融合坐标注意力与多尺度特征的轻量级安全帽佩戴检测
2023-12-06李忠飞冯仕咏郭骏张云鹤徐飞翔
李忠飞,冯仕咏,郭骏,张云鹤,徐飞翔
(1.内蒙古电投能源股份有限公司 北露天煤矿,内蒙古 霍林郭勒 029200;2.中国矿业大学 信息与控制工程学院,江苏 徐州 221116;3.北京和利时数字技术有限公司,北京 100176)
0 引言
近年来,在煤矿生产过程中由于不按规定佩戴安全帽引发的安全事故频发。正确佩戴安全帽可有效保护工人头部免受坠落物、碰撞和其他意外的侵害,因此,及时发现并纠正安全帽佩戴不符合规定的煤矿工人,实现安全帽佩戴检测至关重要[1]。然而,当前大部分安全帽佩戴检测存在人力成本高、易受环境影响、准确率和效率不高等问题。
进入深度学习时代,利用计算机视觉技术进行图像处理分析已成为业界的主要研究方向[2-3]。基于计算机视觉技术的安全帽佩戴检测研究分为2 类。一类是利用传统目标检测算法进行检测,由于安全帽有着区别于背景的颜色特征及区别于人头的形状特征,所以多是与图像分割技术相结合。李琪瑞[4]首先通过方向梯度直方图找到人体区域,然后用“凸”字型头部特征获取头部信息,最后用梯度直方图(Histogram of Gradient,HOG)+支持向量机(Support Vector Machine,SVM)技术检测安全帽。Sun Xiaoming 等[5]采用视觉背景差分算法检测工人,通过头部与全身的比例关系确定安全帽的初始定位,利用基于贝叶斯优化的SVM 模型对安全帽进行检测。Li Tan 等[6]使用视觉背景提取(Visual Background Extractor,ViBe)算法进行背景建模,同时基于运动目标分割图像,使用实时人体分类框架定位行人,然后利用头部位置、色彩空间变换和色彩特征实现安全帽佩戴检测。另一类是利用基于深度学习的目标检测算法进行检测。徐守坤等[7]对更快的区域卷积神经网络(Faster Regions with CNN features,Faster RCNN)进行不同尺度的训练,并引入在线难例挖掘策略以增强网络检测不同尺寸目标的能力,最终采用多部件结合算法进行安全帽佩戴检测。Wang Xuanyu 等[8]通过添加大尺寸的特征输入进行多尺度预测以改进YOLOv3 模型,从而实现安全帽佩戴检测。罗欣宇[9]先采用限制对比度自适应直方图均衡(Contrast Limited Adaptive Histogram Equalization,CLAHE)算法进行图像预处理,再使用RetinaNet 算法进行安全帽目标检测。梁思成[10]使用密集连接网络来改善模型对安全帽特征的提取能力。张培基[11]在YOLOv5 基础上,通过增加上采样模块构成显著性目标检测(Salient Object Detection,SOD)算法,以解决复杂场景下安全帽佩戴检测困难问题。
但上述算法都未能很好地平衡检测速度与检测精度之间的关系,且模型的计算量、参数量较大,无法在相关智能视频监控终端上实现嵌入式安装,同时作为小目标的安全帽也进一步加大了检测难度。因此本文使用网络结构较简单的YOLOv4[12]作为安全帽佩戴检测算法框架,并在此基础上提出轻量化的M-YOLO 模型。