基于空洞空间金字塔池化U-Net的遥感图像多目标检测方法
2023-11-28张善文许新华齐国红
张善文,许新华,齐国红
(郑州西亚斯学院电子信息工程学院,河南 郑州 451150)
0 引言
从遥感图像(RSI)中检测飞机、舰船和油罐等目标对战场侦察、无人作战以及防御警戒等方面有着重要的作用。由于RSI中小目标具有视角宽、目标占比小、背景复杂以及目标容易产生缩放、扭曲等现象,使得RSI中目标检测一直是一个重要且具有挑战性的研究课题[1-3]。传统的RSI目标检测算法依赖于从每个RSI中提取的特征,但由于RSI的多样性,很难从每个RSI中提取鲁棒的特征,而且提取的低级特征及其特征组合不足以表达各种各样的RSI小目标,容易出现目标错检、漏检、以及检测精度低、无法解决小目标检测等问题[4-6]。
卷积神经网络(CNN)及其改进模型能够从复杂图像中提取丰富的语义特征,广泛应用于RSI目标检测任务中,取得了显著效果[7-9]。宋晓茹等[10]总结了基于深度学习的目标识别技术的发展现状和目前主流的6种CNN改进模型Mask R-CNN,GAN+deep Forest,DRFCN,E-MobileNet,SSD300和YOLO及其相关网络结构、改进模型和实际应用,并展望了未来的发展趋势。Tu等[11]提出了一种通过同时优化显著目标边界来学习鲁棒多尺度区域特征的模型,并结合局部线索和金字塔池生成的全局信息生成边界特征。周秦汉等[12]提出了一种基于多尺度特征增强CNN的遥感目标检测算法。该算法由特征提取模块、特征增强模块、自注意机制和金字塔特征注意机制组成。在DOTA数据集上的实验结果表明,该算法通过对不同卷积层特征的增强和融合,具有较快的训练速度和较高的检测精度。Zheng等[13]提出了一种改进的YOLOv4-CSP网络,用于遥感图像中的旋转目标检测。该网络通过为所有锚点分配具有代表性的角度进行训练,将锚点调整到ground-truth边界框,有利于降低网络的复杂性。在HRSC2016,UCAS-AOD和SSDD+三个遥感数据集上的实验结果验证了该方法的有效性。U-Net是一种结构比较简单的U型全CNN模型,可以用少量有注释的训练样本达到更好的分割效果,已被广泛应用于医疗图像检测与分割任务[14]。在U-Net中加入注意机制能够学习特定的特征并抑制不需要的特征[15]。张善文等[16]构建了一种基于轻量级注意力U-Net的遥感图像飞机检测方法。该方法利用了轻量化、多尺度卷积、残差连接、注意力和U-Net等优点,从U-Net中提取不同尺度的特征图,然后通过残差拼接将编码特征与相应的解码特征融合,增加了飞机检测的细节,提高了对小型飞机的检测精度。Mu等[17]提出了一种基于VGG-16与U-Net相结合的轻量级网络的遥感图像场景分类方法。该方法在保证模型准确性的同时,极大减少了模型参数,提高了模型的分类速度和收敛速度。
