改进SSD特征融合的目标检测算法研究
2023-11-27葛海波黄朝锋
葛海波,李 强,周 婷,黄朝锋
西安邮电大学 电子工程学院,西安710121
随着计算机视觉的快速发展,目标检测越来越受到关注。自从DNN(deep neural networks)[1]被引入以来,在目标检测上比传统方法具有更高的鲁棒性和准确性。近年来,相继出现了多种基于深度学习的目标检测算法,如Faster R-CNN(faster region-based convolutional neural network)[2]、SSD(single shot multibox detector)[3]、DSSD(deconvolutional SSD)[4],YOLO(you only look once)[5]系列等。不同的目标检测算法对同一物体检测的结果也有所不同。
SSD 算法基于VGG(visual geometry group)[6]的主干网络,从Conv4_3、FC7、Conv8_2、Conv9_2、Conv10_2、Conv11_2中提取了6组不同尺度的特征,通过非极大值抑制进行筛选,根据筛选出的default box在检测图像中绘制检测框,并标出类别和得分[7]。SSD 网络结构如图1 所示。但是SSD 模型用于检测的低层特征层只有一层,特征细节信息较少,导致图像的分辨率显著降低,目标遮挡或背景污染会导致检测效果变差。Fu 等人[8]提出DSSD 模型,采用特征提取能力更强的ResNet-101主干网络。DSSD 保持了SSD 目标检测的6 个特征图,直接将最深层的特征层用于分类回归,然后经过反卷积模块与前一层特征逐层元素相乘并进行输出,但由于DSSD 模型网络层数更深,大大降低了物体检测速度,使得实时性较差。同时期RSSD(rainbow SSD)[9]通过增加特征图的通道数来提高检测效果,在浅层特征图中通过池化融合到深层中,在深层特征通过反卷积融合到浅层中,因为每一层的感受野不同,需要归一化来融合每个层的尺度,从而达到检测的效果。FSSD(feature pyramid SSD)[10]则是通过对FPN(feature pyramid networks)进行改造,将来自不同尺度的特征连接在一起,使用批量归一化对特征值进行归一化,通过下采样生成新的特征金字塔进行预测。因此,如何将高低层特征融合来提高检测精度和速度成为一大挑战。
