一种基于聚类分析的最近邻分类算法
2023-12-02杨海娟
杨海娟
(兰州职业技术学院电子信息工程系,甘肃兰州 730070)
1 研究背景
分类是机器学习、数据挖掘等领域的一个重要研究方向。分类通过对现有的数据进行学习,掌握数据中潜在的规律,给决策、商务应用、医疗保健和生命科学、目标识别及安全认证等领域提供了更有效的支持,各种分类算法的研究具有重要的理论研究意义及实际应用价值。一般情况下,分类是一个有监督的学习过程,一个分类算法一般分为两阶段,第一阶段训练分类器,利用带标签的数据,训练产生一个分类器,第二阶段就是将得到的分类器应用于实际的生产环境。机器学习、数据挖掘领域考虑的多是第一个阶段的问题,即选用何种模型,如何进行训练以得到最好的分类器。
K-近邻算法(KNN)是一种经典分类算法,被国际数据挖掘会议评选为机器学习的十大经典算法之一,它是一种惰性分类算法,没有训练过程,该分类方法首先简单地把训练样本储存起来,分类时通过计算测试样本和每个训练样本的相似性,然后找出k个最近邻样本,对k个最近邻样本的标签进行投票,以投票的方式决定自身的标签。KNN算法思想简单,准确率相对较高,广泛地应用于各种分类问题,对维度很高的数据也可以正确分类,尤其适合于多分类问题,但是KNN在样本容量分布不均匀时,表现出更倾向于大容量样本,而且如果样本容量大,所需的计算量大,效率低。针对这一问题,本文提出了一种基于聚类分析的最近邻方法,其分类器准确率接近甚至优于KNN 方法,可以极大地提高分类效率。
本文剩余部分的章节按如下结构进行组织。第2节回顾KNN方法相关的文献,第3节详细阐述本文提出的算法的思想,第4节给出实验过程,并对实验结果进行详细分析,本文最后以第5节的结论作为结尾。
2 相关工作
由于分类具有重要的意义及实用价值,研究人员已经提出了大量的分类方法,例如决策树[1]、贝叶斯分类器[2]、神经网络[3]、SVM[4]、Adaboost 分类器[5]以及深度学习方法[6]等。其中KNN 是一个典型的惰性分类方法,如前所述,在KNN算法中,要计算待测样本和每个样本的相似性,一旦数据分布不均,大类别样本就会占有密度优势,某个类别的样本数量大,会增加预测结果成为该类的可能,某个类别样本容量太小,则有可能大大减少成为该类的可能。随着分类数据的不断快速增长,大数据分析与挖掘技术被广泛应用于各个行业,因为KNN需要大小和样本个数n一样的线性复杂度来计算距离完成分类,需要较大的内存开销,分类时间开销大。即使如此,由于KNN 算法简单,易于实现,具有较高的分类准确率,因此为了提高KNN的分类准确度和效率,多种尝试提高该算法效率的方法被提出。文献[7]提出了一种基于将原始样本替换为新的样本集合从而建立分类模型的方法,减少了KNN算法需要进行相似计算的样本数,从而达到提高分类速度的目的。文献[8]通过基于熵的改进距离计算,基于加权距离的分类确定和定量转换来改进KNN算法,克服了传统KNN 算法的缺点。文献[9]构建了一种基于KNN 的快速分类算法,减少了大量计算,保持了相同的准确率,提高了分类的速度。很多的算法都一直致力于提高KNN的运算效率。