尽管基于U-Net及其改进模型的RSI目标检测方法极大提高了检测精度,但由于U-Net通过跳跃连接仅拼接了每次池化操作前最深一层的特征图信息,忽略了包含较大尺寸以及具有更加丰富细节信息的浅层特征,所以容易丢失目标细节信息。虽然深层网络能够得到图像的深层次细节信息,但由于RSI中的目标本身过小,使得深层网络中经多次下采样处理后容易导致较小目标被漏检。由于遥感图像分辨率比较低、包含的目标比较模糊、小目标携带的信息较少等因素导致RSI中的小目标的特征表达能力弱而被丢失。空洞卷积能够扩大感受野而不增加模型的参数量[18]。空洞空间金字塔池化(DSPP)通过不同的空洞卷积核能够提取多尺度目标特征,极大提高模型的检测率[19]。
针对传统RSI目标检测方法对复杂背景和不同尺度目标检测效果不理想的问题,文中提出一种基于空洞空间金字塔池化的U-Net的遥感图像多目标检测方法。该方法利用空洞多尺度卷积和空洞空间卷积池化金字塔结构提取RSI中目标的多尺度分类特征,利用注意力模块有效地从背景复杂的RSI中提取到特定的特征,学习空间层面上RSI目标的像素的关联性,并在公开数据集上进行实验验证。
1 空洞空间金字塔池化(DSPP)
空洞卷积可以任意放大各个CNN层卷积核大小。空洞率为R的空洞卷积在卷积核元素之间引入(R-1)个零,在不增加参数数量或计算量的情况下有效地将k×k卷积核的大小扩大为k+(k-1)(R-1),能够提供一种有效的机制控制卷积感受野。设置不同R使得卷积网络具有不同的感受野,由此获取多尺度特征,进而进行多尺度RSI目标检测。特别的,若卷积核尺寸选择为3×3时,则空洞卷积核始终保持3×3 不变。
在经典的CNN模型中,需要将图像剪切为固定尺寸,但可能导致图像形变,进而影响目标检测精度。空间金字塔池化 (SPP)和空洞SPP(DSPP)能够解决这个问题,可以让CNN模型输入任意大小的图像,而不需要将图像剪切为固定尺寸。SPP是一种将局部特征和全局特征进行融合的池化方法,得到固定大小的特征向量,不仅可以丰富分类特征,还能提升模型的特征表达能力。具有SPP的基本网络结构如图1(a)所示,256是卷积层的卷积核数。为了扩大卷积核的感受野而不增加参数量,DSPP在SPP的基础上,采用不同采样率的多个平行空洞卷积层,每个采样率提取的特征在单独的分支中进一步处理并融合以产生最终结果。具有SPP的基本网络结构如图1(b)所示。DSPP由4个卷积层组成,然后通过1个全局均值池化层将4个通道的输出进行合并,获取跨通道、不同尺度特征图信息。
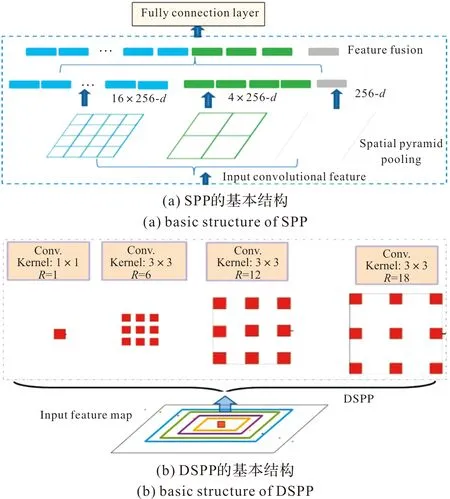
图1 SPP和DSPP的基本结构Fig.1 Basic structures of SPP and DSPP
2 空洞空间金字塔池化U-Net
