工作面刮板输送机煤流状态识别方法
2023-12-06吴江伟南柄飞
吴江伟,南柄飞
(北京天玛智控科技股份有限公司,北京 101300)
0 引言
随着煤矿智能化无人开采进程的纵深推进,构建AI 视觉感知、自动决策、设备协同控制三大环节一体化的生产管理系统已经成为业界共识。在井下工作面中,利用刮板输送机上煤流状态的视觉感知结果,联动控制采煤机和刮板输送机进行生产作业管理,从而实现工作面煤流负载平衡,不仅可以降低工作面堆煤事件发生率,提升工作面自动化生产率,同时可以降低井下能源消耗。
目前矿井煤流状态识别方法大多针对带式输送机场景,其实现方式大致分为两类。第一类是基于图像的方法,如文献[1-2]通过传统图像处理方法获取带式输送机轮廓及煤料边界,并由此计算煤料横截面积和体积,但该方法严重依赖于边缘检测方法,受光照等环境因素影响较大,精度和稳定性差。文献[3]将图像中煤流量大小划分为5 个级别并利用深度学习模型直接对图像进行分类,该方法逻辑简单、部署方便,但对全图进行操作时没有排除非煤流区域的影响,且该方法只对单幅图像进行分类,并没有对煤流的时序特征进行建模。第二类是基于特殊传感装置(如超声波传感器、激光扫描仪等[4-7])的方法,通过计算煤料截面积进而获得煤料体积。此类方法中虽然也可能用到图像信息,但关键在于其引入的硬件设备能够给算法增加诸如深度、超声回波、煤流速度、激光条纹等信号,使得煤流量计算结果更加精确;但此类方法的问题在于处理的数据量较大,相关算法模型实时性、可靠性较差,且硬件设备大幅增加了成本开销。
然而,上述方法无法有效应用于工作面刮板输送机场景中的煤流状态识别,这是因为工作面刮板输送机与带式输送机场景存在巨大差异。①带式输送机有固定外形且运输的煤料经过破碎后形状相对规则、大小相对均衡,这些场景特征使得准确计算煤料横截面积及煤流体积成为可能;而在工作面刮板输送机场景中,刮板输送机姿态易受地质条件影响且煤料形状不规则、大小差异巨大,导致无法准确计算煤料横截面积,煤料间存在的空隙导致无法简单根据体积公式获得煤流体积。② 带式输送机场景中相机、灯具等设备的安装条件相对较好,可将其安装在理想位置使得算法鲁棒性更好;而在空间局促的工作面刮板输送机场景中,由于需要考虑相机、灯具等设备是否会与滚筒、采煤机、护帮板发生干涉,造成其安装位置受限甚至无法安装,进而导致摄像仪视角、可见度等无法满足已有算法要求。③在生产过程中,工作面刮板输送机场景中存在高粉尘、采煤机遮挡、刮板输送机位置改变等不利因素,影响采集数据的质量,导致算法识别精度下降。
针对工作面刮板输送机场景,本文提出了一种基于时序视觉特征的煤流状态识别方法。该方法具有以下优势:①无需计算准确煤量,用空载煤流、正常煤流和饱和煤流3 种状态描述刮板输送机上煤量大小,在满足应用要求的前提下大大降低了算法复杂度。② 仅需以现有工作面中部署的摄像仪作为数据采集设备,避免了设备安装受限问题;同时,只需处理图像数据,数据处理量较小,具有很好的实时性。③采用深度学习语义分割模型确定煤流区域,有效缓解传统方法易受光照、粉尘影响导致算法精度下降的问题;同时,能够精确定位煤流区域,排除无关图像区域影响。④ 采用深度学习动作识别模型进行煤流特征建模,不仅能够学习到煤流的纹理特征,而且能够学习到煤流的时序特征。
1 方法原理
基于时序视觉特征的刮板输送机煤流状态识别方法原理如图1 所示。针对工作面煤流视频帧图像,首先利用深度学习语义分割模型获得粗略煤流区域,在此基础上通过线性拟合方法定位精细煤流区域坐标并裁剪出煤流图像;然后将煤流图像按视频时序排列形成煤流图像序列;最后通过动作识别模型对煤流图像序列进行特征建模,获得煤流状态识别结果。
