基于多模态特征融合的井下人员不安全行为识别
2023-12-06王宇于春华陈晓青宋家威
王宇,于春华,陈晓青,宋家威
(1.辽宁科技大学 矿业工程学院,辽宁 鞍山 114051;2.凌钢股份北票保国铁矿有限公司,辽宁 朝阳 122102)
0 引言
由于井下作业环境复杂多变,很容易存在安全隐患,从而导致矿井安全事故[1]。调查结果显示,矿工的不安全行为是导致矿井事故发生的主要原因,我国重大矿井事故中,超过90% 是由人为失误引起的[2]。因此,对井下人员的不安全行为进行识别分析,对保证矿井安全生产具有重要意义。随着人工智能技术的发展与智能矿山的建设,人工智能技术被运用于矿山的生产和监管中[3]。采用人工智能技术对井下人员的行为进行实时识别,能减轻人工负担,提高识别效率,从而减少矿井事故的发生。
作为计算机视觉中的热门研究方向,人体行为识别可分为基于行为识别的方法[4]、基于时序动作检测的方法[5]、基于时空动作检测的方法[6]、基于骨骼点动作识别的方法[7]。随着矿山智能化、智慧化的推进,人体行为识别技术被应用到井下人员行为识别中。党伟超等[8]通过改进传统的双流卷积神经网络,对井下配电室巡检行为进行识别检测,具有较高的准确率,但在多人巡检的场景下会出现误识别等问题。刘浩等[9]采用OpenPose 神经网络对人体骨骼关键点进行提取,并将提取到的信息输入ST-GCN(Spatial Temporal Graph Convolutional Network,时空图卷积网络)得到识别结果,实现了对井下多种不安全行为的识别。黄瀚等[10]提出了DAGCN(Dynamic Attention and Multi-layer Perception Graph Convolutional Network,动态注意力与多层感知图卷积网络)并用于煤矿人员行为识别,在提高模型泛化力的同时,也提高了识别精度。
基于RGB 模态数据,能获得丰富的人与物体外观特征信息,但井下开采过程中会产生大量粉尘,加上井下环境复杂、光照不足,使得采集到的RGB 视频图像背景噪声增多[11]。这些噪声会影响RGB 模态特征提取与行为识别。基于骨骼模态的行为识别方法能降低无关背景噪声的影响,但缺乏人与物体的外观特征信息。因此,本文采用多模态特征融合方法,将从RGB 模态与骨骼模态中提取的特征进行融合,对视频中人员的行为进行识别,提高井下人员不安全行为识别准确率。
