一种面向自然语言需求的安全需求获取方法研究
2023-12-13李广龙沈国华黄志球杨思恩
李广龙,沈国华,3,黄志球,3,杨 阳,杨思恩
1(南京航空航天大学 计算机科学与技术学院,南京 211106) 2(南京航空航天大学 高安全系统的软件开发与验证技术工业和信息化部重点实验室,南京 211106) 3(软件新技术与产业化协同创新中心,南京 210093)
1 引 言
在软件开发过程中,尽早地实现安全性(Security)非常重要,尤其是在需求阶段,这样可以在进一步处理流程之前尽早解决安全问题并避免返工[1].安全需求工程(SRE:Security Requirements Engineering)关注在需求阶段的早期对软件系统进行安全性分析[2],它指的是获取软件系统的安全需求(Security Requirement)的一系列方法流程[3].
目前,安全需求的主流定义分为以下两种观点:一种把安全需求看作非功能性需求,认为安全需求是对系统功能的一种约束;另一种把安全需求看作功能性需求,认为它是对系统安全行为的描述.本文对于安全需求的理解与第2种观点一致,即安全需求是对软件系统中需要实现的安全功能(SF:Security Functionality)的描述.
在安全需求工程的相关研究中,已有若干安全需求获取方法,如Security Use Cases[4]、Abuse Cases[5]、Misuse Cases[6]以及故障树[7]、攻击树[8]等,它们往往需要完备的专家知识,并需要对需求进行详细的人工分析,从中抽取出关键资产(也称作实体),分析实体面临的安全威胁,进一步获得与威胁相对应的安全目标,最后将安全目标细化到安全需求上,它们大多存在以下不足:
1)需要需求分析人员手动执行,耗费很多的时间和精力.尤其是需要通过手工处理大量的自然语言需求来识别需求实体(如资产)、实体关系(如用户对资产的操作)等需求相关信息;
2)需要需求工程师有完备的软件安全领域的专家知识,以支持完成安全需求的规约或建模.比如:Mai等人[9]的方法要先从需求中获取Security Use Cases、Misuse Cases等;微软的威胁建模工具[10]要先建立软件的数据流图;攻击树需要先根据功能需求建模攻击路径;
3)生成的安全需求对相关安全标准的符合性缺乏考虑.目前已有若干安全性标准,获取的安全需求模型是否符合标准是一个值得探讨的问题.
针对以上不足,本文使用自然语言处理技术自动地从每一句自然语言需求文本中抽取需求实体及实体关系,并将抽取到的信息用于实例化一组基于CC(Common Criteria)[11]标准构建的参数化安全需求模板,最终形成针对每一句自然语言需求文本的安全需求集.CC标准作为评估IT产品安全性的国际准则,提供一套通用要求来进行IT产品的安全评估.基于CC标准的通用要求构建的参数化安全需求模板不仅可以实现安全知识重用,还可以有效应对需求工程师在软件安全领域经验知识上的缺乏.
在实例化安全需求模板之前,需要准确地获取适用于需求文本的安全需求模板.Riaz等人[12]和Firesmith等人[13]认为拥有相同安全目标的软件系统,也拥有相似的安全需求集,通过整理、总结这些需求集,可以得到一组通用的参数化安全需求模板.安全目标(Security Object)指的是系统所期望的安全属性(Security Properties)[12],如“Confidentiality”、“Integrity”、“Availability”等.因此,本文使用深度学习技术自动识别输入的需求文本的安全目标,进而初步获得一组相应的安全需求模板.但是,这组安全需求模板只是可以满足对应的安全目标,它们并不一定都适用于输入的需求文本,因此,本文对每一个需求模板还建立一组匹配条件来表征其所适用的需求文本.
针对以上情况,本文结合自然语言处理技术与深度学习技术,提出了一种从自然语言描述的需求文本中自动获取安全需求的方法.该方法的输入是英文自然语言需求文本,输出是每一句需求文本对应的安全需求.为便于阐述,本文后续内容使用“需求文本”指代“英文自然语言描述的需求文本”.本方法有如下四个步骤:首先,使用自然语言处理技术从每一条需求中抽取实体、实体关系;其次,使用基于深度学习的多标签文本分类模型预测每一条需求的安全目标集;然后,通过一组映射关系获得安全需求模板集,再使用抽取出的相关信息判断每个安全需求模板的匹配条件是否成立,以此来筛选出最终的安全需求模板集,本文中提出的安全需求模板基于CC标准构建;最后,使用抽取出的实体及实体关系来实例化安全需求模板,获得每条需求文本的安全需求.
本方法的优点在于将原本耗时耗力的人工处理自动化,且不明显依赖专家经验,依据相关标准将专家经验隐匿在安全目标的识别和安全需求模板中,由此获得的安全需求自然而然符合安全标准.