传统的U-Net由编码部分、解码部分和跳跃连接组成,共包括18个卷积层、4个下采样层和4个上采样层,下采样池化过程中每一层的宽度自上而下依次为64、128、256、512和1 024,对应自下而上的上采样过程。其中编码部分由两个3×3卷积操作和一个最大池操作组成,用于从图像中提取空间特征。在每次下采样后,卷积中的卷积核量将增加1倍,最后两个3×3卷积运算将编码器连接到解码器;解码部分为上采样过程,根据编码特征构造分割图,并使用2×2转置卷积运算对特征图进行上采样,然后将特征通道缩小为1/2,再次执行两个3×3卷积运算的序列,最后执行1×1卷积运算以生成最终的分割图。跳跃连接将下采样中的高分辨率特征与上采样特征连接起来,以尽可能保留更多细节,提高最终分割结果的分辨率和边缘准确率。
考虑到RSI中目标的多样性和多尺度性、目标较小且大小和形状不一、对比度较低、包含复杂背景,所以RSI中的目标具有更大的差异性。在U-Net中采用空洞多尺度卷积模块Inception代替U-Net的卷积层,用ASPP模块替代U-Net的底层,构建一种空洞空间金字塔池化U-Net(DSPPUNet),并应用于RSI中不同大小目标的检测,其架构如图2所示。图2(a)为空洞Inception模块,图2(b)为注意力跳跃连接模块。
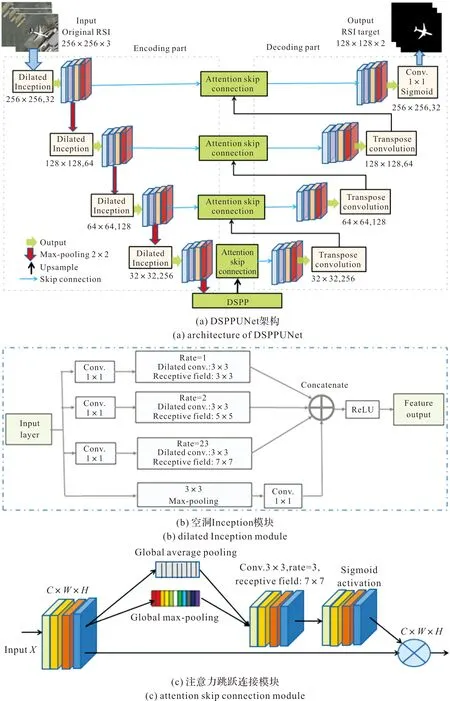
图2 空洞空间金字塔池化U-NetFig.2 DSPPUNet
如图2所示,DSPPUNet由4个空洞Inception模块、4个最大池化(下采样)模块、3个转换卷积模块、4个注意力跳跃连接和1个DSPP连接组成。每个空洞Inception模块中添加1个归一化(BN),对前一层得到的特征进行批标准化处理和ReLU激活,避免网络过拟合,加速网络训练。编码部分包含4个下采样操作,解码部分包含4个上采样操作,每个上采样模块同样包含 1 个改进的残差块和一个注意力模块,将局部特征的分辨率恢复至输入图像大小。编码部分与解码部分利用ASPP模块桥接,该模块从编码部分学习到的高层特征中提取结节的多尺度特征,并将这些特征传递至解码部分中。
DSPPUNet的主要模块和操作过程为:
1) 空洞Inception模块结构如图2(a)所示,由4个1×1卷积、4个空洞卷积和一个连接操作组成,使用Rate为1、2和3的三种空洞率的3×3空洞卷积依次进行特征提取,得到多尺度分类特征,空洞卷积的感受野大小分别为3×3、5×5和7×7,小空洞率感受野用于提取小目标图像的细节特征信息,大空洞率感受野用于提取更具有全局性的特征信息。第四分支中最大池化后使用1×1卷积来降低通道数量。网络参数主要由卷积核大小和卷积核数决定,每个空洞Inception模块中常用3×3卷积核,只有9个参数,能显著减少网络的计算量。
对于空洞率为R的空洞卷积,实际卷积核感受野大小为:
kr=k+(k-1)·(R-1)
(1)
式中:k为原始卷积核大小;kr为扩张后的卷积核大小;R为空洞率。
空洞卷积表示为:
(2)
式中:x(i)为输入信号;w(k)为长度为k的卷积核;r为对输入数据进行采样的步长;y(i)为空洞卷积输出。
2) 在解码部分,每个转换模块由3个3×3卷积组成,每个卷积后进行BN和ReLU激活操作。传统的U-Net利用跳跃连接融合低层细节特征与高层语义特征,得到更加丰富的分类特征,但可能得到对最终目标检测无用的特征,在解码阶段进行上采样操作会丢失一部分位置空间等信息,从而导致目标区域分割不精确。