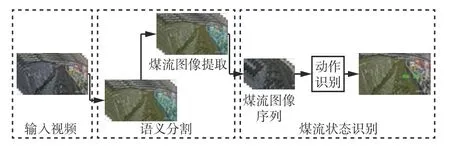
图1 基于时序视觉特征的刮板输送机煤流状态识别方法原理Fig.1 Principle of method for recognizing coal flow status of scraper conveyor based on temporal visual features
2 刮板输送机煤流图像提取
刮板输送机煤流图像提取整体流程:针对视频帧图像进行图像语义分割,获得线缆槽边缘;针对线缆槽边缘进行曲线拟合;根据视频帧图像中刮板输送机特点及线缆槽边缘拟合曲线获取煤流区域边界;从视频帧图像中裁剪出煤流区域形成煤流图像。
2.1 煤流视频图像语义分割
针对煤流视频帧图像进行语义分割的主要目的:①获取视频帧图像中局部煤流区域,从而排除大量非煤流区域图像对后续动作识别模型的影响,使得煤流状态识别结果更加准确。② 受限于安装条件,监控摄像仪往往只能安装在液压支架顶板上,当支架顶板与刮板输送机相对位置不变时,煤流区域处于图像中的固定位置;然而,采煤过程中频繁性推刮板输送机动作使得支架顶板与刮板输送机相对位置发生变化,导致煤流区域在图像中的位置也随之发生变化。因此,需要利用语义分割结果动态定位煤流区域。
语义分割是图像分割的一个分支,可实现图像中不同语义区域的分割。经典的深度学习语义分割模型有SegNet[8],Mask R-CNN[9],U-Net[10],DeepLab系列[11-13]等。本文采用DeepLabV3+语义分割模型,如图2 所示,DeepLabV3+语义分割模型将空间金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP)与编解码结构相结合,既能够使模型获得多尺度上下文信息,又能够保证图像分割结果中物体的边缘分割更加准确。同时,DeepLabV3+语义分割模型采用了Xception[14]框架,使得模型分割处理速度更快,满足实际应用的实时性要求。
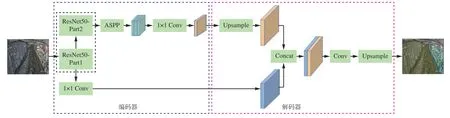
图2 DeepLabV3+语义分割模型网络结构Fig.2 Network structure of DeepLabV3+semantic segmentation model
如图2 中DeepLabV3+语义分割模型输出的分割结果所示,本文将视频帧图像以线缆槽底部为界划分为2 个部分:①线缆槽底部到煤壁为粗略煤流区域,是后续动作识别模型的候选输入数据。② 线缆槽底部到支架为非煤流区域。
2.2 煤流区域定位获取
由于语义分割获得的粗略煤流区域中仍包含较多非煤流区域(如煤壁、浮煤等),且该分割区域形状不规则,所以不能直接作为后续动作识别模型的输入图像。为获得精细煤流区域,需确定煤流区域的4 个边界,选取原则为尽可能包含更多煤流区域且排除非煤流区域。本文直接选取图像高度的一半处作为上边界,选取图像的下边界作为煤流区域下边界。对于右边界,本文先提取线缆槽边界点并对其进行分段直线拟合,获得拟合曲线,然后取拟合曲线与视频帧图像下边缘交点横坐标作为煤流区域右边界。分段直线拟合计算公式为
式中:为求解参数结果;为待求参数集合;为待求直线方程;xi和yi分别为线缆槽边界点中第i(i=1,2,···,n,n为线缆槽边界点总数)个点的横坐标和纵坐标。
对于左边界,由于刮板输送机在图像中大小不会发生变化,所以当右边界确定时,可通过线性拟合方法根据右边界值预测出左边界值,计算公式为
