改进条件对抗网络在小样本故障诊断中的研究
2023-12-07谢由生张军
谢由生,张军
(安徽理工大学 人工智能学院,安徽淮南 232001)
在现代生产中,高效的智能设备故障诊断方法可以减少人力和物力的投入。因此,对智能设备的故障诊断需求正在快速的增长[1]。近年来,随着机器学习的发展,大量学者将机器学习算法应用在智能设备的故障诊断中。文献[2]提出一种处理多通道信息的加权卷积神经网络用于齿轮箱故障特征提取;文献[3]采用改进的解卷积算法识别轴承的复合故障;文献[4]提出了一种基于Lenet-5 的新卷积神经网络(Convolutional neural networks CNN),用于故障诊断;文献[5]提出了一种具有压缩感应(CS)的改进卷积深信念网络(CDBN)的新型方法,用于滚动轴承的特征学习和故障诊断;文献[6]提出了一种基于混合注意力改进残差网络(HA-Res-Net)的方法来诊断风力涡轮机齿轮箱的故障。但是这些方法前提是有一个样本充足且平衡的数据集。然而,在实际生产活动中,很难采集到足够的故障样本。在训练样本不足的情况下,基于人工智能算法的故障诊断性能可能会很差。为提高小样本故障检测的性能,通常的方法是对样本进行数据增强。
Goodfellow 等在 2014 年提出的生成式对抗网络(GAN)[7]能够模拟数据的分布,在图像生成方面有显著的能力。因此,生成对抗网络被引入故障诊断领域解决机械设备故障数据样本少,数据不平衡等问题。如文献[8]提出了一种结合条件生成网络(CGAN)和深度卷积生成网络(DCGAN)的模型,有效的处理了故障数据不平衡问题,提高了故障诊断的准确率和泛化能力;文献[9]提出了一种基于辅助分类器生成对抗网络(ACGAN)的模型,在小样本故障数据集中取得了很好的效果。虽然上述提出的模型在生成故障样本方面有一定的参考意义,但是这些方法都是基于一维信号,不能充分发挥 GAN 在图像生成上的能力。
本文提出了一种基于条件生成网络的改进模型(CGAN-GP)。将原始的一维信号转换为二维灰度图,通过对二维灰度图进行数据增强,增加故障样本的数量,并且使用梯度惩罚策略来优化模型的训练和生成图像的质量,最后利用轴承数据对上述模型进行对比,分析模型的效果。
1 GAN、CGAN