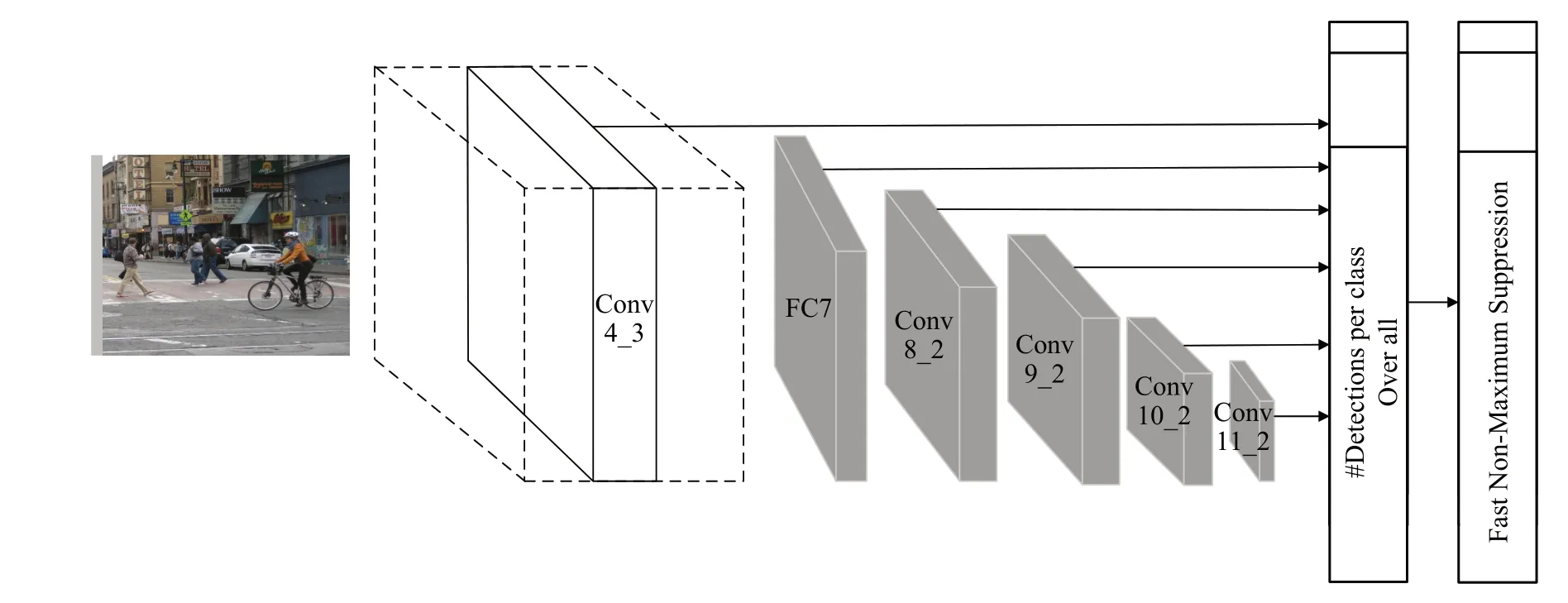
图1 SSD网络结构Fig.1 SSD network structure
为了减少网络的深度,同时提高检测的速度和准确性,研究人员对感受野进行了研究。感受野的应用增强了大脑表征这个地区。Liu等人[11]提出结合多分支结构卷积的感受野模块的RFB-Net(receptive field block net)模型,通过将RFB 替换SSD 的顶部卷积层,并使用空洞卷积进一步增强目标检测能力。Inception[12]通过使用不同大小卷积核,提取不同尺度特征,使用3 个不同分支,不同分支分别使用1×1、3×3和5×5不同的卷积核和膨胀率为1、3、5的空洞卷积获得不同的感受野,然后将所有的特征图连接起来。将RFB模块融合到SSD中可以提高目标检测精度。
基于深度学习的目标检测算法依然存在一些被遮挡的目标或者小目标识别效果较差,检测精度不高。本文基于SSD目标检测算法进行高低层特征融合,设计了一种既能提高目标检测精度又能保证检测速度的算法。该算法是将深层Conv9_2、Conv10_2、Conv11_2 三层特征层进行反卷积得到新的Conv10_2、Conv11_2,在深层特征中使用反卷积是为了将深层特征融合输出后而不影响特征层图尺寸大小。输出新的特征层Conv10_2以及新的Conv11_2是将原有的特征层以及相邻的特征层特征叠加,还原操作后特征图分辨率变小的问题,有利于进行目标定位。使用RFB模块提高感受野的同时减少参数计算量,由于浅层生成的小目标特征缺乏足够的语义信息,对于浅层的小目标检测依赖上下文信息,故将浅层Conv4_3、FC7、Conv8_2分别在卷积操作后进行特征连接,提高小目标的信息特征。最后对改进的SSD 结构进行再训练。本文选取输入尺度相差不大的SSD、DSSD模型做对比实验,通过比较mAP值和检测帧数FPS(frames per second)来验证改进算法的检测结果。
