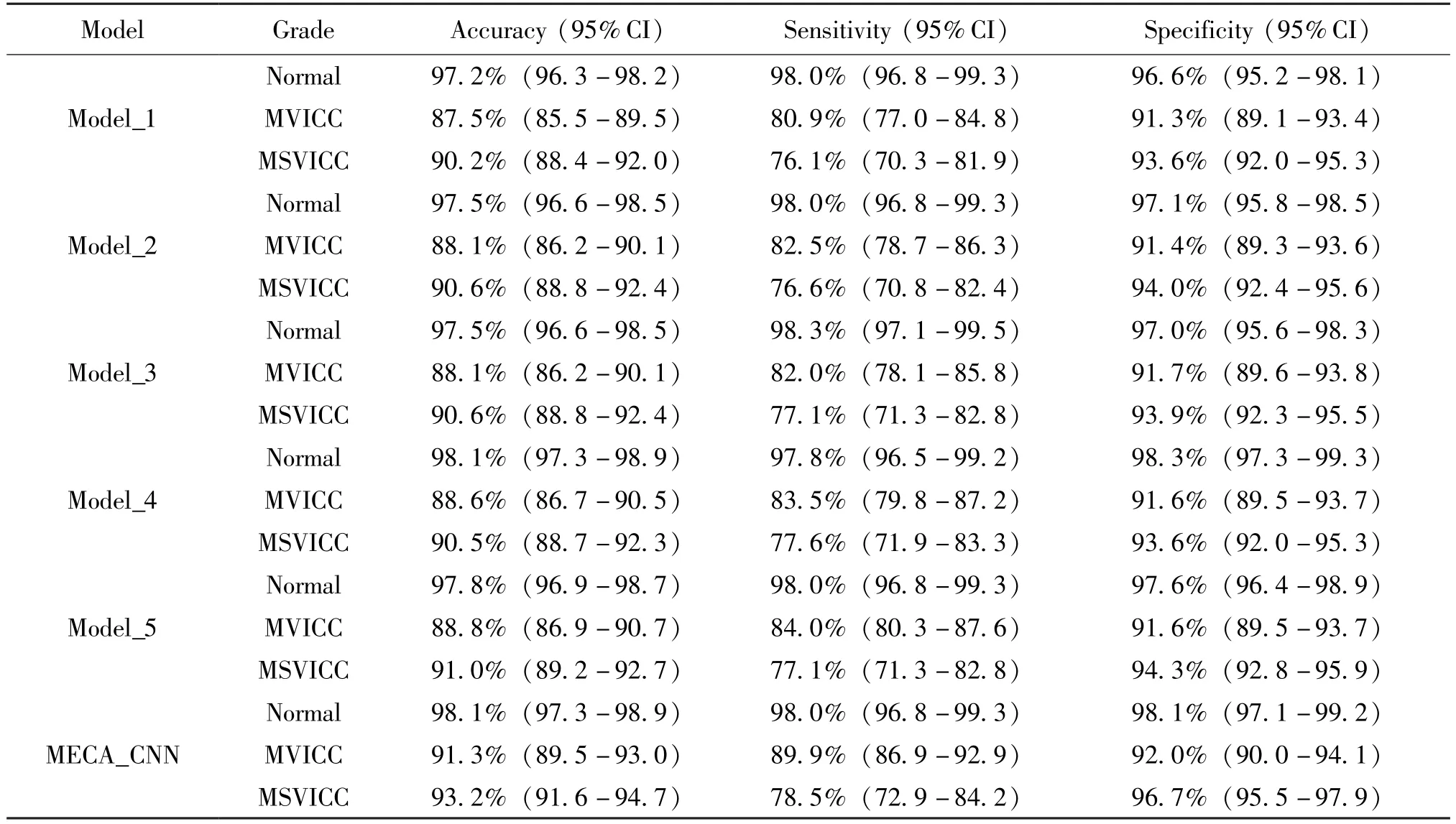
Table 2 Performance comparison of the MECA_CNN and its ablation experiments
2.6 Performance comparison of the MECA_CNN and conventional CNNs
To further examine the performance of MECA_CNN model for visual impairment grading, three conventional CNNs are selected for comparison in this study, including a deep residual network (ResNet50),a multiscale deep residual network (Res2Net50), and a dense convolutional network (DenseNet121).All models are trained and tested based on the same dataset of fundus images.The detailed experimental results are compared in Table 3.