生成对抗网络(GAN)是 Goodfellow 等在 2014年提出的一种基于博弈论的深度学习模型。该模型框架中包含两个模块:生成模型(Generative model,G)和判别模型(Discriminative model,D)。两个模型相互博弈,不断优化自身的能力,最终达到纳什均衡状态,在这种状态下任何一方无论怎么优化都不能改善模型的能力。GAN 模型结构如图1a)所示,生成模型 G 构成的映射函数G(z,θg)将噪声z,从原始分布Pz映射到与真实样本x的分布Pdata相似的分布Pg中。判别模型需要判断输入样本是来自真实样本分布Pdata还 是来自生成样本分布Pg,最终找到使两个模型代价最小的位置,即纳什平衡点。
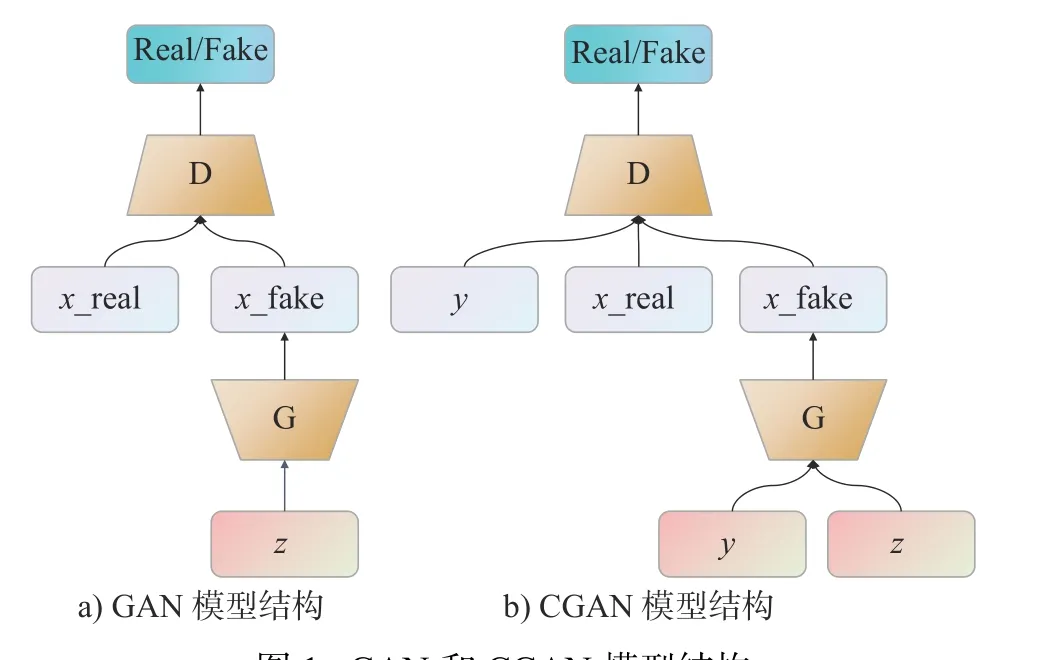
图1 GAN 和CGAN 模型结构Fig.1 GAN and CGAN model structures
两个模型的代价函数为
式中:E(·)为 对应分布的期望;G(·)为生成模型生成的数据;D(·)为判别模型的输出。
原始 GAN 无法生成指定的目标数据,Mehdi Mirza 等提出了一种条件生成对抗网络(CGAN)[10],通过在原始 GAN 的生成模型和判别模型输入中添加辅助的信息y,如数据的类型标签,来实现生成指定的目标数据。模型结构如图1b)所示,CGAN 的代价函数为
2 模型描述
2.1 损失函数
GAN 采用JS 散度或KL 散度来衡量两个分布Pg和Pdata之间的距离时,在训练中要把握好生成器和判别器的训练程度,否则会导致模型效果变差、并且训练中无法通过生成器和判别器的损失获知模型的训练效果和模型崩坏等问题。为解决上述的问题,本文采用文献[11]中提到的Wasserstein 距离来描述模型中两个分布的距离,即
式中: Π (Pdata,Pg)为Pdata和Pg所有可能的联合分布的集合; inf为下确界;x为真实样本;y为生成样本;|x-y|为两个样本的距离。
由于Wasserstein 距离无法直接求解,式(3)可转换为
式中:K为常数;sup 为上界; |f|L为f(x)的Lipschitz常数,|f|L≤K。