1 相关工作
1.1 算法改进
SSD网络生成的预测框质量较低,导致复杂环境下目标定位失败,影响检测结果[13]。本文提出一种新的特征融合的SSD算法,其网络框架如图2所示。该算法主要设计了三个模块来增强特征图尺度信息。首先,使用浅层特征融合模块来增强保留的特征细节信息,从而提高对复杂背景或者小目标检测的能力。因为在SSD 算法中靠前的特征层卷积次数较少,相对靠后的有效特征层包含的语义信息少,导致在检测小目标时信息不够全面以及将图片resize 到300×300 的尺寸时,同样对于小目标的尺寸也会随之减少,可能会使小目标失真,从而影响整个网络的检测精度。然后,通过反卷积模块获得上下文信息增强的同时,将特征图还原为原来特征图尺寸的大小,避免还原后的特征图分辨率变小。为了融合不同的特征信息,使用不同膨胀率的卷积来增强网络感受野。在SSD 算法中Conv4_3 层的先验框默认为38×38×4,FC7 层的先验框默认为19×19×6,改进的算法使用RFB 模块后将Conv4_3 和FC7 层融合后得到的先验框总数为38×38×6。选取了Conv4_3层中的网格数38×38,同时选中FC7层中的rate=6的先验框可以减少参数计算量,增加Conv4_3 层和FC7 层之间的关联,不同于在网络中提取不同尺度的特征进行独立预测。另外RFB是镶嵌在改进算法中,在改进算法中融合多个不同尺度的特征层,故检测精度也随之提升。对于在小目标检测能力不足的情况下,通过特征连接将Conv4_3、FC7、Conv8_2 大特征图尺寸使用不同层的附加特征作为上下文,在连接融合之前对上下文特征执行反卷积,使其具有与目标特征相同的空间大小。同时利用反卷积操作将Conv9_2 与Conv10_2,Conv10_2 与Conv11_2二者特征融合在一起,得到新的特征层,经过感受野增强模块捕获更多的目标区域特征。其中图2 灰色部分为提取的特征图,红色部分则是融合后的特征图。最后,经过非极大值抑制进行分类筛选,得到检测结果。
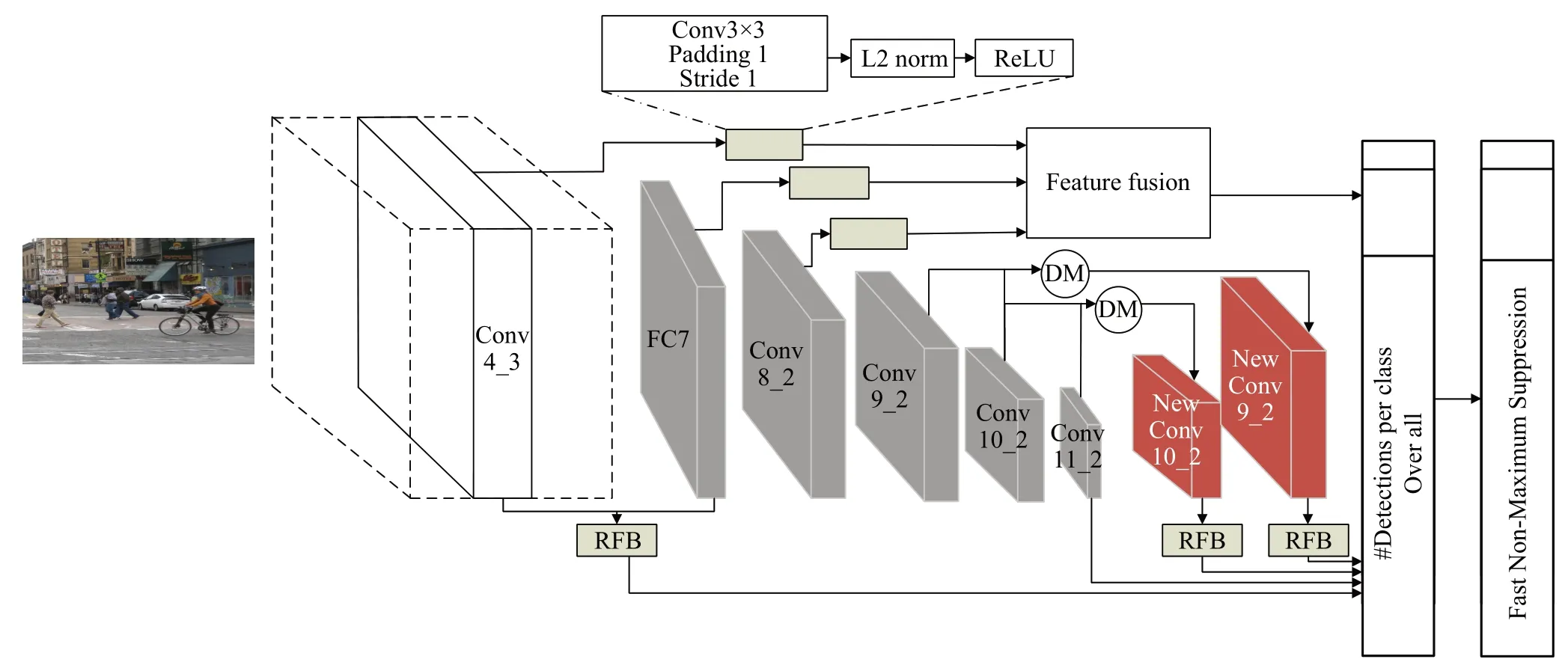