1 行为识别模型总体架构
基于多模态特征融合的行为识别模型框架如图1 所示。该模型由2 层网络组成,分别处理RGB 模态与骨骼模态的数据。对于RGB 模态的输入视频数据,通过SlowOnly 网络[12]进行特征提取。对于骨骼模态的数据,先通过YOLOX 算法[13]对输入的RGB 视频数据进行人体目标检测,再使用Lite-HRNet(Lightweight High-Resolution Network,轻量级高分辨率网络)[14]对目标检测结果进行人体姿态估计,获取人体2D 骨骼关键点数据,从而得到骨骼模态数据;以2D 人体骨骼关键点生成对应的2D 关键点热图,并将这些热图按帧堆叠生成紧凑的3D 热图堆叠,输入PoseC3D(Pose Convolutional 3D Network)网络[15]进行特征提取。在特征提取期间,SlowOnly 与PoseC3D 进行特征的早期融合,进行特征提取后,对提取到的2 种模态特征进行晚期融合,从而完成RGB 模态与骨骼模态的特征融合,最后得到行为识别结果。
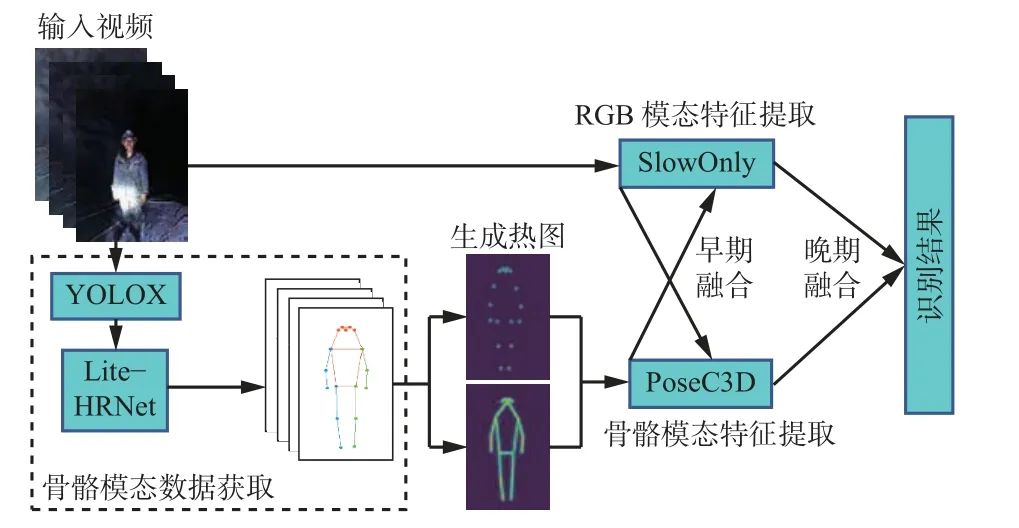
图1 基于多模态特征融合的行为识别模型框架Fig.1 Behavior recognition model framework based on multimodal feature fusion
2 骨骼模态数据获取
2.1 基于YOLOX 的人体目标检测
YOLOX 目标检测算法在YOLOv3 算法[16]的基础上进行了改进,在主干网络中加入Focus 结构,解耦预测分支,取消先验框,动态匹配正样本。Focus结构如图2 所示,对图像每隔一个像素点取一个值,得到4 个特征层,相当于输入图像的通道数扩充了4 倍,有效集中了图像的宽高信息。解耦预测分支是指将分类与回归分开实现,在预测时合并,可提高模型的收敛速度与预测精度。取消先验框是指将原来网络中的3 组先验框减少为1 组,即直接预测目标检测框的左上角坐标及高宽,可减少网络参数量,提高网络性能。动态匹配正样本是指根据不同目标设定不同的正样本数量,从全局角度进行最优分配,从而大大缩短训练时间,提高运算速度。