为了让f(x)满 足 |f|L≤K,文献[11]中的模型WGAN 采用权值剪裁策略,将权值的范围限制在[-c,c]。模型权值更新时,在范围外的权值将被剪裁为-c或者c。文献[12]发现WGAN 在处理Lipschitz限制条件采用的权值剪裁策略,容易造成模型的梯度消失或者梯度爆炸,导致模型训练困难、收敛速度慢等问题。因此本文采用文献[12]中的梯度惩罚策略来满足Wasserstein 距离的Lipschitz 限制条件,生成器和判别器的损失函数LG和LD分别为:
式中:z=εxdata+(1-ε)xg,ε ∼U(0,1);λ 为梯度惩罚项。
2.2 模型结构
本文提出的CGAN-GP 模型通过对真实样本的分布特征学习,生成高质量的样本,用于数据增强,填补样本量小的数据集,用于进一步的故障诊断。模型主要有两部分组成:生成器和判别器。生成器用于生成虚假的样本,判别器负责对样本进行评估,指引生成器生成更高质量的样本。
在生成器和判别器的输入中添加标签信息,引导模型学习故障类别的特征,进而可以根据相应的标签生成指定的故障样本。在生成器中,输入由从标准高斯分布中随机采样的100 维噪声z和随机标签label 组成,先通过全连接层对输入数据进行扩展,再对数据的维度进行重塑、然后经过几个特征学习块的处理,充分学习故障样本的特征,最终生成虚假样本。特征学习块主要由上采样层和卷积层构成,在特征学习块中加入BatchNorm 层对数据进行归一化,防止模型发生过拟合。为加快模型的训练和克服反向传播中梯度消失等问题,在归一化层后使用ReLU 作为激活函数。输出层则使用tanh 作为激活函数。
判别器由多个卷积层构成,每个卷积层后采用LeakyReLU 作为激活函数。在计算损失时,由于采用梯度惩罚策略来满足Wasserstein 距离的Lipschitz限制条件,其中梯度惩罚是对每个样本单独进行,而BatchNorm 归一化层会引入不同样本的相互依赖关系,所以判别模型中没有使用BatchNorm 层。CGAN-GP 具体参数如表1 所示。
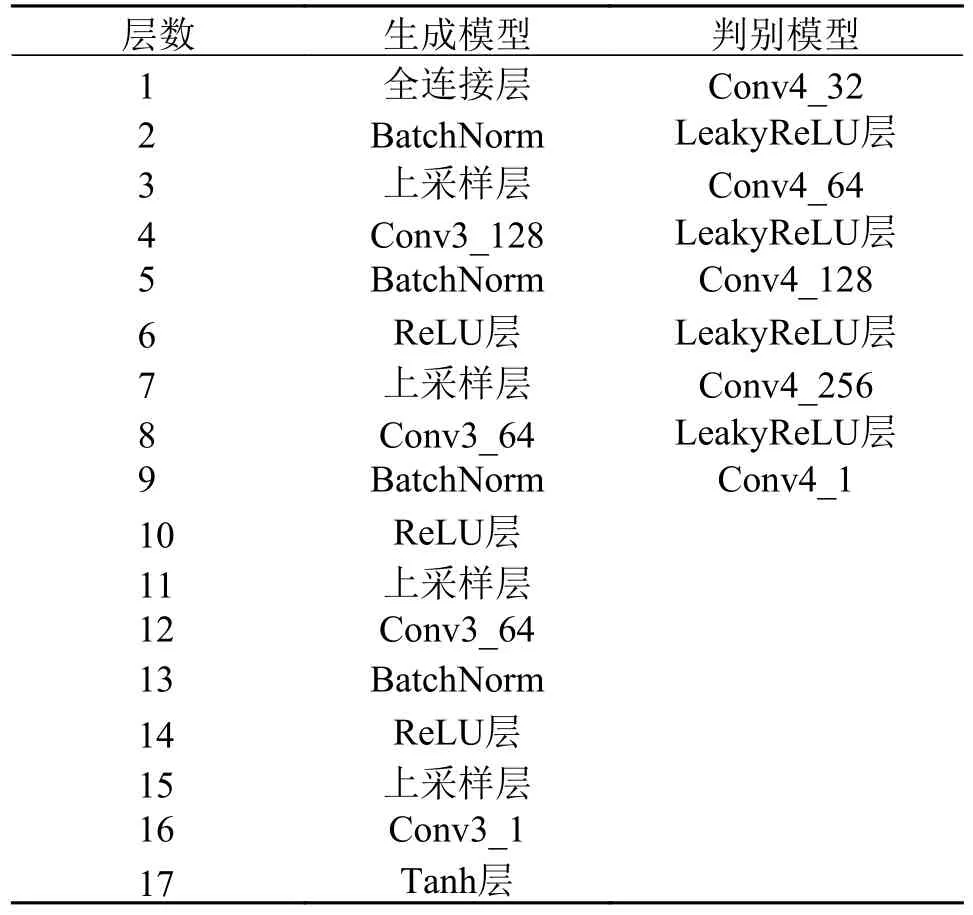
表1 CGAN-GP 具体参数Tab.1 Specific parameters of CGAN-GP
2.3 样本生成流程
