融合位置特征注意力与关系增强机制的远程监督关系抽取
2023-12-13郑志蕴徐亚媚张行进
郑志蕴,徐亚媚,李 伦,张行进,李 钝
(郑州大学 计算机与人工智能研究院,郑州 450001)
1 引 言
关系抽取是自然语言处理和知识图构建的一项重要任务,又叫做实体关系抽取,旨在从非结构化文本数据中识别出给定实体之间的关系类型[1],并抽取文本中的(实体e1,关系r,实体e2)结构化三元组信息.关系抽取主要应用在文本摘要[2]、问答[3]、知识库构建[4]、网络搜索[5]等领域.
有监督的方法在关系抽取任务中已取得显著的成果[6],但是该方法需要手动标记大量数据来训练模型,不仅耗费时间,而且成本也很高,在大规模的关系抽取任务中具有限制性.远程监督方法的出现缓解了上述问题[7],该方法通过将文本语料库与巨型知识图谱对齐,自动生成大规模带标注的数据集.该方法基于如下假设:如果两个实体e1和e2在一个已知的知识库中存在某个关系R,那么所有提到这两个实体的句子都会以某种方式表达这种关系R.例如,已知在知识库中存在三元组关系实例(new_york,contains,chenango),则包含这两个实体new_york和chenango的所有句子都会被标注为contains关系.在句子“presidentbushyesterdaydeclaredadisasterineightupstatenew_yorkcountieshithardbytheflooding:broome,chenango,delaware,herkimer,montgomery,otsego,sullivanandulstercounties.”中,包含上述两个实体,所以会被标记为contains关系.但是,并非所有提到new_york和chenango的句子都会表达contains关系.显然,由于远程监督的假设过于绝对,大量的训练数据被错误的标记.
因此,许多研究人员利用基于at-least-one假设的多实例学习(Multi-Instance Learning,MIL)[8]来缓解噪声问题.该假设规定:若两个实体之间存在关系r,则句子包中至少会有一个句子能够表达出关系r.MIL是进行句子包级的训练和测试,其中句子包是具有相同三元组的句子的集合.后续很多研究者都是在MIL的基础上进行关系抽取的改进,这些方法通常分两类[9]:一类是强策略方法,直接将嘈杂的句子从句子包中分离出来.另一种是软策略方法,试图对句子施加不同的权重,以减少有噪声的句子的影响.
然而,这些方法忽略关系之间存在的相关性,例如,在表1中,句子实例S2的实体SteveJobs可以是实体Apple的创建者(founder)和主要股东(major_shareholders),这些关系的目标实体词是相同的,出现重叠关系,增强这些关系之间的语义关联有利于提高关系抽取的效率.同时,大量研究人员使用混合神经网络在句子层面捕捉特征,并使用位置特征(Position Feature,PF)[10]来获取单词的位置信息.但是,该方法只记录当前单词与句子中目标实体之间的距离,没有考虑距离关系的重要性,导致句子信息的缺乏,影响关系提取的准确性.

表1 表达多个关系的实体对Table 1 Entity pairs that express multiple relation
为解决上述问题,本文提出融合位置特征注意力和关系增强机制的远程监督关系抽取模型(Distantly Supervised Relation Extraction with Position Feature Attention and Relation Enhancement,PARE).在单词层面,提出基于高斯分布的位置特征注意力机制,通过高斯分布函数对非实体词和实体词之间的位置关系进行建模,来为句子中的单词分配权重;在句子层面,本文使用分段卷积神经网络捕捉句子的局部特征,使用词级注意力捕捉重要词的特征;在关系层面,为充分捕获重叠关系之间丰富的语义相关性,提出关系增强机制来处理关系向量,对可能的关系进行编码,同时保留目标关系表示,以帮助识别实体对.
本文的主要贡献总结如下:
1)为充分利用词间的位置关系信息,捕获句子特征,本文提出一种以高斯分布为基础的位置特征注意力机制,对非实体词和实体词之间的位置关系进行建模,为句子中的单词分配权重.同时使用分段卷积神经网络和词级注意力捕获句子的多维度信息.
2)为得到重叠实体关系之间的语义关联,本文提出以多头自注意力为基础的关系增强机制,重新编码关系向量.
