基于多元概化理论的英语口语测试任务研究
2023-12-12吴泓霖
[摘要]基于多元概化理论,对某次口语测试所包含的朗读、听后回答、回答问题、听后复述四类常见的测试任务进行研究,重点关注不同类型测试任务的区分效果、测量精度和对总分的贡献程度。研究结果表明,偏封闭型、内容导向的测试任务相比偏开放型、技能导向的测试任务,在区分效果、测量精度和对总分的贡献上表现更好。
[关键词]口语测试任务;多元概化理论;计算机化考试
[中图分类号]G424.74[文献标识码]A
[文章编号]1673—1654(2023)03—051—008
一、引言
(一)口语测试任务
口语测试是语言测试研究和实践的重要领域。根据考官的参与程度,一般可分为直接型、半直接型、间接型口语测试[1]。间接型口语测试现在已经很少使用,例如,早期的语音测试是让考生在纸笔考试中选择与对应音素发音不同的单词,不需要进行口头交流。直接型口语测试主要采用现场面试型口试的方式,由一位或多位考官对一位或多位考生进行面对面的口语测试,例如雅思(IELTS)、剑桥通用五级(Main Suite)和全国英语等级考试(PETS)各个级别的现场口试等。随着信息技术的广泛应用,目前最为主流的是半直接型口语测试,主要采用计算机化考试的实施方式。计算机化考试的研究和实践开始于20世纪70年代[2],历经多年探索,伴随着计算机技术和语言测试理论的融合发展,其应用已经日渐成熟。目前,国外知名的语言类考试大多已经推出了计算机化考试,例如托福网考(TOEFL iBT)、雅思机考(IELTS CBT)、剑桥领思(Linguaskill)等。国内的语言类考试实行计算机化考试主要集中在口试的改革中,例如大学英语四、六级口语机考,以及部分省市(北京、上海、天津、广东等)高考英语的口语机考。相关研究表明,实行口语机考对教学产生了良性的引导作用,促进了学生听、说能力的发展[3]。
设计口语测试时,设定测试任务十分重要,它不仅是测试本身构念定义的直接反映,也会对语言学习产生反拨作用。口语测试任务可以理解为说话者在特定的口语交际场景下,为了实现某种交际目标而使用语言的活动[4]。口语测试任务可以有不同的分类维度,包括技能的综合性、任务的开放性、交谈内容是事实性还是评价性、任务设计是基于构念还是基于任务、所测能力属于宏观还是微观等[5]。以计算机化口语测试为代表的半直接型口语测试中,最为常见的任务类型包括朗读、情景问答、看图说话、回答问题、听后回答问题、故事复述等,这些任务已在相关省市的高考英语口语机考中被广泛使用。
(二)多元概化理论
概化理论是现代心理测量理论之一[6],虽然出现较晚、统计要求比较繁琐,但随着计算机技术的发展,其应用范围越来越大,包括常模参照性测验、标准参照性测验、非标准化测验、表现性评价等,受重视程度日渐提升。
根据概化理论,传统意义上测量信度的概念被概化系数或可靠性系数取代[7]。概化理论重点关注分数差异与相关影响因素(例如考生能力、试题难度等)之间的关系。在经典测量理论的基础上,概化理论引进了实验设计和方差分析技术[8],可以分离各类误差的方差,并估算出不同方差成分的大小,用于探究不同因素对分数差异造成的影响和各个因素之间的交互作用,这个过程被称为概化研究或者G研究。在此基础上,概化理论还能通过实验性研究估算出不同条件下概化系数的变化,寻找最佳的误差控制方法,帮助考试设计者优化试卷设计,这个过程被称为概化理论的决策研究或D研究。
多元概化理论是概化理论的进一步发展,主要适用于具有多个全域分数等方面问题的研究,例如分析当总测验被分解成多个分测验时,分测验的信度和试题数量变化对总测验信度造成的影响[9]。近年来,多元概化理论被广泛应用于高考等大规模高利害考试的评价中,可定量比较试卷中各个内容模块和相关题型的区分度与内部一致性,为试卷质量研究提供了理论模型和方法依据,有助于考试命题质量的提高。基于多元概化理论对口语测试进行研究,可以分析各项测试任务的区分功能和测试信度,探究不同任务对总分的贡献程度,便于考试设计者调整测试设计,进而更好地达到预期的测量效果。
二、研究设计
(一)研究问题
基于定量分析回答不同类型口语测试任务的三个问题:
1.区分效果分别是什么样的?
