基于改进STDC 的井下轨道区域实时分割方法
2023-12-06马天李凡卉杨嘉怡张杰慧丁旭涵
马天,李凡卉,杨嘉怡,张杰慧,丁旭涵
(1.西安科技大学 计算机科学与技术学院,陕西 西安 710054;2.西安科技大学 安全科学与工程学院,陕西 西安 710054)
0 引言
近年来,随着我国煤矿智能化开采规模不断扩大,对井下运输安全化和智能化日益重视[1]。作为煤炭生产中一种重要的运输方式,矿井轨道运输若发生安全事故将严重影响生产效率。目前我国大部分井下轨道运输场景相对开放,在这种情况下存在作业人员、散落物料或煤渣侵入到轨道上的问题,这些因素都会给机车行驶带来威胁。因此,在有轨机车行驶过程中划定出轨道区域,并进行有效异物检测和决策判断非常必要,不仅可提高机车主动感知能力,且在辅助驾驶方面具有重要研究意义[2]。
在不同场景下,精准识别轨道区域已成为当前的研究热点之一。文献[3-4]采用传统的计算机视觉技术进行了相应研究,如边缘检测、Hough 变换、阈值分割等,以实现轨道区域的识别和分割。文献[5]提出了一种适用于井下复杂环境的轨道检测方法,该方法将图像片段进行灰度拉伸和边缘检测,并通过动态跟踪识别前一帧图像轨道来消除后一帧图像中的干扰。然而,该方法存在前后帧依赖性强、局限性较大、低光照条件下表现不佳等问题。文献[6]基于Hough 变换提出了极角极径约束法,在建立轨道感兴趣区域时考虑了轨道角度约束范围,从而有效提高了轨道检测效果。但由于算法复杂度较高,难以处理复杂环境下的检测任务。传统图像处理算法需要手工设计和组合复杂特征,大多数只适用于轨道以直线为主的理想情况。然而,实际矿井巷道环境复杂,传统算法在弯道、多轨交叉或目标轨道被遮挡的情况下,难以准确提取出轨道区域,且容易包含非轨道信息,使得检测性能不佳且鲁棒性差。因此,需要研究高效可靠的轨道检测方法,积极推进智能化驾驶在煤矿井下的应用,为煤矿智能化建设提供有力支撑[7]。
近年来,深度学习技术的快速发展和广泛应用为轨道检测领域带来了全新机遇。文献[8]提出了一种利用空间卷积神经网络检测轨道线的方法,该方法采用扩张卷积和改进空间卷积网络来整合不同尺度的上下文信息。然而,由于模型参数量较大,无法满足实时性需求。文献[9]为实现井下轨道线的实时检测,改进双边分割模型,并通过金字塔注意力模块获取更大感受野,以提高轨道检测精度。然而,在较为昏暗和过度昏暗环境中的误检率较高。此外,煤矿井下轨道区域多呈线性或弧形不规则区域,且轨道会逐渐收敛。使用目标识别框[10]或检测轨道线[11]的方法划分轨道区域难以精确获得轨道范围。