基于深度学习的人体动作识别算法*
2023-12-13周鹏飞汤健华
江 励,周鹏飞,汤健华
(五邑大学智能制造学部,广东 江门 529020)
0 引言
近年来,基于3D 卷积神经网络(Convolutional Neural Network,CNN)的人体动作识别算法受到了广泛关注。其中,双流网络(Two-Stream Network)[1]是一种广泛使用的方法,它分别对RGB 图像和光流图像进行处理,并将二者的特征融合起来,获得了较高地识别精度。C3D[2]和I3D[3]则是专门针对视频数据进行处理的网络模型,通过时间维度的卷积操作,有效地利用了视频序列中的时序信息。尽管这些基于3D卷积神经网络的人体动作识别算法在识别准确率方面取得了显著的进展,但仍然存在一些问题。首先,这些算法需要大量的训练数据和计算资源,训练时间长、计算复杂度高,不适用于实时应用场景。其次,这些算法在面对复杂场景、复杂动作时,往往识别效果较差。
为了解决这些问题,本文提出了一种新的基于高精度Transformer[4]风格骨干网络的人体动作识别算法,该算法采用时序移位模块[5]和轻量级注意力机制来提取动作时序信息和增强动作特征,实现更好的识别效果。具体来说,本文采用骨干网络CoTNeXt[6]对上下文信息进行挖掘并进行自注意力学习,从而有效地增强动作特征;时序移位模块则可以充分提取动作时序信息,进一步提高识别准确率;融合注意力机制则可以通过增加正则化项来进一步抑制不显著的特征,突出显著动作特征。在Jester 和Kinetics-400 数据集上的实验结果表明,本文提出的算法在识别准确率和识别速度方面均优于现有的大多数基于3D卷积神经网络的人体动作识别算法。
1 网络结构
1.1 CoTNeXt骨干网络
当前,基于深度学习的人体动作识别算法在机器人交互中得到了广泛应用。其中,基于3D卷积神经网络的算法受到了广泛的关注。然而,这些算法在实时性、训练时间和计算复杂度等方面还存在一些问题。为了克服这些问题,本研究提出了一种新的人体动作识别算法,该算法采用高精度的CoTNeXt骨干网络作为特征提取器。CoTNeXt 骨干网络可以通过挖掘上下文信息来增强动作特征,并通过自注意力机制来学习自身特征,从而有效地提高识别准确率。
CoTNeXt-50 是通过将ResNeXt-50[7]的组卷积中所有3×3 卷积核替换为CoT 块来构建的。与典型的卷积相比,当组数C增加时,组卷积核的深度明显减小。因此,在ResNeXt-50 中,组卷积的计算量减少了C倍。 为了实现与ResNeXt-50 相似的参数数量和FLOPs,本文还将CoTNeXt-50的输入特征映射的尺度从32×4d减少到2×48d。最后,CoTNeXt-50 只需要比ResNeXt-50 多1.2 倍的参数和1.01 倍的FLOPs。CoTNeXt-50 的网络结构如图1 所示。
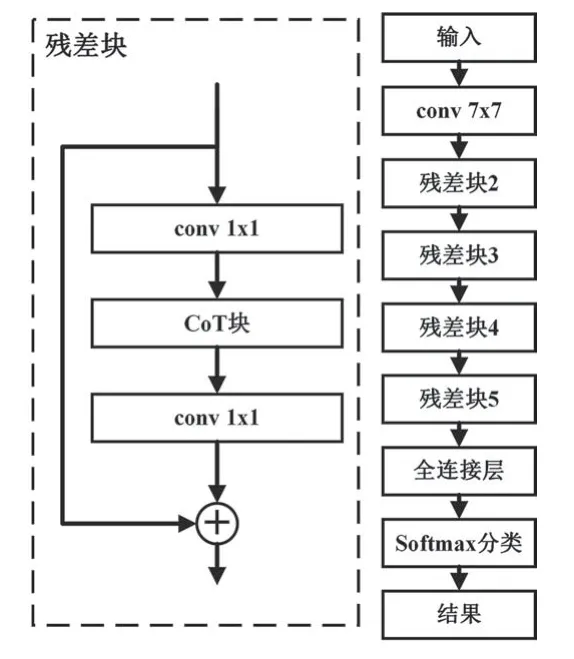
图1 CoTNeXt-50网络结构
CoT 块的结构由一个3×3 卷积层,一个自注意力层和一个线性融合层组成。3×3 卷积层用于挖掘静态上下文,自注意力层用于获取动态上下文,而线性融合层则用于动态地融合静态和动态上下文。具体来说,3×3 卷积层会对输入的键进行上下文编码,从而得到静态上下文表示,即捕获输入键之间的关系;自注意力层则会将查询和上下文编码的键进行拼接,从而学习动态多头注意力矩阵,即捕获查询和上下文化键之间的关系;最后,线性融合层会将静态和动态上下文表示进行融合,从而得到最终的输出。CoT的网络结构如图2所示。
