新型电力系统终端通信协议的逆向分析及模糊测试
2023-11-28韩嘉佳孙昌华
韩嘉佳,孙 歆,吕 磅,孙昌华,钱 锦
(国网浙江省电力有限公司电力科学研究院,杭州 310014)
0 引言
随着我国大力推进实施以双碳和新能源为主的新型电力系统战略,未来电力系统结构形态将发生较大改变,电力系统逐步打破了以往的封闭性和专有性,接入企业的终端数量快速增加。电力行业安全防护责任界限扩展,安全防护压力增加,各类设备、平台广泛接入电力系统,可能出现多种异构网络,通信传输模型更为复杂,可能出现通过破解算法、协议及中间人攻击等多攻击方式,对传输数据及控制指令进行篡改、屏蔽等,新型电力系统安全形势日益严峻。因此,如何在新型电力系统终端上利用拟态防御思想,对提升新型电力系统终端系统的防御能力和安全等级至关重要。新型电力系统终端拟态防御的第一步,就是要通过对截获的新型电力系统终端通信数据进行分析,动态识别出新型电力系统终端应用程序所用的网络协议,从而理解通信行为,判断未知数据是否为攻击方发出的病毒数据。
新型电力系统终端可获取的通信数据类型繁多,随着应用程序的爆发式增长,针对应用程序执行产生的数据信息的获取途径逐渐成为研究热点。然而,在应用程序执行过程中,初始数据可能被覆盖或者删除,也可能由于加密技术,不能获得完整的应用程序数据。为了信息采集的完整性,还应对应用程序执行过程中产生的网络通信数据进行获取。通过分析截获的通信数据,识别和解析出应用程序采用的网络协议,根据其通信机制和内容,理解通信行为,为判断网络数据的危险性、提取有效证据信息提供基础。
目前工控漏洞挖掘方法有两种,一种是面向协议报文的逆向分析,另一种是面向固件及执行程序的逆向分析。对固件进行分析如文献[1],该类方法需要的条件较为严苛,需要对实现通信的程序进行监控,访问其运行环境并记录产生的指令信息,使用了软件逆向的方法。但是在实际工业控制系统中很难接触到工控设备实体。一般来说,为了提高协议安全研究的效率,需要首先对协议进行协议逆向工程,以获取协议的消息格式等信息。因此,在工业互联网中更加关注以协议逆向为前提的面向协议的漏洞挖掘和分析技术。PRE(协议逆向工程)仅通过对捕获到的通信实体双方的通信流量进行分析,提取协议消息格式等相关内容,从而推断出未知协议的消息格式和状态机模型的过程[2]。在相关领域,已经有许多研究对协议逆向的方法进行探索和改进,目的是提高逆向结果的准确性。近年来,协议逆向技术被用于各个相关的安全领域,模糊测试、网络入侵检测、入侵防御等都使用了协议逆向来获取未知协议的先验知识,以提高分析工作效率。
通常采用对未知协议流量中的报文序列分析来进行协议逆向。最早的协议逆向技术的是Protocol Informatics[3]项目(以下简称“PI”)。PI 项目借鉴了一种从DNA序列寻找特定基因的算法,类比到协议逆向领域即从捕获流量报文数据中寻找特定类型的消息。PI 项目为后来的许多工作提供了指导,后来的研究者对方法进行了改进,例如Al-Dhaq[4]等人的协议状态机自动提取工具ScriptGen就是以PI 项目为指导,该工具完成部分语义的提取,但是在推断状态机之前并未对消息序列进行聚类,性能上与今天的工具有很大差距。另一个重要且经典的工具是Golubeva[5]等人提出的Discoverer 工具,其对不同类型的待分析报文能够选择合适的方法,提高了分析性能。