多尺度坐标注意力金字塔卷积的面部表情识别
2023-11-27倪锦园张建勋
倪锦园,张建勋
重庆理工大学 计算机科学与工程学院,重庆400054
在人们日常交流的过程中,人脸面部表情是传达情感和信息的一种常用方式。近年来,随着人工智能技术的持续发展,计算机视觉在识别领域取得了突破性的成果,对面部表情识别的研究也逐渐深入,人脸面部表情识别在智能驾驶、医疗服务、智慧课堂和犯罪测谎领域中都有着广阔的应用前景[1-3]。
早期的人脸表情识别研究通过一系列图像关键帧跟踪关键点的方法识别面部表情,但是效率低下,参数量过多,导致识别的准确度较低[4]。近年来,深度学习在图像识别上取得了突破性的发展,Wang等人[5]提出了一种改进的MobileNet 网络模型,通过改进的深度可分离卷积减少网络的计算量的同时选择SVM进行面部表情分类,大幅度轻量化了模型。Lan 等人[6]基于ResNet18残差网络提出了联合正则化策略,通过将多重正则化方法放入网络中,减缓了模型过拟合的现象,提高了模型整体性能。Tang 等人[7]设计了一种多区域融合的轻量化人脸表情识别方法,融合了局部细节特征和整体特征,增强了模型对面部表情细节特征提取能力,并通过剪枝算法对模型进行轻量化处理,减少了模型的参数量和复杂程度。Zhou 等人[8]设计了一种轻量级的卷积神经网络,采用多任务级联卷积网络完成人脸检测,并且结合残差模块和深度可分离卷积模块减少了大量网络参数,使模型更具可移植性。Shen等人[9]通过改进的倒置残差网络搭建了轻量化的卷积神经网络模型,通过采用全局平均池化等方法筛选出了人脸表情的浅层特征,并将浅层特征和深层特征融合进行表情识别。Shi等人[10]提出了一种基于多分支交叉连接卷积神经网络的人脸表情识别方法,该方法是基于残差连接、网络中网络和树结构共同构建的,它还为卷积输出层的求和增加了快捷的交叉连接,使得网络间的数据流更加平滑,提高了每个感受域的特征提取能力。Gao等人[11]基于RenNet50残差结构提出了一种多尺度融合的注意力机制网络,通过7 个三条支路的注意力残差学习单元对面部表情图像做并行卷积处理,引入注意力机制加强网络对图像的特征提取,利用注意力模块之间的过渡层减少网络参数的计算量。
虽然上述很多网络都能够在一定程度上轻量化模型和提取表情特征,但是在部分有遮挡的数据集下模型对面部表情特征表示能力不足,导致识别准确率较低。随着深度学习网络的层数的叠加也会造成模型的冗余,导致参数量较大,识别速度较慢。针对以上问题,本文提出了一种多尺度融合注意力金字塔卷积网络,主要工作概括如下:
(1)为了提取多尺度的特征信息,改进了金字塔卷积结构,扩大了模型的感受野,在减少网络计算的参数量的同时加快了模型的运算速度。
(2)为了进一步提取面部表情的深层特征,提出了SECA坐标注意力机制模块,将从通道和空间两个维度上重新对人脸表情的特征进行表示。
(3)为了解决卷积层数过多造成模型冗余的问题,提出了深度可分离混洗方法,节省了网络的计算量,增加了模型的非线性表达能力。