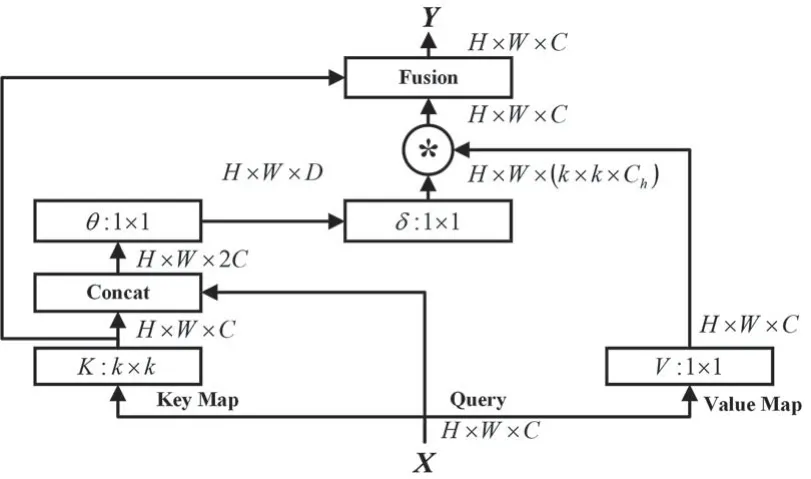
图2 CoT的网络结构
对于输入2D 特征图X,CoT 块首先对k×k网格内的所有相邻键进行k×k组卷积,以在空间上对每个相邻键表示进行上下文化,而不是像典型的自注意力那样通过1×1 卷积对每个键进行编码。学习到的上下文键K1自然地反映了局部相邻键之间的静态上下文信息,本文将K1作为输入X的静态上下文表示。之后,在上下文键K1和查询Q拼接的条件下,通过两个连续的1×1 卷积实现注意力矩阵:
式中:T为注意力矩阵;K1为输入特征图X的静态上下文信息;Q为查询(query);Wθ为具有ReLU 激活函数的1×1卷积;Wδ为不具有激活函数的1×1卷积。
对于每个头部,每个空间位置的局部注意矩阵是基于查询特征和上下文键特征学习来的,可以通过挖掘的静态上下文K1来增强自注意力学习能力。接下来,根据上下文注意力矩阵T,本文像典型的自注意力一样通过聚合所有值V来计算出关注的特征图K2。具体来说,对于输入2D 特征图X,将值(value)定义为V=XWν,Wν为值(value)的权重矩阵,然后将上下文注意力矩阵T与值V点相乘得到特征图X的动态上下文信息K2,计算公式如下:
式中:K2为输入特征图X的动态上下文信息;T为注意力矩阵;V为值(value)。
最后,本文将静态上下文信息K1和动态上下文信息K2通过SKNet 中的注意力机制融合,得到CoT 模块的输出Y。
总而言之,CoTNeXt 结合了Transformer 和CNN 两种模型的优点,既能捕捉全局依赖关系,又能保留局部细节信息。这是由于CoTNeXt 骨干网络由多个注意力模块组成,每个注意力模块由一个局部注意力模块和一个全局注意力模块组成。局部注意力模块用于捕捉特征之间的局部关系,而全局注意力模块用于捕捉特征之间的全局关系。通过对特征进行逐层加权,CoTNeXt 骨干网络可以更好地捕捉输入数据中的信息,利用相邻键之间的上下文信息来增强自注意力机制,提高特征的表达能力。同时,CoTNeXt 又具有较低的计算复杂度和内存消耗,在保证高精度的同时也具有较高效率。因此,在人体动作识别任务中,CoTNeXt 骨干网络可以用于提取动作特征,进而实现准确的动作识别。具体而言,CoTNeXt 骨干网络通过对上下文信息的挖掘,可以更好地识别不同动作中的关键特征,从而提高识别准确率和鲁棒性,并在人体动作识别中取得了优异的表现。
1.2 时序移位模块
随着人体动作识别的研究不断深入,越来越多的工作开始关注动作的时序信息。传统的人体动作识别方法往往只利用单帧图像或视频进行分析,难以充分利用动作中包含的时间序列信息。而时序移位模块(Temporal Shift Module,TSM)作为一种有效的时序建模方式,可以有效地利用时序信息,进一步提高动作识别的性能。
为了进一步提高CoTNeXt 骨干网络在人体动作识别任务上的性能,本文将时序移位模块(TSM)融入到了网络中。时序移位模块是一种能够有效提高视频分类和动作识别性能的模块,其可以学习到视频中时间维度的关系,从而提高模型的鲁棒性和泛化能力。本文将时序移位模块融入CoTNeXt 骨干网络中,以进一步提高人体动作识别的性能。
时序移位模块的主要思想是通过对输入的特征图进行时间维度的移位操作,将相邻的时序特征进行混合。具体来说,时序移位模块将输入的特征图沿着时间轴进行划分,并对每个时间段的特征图进行移位操作,然后将移位后的特征图按照时间轴重新组合,生成一个新的特征图。时序移位模块沿时间维度移位,如图3所示。