图2 Focus 结构Fig.2 Structure of Focus
以上改进使YOLOX 目标检测网络的参数量大大减少,同时提高了检测的精度与速度。本文使用训练好的YOLOX 网络对人体目标进行检测,对输入图像中的人员进行定位和标志。
2.2 基于Lite-HRNet 的人体骨骼关键点检测
人体骨骼关键点检测是指通过人体姿态估计算法,从输入图像中提取人体骨骼关键点对应的坐标位置。基于COCO(Common Objects in Context)数据集[17]的人体17 个骨骼关键点及其对应位置名称如图3 所示。目前人体姿态估计算法可分为自顶向下式和自底向上式2 类。自顶向下式姿态估计算法先对图像中的人体进行目标检测,找到每个人对应的位置,再对每个人体目标进行姿态估计,找到对应的骨骼关键点位置。该算法检测准确度较高,但检测速度会受到一定影响。自底向上式姿态估计算法则是直接检测出图像中所有的骨骼关键点位置,然后通过聚类对属于同一个人体目标的骨骼关键点进行关联,生成每个人体目标的骨架。由于不需要先对人体目标进行检测,该算法检测速度较快,但准确度不及自顶向下式算法。

图3 人体骨骼关键点及其对应名称Fig.3 Key points of the human skeleton and the corresponding names
基于骨骼模态数据的人体行为识别效果受提取到的人体关键点质量影响较大,因此,要求姿态估计网络有较高的识别精度。同时,井下不安全行为识别要求有一定的实时性,因此,对姿态估计网络的识别速度也有一定要求。Lite-HRNet 是HRNet(High-Resolution Network,高分辨率网络)[18]的轻量化模型,属于自顶向下式姿态估计算法。Lite-HRNet 先将轻量化网络Shufflenet[19]中的Shuffle Block 与原有HRNet相结合,使整个网络轻量化;再用条件通道加权操作替换Shuffle Block 中的1×1 卷积操作,以降低计算量。以上操作使得Lite-HRNet 的计算量大大减少,加快了网络检测速度,同时由于保持了HRNet 的高分辨率特征层,使网络能够获得足够多的特征信息和位置信息,提高了人体骨骼关键点检测精度,满足了行为识别网络对人体骨骼关键点质量与识别速度的要求。