3)本文在NYT10公开数据集上进行实验,结果表明,与基线模型相比,模型PARE具有更好的性能和更高的准确率.
2 相关工作
在关系抽取中,大量的结构化数据源缺乏显式标注的文本,比如Freebase等大型公共知识库.远程监督关系抽取方法为充分利用知识库和非结构化文本提供一种有效的解决方案,启发式地将给定的知识库与文本对齐,利用自动生成的带标注的数据来完成关系抽取.
由于不依赖带标注的文本,远程监督关系抽取方法受到广泛的关注,研究者们提出各种类型的模型.Mintz等[7]聚合一个包中所有实例的特征,并将其送入分类器进行模型训练,但该方法导致错误标注问题.Riedel等人[8]提出at-least-one假设来缓解远程监督的强假设.Hoffmann等人[11]引入概率的、图形化的模型来选择句子,并允许重叠关系.
深度神经网络可以自动学习低维文本特征,在关系抽取中得到普遍应用.Zeng等人[12]使用分段卷积神经网络(Piecewise Convolutional Neural Networks,PCNN)自动学习文本特征,并使用MIL方法进行实例的选择.Lin等人[13]使用PCNN学习句子的局部特征,并使用句子级注意力机制减少噪声句子对选择有效实例的影响.Feng等人[14]改进句子级注意机制,根据句子向量的相关性对句子向量进行排序和组合,选择无噪声句子作为包向量,来完全消除有噪声句子的影响.Fei等人[15]提出一个端到端神经模型,通过图注意力模型对实体之间的关系图进行建模,来解决重叠实体对的问题.Chen等人[16]提出一种新的神经网络方法,模型首先抽取所有可能的关系,然后对每个目标关系抽取所有可能的实体对,同时将这两个过程打包成一个联合模型,来解决重叠实体对的问题.
研究人员还将注意力机制与长短期记忆网络(Long Short-Term Memory,LSTM)相结合,以提高关系提取的性能[17].Tran等人[18]在LSTM和PCNN的混合神经网络模型中加入注意力机制,抽取了句子不同方面的特征,同时提高模型的抗噪能力.Zhou等人[19]提出分层的选择性注意网络,首先对实体对中所有句子进行粗粒度的句级注意力来选择最相关的句子,然后使用PCNN和基于LSTM的词级注意力来构建句子向量,最后使用细粒度的注意力将结果聚合成句子向量来预测关系.上述方法通过融合不同神经网络的特征,更好地捕捉句子中的多维度的语义特征.然而,它们没有充分考虑非实体词到实体词的距离关系的重要性.Zhang等人[20]提出一种位置感知注意力机制,融合位置嵌入和单词特征来形成注意力矩阵.Wang等人[9]提出位置特征注意力,通过计算目标实体对的所有位置组合来获得加权的句子表示.Li等人[21]提出一种使用高斯函数的位置注意力,以减少低噪声对模型的影响.
与上述方法不同的是,本文提出位置特征注意力与关系增强机制,并将其融入两种神经网络中,在单词层面利用了单词位置所蕴含的丰富信息,在句子层面捕获到多个维度的语义特征,在关系的层面充分捕获重叠关系之间丰富的语义相关性.
3 模 型
本节将具体介绍PARE的关系抽取方法,模型图如图1所示.给定包含l个句子的句包B={S1,S2,…,Sl},包含n个单词的句子S= {w1,w2,…,wi,…,wn},其中wi是句子S中的第i个单词,并将关系标记为R= {r1,r2,…,rk},k是关系的总数.模型首先通过词嵌入和位置嵌入得到文本的输入特征向量,然后利用位置特征注意力重新分配句子中词的权重;其次,利用PCNN和词级注意力得到句子的特征向量;然后,本文提出关系增强机制来捕捉关系之间的语义关联;最后,通过句级注意力机制得到包向量,将其输入到全连通网络中来预测关系.

图1 PARE模型图Fig.1 PARE model
3.1 嵌入层
文本语句无法直接被神经网络编码,所以需要将文本语句转化成向量表示,主要包含词嵌入和位置嵌入两部分.