基于上述损失函数式(5)和式(6),训练模型,更新模型参数。生成器和判别器均采用Adam 优化器[13],学习率均为0.000 1。 CGAN-GP 模型训练流程可分为3 个步骤,如图2 所示。
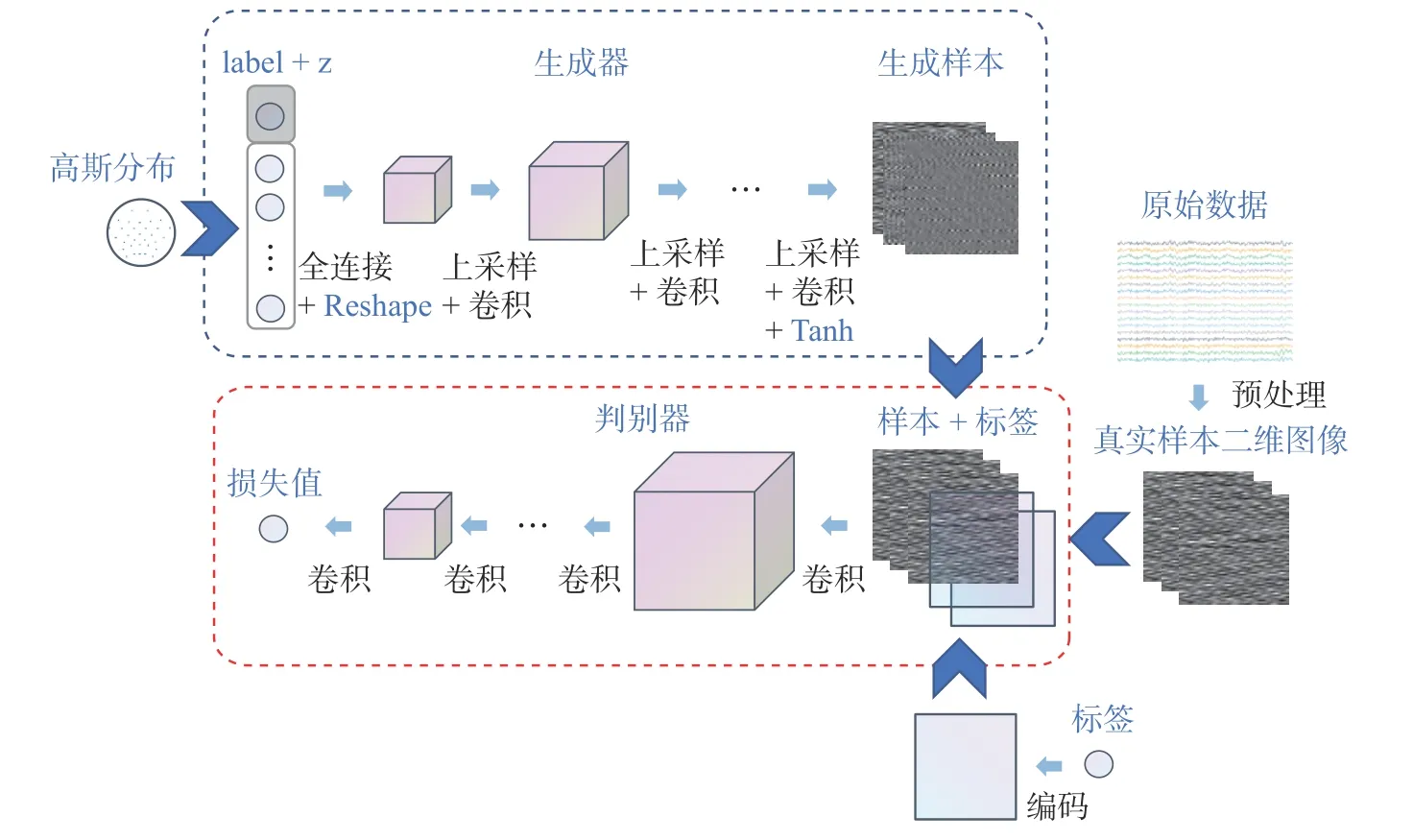
图2 CGAN-GP 模型训练流程Fig.2 CGAN-GP model training process
1) 原始数据预处理。CGAN-GP 模型是针对二维图像数据构建的,所以训练模型前需要对原始的一维数据进行处理,把原始数据转换为二维图像数据。具体做法详见第3 节。
2) 更新判别器参数。带有标签label 的随机噪声z经过生成器的计算,生成虚假样本。然后将经过编码的标签信息与生成样本或真实样本组合传入判别器中,通过损失函数式(5)计算损失值,并更新判别器的参数。
3) 更新生成器参数。训练完判别器后,固定判别器的参数。根据式(6)计算的损失值更新生成器的参数。
2.4 模型诊断流程
将CGAN-GP 应用到进行故障诊断时,如图3所示,可分为两个步骤:
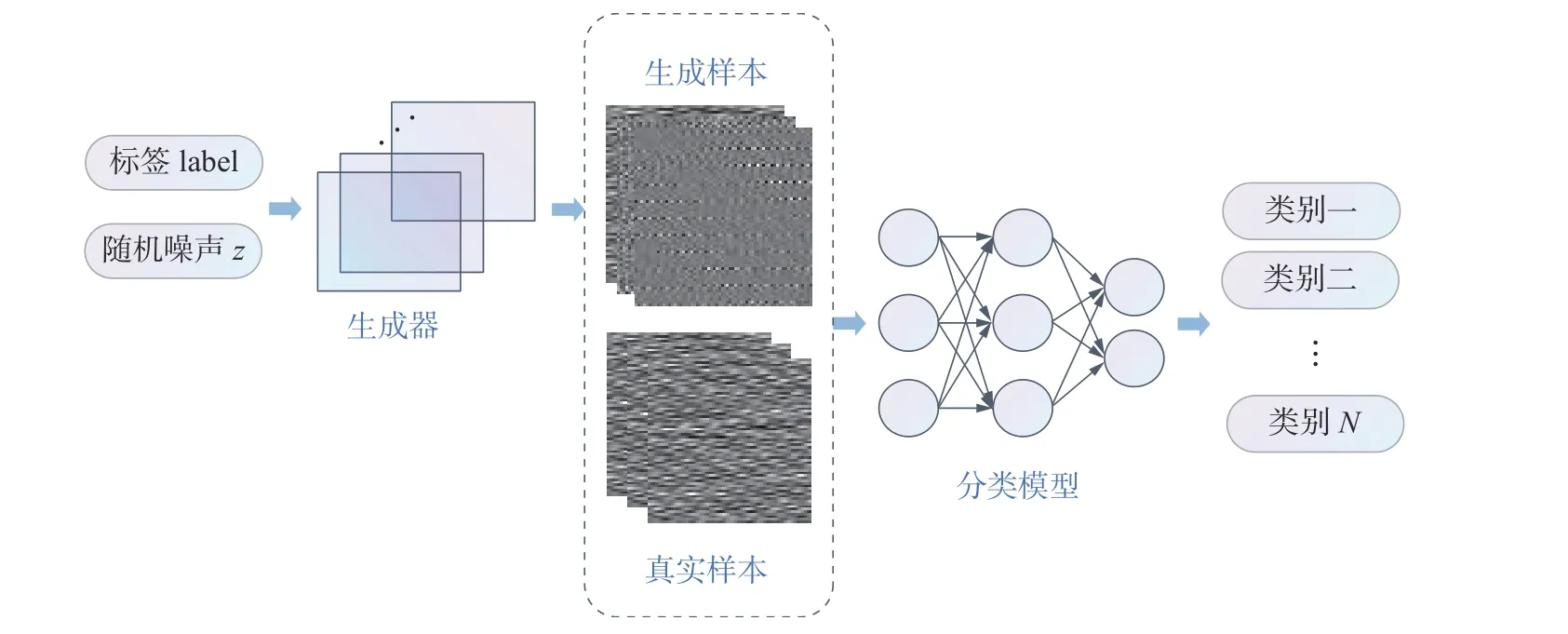
图3 故障诊断流程Fig.3 Fault diagnosis process
1) 生成虚假样本。在CGAN-GP 训练后,用更新好参数的生成器生成指定故障的样本,混合到小样本数据集中,得到数量充足且平衡的故障样本。
2) 故障诊断。利用混合后的样本数据训练故障分类模型,将训练好的分类模型用于故障诊断。
3 实验与分析
本实验在Windows10 下进行,计算机的CPU 为AMD Ryzen 7 5800H@3.2 GHz,运行内存为16 G,GPU 为内存6 G 的NVIDIA GeForce RTX 3060。模型使用Python 语言,基于深度学习框架 Pythorch1.9搭建。
3.1 数据集
本文使用的是美国凯斯西储大学(Case western reserve university,CWRU)的轴承数据集。轴承的故障通过电火花在轴承内圈、外圈和滚动体上分别加工单点损伤,形成轴承的各种故障,损伤直径有0.177 8 mm、0.355 6 mm、0.533 4 mm。在电动机风扇端和驱动端的轴承座上方各放置一个加速度传感器,分别以12 kHz、48 kHz 采样频率采集故障轴承在不同电机载荷下的振动加速度信号[14]。实验平台如图4 所示。

