基于注意力及边缘提取任务的实时分割网络
2023-11-27杨一鹏熊俊臣韦胜男
文 凯,杨一鹏,熊俊臣,韦胜男
1.重庆邮电大学 通信与信息工程学院,重庆400065
2.重庆邮电大学 通信新技术应用研究中心,重庆400065
现有语义分割方法通过有效的模型设计,在推理速度和精度上取得了一定成功。精度提升主要体现在道路、建筑物等大目标上,而在交通灯等小目标物体上的分割却不理想。尽管一些方法利用横向链接[1]及条件随机场[2]改善了物体的分割边界,但仅是提高了边界信息的恢复能力,已经损失的细节信息则无法恢复,以致分割边界较为离散,易出现断续的情况。造成这种现象的原因有:(1)将级别程度不同的颜色、形状及纹理信息放在同一网络中处理,导致处理精度相对不高。(2)小目标在训练过程中对整体损失贡献较小,故在训练过程中易被忽略。
近来,一些研究采用语义流及边缘流协同处理的方式,获得了不错的精度提升。文献[3]通过像素向对象内弯曲获得相应的主体特征,再采用差值得到边缘特征,随后对它们分别监督并进行融合。Takikawa 等人[4]提出了一种用于语义分割的门控形状卷积设计网络(gated shape convolutional neural network,GSCNN),通过门控卷积层及激活函数抑制了与边界无关的信息,从而使形状流分支只关注与边界相关的信息,有效地改善了边界清晰度及小目标分割精度。
非对称卷积已用于许多有效模型,非对称卷积将标准n×n卷积更改为n×1 卷积和1×n卷积,文献[5-6]利用非对称卷积,通过分解标准卷积减少模型参数,在不损失有效信息的前提下,加快训练速度。文献[7]利用短期密集拼接(short-term dense concatenate,STDC)设计了语义分支,并通过提取的边界信息恢复了下采样损失的细节信息,在验证集上获得了较好的性能表现。本文将非对称卷积与短期密集拼接模块相结合,减少了原有STDC模块的参数。
使用注意力机制可显著提升模型的精度。文献[8]提出了一种用于场景分割的双重注意网络,可以基于自注意机制捕获丰富的上下文依赖关系。MSCFNe(tmultiscale context fusion network)[9]根据网络在不同阶段的不同情况引入空间注意力和通道注意力,自适应地提高提取特征的表征能力,极大地促进局部和上下文信息的交互。本文将空间注意力与通道注意力以并联方式融合,捕捉全局上下文信息和细节信息,提升精度。
在语义分割算法领域中,训练模型的精度与损失函数息息相关,现有的实时语义分割模型使用的损失函数有交叉熵损失函数、加权交叉熵损失函数、Focal Loss函数等,已有的损失函数不能很好地解决类不平衡方面的问题。因此最近文献[10]提出陌生人焦点学习(focal learning on strangers,FLS)的思想来关注小特征幅度值的样本,可以显著提高图像分割的分割精度。文献[11]提出动态平衡类损失(dynamically balance class losses,DBCL)的思想,并应用于三种先进的成本敏感型损失函数,提高了模型的分类能力。本文采用联合损失函数,对语义分支和边缘分支采用不同的损失函数指导模型训练。