本文后续内容安排如下:第2节介绍本文的相关技术背景;第3节介绍本文中使用的安全需求模板;在第4节中介绍本文所提方法的流程框架以及方法的具体步骤,并结合一条需求文本处理的实例来具体介绍方法每一步的输入与输出.第5节给出工具实现和安全目标多标签文本分类模型的实验分析;第6节是对相关工作进行分析;第7节是本文的总结与展望.
2 相关技术背景
2.1 安全目标分类
通过识别文档中某一特定句子所表达或暗示的安全目标,可以了解该句子的意图,以及建立该意图的可能安全功能与需求[12].本文使用Riaz等[12]收集的六种安全目标,这些安全目标主要关注软件系统的实现技术,六种安全目标的定义如下:
1)机密性(C:Confidentiality):系统保证信息不泄露给未授权者.
2)完整性(I:Integrity):系统阻止未经授权的修改计算机程序或数据的程度.
3)标识和鉴别(IA:Identification &Authentication):系统需要标识和鉴别有效的身份.
4)可获得性(A:Availability):系统的资源或服务在需要被使用时,可以被操作和被访问的程度.
5)问责制(AY:Accountability):影响软件资产的操作可以追溯到负责该操作的参与者的程度.
6)隐私(P:Privacy):参与者理解和控制其信息使用方式的程度.
在本文中,使用多标签文本分类任务来完成安全目标分类,任务的输入是一句英文自然语言需求,输出是这句需求的多个安全目标类别.传统的分类任务假设一个实例只属于一个特定的类别,然而在大多数实际分类任务中,一个实例往往可能同时属于多个标签类别,这种任务被称为多标签分类任务.多标签文本分类是多标签分类的一个重要分支,它指的是对于给定的文本预测其属于的多个标签类别,主要应用于主题识别、情感分析、问答系统等[14].
2.2 依存解析、开放信息抽取
依存解析(Dependency Parsing)是句法分析的一种形式[15],它和开放域信息抽取(Open IE:Open domain Information Extraction)[16]是本文抽取实体及实体关系的关键.
依存句法解析指的是识别句子中单词与单词之间的相互依存关系.依存句法解析的输出可以表示为单词之间的有向无环图,单词之间标记的是依存关系.图1是自然语言处理工具Stanford CoreNLP[17]对需求语句R1进行依存解析的图形化显示结果,这里的一个依存关系的示例是:nsubj(evaluate{4},doctor{2}),它指的是“doctor”是动词“evaluate”的主语,大括号“{}”里面的数字是对应单词在句子里的序号.关于依存关系的详细解释可以参考文献[18].需求语句R1还将在本文第4节的方法流程介绍中使用.

图1 Stanford CoreNLP对R1进行依存解析的图形化输出Fig.1 Stanford CoreNLP graphical output of dependency parsing for R1
开放域信息抽取指的是从句子中抽取开放域关系三元组:关系的主体(subject)、关系(relation)和关系的客体(object).图2是Stanford CoreNLP对需求语句R1进行开放域信息抽取的图形化显示结果,这里的一个关系三元组的示例是{‘subject’:‘doctor’,‘relation’:‘shall evaluate’,‘object’:‘results of tests’}.

图2 Stanford CoreNLP对R1进行开放域信息抽取的图形化输出结果Fig.2 Stanford CoreNLP graphical output of open information extraction for R1
本文基于依存解析输出的依存关系来构建用于抽取实体及实体关系的启发式规则,并结合开放域信息抽取,以此来尽可能地抽取实体及实体关系.
2.3 CC标准简介
本文所使用的安全需求模板是基于CC标准[11]第2部分“安全功能组件”构建的.CC标准全称为信息技术安全评估准则(Common Criteria for Information Technology Security Evaluation),又被称为ISO/IEC 15408标准,目前最新版本为V3.1[11],它是用来评估信息系统、信息产品的安全性的国际标准.CC标准包括以下3部分:简介和一般模型(Introduction and General Model)、安全功能组件(Security Functional Components)、安全保证组件(Security Assurance Components).
CC标准第2部分(安全功能组件)是一个可以用于规约评估对象(TOE:Target of Evaluation)的安全功能(TSF:TOE Security Functionality)需求集,该需求集以“功能类(Functional Class)—功能族(Functional Family)—功能组件(Functional Component)”的三级层次结构进行组织.图3提供了一个有关用户数据保护(User Data Protection)的功能类的分解示范,图中的功能类、族的名称以“标识名:真实名称”的格式给出.如图3所示,该功能类含有多个族,每个族含有多个组件,其中用于数据鉴别的功能族(FDP_DAU)提供一种保证特定数据单元有效性的方法,并应用于验证数据是否被伪造或欺诈性修改[11].