3) DSPPUNet利用注意力模块+跳跃连接(如图2(b)所示),使得网络学习更为关注的目标区域,分别在位置维度和通道维度上建模语义相关性,其中位置注意力模块选择性地聚合所有位置的特征,通道注意力模块选择性地强调相互依赖的通道特征图。由此提高语义分割的准确性,增强模型的目标检测的性能。
4) 在RSI目标检测中,低级特征存在图像的细节信息,利用空间注意力模块能够得到目标区域和背景之间的边界轮廓,滤除其余区域的细节纹理信息。为了扩大感受野和获取更丰富的全局特征,使用2个相邻的卷积核,再使用Sigmoid函数将最终特征映射到(0,1)内。
给定卷积后的特征图F∈IH×W×C,其中H、W和C分别为特征图的长度、宽度和通道数,经过最大池化和平均池化得到的特征图为Fmp∈IH×W×1和Fap∈IH×W×1,拼接得到特征图为Ms∈IH×W×1,再经过空洞卷积和Sigmoid激活后,得到空间注意力特征图Fs∈IH×W×C为:
Fs=F·σ(f7×7(Fmp);Fap))
(3)
式中:f3×7为大小为空洞卷积运算,空洞率为3,感受野为7×7;σ为Sigmoid函数;Fap和Fmp分别为平均池化和最大池化运算。
采用交叉熵损失函数训练U-Net及其改进模型,RSI目标检测方法看作二分类问题,其交叉熵损失函数为:
(4)
式中:N为样本总数;yic为第i个样本的真实类别,若样本的真实类别为c,则取1,否则取0;pic为第i个样本属于类别c的预测结果。
5) 损失函数。小目标图像的语义分割问题为一个二分类问题,可采用二分类的交叉熵(binary cross entropy, BCE)损失函数为:
(5)
式中:N为图像像素数目;yi和pi分别为第i个像素点的标签值和预测概率值。
3 实验结果与分析
为了验证所提出的基于DSPPUNet的RSI目标检测方法,在EORSSD数据集上进行实验,并与典型RSI目标检测方法进行比较:U-Net、改进的U-Net (IU-Net)[15]、轻量级多尺度注意力U-Net (LWMSAU-Net)[16]和VGG-U-Net[17],其中U-Net为基准网络。上述实验在以下条件下进行:操作系统为Windows10,CPU为Intel(R)Core(TM)i5-10300H CPU@2.5 GHz,GPU为NVIDIA GeForce GTX1660Ti/内存16 GB,CUDA为CUDA 11.0,Anaconda为Anaconda3,Cudnn为cudnn 7.6.5,编程语言为Python3.6,深度学习框架为Tensorflow GPU 2.2.0。
3.1 RSI数据集