通过上述分析,发现仍有以下几点不足:(1)在测试集上处理时由于缺乏标签,无法再采用边缘分支指导网络分割,对于实时的自动驾驶场景,缺乏边缘信息仍会导致物体在边界处的分割效果不佳,无法很好地应用于现实场景;(2)由于该网络在深层输出的通道数多,包含大量有用及无用特征,在解码时再采用类似通道注意的特征优化模块(attention refinement module,ARM)来筛选深层语义特征对精度的提升作用不大;(3)BiSeNet V3[7]采用拉普拉斯算子在突出边界信息的同时也增强了噪声,此外,提取的边缘信息单一,未利用语义分支特征,导致精度提升受限;(4)小目标分辨率低,使得可视化信息过少,以及小目标的边界信息容易受周围像素影响,导致分割精度误差大。
针对上述不足,本文的主要工作内容及贡献如下:
(1)边缘分支设计了边缘特征融合模块,可利用上一层边缘特征滤除语义特征中与边界无关的信息,并以通道拼接的方式获取更充足的边界细节信息。它促进了语义分支及边缘分支的信息交流,提高了小目标对象的边界分割精度,并使网络在真实场景下仍能利用边缘信息分割。
(2)受NLNet[12]空间注意力机制及SENet[13]通道注意力的启发,在语义分支中设计了能同时对通道域及空间域建模的轻量全局注意力模块,使网络能够筛选出更符合分割任务的有效特征。
(3)为使网络在训练时侧重于向着利于提高小目标分割精度的方向更新参数,采用改进的加权交叉熵损失函数,进一步改善了小目标的分割质量。
1 基于全局注意力及边缘提取任务的双流分割网络
本文结合注意力及边缘分支设计了能同时提高小目标分割精度及边界清晰度的双流分割网络(two stream segmentation network based on attention mechanism and edge detection,AMEDNet),它是通过边缘分支及语义分支以并联的方式交织而成,如图1 所示。该网络主要由获取边缘信息的边缘分支——边缘特征融合模块(edge feature fuse module,EFFM)、短期密集拼接(STDC)模块设计的语义分支、全局注意力模块(global attention module,GAM)及阶段融合模块(stages fuse module,SFM)构成。图1中,Lseg及Ledge分别为分割任务及边缘信息提取任务的损失函数;stage1、stage2每个阶段为两个3×3 卷积,stage3、stage4、stage5 每个阶段为一个STDC-AC2模块和两个STDC-AC1模块。
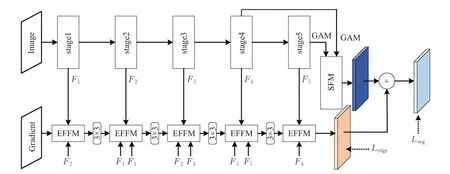
图1 AMEDNet结构示意图Fig.1 Schematic diagram of AMEDNet structure
1.1 边缘分支
边缘分支设计的目的是在解码过程中,将低级的边缘信息同高级的语义融合,弥补损失的边界细节信息。该分支的核心是边缘特征融合模块(EFFM),如图2 所示。它能帮助语义特征滤除与边界无关的信息,从而得到低级的粗粒度语义边界。
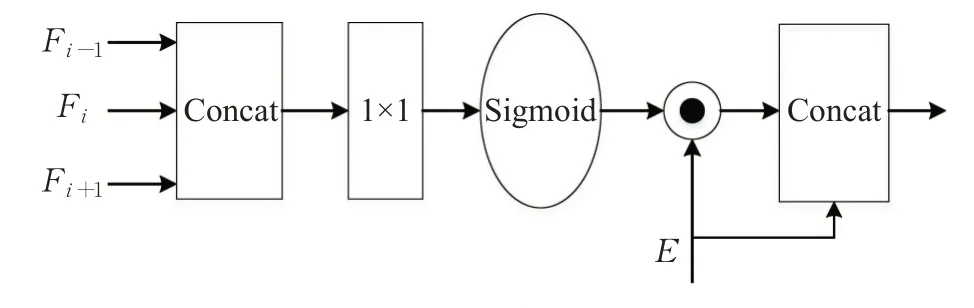
图2 EFFM结构示意图Fig.2 Schematic diagram of EFFM structure