因此,将轨道线检测问题视为对轨道区域进行整体分割的任务。相较仅检测轨道线,轨道区域分割具备更强的抗干扰能力和全局信息捕获能力,从而实现像素级别的精确轨道区域检测。文献[12]根据轨道结构特点,提出了改进BiSeNet[13]的实时语义分割网络,在原模型上添加子网络融合模块,进一步细化特征图。然而,与BiSeNet 相比,这种改进导致了帧速率的降低。煤矿井下轨道场景图像具有噪声大、目标像素占比少且边界不清晰等特点给轨道分割带来了极大挑战。
为解决上述问题,本文设计了一种基于改进短期密集连接(Short-Term Dense Concatenate,STDC)的轨道区域实时分割方法。首先,采用STDC 网络作为骨干架构,以降低网络参数量与计算复杂度。其次,采用判别语义特征的注意力模块来提升网络表征能力,同时利用双分支融合模块输出多层次特征,以提高模型的学习与表达能力。然后,在网络训练过程中,采用二元交叉熵损失、骰子损失和图像质量损失优化细节信息,生成细节特征图。最后,采集真实煤矿场景和模拟矿井的视频数据,构建煤矿井下轨道数据集,以进行训练与验证。
1 基于改进STDC 的实时分割方法
基于改进STDC 的实时分割方法的整体网络结构包括仅训练部分和训练及测试部分,如图1 所示。仅训练部分由细节损失(Detail Loss)、分割损失(Seg Loss)、细节头(Detail Head)和分割头(Seg Head)组成;训练及测试部分包含STDC 骨干网络、特征注意力模块(Feature Attention Module,FAM)和特征融合模块(Feature Fusion Module,FFM)。其中,STDC 骨干网络包括5 个阶段,第1,2 阶段仅使用1个卷积块提取低级特征;第3—5 阶段对特征图进行下采样操作,生成下采样率为1/8,1/16,1/32 的特征图。
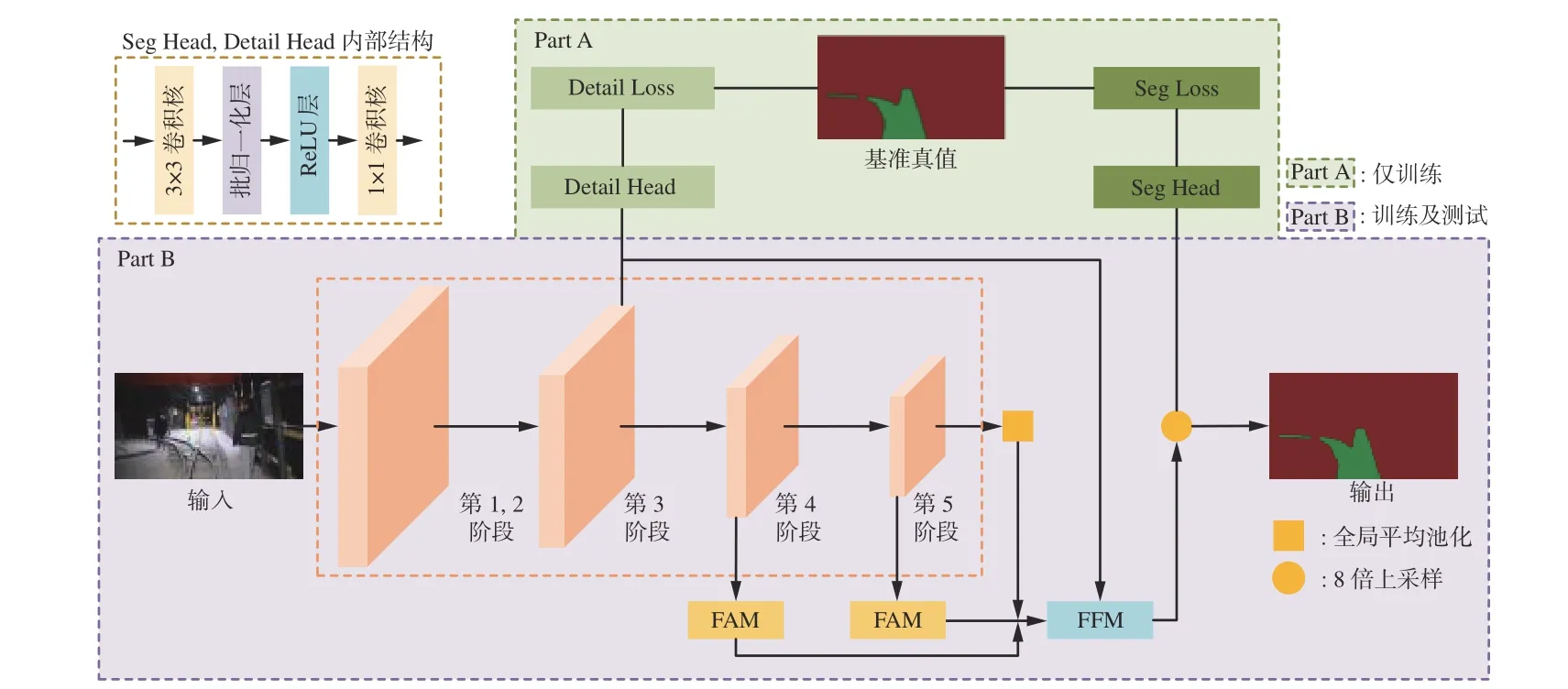
图1 基于改进STDC 的实时分割方法的整体网络结构Fig.1 Overall network structure of real time segmentation method based on improved short-term dense concatenate (STDC)