2.测量精度分别是什么样的?
3.对总分的贡献程度分别是什么样的?
(二)研究工具
基于高考英语学科对于关键能力中口语表达的界定[10],结合常见的口语测试任务类型,设计和实施了一次研究性英语口语测试,采用了计算机化考试的形式。如表1所示,本次口语测试满分分值为10分,共11道试题,包含朗读、听后回答、回答问题、听后复述四项任务,测试过程中允许考生做笔记。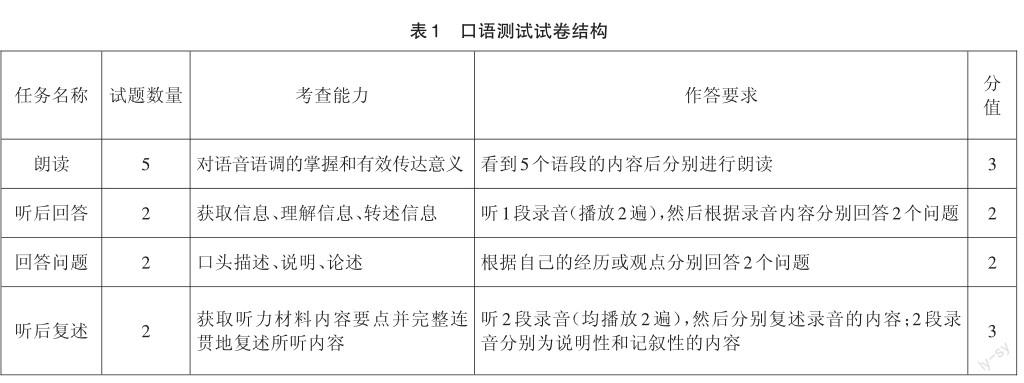
参加本次口语测试的受试者为华东某省2所中学的高二年级学生,有效样本共725份,其中男生约占45%,女生约占55%,学生的英语口语水平基本覆盖了好、中、差各个层次。
(三)评分设计

10名评分员均为来自高校的英语教师,具有大型考试的阅卷经验。正式评分开始前,评分员接受了培训,熟悉了评分标准并进行了试评分,以保证评分尺度的一致性。
(四)数据分析
采用mGENOVA 2.1程序進行多元概化分析全体有效样本共725份。按照口语测试任务的结构,将全部试题划分为“朗读”“听后回答”“回答问题”“听后复述”4个分测试,使用了4因子单面交叉设计p×i多元概化模型,p代表受试者(测量目标),i代表试题(测量侧面),分别计算各项口语测试任务和整个测试的概化系数(即信度)。在此基础上,结合相关信息分析各项口语测试任务对整个测试的贡献程度。
三、结果与讨论
(一)描述性统计
各项测试任务的平均得分率从高到低依次为回答问题(68.18%)、朗读(66.75%)、听后回答(66.18%)、听后复述(45.22%)。这表明,相比其他三项任务,听后复述的平均得分率较低,任务难度相对较大。
(二)四因子模型的G研究
基于四因子概化模型的G研究,得到考生效应(p)、试题效应(i)及考生和试题之间的交互效应(pi)在四个因子上的方差與协方差分量的估计矩阵,如表2所示。
考生效应(p)反映由于考生水平差异导致的成绩变异大小。从表2可以看出,四个因子中考生效应(p)方差分量从大到小依次为听后复述(0.32621)、朗读(0.23622)、听后回答(0.22236)、回答问题(0.09165)。这表明,在本次口语测试中,听后复述对不同水平考生的区分作用最大,朗读和听后回答的区分作用大致相当,回答问题的区分作用最小。可能导致这一现象的原因是:回答问题任务的开放性较大,考生发挥的空间也比较大,紧扣主题言之成理即可得到一定分数,因此比较难以区分不同水平的考生,而其他三项任务对考生作答的评判具有相对刚性的约束,更容易区分不同水平的考生。
此外,根据相关系数的估计值,四个因子之间的相关系数介于0.36和0.51之间,这表明考生在各项任务上的得分高低顺序有所差异。其中可能原因是四项任务分别测量了考生口语表达能力的不同方面。