3 多模态特征融合
3.1 RGB 模态特征提取
基于SlowFast 网络的慢速支流SlowOnly 网络进行RGB 模态特征提取,SlowOnly 网络结构如图4所示。SlowOnly 网络的帧采样速率较低,即输入帧数较少,但分辨率较高。这样能够使网络更好地从RGB 模态中提取出相应的空间特征。SlowOnly 网络在最后2 个ResNet Layer(残差网络层)使用了3D 卷积,而前面几个ResNet Layer 都是2D 卷积。特征图经过前面多次卷积后,拥有更大的感受野,网络能够从中提取到足够的时间特征信息。最后经过Global Average Pooling(全局平均池化)与Fully Connected Layer(全连接层),得到基于RGB 模态的行为识别结果。
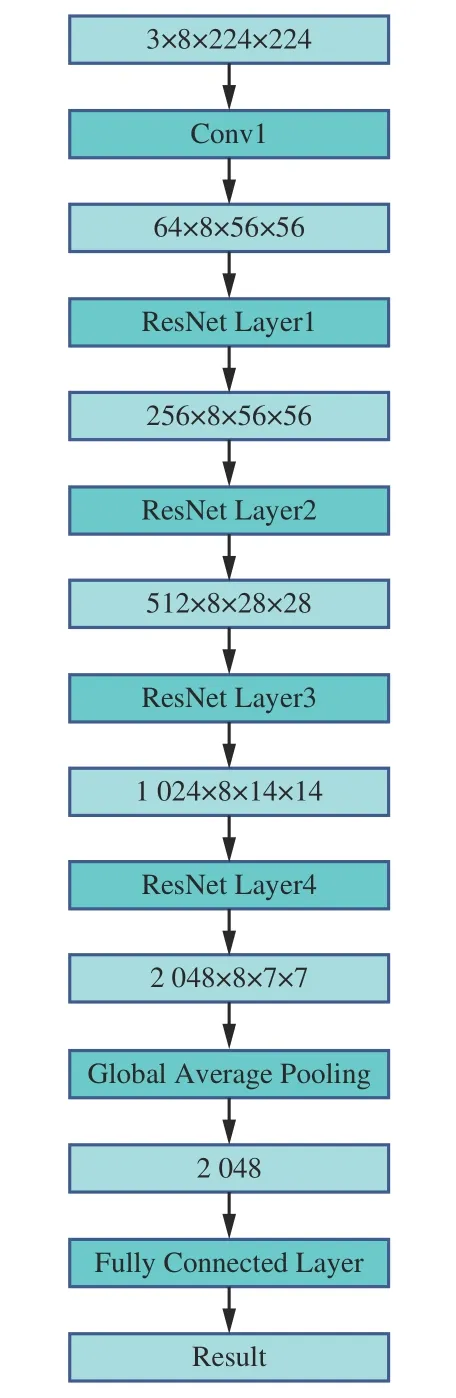
图4 SlowOnly 网络结构Fig.4 SlowOnly network structure
3.2 骨骼模态特征提取
大部分基于骨骼模态的行为识别都采用GCN(Graph Convolutional Network,图卷积网络)及其各种改进方法。人体的骨架图由骨骼关键点连接形成,因此十分适合使用GCN 处理。ST-GCN 将GCN与TCN(Temporal Convolutional Network,时间卷积网络)相结合,对于输入的骨架图序列数据,通过GCN 提取空间维度上的特征信息,通过TCN 提取时间维度上的特征信息,将2 种特征融合并进行分类,识别出具体的行为。基于GCN 的行为识别方法存在如下缺点:对骨架图序列数据中的噪声较敏感,噪声对识别结果的影响较大;在多模态数据融合学习中,GCN 与使用其他模态的模型之间难以进行特征融合;对多人场景的行为识别支持较差。
