档案数据挖掘的应用设计原则与应用实践研究
2023-12-11庄宏武
摘 要:如何发挥档案的价值,始终是档案管理工作的重要问题。随着人工智能、大数据、云计算等信息技术的发展,数据挖掘技术进入人们的视野,成为档案管理工作的研究热点。本文对这一现象进行研究后,发现受一些客观因素影响,数据挖掘技术在档案管理工作中应用的并不普遍,还存在一些困惑和疑虑。作者以实际应用为例,围绕档案挖掘技术在档案领域中应用的热点问题进行了研究,提出了一些设计建议,希望能给档案同人提供一些参考。
关键词:档案管理;数据挖掘;应用价值
数据挖掘技术是机器学习和数据库管理的交叉,在数据库管理技术的支撑下从数据库中提取大量数据,通过机器学习技术进行分析,从而挖掘潜在有价值的信息。在档案管理工作中应用数据挖掘技术,已经有很多成功的例子,但受一些客观因素影响,数据挖掘技术在档案管理工作中应用得并不普遍,而且一些部门在应用档案数据挖掘技术时还产生了一些困惑和疑虑,档案数据挖掘技术本身也还在进一步发展之中[1]。
1 档案数据挖掘的应用设计原则
1.1 需求导向原则
档案数据挖掘应以用户的需求为导向,立足于满足与档案管理活动相关人员的普遍需求,同时还应将未来可能出现的状况考虑进去,做到对问题的及时应对[2]。档案数据挖掘主要以电子文件为对象。一旦进入无纸化时代,整个社会的信息流将加快,单位时间内产生的电子文件将急剧增加,会直接加大档案管理压力,给档案管理系统的稳定性带来了挑战,对整个工作流程的可持续性产生影响[3]。由于档案管理从档案的收集、整理、著录、保管、鉴定到利用都是有秩序的流程,任何一个环节的出错,都可能导致后续档案工作无法开展[4]。因此,在档案数据挖掘设计时,必须要将各个环节人员的需求都考虑进去,保证管理的有条不紊。
1.2 数据前提原则
数据挖掘虽然在一定程度上能够解决异构数据所带来的问题,但并不代表数据挖掘对数据没有任何要求。数据前提原则在档案数据挖掘上具体表现为以下几点:①数据量满足数据挖掘的要求,具体的最小数据量并没有在相关文献中提到,根据scikit-learn(Python平台的一个数据挖掘开源库)开发组的建议,数据挖掘的最小数据量为50,显然数据量越大,最后的结果越令人信服[5]。②保证所用数据的质量,即数据能够反映自身的信息,这一点在档案数据挖掘上尤为重要。由于档案管理的相关要求,很多机构都会对纸质档案进行数字化,但数字化产生的文档不能用于数据挖掘,因为数据挖掘所用的是文档中的文本数据,而数字化文档经过OCR后并不能完美还原最初的文本数据,经常出现乱码、错别字等情况,因此档案数据挖掘所用的数据必须来自含有正确数据的电子文件[6]。③数据间应有一定的特征差别,不能具有同一性,诸如基建档案中的图纸类数据等不符合这一要求[7]。由于基建图纸类数据是通过建筑设计软件产生的专业领域数据,所有图纸几乎都是由线条构成,在颜色、轮廓等方面都没有明显的区分,特征非常不明显,因此这类数据应该排除出档案数据挖掘范围[8]。
1.3 成本效益原则