首先,对通过骨干网络处理后的特征图进行全局平均池化,获得全局上下文信息。其次,将第3 阶段输出的低层次细节信息输入FFM。第4,5 阶段输出的特征图经FAM 处理后与全局上下文信息融合,为FFM 提供高层次语义信息。最后,FFM 输出的特征图通过8 倍上采样进入Seg Head。Seg Head 包括1 个3×3 卷积核、批归一化和ReLU 操作,以及1 个1×1 卷积核,并在最终输出维度方面进行调整。Seg Loss 使用二元交叉熵损失函数来优化语义分割学习任务。
为了增加第3 阶段输出特征图中的细节信息,以更好地与上下文路径分支捕获的高层次语义特征相结合,在该阶段引入了Detail Head。Detail Loss 通过采用二元交叉熵损失、骰子损失和图像质量损失对细节信息进行学习任务优化,生成细节特征图。在预测语义分割结果时,将来自底层的空间细节和深层次的语义信息进行融合。需要注意的是,在训练过程中仅使用Detail Head。
1.1 STDC 模型
为了减少特征提取过程的参数量,提出了STDC模型,其结构如图2 所示,其中ConvX表示“卷积+批归一化+ReLU 激活函数”的结构,M和N分别表示输入和输出特征图的数量。在STDC 模型内部没有进行下采样操作,随着卷积次数的增加,卷积核通道数量逐渐减少。参照BiSeNetV2[14],在处理深层高级语义信息时使用较少通道数,在处理浅层空间细节信息时使用较多通道数,以避免冗余信息的产生。在多级特征提取后,STDC 模型的输出为各级特征的融合。

图2 STDC 模型结构Fig.2 Module structure of short-term dense concatenate(STDC)
式中:xoutput为STDC 模型的输出结果;F(·)为融合操作;(x1,x2,···,xn)为n个特征映射。
将各级卷积块的输出特征组合,STDC 通过通道拼接实现多尺度信息的提取,同时保持较低的计算量。
1.2 FAM
STDCSeg[15]中的注意力细化模块使用全局平均池化来捕获全局上下文特征,但该模块无法针对性地关注局部特征信息,在应用于井下场景时,可能出现分割结果边缘模糊、小目标分割效果不佳等问题。因此,设计了FAM(图3),该模块利用通道间关系来突显通道级别的有效语义特征并抑制无效的语义特征,以降低矿井图像中混淆物体之间的类别相似性。首先,将大小为H×W×Cin(H,W,Cin分别为输入特征图的高度、宽度和通道数)的特征图Fin分别通过2 种池化方式生成全局平均池化特征图Favg∈R1×1×Cin和最大池化特征图Fmax∈R1×1×Cin。接着,使用1×1 卷积将Favg和Fmax连接并降维到R1×1×Cout/r,其中Cout为输出特征图的通道数,r为减速比。然后,应用ReLU 非线性激活函数以避免梯度消失,并利用1×1 卷积作为增维层返回通道数Cout。最后,使用Sigmoid 函数对卷积结果进行激活,得到权重向量V∈R1×1×Cout。同时,引入残差网络思想,将输入特征图Fin通过1×1 标准卷积进行校正通道数量得到特征图映射F′∈RH×W×Cout。最终,将权重向量V乘以特征图映射F′得到输出特征图Fout∈RH×W×Cout。