(4)通过与不同的网络模型进行对比,可以验证本文提出的模型保持较低参数量的同时拥有更高的精确度。
1 相关工作
1.1 金字塔卷积
金字塔卷积(pyramidal convolution,PyConv)[12]可以在多个不同的滤波器尺度对输入的数据进行处理,PyConv 包含了一个核金字塔,为了提取不同尺度的特征信息,每一层包含了不同尺度的滤波器,相比于普通卷积来说,PyConv 不会增加额外的参数量,PyConv 通过多个滤波器捕捉了不同环境下、不同场景的信息,从而提高了模型的性能。Qiao 等人[13]基于金字塔卷积提出了金字塔沙漏网络,丰富了模型对特征提取的感受野,增大了模型对特征的表示能力,进一步提高了预测的准确率。Kang 等人[14]提出了一种融合注意力的多路金字塔聚类算法,通过自注意力机制获取整体特征,然后通过多路金字塔卷积从不同维度挖掘文本特征。金字塔卷积模型如图1所示。

图1 金字塔卷积模型Fig.1 Pyramid convolution model
1.2 Coordinate Attention
Coordinate Attention(CA)是一种结合了通道注意力[15-17]和空间注意力[18]的轻量级模块,在带来小幅计算量和参数量的情况下,可以大幅提升模型性能。CA 将通道注意力分解为两个一维特征编码过程,分别沿两个空间方向聚合特征。这样操作可以向一个空间方向获取远程依赖关系,同时保持另一空间方向的位置信息,然后将生成的特征图分别编码为一对方向感知和位置敏感的注意力图,可以加强对对象特征的表示能力,因此CA模块操作能够区分空间方向(即坐标),并且生成坐标感知的特征图。
1.3 深度可分离卷积
深度可分离卷积是轻量级网络MobileNet的核心结构[19],由逐通道卷积(DepthWise,DW)和逐点(PointWise,PW)卷积两个部分结合起来,其具体结构如图2 所示。相比于常规卷积操作过程,深度可分离卷积所包含的参数数量和运算成本较低。逐通道卷积的卷积核数量与上一层的通道数相同,一个卷积核负责一个通道,此过程产生的特征图的通道数与输入通道数一致,无法扩展特征图的维度,并且对每个通道独立进行卷积运算无法有效利用不同通道在相同空间位置上的特征信息,因此需要逐点卷积将这些特征图进行组合,从而生成新的特征图[20]。逐点卷积主要使用1×1的卷积将上一步得到的特征图在深度方向进行加权组合。

图2 深度可分离卷积Fig.2 Depthwise separable convolution
假设输入特征图大小为Wi×Hi×C,Wi、Hi、C分别代表输入特征图的宽、高和通道数,标准卷积大小为Wc×Hc×C×H,分别代表常规卷积的宽、高、通道数和卷积核的个数,经过常规卷积操作后,输出特征图大小为Wo×Ho×N,则常规卷积的计算量为:
观察组急性阑尾炎合并糖尿病患者空腹血糖(5.31±1.24)mmol/L、糖化血红蛋白(6.69±1.31)%均低于对照组,差异有统计学意义(P<0.05)。见表4。
深度可分离卷积首先使用卷积大小为Wc×Hc×C×1 的卷积进行逐通道卷积,然后使用1×1×C×N的卷积进行逐点卷积,则深度可分离卷积的计算量为:
两者之比为:
2 方法
2.1 整体架构
由于全连接神经网络层数过少会导致模型对人脸表情的特征表示不足,过多则会增加网络的计算量,造成网络冗余的问题。本文结合以上问题,设计了一种多尺度坐标注意力金字塔卷积的面部表情识别网络。在图像预处理阶段,通过对比度加强、翻转、旋转等方法对面部表情图像进行增强处理,提高了模型的鲁棒性,同时丰富了整个数据集。然后将预处理后的面部表情图像传入网络,通过改进的金字塔卷积结构捕捉面部表情中不同级别的细节,中间嵌入了SECA坐标注意力机制模块提取面部表情的深层特征,通过深度可分离混洗模块减少模型的参数量,加快网络的运算速度,增加了模型的非线性表达能力。最后进入Softmax层分类输出结果。模型的整体架构如图3所示。
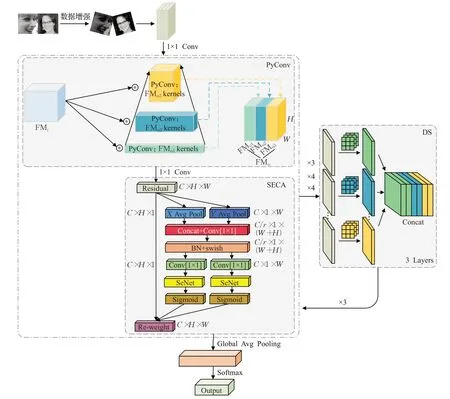
图3 整体架构Fig.3 Overall architecture
该网络输入的目标图像大小为48×48,通道数为3,每个卷积层后面会有一个BN 层和ReLU 激活函数层,BN 层加快了网络训练和收敛的速度,一定程度上防止了梯度的消失。为了提高网络的特征表示能力,在每个金字塔卷积模块和深度可分离混洗模块后面都设有一个SECA坐标注意力机制,然后通过Global-Ave-Pooling层降低过拟合的风险,并减少了计算的参数,最后通过Softmax 层对图片进行分类处理。类别一共包含了生气、厌恶、害怕、开心、伤心、惊讶、中性7类。
2.2 轻量化的金字塔卷积模块
PyConv包含了一个不同类型卷积核的金字塔[21-22],每一层级都是大小和深度不同的卷积核,从而可以捕捉面部表情中不同级别的细节,表示更多的特征,每一层通过分组卷积处理,减少PyConv 的参数量。由于普通卷积的卷积核大小固定,在面对复杂场景的时候,难以捕获多种特征,普通卷积如图4(a)所示。虽然PyConv可以提取多维度的特征,但是模型较为复杂,参数量较大,容易出现过拟合的现象。本文提出了一个轻量化的金字塔卷积模块,通过减少模型的参数量来提高网络的训练效率,有利于部署在算力较低的设备上。为了减少卷积参数量,本文把3×3 的小卷积核全部改为组数为4的分组卷积,则3×3小卷积核的参数量变为了原来的1/4,减缓了网络的冗余,提高了模型的运算速度。普通卷积和分组卷积的对比如图5所示,PyConv结构设置为3层,避免出现比7×7 更大的卷积核。轻量化的金字塔卷积如图4(b)所示。

图4 轻量化的金字塔卷积模块Fig.4 Lightweight pyramid convolution module

图5 普通卷积和分组卷积对比图Fig.5 Comparison of normal convolution and grouped convolution
2.3 改进的坐标注意力机制
为了进一步提取面部表情的深层特征[23-24],提高模型识别的精度,本文对坐标注意力机制模块(CA)[25]进行了改进,提出了SECA坐标注意力模块。主要通过精确的位置信息对通道关系和长期依赖性进行编码,形成一个对方向和位置敏感的特征图来增强对面部表情的特征表示,一共包含坐标信息嵌入和坐标注意力生成两个步骤。改进的坐标注意力机制如图6所示。