针对KNN算法无训练的特点[10-11],本文对KNN引入一个训练过程,提出了一种新的分类方法。首先,在训练阶段,对每个类通过聚类进行分类,在每个分得的更小的类中求出一个具有代表性的虚拟样本,此虚拟样本就是由本类中所有样本的均值构成的一个“中心样本”,作为本类别的代理,也称之为代理样本。数据集有多个类别,每个类被分为多个更小的类,每个小的类别都有一个代理样本,因而形成一个代理样本集合,在测试阶段,每个测试样本按照KNN算法进行分类,由于每个代理样本已经有很强的代表性,不需要对多个最近代理样本投票进行选择,所以取K值为1进行分类。
本文提出了一种名为BCNNC(Nearest Neighbour Classifier based on Cluster Analysis)的算法,实验表明,该算法适应性强,能对分布不规则但是类别之间差异较大的数据集进行很好的分类,而对于有些数据集,能在提高效率的情况下和KNN有近似的表现,在有些数据集上甚至超过了KNN的分类效果。
3 BCNNC算法
3.1 算法的提出
机器学习中样本分类的基础是“类内样本间相似度高,类间样本的相似度低”,如图1所示的数据集有3个类,均为二维特征的数据集,可用距离代表其相似性,距离越近的样本越相似。通过观察发现,3个类内部样本分布密集,距离较近,类之间样本距离较远,此三种类别的数据之间差别较大,考虑从每个类找出一个“中心样本”作为每个类的代表,测试样本分类时,用每个类的代表与测试样本之间求相似性,那个类代表和测试样本最相似,就认为测试样本是属于这种类代表所在的类别,执行KNN算法。通过在UCI数据集Iris和Wine上测试,发现其效果与KNN近似。当数据集中两类数据如图2所示的环形分布模拟数据集或者其他数据集上测试,发现此方法完全失效,因为两个类的代理样本很相似,测试样本根本无法以此代理为参考来分类,此时类代理显然失效,如何找出每个类中真正的代理是这种方法是否有效的关键。
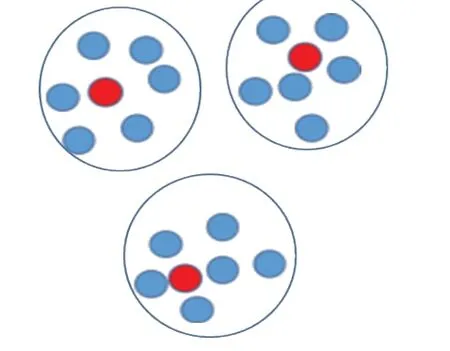
图1 类的代理样本示意图

图2 环形的代理样本示意图
通过观察发现,在环状分布的类样本中,如果再次分类,将每个大类分成若干个小类,再找到合适的代理样本,测试样本通过这些代理样本找到自己所在的类。这就好比在众多图片中分出人的图片,经常使用的办法不是直接确定此图片是不是人的图片,而是从众多图片中找出男人、女人、小孩、老人等具体的人中的一个小类别,最终就找出了所有人的分类,所以对于每一类数据样本来说,都可以考虑对其进一步分类,以帮助人们更好的确认测试样本的分类。
根据上述事实,将每一类训练样本进行聚类,分成更小块的类,如图3所示。从每块小分类中找出各自的代理样本,接着再以代理样本集合作为KNN的训练样本,设置k 值为1,执行KNN 算法,此时每个小分类的虚拟代理都可以更好地代表自己所在分类的特性,接着再执行KNN算法会得到较好的分类效果。

图3 类内部分类后的代理样本示意图
3.2 算法的设计
本算法分为两步实现,第一步是训练阶段,先对数据进行标准化处理,然后将训练集中的每个类分块,本方法以聚类的方法在类内分块,聚类的方法很多,如基于划分的K-means 算法,基于层次的BIRCH算法[12]和基于密度的DBSCAN 聚类算法[13],本文采用了K-means++算法[7]进行类内聚类,将类分成小的分类,选出每个小分类中的代理样本。当样本数量很大时,如果待分类样本能处理成以类别为单位,则可以考虑对每个类别并行分类,找出代理样本集合。第二步为测试阶段,将测试样本进行分类,此阶段求出距离测试样本最近的代理样本,将测试样本的类别确定为和此代理样本的标签一致。