1)词嵌入
词嵌入将句子中每个单词映射到一个低维的实值向量中,来捕获单词的句法和语义.给定一个句子S={w1,w2,…,wi,…,wn},通过查找预先训练好的词向量矩阵E∈|v|×dw,每个单词wi被转换为dw维实值向量.其中|v|表示词汇表的长度,dw为词嵌入的维数.
2)位置嵌入
本文使用位置特征记录当前非实体单词到两个目标实体单词e1和e2的相对距离,从而捕获句子实体间的结构信息.例如,在句子“intokyo,ontheedgesoftheakihabaraneighborhood,knownaselectrictownforitsconcentrationofelectronicsstores.”中,单词“neighborhood”到e1(tokyo)和e2(akihabara)的相对距离分别为7和1,每个单词的相对距离都被映射到一个dp维实值向量中.
所有的单词的词嵌入和位置嵌入连接起来共同组成该句子的向量表示X∈n×d,其中,n表示句子中单词的数量,d=dw+2dp.
3.2 位置特征注意力
Vilis等人[21]使用以高斯分布为原理的高斯嵌入来获取单词向量,本文在此基础上提出以高斯分布为基础的位置特征注意力,来计算单词的重要性权重,从而充分利用单词之间的位置关系信息.
位置注意力机制原理如下:
在句子向量Xi中,首先收集句子中每个单词和目标实体e1之间的距离,并将其标记为d1,每个单词与目标实体e2之间的距离标记为d2,其中d1和d2是离散距离序列.
然后使用高斯函数来建模单词之间的位置关系,高斯函数的公式如式(1)所示,本文实验使用μ= 0和σ= 0.5.将距离序列d1和d2映射到函数G(X)中,x是单词与目标实体的距离值,得到对应的高斯序列值G1和G2.
(1)
利用softmax函数将序列值G1和G2的和归一化,以求出最终的结果,计算公式如式(2)所示:
α=softmax(G1+G2)
(2)
最后,对句子中的单词向量进行加权,得到新的向量表示,计算公式如式(3)所示:
X′i=Xi·α
(3)
3.3 句级特征提取
本节使用两种不同的神经网络模型从包含目标实体的句子中提取语义特征:1)使用PCNN挖掘每个句子的词相特征和实体之间的结构信息;2)使用基于长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)的词级注意力机制挖掘句子的重要词特征.
1)PCNN
在关系抽取中,由于句子中重要信息的位置不固定,通常使用卷积操作实现局部特征信息的抽取.卷积操作是权重矩阵和句子向量之间的操作.
通过卷积操作层,得到结果句子向量C={c1,c2,…,cm},其中c∈m×(n+f-1),m是过滤器个数,n是句子的长度,f是滑动窗口大小.
为进一步抽取最重要的特征,捕获句子的结构信息和细粒度特征,PCNN采用分段池化操作,根据目标实体对e1和e2的位置将实例分成3个片段,并对每段执行最大池化操作[22],计算公式如式(4)所示:
pij=max(cij),1≤i≤m,1≤j≤3
(4)
其中cij为每个特征向量ci根据目标实体对的位置分成的3部分.
将每个过滤器的输出pi={pi1,pi2,pi3}连接起来形成p1:m,并采用双曲正切函数来进行输出,计算如式(5)所示:
Sic=tanh(p1:m)
(5)
其中Sic∈3m是句子Si的局部特征向量.
2)词级注意力
在关系抽取任务中,识别出重要单词有助于提高模型的性能.本文采用词级注意机制来挖掘句子的重要词特征[19].
首先使用BiLSTM处理句子向量,得到矩阵H=[h1,h2,…,hn],其中H∈d×n,d为隐藏单元的数量,n是单词的个数.
然后,输出向量H的加权和构成句子的向量表示sia,计算如式(6)~式(8)所示:
M=tanh(H)
(6)
α=softmax(wTM)
(7)
Sia=HαT
(8)
其中,Sia∈d是句子Si的重要单词特征向量.
本文利用PCNN和词级注意力两种方式,得到包B中第i个句子Si的两种不同句子向量Sic和Sia.将Sic和Sia连接起来,形成一个新的向量Si,如式(9)所示:
Si=[sia:sic]
(9)
其中,句子向量Si∈3m+d.