式中:xl为煤流区域左边界值;k为线性系数,本文对推刮板输送机动作前后2 种情况分别进行线性拟合,推刮板输送机动作前k取0.57,推刮板输送机动作后k取0.4;xr为煤流区域右边界值。
3 刮板输送机煤流状态识别
3.1 问题建模
通常煤流实际是指煤料随刮板输送机运动而形成的流体,煤量由刮板输送机上煤料横截面积与刮板输送机长度积分获得:
式中:V为待求煤量;L为刮板输送机长度;ρ为煤料密度;F(x)为刮板输送机上x处的煤料横截面积。
这种方法要求精确计算刮板输送机上煤料横截面积。但在工作面刮板输送机场景下精确计算煤料横截面积面临极大挑战。因此,本文采用一种新的方法:煤量可由刮板输送机上某一点在某一时刻的煤量与时间积分获得:
式中:T为时间;G(t)为刮板输送机某一位置在t时刻的瞬时煤量。
与式(3)相比,式(4)虽然不需要计算煤料横截面积,但其中的瞬时煤量G(t)同样无法计算。为避免精确煤量计算,本文将煤量离散化,分为空载煤流、正常煤流及饱和煤流3 个状态。同时,为避免煤流状态随着刮板输送机上煤料分布变化而频繁变化,对一个时间段内的煤流状态进行融合:
式中:S为t1到tT时刻刮板输送机上煤流状态;g(t)为t时刻刮板输送机上煤流状态,g(t)=0,1,2,分别表示空载煤流、正常煤流、饱和煤流状态;H(g(t1),g(t2),···,g(tT))为对t1到tT时刻的煤流状态进行融合操作。
3.2 煤流状态识别
如式(5)所示,求解刮板输送机煤流状态就是求解函数H(·)。求解函数H(·)可采用多种方法,最简单的是加权平均法,即先求得各个时间点煤流状态,然后对其进行加权平均,但该方法忽略了邻近煤流状态在时序上的内在联系。因此,本文采用动作识别模型直接对不同煤流状态图像序列的时空特征进行建模。
动作识别通常是指通过某种算法识别出视频中人的行为,并对其进行分类,其本质是对视频图像序列中呈现的行为模式进行建模。经典的动作识别模型有TSN(Temporal Segment Networks)[15],TSM(Temporal Shift Module)[16],SlowFast(SlowFast Networks)[17],I3D(Two-Stream Inflated 3D convNet)[18],R(2+1)D(Residual Spatial and Temporal Factorized Block)[19],C3D(Convolutional 3D)[20],TimeSformer(Time-Space Transformer)[21]等。其中TSN,TSM 使用2D 卷积用于提取图像特征,并通过光流、时序漂移等方法补充时序信息;SlowFast 通过快慢2 路视频流分别对时序信息和空间信息进行建模;I3D,R(2+1)D,C3D 则使用3D 卷积直接对视频进行时空特征建模,有更强的时空特征表示能力;TimeSformer采用Transformer 结构完成特征提取,模型识别准确率优于前三者,但模型处理耗时较大,无法满足实时性要求。
本文采用C3D 动作识别模型对煤流视频帧图像序列进行建模和煤流状态分类,模型结构如图3 所示。将煤流图像按时序组成新的图像序列,再将图像序列输入到C3D 动作识别模型中,从而计算并输出煤流状态识别结果。
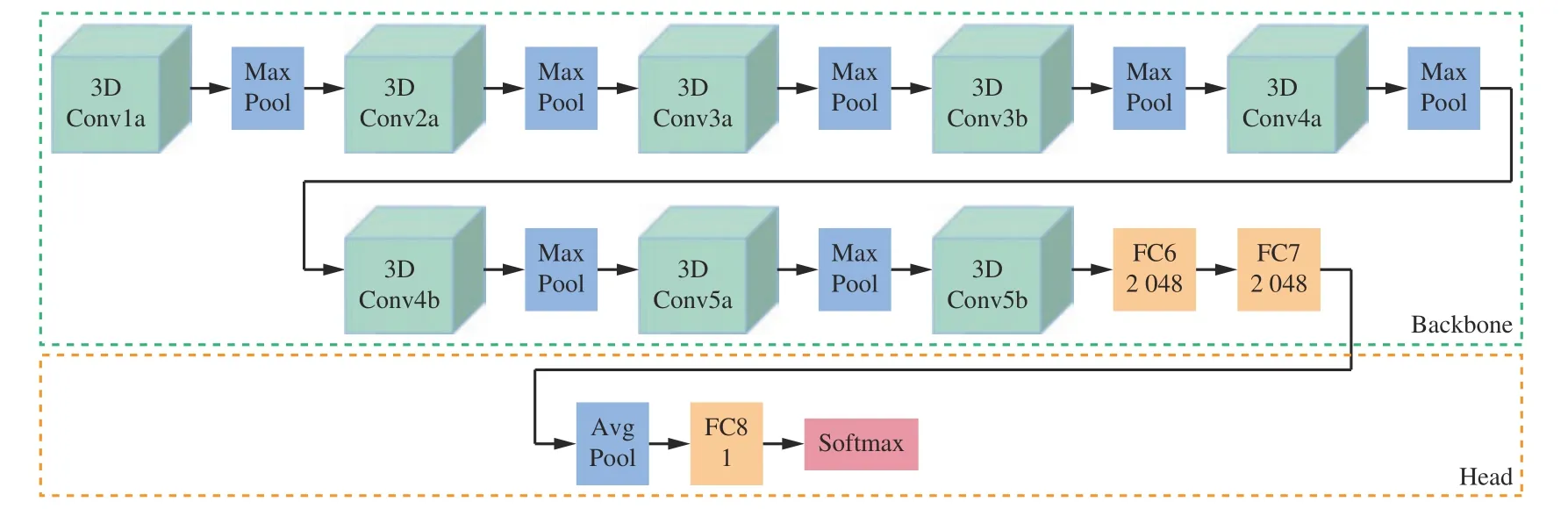
图3 C3D 动作识别模型网络结构Fig.3 Network structure of convolutional 3D action recognition model
