面向客服领域智能派单调度场景的算法研究与应用
2023-12-10肖军陈震原
[肖军 陈震原]
1 引言
在运营商服务客户的过程中,有许多来自客户的需求会最终形成各类工单,再由专业的服务人员进行施工或者受理,有些是客户对业务的咨询和投诉,有些是客户购买宽带服务后的施工或维护业务。在更为广泛的客户服务业,无论是电力、银行、煤气还是政务,都有着各式各样的服务型工单,例如在12345 政务服务热线,每天都有群众来电或留言,形成各种业务工单。这些工单由于需求内容不同,客户标签不同,需要由不同的单位,不同的个体来提供服务。让合适的人来服务是确保服务满意度的第一步。否则,由于派错了人,由于不专业,带来客户的二次服务会大大降低客户的服务满意度。因此派单准确率是确保服务满意度的第一道关。
在传统的派单流程中,客服人员接到客户的需求后,一般都是由人工来判断、审核、分析后再做出决策,将这个工单流转到下一个处理环节。由于人工操作,需要投入大量的人员进行调度安排,这也会逐年增加企业服务的开支。另外,有些业务例如政务热线服务需要掌握的调度规则非常复杂,处理的去向单位非常多,有时候会超出座席人员的学习和处理能力,这也会导致座席人员的学习成本非常高,最终也会导致派单准确率和效率降低,客服满意度下降。
在大数据技术和AI 赋能的数字化改革浪潮中,如何用AI 技术形成智能派单,建立派单模型,人工辅助AI 训练,逐步替代人开展工单的智能调度,将是客服领域派单调度场景的未来趋势。这需要我们根据大量的历史数据,找出关键特征项,利用有效的决策树和随机森林等算法,再结合各种场景实际的规则,综合实现智能派单和智能调度功能。
2 智能派单调度涉及到的主要技术和算法介绍
在派单调度场景中,有一些是可以基于规则进行派单的,只要根据工单中出现的特定关键词组合,或者一些条件参数计算后符合某些业务规则,就可以精准派送到相关的处理人员或单位。这种情况可以基于场景进行规则梳理,建立和开发规则引擎,就可以实现派单的自动化了。当然,实际工作中还有一些工单就比较模糊了,往往依赖人的判断,去分析工单以及基于该工单关联的其它系统提供的更多特征项进行判断分析,再决定派往何处。那这个思考的过程就比较个性化了。这种情况我们就需要针对历史数据进行建模训练。这类算法在智能派单应用中会更好地拟合真实场景,弥补规则引擎的不足。
2.1 规则引擎
2.1.1 什么是规则引擎
顾名思义,规则引擎[1]是针对业务规则的一个管理系统,实际生产实践中,由于各种场景对应的业务规则很复杂,如果程序定制开发,那么代码复杂度太高,不便于阅读,也不便于管理和修改。因此,从业务和开发的角度来看,都需要建立一个业务和规则管理系统代码隔离的机制[2],这就是规则引擎引入的原因,规则引擎原理结构如图1所示。

图1 规则引擎
2.1.2 如何建立规则引擎
如何建规则引擎[3]有许多不同的方法。一般来说,步骤如下:
(1)设计规则。这一步包括定义规则的格式、语法和结构。
(2)定义数据模型。规则引擎需要知道你的数据模型是什么样的,才能够处理数据。