As shown in Table 3, statistical results show that the average accuracy of the MECA_CNN model on the three grades of visual impairment is 94.2%, which exceeds three conventional CNNs by 2.9%,3.8%, and 2.6%, respectively.The average sensitivity of the MECA_CNN model is 88.8%, which is higher than three conventional CNNs by 4.3%, 5.1%, and 3.9%, respectively.The average specificity of the MECA_CNN model is 95.6%, which is higher than three conventional CNNs by 2.0%, 2.4%, and 1.8%, respectively.
The t-SNE method is further used to analyze the discriminative ability of the extracted high-level features.The high-level features obtained from the MECA_CNN and conventional CNNs were mapped into a twodimensional space in the internal test dataset to visually show their ability to distinguish between different classes.As shown in Fig.5, the circular points represent normal samples, the square points represent MVICC patients, and the triangular points represent MSVICC patients.Notably, the discrimination ability of conventional CNNs was obviously inferior to that of the MECA_CNN.The t-SNE technique showed that the MECA_CNN had a better capability in high-level features separability for visual impairment grading.
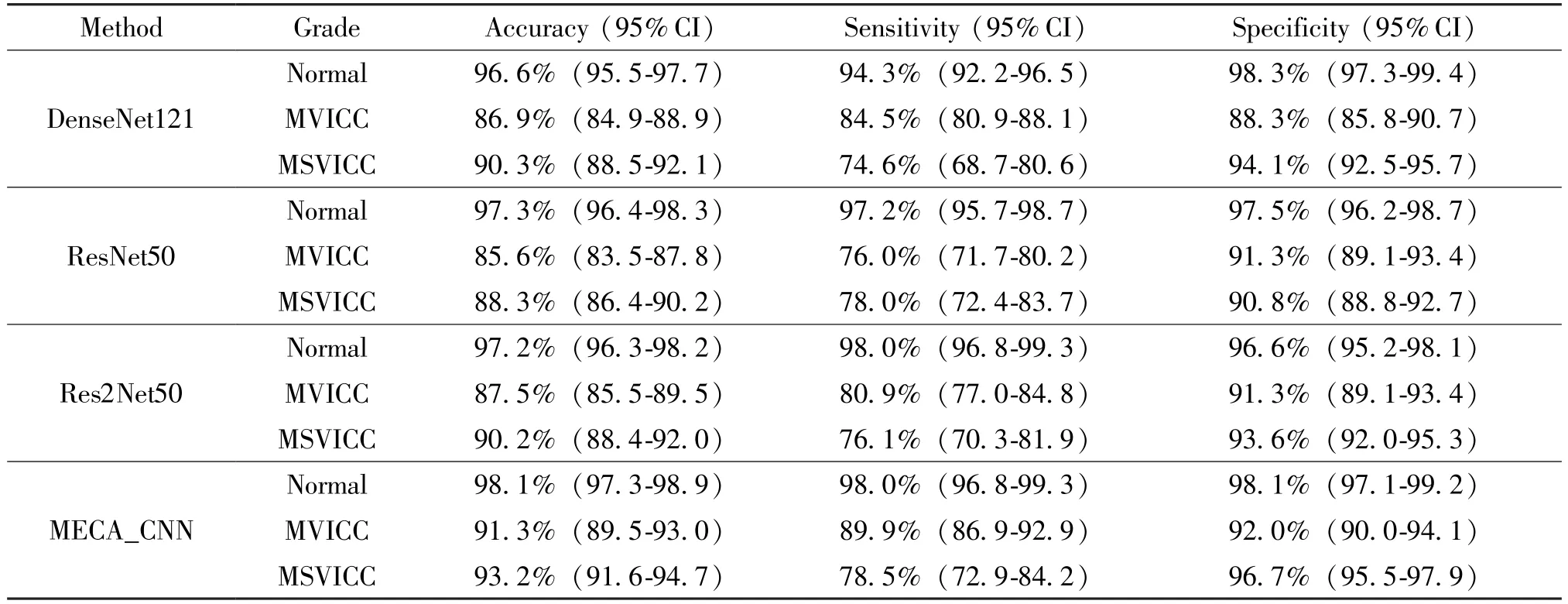
Table 3 Performance comparison of the MECA_CNN and conventional CNNs for visual impairment grading in the internal test dataset

Fig.5 Visualization of the separability for the high-level features extracted by the MECA_CNN and three conventional CNNs in the internal test dataset using t-SNE
The ROC curve is a comprehensive evaluation metric for classification models.The upper-left corner of the ROC curve indicates a superior classifier.As shown in Fig.6, the ROC curves and AUC value of the MECA_CNN and three conventional CNNs on the internal test dataset are compared.The experimental results indicate that the performance of MECA_CNN is superior to those of three conventional CNNs.Specifically, compared with the DenseNet121, the AUC values of the MECA_CNN on the three grades of visual impairment are improved by 0.2%, 3.7%, and 2.1%,respectively.Compared with the ResNet50, the AUC values of the MECA_CNN on three grades of visual impairment are improved by 0.4%, 2.4%, and 1.9%,respectively.Compared with the Res2Net50, the AUC values of the MECA_CNN on the three grades of visual impairment are improved by 0.2%, 2.9%, and 2.8%, respectively.