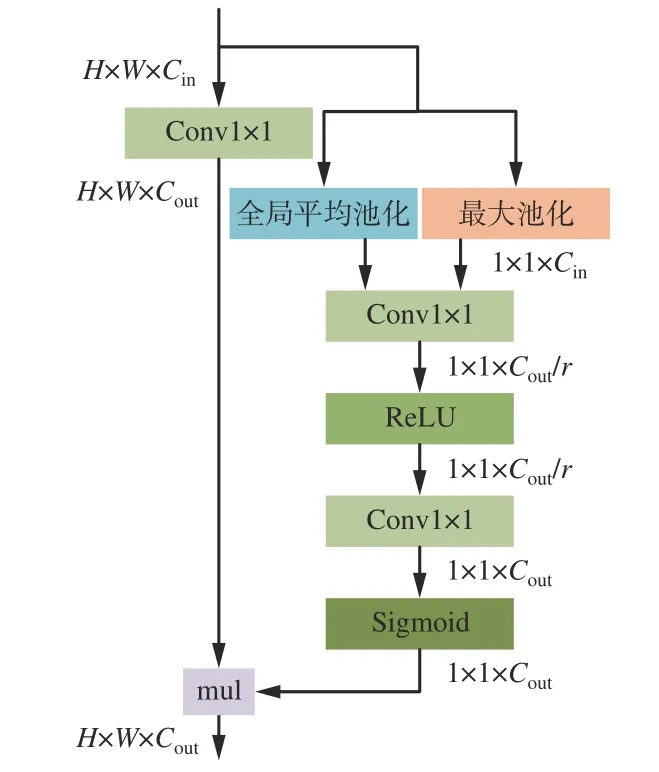
图3 FAM 结构Fig.3 Structure of feature attention module(FAM)
1.3 FFM
借鉴STDCSeg 特征融合模块的思路,本文方法将上下文路径和细节引导路径的输出特征进行连接,并计算权重向量,以实现特征向量的合并。为了增强特征图的表达能力,本文引入了空间维度信息到FFM(图4)中,可使双路径输出具备不同层次的特征表示。
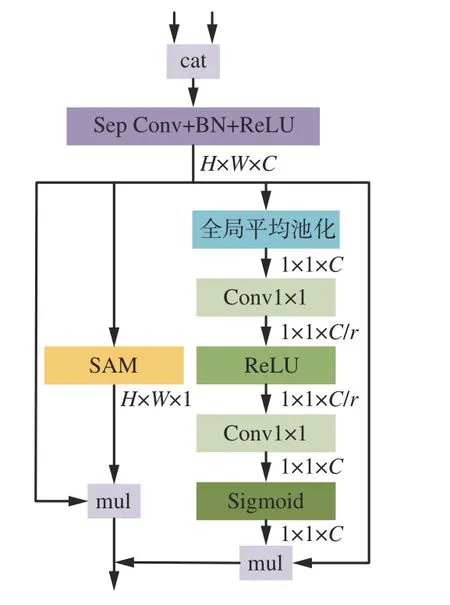
图4 FFM 结构Fig.4 Structure of feature fusion module(FFM)
首先,连接上下文路径和细节引导路径的输出特征,并使用批归一化来平衡特征的尺度。使用深度可分离卷积来减少参数量和计算量,得到初步融合特征X∈RH×W×C,其中特征图的输入、输出通道数C保持不变。然后,将特征图输入通道注意力机制部分,通过全局池化并经过1×1 卷积降维操作后应用ReLU 函数引入非线性,得以计算出权重向量Vchannel∈R1×1×C。最后,使用Vchannel对输入X重新加权,得到通道路径特征图Fchannel。
空间注意力模块[16](Spatial Attention Module,SAM)利用像素之间的关系来计算权重,以表示输入特征中每个像素的重要性。首先,在通道维度上对X生成全局平均池化特征图Farg∈RH×W×1和自适应全局池化特征图Fmax∈RH×W×1,将其拼接整合,经过标准卷积和Sigmoid 激活函数得到空间注意力权重向量Vspatial∈R1×1×C。然后,使用该特征图重新加权输入X,得到空间路径特征图Fspatial。最后,将通道路径和空间路径生成的特征图串联以完成特征融合。
2 实验分析
在深度学习框架飞桨(Paddlepaddle)下进行模型实验,实验环境为Windows 10 系统,硬件设备CPU为Intel(R)Core(TM)i7-10700K 处理器,并使用单NVIDIA RTX 3060 显卡加速运算。为了加快网络对训练的适应速度,采用学习率为10-3的随机梯度下降优化器进行参数优化,输入大小为1 024×512 的图像,批大小设定为8,迭代次数为10 000,权重递减为4.0×10-5。