图3 一个功能类的分解图Fig.3 Class decomposition diagram
同一功能族内的功能组件之间可能存在从属关系,如图3中:功能族FDP_DAU的功能组件2从属于功能组件1(FDP_DAU.1:Basic Data Authentication),即组件2所描述的数据鉴别方式依赖于组件1.每一个功能组件含有多个功能元素,如FDP_DAU的组件1包含两个功能元素,每一个功能元素在经过实例化之后可生成一条安全需求.
3 安全需求模板
本文使用的安全需求模板是基于CC标准第2部分“安全功能组件”构建的,然而,由于对标准的理解与应用非常依赖安全领域知识,本文精简了一部分安全功能组件(去除少数不相关的管理类组件),最终形成了36个安全功能SF和40条安全需求模板1(Security Requirements Template).每一个SF在粒度上对应到CC中的一个功能族,因此本文将CC中功能族的标识名作为对应SF的标识.选择功能族作为SF的对应,这是因为功能族涵盖了对功能组件包含的所有功能元素的概括描述,它比功能类更加具体,也比功能组件有更好的概括表达能力,是一个精确度和抽象度的最佳平衡点.
本文基于对CC标准的理解,每一条安全需求模板是经过手动筛选、简化、合并功能族内的功能元素得到的,对功能元素进行以上操作的主要原则是:在保持功能元素的基本语法结构以及语义不变的情况下,生成能够覆盖其他功能元素主要内容的安全需求模板.
对功能元素的具体处理如下:首先,优先选择从属关系靠前的功能组件下的功能元素,并根据功能元素所描述的安全控制范围(Security Control Scope,见3.1节)的不同来选择其他组件内的功能元素;然后,适当简化功能元素中安全相关词汇,使其更加易于理解,如“information types”简化为“information”;最后,合并在实际执行中存在先后顺序的功能元素,如CC标准中在涉及加密秘钥管理的功能族中,有4条存在先后顺序的功能元素(秘钥生成、分发、存取和销毁),本文按照顺序将其合并为一条安全需求模板.在经过以上处理之后,得到的安全需求模板仍然能够保证在内容以及表达的语法结构上对CC标准的符合性.
3.1 安全需求模板的组织结构
每一条安全需求模板都是对系统应该实现的安全功能的描述,同时,每一条模板还可以满足特定的安全目标.如图4所示,每一个SF包含一个功能的名称、功能的介绍、以及一个或多个安全控制范围.每一个安全控制范围包含一组匹配条件、一个安全需求模板以及模板所满足的一个或多个安全目标.安全控制范围由SF所针对的主体、动作和客体定义,它由其包含的安全需求模板的匹配条件来表现.同一个SF因为在实际应用上的不同选择(不同的主体、动作、客体),可能有多个安全控制范围,也即有多个安全需求模板.本文使用安全需求模板的匹配条件来表现安全控制范围,也就是将匹配条件用于判断当前安全需求模板是否适用于输入的需求文本.

图4 安全需求模板的组织结构Fig.4 Structure of security requirements templates
本文给出一个SF的完整示例,该SF对应图3中的功能族FDP_DAU.其中“SF.6”是该SF的序号,“Data authentication”是该SF的名称.该SF如下:
SF.6Dataauthentication(FDP_DAU)
SF Introduction:This SF provides a method of providing a guarantee of the validity of data that can be used to verify that the information content has not been modified.
SecurityControlScope1:
Security objects:I
Matchingconditions:
Securityrequirementtemplate:The SF shall provide a capability to generate evidence that can be used as a guarantee of the validity of [assignment:
SecurityControlScope2:
Securityobjects:IA,AY
Matchingconditions:
Securityrequirementtemplate:The SF shall provide [assignment:
本文给出了一组安全目标与安全功能的映射关系,如表1所示,表中第1列是安全目标(SO:Security Object).考虑到本文的安全需求模板的组织关系,所以本文建立了安全目标与SF的映射关系.因此,给定安全目标就可以映射到特定的SF,再通过遍历SF下的安全控制范围,就可以获得特定的安全需求模板,最后通过相应的匹配条件筛选出适合原始输入需求的安全需求模板.

表1 安全目标、SF之间的映射关系Table 1 Mapping between SO and SF
3.2 安全需求模板的匹配条件
由安全目标获得的安全需求模板,需要使用安全需求模板的匹配条件来进一步筛选出适合原始输入需求的安全需求模板.一组匹配条件包括多条单独的匹配条件,当每条条件都成立时,这一组条件才算成立,即当前需求模板匹配成功.所有匹配条件共有8种基本参数(Basic Parameters)以及4种语法形式.