3.4 关系增强
为捕获重叠实体对关系之间的语义关联,本文提出以多头注意力为基础的关系增强机制,首先利用词嵌入将关系映射到向量中,然后使用多头自注意力机制对关系向量进行编码,得到语义信息更加丰富的可能关系向量与目标关系向量,以帮助识别实体对.
1)词嵌入
首先使用相同的词嵌入矩阵E∈dw,将关系映射为Ri.所有关系向量形成关系向量矩阵R∈k×dw,其中k是关系的数量,dw是词嵌入的维度.
2)多头自注意力机制
为捕捉向量的深层全局结构特征,研究者人员提出自注意力机制[23].该机制通过相似度公式计算向量之间的相似度,并获得对应的相似度权重向量.
在本文中,为获得重叠关系之间的语义相关性,模型使用多头自注意力机制,模型结构如图2所示,其中h表示该机制中的并行头部的数量.
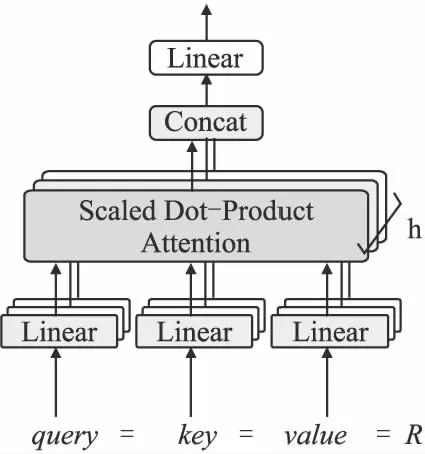
图2 多头自注意力机制Fig.2 Multi-headed self-attention model
多头注意力机制的原理如下:
首先使用缩放点积来计算相似性分数,经过权重的分配得到结果A,计算如式(10)~式(12)所示:
(10)
α=softmax(score)
(11)
A(query,key,value)=α·value
(12)
多头注意力的每个平行头部的计算如式(13)所示:
(13)
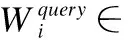
最后,连接每个头部的输出,来获得包含丰富语义信息的向量矩阵,如式(14)所示:
MutiHead(query,key,value)=WM[head1,head2,…,headh]
(14)
本文把向量R与向量S拼接形成Rs,令query=key=value=Rs,计算过程如式(15)所示:
R′=MultiHead(Rs,Rs,Rs)
(15)
其中,R′∈k×dw是关系增强向量矩阵.
3.5 句级注意力
本文使用句级注意力机制来动态突出重要的句子实例.句级注意力机制原理如式(16)~式(18)所示:
ei=S′iAr
(16)
(17)
(18)
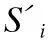
3.6 输出层
本文模型使用softmax函数来计算条件概率p(r|S,θ),它表示在给定参数θ的情况下,将特征向量S划分为相应的关系r的概率.计算如式(19)~式(20)所示:
(19)
o=Ms+d
(20)
其中k为关系的个数,o是上述网络的输出,d∈k是一个偏置向量,M是关系类型的向量矩阵.
3.7 优化目标函数
本文用交叉熵对句子集合S定义目标函数,如式(21)所示:
(21)
其中,n表示句子包的数量,θ是模型所有的参数,包括词向量、位置嵌入、关系增强、卷积操作、词级注意机制和分类器的参数.本文采用随机梯度下降法来最小化目标函数.
在训练过程中,对输出层采用dropout算法[24]来防止过拟合.
4 实验与评估
本章首先介绍实验中使用的NYT10数据集和相应的评价指标.然后将本文的方法与基线关系抽取方法的性能进行对比,并展示它在不同大小的数据集上的表现.
4.1 数据集评估指标
NYT10数据集常被用于远程监督关系抽取任务,最初由文献[8]提出,并被众多研究人员广泛使用[25,26].该数据集是通过将Freebase中的实体对与《纽约时报》语料库对齐生成的.首先使用斯坦福命名的实体识别工具来识别场景中的实体.然后使用Freebase中的三元组实例来标记句子.该数据集中有53个关系类型,包括特殊关系NA,表明句子没有表达任何关系.2005~2006年的句子作为训练集使用,2007年之后的句子作为测试集使用.