2.1 数据集构建
由于当前没有公开的煤矿井下轨道数据集,为评估本文方法的性能,自建了专用数据集。该数据集包括真实矿井的监控视频数据和西安科技大学模拟矿井的车头车况视频数据,通过提取视频帧筛选得到700 张煤矿井下轨道图像,其中真实矿井监控图像310 张,模拟矿井图像390 张。使用基于Paddlepaddle 开发的交互式分割标注软件EISeg[17]对轨道目标进行标注。标注图像涵盖了直线轨道、曲线轨道、遮挡轨道等多种轨道类型。利用Python 图像增强工具Augmentor 库,对图像进行随机翻转、缩放变形、亮度增强和对比度增强等变换。增强后的数据集包含1 400 张图像,图像分辨率大小统一处理为1 024×512,并将其按7∶2∶1 的比例随机划分为训练集、验证集和测试集。
2.2 评价指标
在设定的参数条件下,将模型在数据集上进行训练,并使用平均交并比(Mean Intersection over Union,MIoU)来评估轨道分割方法的准确性。当MIoU 趋近于1 时,推断模型性能较优。
式中:M为MIoU;k为标注类别总数量;i为标签类别个数;NTP为被预测为正样本的正样本数量;NFN为被预测为负样本的正样本数量;NFP为被预测为正样本的负样本数量。
帧速率(Frames Per Second,FPS)指标用于衡量轨道分割方法的推理速度,即模型每秒处理的图像帧数,较高的帧数表示模型具有更快的处理速度。参数量(Params)用于衡量模型大小。准确率表示分割结果中被正确分类的像素数与总像素数之比,准确率越高,说明分割结果中被正确分类的像素越多,即分割性能越好。
2.3 消融实验
为验证FAM、FFM 及优化损失函数的有效性,在保持主干网络STDC 不变的情况下,采用MIoU和Params 作为评价指标,在自建数据集上进行训练和验证。消融实验结果见表1。
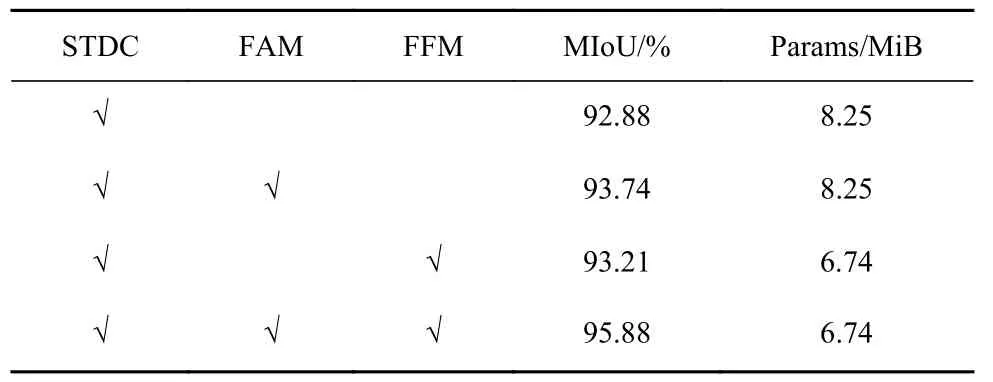
表1 消融实验结果Table 1 Results of ablation experiment
由表1 可看出,在STDC 中加入FAM,MIoU 为93.74%,这是因为FAM 将全局池化操作和最大池化操作结合,能够更加关注训练中的特征信息,并提升网络表达能力。在STDC 中加入FFM 时,MIoU 为93.21%,Params 为6.74 MiB,较STDC 降低了18.3%。这是因为FFM 将注意力机制扩展到特征融合领域,在有效融合高层次语义信息和低层次空间信息方面发挥着重要作用,并显著提升网络性能。在STDC中加入FAM 和FFM,MIoU 达95.88%,同时Params达6.74 MiB,较STDC 降低了18.3%。