全局池化方法常用于通道注意力编码空间信息的全局编码,但在压缩过程中,难以保存具体位置信息,为了促使注意力模块可以捕捉更精确位置信息的远程空间交互,将全局平均池化转化为一对一特征编码操作。对输入的X,使用尺寸为(1,W)和(H,1)的池化卷积核分别沿着垂直坐标和水平坐标对每个通道进行编码,因此高度为h的第C个通道的输出可以表示为:
宽度为w的第c通道的输出可以表示为:
上述两种变换分别沿着两个空间方向聚合面部表情特征,这两种变换允许注意力机制模块捕捉到空间方向上的长期依赖关系,而且沿着另外一个空间方向保存更精确的位置信息。
2.3.2 坐标注意力生成
为了进一步捕获面部表情特征并编码精确的位置信息,通过坐标信息嵌入中的变换后进行拼接操作,接着使用1×1的卷积变换函数F1进行操作,示例如下:
其中,δ为非线性激活函数,[·,·]为沿空间维度的拼接操作,F1为对空间信息在水平方向和垂直方向上的中间特征映射。然后沿着空间维度将f分解为两个独立的张量f h∈RC/r×W和f w∈RC/r×W,其中r表示下采样的比例值。然后采用一组SeNet注意力模块SeFh和SeFw将f h和f w变化为同输入X具有相同通道数的张量,示例如下:
其中,σ表示sigmoid 激活函数,为了降低模型的参数量,加快运算速度,通常采用下采样比r来降低f的通道数,最后改进的坐标注意力机制输出实例如下:
2.4 深度可分离混洗方法
本文采用通道混洗方法(Channel Shuffle)改进深度可分离卷积[26],具体结构如图7 所示。深度可分离卷积首先采用逐通道卷积对输入特征图进行处理,不同通道采用不同卷积操作后使用Concat方法进行通道拼接,因此最终输出的特征仅由一部分输入通道的特征得出,不同通道间无法进行信息交流,进而导致所提取的特征表征能力有限[27]。虽然深度可分离卷积采用逐点卷积进一步提高特征的维度,在一定程度上能够加强空间特征信息的交流,但是维度的增加会导致网络参数量增加。Channel Shuffle方法与逐点卷积的功能相同,但是因其维度并未改变,所以整个网络的参数量不会增加。同时特征的表征能力有所加强,能够提高整个网络的人脸识别精度。

图7 深度可分离混洗Fig.7 Depthwise separable shuffle
3 实验与分析
3.1 实验数据集
本文实验验证的数据集是FER2013数据集、CK+数据集和JAFFE 数据集。FER2013 人脸面部表情数据集由35 886张人脸面部表情组成,通过翻转、裁剪、平移等方法将数据集扩充到50 000 张,其中训练集占70%,测试集占30%,一共包含了7种不同的表情,每张图片都由大小为48×48的图像组成。CK+数据集是在Cohn-Kanda数据集的基础上扩展而来,其中包含123 个对象的327个被标记的表情图片序列,共分为正常、生气、蔑视、厌恶、恐惧、开心和伤心7种表情。