(3)编写规则代码。
(4)编写测试用例。为了确保规则引擎正常工作,需要编写测试用例来测试它。
(5)运行规则引擎。使用测试用例运行规则引擎,并根据测试结果调整规则代码。
2.2 决策树和随机森林
2.2.1 什么是决策树
决策树(Decision Tree)[4]是在已知各种情况发生概率的基础上,通过构成决策树来寻找最终最优决策的一种预测模型[5],一般决策树是if-else 逻辑。
2.2.2 如何构建决策树
决策树的构建包括两个关键部分:样本和特征[6]。
样本:对于给定的总体训练集T,T 中包含N 个样本。在构建决策树时,我们使用有放回地随机选择N 个样本进行训练。
特征:假设训练集中的特征总数为d,在构建决策树的过程中,每次仅从中选择k 个特征(其中k<d)。
决策树的构建过程:
第一步:从总体训练集T 中随机选择N 个样本,作为决策树的根节点[7]。
第二步:对于每个需要分裂的节点,在节点的M 个属性中随机选择m 个属性(满足条件m<<M)。然后,使用某种策略(例如信息增益)从这m 个属性中选择最佳属性,作为该节点的分裂属性[8]。
第三步:重复进行步骤2,直到无法再进行分裂为止。在整个决策树的构建过程中,没有进行剪枝[9]操作。
2.2.3 随机森林
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,从而构成了随机森林[10],如图2 所示。

图2 随机森林算法
3 实践:在电信运营商客服派单场景实现智能派单
基于以上技术,以下以广州电信客服部智能派单功能为实践应用案例:
3.1 智能派单功能需求的背景介绍
在客户通过10000 号或其它渠道投诉到电信后,有些复杂的投诉问题需要本地网去解决,第一步就涉及到投诉工单的派单问题,因为涉及到的投诉工单业务比较复杂,有些是资费问题,有些是一线营销人员营销解释口径问题,有些属于创新业务问题,那么就涉及到这些工单该如何派发到对应的人去解决。在投诉处理高质量服务的要求下,各地运营商都需要降低重复投诉率,对重要客户提供更高等级的客户服务。这就要求对原有的派单提出了新的要求,让专家来处理高等级客户和重复投诉客户,降低客户越级投诉风险,让合适的人做合适的事,智能派单的功能需求就至关重要。资源调度的合理性也决定了整体客户服务质量的起点。
在传统的派单场景下,以广州电信为例,座席人员平均5 分钟可以处理一次派单任务,座席人员需要根据来单的基本信息,以及客户留言信息,再查询电信CRM、BSS等各类业务支撑系统,全面分析后再做出派单去向。针对每天数千工单任务,需要大量派单人员人工决策并派单,效率低,耗费人工较多,因此,建立基于规则和AI 算法的智能派单是客户投诉处理服务的一个基础场景功能。
3.2 智能派单功能技术路线
3.2.1 技术路线