试题效应(i)反映出因试题难度差异导致的成绩变异大小。从表2可以看出,听后复述的方差分量(0.06921)最大,这表明在所有任务中,听后复述任务由于试题难度差异造成的考生成绩变异最大。换言之,这项任务的不同试题难度差异最为明显。造成这个差异的可能原因在于听后复述任务中听力文本体裁对考生复述表现的影响。本次口语测试中,听后复述的两道试题分别使用了说明文和记叙文作为输入内容,且两种体裁的内容长度相当,但考生复述说明文的得分率明显低于对记叙文的复述,在一定程度上表明,对于考生来说,听取说明文并进行复述的难度大于记叙文,这与此前相关的研究结论一致[11]。
(三)四因子模型的D研究
1.各项任务全域分数的测量精度
通过D研究估计出考生在四项任务上的全域分数与相应误差项的方差分量,并计算出概化系数、可靠性指数及信噪比等指标,如表3所示。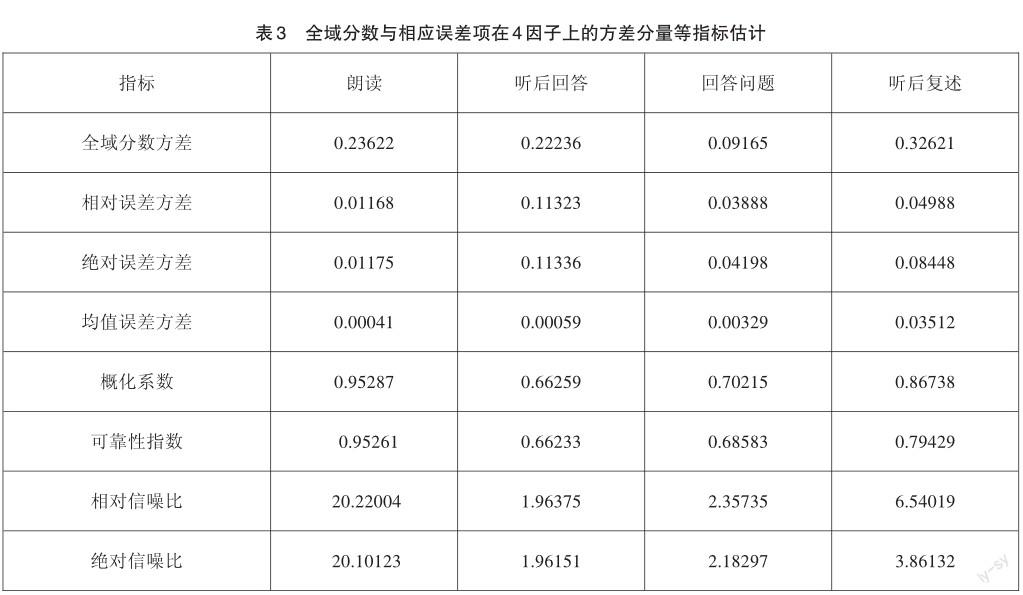
从表3可以看出,各项任务的概化系数(Gen Coefficient)均超过0.66,表明本次口语测试的试卷质量较高,各项任务具有良好的测量精度、测量误差较小。各项任务按照概化系数从高到低排序,依次为朗读(0.95287)、听后复述(0.86738)、回答问题(0.70215)、听后回答(0.66259),这表明朗读相比其他任务测量精度更高,其中可能的原因是朗读部分的试题数量多于其他任务,相当于对同一能力反复进行多次测量,因此效果更好。
2.全域总分的测量精度
根据各项任务的题目数量比例,对四个因子的全域分数进行合成,估计出全域总分与相应误差项的方差分量,以及全域总分的概化系数、可靠性指数和信噪比等指标,如表4所示。
从表4可以看出,全域总分的概化系数达到了0.93555,相对误差和绝对误差的方差分量分别仅为0.00909和0.01036,表明本次口语测试的总体测量信度较好。
3.各项任务对总分方差的贡献度
为进一步研究本次口语测试的四项任务对总分方差的实际影响程度,计算出各项任务对测试总分方差的实际贡献度,如表5所示。
从表5可以看出,各项任务对总分方差的贡献比例从高到低依次是朗读(53.52%)、听后复述(19.16%)、听后回答(17.40%)、回答问题(9.12%)。各项任务对总分方差的贡献比例与预先设定的赋分比例相比,存在一定差距。朗读任务的贡献比例高于赋分比例,听后回答任务的贡献比例大致相当于赋分比例,回答问题和听后复述任务的贡献比例低于赋分比例。其中可能的原因是:朗读任务的题量相对较大,包含了5道试题,而且考生成绩分布较为分散;而回答问题和听后复述任务都只有2道试题,且考生成绩分布相对集中。这表明,可以考虑进一步提高朗读任务的赋分比例,或者增加回答问题和听后复述任务的试题数量,以进一步提升考试的信度和区分效果。
4.各项任务题目数量对测量精度的影响研究