对于每一个图片序列,只有最后一帧被提供了表情标签,因此共有327个图像被标记。为了增加数据,把每个视频序列的最后3帧图像作为训练样本,这样CK+数据总共被标记的有981张图片,然后通过翻转、对比度增强、平移的方式将数据集扩充到2 000张图片,其中训练集1 400张,测试集600张。JAFFE 数据集选取了10 名日本女学生,每个人做出7种不同的表情,一共有213张照片,通过旋转、裁剪、缩放等操作将数据集扩充到1 208张照片。
3.2 实验环境
该文实验配置如下:Windows10 系统,CPU 为主频2.9 GHz的Intel Core i7-10700F,内存为16 GB,GPU为NVIDIA GeForce RTX 3070(8 GB)。该实验基于TensorFlow 深度学习框架进行训练,在Pycharm 上进行测试。实验超参数设置如表1所示。
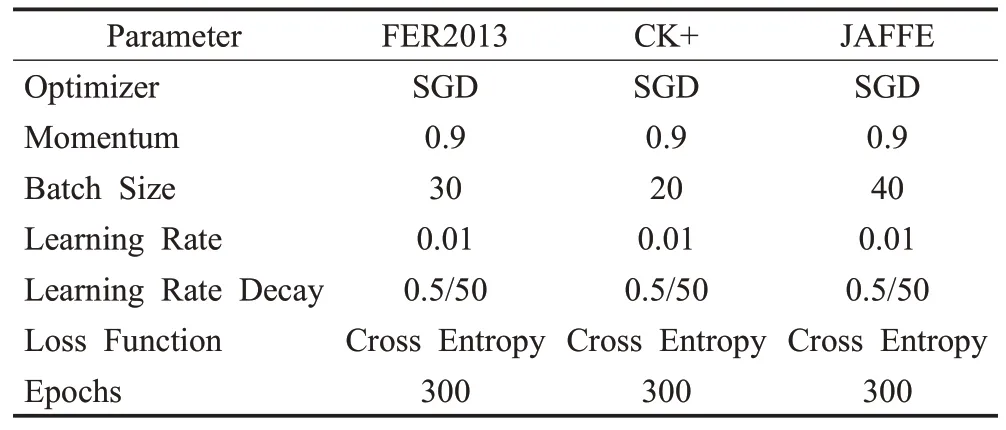
表1 实验超参数设置Table 1 Experimental hyperparameter setting
3.3 消融实验
为了验证本文提出来的MCAPyResnet各模块的有效性,将对每个模块进行消融实验。其中PyConv代表改进的金字塔卷积结构,SECA代表优化后的坐标注意力机制,DS代表深度可分离混洗结构,实验结果如表2所示。

表2 MCAPyResnet消融实验Table 2 MCAPyResnet ablation experiment
首先将面部表情图像通过数据增强的方式传到网络中。然后进入改进的金字塔卷积结构中,金字塔卷积丰富了模型对面部表情特征提取的感受野,增大了模型对特征的表示能力,同时减少了网络的参数量。接着通过SECA 坐标注意力机制进一步提取面部表情的深层特征,增加网络识别的精度。为了解决卷积层数过多造成模型冗余的问题,提出了深度可分离混洗方法,在一定程度上轻量化了网络,加快了模型的计算速度。PyResnet网络消融实验如表2所示。
3.4 对照实验
对照实验如图8所示。从FER2013数据集对照实验可以看出MCAPyResnet 的收敛速度最快,当训练到200 epoch 时,模型识别准确率增长缓慢,在训练到250 epoch的时候,准确率逐渐趋于平稳,最高准确率达到72.89%。从CK+数据集的对照实验可以看出在训练初期模型的识别准确率增长迅猛,在第60 epoch 到120 epoch 时,模型识别的准确率上下震荡,当训练到130 epoch时,准确率趋于平稳,最高准确率可达98.55%。从JAFFE数据集的消融实验可以看出模型在训练初期,准确率同样增长较快,当训练到100 epoch时,准确率趋于平稳,最高准确率可达94.37%。
从实验数据中可以发现该模型通过金字塔卷积扩大了模型的感受野,一定程度上提取了面部表情多尺度特征,再加入SECA 坐标注意力机制后,准确率得到了进一步的提升,但网络运算速度有略微的损失,DS能够有效降低网络参数量,提升模型的准确度。本文提出的模型相比于原模型来说,在FER2013、CK+和JAFFE 三个数据集上,准确率分别提高了4.17 个百分点,3.34 个百分点和3.32 个百分点,参数量相比于原网络降低了20.54%,可以证明本文提出的模型具有更好的准确性,同时拥有更快的运算速度。