3.2.1 8种基本参数
所有匹配条件共有以下8种基本参数:
3.2.2 4种语法形式
所有匹配条件共有以下4种语法形式,其中,使用“and”表示逻辑与,“or”表示逻辑或,“=”表示赋值操作,、表示8种基本参数中的一种,W表示一组单词的集合:
1):当条件为一个基本参数时,表示在原始需求语句中如果存在该参数类型的信息,则该条件成立;
2)=W:当条件为一个基本参数的赋值语句时,表示在原始需求语句中如果存在等号右侧的词语,则该条件成立.参数
3)and:当条件为多个基本参数相“and”时,表示在抽取的信息中如果同时存在这几个基本参数类型的词语,则该条件成立;
4)or:当条件为多个基本参数相“or”时,表示在抽取的信息中如果存在其中一个参数类型的词,则该条件成立.
3.3 安全需求模板中的参数
在安全需求模板中,单词串“[assignment:< >]”中带有尖括号“< >”的词语是需要实例化的参数,例如第3.1节的SF示例中的“[assignment:
4 面向自然语言需求的安全需求获取方法
本文提出了一个用于从英文自然语言需求文本中自动获取安全需求的方法,方法的整体流程框架如图5所示.
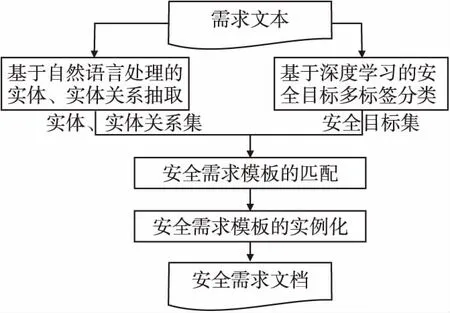
图5 方法整体流程框架图Fig.5 Overall process of our method
本文的方法一共包含4个步骤:首先,基于自然语言处理抽取每一条需求语句中的实体以及实体关系;其次,使用基于深度学习的多标签分类模型预测每一条需求语句的安全目标集;然后,根据前两步的输出,通过匹配得到适用于输入需求的安全需求模板;最后,实例化安全需求模板中的参数.方法更加具体的细节,将在本章节的下面几个小节详细介绍.此外,本章节还提供一个需求文本(第2.2节所示的R1)的处理实例,并将其贯穿于方法流程的介绍中.
4.1 基于自然语言处理的实体、实体关系抽取
从需求文本中抽取实体以及实体关系,不仅可以在本文方法的第3步中用于判断安全需求模板的匹配条件是否成立,还可以在第4步中用于实例化安全需求模板.本文联合Javed等人的方法iMER[19]和自然语言处理工具Stanford CoreNLP[17]来抽取实体及实体关系,并进一步从中筛选出本文所期望的实体以及实体间的动作关系.在本文中,实体间的动作关系是实体关系的一种,这种关系更关注主体对客体执行的一个操作或动作.主要步骤如下:
首先,使用自然语言处理工具Stanford CoreNLP来预处理需求文本,包括标记化(Tokenizing)、拆分句子(Spliting)、词干化(Lemmatizing)、词性标记(Part of Speech)和依存解析.需求文本R1在经过Stanford CoreNLP处理后得到依存关系,该依存关系的图形化显示见图1.
其次,使用iMER中构建的基于依存关系类型的启发式规则来进行实体以及实体关系的抽取.在抽取需求实体及实体关系这个领域中已有很多基于自然语言处理的方法,本文选择iMER的原因主要是其采用的依存关系的类型多且较为全面.在需求文本R1中,iMER抽取到的实体集有:[‘tests’,‘results’,‘doctor’,‘hospital’,‘patient’],实体关系集有:[{subject’:‘doctor’,‘relation’:‘evaluate’,‘object’:‘results’}].
然后,本文还使用Stanford CoreNLP的openIE标注器进行实体关系抽取,图2是需求文本R1在经过Stanford CoreNLP处理得到的图形化显示的实体关系,抽取到的实体集有:[‘doctor’,‘results of tests’,‘results’],抽取到的实体关系集有:[{‘subject’:‘doctor’,‘relation’:‘shall evaluate’,‘object’:‘results of tests’},{‘subject’:‘patient’,‘relation’:‘is in’,‘object’:‘hospital’},{‘subject’:‘doctor’,‘relation’:‘shall evaluate’,‘object’:‘results’}].
最后,取所有实体及实体关系抽取结果的并集,以此来尽可能的抽取所有潜在的实体及实体关系.在取并集之后,需要去除一些停止词(Stop Words),如“shall”、“should”、“the”等.值得注意的是,实体之间会存在实体嵌套的情形,例如:“list of drugs”与“drugs”,为了避免重复,本文采用最大化原则:选择单词边界最大的实体,即“list of drugs”.本文给出实体嵌套时选择最大化实体的算法,如算法1所示.