通过D研究计算出各项任务题目数量变化对口语测试整体测量信度的影响情况,结果如表6所示。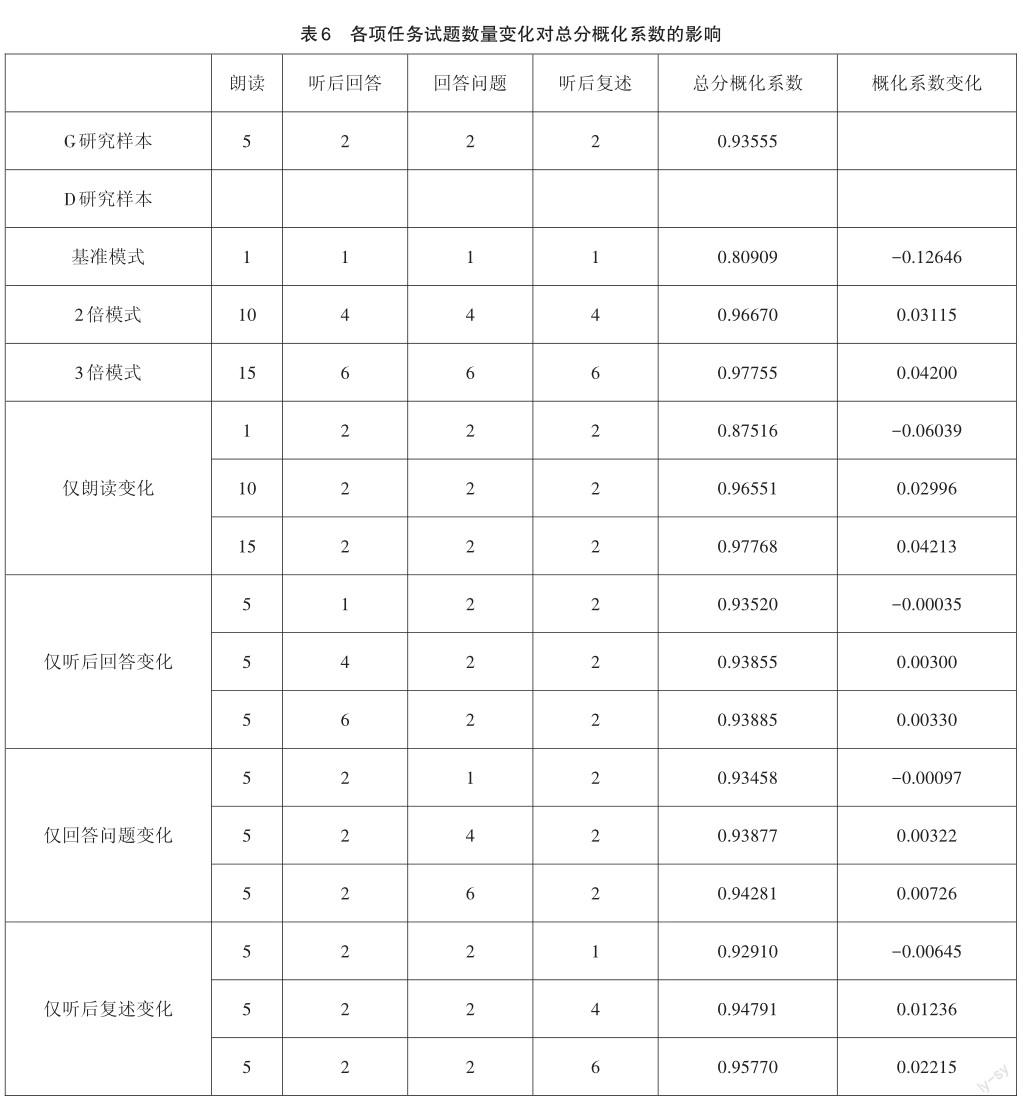
由表6可知,当各项任务的试题数量增加为2倍和3倍时,总分概化系数分别增加至0.9667和0.97755。此外,单独增加某一项任务的试题数量,也可以提高总分概化系数,其中对提升整卷信度作用比较大的是增加朗读和听后复述的题目数量。
四、结论与启示
(一)研究结论
采用四因子多元概化模型,对同一口语测试中的不同任务进行了分析,得到以下结论:
在测量信度方面,本次口语测试的全域总分概化系数为0.93555,总体测量信度高,达到了预期的测量目的。具体到任务上,朗读的概化系数最高,听后回答的概化系数最低。四项任务分别测量了考生不同方面的口语表达能力,这与考试的构念设计是一致的。
在区分效果方面,听后复述和朗读对不同水平考生的区分效果较好,而听后复述由于不同试题难度差异对考生成绩造成的影响最为明显。这表明,需要注意听后复述任务的难度控制,尤其是关注不同听力体裁对任务难度的影响。
对总分的贡献程度方面,朗读对总分变异的贡献最大且远高于其他三项任务,而回答问题的贡献最小。此外,朗读对总分方差的贡献比例高于其赋分比例,而回答问题和听后复述对总分方差的贡献比例低于各自的赋分比例。这表明,应该适当增加朗读部分的分值,或者增加回答问题和听后复述部分的试题数量。
试题数量变化对总分概化系数的影响方面,同时增加各项任务的题目数量可以提升总分概化系数,而单独增加朗讀或听后复述的题目数量对总分概化系数的提升效果最为明显。
(二)研究启示
基于上述结论,在口语测试任务设计方面可得到如下启示。
Wright提出,根据交际潜质(communicative potential)不同,口语测试任务可以按照两个维度进行分类:任务类型和导向[12]。在任务类型的维度上,口语测试任务从开放到封闭进行排列:开放性任务对考生作答不作限制,有多种可以接受的答案;封闭性任务则会对考生的作答进行限制,超出范围的答案是不可接受的。在导向的维度上,口语测试任务从技能导向到内容导向进行排列:技能导向任务一般考查口语能力本身,答案往往比较开放;内容导向任务则将口语能力与具体的内容融合起来进行考查,答案的可控程度一般较高。
基于该分类依据,本次口语测试的四项任务中,朗读、听后复述、听后回答属于偏封闭型和内容导向的任务类型,回答问题属于偏开放型和技能导向的任务类型。本次研究的结果表明,整体而言,偏封闭型、内容导向的测试任务比偏开放型、技能导向的测试任务在区分效果、测量精度和对总分的贡献上表现更好。