为了进一步验证本文提出的模型的有效性和健壮性,混淆矩阵实验如图9所示。
从FER2013数据集上的混淆矩阵可以看出生气、害怕、厌恶和伤心这四类的识别准确率较低,因为这四类面部表情的活动不太明显,特征点难以提取。在CK+数据集上各个类别的识别表现都比较好,精确度都比较高。在JAFFE 数据集上,生气、厌恶和伤心这三类的识别精确度较低,可能是被错误识别的样本表情都属于较消极类情绪,相似度较高,难以提取面部深层特征,因此识别难度较大。
3.5 与其他方法对比
为了验证本文提出的MCAPyResnet 算法针对人脸面部表情识别的有效性,主要与AlexNet、VGG19、ResNet18、Pyconv50 和ResNet50 五种主流算法进行对比实验。除此之外,将本文提出的方法与最近几年比较先进的面部表情识别方法进行对比。现有的较先进方法有:Zhang 等人[28]通过使用多尺度注意力来提取人脸表情的特征信息;在网络中引入Inception 结构,使用ECA注意力强调与面部表情相关区域的模型Minaee[29];Han 等人[30]基于融合注意力模块和轻量化神经网络ShuffleNet V2 的表情识别模型,提出了两种注意力机制融合的卷积神经网络;通过在AlexNet 网络中引入多尺度卷积表示出不同尺度的特征信息,并在把多个低层次特征信息向下传递的同时与高层次特征信息进行跨连接特征融合模型Em-AlexNet[31];在StarGAN基础上提出了一种修改重构误差实现面部表情转换的方法[32];通过加入了区域注意力网络关注面部表情局部特征,排除了无用特征的干扰,提出了一种联合归一化方法,增强特征信息交流的同时优化了数据的归一化方法FFCN[33];Ju[34]设计了一种基于深度可分离卷积结构的改进卷积神经网络模型;将残差块赋予空间掩膜信息的模型MIANet[35];使用双通道加权混合的深度卷积模型WMDCNN[36]等。具体结果如表3所示。
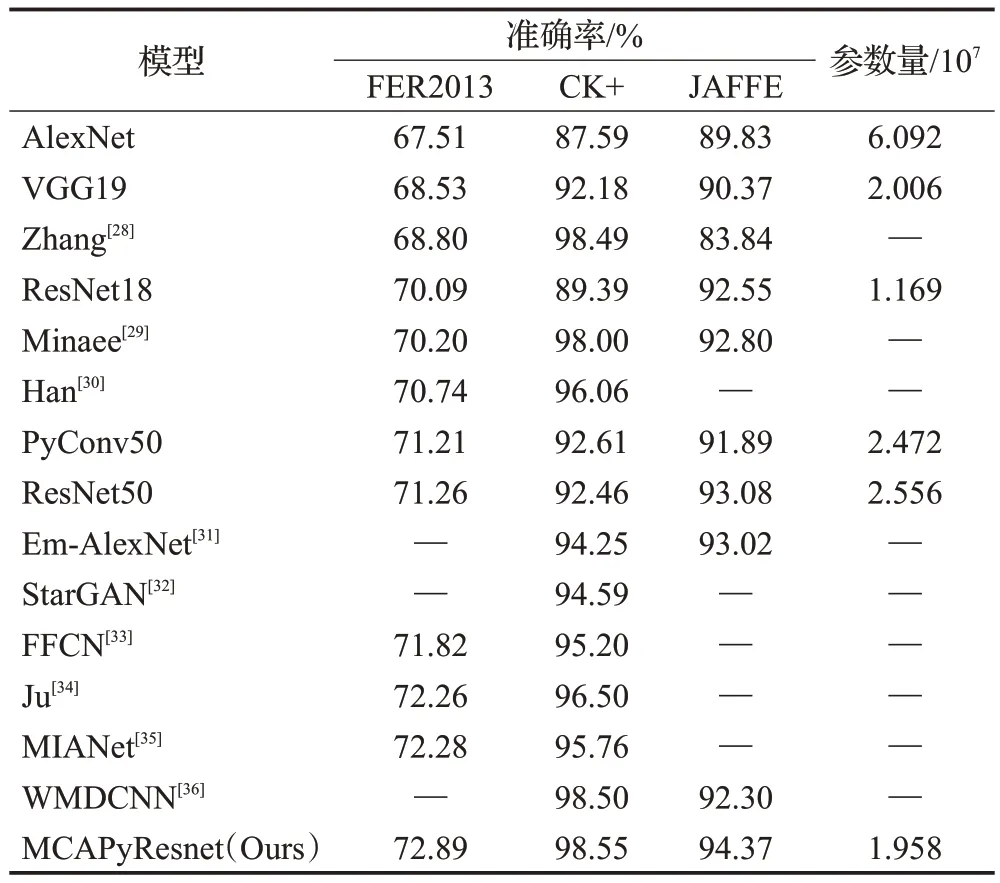
表3 与其他方法对比实验Table 3 Comparative experiment with other methods
由表3 可知,本文提出的MCAPyResnet 算法在FER2013数据集、CK+数据集和JAFFE数据集上都取得了更好的识别效果。在FER2013 数据集上相对于经典的卷积神经网络ResNet50 模型识别效果提升了1.63 个百分点,ResNet50 模型虽然已经达到了人类的识别水平,但是对面部表情特征提取能力仍不足,相比较文献[30],识别效果提升了2.15 个百分点。文献[30]通过将两种注意力机制融合形成的特征提取模块能够加强对面部表情的识别能力,但效果仍不够理想。文献[35]将残差块赋予了空间信息,其结构适合FER2013 数据集,但在其他数据集上的表现不够好。