档案数据挖掘系统的开发与大部分信息系统一样,需要投入大量的人力、物力,需要充足的资金来维持[9]。然而,无论是政府机构还是企业内部,档案部门一直处于边缘地位,可供规划使用的资金不是很多。因此,在档案数据挖掘上的投入应量力而行,在满足多数人需求的情况,尽量降低研发所用的资金[10]。同时,资金的支持与其产生的效益相关,如若一个项目不能产生明显的效益,那么对于整个机构来说,这就是一个失败的项目,对于资金的申请自然不能成功。因此,在档案数据挖掘的研发上应更偏向档案利用的目的,高效地利用过去所产生的所有文件,在文化产品、辅助决策等方面都可以发挥档案应有的作用,如对于企业内部的档案,通过数据挖掘可归纳出企业近几年的发展状况和规划,结合企业实际的运营情况可适当做出有利于企业发展的建议,发挥辅助决策的作用[11]。
1.4 档案保护原则
数据挖掘的数据来源是档案,但并不意味着要使用原始数据。对于档案来说,原始数据有且只有一份,即使是拷贝后的电子文件,从数据的性质来说,该数据也不是原来的数据[12]。在档案数据挖掘过程中,可能会给档案数据带来不可逆的后果,一旦档案数据遭到损坏,意味着整个档案管理的流程将重新进行[13]。从档案数据挖掘的效率来考虑,数据出现损坏的情况必须降至最低,挖掘使用的数据应来源于原始数据的拷贝,同时也要对使用的拷贝数据进行备份,降低过程中产生的数据风险[14]。
2 档案数据挖掘技术应用实践案例分析
随着信息化建设的不断深入,档案部门产生海量数据,档案数据量已形成一定规模。基于满足社会公众对档案信息深层次需求和利用的多样化的考虑,有的档案部门拟开发建设“民生档案智慧分析挖掘应用平台”项目,该平台将以民生档案为主体的大数据为主要对象,实现对档案信息的数据挖掘和综合管理、分析、研究[15]。
2.1 系统架构
民生档案智慧分析挖掘平台主要从开放性、跨平台、技术成熟的角度考虑,在开发架构上采用B/S模式的三层或多层架构,以J2EE技术体系结构和MVC开发模式为支撑,数据库则使用Oracle,没有使用非关系型数据库,同时使用Weblogic、Websphere、东方通等中间件。除此之外,系统基于XML的数据交换接口,支持上下级之间的数据交换[16]。
2.2 数据管理
民生檔案智慧分析挖掘平台可接收和管理各种结构化和非结构化数据,如ODBC数据源数据目录接收导入,以及支持接收PDF、DOC、WPS、RTF、WAV、MP3、MPEG、ASF、WMV等格式电子文件,所有文本类和图像类电子文件要求通过“档案数据标准化转换工具”转换为PDF格式,对于所有音频、视频类的电子文件转换为FLV格式,有关两种格式作为系统统一规范利用格式。整个应用系统应实现对海量的结构化与非结构化数据的组织、管理、应用、组织,解决馆藏资源管理系统与网上接收、发布各子系统之间接口问题和数据交换问题,实现资源共享[17]。
2.3 功能设计
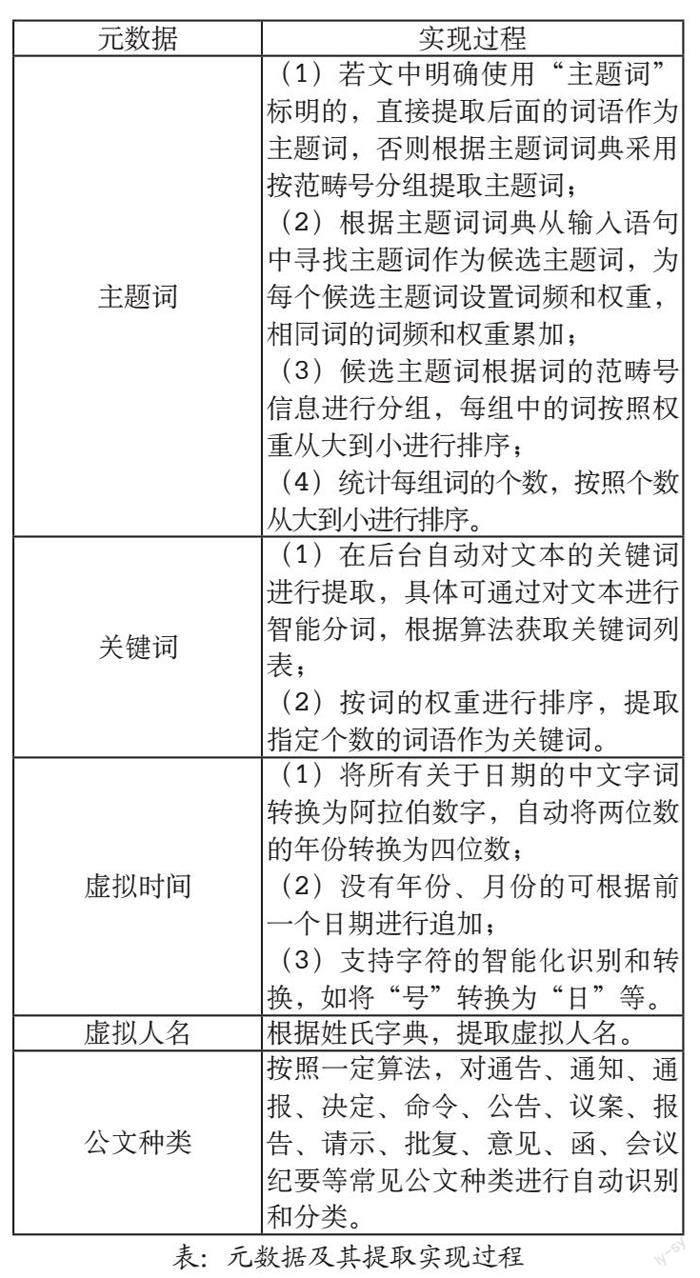