在训练过程中使用2 个Head 输出计算损失。对于井下轨道区域识别的Seg Loss 部分,采用二元交叉熵损失函数(Binary Cross Entropy Loss,BCELoss)来区分正样本和负样本。然而,在进行前景与背景的细节预测Detail Loss 时,如果背景元素数量大于前景元素数量时,仅使用BCELoss 会造成模型严重偏向背景,而对模型训练和预测效果产生影响。因此,本文加入骰子损失函数DiceLoss 和结构相似性损失函数(Structural Similarity Index Loss,SSIMLoss)共同优化细节学习。其中,DiceLoss 可缓解样本中前景背景(面积)不平衡带来的消极影响,SSIMLoss则能有效地捕获图像中的结构信息。
基于Paddlepaddle 的可视化工具VisualDL 对整个训练过程进行记录。损失函数优化结果如图5 所示,可看出随着迭代次数增加,本文模型损失函数值持续减小,且较原始模型降低更为显著。说明本文方法不仅拟合速度更快,且指标增长更明显。
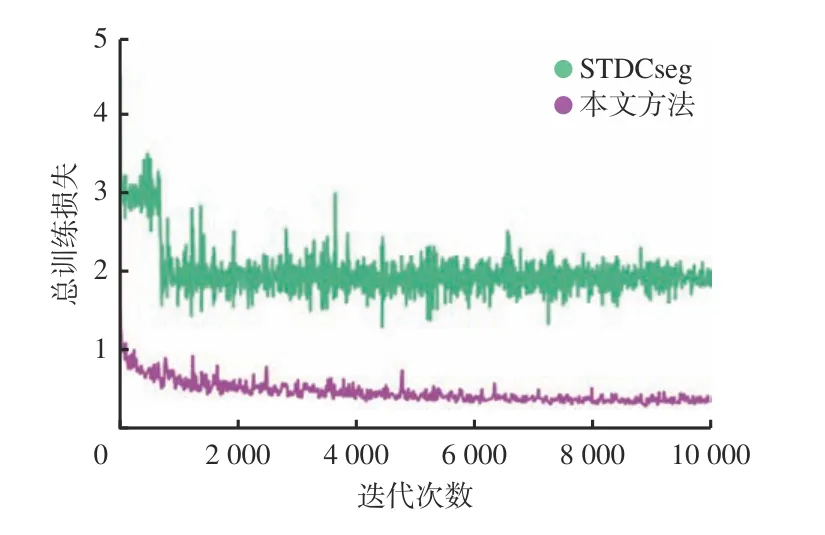
图5 损失函数优化结果Fig.5 Loss of the function optimization results
2.4 对比实验
为验证本文方法的分割性能,在自建数据集上将其与ENet[18],SegNet[19],Deeplab3v+[20],BiSeNetV2,SFNet[21],STDCSeg 6 种经典分割方法及文献[12]的井下轨道分割方法进行对比,结果见表2。可看出本文方法MIoU 达95.88%,FPS 为37.8 帧/s,准确率为99.46%。与其他分割方法相比,本文方法的MIoU 分别提升了20.04%,11.57%,5.16%,13.78%,1.61%,3%,8.69%,FPS 分别提升了14.5,20.2,28.6,6.5,11.2,5.5,7.1 帧/s,Params 为6.74 MiB,略低于ENet、BiSeNetV2和文献[12]方法。这是因为FAM 能够捕获通道之间的依赖关系并突出分割对象,从而减轻了冗余特征对准确性的影响,进而取得更出色的分割结果。本文方法能够在资源有限的情况下有效执行分割任务。