在实际使用过程中,由于工作面工况场景中存在导致监控摄像仪无法观测到煤流的情况,为使模型能力更加完备且符合现场实际情况,本文在空载煤流、正常煤流及饱和煤流3 种状态之外还增加了“未检测煤流”,用于表示视频帧图像中未出现煤流的情况。另外,由于煤流状态识别任务相对比较简单,所以需要减少模型参数量,以防止模型过拟合情况发生。本文一方面将原始C3D 动作识别模型主干网络中最后2 个全连接层FC6,FC7 维度从原来的4 096 修改为2 048,从而极大地减少模型参数量;另一方面,在全连接层FC7 之后添加自适应平均池化层(Avg Pool),将最终特征层缩小为1×1×1,以扩大感受野,并进一步减少了模型参数量。
4 实验结果及分析
4.1 实验设定
4.1.1 硬件设备
实验所用设备配置:操作系统,Ubuntu20.04;显卡,NVIDIA GeForce RTX 3 090 ;CPU,Intel(R)Xeon(R)Gold 6258R 2.7 GHz;CUDA,版本11.4;TensorRT,版本8.2;训练框架,PyTorch 1.10。
4.1.2 数据集
实验所用数据来自国内某煤矿井下工作面视频监控系统,视频帧速率为25 帧/s,图像分辨率为1 280×720。
对于语义分割,本文人工采集、筛选并标注图像总数量为1 867 幅,其中训练集1 767 幅,测试集100 幅;每幅样本图像标注2 个类别:煤流区域、非煤流区域。
在C3D 动作识别模型训练构建阶段,本文先采集工作面煤流视频数据并进行人工筛选,获得共5.3 h的训练视频数据,对筛选视频进行4 个类别标注,然后按3 帧/s 的速率对训练视频数据进行采样,形成图像序列。对于较长图像序列,将其切分为多个片段,每段长度为32 幅图像;对于较短图像序列,用序列尾部图像进行补齐,最终长度为16 幅图像。最终训练数据包含1 728 个视频片段,总共58 568 幅样本图像。
在C3D 动作识别模型测试阶段,本文采集工作面采煤工况条件下1 刀的煤流视频数据,时长约52 min,按1 s/段对视频进行分段,总共3 138 个片段,对每个片段煤流状态进行标注并形成最终测试样本数据。
4.1.3 训练参数设置
DeepLabV3+语义分割模型的主要训练参数:模型输入图像尺寸为513×513;初始学习率为0.02,学习率按多项式曲线进行下降,最小学习率为10-6;使用随机梯度下降(Stochastic Gradient Descent,SGD)优化器,设置动量参数为0.9,权重衰减因子为10-4;设置批处理大小为32,共迭代6 000 次。
C3D 动作识别模型的主要训练参数:模型输入视频片段长度为16,图像尺寸为112×112;初始学习率为0.002,学习率采用阶梯下降方法,分别在第30,60 轮下降为原来的1/10;使用SGD 优化器,设置动量参数为0.9,权重衰减因子为10-4;设置批处理大小为96,共训练80 轮。
4.2 煤流图像提取实验
煤流图像提取结果如图4 所示,其中淡黄色和淡蓝色2 个区域为语义分割结果,红色曲线为线缆槽底部边界经过分段直线拟合后结果,深蓝色点表示待裁剪煤流图像的4 个顶点。

图4 煤流图像提取结果Fig.4 Coal flow image extraction results
从图4(a)可看出,在液压支架推刮板输送机动作后,本文方法能够准确定位线缆槽边缘并获取煤流区域;从图4(b)可看出,煤流视频帧图像中存在大量粉尘,导致图像中物体纹理模糊,在此情况下本文方法仍能准确定位线缆槽边缘并获取煤流区域;从图4(c)可看出,在采煤机进入监控视野并遮挡住刮板输送机时,虽然无法直接观察到煤流区域,但通过采煤机边缘同样能够获取煤流区域;从4(d)可看出,与前3 幅图像相比,该图中刮板输送机和煤流区域在图像中位置发生明显变化,在此情况下本文方法同样能够自适应地准确获取煤流区域。这表明本文方法能够针对工作面复杂工况场景准确定位煤流区域。