在图2 中,EFFM 首先将本阶段及其相邻两阶段输出的语义特征作为输入,并将这些特征在通道域上进行拼接,这里Fi是语义分支第i阶段的输出特征经上采样操作所得。拼接后的特征采用1×1 的卷积操作对通道维度进行压缩,然后经过Sigmoid激活函数,将其输出同上一层边缘特征E在空间维度上点乘,得到相应的语义边界。最后,将此边界信息同E以通道拼接的方式得到下一层边缘。该模块利用边缘特征抑制了语义特征中与边缘无关的信息,并进一步丰富了边缘信息。EFFM可被表示为:
式中,||为通道拼接操作,F为相关阶段特征经上采样及拼接操作后的输出。值得注意的是,边缘分支中第一个EFFM的语义特征只包含F1及F2,且其输入梯度图由输入图像经Canny检测后所得,最后一个EFFM 的输入语义特征为F4及F5。
1.2 语义分支
在语义分割任务中,感受野过小会导致特征局部感知,感受野过大又会出现一些无用的信息,它们都会对网络的分割性能造成不利影响。比较常用的方法是利用多尺度来克服上述缺陷,一些研究[14]也表明多尺度信息可有效地改善网络性能。由于BiSeNet V3[7]中采用的短期密集拼接(STDC)模块聚合了多个卷积操作的输出特征,其输出含有丰富的多尺度信息,因此AMEDNet的语义分支设计引入了该模块。由于边缘分支、全局注意力模块及阶段融合模块的引入会额外增加浮点计算量而延缓网络的推理速度,本节结合非对称卷积对STDC模块做了轻量化处理,将其称为结合非对称卷积的短期密集拼接(short-term dense concatenate module combined with asymmetric convolution,STDC-AC),具体情况见图3。其中ConV表示卷积操作;M为输入通道的维数;N为输出通道的维数;AVGPool为平均池化。

图3 STDC-AC结构示意图Fig.3 Schematic diagram of STDC-AC structure
在图3中,图(a)可用于多尺度提取的特征映射,图(b)可用于语义分支的下采样过程。在对STDC进行轻量化处理后,模块涉及的参数量为:
其中,M及N分别表示为模块的输入、输出通道数,n为该模块中隐藏层的数量。相较于STDC模块,STDC-AC涉及的参数量更少。本节利用STDC-AC 模块,重新设计了语义分支,详细的设计细节如表1所示。
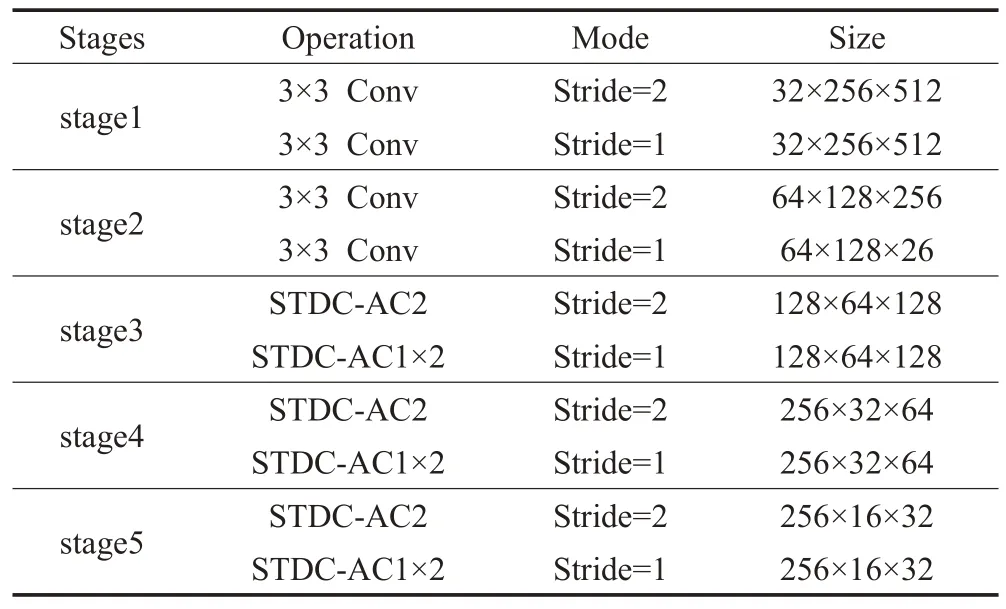
表1 语义分支各阶段设计Table 1 Design of semantic branch at each stage
语义分支共包含五个特征提取阶段,前两个阶段均采用步长为2的3×3卷积缩减特征尺寸,随后利用步长为1的3×3卷积核完成特征映射。这两个阶段主要被用于提取浅层的低级信息。后三个阶段为解码过程的重要部分,它们均采用STDC-AC1 及STDC-AC2 进行设计:首先采用STDC-AC2 对输入特征进行下采样,然后采用两个STDC-AC1来处理下采样后的输出。通常,深层应更多关注感受野及多尺度信息,而浅层需要足够的通道来编码细粒度信息,将深层的通道数目设置过大会导致信息冗余且不利于网络的实时性。因此,本文在语义分支的前两个阶段设置的输出通道数分别为32、64,与BiSeNet V3 网络保持一致,后三个阶段设置的通道数分别为128、256、256,而BiSeNet V3网络中后三个阶段的通道数分别为256、512、1 024,相比之下,本文在语义分支的深层提取的通道数要远远小于BiSeNet V3网络。为了补充由于通道数减少而缺失的信息,本文设计了全局注意力模块。