本文采用的PoseC3D 是一种基于3D-CNN(3DConvolutional Neural Network,三维卷积神经网络)的行为识别模型。不同于GCN 的是,PoseC3D 采用由骨骼关键点数据生成的热图堆叠数据作为输入。在进行姿态估计得到人体的骨骼关键点坐标后,以(xk,yk,ck)的形式储存,其中(xk,yk)为所预测的关键点坐标,ck为该关键点预测的置信度。以(xk,yk)为中心,ck为最大值,以高斯分布的形式生成对应的关键点热图h(x,y),其公式为
式中σ为高斯分布的标准差。
同理,也能以高斯分布的形式生成2 个关键点间骨骼的对应热图,其公式为
式中:D(·)为距离计算函数,用于计算点(x,y)与骨骼线段s[ak,bk]之间的距离;ak,bk为骨骼两端的关键点;为ak,bk两点的置信度。
使用井下人员骨骼关键点生成的关键点热图与骨骼热图如图5 所示。
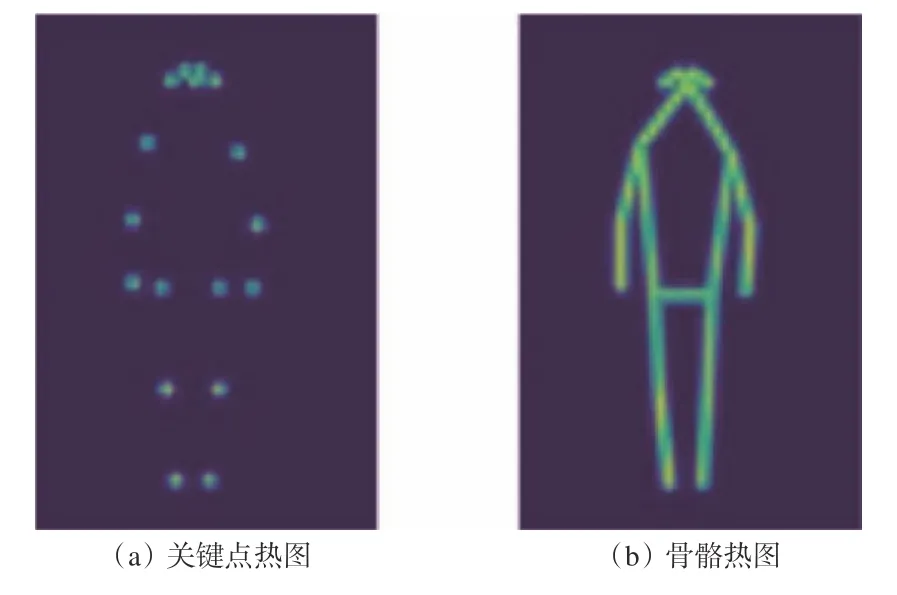
图5 关键点热图与骨骼热图生成结果Fig.5 Key point heat map and skeleton heat map generation results
PoseC3D 行为识别模型结构如图6 所示。模型需输入尺寸为K×T×H×W的三维热图堆叠,其中K为骨骼关键点数量,T为参与热图堆叠的二维关键点热图数量,即视频帧数,H与W分别为热图的高与宽。先经过多个卷积操作与多个ResNet Layer,再通过全局平均池化,最后经全连接层输出骨骼模态下的行为分类。
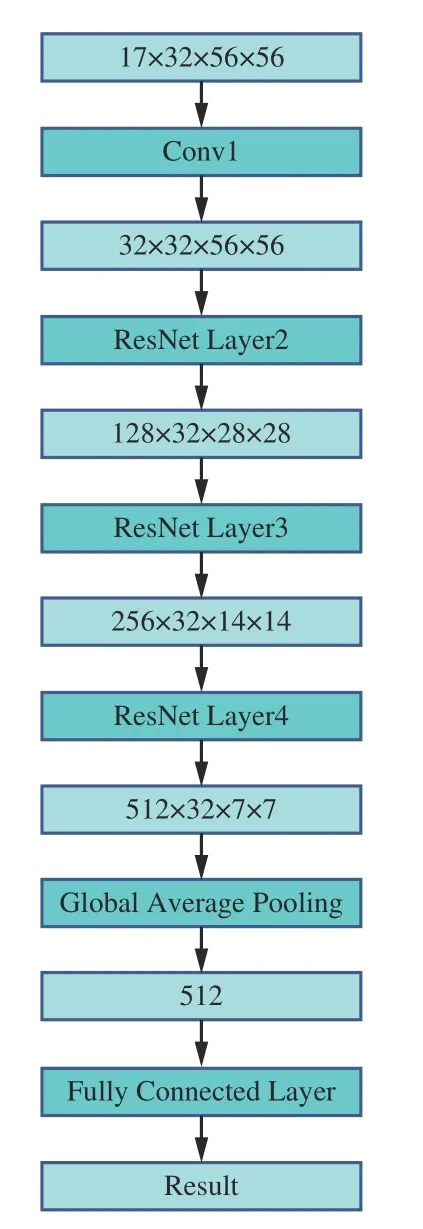
图6 PoseC3D 行为识别模型结构Fig.6 Structure of PoseC3D behavior recognition model
3.3 特征融合
RGB 模态与骨骼模态的特征融合模型结构如图7 所示,2 条支流网络分别是提取RGB 模态特征的SlowOnly 网络与提取骨骼模态特征的PoseC3D网络。RGB 模态特征提取支流能提供更多的空间信息,骨骼模态特征提取支流的输入拥有更多的通道数,即输入帧率更高,这能提供更多的运动信息。在训练特征融合模型之前,对2 条支流网络分别进行预训练,并用训练得到的权重来初始化特征融合模型,使特征融合模型收敛速度提高。