图4 CWRU 轴承实验平台[14]Fig.4 CWRU bearing experimental platform
3.2 数据预处理
本文的模型(CGAN-GP)是通过对二维图像进行数据增强,因此在训练模型前,需要对原始的一维时序信号预处理,将一维信号转换为二维灰度图。本文采用文献[4]中的方法,即
式中:P(i,j) 为 转换后二维图中的第i行 ,第j列的值;N为二维图的长和宽;L为从一维时序信号采样的值,一次采样数量为N2;L(i)为L中 的第i个采样点的值;函数 round(x)将计算后的值进行取整,保证转换后的取值是[0,255]的整数。
本实验使用12 kHz 采样频率下,电机风扇端的轴承数据,包含正常轴承共10 种类型样本。原始信号样本连续采集1 024 个数据点作为一个样本,数据预处理后转换为一个64×64 的二维灰度图样本。从转换后的灰度图数据集中选取6 000 张作为CGAN-GP模型的训练集,具体如表2 所示。每种类型的灰度图如图5 所示。
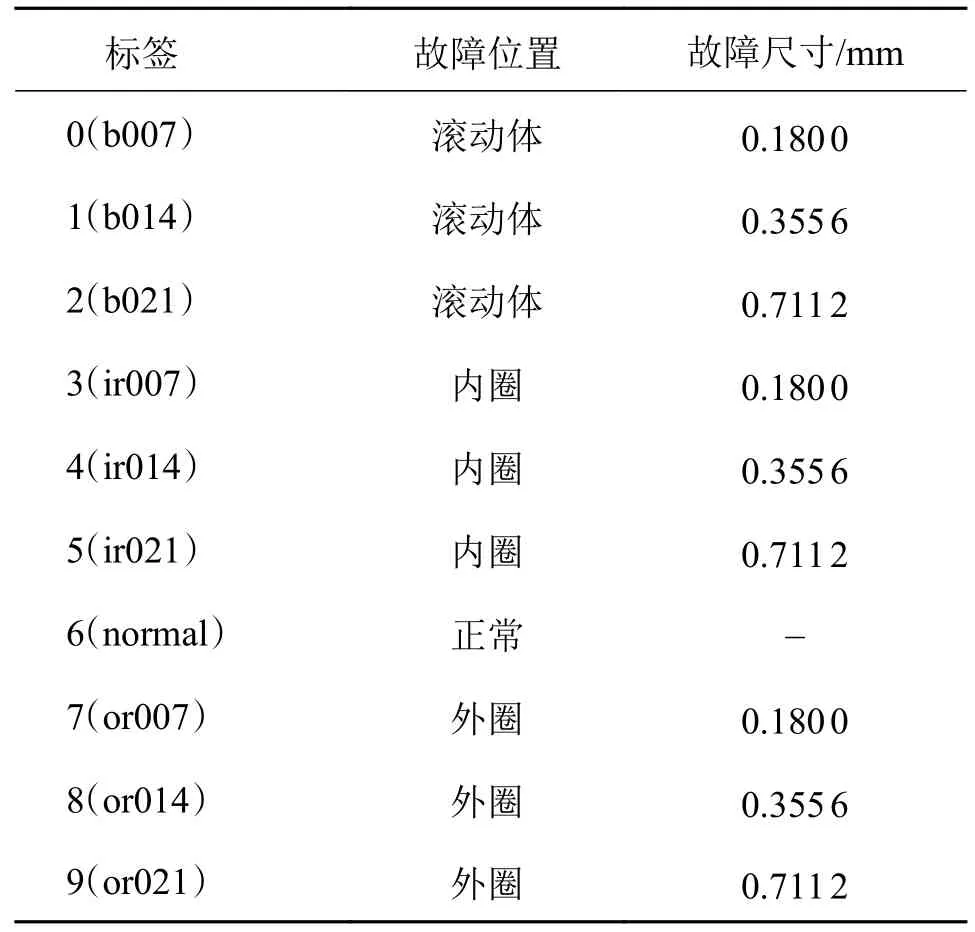
表2 故障类别及对应标签Tab.2 Fault categories and corresponding labels

图5 真实样本转换后的灰度图Fig.5 Gray scale image after real sample conversion
3.3 损失函数图像
在训练CGAN-GP 模型过程中,为加快模型的训练,每更新5 次判别模型参数,更新一次生成模型参数。模型每批次处理32 个样本,共训练模型850 次,即epoch 为850,梯度惩罚系数λ=10。图6为生成模型训练过程中的损失,由图6 可以看出,生成模型的损失开始大幅度增加,说明模型处于学习阶段,没有很好的拟合轴承数据。然后损失开始振荡减小,此时模型开始慢慢学习轴承数据的分布特征。在经过800 次迭代后,损失小幅度振荡并趋于稳定,说明模型已经得到很好的训练,能够较好的拟合轴承数据,生成的样本与真实样本具有很高的相似性。