我们将工单按难易情况、重要情况、敏感情况等考虑因素将工单分成了危险度、重复度、星级度、难易度、敏感度五个维度,每个维度设置其权值[11],如图3 所示。同时将处理坐席按能力因素分成了专家座席、高时效座席、中时效座席、低时效座席及新人座席,每个座席维度设置其权值,如图4 所示。再对实时生产因素,例如:座席当天出勤情况、当天工单超时情况及工单二次释放情况等多个因素进行多重计算决策[12],应用相应制定的溢出法则、爆单法则等异常法则[13]对非正常进行决策,从而构建出智能派单规则引擎,如图5 所示。
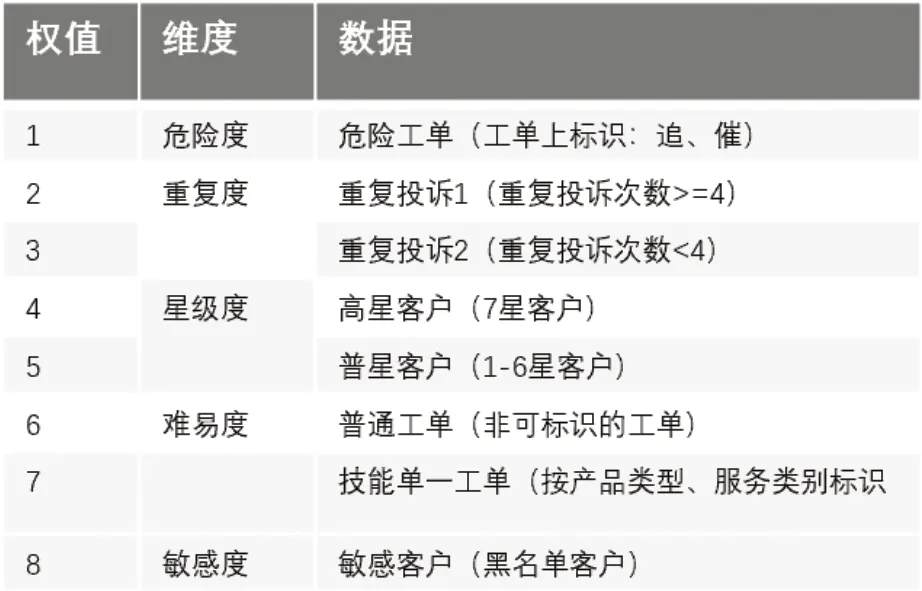
图3 工单数据集

图4 座席数据集
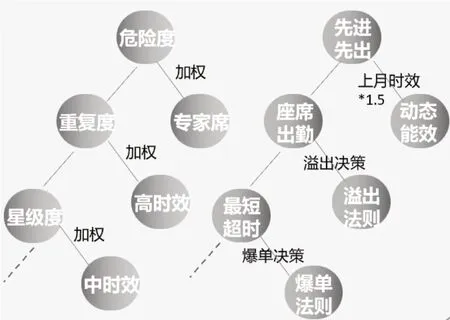
图5 规则引擎派单原理
我们将工单的危险度、重复度、星级度、难易度、敏感度五个维度组成工单数据集,将处理坐席专家座席、高时效座席、中时效座席、低时效座席及新人座席组成座席数据集,及将生产实时因素,例如:座席当天出勤情况、当天工单超时情况等组成生产数据集[14]。将工单数据集、座席数据集及生产数据集输入到决策树与随机森林算法架构中,经过决策森林的计算,从而得出理想的派单路径,智能派单的功能技术路线如图6 所示。
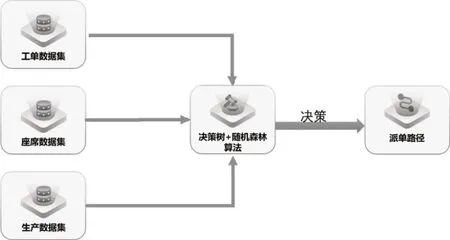
图6 技术路线
3.2.2 模型构建
本文所研究的客服智能派单模型基于随机森林算法来构建,是因为随机森林算法模型一种集成算法(Ensemble Learning),它通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。而其可以取得不错成绩,主要归功于“随机”和“森林”,一个使它具有抗过拟合能力,一个使它更加精准。
(1)数据集:我们通过全量提取最近半年人工派单历史记录共558 720 宗,作为原始数据集。
(2)生成训练样本:在原始数据集上通过有放回抽样重新选出30 个新数据集来训练分类器,每组训练样本数量为18 624 宗。
(3)分类器构建[15]:我们所构建的模型中分类器使用的是CART 树,CART 树又称分类回归树。当数据集的因变量为连续性数值时,该树算法就是一个回归树,可以用叶节点观察的均值作为预测值;当数据集的因变量为离散型数值时,该树算法就是一个分类树,可以很好的解决分类问题。
(4)特征选择[16]:我们对工单数据信息、座席数据信息及生产数据信息使用基尼系数进行特征选择。基尼系数的选择的标准就是每个子节点达到最高的纯度,即落在子节点中的所有观察都属于同一个分类,此时基尼系数最小,纯度最高,不确定度最小。结合我们所使用的CART树分类器,特征选择基尼系数公式如下:
(5)最终模型使用训练出来的分类器的集合来对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签。我们所构建的模型结构如图7 所示。

图7 模型结构