在此之后,随着人工智能技术的兴起,机器学习、自然语言处理领域的算法被应用于协议逆向领域中,协议逆向工程在短时间内得到迅速发展,研究对象从普通的文本协议扩展到二进制协议,方法类型也不断丰富,并且准确率和可靠性等方面得到大幅度提升。比如张明远[6]等人使用了基于序列比对算法将报文各个字段对齐,Casino[7]等人使用了概率模型寻找报文关键字段,Khan[8]等人基于频繁集和先验算法提出了一种无监督学习方法来提取消息格式和协议状态机,Li[9]等人和Rahman[10]等人同时考虑了基于语义分析和语义分析,并提出了一种由数据流和控制流信息组成的EFSM(扩展有限状态机)行为模型。近年来也不断有新的方法提出,例如Sun[11]等人提出使用基于聚类效果直观度量的协议关键词概率提取算法,Yang[12]等人提出利用报文本身特点使用连续段相似性。
上述文献针对协议安全性分析的工作主要包括对协议进行逆向,推断协议状态机,大多数是基于网络流量的被动推断方式。在协议漏洞挖掘方面主要是模糊测试,但存在测试用例效率低下、耗时长、程序崩溃时无法定位到崩溃点等问题。
为了解决上述问题,本文提出了一种基于网络流量分析的私有协议逆向方法,通过对捕获的流量报文进行分层处理,将未知协议的数据字段提取出来,然后利用N-gram算法进行分词,对协议关键词进行聚类,利用增广前缀树合并状态,推断出协议状态机。生成的协议状态机与标准协议状态机利用深度学习进行一致性匹配,推测出协议脆弱性可能出现的地方。对协议进行安全性测试,利用模糊测试的方法分别对Modbus协议源码和消息格式进行测试,通过对比不同模糊测试工具的效率和性能,选择出了一种较好的协议测试工具。
1 Modbus协议
物联网终端依靠网络协议进行通信,不同厂商可能会使用不同的协议,而且不同的应用场景和需求对协议也有不同的要求。例如,生活中常见的FTP(文件传输协议)、SMTP(简单邮件传输协议)、汽车使用的CAN(控制器局域网总线协议)、工控领域中的Modbus/TCP 协议和西门子S7Comm协议。
Modbus协议全称为Modbus/TCP协议,就是基于TCP/IP 的工控协议,其通信模式有3 种情况,分别为请求/应答、订阅/推送和主动推送。其设计是面向功能的,协议报文多为二进制报文,主要传输控制命令(控制码),报文精简,比较系统化、结构化。
Modbus 协议定义了PDU(协议数据单元)和ADU(应用数据单元)。ADU由4部分组成,分别是地址域、功能码、数据部分和差错校验。地址域和功能码都为1个字节,前者表示设备地址,后者表示操作功能代码。数据部分可包括偏移量、子功能码、可变参考等,最大为252字节。差错校验部分为2字节。
Modbus 功能码的有效范围是1~255,其常用的功能码及其功能如表1 所示。其中,01 表示读取线圈状态,02 表示读取输入状态,03 表示读取保持寄存器,04 表示读取输入寄存器。可用的功能码有127个,其中108个为公共功能码,公开声明的,具有普遍适用性的,包含保留的未定义的功能码;其余为用户定义功能码,用户自定义操作码功能。
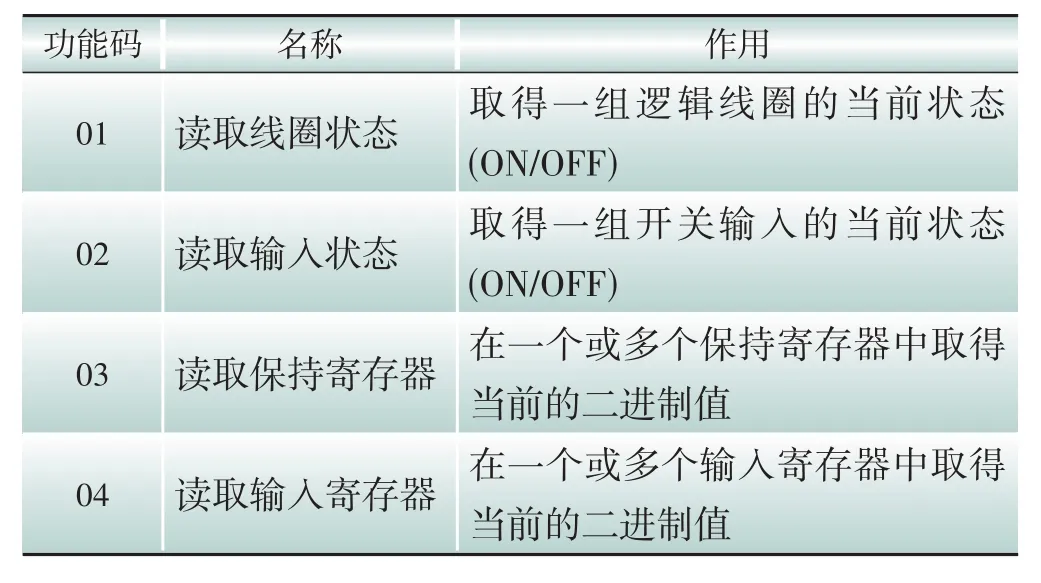
表1 常见功能码及功能Table 1 Common function codes and the functions
2 智能终端协议安全性分析系统