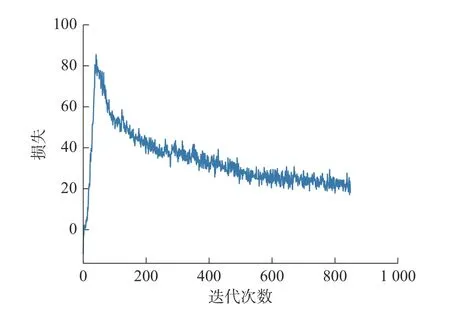
图6 CGAN-GP 中生成模型的训练损失Fig.6 Training loss of the model generated in CGAN-GP
3.4 生成样本分析
本文以标签为0、2、4、6、8 的故障为例,采用定性和定量两种方式分析生成样本,并且与CGAN 模型生成的样本进行对比。CGAN 模型与CGAN-GP 模型具有相同的结构,采用相同的超参数训练相同次数。
通过对比生成样本和真实样本,定性的分析生成样本的质量。如图7 所示,分别展示了对应故障样本的真实样本振动信号、灰度图、CGAN-GP 模型的生成样本和CGAN 模型的生成样本。并且采用T-sne(T-distributed stochastic neighbor embedding)[15]工具把样本的特征降到二维,通过可视化样本的分布,评估生成样本和真实样本的相似性,结果如图8所示。从图7 和图8 中可知,CGAN-GP 模型生成样本的灰度图与真实样本的灰度图高度相似但是又不完全一样,并且两者特征分布有大量的重合区域,说明CGAN-GP 模型能够有效拟合故障样本的特征,且保证生成样本的多样性。CGAN 模型生成的样本与真实样本,无论是灰度图还是特征分布都有着明显的区别,说明CGAN 模型在学习故障样本特征时存在一定缺陷,无法生成高质量的样本。
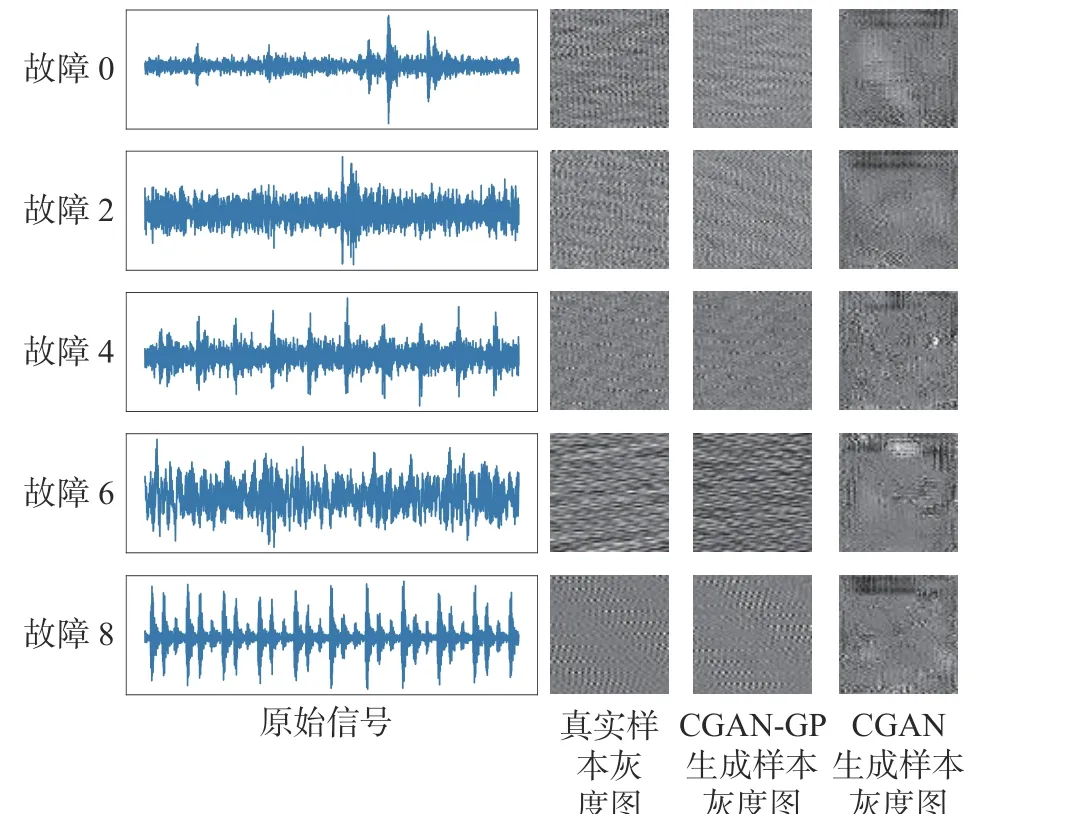
图7 真实样本与生成样本对比Fig.7 Comparison between real samples and generated samples
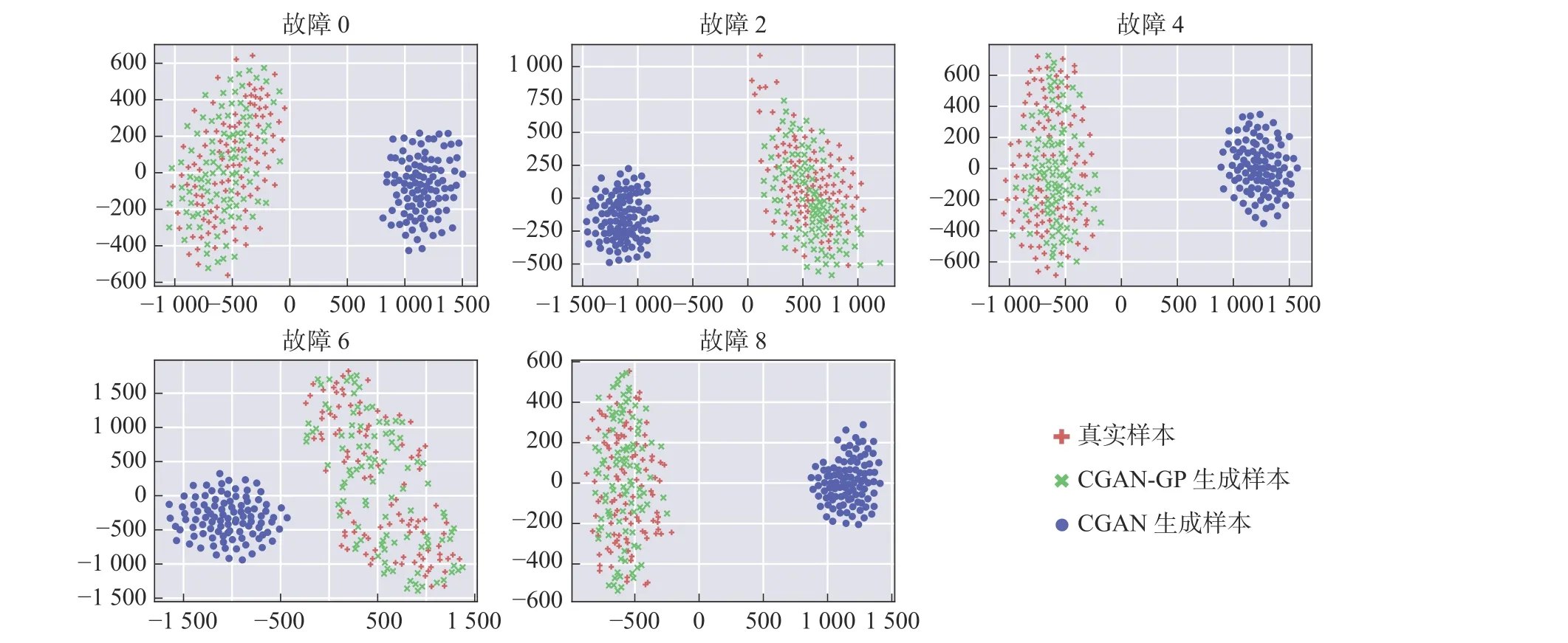
图8 t-sne 可视化生成样本和真实样本Fig.8 t-sne visualization-generated samples and real samples
通过欧式距离(Euclidean distance, ED)和余弦距离(Cosine distance, CD)两个指标定量的描述生成样本和真实样本的相似度。各选取10 张CGAN模型和CGAN-GP 模型生成的样本与真实样本计算ED 和CD,并取平均值,结果如表3 所示。可以看到,CGAN-GP 模型生成的样本整体上优于CGAN模型,与真实样本的相似度更高。