在公共RSI数据集EORSSD中选择包含飞机、舰船和油罐目标的RSI,构建小目标RSI数据集进行实验,验证所提出的小目标检测方法。构建的数据集包含258幅飞机RSI、120幅舰船RSI和58幅油罐RSI,共436幅,部分图像如图3所示,原图像的分辨率在973×760到242×239之间。为了便于训练模型,将每幅图像的大小调整为128×128。为了提高基于DSPPUNet的小目标检测方法的能力和鲁棒性,减少过拟合问题,将每幅原始图像通过随机裁剪、图像旋转和仿射变换增强为10幅图像,有436幅得到4 360幅扩展图像,构建一个包含4 796幅图像。通过5-折交叉验证方法在该数据集上进行实验验证。由图3可以看出,构建的数据集类似于地面战场环境中的军事目标,包含的目标类型和目标数不同,目标的大小、形状和分辨率不一、背景复杂。

图3 代表性的包含小目标的RSIFig.3 Representative RSI containing small targets
3.2 实验结果
在训练过程中,将训练样本分成多个批次,每个批次大小为16幅,全局学习率为0.000 1,迭代次数为3 000,梯度衰减因子为0.9,权重衰减为0.000 5,损失函数为交叉熵,采用Adam方法优化模型。图4为U-Net,IU-Net,LWMSAU-Net,VGG-U-Net和DSPPUNet的训练过程。
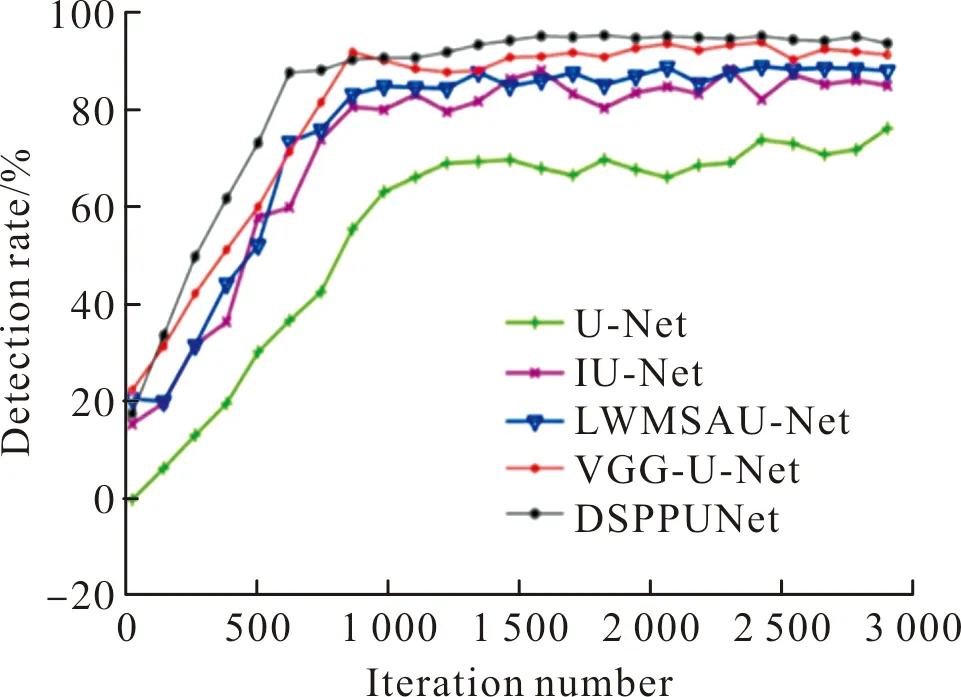
图4 5种方法的训练过程Fig.4 Training process of five methods
从图4可以看出,随着迭代次数不断增加,检测精度不断增加,当迭代次数增加到1 500后,检测精度趋于稳定。当完成迭代次数3 000时后5个模型的训练过程相对稳定,模型基本上收敛。DSPPUNet的检测精度最高,收敛效果最好,说明DSPPUNet的训练效果更好,模型更稳定;U-Net的检测精度最低,且变化波动较大。
利用迭代次数3 000后的模型进行RSI小目标检测实验,实验结果如图5所示。图5(a)为简单背景下的检测结果,图5(b)为复杂背景下的检测结果。
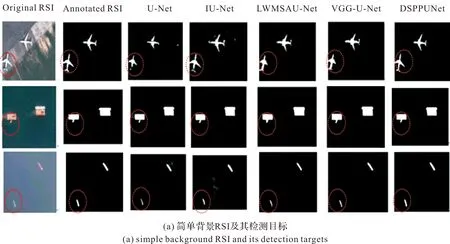

图5 5种方法的目标检测结果Fig.5 Target detection results of the five methods
从图5中可以看出,DSPPUNet通过设置不同大小空洞率的空洞卷积能够捕获特征图中的多尺度信息,对大小不同的小目标的检测效果都好,分割出的小目标轮廓和形状完整清晰,优于其他方法,而U-Net的检测结果最差,还有大量的噪声,而且丢失了低分辨率的小目标。为了进一步验证DSPPUNet的有效性,采用5-折交差验证方法进行实验,选择计算精度、召回率和F1量化检测性能,并与其他4种方法进行比较,结果如表1所示。从表1可以看出,DSPPUNet的检测结果优于其他方法。

表1 5种方法的小目标检测结果Table 1 Small target detection results of five methods %
3.3 消融实验
所构建的DSPPUNet模型与传统的U-Net模型的区别如表2所示。为了表明DSPPUNet的鲁棒性,通过改变DSPPUNet中的不同模块,进行不同的消融实验,并利用检测精度和模型的训练时间作为度量。通过5-折交叉验证在以上设计的数据集上进行实验验证,实验环境与以上实验相同,实验结果如表3所示。