本文主要贡献如下:①在YOLOv4模型的基础上,引入MobileNetV2 轻量级网络[13]模型,并融合具有分组特征的混洗坐标注意力(Shuffle Coordinate Attention,SCA)模块,组成S-MobileNetV2特征提取网络以替换原有的CSPDarknet53 网络,在降低模型参数量的前提下,提高对目标特征位置信息的提取能力,改善复杂环境下特征提取困难的问题。② 将原有的空间金字塔池化(Spatial Pyramid Pooling,SPP)[14-15]方式改为串行连接,将3 个不同大小的池化核统一替换成5×5 的池化核,减少运算复杂度,有效提高计算效率。③将包含足够多空间和细节特征信息的浅层特征加入特征融合网络,有效实现浅层高分辨率特征和深层语义特征的融合,改善对安全帽小目标检测能力较弱的问题。同时在特征融合网络中引入深度可分离卷积,有效降低添加浅层特征带来的参数量与计算量。
1 M-YOLO 模型原理
1.1 M-YOLO 结构
M-YOLO 在YOLOv4 基础上进行改进,结构如图1 所示,其中红色方框表示改进的部分。
主干网络使用由SCA 模块组成的S-MobileNetV2特征提取网络提取特征信息,颈部网络使用添加了浅层特征和快速空间金字塔池化(Spatial Pyramid Pooling-Fast,SPPF)结构的特征融合网络,通过组合自上而下和自下而上的2 种特征融合方式,实现对特征提取网络中提取到的深层特征和浅层特征的融合,使模型更好地综合大、中、小尺度信息。同时为进一步减小模型的参数量和计算量,将YOLOv4特征融合网络中的部分卷积修改为深度可分离卷积。由于Mish 激活函数比Leaky-ReLU 激活函数拥有更好的非线性特征,所以在主干网络输出至特征融合网络中的13×13 特征层处使用CBM 模块,在模型的后续特征融合部分使用DBL 模块取代CBL 模块,以提高模型的泛化能力。
1.2 S-MobileNetV2 特征提取网络
煤矿井下图像背景复杂且存在目标尺寸较小等特点,整体特征提取难度较大,单纯减少模型参数量的操作会导致模型检测能力明显下降。为在保证模型特征提取能力的前提下满足轻量化的要求,MYOLO 模型使用S-MobileNetV2 特征提取网络替换YOLOv4 的特征提取网络CSPDarknet53。
MobileNetV2 模型是轻量级卷积神经网络中的重要标志性模型,具有很好的改进可扩展性,将其应用在目标检测网络中,可有效满足应用环境对模型轻量化的要求,相较于MobileNetV1、MobileNetV3[16]、GhostNet[17]等轻量级网络,其特征提取能力表现更佳。但在应用于安全帽佩戴检测时,虽然相较于CSPDarknet53 网络,MobileNetV2 轻量级主干网络减少了较多计算量和参数量,但其特征提取能力也随之下降。
为提高MobileNetV2 的特征提取能力,将注意力模块嵌入到卷积神经网络中。轻量级网络的注意力模块受限于轻量化需求,大多采用通道注意力模块(Squeeze and Excitation,SE)[18]和卷积块注意力模块(Convolutional Block Attention Module,CBAM)[19],但SE 模块只考虑了特征通道间的信息,忽略了特征的位置信息,而CBAM 模块虽然在降维操作后通过添加卷积来获取特征的位置信息,但相关卷积只能获取到特征位置的局部关系,无法对长距离的特征关系进行提取。