Fig.6 ROC curves and AUC of MECA_CNN and conventional CNNs in the internal test dataset
2.7 Visualization heatmaps of visual impairment grading
To explore the reasonability of the MECA_CNN model, the gradient-weighted class activation mapping(Grad-CAM) method was use to generate visualization heatmaps, which highlighted the cataract-related regions that the MECA_CNN model focused on the most.The Grad-CAM is an explainable technique for MECA_CNN, which leverages the gradients of any target concepts flowing into the last layer of the MECA_CNN to generate a localization map highlighting remarkable regions in the image for predicting the concept.The regions that appear redder on the visualization heatmaps represent the areas on which the MECA_CNN model has focused the most, indicating their significance as cataract-related features.
For normal fundus images, there are more redder regions highlighting areas in the heatmap due to the large number of clear vessels.For fundus images of the MVICC and MSVICC, there are fewer redder regions highlighting areas in the heatmap due to the deeper turbidity of the vessels around the optic disc.It is easy to conclude that the visualization heatmaps are consistent with the quantitative experiment results of the MECA_CNN model.The representative heatmaps examples of the MVICC, MSVICC, and normal sample are displayed in Fig.7.Using the Grad-CAM, which illustrates the reasonable of the MECA_CNN for discriminating MVICC, MSVICC, and normal sample.
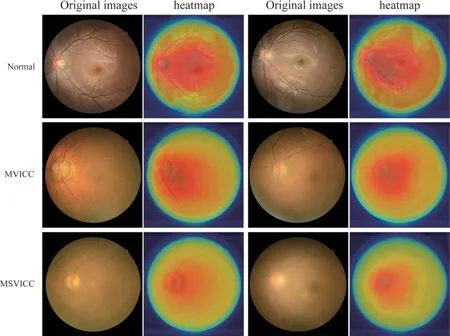
Fig.7 Representative heatmaps for visual impairment grading of cataracts
3 Discussion
In this study, an automatic assessment model MECA_CNN is developed for visual impairment grading in cataract patients.In the MECA_CNN network,an efficient channel attention mechanism and asymmetric convolutional module are explored to extract multiscale features focusing on small blood vessels, optic disc, and macula, etc.Detailed comparative experiments demonstrate that the MECA_CNN proposed in this study could effectively discriminate MVICC and MSVICC from normal sample.The performance of the MECA_CNN outperforms other conventional CNNs on the internal and external test datasets, which verifies its effectiveness and generalization ability.Moreover,the Grad-CAM technique provides an interpretable path for the visual impairment grading of cataract.