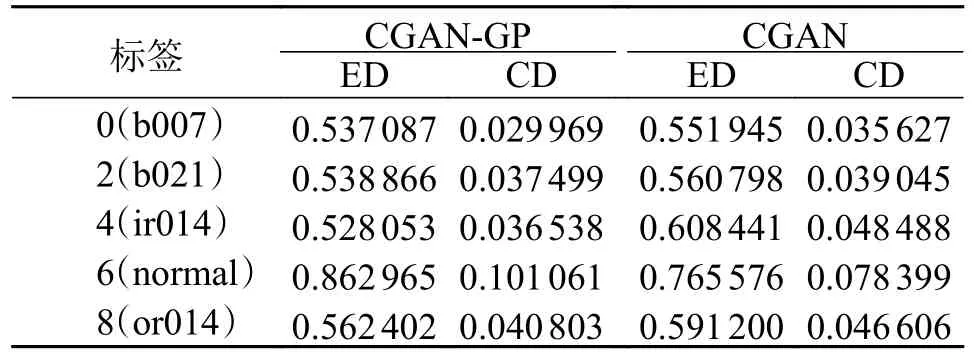
表3 不同方法的生成样本对比Tab.3 Comparison of generated samples using different methods
综合上述结果,CGAN-GP 模型可以生成高质量的样本,相比于CGAN 模型生成的样本,CGANGP 模型生成的样本与真实样本具有更高的相似度,数据增强的效果更好。
3.5 生成样本在小样本故障诊断中的应用
为了验证生成样本在故障诊断中的有效性,本文设计了一组对比实验,利用上述预处理后的CWRU轴承数据模拟以往小样本数据集添加CGAN-GP 模型生成的样本对故障检测的影响,具体如表4 所示(其中验证集和测试集均为400)。
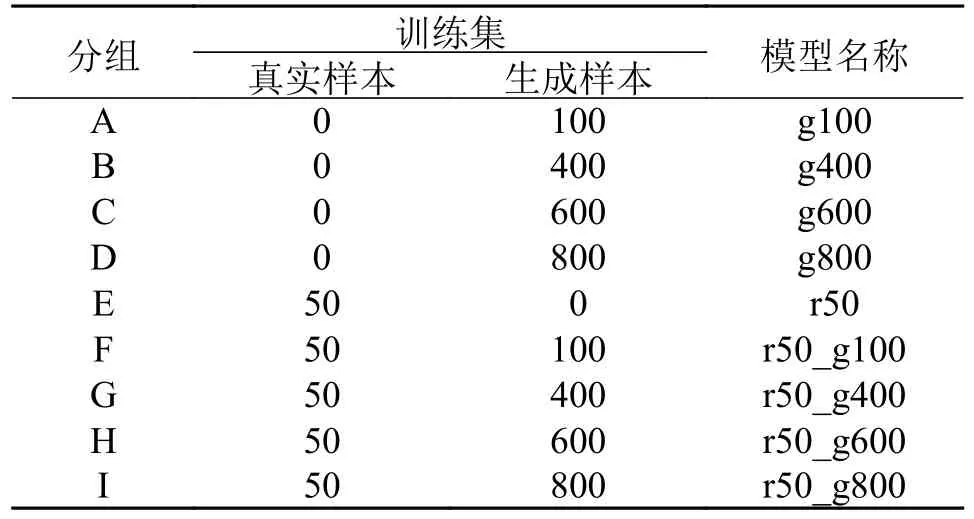
表4 故障诊断模型实验分组Tab.4 Experimental grouping of fault diagnosis model
实验利用真实样本和生成样本按不同的比例混合组成训练集,表中的数据为每一类样本数量。利用这些数据,使用相同的超参数设置,训练一个由卷积层和全连接层组成的分类模型。训练中各模型在训练中的损失及在验证集上的表现如图9 所示。从图中的结果看,随着训练集样本数量的增加,模型的分类准确率更高,并且具有更快的收敛速度。训练集中采用混合数据,即有真实样本和生成样本,比只含有生成样本,模型有更好的分类效果。
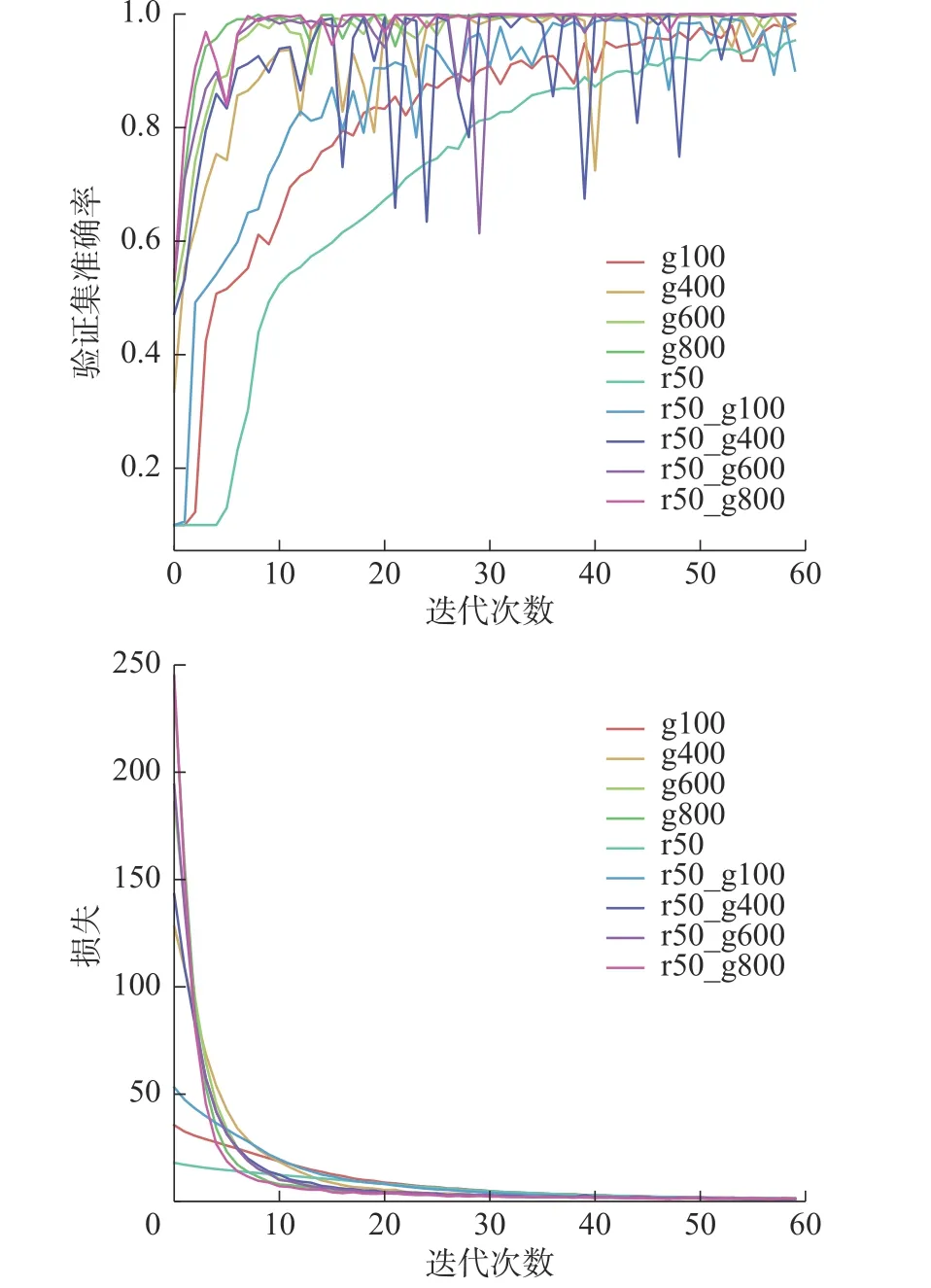
图9 故障诊断模型在各训练集的损失及在验证集上的准确率Fig.9 Loss of the fault diagnosis model in each training set and its accuracy on accuracy validation set
为了模拟各个模型在真实故障诊断下的表现,选取各实验在验证集上表现最优的模型,测试各最优模型在测试集上的分类效果,如图10 所示。