坐标注意力模块[20]则有效解决了上述2 种注意力模块存在的问题。坐标注意力模块将横向和纵向的位置信息编码到通道注意力中,同时为避免通道注意力的二维全局平均池化导致的完整位置特征信息的损失,注意力模块将通道注意力划分为2 个并行的一维特征编码,从而高效地将空间坐标信息整合到生成的注意力映射图中。
坐标注意力模块结构如图2 所示。在通道注意力中,对于输入特征图m,先使用2 个不同尺寸的池化核分别沿着水平(X)和竖直(Y)这2 张坐标方向对各个通道进行平均池化,这2 种池化分别沿水平和竖直空间方向聚合特征,得到2 张包含方向信息的特征图。这与通道注意力中生成单一特征向量的SE 模块有很大区别。这种方式使得坐标注意力模块在提取到其中一个空间方向的长距离的依赖关系时,还可保存另外一个空间方向的相关位置信息,从而使网络在面对待检目标时可以更精确地定位。
通过坐标注意力模块获得全局感受野和感兴趣目标的位置信息特征。为充分利用这些信息,将上述分开的特征堆叠(Concat)在一起,然后使用1×1 大小的卷积对其进行降维操作,沿着空间维度对中间特征图在水平方向和竖直方向进行分离操作,切分为竖直方向的特征张量f1∈Rc/r×h和水平方向的特征张量f2∈Rc/r×w,其中c为通道数,r为下采样的比例,用以控制模块大小,h,w分别为特征图高度、宽度。再利用2 个1×1 大小的竖直方向上的卷积F1和水平方向上的卷积F2,将特征张量f1和f2的通道数升维至m(m为输出特征的通道数),具体公式如下。
式中:G1和G2分别为竖直、水平方向上扩展后的注意力权重;σ(·)为Sigmoid 激活函数。
坐标注意力模块通过提取2 个方向上的并行特征来保留完整的位置特征信息,但这无疑会增加参数量。因此,本文提出了SCA 模块,在减少坐标注意力参数量的前提下,有效改善特征之间的联系。
SCA 模块结构如图3 所示。首先将原始特征图沿通道维度平均分成g组,然后对每组通道进行坐标注意操作,将2 个并行的特征进行融合,最后进行通道混洗操作[21],对特征组进行重排,以改善不同特征组之间的信息交流。
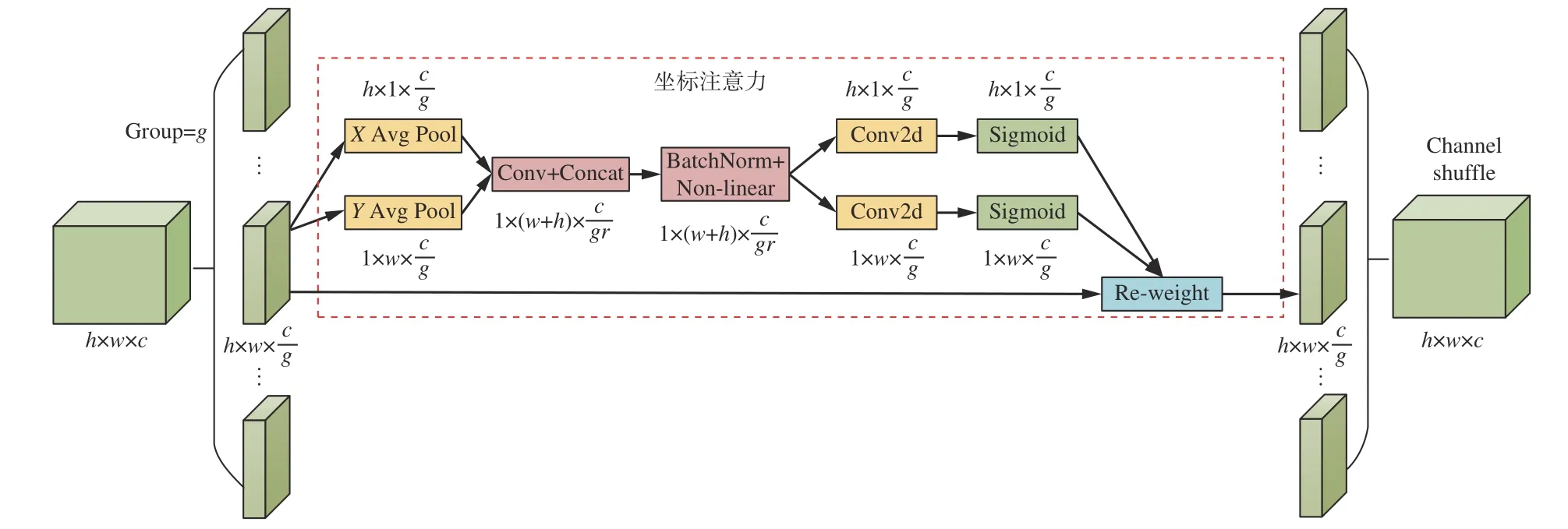
图3 SCA 模块结构Fig.3 Shuffle coordinate attention module structure
MobileNetV2 中的每一个Bottleneck 都是由2 个1×1 普通卷积和1 个3×3 深度卷积组成。安全帽普遍较小,将SCA 模块加入Bottlenetck 中形成SCABottleneck,将得到更准确的位置特征信息,更有利于检测小目标。
初始MobileNetV2 中有17 个Bottlenetck,如果将所有Bottlenetck 全部替换为SCA-Bottleneck 模块,会导致模型的参数量与计算量增大,检测速度下降明显,因此选用输出特征图尺寸为104×104、52×52、26×26、13×13 的Bottlenetck 进行替换,模块中的分组数g选定为4。融合了SCA 模块的S-MobileNetV2结构见表1。

表1 S-MobileNetV2 结构Table 1 S-MobileNetV2 structure
1.3 SPP 结构改进
YOLOv4 的SPP 结构如图4 所示。对输入的特征图分别使用3 个不同尺度的最大池化得到3 张感受野扩大的特征图。池化核尺寸越大,提取到的特征就越具全局语义性;池化核尺寸较小时,提取到的特征更多地包含局部细节信息。将3 张经过不同池化核的特征图与输入特征图进行拼接,融合成新的特征。通过最大池化操作可降低卷积层参数误差造成的估计均值偏移,从而保留更多的浅层特征信息。