1.3 全局注意力模块
AMEDNet 在语义分支设置的输出通道数不及BiSeNet V3 多,因此如何筛选出有用的特征来满足分割质量是十分重要的。此外,语义分支在第四及第五阶段损失了较多空间细节信息,为避免分割质量下降,一些网络会采用跳跃连接[1]来弥补损失的细节信息,但这种方式无法对像素间的关系及通道间的重要程度建模。因此,AMEDNet 结合NLNet 空间注意力及SENet通道注意力设计了全局注意力模块(GAM),其结构如图4所示。

图4 全局注意力模块Fig.4 Global attention module
全局注意力模块由通道注意力分支及空间注意力分支以并联的方式融合而成,采用这种方式可以加快训练时的收敛速度并避免过拟合现象。此外,它可在空间域及通道上重新衡量深层语义特征与目标任务的相关程度,从而使粗糙的特征图能更好地符合分割任务,并实现分割效果的优化。
1.4 阶段融合模块
在AMEDNet 的解码部分,采用了阶段融合模块(SFM)来聚合语义分支的相关特征,见图5。首先SFM对经GAM处理的第五阶段特征进行上采样及3×3卷积操作,得到尺寸大小1/16的特征,随后与经GAM处理的第四阶段特征逐像素相加,最后再以同样的方式同第三阶段特征进行像素级相加。SFM 模块经过以上操作后可用下面的公式来表示其输出:

图5 阶段融合模块Fig.5 Stages fuse module
式中,⊕表示像素级相加操作,xstage5-GAM为经上采样操作的输出,conv3×3及onv3×3(·)分别表示3×3 卷积及对·进行上采样后再进行3×3卷积操作。
1.5 多任务损失函数
AMEDNet 设计的方法包括语义分支及边缘分支,边缘分支提取的边界信息为低级信息,而语义分支的输出特征为高级语义信息,若采用单一的交叉熵损失函数来指导网络学习是不合理的,故在网络训练时,采用了联合损失函数。其中对于语义分割任务,在加权交叉熵基础上进一步改进,对于边缘提取任务,则采用二进制交叉熵(binary cross-entropy,BCE)损失函数来指导该分支[15]。
采用交叉熵损失函数会导致网络向着易分样本方向学习,以致网络对小目标的处理效果不佳。尽管加权交叉熵解决了数据集中各类别像素占比不平衡问题,但是从本质上来说,随着训练程度的加深,网络的参数仍然会侧重于向着易分样本更新。这是因为当Softmax输出概率值较大时,该像素被判别为数据集中易分样本的可能性更高;反之,当输出的概率值较小时,最后的预测输出可能会将它忽略,但它可能对应的正是难分样本,难分样本在图片中所占像素少,比例小,因此称为小目标类别。Focal Loss[16]是一种处理样本分类不均衡的损失函数,常用于解决二分类问题,它给易区分的样本添加较小的权重,给难区分的样本添加较大的权重,也就是增加小目标对象的类别权重,使得训练时模型更多关注小目标对象。本节将Focal Loss 与加权交叉熵损失函数相融合,应用于多分类的语义分割任务中,改进的损失函数为:
式中,C为预测的通道数,X是各通道对应的像素空间,n是输出的C个通道对应的所有像素数目总和,γ为聚焦参数,被用于聚焦难分样本。ygt及yp分别表示数据集的真实标注及网络的预测输出。wi为各类别权重系数,用于改善类别不平衡问题,其定义为:
式中,c是一个额外的超参数,设置为1.12,pi表示每个类别的概率。通过上式,将易分样本,例如道路、建筑、汽车等类别所占权重降低,将难分样本,例如交通灯、行人、自行车等类别所占权重增加,以此来改善类别不平衡问题。
式(4)是对加权交叉熵损失函数的一种改进,对于易分样本来说,yp(i)对应的值较大,引入该式会使它在总损失中的占比被削弱;反之,难分样本产生的损失在总损失中的比值会有所提升,使得整个网络更有利于小目标的训练识别。对于边缘提取任务,AMEDNet 采用了式(5)的二进制交叉熵损失函数来指导边缘分支并更新相关参数。
式中,及分别表示为由真实标注生成的边缘标注及边缘分支对应的预测。由于数据集中的训练集未提供边缘标签,故AMEDNet采用式(6)来获取相应的二值化标签,表示为:
式中,MaxPooling 为最大池化,θ为卷积核大小,它可控制边界像素宽度,onehot 可将数据集中的语义标签按0与1编码。因此,最后联合损失函数可被表示为:
式中,Lseg及Ledge分别为分割任务及边缘信息提取任务的损失值。
2 实验与分析
AMEDNet设计的目的在于实现推理速度及分割精度平衡的前提下,提高数据集中小目标的分割精度及边界清晰度,故在实验中使用了网络参数量、推理速度、平均交并比及各类别的交并比来进行评价。
本文设计的网络是从自动驾驶场景的落地应用方面考虑的,因此实验是在Cityscapes及CamVid两个道路场景数据集上完成的。Cityscapes数据集被广泛使用在图像语义分割领域,该数据集包含2 975 个训练图像、500 个验证图像和1 525 个具有精确像素级注释的测试图像。注释包括30个类,其中19个用于语义分割任务,图像为1 024×2 048 的高分辨率,实验中使用分辨率为512×1 024 的测试集图像进行评估。CamVid 数据集为道路街景数据集,该数据集包含701 张注释图片,其中367 张训练图像、101 张验证图像和233 张测试图像,并且有11 个类别用于语义分割任务,图片的分辨率为720×960,实验中使用分辨率为720×960 的测试图像进行评估。
2.1 实验环境及设置细节
本文的实验都是在1080Ti GPU 上执行的,Pytorch的配置环境是CUDA 9.0,cuDNN V7。为了充分利用GPU显存,在训练模型时,批处理大小被设置为8,动量为0.9,采用权重衰减为0.000 1 的优化器对模型进行优化。本文采用“poly”学习率策略,初始学习率设置为0.045,动量为0.9。由于本研究没有采取任何的预训练机制,训练时epoch被设置为1 000。
另外,为更好地拟合网络,提升模型的泛化能力,本研究采用了数据增强策略。随机水平翻转、随机放缩等常用的数据增强策略被用于训练过程,且随机缩放因子为{0.75,1.00,1.25,1.75,2.00}。最后将图片随机裁剪成固定大小用以训练。
2.2 消融实验
本节首先在Cityscapes数据集上验证了边缘分支及GAM 对网络性能的影响,然后在AMEDNet 及BiSeNet V3 上设置了一系列对比实验来验证网络设计的有效性。下面对具体的实验细节进行详细的阐述及分析。