图3 时序移位模块沿时间维度移位示意图
在CoTNeXt 骨干网络中,本文将时序移位模块放置在每个residual模块的第一层卷积之前。具体地说,先将residual模块的输入特征图按照时间维度分割成不同的子序列,然后对每个子序列进行移位操作,从而达到时序变换的效果,最后再将输出的特征图输入residual 模块的第一层卷积。时序移位模块可以用简单的卷积操作实现,同时具有较少的额外参数,可以很方便地集成到现有的卷积神经网络中。CoTNeXt-50融合时序移位模块的具体网络结构如图4所示。

图4 TSM-CoTNeXt网络结构图
通过将时序移位模块融入到CoTNeXt 骨干网络中,可以更好地利用时间维度的信息,从而提高模型在人体动作识别任务上的性能。在实验中,使用时序移位模块后,模型的性能得到了明显的提高。同时,时序移位模块的使用也使得模型在时间维度上更加鲁棒,能够更好地处理动作的时序信息,从而进一步提高模型的泛化能力。
总之,将时序移位模块融入到CoTNeXt骨干网络中,可以进一步提高模型在人体动作识别任务上的性能。通过实验,证明了该模块的有效性,并且得到了更好的实验结果。
1.3 轻量级注意力机制
为了提高CoTNeXt 骨干网络的性能,本文在模型中融入了Normalization-based Attention Module (NAM)[8]。NAM 的加入旨在增强网络对动作序列中关键帧的关注度,从而提高动作识别的准确率。
NAM 是一种有效的轻量级注意力机制,旨在通过利用训练模型权重的变化来突出显着特征。它由通道注意力模块和空间注意力模块两个子模块组成。通道注意力模块使用批量归一化(BN)[9]的缩放因子来衡量通道的方差,从而表明它们的重要性。具体来说,它使用BN的缩放因子来计算每个通道的注意力,并将其乘以输入特征图,以便突出显着特征。空间注意力模块使用缩放因子来衡量像素的重要性。具体来说,空间注意力子模块使用卷积层和MLP(多层感知器)来计算每个像素的注意力,并将其乘以输入特征图,以便突出显着特征。NAM 将这两个子模块结合起来,以提高深度神经网络的性能。此外,为了有效抑制较不显著的权重,NAM 在损失函数中添加了正则化项,从而提高模型的准确性。NAM 的结构简单,但具有高效的性能。它的结构可以被称为“结构化的注意力”,因为它将通道注意力和空间注意力结合在一起,以提高深度神经网络的性能。
在CoTNeXt 骨干网络中,本文将NAM 嵌入在残差结构的末尾。在通道注意力子模块中,使用来自批量归一化(BN)的缩放因子,如式(3)所示。缩放因子测量通道的方差,表明它们的重要性。
式中:μB为小批量(mini batch)B的平均值;σB为小批量(mini batch)B的标准差;γ和β均为可训练的仿射变换参数。
通道注意力模块如图5所示。图中,F1为输入特征,γ为每个通道的比例因子,Mc为输出特征,权值为ωγ=。