图4 SPP 结构Fig.4 Spatial pyramid pooling structure
虽然SPP 结构对于特征提取起到了积极作用,但9×9、13×13 的最大池化会给模型增添部分计算复杂度,同时并联3 个不同尺度的最大池化也会导致模型运算时间增加。为提高模型对安全帽佩戴检测的速度,本文使用SPPF 结构,如图5 所示,将SPP 结构中的各个并行池化改为串行池化。

图5 SPPF 结构Fig.5 Spatial pyramid pooling-fast structure
串行2 个池化核大小为5×5 的最大池化层的计算结果和1 个池化核大小为9×9 的最大池化层的计算结果相同,而串行3 个池化核大小为5×5 的最大池化层的计算结果和1 个池化核大小为13×13 的最大池化层的计算结果相同。结合主干网络添加的注意力模块,将SPP 结构中3 个并行的不同尺度最大池化层替换为3 个串行的池化核大小相等的最大池化层,这样不仅实现了全局特征与局部特征的融合,还将原来3 个5×5、9×9、13×13 大小的池化核统一替换成5×5 大小的池化核,减少了相关模型运算的复杂度,有效提高了计算效率。
1.4 特征融合网络重构
将主干网络提取到的不同尺度特征充分融合是提高目标检测性能的一个重要手段。主干网络中深层特征图由于经过多次卷积,其特征信息表现得更具语义性,但分辨率很低,对细节的感知能力较差,而浅层特征图由于经过的卷积次数少,其特征信息表现得更具细节化,同时也由于其经过的卷积少,语义性较差,包含的噪声也更多[22]。在实际应用中,安全帽多以小目标出现,因此应提高模型对于小目标检测的精度。但YOLOv4 特征融合结构并没有特意加强对小目标检测的操作,随着主干网络卷积层的不断加深,小尺寸的安全帽目标在特征图上的信息逐渐丢失,如图6 所示,可看出卷积层次越深,图像特征就越抽象,细节特征就越少。为提高安全帽小目标检测的准确性,需要对浅层特征图上的细节信息进行充分利用。

图6 特征图可视化Fig.6 Feature map visualization
为降低模型对安全帽的漏检率,改善模型对小目标的检测效果,本文对特征融合网络进行改进。将主干网络中的浅层特征图加入到特征融合网络中,具有高分辨率、多细节纹理信息的浅层特征图可有效加强模型对检测目标特征表达能力的提取,使得浅层的表征信息和深层的语义信息充分融合[23],提高目标检测的准确性。
主干网络结构如图7 所示。将416×416 大小的图像输入YOLOv4,主干网络和特征融合网络之间传输13×13、26×26 和52×52 这3 种不同尺寸的特征图。这3 种特征图分别经过特征融合网络的各项操作,最终分别用于检测大、中、小目标。为丰富特征图的细节特征,本文在特征图P3—P5 的基础上额外增加浅层特征图进入特征融合网络。虽然特征图P1 包含较多空间和细节特征信息,但P1 因为经过的卷积层过少,其包含的背景噪声信息过多,加大了模型检测难度。而特征图P2 相较于P1 经过了若干卷积层的提取,减少了因浅层特征而带来的背景噪声,同时相比于特征图P3—P5,其包含了足够多的空间和细节特征信息,因此本文选择将特征图P2 加入特征融合网络,实现浅层高分辨率特征和深层语义特征的融合。

图7 主干网络结构Fig.7 Backbone network structure