多模态特征融合采用早期融合与晚期融合2 种方式。早期融合是在模型的前期特征提取阶段,在ResNet Layer2 与ResNet Layer3 之后,通过双向的横向连接进行2 种模态间的特征融合。对比单向的横向连接,双向的连接能使整个融合模型更好地学习到不同模态的时空特征,使2 个网络进行信息互补。晚期融合则是在最后对2 个网络的预测结果进行融合,输出行为分类结果。
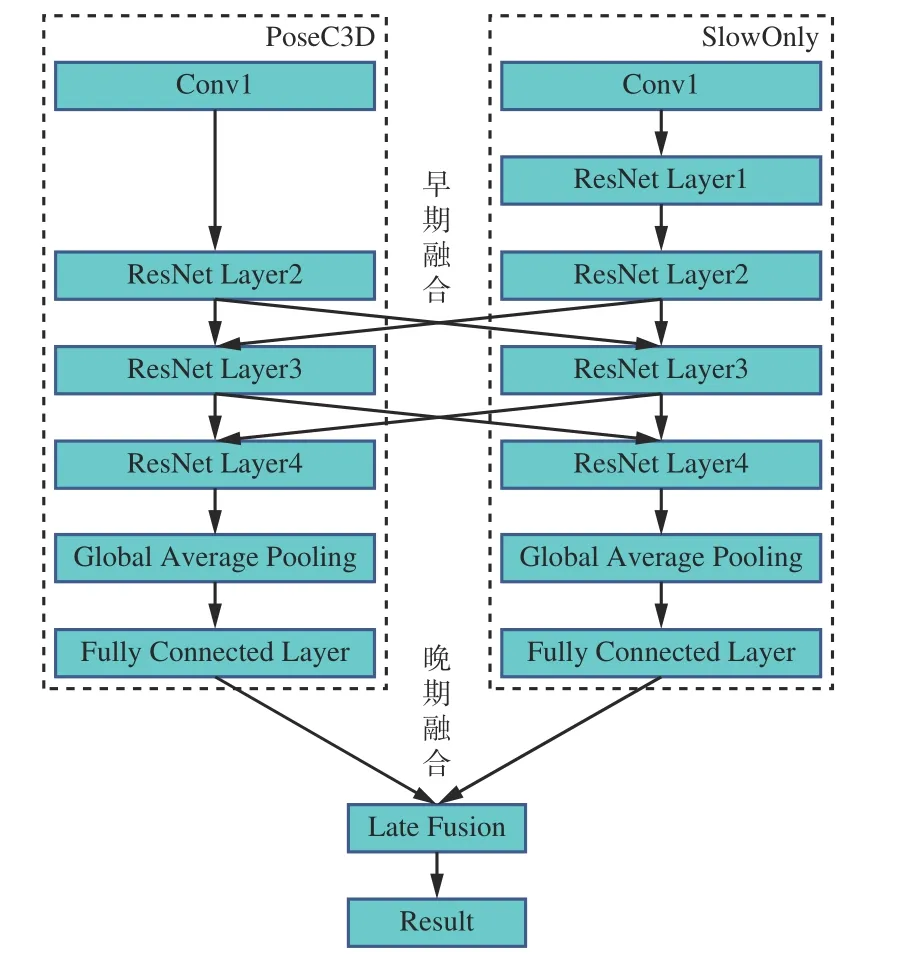
图7 多模态特征融合模型结构Fig.7 Structure of multimodal feature fusion model
4 实验验证与结果分析
4.1 实验数据集
分别在公开行为识别数据集NTU60 RGB+D[20]与自制井下不安全行为数据集上进行测试验证。NTU60 RGB+D 数据集是由新加坡南洋理工大学发表的公开行为识别数据集,由40 名演员参与拍摄,包含60 类行为,共56 880 个行为样本视频。该数据集包含2 种标准,X-Sub 与X-View。X-Sub 表示训练集与测试集按不同演员分配,其中20 名演员的行为视频作为训练集,剩余20 名演员的视频作为测试集。X-View 则是按不同的拍摄角度来划分训练集与测试集。
自制井下不安全行为数据集采集自矿井下实际拍摄视频,从固定机位对井下人员的10 类不安全行为进行采集,不安全行为类别及含义见表1。共采集了600 段视频,每类不安全行为有60 段视频,每段视频持续8 s 左右,帧速率统一为30 帧/s,其中75%作为训练集,25%作为测试集。
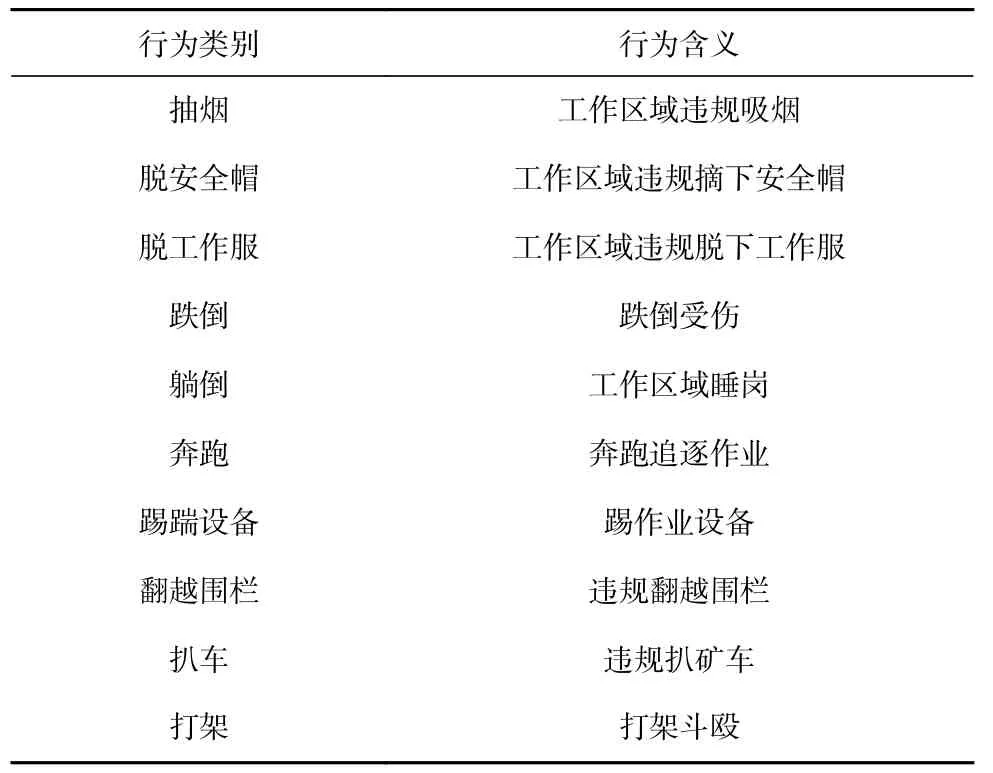
表1 不安全行为类别及含义Table 1 Categories and meanings of unsafe behaviors
4.2 实验方案
实验平台基于Ubuntu 18.04 操作系统,编程语言为Python3.8,深度学习框架Pytorch 版本为1.10.0,计算平台CUDA 版本为11.3,处理器为Intel Xeon Gold 6271,显卡为Nvidia Tesla P100-16G,内存为48 GiB。