SFNet 的MIoU 为94.27%,其优势在于通过语义流对齐不同层之间的特征,使高级特征图上的低分辨率语义信息能够有效传递至低级特征图中。然而,SFNet 的FPS 仅为26.6 帧/s,在满足实时需求方面有所欠缺。此外,文献[12]方法的MIoU 较BiSeNet提高了5.09%。然而,与本文方法相比,并没有明显的优势。尽管ENet 的Params 最少,但其MIoU 仅为75.84%,分割效果不佳。因此,本文方法在满足实时需求的同时,在分割效果上也取得了显著提升,更适用于井下轨道分割任务。
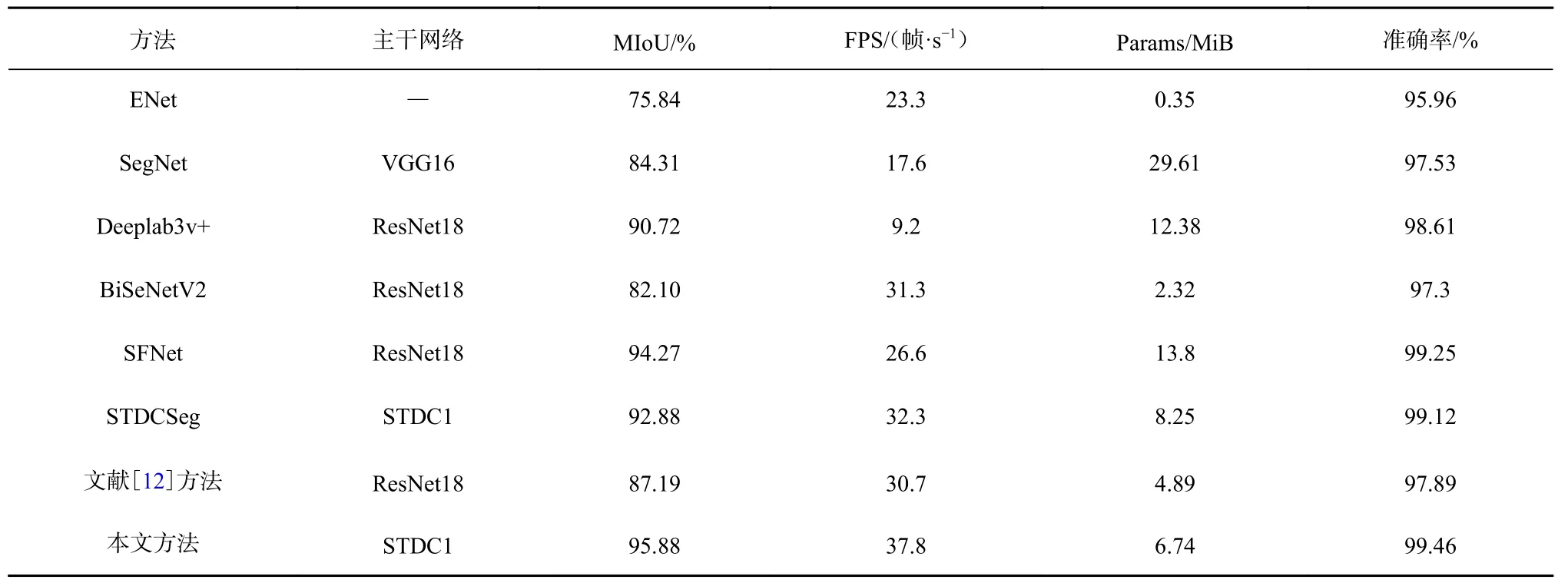
表2 不同方法的轨道分割性能Table 2 Track segmentation performance of different methods
不同方法的轨道分割效果如图6 所示,其中绿色表示轨道区域,红色为背景。通过与原图像和真实标签对比可看出,其他方法在不同程度上出现了分割不完整或错误分割的情况:SFNet 的分割结果较理想,但其对遮挡轨道分割效果略差于本文方法;ENet 未能正确地分割出轨道区域,且其边缘粗糙;SegNet、BiSeNetV2 和文献[12]方法在处理图像边缘时表现欠佳,导致边缘分割效果也不理想;STDCSeg在轨道区域上具有良好的分割效果,但存在误检情况。本文方法可完整识别轨道区域,轨道被准确分割且边缘轮廓完整准确。这是由于FFM 能够更好地将浅层特征信息融入高级语义特征中,在补充丢失信息的同时,利用通道与空间注意力机制丰富融合特征,从而大幅度提高模型的学习与表达能力。本文方法能够更好地应对井下场景中的复杂背景、光照变化和噪声等因素,提高了分割结果的泛化性和准确性。

图6 不同方法的轨道分割效果Fig.6 Track segmentation effect of different methods
3 结论
1)提出了一种适用于井下轨道区域的实时分割方法。通过采用STDC 网络和多个模块来优化网络性能,其中包括用于判别语义特征的FAM 及用于有效特征融合的FFM。
2)基于煤矿井下轨道数据集训练改进STDC 的分割模型,其MIoU 达95.88%,FPS 为37.8 帧/s,参数量大小为6.74 MiB,准确率为99.46%。该模型在精度和速度之间取得了良好平衡,并展现出优秀的分割结果。
3)尽管实时分割模型在准确率和推理速度方面取得了领先,但该方法的模型复杂度略低于ENet。在未来的工作中,将考虑设计更轻量级、更高效的编码器模块、注意力模块以改进模型。