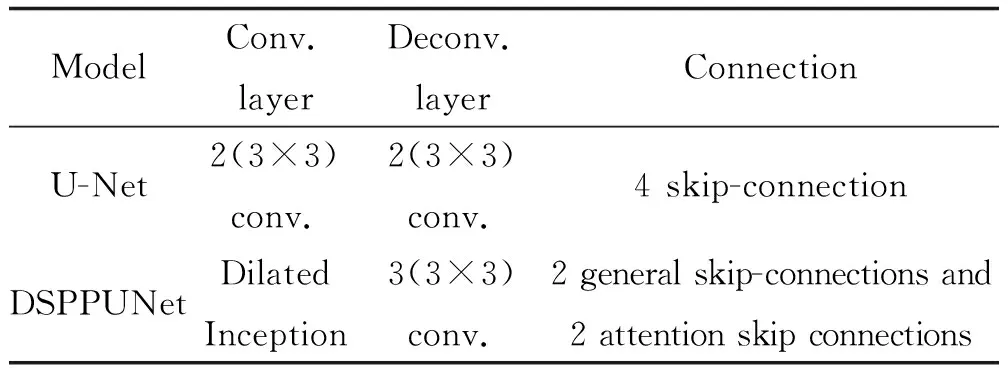
表2 U-Net与DSPPUNet的区别Table 2 Difference between U-Net and DSPPUNet
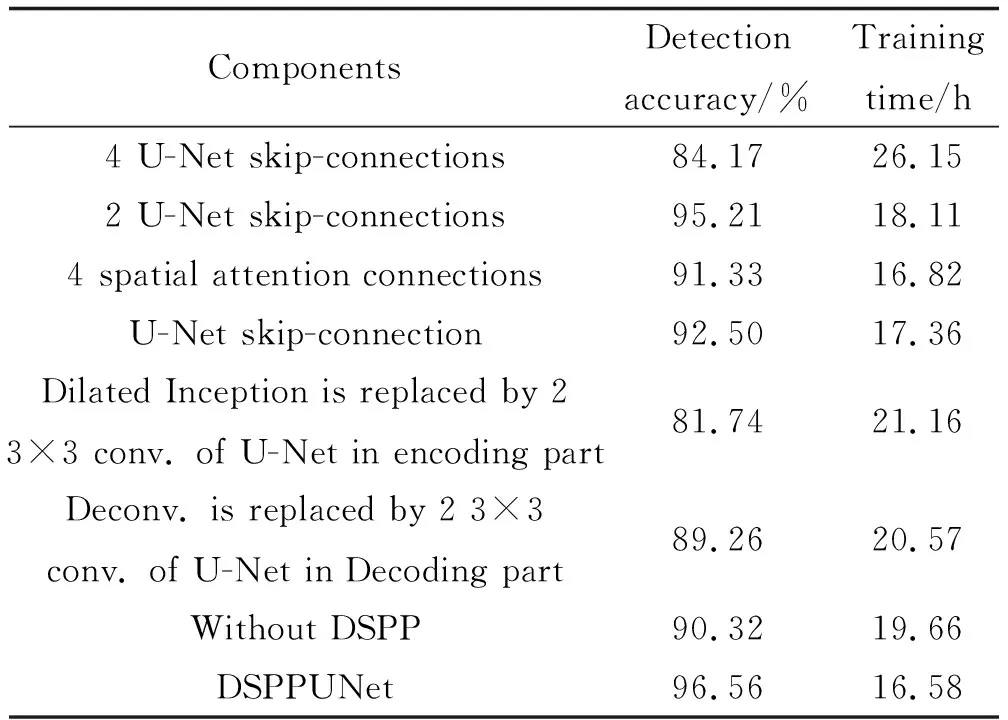
表3 基于DSPPUNet的消融实验的检测精度Table 3 Detection precision of DSPPUNet-based ablation experiment
由表3可以看出,由空洞Inception模块构建的检测方法明显优于一般由3×3卷积构建的检测方法。原因是空洞Inception为多尺度卷积模块,在没有增加训练参数的情况下,提高了检测精度且减少了训练时间;空间注意力和双注意力各有优势且都能极大加速模型收敛,原因是空间注意力和双注意力都能够搜索同一通道内不同距离之间、以及不同通道之间深层语义特征的依赖关系,并对具有依赖关系的特征进行增强,从而提升模型的训练性能。由于空间注意力与双注意力的侧重点不同,不同卷积层的特征图维数和个数不同,得到不同的连接组合的效果有差异;DSPP的检测率比较高,因为第4层的特征图比较小,空间注意力适用于小目标显著性检测。
3.4 结果分析
从图4、图5和表1、表3可以看出,基于DSPPUNet的小目标检测方法能够有效检测低分辨率、小型目标,其检测结果优于其他方法。该模型具有有效性和鲁棒性。与标注图像相比,该模型检测到的目标具有相对完整的形状、边缘和位置,具有较高的检测精度。主要原因是DSPPUNet融合了空洞卷积和多尺度提取特征的优点,利用空洞Inception将编码阶段每个最大池化操作前提取的多尺度空洞卷积特征进行特征融合传入到解码阶,空洞Inception、DSPP与注意力模块相结合,使得DSPPUNet能够聚合不同层次的特征信息,捕获重要特征并抑制不重要的特征,提取更加精细的特征,提高小目标图像边界检测的精确度,获得更准确的目标的形状和边界。
4 结论
针对遥感图像小目标检测难题,在U-Net和空洞卷积的基础上,提出一种基于空洞空间金字塔池化U-Net的遥感图像多目标检测方法。该方法集成了空洞卷积、多尺度卷积、空间金字塔池化和空间注意力机制等优点。在RSI数据集EORSSD中包含小目标的图像集上进行对比实验表明,所提出的DSPPUNet能够实现多尺度RSI目标检测,检测精度为96.56%,优于其他模型。由于实际RSI中的小目标较小,背景比较复杂,一般存在伪装和遮挡等现象,存在检测错误、相邻目标识别效果差、将阴影误认为小目标、被背景覆盖的目标无法识别等问题,所以未来的工作聚焦于优化DSPPUNet模型结构,提高复杂RSI场景下的小目标检测精度和性能。另外,由于实际战场应用中有可能出现未知类别目标,为此下一步研究重点是,对数据集添加语义标签,通过修改模型结合零样本分类器进行未知类别目标检测。