我们所构建的模型具有抗过拟合的特点,可以有效降低bias,并能够降低variance。首先,每个树选取使用的特征时,都是从全部m 个特征中随机产生的,本身已经降低了过拟合的风险和趋势。模型不会被特定的特征值或者特征组合所决定,随机性的增加,将控制模型的拟合能力不会无限提高。其次,与决策树不同,模型对决策树的建立做了改进,对于普通的决策树,我们会在节点上所有的m 个样本特征中选择一个最优的特征来做决策树的左右子树划分。但是模型的每个树,其实选用的特征是一部分,在这些少量特征中,选择一个最优的特征来做决策树的左右子树划分,将随机性的效果扩大,进一步增强了模型的泛化能力。
3.2.3 模型实现
本文所研究的客服智能派单模型在代码实现过程中我们基于sklearn 的python 机器学习代码框架来实现,关键代码如下所示。
基中关键参数说明如下:
n_estimators=100,随机森林中决策树的数量,取值为100;
criterion='gini',纯度衡量指标,取值为基尼系数;
bootstrap=True,控制抽样技术的参数,取值为True。采用有放回的随机抽样数据来形成训练数据;
oob_score=True,是否采用袋外样本来评估模型的好坏,True 代表是,袋外样本误差是测试数据集误差的无偏估计;
n_jobs=5,并行任务数,取值为5,这个在集成算法中非常重要,可以并行从而提高性能;
random_state=10,随机率,控制生成随机森林的模式,随机性越大,模型效果越好,我们取值为10;
warm_start=False,热启动,取值为False,不使用上次调用该类的结果。
4 实践成果总结和未来展望
4.1 成果总结
经过半年的实践和模型训练,从实践结果来看,自从广州电信客服部智能派单功能上线以来,机器人自动派单到座席日均约3 000 单,自动派单率达92.56%,12 位派单工作人员减少到3 位,大幅度节约了人工成本。剩下的三位主要是由监督地训练模型,使得智能派单模型准确率更高。而且由于工单与座席的能力相匹配而派单,座席绩效也得到了提升,实现了合适的人做合适工单,能者多劳,多劳多得,让客服生产更公平、更高效。实际广州电信客服部智能派单界面如图8 所示。
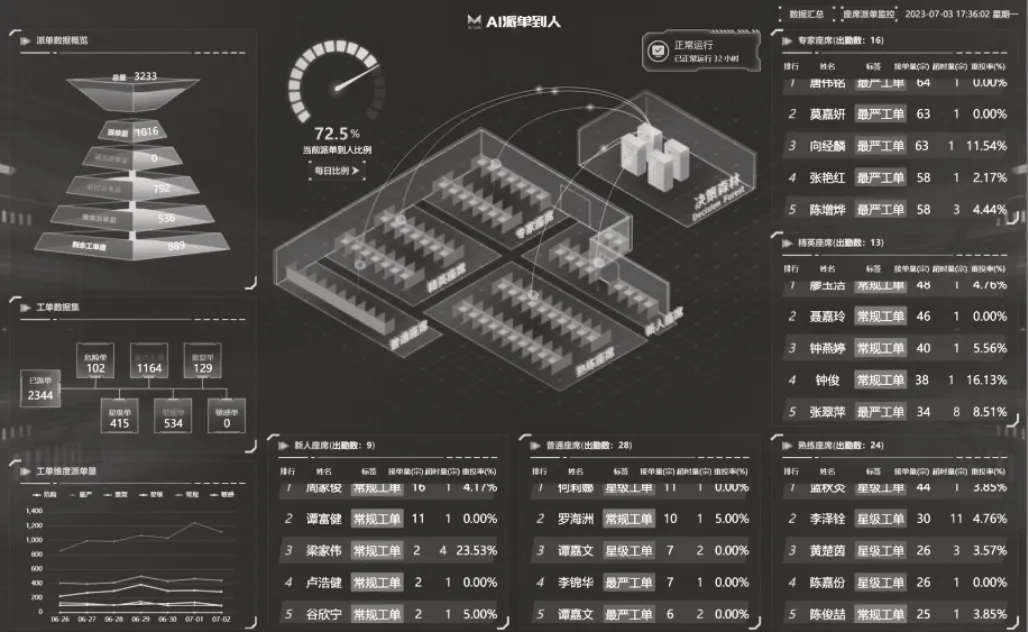
图8 广州电信客服部智能座席看板
4.2 未来展望
智能派单在广州电信客服领域的成功应用,可以推广到电信需要派单场景的各个领域,例如在电信装维场景,可以根据装维师傅的地址定位、网格划分、自身能力信息等再结合客户装和维的需求信息、客户的星级、客户的投诉信息、以及客户的地址信息等进行匹配,利用规则引擎和决策树随机森林算法给出更为合理的智能调度引擎。一方面可以大量节约装维辅助调度支撑人员,另一方面也可以大幅度提高装维响应效率,提升客户服务感知。
站在更为广义的角度分析,智能派单可以应用在各种涉及到任务单派发的场景中,基于规则引擎和决策树随机森林算法的智能调度和派单,是企业数字化转型的重要一环。从源头上开始业务流程的数字化,可以确保工作任务的公开、公平、公正,更可以提高企业运营效率。