分别在公开行为识别数据集NTU60 RGB+D 与自制井下不安全行为数据集上对基于多模态特征融合的行为识别模型进行验证,并与基于单一骨骼模态 的ST-GCN、2S-AGCN(Two-Stream Adaptive Graph Convolutional Network,双流自适应图卷积网络)[21]、PoseC3D 行为识别模型进行对比。训练开始前,通过预训练好的YOLOX 与Lite-HRNet 模型从数据集视频中提取人体骨骼点数据,作为识别模型的输入。行为识别模型训练参数设置如下:算法优化器采用SGD(Stochastic Gradient Descent,随机梯度下降法),初始学习率为0.1,采用余弦退火算法调整学习率,权值衰减系数为0.000 1,动量值为0.9,批处理大小为8,训练轮数为160。按照设置好的参数训练模型,并以行为识别模型在测试集上的最高准确率作为评价指标。
4.3 NTU60 RGB+D 公开数据集实验结果分析
在X-Sub 标准下的NTU60 RGB+D 数据集上实验验证,结果见表2。可看出,在基于单一骨骼模态的行为识别模型中,PoseC3D 的识别准确率高于GCN类方法,达到93.1%。这是因为GCN 类方法更易受骨骼模态数据中的噪声影响。基于多模态特征融合的行为识别模型的识别准确率比基于单一骨骼模态的行为识别模型高,达到95.4%。这是因为基于单一骨骼模态的行为识别模型注重提取人的运动特征,忽视了人与场景的外观特征,而基于多模态特征融合的行为识别模型能同时提取人的运动特征与外观特征。

表2 不同行为识别模型对比实验结果Table 2 Comparison experimental results of different behavior recognition models
在公共数据集上的实验基本验证了本文融合模型支流网络PoseC3D 的优秀识别能力,对比基于单一骨骼模态行为识别模型,基于多模态特征融合的行为识别模型拥有更好的特征提取能力与更高的识别准确率。
4.4 自制井下不安全行为数据集实验结果分析