民生档案智慧分析挖掘平台的后台数据挖掘功能包括文本自动分类、数据抽取、数据建模等几大功能。在文本自动分类方面,系统通过贝叶斯网络和支持向量机等算法对文本进行分类,并支持基于语料的自动分类(通过训练语料,系统实现全自动分类)、基于规则的自动分类(规则分类是按照人工预先定义的规则文件,为文档集合中的每个文档确定一个类别,支持对文本的预处理功能、词频统计、权重、相似度计算等)和混合分类(提供基于语料、规则的双重自动分类方式,支持用户可按照《中国档案分类法》对分类规则进行自定义,从而实现档案的自动分类)[18]。在数据抽取方面,系统提供元数据等数据的智能化自动抽取功能,所涉及元数据的抽取实现如下表所示,共包括主题词、关键词、虚拟时间、虚拟人名、公文种类等几类。在数据建模方面,民生档案智慧分析挖掘平台通过文本分析挖掘技术,结合档案局的实际业务管理需要,建立相关数据模型,实现馆内业务的智能化、自动化处理,所涉及的业务包括档案接收、档案分类、档案保管、档案等级划控、档案利用等。档案的具体内容以社保类民生档案为主,目的是了解参保群体的背景、参保对象的信息和数据资源共享[19]。通过数据挖掘,一方面加深不同参保群体的了解,更好地服务参保对象,提高社会保障服务水平,另一方面为规范社会保障数据收集和整理工作提出了客观要求,整合了多个数据库平台资源,达到资源的充分利用,有利于节约劳动力成本。
元数据 实现过程
主题词 (1)若文中明确使用“主题词”标明的,直接提取后面的词语作为主题词,否则根据主题词词典采用按范畴号分组提取主题词;
(2)根据主题词词典从输入语句中寻找主题词作为候选主题词,为每个候选主题词设置词频和权重,相同词的词频和权重累加;
(3)候选主题词根据词的范畴号信息进行分组,每组中的词按照权重从大到小进行排序;
(4)统计每组词的个数,按照个数从大到小进行排序。
关键词 (1)在后台自动对文本的关键词进行提取,具体可通过对文本进行智能分词,根据算法获取关键词列表;
(2)按词的权重进行排序,提取指定个数的词语作为关键词。
虚拟时间 (1)将所有关于日期的中文字词转换为阿拉伯数字,自动将两位数的年份转换为四位数;
(2)没有年份、月份的可根据前一个日期进行追加;
(3)支持字符的智能化识别和转换,如将“号”转换为“日”等。
虚拟人名 根据姓氏字典,提取虚拟人名。
公文种类 按照一定算法,对通告、通知、通报、决定、命令、公告、议案、报告、请示、批复、意见、函、会议纪要等常见公文种类进行自动识别和分类。
结语
综上所述,档案管理部门应用数据挖掘技术并不普遍。很多档案管理人员对于档案管理部门应用数据挖掘技术存在一些困惑和疑虑,甚至有一些档案管理工作人员还不愿意运用这一技术。随着人工智能、大数据、云计算等计算机信息技术的发展,越来越多的档案管理工作人员开始思考如何利用先进的计算机信息网络技术进一步发挥档案的价值,怎么才能从浩如烟海的档案原始资料中,找到有利用价值的档案,更快更好地挖掘出档案蕴含的巨大价值。随着研究的深入,数据挖掘技术最终走进了人们的视野,成为档案管理工作人员研究如何更好地发挥档案价值的研究热点。数据挖掘技术是机器学习和数据库管理的交叉,在数据库管理技术的支撑下从数据库中提取大量数据,通过机器学习技术进行分析,从而挖掘潜在有价值的信息[20]。
参考文献
[1]孙鹏飞.数据挖掘技术在软件工程中的应用探究[J].现代工业经济和信息化,2022,12(03):136-138.DOI:10.16525/j.cnki.14-1362/n.2022.03.050.