相比较于文献[28-29,33-34],本文提出的模型识别效果分别提升了4.09个百分点、2.69 个百分点、1.07 个百分点和0.63 个百分点。上述文献都缺少对不同尺度大小的面部表情特征进行分析,相比之下,本文不仅提取不同尺寸的面部特征,还提出了新的注意力机制更深层次表示面部表情的特征信息。从CK+数据集上的实验结果来看,主流网络中PyConv50 模型的识别精度最高,而本文提出的模型相较于PyConv50 识别精度提高了5.94 个百分点,相比较于文献[31],本文模型效果提升了4.30个百分点。文献[31]采用了低层次特征信息在向下传递的同时与高层次特征信息进行跨连接特征融合,导致了对分类过程中有影响的特征比较少,因此识别结果偏低,相比较文献[36],识别效果提升了0.05 个百分点。文献[36]在CK+数据集上的表现较好,但是在其他数据集上的准确率有待提升。相比于其他文献或主流网络,本文提出的模型都取得了更好的实验效果,在JAFFE数据集上的识别精度高达94.37%,相比于主流算法ResNet50 提升了1.29 个百分点,相比较于文献[31]提升了1.35 个百分点。文献[31]引入了多尺度卷积表示面部表情的不同尺度特征,但是对面部表情无关信息抑制不够明显,相比较于文献[28-29,36],本文的识别效果分别提升了10.53 个百分点、1.57个百分点和2.07个百分点。上述文献都缺少了关注面部表情的重要信息,没有抑制无关信息对模型的干扰,相比之下,本文提出的模型具有更高的准确性和鲁棒性。通过以上实验可以证明本文提出的MCAPyResnet算法在人脸面部表情识别上的精度最高,算法性能最好,并且具有较强的泛化能力。
在模型参数量方面,本文提出的网络模型参数量为1.958×107,相较于ResNet18网络,参数量增加了7.89×106,虽然参数量有所上升,但是识别效果却大幅提升,相比于其他主流网络,模型保持高精度的情况下同时拥有较少的参数量,验证了模型的先进性和优异性,同时进一步验证了本文提出的改进方法对于模型轻量化的有效性。
4 结束语
本文提出了一种多尺度坐标注意力金字塔卷积的面部表情识别网络,有效地抑制了无关特征信息对模型的影响,同时减缓了神经网络层数过多造成梯度消失的情况,减少了网络计算的参数量,提高了模型的运算速度。优化的金字塔卷积扩大了模型的感受野,通过多个滤波器捕捉了不同环境下、不同场景的信息,从而提高了模型的性能。改进的SECA 坐标注意力机制模块更多关注特征信息,加快模型的收敛速度,提高模型的性能。深度可分离混洗方法减少了网络计算的参数量,同时加快了网络的运算速度。本文提出的模型MCAPyResnet 在FER2013 数据集上的准确率为72.89%,在CK+数据集上的准确率为98.55%,在JAFFE 数据集上的准确率为94.37%,同时拥有较低的参数量。实验结果优于目前诸多主流算法,展现了较好的有效性和鲁棒性。但在面部表情有遮挡的情况下识别精度仍不够高,在未来要多关注这类数据集的识别性能。