在自制井下不安全行为数据集上进行实验验证,不同行为识别模型在测试集上的识别准确率随训练轮数的变化如图8 所示。可看出,随着训练轮数的增加,各模型准确率均增加。基于多模态特征融合的行为识别模型在第140 轮时收敛至93.3%,基于单一骨骼模态的ST-GCN 模型在第150 轮时收敛至77.3%,2S-AGCN 模型在第140 轮收敛至82.6%,PoseC3D 模型在第160 轮收敛至90.6%。上述结果表明,在井下不安全行为识别背景下,基于多模态特征融合的行为识别模型仍有较高的识别准确率,高于单一骨骼模态的行为识别模型,更适用于井下复杂环境下的人体行为识别。
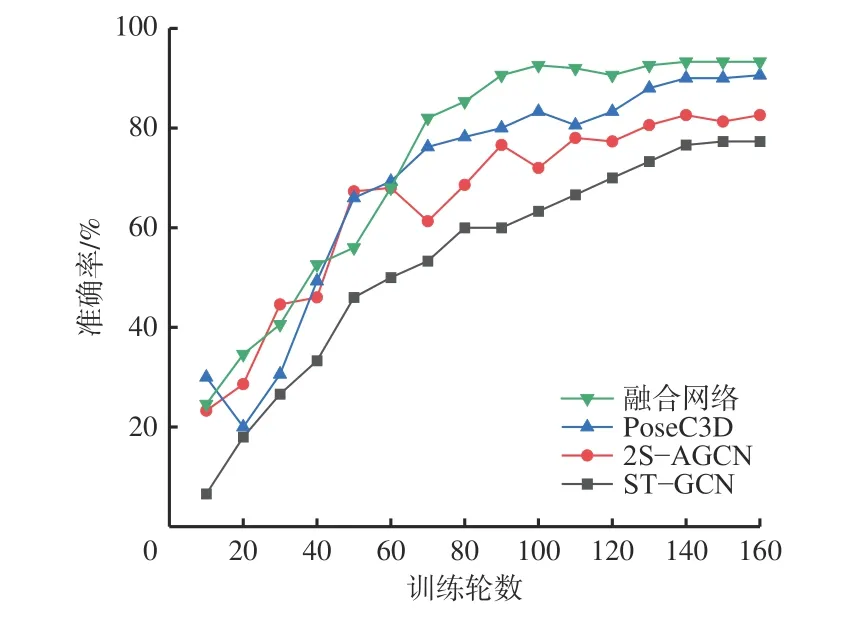
图8 不同行为识别模型准确率Fig.8 Accuracy of different behavior recognition models
基于多模态特征融合的行为识别模型对井下不安全行为的部分识别结果如图9 所示。可看出模型对较为相似的扒车与翻越围栏行为做出了准确的区分与识别,在多人识别场景下,对多人脱安全帽行为也能够准确识别。

图9 基于多模态特征融合的行为识别结果Fig.9 Behavior recognition results based on multimodal feature fusion
5 结论
1)针对井下复杂环境下人员不安全行为识别的问题,采用多模态特征融合的方法构建行为识别模型。通过SlowOnly 网络提取RGB 模态数据特征;采用YOLOX 与Lite-HRNet 来获取骨骼模态数据,并用PoseC3D 网络提取骨骼模态数据特征;对提取到的RGB 模态特征与骨骼模态特征进行早期融合与晚期融合,得到井下人员不安全行为识别结果。
2)在X-Sub 标准下的NTU60 RGB+D 公开数据集上的实验结果表明:在基于单一骨骼模态的行为识别模型中,PoseC3D 的识别准确率比GCN 类方法高,达到93.1%;对比基于单一骨骼模态的行为识别模型,基于多模态特征融合的行为识别模型拥有更高的识别准确率,达到95.4%。
3)在自制井下不安全行为数据集上的实验结果表明,在井下复杂环境下,基于多模态特征融合的行为识别模型识别准确率仍然最高,达到93.3%,对相似不安全行为与多人不安全行为均能准确识别。