(1)边缘分支验证。为使物体的分割边界更加清晰并改善小目标的分割精度,AMEDNet在解码时,将边缘分支提取到的边界细节信息同阶段融合模块的输出特征进行了逐像素相加操作,以弥补特征图中与边界及角落相关的信息。故本节通过实验验证了边缘分支对网络的性能影响,结果如表2所示。

表2 边缘分支有效性验证Table 2 Edge branch validity verification
从表2可知,含有边缘分支的网络在精度上提高了2.4 个百分点,验证了边缘特征融合模块可以帮助语义特征滤除与边界无关的信息,得到低级的粗粒度的语义边界。此外,边缘分支对网络的前向推理速度不会产生太大影响,速度达到了118.6 FPS,这与现有的实时分割网络的推理速度相比,依旧可观。这是因为边缘特征融合模块在对语义分支特征进行通道拼接操作后,采用的1×1 卷积层直接将输出通道设置为1,这种设计所包含的参数量及浮点运算量不会大量增加。因此,边缘分支以较小的计算代价帮助解码阶段特征恢复了重要的边界细节信息,有效地改善了分割效果。
(2)全局注意力模块验证。所提网络的深层语义特征数量不及BiSeNet V3[7]且在解码过程未利用浅层语义特征,为避免对分割精度产生影响,所提网络采用了GAM来优化语义分支第五阶段及第四阶段的输出。为验证其影响,本节对是否添加GAM 及GAM 的添加位置做了相关实验,结果如表3 所示。由表3 结果可知,Baseline 的平均交并比为72.9%,而在语义分支第四阶段及第五阶段单独增加全局注意力模块所产生的平均交并比分别提高了1.6 个百分点及0.8 个百分点,说明GAM有效地帮助语义分支特征实现了像素间的关系建模及通道域上的关注,改善了网络的分割效果。由于第五阶段损失的空间细节信息更多,GAM 的优化作用相对较弱,这也造成了Biseline+GAMstage4产生的分割精度高于Biseline+GAMstage5。尽管它们的参数量一致,但Biseline+GAMstage5对应的推理速度更快,其原因在于语义分支第五阶段特征尺寸更小,相应的浮点计算更低所致。同时对语义分支第四阶段及第五阶段采用GAM处理的网络Biseline+GAMstage4+GAMstage5获得了74.9%的平均交并比及118.6 FPS的推理速度。相比之下,Biseline+GAMstage4+GAMstage5在推理速度及分割精度的平衡上更具优势,故成为了AMEDNet设计采用的方案。

表3 全局注意力模块有效性验证Table 3 Validation of global attention module
(3)同BiSeNet V3 的对比验证。为进一步探究网络设计的合理性,本节将BiSeNet V3 解码阶段的特征优化模块(ARM)替换为全局注意力模块(GAM),并将其输出结合阶段特征融合模块(SFM)设置了消融对比实验,结果如表4及图6所示。

图6 同BiSeNet V3的消融可视化对比Fig.6 Ablation visualization comparison with BiSeNet V3