为验证DeepLabV3+语义分割模型的准确性,在测试集上计算分割结果与真实值的IoU(Intersection over Union,交并比):
式中:Agt为真实区域;Apred为预测区域。
IoU 计算结果:线缆槽底部到煤壁区域IoU 为0.976,线缆槽底部到支架区域IoU 为0.946,平均IoU 为0.961。这表明DeepLabV3+语义分割模型的预测准确率较高,能够准确分割出煤流区域。
为验证煤流图像裁剪框的准确性,需要标注理想裁剪框并将其与预测裁剪框进行比较,然后计算2 个裁剪框的IoU,但由于理想裁剪框没有明确标准,所以无法实现。裁剪框边界中最重要的是右边界的确定,即线缆槽底部边缘与图像下边缘的交点横坐标。因此本文对每幅测试图像进行右边界标注并将其与预测的右边界进行比较,计算得到平均偏差为8.4 像素(图像宽度的0.66%),标准差为3.3 像素。表明误差较小,不会导致煤流图像缺失关键区域。
4.3 煤流状态识别实验
刮板输送机煤流状态识别结果如图5 所示。图5(a)由于刮板输送机被采煤机遮挡导致煤流不可见,所以显示未检测煤流状态;图5(b)为空载煤流状态,其中左图为无粉尘情况,右图为存在粉尘干扰情况;图5(c)为正常煤流状态,左图为液压支架推刮板输送机动作后情况,右图为液压支架推刮板输送机动作前情况;图5(d)为饱和煤流状态。

图5 刮板输送机煤流状态识别结果Fig.5 Recognition results of coal flow status of scraper conveyor
在采煤作业1 刀52 min 的3 138 个测试视频片段中,煤流状态平均识别准确率为92.73%,其中未检测煤流状态识别准确率为99.05%,空载煤流状态识别准确率为96.13%,正常煤流状态识别准确率为90.04%,饱和煤流状态识别准确率为90.30%。
4.4 模型加速实验
为提升整体处理速度,将PyTorch 训练生成的模型使用TensorRT 进行转换。对DeepLabV3+语义分割模型和C3D 动作识别模型分别进行转换,转换前后模型推理耗时对比见表1。可看出:DeepLabV3+语义分割模型推理耗时从39.5 ms 下降到14.1 ms,处理速度提升1.8 倍;C3D 动作识别模型推理耗时从15.1 ms 下降到5.7 ms,处理速度提升1.6 倍。经过TensorRT 加速后,整体处理速度为42.7 帧/s,满足实时处理要求。
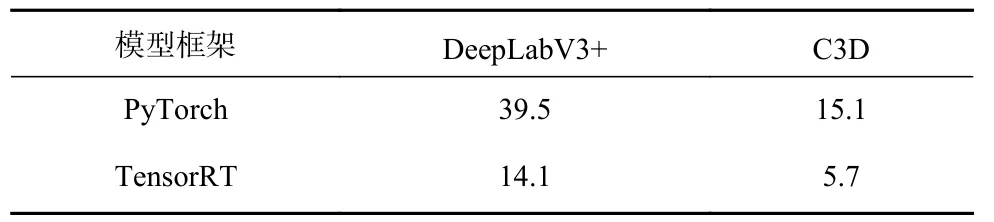
表1 模型加速前后推理耗时对比Table 1 Comparison of inference time before and after model accelerationms
5 结论
1)基于图像语义分割的刮板输送机煤流图像提取方法能够准确定位煤流区域并获取煤流图像,为后续煤流状态自动识别提供可靠数据输入。针对高粉尘、采煤机遮挡、刮板输送机位置改变等不同工况,该方法都能够自适应获得煤流图像。
2)C3D 动作识别模型能够有效提取煤流图像视觉特征和图像序列的时序特征,并进行准确表征,实现煤流状态自动识别,煤流状态平均识别准确率达92.73%,满足工作面刮板输送机煤流状态智能监测实际应用需求。
3)针对工程化部署应用,利用TensorRT 对模型进行加速处理,整体处理速度达42.7 帧/s,满足现场工程化应用的实时性要求。