图5 通道注意力模块
通道注意力模块公式如式(4)所示。
在空间注意力子模块中,将BN 的缩放因子应用于空间维度来衡量像素的重要性,这操作称为像素归一化(pixel normalization)。
空间注意力模块如图6所示。图中,F2为输入特征,λ为每个通道的比例因子,Ms为输出特征,权值为ωλ=。

图6 空间注意力模块
空间注意力模块公式如式(5)所示。
最后,为了有效抑制较不显著的权重,NAM 在损失函数中添加了正则化项,如式(6)所示。
式中:x为输入;y为输出;W为网络权重;l( · )为损失函数;g( · )表为L1 范数惩罚函数;p为惩罚因子,平衡g(γ)和g(λ)的惩罚。
总之,NAM 模块是一种有效的轻量级注意力机制,可以有效地减少参数数量,从而提高模型的效率,并且可以更好地捕捉特征图的空间关系,从而更好地突出显着特征。通过将NAM 模块融入CoTNeXt 骨干网络中,我们可以进一步增强网络对不同层特征的利用能力,从而提高动作识别任务的性能。
2 实验结果分析
2.1 数据集
为了验证本文模型的性能和泛化能力,本文在公共数据集Jester和Kinetics-400上对本文模型进行评估。
Jester 数据集是由20bn 公司提供的一个大规模视频数据集,它包含了148 092 个带有密集标签的视频剪辑,这些视频剪辑显示了人类在笔记本电脑摄像头或网络摄像头前执行预先定义的27 种手势。这些手势包括向下滑动两根手指、向左或向右滑动以及敲击手指等。该数据集分为训练集、验证集和测试集,其中训练集有118 562个视频剪辑,验证集有14 787 个视频剪辑,测试集有14 743个视频剪辑。Jester数据集的部分动作视频的采样帧如图7所示。

图7 Jester的部分动作视频采样帧
Kinetics-400 数据集是由DeepMind 和Google Research 团队于2017年发布的一个大规模的视频动作识别数据集,旨在推动视频理解领域的研究进展。该数据集包含400个人类动作类别,每个类别至少有400个视频剪辑,共计约30 万个视频。每个视频剪辑持续大约10 s,并且取自YouTube 视频。这些动作以人类为中心,涵盖广泛的类别,包括演奏乐器、运动、日常活动等。Kinetics-400数据集的部分动作视频的采样帧如图8所示。
图8 Kinetics-400的部分动作视频采样帧
2.2 实验设置
本文实验是在Linux 系统搭建的Pytorch 深度学习框架下,使用4 张Tesla V100-PCIE-32GB 显卡完成的。优化器采用随机梯度下降(SGD)算法来学习网络参数,使用Nesterov 动量,动量参数设置为0.9。对于公共数据集Jester 和Kinetics-400,SGD 优化器权重衰减分别设置为0.000 5 和0.000 1。其中,批量大小(batch-size)设置为8,Dropout 设置为0.5。通过ImageNet 上的预训练模型初始化网络权重,整个训练次数epoch设置为50。在实验中,初始化学习率lr设置为0.005,每经过20个epoch,学习率下降为到原来的1/10,经过50个epoch后完成全部训练。
2.3 Jester测试结果分析
对本文提出的人体动作识别网络进行评估,图9 是本文的人体动作识别网络在Jester 数据集上训练过程中准确率和训练损失Loss曲线图。