本文使用精确率-召回率(Precision-Recall,P-R)曲线,平均精确率P@N以及AUC值作为评估指标.
4.2 实验设置
本文采用与Lin等人[13]相同的参数设置来训练模型,使用三折交叉验证法对模型进行调整[27],实验使用的参数如表2所示.
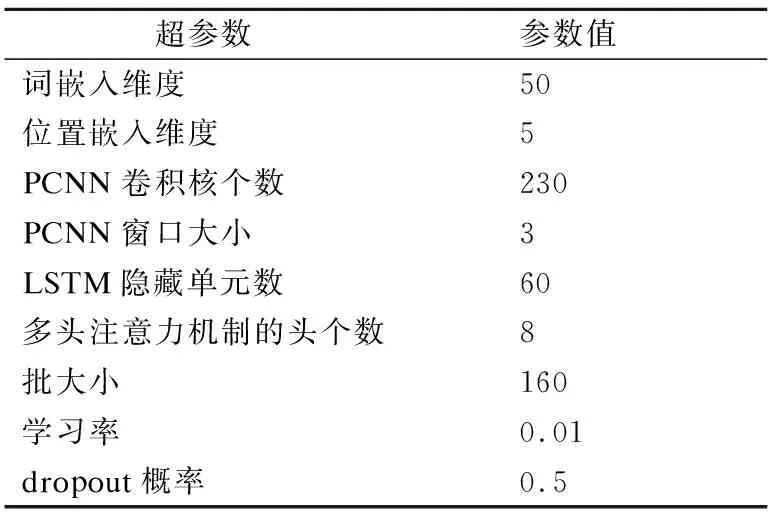
表2 实验参数表Table 2 Experimental parameters
4.3 实验比较
4.3.1 与基线算法的P-R曲线比较
为验证本文模型的性能,将其与以下工作进行比较.
1)Mintz[7]是传统的基于特征的远程监督模型,聚合一个包中所有实例的特征,并将其送入分类器进行模型训练.
2)Hoffmann[11]是传统的基于特征的远程监督模型,在MIL思想的基础上,提出“at-least-one”假设.
3)PCNN+MIL[12]将MIL融合到PCNN中以解决标签错误问题.
4)PCNN+ATT[13]使用句子级注意力自动为句子向量分配权重,以缓解错误标记的问题.
5)HSAN[19]使用一种分层选择性注意力网络,来降低计算成本并捕获关键词特征.
6)PCNN+PATT+SBA[21]使用位置注意机制来减少噪声词的影响.
7)MrMep[16]提取所有可能的关系和目标关系,并将这两个过程打包成一个联合模型,来解决重叠实体对的问题.
图3展示本文模型与基线模型的P-R曲线对比结果.
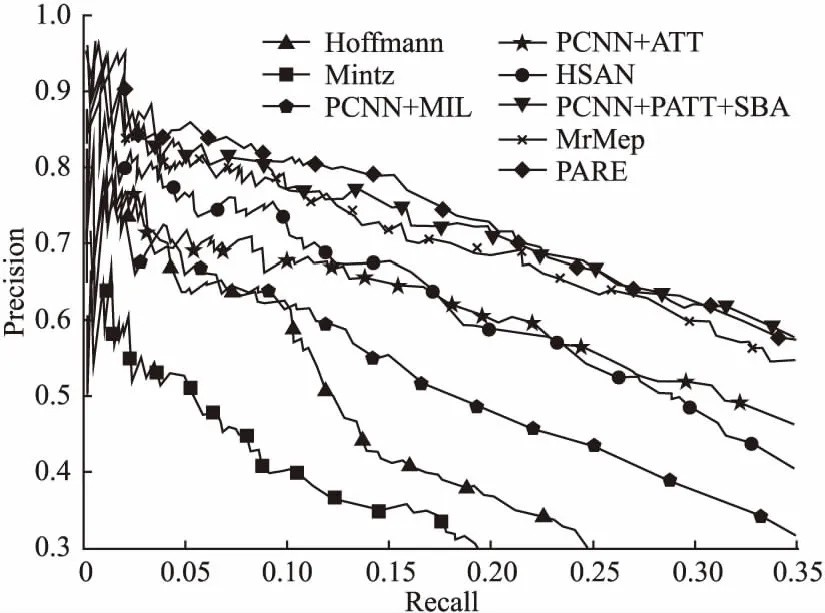
图3 本文模型与基线模型的P-R曲线对比结果Fig.3 P-R curves of the model in our paper and the baseline model
由图3可得:
1)基于神经网络的关系抽取模型比基于特征的模型具有更好的性能,这表明基于特征的模型在捕捉深层语义信息方面较弱,不适合大规模数据的关系提取.