系统框架如图1所示,新型电力系统终端第三方厂商私有协议安全性分析系统共分为两个模块:协议逆向模块和模糊测试模块。协议逆向模块是基于网络流量分析而设计的,主要包括4 个步骤:预处理、格式推断、语义分析和状态机推断。模糊测试模块分为两部分,为基于源码的模糊测试和基于消息格式的模糊测试,分别对应不同的模糊测试工具AFL和Boofuzz。

图1 智能终端协议安全性分析系统框架图Fig.1 Framework of protocol security analyzer for intelligent terminal
对于网络中捕获的流量,由于带宽的不稳定和混杂流量的影响,需要先对捕获的报文进行分流、去重传等操作,然后基于5层网络架构体系对流量报文进行处理。预处理可将私有协议字段部分提取出来,然后进行格式推断,通过分词提取协议关键词,分析各关键词之间的关系,初步推断协议格式。之后进行语义分析,划分后的关键词需要推断其所代表的含义,如报文长度、操作功能、地址或ID等,需要对固定的取值和可变取值进行分析,甚至还有协议未使用的字段部分。最后依据前面的分析,推断协议状态机,将具有相同特征的关键词聚为同一类簇,可视为同一个状态,由此为基础推断协议状态机,来获得每个状态之间的关系,尤其是最重要的时序关系。最后将推断的状态机与开源协议逆向软件推断的结果进行比对,来对协议安全性进行分析。
2.1 基于N-gram的字段分词
N-gram 模型是一种基于统计的语言模型算法,常用于NLP(自然语言处理)。其基本思想是利用了滑动窗口的思想,即对一串文本数据进行分词时,按照字节的先后顺序,依次进行大小为N的滑动窗口分词操作,形成若干个长度为N的字节片段序列。
这与协议关键词和协议状态机的思想类似,所以将N-gram算法用于划分协议格式,推断协议关键字是一种有效的方式。常用的算法是基于二元的Bi-Gram和基于三元的Tri-Gram。
经过前面的处理,私有网络协议的字段被处理成文本,由于协议未知,无法进行状态标注,于是可以先用N-gram算法进行处理切分,提取协议关键词。评价N-gram算法的有效性在于N的取值大小。若N的值过小,会使得协议关键词被切分,影响准确率;若N的值过大,会导致切分结果体量过大,影响处理效率。在经过多次实验后,了解到关键词的大小多为1~2 字节,因此选取N的值为1~2。
2.2 协议状态机推断
由于Modbus是单状态协议,很难根据协议的运行状态推断协议状态机,因此,本节利用协议的字段构建Modbus协议状态机。在进行关键词分类时,由于对每个类簇进行标记,所以进行无监督学习分类。对于私有网络协议的报文,其数据字段可能由于功能不同,结构也不同,所以根据分词后协议特征关键词的分布密度进行聚类,测试结果也可能是不同的。
因此,需要用一种方法来对聚类结果进行有效性评价,轮廓系数被认为是一种比较好的用于评估聚类有效性的方式。它的取值范围在-1~1,越接近1 表示聚类的结果越有效。当系数小于0时,表示有部分重叠样本,即分类出现误差;当系数在0上下浮动时,表示边际有重合;当系数大于0 时,表示聚类效果较好,每一类簇的分类较清晰。
进行轮廓系数计算方法时,首先随机选择一个类簇里的样本,作为初始向量,然后计算其到同类样本距离的期望,表示簇内的聚合度。然后再计算其到其他类簇的距离的最小值:
式中:a(j)是样本j与同一簇内其他所有样本的平均距离,这个值越小,表示该样本与所在簇的相似度越高;b(i)是样本i与其他簇内所有样本的最小平均距离,即样本i与最近的那个簇的所有样本的平均距离,这个值越小,表示该样本与其他簇的差异性越小;轮廓系数S(i)的取值范围是[-1,1],S(i)的值越接近于1,说明样本i与所在的簇匹配得很好,S(i)的值越接近于-1,说明样本i与所在的簇匹配得不好,可能被分到了错误的簇,如果S(i)接近于0,则说明样本i在两个簇的边界上。
由于Modbus协议为单状态协议的特殊性,所以基于协议的帧格式来构建协议状态机。构建的过程如下:以帧的起始作为状态机的开始状态,然后对后面读入的字节进行校验,若为合法的输入,则转到下一个状态,否则回到起始状态,直到读入帧结束字符。
基于逆向分析推导的协议状态机如图2 所示。对于帧起始,可作为初始状态,一个输入事件可由每一次读入的字符决定,若判断为合理输入,则跳转到下一状态;若为非法输入,则状态机返回初始态。Modbus协议不同的功能码则可以对应不同的设定状态。
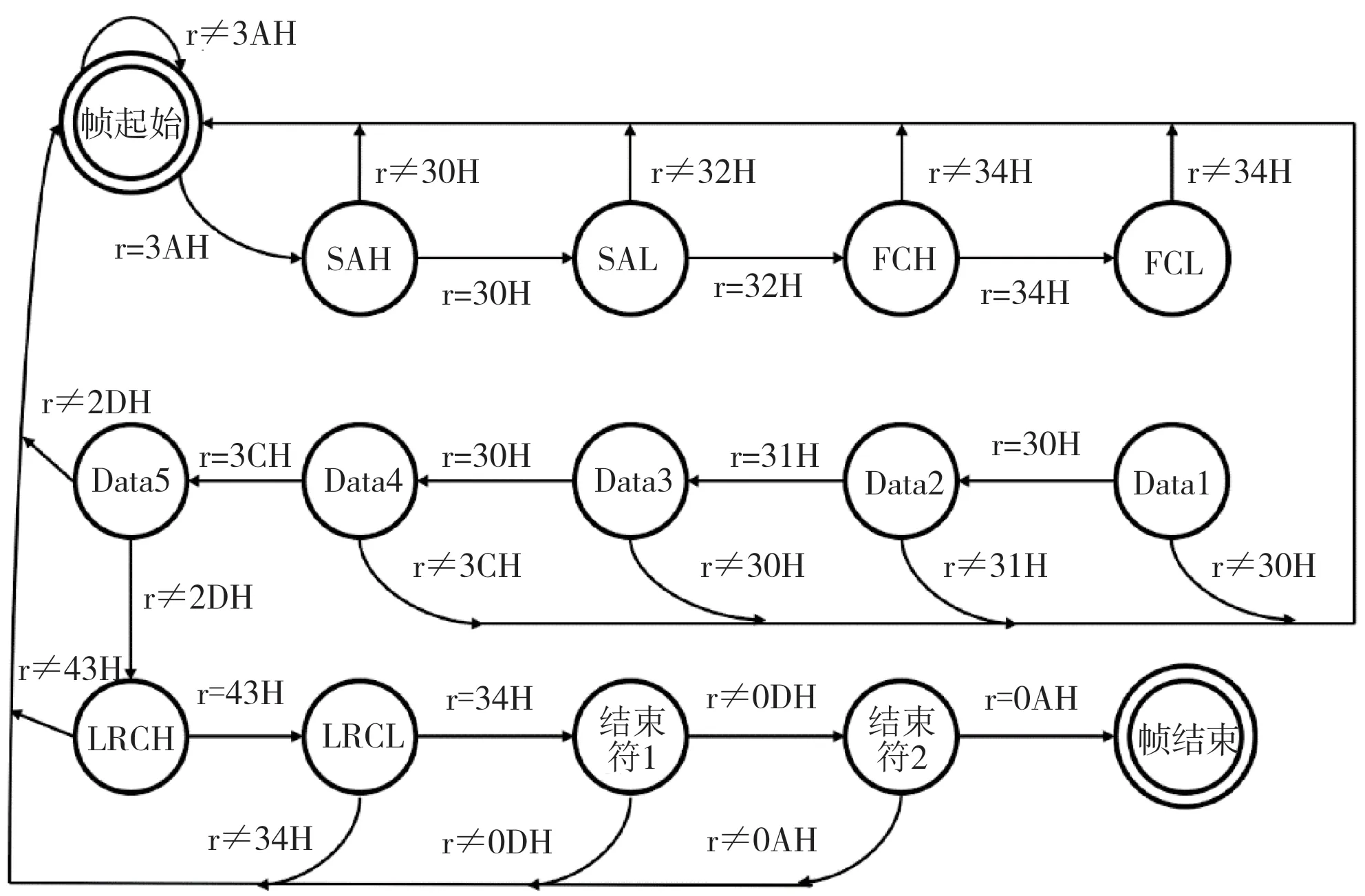
图2 Modbus协议逆向推导得出的状态机Fig.2 State machines obtained through reverse derivation of Modbus protocols
3 私有协议模糊测试
在Modbus 协议分析结果基础上,选用Boofuzz作为协议的模糊测试工具。Boofuzz是基于Python 语言实现的,但它无法直接获得协议相关信息,需要人工定义协议格式,因此使用Boofuzz对Modbus的协议格式进行模糊测试。
由于Boofuzz 无法直接获得协议的相关内容,需要借助工具PyModbus实现一个Modbus服务器。为了构建一个Modbus服务器,首先需要实例化一个ModbusSlaveContext,并向其传递一些与输入寄存器、线圈等相对应的“数据块”。数据块是一种存储机制的实例,它至少支持在某个地址读取和写入数值。最简单的,Modbus Sequential Data Block,只是对可序列化字节集合的一个简单封装,其本质上只是一个C 数组。在实验中将使用数据块来创建数据存储,本质上只是几个数据块的集合,从中构建代表设备状态的上下文。设置TCP服务器模拟设备与服务器之间的通信。Modbus 服务器主要包括3 个模块:Sequential Data Block、Bad Data Block 和Communication Block。第一个模块负责顺序通信,包括定义了线圈、寄存器个数等相关数据块;第二个模块只要定义了触发崩溃的条件,即服务器被要求在高于0xFF的地址处输入值时,程序将会出现崩溃;第三个模块主要是定义通信过程,创建socket 线程与客户端通信。
Boofuzz 进行测试的基本单位是会话,每个会话由一个连接和多个字段定义,这些字段可以组织成块。通常,每个Boofuzz字段映射到一个协议字段。根据协议,某些字段将是“二进制”字段。例如s_bytes,这是描述IP数据包的源和目标字段的一种方式,但其他字段可以是完全的ASCII 字符串。每个字段都由一个起始值和一些参数定义,这些参数描述了它将如何被模糊化。例如,事务ID字段如下所示:
s_bytes(value=bytes([0x00, 0x01]),size=2,max_len=2,name="transaction_id")
如果一个字段应该是固定的,可以通过fuzzable=False。但是,对数据包的所有字段进行模糊测试是没有意义的,在大多数情况下都是如此,可以在一个块中收集多个字段。因此,使用Boofuzz构建的模糊测试器工作步骤如下:
1)实例化一个会话对象,将它指向需要模糊测试的对象,例如会话进程。
2)通过定义协议的每个字段并告知Boofuzz如何修改字段的值来定义协议,或者将字段都放入块中。
3)使用上面的会话对象连接到被测目标,调用fuzz()开始测试。
在测试中将构建一个仅包含一种数据包类型的协议定义——读取输入寄存器。这个数据包的结构除了典型的Modbus 头和函数ID,它只包含两个字段:起始地址和要读取的输入寄存器的数量。从输入地址开始,两者都是2字节。
接下来确定需要模糊测试的字段。显而易见的是,起始地址和寄存器数量字段是被测对象,如果处理请求的逻辑有缺陷,它将与这两个值相关联。在测试中对读取输入寄存器函数进行模糊测试,因此需要将函数ID字段固定为0x04。协议字段设置为:起始地址、寄存器数量和事务处理ID字段将模糊测试;协议ID、长度、单元ID和函数ID字段将固定。
测试服务器主要由4 个模块构成,分别为:Communication Block、 Fuzz Data Block、 Fixed Data Block和Operation Data Block。第一个模块主要是实现与服务器的通信;第二个模块是定义需要模糊测试的字段;第三个模块是固定字段;最后一个模块是向服务器发送操作码。
为了实现环境隔离的原则,实验中Boofuzz运行在虚拟环境中,并使用pip对Boofuzz下载安装,具体安装命令如下:
# mkdir boofuzz && cd boofuzz
# python3 -m venv env
# source env/bin/activate
# pip install boofuzz
首先运行Modbus 服务器,然后开始对TCP会话进行模糊测试。通过观察运行结果发现程序崩溃,具体结果存放在boofuzz-results 文件夹中,这是一个简单的SQLite数据库,可以使用Boofuzz自带的Web UI进行查看,如图3所示。

图3 使用Boofuzz模糊测试运行过程Fig.3 The operating process using Boofuzz
在浏览器中打开127.0.0.1:26000可以查看每次测试运行的具体情况,如图4所示。由图4可以看到测试用例一共运行了78次,第78次是尝试连接但是连接失败了,所以程序在第77 次发生了崩溃。程序崩溃的原因在于尝试从地址0xFF00读取1 个寄存器(04)。可以看出Boofuzz 的模糊测试虽然前期需要准备协议的相关知识,但测试有效性要高于AFL。

图4 测试数据具体情况Fig.4 Data testing
4 结语
针对现有第三方厂商新型电力系统终端协议封闭难以识别及测试的安全问题,提出了基于Ngram 算法和协议状态机推断的逆向分析方法,在此基础上通过协议源码编译插桩的方式,实现协议的模糊测试。以典型Modbus协议为例开展本文所提方法的有效性验证,经测试表明,该方法可以有效对第三方厂商私有协议开展快速识别和安全性测试,有较高的实用价值。