图9 准确率和训练损失曲线
本次训练总共有50 个epoch,对每一个epoch 得到的模型,在Jester 数据集的验证集上进行评估,得到模型Top-1 和Top-5 准确率的曲线图。Top-1 和Top-5 准确率的曲线图如图10所示。

图10 Top-1和Top-5准确率的曲线
由图10 可知,本文模型在经过第48 个epoch 时,准确率达到了最高值,Top-1 识别精度为0.974 2,Top-5 识别精度为0.998 5。本文模型fps 为7.6 video/s,具有良好的实时性。实验结果表明,CoTNeXt 骨干网络、NAM 模块和TSM 模块的组合形成了一个强大的动作识别网络,在Jester数据集上取得了优异的性能。
本文的模型算法与其他主流动作识别模型算法在Jester 数据集进行比较,结果如表1。从表中可以清晰得知,本文提出的人体动作识别算法优于其他主流算法,识别准确率更高。

表1 不同模型识别准确率对比(Jester数据集)
2.4 Kinetics-400测试结果分析
在Kinetics-400 数据集上,对本文提出的人体动作识别网络进行评估,本文的人体动作识别模型在Kinetics-400数据集上训练过程中准确率和训练损失曲线如图11所示。

图11 准确率和训练损失曲线
在CoTNeXt-50 与时序移位模块组合形成的新骨干网络中,对于融合NAM注意力模块对最终识别准确率的影响进行对比。融合NAM 注意力模块的对比图如图12 所示。由图可知,融合NAM 注意力模块的网络模型,相比只有CoTNeXt-50 与时序移位模块组合成的新骨干网络,识别准确率由75.58%提升至75.94%,这表明NAM 模块能够有效地加强人体动作识别模型对于重要特征的关注,提高模型的识别精度和鲁棒性。
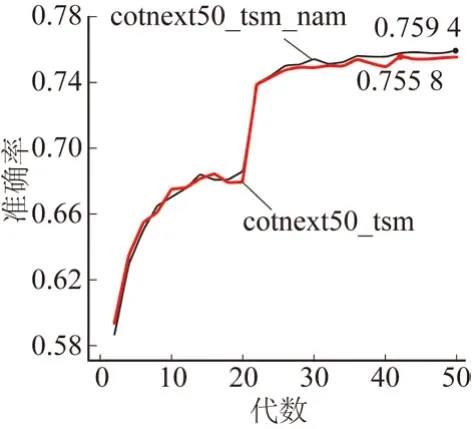
图12 融合NAM注意力模块的对比图
本文的模型算法与其他先进的动作识别模型算法在Kinetics-400 数据集上进行比较,如表2 所示。从表2 中可知,本文提出的人体动作识别算法具有较高的识别准确率,优于其他先进算法。

表2 不同模型识别准确率对比(Kinetics 数据集)
3 结束语
本文提出了一种新的人体动作识别算法,首先通过骨干网络CoTNeXt 对上下文信息进行挖掘并进行自注意力学习,从而有效地增强动作特征,更好地识别不同动作中的关键特征,提高人体动作识别算法的识别准确率和鲁棒性;然后,利用时序移位模块对动作时序信息建模,可以充分提取动作时序信息,进一步提高动作识别的性能;最后,融合轻量级的NAM 注意力机制,可以通过增加正则化项来进一步抑制不显著的特征,从而突出显著动作特征,进一步提升人体动作识别算法的性能。实验结果表明,在ImageNet 预训练模式下,本算法在Jester 数据集和Kinetics-400 数据集上分别取得了97.42%和75.94%的识别准确率,性能优于现有大多基于3D 卷积神经网络的人体动作识别模型。本算法有很好的实时性,在未来的工作中,将结合机器人,实时识别人体动作,将相应的动作语义反馈到机器人,实现更加友好的实时人机交互。