图10 各故障诊断模型在测试集上的准确率Fig.10 Accuracy of each fault diagnosis model on the test set
从图10 中发现混合数据训练的模型整体上比只用生成数据训练的模型分类准确率更高,并且相比于只含有真实样本训练的模型,混合数据训练的模型的分类准确率提升明显,说明CGAN-GP 模型生成样本在填充小样本数据集后,可以有效的提高故障诊断精度。但是并不是随着添加生成样本越多,模型的分类准确率越高,混合了每类故障50 个真实样本、600 个生成样本数据和混合了每类故障50 个真实样本、800 个生成样本数据训练的模型r50_g600、r50_g800 的分类准确率比r100_g400 训练模型的分类精度稍低,说明CGAN-GP 生成的样本含有真实样本特征的其他信息,导致分类模型的分类错误。
为了解分类模型对各个故障的识别效果,绘制了各模型在测试集上分类结果的混淆矩阵,如图11所示。从图中可以知道,模型在故障0、故障1 和故障2 的分类上存在一定缺陷,特别是只含有真实样本训练的模型r50 尤为明显。但是在真实样本中添加了生成样本训练的模型,该情况得到明显的改善。
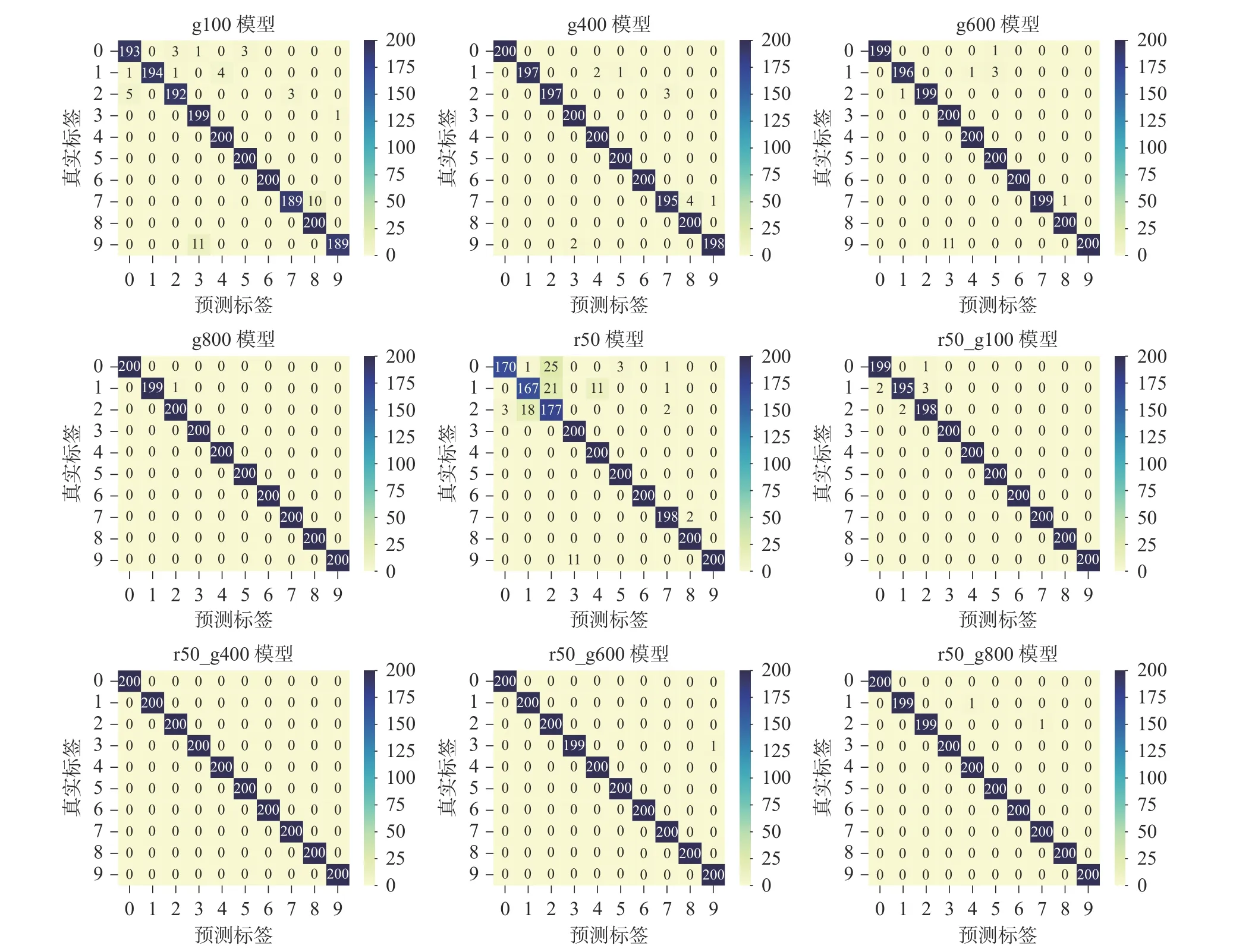
图11 各故障诊断模型在测试集上诊断结果的混淆矩阵Fig.11 Confusion matrix of diagnostic results for each fault diagnosis model on the test set
综合以上的结果,本文CGAN-GP 模型生成的样本与真实样本具有很高的相似性,能够有效的扩充小样本的故障数据,在提高小样本故障诊断精度上有一定的效果。
4 结论
通过分析现有智能设备故障诊断面临的问题,提出CGAN-GP 模型用于数据增强,提高小样本故障诊断模型的分类精度。得出结论如下:
1) 通过将故障样本的标签信息添加到模型的输入中,使模型可以根据指令生成特定的故障样本,提高了生成样本的效率。
2) 在生成样本的质量上,相比于CGAN 模型,CGAN-GP 模型生成样本的质量更优,与真实样本的相似度更高。
3) 实验表明:通过向小样本轴承数据集中添加CGAN-GP 模型生成的样本,获得充足的训练样本,可以有效的提高故障诊断率。