算法1.SelectMaximizeEntities
输入:Entities
输出:MaxEntities
1.MaxEntities=Ø
2.for each Entity e in Entitiesdo
3.foreach MaxEntity me in MaxEntitiesdo
4.ifme in ethen
5. MaxEntities.remove(me)
6. MaxEntities.add(e)
7.break
8.elife in methen
9.break
10.endif
11.else
12. MaxEntities.add(e)
13.endfor
14.endfor
此外,本文认为安全需求是对软件系统中需要实现的安全功能的描述,且安全需求模板中涉及到需求实体关系的参数只关注实体间的动作(主体对客体的一个操作),所以对于一个实体关系来说,如果它不包含动词,那么该实体关系会被舍去,例如对于图2中的实体关系,关系{‘subject’:‘patient’,‘relation’:‘is in’,‘object’:‘hospital’}会被舍去.其次,在筛选实体间的动作时,如果两个关系中存在嵌套:一个关系中的relation是另一个关系中的relation的一部分,或一个关系中的实体是另一个关系中的实体的一部分,为了避免重复,本文也采用最大化原则:选择单词边界最大的实体关系(这一部分的算法与算法1类似,本文不再赘述).
经过第1步的处理,从需求文本R1中抽取到的实体集有:[‘results of tests’,‘doctor’,‘hospital’,‘patient’],动作关系集有:[{‘subject’:‘doctor’,‘relation’:‘evaluate’,‘object’:‘results of tests’}],这些也将作为本文方法的第3步的输入.
4.2 基于深度学习的安全目标多标签分类
在这一步中,本文使用基于深度学习的安全目标多标签分类模型来获得每一条需求语句的安全目标集,安全目标集中可能含有0个或1个或多个安全目标.在本文的工作中,一共使用了6种典型的安全目标:“Confidentiality”,“Integrity”,“Availability”,“Identification &Authentication”,“Privacy”,“Accountability”.
在多标签文本分类领域中已经有很多表现出色的分类模型,但是这些模型都是在新闻或者学术论文等文本类型的数据集中训练得到,它们在需求文本的安全目标多标签分类上的表现并未可知.为获得出色的安全目标多标签分类模型,在第5.2节中,本文在文献[12]公开的数据集上进行一组十折交叉验证实验,并使用3种常用的评估指标来评判每一个模型的分类效果.3种指标分别为:精度(P:Precision)、召回率(R:Recall)和F1,这些指标的值越高越表明模型的分类效果越好.实验结果(见表3)表明,BERT-TextCNN模型的平均精度、平均召回率和平均F1值均高于其他模型,分别达到:88.4%(该模型预测出来的所有安全目标中平均有88.4%的安全目标是预测正确的)、88.1%(所有被标注的安全目标中平均有88.1%的安全目标被该模型预测出来)和84.6%.因此本文选择该模型用于安全目标多标签分类.
需求文本R1在经过BERT-TextCNN模型预测后得到的安全目标类别为“Confidentiality,Integrity”,这符合本文的预期:因为医生要评估病人的检查结果,这涉及到病人数据的机密性,以及检查结果的完整性.
4.3 安全需求模板的匹配
在获得需求语句的实体、实体间的动作关系以及安全目标集之后,本文使用这些信息去匹配安全需求模板:根据安全目标和SF之间的映射关系,由安全目标集可以获得一组安全需求模板,但是这些模板并不一定都适用于输入的需求语句,这需要根据每条模板的匹配条件去判断.
想要判断匹配条件是否成立,首先需要从输入的需求文本中识别匹配条件的8种基本参数的单词实例.在本文第3节的介绍中,基本参数
对于
1)通过英文的词缀‘-er’、‘-or’、‘-ist’识别;
2)建立一些user类的关键词,如:职业者、特定领域的人的称呼词(如医疗领域的patient、doctor).
对于
对于需求文本R1来说,本文从第1步的输出中抽取以下参数以及参数的单词实例:
对于需求文本R1来说,由第2步得到的安全目标“Confidentiality”,可以映射到“SF.5 Access control policy(FDP_ACC)”,最终可以获得一条满足“Confidentiality”的安全需求模板及其匹配条件:
Matchingconditions:
Securityrequirement:
The SF shall enforce the[assignment:
该模板的匹配条件是成立的,即该安全需求模板适用于需求文本R1,这条安全需求模板(后文简称SRQ1)将在下一小节补全.