由表4可知,AMEDNet以1.78×106的参数量获得了74.9%的平均交并比。这是因为采用拉普拉斯算子会导致梯度图产生与边界无关的噪声,且边缘信息直接被融合进语义分支,导致两分支之间缺乏信息交互,从而限制了分割精度。在STDC2 的基础上,增加GAM、SFM能够对深层语义特征在空间域及通道域上进一步优化,故其精度提高了0.4 个百分点。但在上采样过程中,GAM、SFM 处理的通道数为1 024 及512,而ARM 则是先采用3×3的卷积将通道数降维到128后再进行通道域关注。相比之下,STDC2+GAM+SFM 的运算量会显著增加,故其推理速度受到了显著影响。为避免GAM、SFM 影响网络的实时推理,AMEDNet 缩减了深层语义特征数目,但其分割精度仍然高于STDC2+GAM+SFM,表明融合语义分支特征的边缘分支获得了更为充分的边缘细节信息,且该分支的设计比BiSeNet V3 更为有效。图7 进一步给出了AMEDNet 边缘分支的输出特征,由可视化结果可知,在语义特征及梯度图的共同作用下,边缘分支获得了很好的边缘掩码,解码阶段依靠该信息可有效地恢复出与细节相关的信息,从而提高网络最终的分割精度。

图7 边缘分支预测可视化效果Fig.7 Visualization of edge branch prediction
前两组实验验证了边缘分支及GAM 模块的有效性,第三组消融对比实验进一步表明GAM 对精度的提升作用大于ARM,且AMEDNet采用边缘分支获得的边缘细节信息对网络的精度提升优于BiSeNet V3[7]。此外,当面临真实交通环境时,AMEDNet仍可采用边缘信息指导网络预测,相较于BiSeNet V3,本文所提方法具备更高鲁棒性。
2.3 网络性能对比
为验证所提网络AMEDNet 的高效性,本节在相同实验条件下,选取了现阶段几种优秀的算法模型进行对比分析,这些网络分别为ENet[17]、ERFNet[18]、ESPNet[19]、ESNet[20]、DABNet[21]、LEDNet[22]、LADNet[5]、DSNet[23]、STDC2(BiSeNet V3[7]中提出的网络)。实验结果如表5 及图8所示,从精度上看,AMEDNet获得了74.9%的平均交并比,高于所有的对比模型,LADNet[5]和DSNet[23]分别低于AMEDNet 3.8个百分点和5.6个百分点。本文模型获得优异精度的原因有三点:首先,边缘分支有效地弥补了边缘细节信息,使得分割边界更加清晰;其次,STDC模块聚合了多尺度信息,且GAM 对深层特征做了进一步优化;最后,本文改进的损失函数会使网络参数向着利于难分样本的方向训练,提高了小目标的精度。图8的可视化效果也对其进行了很好的验证。在推理速度方面,AMEDNet也表现出巨大优势,取得了118.6 FPS,仅低于STDC2,因为GAM、SFM 对深层特征(通道数多)处理时涉及大量运算量,显著影响了网络推理速度,但速度仍然高于其他对比模型。从参数量来看,所提模型拥有1.78×106的参数,是LADNet[5]和DSNet[23]的接近两倍,但其他指标明显低于所提模型。综上所述,AMEDNet更能较好地兼顾精度和推理速度。
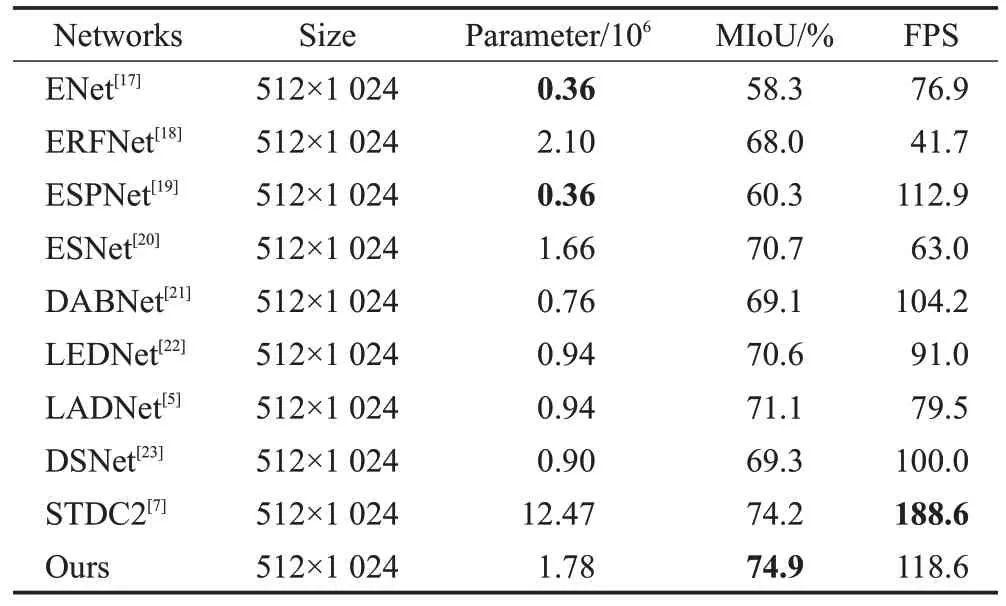
表5 Cityscapes数据集上的性能对比Table 5 Performance comparison on Cityscapes dataset

图8 Cityscapes数据集上的可视化效果Fig.8 Visualization on Cityscapes dataset