2 实验结果与分析
实验使用由Munkhjargal Gochoo 收集的5 000 张图像组成的SHWD(Safety Helmet Wearing Dataset)数据集,原有数据集包含5 个类别:安全帽、戴安全帽的头部、戴安全帽的人、头部、不戴安全帽的人。为方便研究和展示检测效果,本文对数据集的标签XML 文件进行更新,只保留戴安全帽的头部(helmet)和不戴安全帽的人(no-helmet)2 个类别。按照8∶1∶1 的比例设置训练集、验证集、测试集。
同时为验证模型性能的鲁棒性,本文引入公开数据集Pascal VOC,数据集包含人、自行车、汽车等20 个类别的图像,使用VOC2007 和VOC2012 数据集中的16 551 张图像进行训练,VOC2007test 部分的4 952 张图像进行测试。
2.1 基础MobileNetV2 特征提取能力实验
为验证MobileNetV2 主干网络的特征提取能力,对不同主干网络在VOC 数据集、SHWD 数据集上进行实验。按照主干网络差异,将不同主干网络的M-YOLO 模型分别命名:主干网络为CSPDarkNet53的M-YOLO、主干网络为MobileNetV1 的M1-YOLO、主干网络为MobileNetV2 的M2-YOLO、主干网络为MobileNetV3 的M3-YOLO、主干网络为GhostNet的G-YOLO。不同主干网络实验结果见表2。
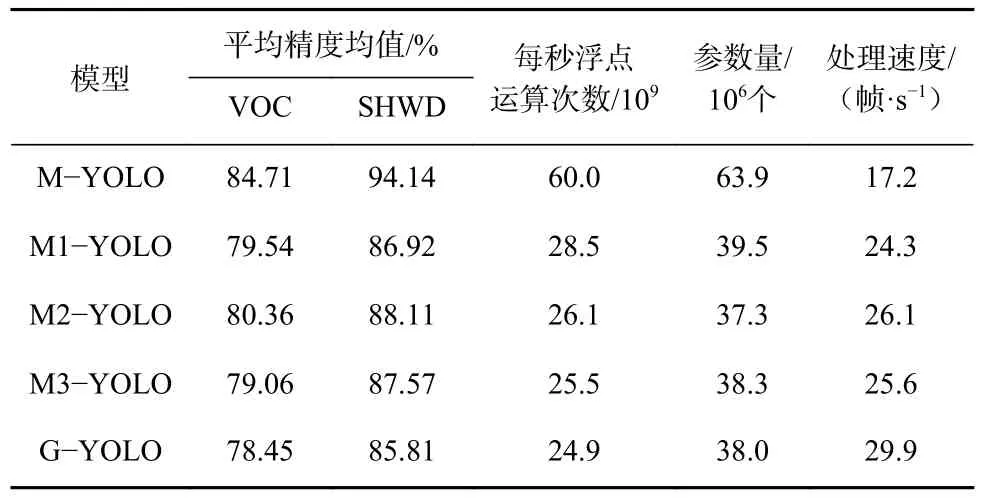
表2 不同主干网络实验结果Table 2 Experimental results of different backbone networks
从表2 可看出,相较于其他轻量级网络,M2-YOLO 模型在VOC 数据集、SHWD 数据集上的检测精度最高。
2.2 不同SCA 模块位置实验
为进一步探究SCA 模块对网络特征提取能力的贡献,在SCA-Bottleneck 模块中使用不同位置的SCA 模块来进行实验。SCA 模块融入到逆残差结构Bottleneck 不同位置的方式如图8 所示。

图8 SCA 模块不同分布位置Fig.8 Different distribution positions of shuffle coordinate attention module
分别由SCA-Bottleneck-1、SCA-Bottleneck-2、SCA-Bottleneck-3、SCA-Bottleneck-4 组成的不同SMobileNetV2 的实验结果见表3。可看出采用SCABottleneck-3 的位置分布时检测精度最高,且处理速度较快。
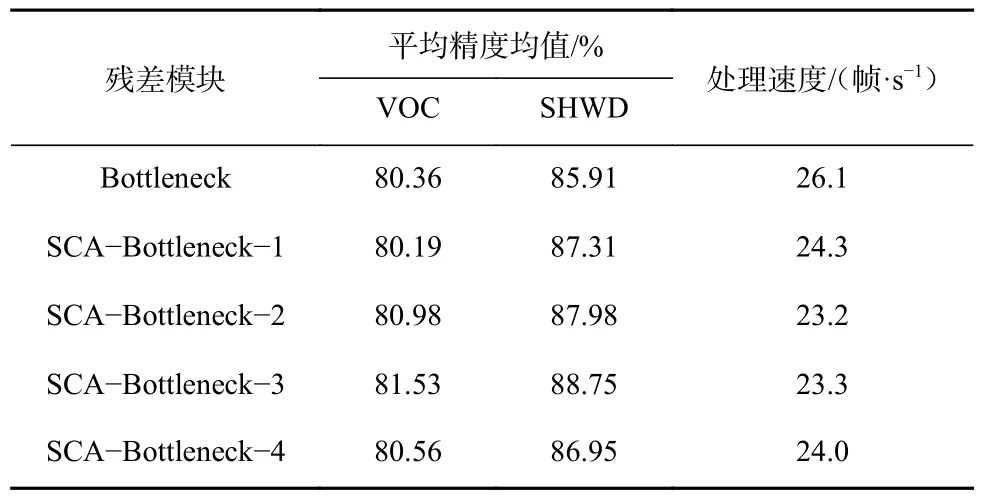
表3 不同位置SCA 模块实验结果Table 3 Results of shuffle coordinate attention module experiments at different positions
2.3 消融实验
为进一步评估各项改进对检测效果的影响,针对M-YOLO 的各项轻量化改进在SHWD 数据集上进行了消融实验,结果见表4。

表4 消融实验结果Table 4 Ablation experiment results