本文给出判断匹配条件是否成立的算法,如算法2所示,其中,算法2的输入“BasicParameters”指的是从输入的需求文本中识别到的8种基本参数及其单词实例.
算法2.JudgeMatchingConditions
输入:MatchingConditions,BasicParameters,ReqSentence
输出:isMatching
1.foreach Condition c in MatchingConditionsdo
2.ifc =“”then
3.ifBasicParameters.= Nullthen
4.returnFalse
5.endif
6.elifc =“=W”then
7.foreach word w in Wthen
8.ifw in ReqSentencethen
9.break
10.endif
11.else
12.returnFalse
13.endfor
14.elifc =“ and ”then
15.foreach Parameter p in {,}then
16.ifBasicParameters.p = Nullthen
17.returnFalse
18.endif
19.endfor
20.elifc =“ or ”then
21.foreach Parameter p in {,}then
22.ifBasicParameters.p != Nullthen
23.break
24.endif
25.else
26.returnFalse
27.endfor
28.endif
29.else
30.returnTrue
31.endfor
4.4 安全需求模板的实例化
本文通过一组字符串正则表达式来找到安全需求模板中需要实例化的参数,即“[assignment:<>]”里的带尖括号的参数,并将可以赋值的参数以“=string value”的形式赋值.所有可以自动填写的参数基本都是匹配条件中的基本参数,但是还有一种参数:
如下是经过填写的安全需求模板SRQ1:
The SF shall enforce the [assignment:
5 安全需求获取工具实现
本节首先介绍支撑所提方法的辅助工具;然后详细介绍一组多标签文本分类模型的对比实验,这是因为选择一个分类指标最优的分类模型对辅助工具来说十分重要.
5.1 工具实现
本文实现了一个支撑所提方法的辅助工具SRE4CC,用户可以选择批量输入需求文本或者单例输入需求文本,批量输入是以文本文档的形式输入多条需求语句.对于批量输入来说,本文的工具首先切分需求语句,然后对每一条句子单独处理,并将每一句的处理结果进行分页显示.按照MVC的设计思想,本文给出了工具的实现框架,如图6所示.
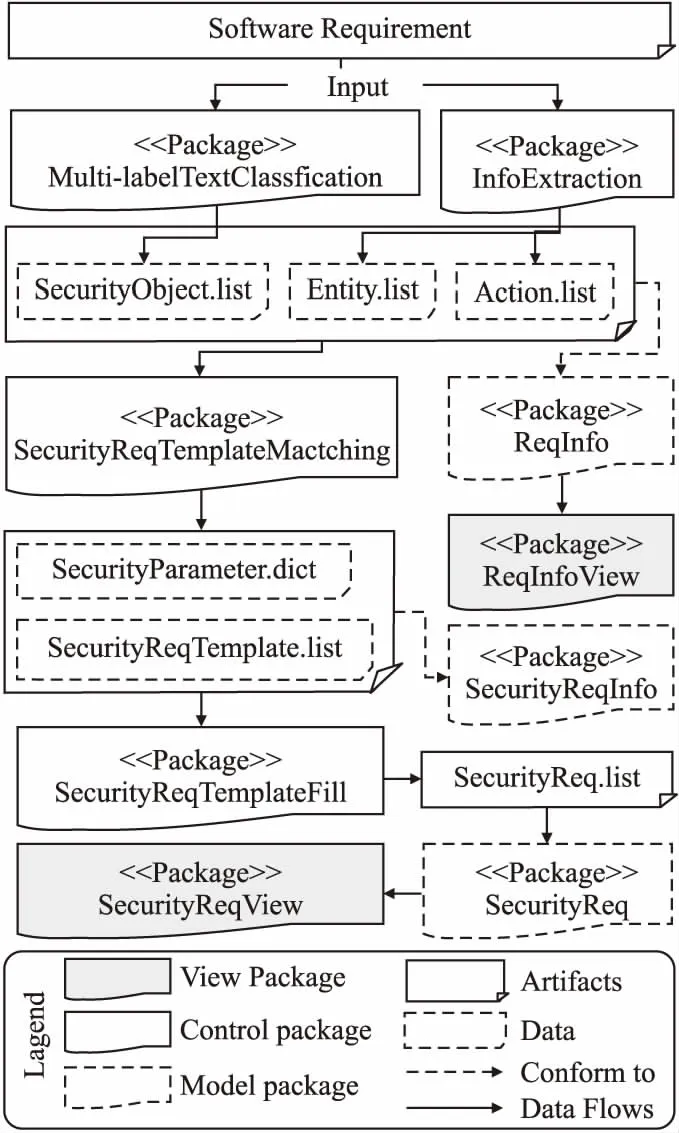
图6 原型工具实现框架Fig.6 Framework of prototype tool
在SRE4CC中,对于需求语句R1的输出界面如图7所示,其中包括:预测的安全目标,抽取到的实体、实体间的动作关系,程序运行时间消耗,以及安全需求.最终输出的安全需求是以“安全目标-安全功能-安全需求”的三级层次结构来组织的.用户可以选择右上角的按钮以下载“.docx”格式的所有安全需求.