Due to the reliable performance, the MECA_CNN can be applied as a remote medical screening tool for early detection of cataract patients with abnormal visual acuity.For underdeveloped areas and remote mountain villages, limited ophthalmologists and medical resources are unable to assess the visual impairment for cataract patients in a timely manner, making it impossible for patients to receive appropriate treatment.In addition, less-educated residents tended to neglect eye health, and they sought medical attention only when cataracts seriously affected visual acuity.However, at this time, visual impairment is often severe and might be accompanied by some complications.Only surgical treatment could be implemented, and postoperative recovery is not ideal.Therefore, based on fundus images and corresponding annotations by senior ophthalmologists, the trained MECA_CNN model can be deployed in the clinic to assist doctors to automatically grade visual impairment in cataract patients, which can provide the patients with an appropriate treatment protocol.
The performance of the MECA_CNN is superior to those of other conventional CNNs.First, the CLAHE algorithm is employed to enhance the quality of fundus images for discerning blurred and small blood vessels from background noises.Second, an efficient channel attention mechanism is performed to enable the MECA_CNN to extract fine-grained features, which is beneficial to improve the recognition rate of the MVICC from MSVICC.Conventional CNNs ignored the fine-grained features and thus potentially led to biased prediction results.Third, to fully consider the problem of imbalanced dataset in clinical practice, the ASL_Loss function is adopted to facilitate the MECA_CNN to focus more on the minority category of MSVICC.In addition,the transfer learning, asymmetric convolution, and multi-scale residual module are adopted to extract multi-scale features for enhancing the performance of MECA_CNN.Compared with the Res2Net50, the accuracy, sensitivity, and specificity of MECA_CNN for MVICC are improved by 3.8%, 9.2%, and 0.6%,respectively.Similar improvements are presented on the grading of MSVICC and normal samples.
To illustrate the interpretability of the MECA_CNN, the Grad-CAM technique is applied to generate heatmaps for visualizing the regions that the MECA_CNN pays most attention to the final grading.Six typical fundus images are presented to show the visualization results.For normal fundus images, there are more redder regions highlighting optic disc, macula, and blood vessels in the heatmap.For the MVICC and MSVICC images, only the optic disc and its surrounding blurred blood vessels are highlighted.This interpretability exploration further facilitates the MECA_CNN to be applied in real-world clinics, so that ophthalmologists and patients can easily capture the reasons for the final grading results inferred by the MECA_CNN.
This work has several limitations.First, although the MECA_CNN method provides a practical strategy for visual impairment grading,the sensitivity of MVICC and MSVICC is still slightly low,which may be attributed to the more similarity of the phenotypes between these two categories.The next step is to analyze the characteristics of fundus images and explore finegrained feature extraction and classification algorithms.Second, this study only explores the automatic grading of visual impairment based on fundus images, however, epidemiological datasets, including age, medical history, and other underlying diseases, are still underinvestigated.Combining the electronic medical records and other optical images, multimodal fusion algorithms will be explored to provide valuable supplements for the comprehensive assessment of visual impairment.In addition, due to the limited external test data, the generalization of the MECA_CNN has not been fully verified.As more and more fundus images of cataract and corresponding BCVA are collected and annotated, the generalization of MECA_CNN will be further verified to ensure that the deployed model can be effectively applied in real clinical practice.
4 Conclusions
In this study, a feasible MECA_CNN method is proposed for the automated grading of visual impairment using an efficient channel attention mechanism and multi-scale deep residual network.The MECA_CNN model exhibits excellent performance in identifying MVICC and MSVICC from normal sample in both internal and external test datasets.The experimental results verifies that the proposed method is superior to other conventional methods.The ablation experiments demonstrate that the combination of several improved modules in the MECA_CNN is beneficial to exert its optimal performance.Interpretability analysis and external test dataset validation indicate that the MECA_CNN method has better rationality and generalization ability in clinical applications.This study may also provide a valuable reference for the automated analysis of visual impairment in other eye diseases.
杂志排行

High Technology Letters的其它文章
- Design and implementation of control system for superconducting RSFQ circuit①
- A novel adaptive temporal-spatial information fusion model based on Dempster-Shafer evidence theory①
- A dynamic fusion path planning algorithm for mobile robots incorporating improved IB-RRT∗and deep reinforcement learning①
- Research on dual-command operation path optimization based on Flying-V warehouse layout①
- Two stream skeleton behavior recognition algorithm based on Motif-GCN①
- A fault recognition method based on clustering linear regression①