2)HSAN优于PCNN+ATT和PCNN+MIL模型,结果表明混合神经网络模型可以抽取句子多维度的特征,从而提高关系抽取的性能.
3)PARE模型性能优于HSAN、PCNN+PATT+SBA和MrMep模型,说明本文提出的关系增强机制与位置注意力提高关系抽取的准确率.
4.3.2 不同句子数量的影响
本文使用平均准确度P@N展示不同模型的关系提取性能.实验结果示于表3中.

表3 不同句子数量实体对的P@N值Table 3 P-R curves of the model in our paper and the benchmark model
从表3可以看出:
1)PARE模型的P@N值超过基线模型PCNN-ATT,与PCNN-ATT模型相比增加19%.
2)PARE模型的P@N值超过模型HSAN、PCNN-PATT-SBA和MrMep.这表明,关系增强机制增强了关系之间的语义关联,位置特征注意力机制充分利用了单词之间的位置信息,这两个模块为关系抽取提供了更多维度的语义特征.
4.3.3 消融实验
本节设计消融实验,来更好地说明PARE模型中每个模块的贡献.PA表示PARE模型缺省关系增强模块,RE表示PARE模型缺省位置特征注意力模块.结果如图4所示.

图4 消融实验结果Fig.4 Ablation experiment results
从图4中可以得到:
1)PARE模型的性能高于模型HSAN.这表明,在混合神经网络中增加关系增强机制与位置特征注意力可以捕获更多维度的语义特征.
2)PA模型比HSAN模型取得了更好的效果,表明本文提出的位置增强机制通过高斯分布对句子中的单词重新分配权重,提高模型的抗噪能力.
3)RE模型的性能高于模型HSAN,表明使用多头自注意力机制来捕获关系之间的相关性有助于提高关系提取的准确率.
4.3.4 AUC值
将本文算法的AUC值与CNN+ATT、PCNN+ATT和HSAN算法进行比较,结果如表4所示.

表4 不同模型的AUC值Table 4 AUC values of different models
由表4中可以观察到,与基线方法相比,PARE方法的性能有很高的提升.
4.3.5 多头注意力机制中头部数量的影响
在关系增强机制中,多头注意机制中头部的数量也会影响关系相关性的捕获.因此,本节使用不同数量的头部进行进一步的实验分析,结果如表5所示.
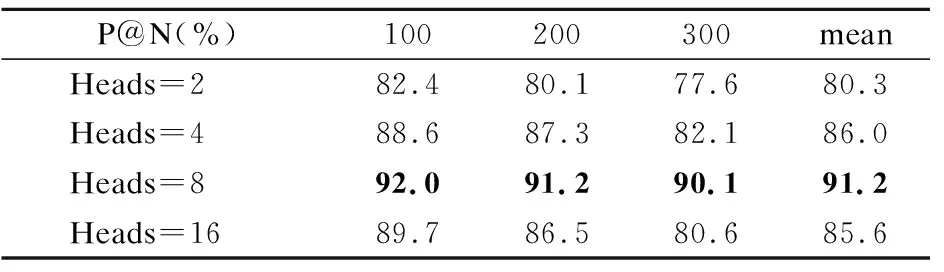
表5 不同头部数量的P@N值Table 5 P@N values of different numbers of heads
由表4可得,随着头部数量的增加,模型的性能并非持续上升,当头部数量为8时,模型效果取得最优.
5 总 结
本文提出融合位置特征注意和关系增强机制的远程监督关系提取模型,在混合神经网络中加入位置特征注意力,以充分利用单词之间的位置关系信息;为捕捉重叠关系间的关联性,本文提出以多头自注意力为基础的关系增强机制来重新编码关系向量.实验表明,本文模型的性能相比于基线模型有较大改进.