图7 R1的输出界面Fig.7 Output interface of R1
5.2 多标签文本分类模型实验
本节在开源数据集(“Security Discoverer”[12])上对5种基于深度学习的多标签文本分类模型进行实验评估,实验所用的分类模型在非需求文本数据集上都曾获得出色的表现.
5.2.1 数据集
Security Discoverer[12]:这份数据集是从6个医疗保健网站收集到的需求文本,总计10963条文本.每条需求文本有多个安全目标的标签,该数据集一共有6个安全目标的标签,其中安全目标:“Confidentiality”、“Integrity”、“Availability”所对应的文本数目最多,分别达到了总体的30%上下,该数据集的详细统计信息如表2所示.

表2 Security Discoverer的统计信息Table 2 Statistics of Security Discoverer
5.2.2 评估指标
对于所有的实验,本文使用3种常用的评估指标来评估性能[12],即精度(P:Precision)、召回率(R:Recall)、F1.
精度是预测正确的类别数量与所有预测出的类别数量的比值:
(1)
召回率是预测正确的类别数量与实际的类别数量的比值:
(2)
F1是精度和召回率的调和平均值:
(3)
其中,TP(True Positive)表示被预测正确的安全目标类别总数.FP(False Positive)表示预测错误的安全目标类别总数.FN(False Negative)表示没有预测出来的安全目标类别总数.
5.2.3 文本分类模型
SGM[20]:将多标签分类任务视为序列生成问题,并应用全局嵌入的序列生成模型在解码标签时考虑全局信息.
LBA[21]:基于BERT的使用标签嵌入的双向注意力模型.
BERT[22]:谷歌公司的一种预训练语言模型,它在11个NLP(Natural Language Processing,自然语言处理)任务中获得了state-of-the-art的结果.
BERT-TextCNN:使用BERT提取文本特征,再使用TextCNN[23]实现多标签分类.
BERT-BiLSTM:使用BERT提取文本特征,再使用双向LSTM[24]建模句子特征,最后使用一个全连接层实现多标签文本分类.
5.2.4 实验细节
本文在数据集Security Discoverer上对分类模型进行十折交叉验证[25]:将数据集随机分成9个相等的不同部分,使用其中的9个部分进行训练,并保留余下的一个部分用于测试;对每一个模型重复训练10次,每次都保留一个不同的部分进行测试.每个模型每次训练30个周期,批处理大小为32.
对于模型SGM,本文使用其开源的代码来完成实验.对于其他的模型,本文使用Transforms库[26]实现模型的编码.BERT模型使用“bert-base-uncased”版本来初始化参数.模型训练过程中使用交叉熵损失(Cross Entropy)函数来计算损失值.
5.2.5 实验结果与分析
图8以箱线图的形式展示了十折交叉验证的实验结果,箱线图是显示一组数据分散情况的统计图.其中,BERT-TextCNN的综合表现最好:BERT-TextCNN的所有指标的箱线图的上边缘、中位数、下四分位数在5种模型中都是最高的.虽然BERT-TextCNN的精度和召回率的箱线图是面积最大的,这意味着该模型的表现的波动较大,但是该模型的中位数是最高的,尤其重要指标F1的箱线图面积和其他几个模型并没有十分显著的差距.
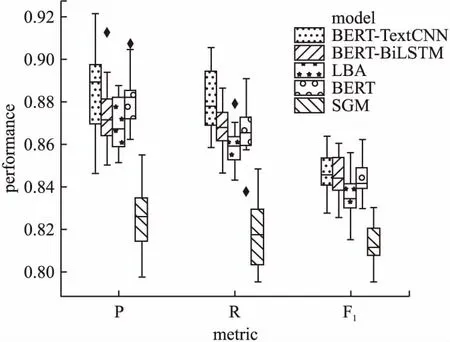
图8 十折交叉实验结果的箱线图Fig.8 Box-plot of the performance
表3列出了所有5种模型的平均精度、平均召回率和平均F1分数,其中加粗的数字是同一指标中最大的数值.具体来说,BERT-TextCNN达到88.4%的平均精度,88.1%的平均召回率和84.6%的平均F1,这些要优于其他模型.表3中Security Discoverer模型指的是数据集“Security Discoverer”的原本方法,该方法将3种机器学习算法的分类结果做最多投票来进行多标签分类,除了这个模型之外的其他模型都是基于深度学习的模型.可以看到,即使是单独的BERT模型其也达到了88.2%的平均精度、86.6%的平均召回率、84.4%的平均F1分数,这也印证了BERT作为预训练语言模型的强大.值得关注的是,模型SGM的表现与其他模型有较明显的差距,这与数据集的标签类别数量可能存在关系:SGM将多标签分类转换为序列生成任务,本文实验的数据集有6个标签,这对序列生成任务来讲数量太少;而且SGM采用一般的词嵌入层,这并没有BERT对于文本的建模效果好.经过比较,本文选择BERT-TextCNN作为本文方法中的第2步的多标签分类模型.