从考试命题的角度,内容导向的口语测试任务有助于减少考生“押题”和“背模板”等应试现象。从考试评分的角度,封闭型的口语测试任务因为作答内容可控,有利于评卷人员把握评分标准、控制评分误差,最终保障评分质量。从考试组织实施的角度,随着人力成本的增加,大规模考试的评分工作和评卷人员的聘请日益成为考试组织机构面临的一大挑战。为了解决这个问题,一些大规模考试纷纷进行了机器自动评分的探索和应用[13]。相关研究表明,封闭型和半封闭型的口语测试任务机器评分与人工评分的一致性明显高于开放型任务[14]。因此,在口语测试中采用相对封闭型的任务,有助于自动评分的应用、减少人工评分的组织成本。
本研究的主要不足在于考生样本量偏少且仅限于高二年级学生,口语测试任务类型偏少。在今后类似的研究中,可考虑增加样本数量和范围,进一步丰富任务类型,基于更具代表性的受试者群体和更多样的任务类型,进而对口语测试任务的特点进行更为全面的研究。
参考文献:
[1] OLoighlin K. The Equivalence Of Direct And Semi-Direct Speaking Tests [M]. Cambridge University Press,2001:4.
[2]曾用强.对计算机化考试的几点思考[J].外语电化教学,2010,(01):52-55.
[3]侯艳萍.外语高考听说测试改革的反拨作用研究[J].外语电化教学,2018,(05):23-29.
[4] Luoma,S. Assessing Speaking [M]. Cambridge University Press,2004:31.
[5]李梦莉,范琳.机助口试理论模型、任务特征和评分标准研究——新托福网络口试和PhonePass~(TM)SET口试对比分析[J].中国考试,2013,(08):22-27.
[6]刘远我,张厚粲.概化理论在作文评分中的应用研究[J].心理学报,1998,(02):211-218.
[7]罗照盛,郭小军.认知行为实验研究中最佳素材容量的选择与确定:多元概化理论应用[J].心理学报,2014,46(06):876-884.
[8]杨志明,张雷.测评的概化理论及其应用[M].北京:教育科学出版社,2003:18-20.
[9]赵轩,任子朝,陈昂.基于多元概化理论的高考数学文理科试卷质量分析与对比研究[J].数学通报,2018,57(01):25-30.
[10]陈康,吴泓霖,李新煜,等.基于高考评价体系的英语科考试内容改革实施路径[J].中国考试,2019,(12):33-37.
[11]柳明明.高考英语听后口头复述任务效度论证研究[D].北京外国语大学,2015:114-115.
[12] Wright,T. Instructional Task And Discoursal Outcome In The L2 Classroom [J]. Lancaster Practical Papers in English Language Education,1987,(07):49.
[13]金艳,王伟,杨浩然.语言测试中的技术应用:基于大学英语四、六级考试的实践分析[J].外语测试与教学,2021,(01):1-7+27.
[14]孙海洋.国内外英语口语自动评分研究综述[J].外语教育研究前沿,2021,4(02):28-36+89-90.
Research on English Speaking Test Tasks Based on Multivariate Generalizability Theory
Wu Honglin
National Education Examinations Authority,Beijing,100084
Abstract:Speaking test tasks,which can be seen as activities that involve a speaker in using language for the purpose of achieving a particular communicative goal in a particular speaking situation,are important parts of the design of a speaking test. Based on Multivariate Generalizability Theory,this study analyzes four common tasks such as reading-aloud,listening-and-answering,answering questions and listening-and-retelling focusing on the effect of differentiation,precision of measurement and contribution to the composite score regarding different tasks. The result of the study shows that in general closed and content-oriented speaking test tasks perform better than open and skill-oriented ones do in terms of the effect of differentiation,precision of measurement and contribution to the composite score.
Key words:Speaking Test Tasks,Multivariate Generalizability Theory,Computer-based Testing
(责任编辑:吴茳)