[2]廖嘉炜,严俊斌,宋强,赵小凡,徐炫东.主数据驱动视角下多源数据数字化挖掘系统设计[J].电子设计工程,2022,30(03):63-66.DOI:10.14022/j.issn1674-6236.2022.03.014.
[3]姚翠艳.数据挖掘技术在档案管理系统中的应用[J].黑龙江档案,2021(04):172-173.
[4]谢元瑰,李仕祺.基于数据挖掘的人事档案信息化管理方法[J].信息与电脑(理论版),2021,33(10):9-11.
[5]鄢明芳,郑川.档案数据挖掘的应用实例分析[J].山西档案,2021(03):132-142+131.
[6]蔡静颖.计算机数据挖掘技术的开发与应用[J].电子技术与软件工程,2021(05):190-192.
[7]潘翠芬.基于数据挖掘技术的数字档案管理信息系统的设计与实现[J].城建档案,2020(04):25-26.
[8]陈春谋.大数据环境下的档案管理系统信息检索及挖掘技术分析[J].电子测试,2019(14):92-94.DOI:10.16520/j.cnki.1000-8519.2019.14.035.
[9]蒋红健.大数据挖掘管理与技术策略在高校档案馆中的应用研究[J].山西档案,2019(01):61-66.
[10]廖淑莉.构建科技档案云平台支撑科技创新驱动——以粤西高校科技档案云平台关键技术研究为例[J].档案时空,2016(02):16-18.
[11]汪楠,张浩.数据挖掘在档案信息管理中的探讨[J].景德镇学院学报,2015,30(03):52-55.
[12]李瑞敏.计算机网络在社保工作系统中的应用[J].山东工业技术,2014(20):147-148.DOI:10.16640/j.cnki.37-1222/t.2014.20.241.
[13]段凤,王小芳.数据挖掘在科研档案管理中的应用研究[J].兰台世界,2012(35):100-101.DOI:10.16565/j.cnki.1006-7744.2012.35.093.
[14]张卫东,左娜,陆璐.数字时代的档案资源整合:路径与方法[J].档案学通讯,2018(05):46-50.DOI:10.16113/j.cnki.daxtx.2018.05.010.
[15]张伟.高校档案管理中融入数据挖掘的实践研究[J].吕梁教育学院学报,2017,34(03):75-76.
[16]哈立原.基于数据挖掘技术的高校图书馆档案信息管理平台构建[J].山西档案,2016(05):105-107.
[17]孫越.数据挖掘技术在保险公司内部审计中的应用[J].现代商业,2019(18):59-60.DOI:10.14097/j.cnki.5392/2019.18.028.
[18]姚翠艳.数据挖掘技术在档案管理系统中的应用[J].黑龙江档案,2021(04):172-173.
[19]陈雪燕,于英香.从档案管理走向档案数据管理:大数据时代下的档案管理范式转型[J].山西档案,2019(05):24-32.
[20]王平,安亚翔.大数据时代的档案信息平台建设[J].档案与建设,2015,(10):8-13.
作者简介:庄宏武,本科学历,任职于通榆县档案馆。