表3 模型的平均实验结果Table 3 Average experimental results of models
6 相关工作
本文的相关工作包括3部分:安全需求工程;需求文本分类;需求知识抽取.
6.1 安全需求工程
安全需求工程指的是获得软件系统的安全需求的一系列方法流程,主要强调在软件开发生命周期的早期识别安全需求.在早期的研究工作中,研究人员大多基于用例的扩展进行安全需求的获取,比如:Security Use Cases[4]、Abuse Cases[5]、Misuse Cases[6]等,但在Saeki等[27]的研究中指出,现存的很多用例模型都需要专家或者具有较为完备的安全知识的人才的介入.Velsco等人[28]和Souag[29]等人使用可重用的安全需求本体来获取安全需求,提高了安全知识的复用性.在本文中使用基于CC标准的安全需求模板来提高安全知识的复用性.
为了提高安全需求获取流程的自动化程度,一些研究人员提出了基于学习的方法来获取安全需求.Wang等人[30]和徐怡琳[31]分别从软件产品的CC标准认证报告(Security Target文档[32])中构造数据集,使用基于机器学习的方法构建模型以自动推荐软件安全需求.Riaz等人[12]利用机器学习算法确定句子的安全目标,并实例化一组上下文特定的安全需求模板来获得安全需求,这种方法与本文的方法相似,不同之处在于,本文使用分类效果更好的深度学习模型,并且本文的安全需求模板是基于CC标准构建的,为了有效的使用模板,本文还使用自然语言处理技术从需求文本中抽取信息用来进一步筛选模板和实例化模板.
6.2 需求文本分类
需求文本分类方法多采用信息检索技术和基于学习的技术.Cleland等[33]和贾一荻等[34]通过计算术语与关键词之间的相似度对非功能需求进行分类.Tong Li等[35]基于安全需求本体和安全需求的语言特征来训练自动识别安全需求的机器学习算法.Riaz等人[12]和Kurtanovic等人[36]分别在需求文本分类上使用了多种机器学习方法,也获得了不错的效果.Guzman等人[37]在需求文本分类任务上的实验结果表明采用深度学习的方法比采用机器学习的方法表现较优.本文经过实验最终确定的深度学习模型BERT-TextCNN,在相应数据集上可以达到平均84.6%的分类F1值,获得较优的分类结果.
6.3 需求知识抽取
一直以来,如何从自然语言描述的需求中自动化的抽取需求实体、实体关系等需求知识,是需求工程相关研究者的热点关注对象.Dwarakanath等人[38]使用语言规则从需求中识别过程名词、抽象名词和助动词;Arora等人[39]使用扩展的提取规则集,从需求中提取领域模型;Javed等人[19]使用37条语言规则,从需求中抽取实体关系和业务流程模型.这些基于启发式的方法往往需要根据专业知识建立语言规则,以提取目标信息[40],为此,Li M等人[40]采用深度学习模型LSTM-CRF来抽取需求实体,并引入一般知识来减少模型对标记数据的需求.本文也正在尝试使用基于深度学习的方法抽取需求实体,并期望未来可以将其纳入到本文方法的流程体系中来.
7 总结与展望
本文设计了一个用于从英文自然语言需求中获取安全需求的方法流程框架,该方法首先使用自然语言处理技术抽取原始输入需求中的实体以及实体关系;然后通过一个基于深度学习的多标签分类模型,预测原始输入需求的安全目标集;最后,使用实体、实体关系和安全目标集匹配到安全需求模板并将其实例化.此外,经过实验评估,本文最终确定了一个表现优秀的多标签文本分类模型,用于预测需求文本的安全目标.在本文的工作中,共使用了40个安全需求模板,这些模板都是基于CC标准构建的.本文还实现了一个辅助工具(SRE4CC)用于支撑本文方法.
在未来的工作中,在需求实体及实体关系的抽取方面,将考虑基于深度学习的方法,增加抽取结果的精度,从而可以更加精准地实例化安全需求模板;在安全需求模板的构建方面,将进一步考虑对模板的扩展,增强模板的表达能力.