从表4 可看出,使用S-MobileNetV2 主干网络的M-YOLO 相较于使用MobileNetV2 主干网络的M2-YOLO 平均精度均值提高了2.84%;M-YOLO使用SPPF 结构后,模型在平均精度均值提升0.72%的基础上,处理速度提高了3.6 帧/s;使用深度可分离卷积替换特征融合网络的部分卷积后,模型在平均精度均值提高1.63% 的同时,处理速度提高了6.7 帧/s。
2.4 模型对比实验
为进一步评估M-YOLO 模型对安全帽佩戴检测的性能,将M-YOLO 与其他目标检测模型进行对比实验,结果见表5。

表5 不同模型对比实验结果Table 5 Comparative experimental results of different models
从表5 可看出,在SHWD 数据集上,M-YOLO模型的平均精度均值只比轻量化改进前的YOLOv4模型低了0.84%,但模型的计算量、参数量、模型大小相较于YOLOv4 模型分别减小了74.5%,72.8%,81.6%,检测速度提高了53.4%。相较于其他YOLO系列模型、以Transformer 为基础的DETR 模型、无锚框策略的CenterNet 和YOLOX 系列模型,M-YOLO模型在准确率和实时性方面取得了较好的平衡。虽然YOLOX-S,YOLOv4-tiny,YOLOv5-S,Efficientdetd0 这4 种轻量级模型的检测速度与M-YOLO 模型相近或略优,但在平均精度均值上低于M-YOLO 模型,无法满足工业场景下准确检测的要求。
2.5 实际场景检测效果对比实验
在实际场景检测中,将M-YOLO 模型与除YOLOv4 模型外表现较好的2 个模型YOLOv5-M,CenterNet 进行检测效果对比,结果如图9 所示。

图9 实际场景检测结果Fig.9 Detection result of actual scenarios
从图9 可看出,对于黑白场景的煤矿井下监控视频,其具有目标与背景对比度低的特点,虽然M-YOLO,YOLOv5-M,CenterNet 都正确检测到了目标,但这3 种模型对目标检测的置信度不同,M-YOLO 对安全帽目标的置信度为0.99,而CenterNet、YOLOv5-M 对安全帽目标的置信度分别为0.57,0.49。对于正常场景下目标个数为24 的煤矿井下图像,可看到M-YOLO 正确检测到23 个目标,漏检1 个目标,无错检;YOLOv5-M 正确检测到19 个目标,漏检1 个目标,错检4 个目标;CenterNet正确检测到21 个目标,漏检2 个目标,错检1 个目标。M-YOLO 模型虽然因安全帽不完整而导致漏检1 个目标,但整体效果依然优于YOLOv5-M 和CenterNet 模型。
3 结论
1)以YOLOv4 模型为基础,提出了一种融合坐标注意力与多尺度的轻量级模型M-YOLO 用于安全帽佩戴检测。该模型通过在轻量级主干网络中使用SCA 模块,以提高网络的特征提取能力;在特征融合网络中使用SPPF 结构和深度可分离卷积,以加快检测速度;同时将特征提取网络中的浅层特征加入特征融合网络,改善了模型对于复杂场景小目标的检测效果。
2)实验结果表明,该模型在保证检测精度的前提下,具有参数量少、计算复杂度低、处理速度快等特点,满足在相关智能视频监控终端上嵌入式安装和使用的需求。
3)虽然该模型实现了对安全帽佩戴的精准检测,但是需依托大量安全帽数据集来进行训练,未来可进一步研究无监督或弱监督的安全帽佩戴检测算法,以减少相应样本标注工作,增强算法的泛化性。