1)数据的标准化(normalization)
数据标准化有很多种方法,最具代表的是数据的归一化处理,文献[14-15]指出,样本数据归一化可以加速学习训练速度并提高分类精度。将数据按比例缩放,使之落入一个小的特定区间。确保各种数量级的特征都会对目标的分类起到各自的作用,即将数据统一映射到[0,1]区间上,归一化计算方法如公式(1)所示:
2) K-means++算法
K-means 算法是一种选择多个中心点作为质心,根据待聚类点离质心点的距离来聚类,离质心近的点将被聚为一类,该算法的聚类结果是球状的,这种分类结果适用于本文所提出的分类算法。然而由于原始K-means算法中心点随机选择的改进,如果初始点的位置选择不当(例如都在一个簇里面),那么其最终的聚类结果将可能很不理想。
K-means++则按照如下思路选择K 个初始中心点:假设已经选取了n 个初始聚类中心(0<n <K),则在选取第n+1 个聚类中心时:距离当前已有的n 个聚类中心越远的点会有更高的概率被选为第n+1 个聚类中心。在选取第一个聚类中心(n=1)时同样通过随机的方法。当然这也非常容易理解:聚类中心当然是相互离得越远越好。
算法1 K-means++算法:
输入:数据集,聚类个数K
输出:K个簇数据的集合
过程:
Step 1:从数据集中随机选取一个样本点作为初始聚类中心C1;
Step 2:首先计算每个样本与当前已有聚类中心之间的最短距离(即最近的聚类中心的距离),用D(x)表示;接着计算每个样本点被选为下一个聚类中心的概率p。最后,按照轮盘法选择出下一个聚类中心;
Step 3:重复第2步直到选择出K个聚类中心;
之后的步骤同原始K-means聚类算法相同。
算法中任一样本点x被选为下一个聚类中心的概率由公式(2) 决定,通过实验表明使用聚类算法Kmeans++相比K-means聚类结果稳定性较高。
3)算法2 BCNNC算法:
输入:数据集Dataset,分类标签Label,类内分类个数X
输出:分类正确率
Step 1 输入数据集,输入X,根据X计算类内分成的类别个数C;
Step 2 在每个类内部用K-means++聚类,得到每个训练数据所在的小类编号,并记录小类的编号和所在大类的对应关系kind数组;
Step 3 根据每列属性的平均值,求出每个小类的代理样本,得到一个means数组;
Step 4 以means 数组作为训练样本,输入测试数据,执行KNN(k=1)算法,得出小类的编号;
Step 5 根据kind 数组对应的大类编号,确定测试样本所在的最终类别。
4 实验结果与分析
4.1 实验数据集
4 个人工合成数据集、5 个UCI 数据集及UCI 中3个手写数字及2个图像数据集,如表1~表3所示:

表1 4个人工合成数据集
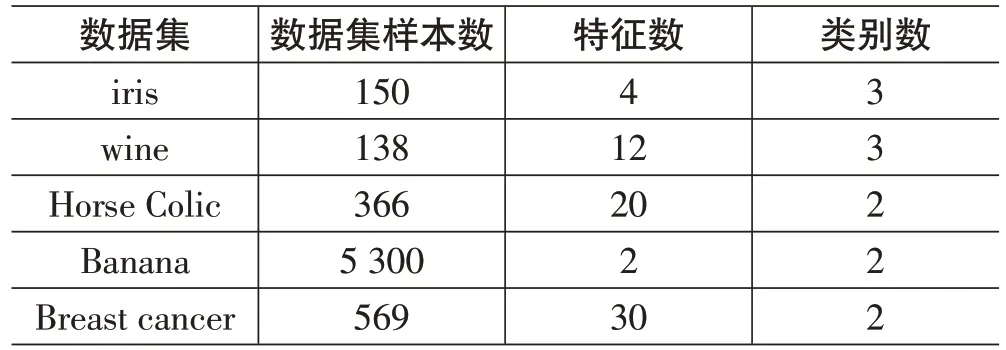
表2 5个UCI数据集

表3 UCI中3个手写数字及2个图像数据集
4.2 算法参数
本文选择的KNN 算法都是在K=3 的情况下的执行结果,而本文提出的算法中每个分类的分块个数C则是由数据集的大小来决定,每个类的分类个数和其样本数成正比,样本数多的分得类别也多。分类个数从每个类只有一个小类,逐渐增加每个类的分类个数,当每个类分成的小类数目跟样本数一样多时,算法则退化成KNN算法中K=1的情况。