表6 进一步给出AMEDNet 在Cityscapes 测试集上的各类别交并比。由表中数据可知,所提网络在Sidewalk、Pole和Traffic Light等难以分割的小类别上获得明显的精度提升。可见提出的模型在提升小目标的分割精度上做出了贡献,在简单场景上性能表现也较为优越。
为验证所提网络的泛化能力,在另一个常用的数据集CamVid 上进行了相关评估实验。实验结果如表7和图9 所示,精度上,AMEDNet 优于其他对比模型,与LADNet[5]相比,精度提高4.3 个百分点;推理速度上,所提模型有着105.9 FPS的高处理速率,虽然略低于STDC2,但AMEDNet 仍以较高的推理速度获得了0.2 个百分点的精度提升,并且参数量远小于它;在参数量上,虽然AMEDNet 的参数量是最小参数量的5 倍,但所提模型的其余指标更优。综上所述,AMEDNet的平衡性更好,在资源受限的硬件设备上,所提网络更有优势。图9的可视化对比也表明,AMEDNet在例如柱子(图中黄色虚线框区域)等类别上的分割效果更好,且边界相对更为流畅。
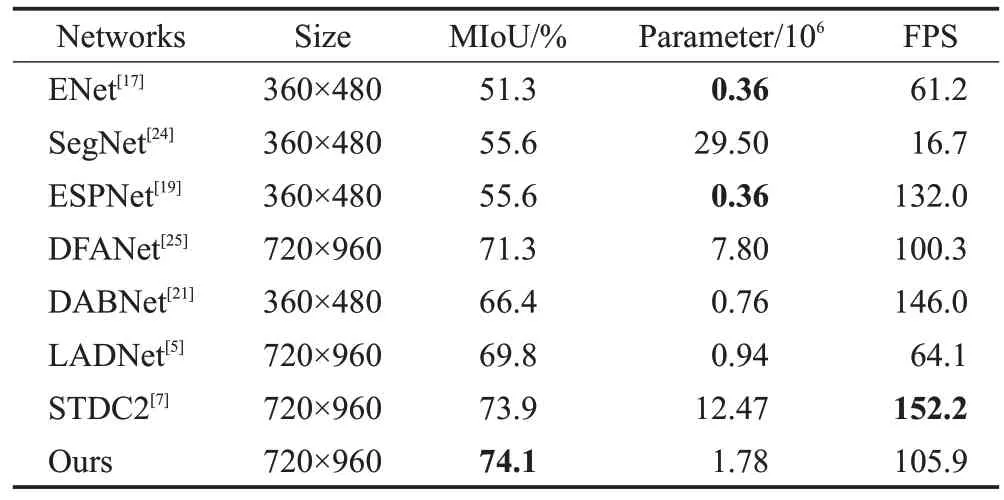
表7 CamVid数据集上的性能对比Table 7 Performance comparison on CamVid dataset
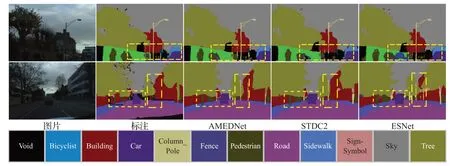
图9 CamVid数据集上的可视化效果Fig.9 Visualization on CamVid dataset
2.4 真实场景对比
由于AMEDNet 面向的是智能驾驶场景,它在真实环境下对图像的处理效果是值得关注的重点。因此,本节利用学校附近拍摄的几张道路场景图片做了进一步对比,其分割效果如图10。
在第一行对比图中,黄色虚线框对应的远方区域被进一步放大。从结果来看,STDC2 对远方柱子的分割出现了断续,而AMEDNet 却能够完整地分割出来。此外,由其他几组对比图可知,本文所提方法在物体的分割边界上,明显优于其他网络。由此证明,AMEDNet在真实环境中,依靠边缘信息指导所产生的分割效果更好。
3 结束语
本文提出了一种基于注意力及边缘检测的双流语义分割网络AMEDNet,它是对BiSeNet V3 的一种改进。首先,边缘特征融合模块结合多个阶段的语义特征,丰富了边缘信息,并在解码时帮助特征有效地恢复了边界细节。其次,全局注意力模块在通道及空间维度上对特征重要程度及像素间关系进行建模,增强了特征信息间的全局相关性,并使用阶段融合模块来聚合经GAM 处理的优化特征。最后,为改善小目标的分割精度,在加权交叉熵基础上,将Focal Loss 应用到多分类的语义分割任务中,使网络能够向着利于小目标分割的方向更新参数。实验表明,AMEDNet 在保证推理速度及分割精度平衡的前提下,改善了边界清晰度及小目标分割精度,并在真实的道路场景下仍具有很高的鲁棒性。尽管本文方法在小目标的分割精度上取得了一定进步,但是其分割精度仍然较低。有些小目标对应的类别在自动驾驶场景中十分重要,因此如何利用有效的方法进一步提高精度仍然具有十分重要的研究意义。此外,运用于自动驾驶的网络模型往往在一些资源受限的设备上,因此设计的网络应该考虑在嵌入式平台上评估性能。