4.3 实验及分析
实验分为3个阶段,分别是人工合成数据集,5个UCI数据集、手写数字和图像数据集,每个数据集在实验时都会在每个类内部分类,在分类个数C不同的情况下进行多次实验,并对实验结果进行分析,对同样的数据集同时执行该算法和KNN(k=3),进行了20 次实验,正确率求平均值。
首先在4 个合成数据集上展开了实验,通过模拟产生数据集,每个数据集经过20次执行求其平均值,执行K-means++把每个类聚成10个小类,求平均正确率,结果如图4 所示,本文的算法和常见的分类算法KNN、Linear SVM、RBF SVM,Decsion tree、AdaBoost 进行了正确率比较,表现均和KNN 接近或超过KNN,circle 数据集的分类效果较差。表明此算法在线性不可分的数据集上表现良好。
接着在UCI 的5 个数据集上展开对比实验,在Iris、Wine、Breast Cancer、horse、banana 这些数据集上进行了验证,Iris 数据集和Wine 数据集本来为3 类,在对每个类不分类或分成2 个小类时,Breast Cancer数据集为两类,在分成11 类时,Iris 和Wine 数据集不用划分成更小的类就可以超过KNN的精度,Banana共有两类,在被分为130类时,因为样本数目为5 300,如果直接运行KNN 需要5 300 次距离运算,而在本算法中只需要130 次距离运算,Breast Cancer 数据集只需要计算11 次,减少了400 多次距离运算,Banana 数据集只需要130 次距离计算,减少了4 000 多次距离计算,由于这些数据集只经过较少的运算就超过了KNN的精度,速度远远超过了KNN,证实了在类内再能细分的数据集上,或者类和类之间差别比较大的数据集上,用此算法可进行高效的分类。
最后,在手写数字数据集Pendigits、Digits、Letter、Image和Magic04数据集上,本文提出的算法在大多数数据集上识别的正确率优于KNN 算法,或者与KNN算法结果相似,实验结果如表4所示,C表示被划分成的小类的总个数,每2~5个数据分成1个小类,也保持了和KNN近似的正确率,表明这种对细节要求更高的数据集中,2~5 以上的样本形成一个小类,才能和KNN的效果保持一致,当每1个样本分成1个小类时,该算法退化为KNN算法。

表4 BCNNC算法和KNN算法在手写数字和图像数据集上的实验结果
5 总结
本文提出了一种在训练集类内聚类的BCNNC分类算法,通过在数据集类内继续分类发现,分成小类后再执行KNN算法与直接执行KNN算法得到相似的结果,有时甚至超过KNN算法的分类精度。通过前两个阶段的实验表明,对那些类间区别较明显但是对类样本分布线性不可分的数据集,采用BCNNC 分类算法后,可以有效地提升分类精度和分类速度。一种数据集分成多少小类,要通过尝试和选择,对于第三个阶段的数字识别和图像识别的数据集,样本分类时要根据样本的形状和细节进行分类,多个样本分成小类,由一个虚拟样本来代替多个样本的特征并不适合,采用此方法并没有显著的提高速度,当数据集由2~5个以上样本聚成一小类,会得到和KNN基本相似或者优于KNN 的分类精度,并且执行效率高于KNN分类算法。综上所述,本文提出的方法适用于类间区别较明显,类内能再细分的数据集分类。