图2 改进的SSD网络结构Fig.2 Improved SSD network structure
1.1.1 RFB模块
RFB模块中引入了空洞卷积,主要作用是增加感受野,应用在检测任务中来获得较大的感受野,提高网络的特征提取能力。使用RFB在增加感受野的同时能够减少参数量。这是因为RFB模块上有多个分支,每个分支的第一层都由特定大小卷积核构成。不同点在于引入3个dilated卷积层(比如3×3Conv rate=1)。RFB结构是一个并联的结构,输入有5 个并行的分支,第一个是进行1×1的卷积,然后进行膨胀率为1的3×3卷积,第二个是1×1的卷积,然后进行普通的3×3卷积,第三个是一个膨胀率为3的3×3卷积,以及其他分支的卷积。目的是大幅度减少参数量来提高检测速率,将这些分支的结果堆叠并进行1×1 的卷积再加上残差结构,得到一个RFB模块的输出。RFB结构如图3所示。
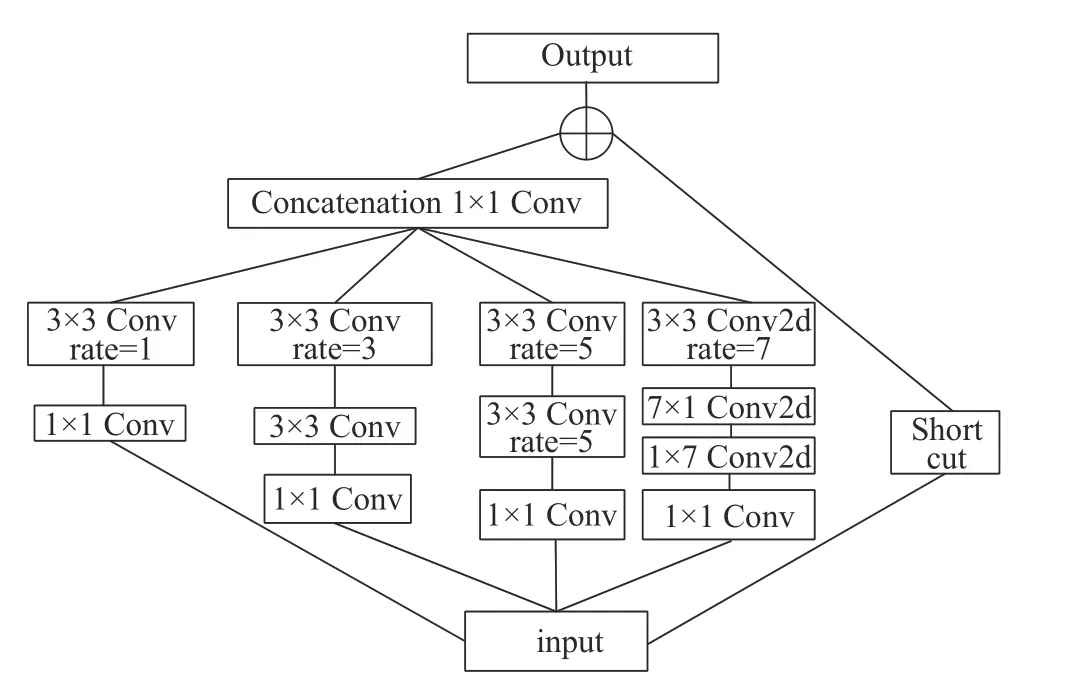
图3 RFB结构Fig.3 RFB structure
1.1.2 特征连接
特征连接是为了给定特征映射用上下文信息,因此进行融合的是来自更高层次的特征映射目标特征层。在改进的网络结构中,给定的目标特征来自Conv4_3,上下文特征来自浅层特征层FC7 和Conv8_2,如图2 所示。虽然特征融合可以推广到任何目标特征,但这些特征图的空间大小不同,因此提出如图4 所示的融合方法。在连接特征进行融合之前,对上下文特征进行反卷积,使其具有与目标特征相同的空间大小。将上下文特征通道设置为目标特征的一半,因此上下文信息的数量就不会超过目标特征本身。此外,在连接特征之前,归一化步骤是非常重要的,因为不同层的每个特征值有不同的尺度,所以在每一层之后执行批处理归一化和ReLU。最后,通过叠加特征来连接目标特征和上下文特征。新生成的特征层包含了目标特征Conv4_3 层以及FC7 和Conv8_2 两个不同层的全局上下文信息和局部上下文信息,通过特征连接的方式将浅层特征融合,扩大连接特征图的分辨率以及利用上下文的特征,能够交互多尺度的特征信息,增强小目标信息的连续性的同时,保留了Conv4_3、FC7、Conv8_2不同层的特征信息。
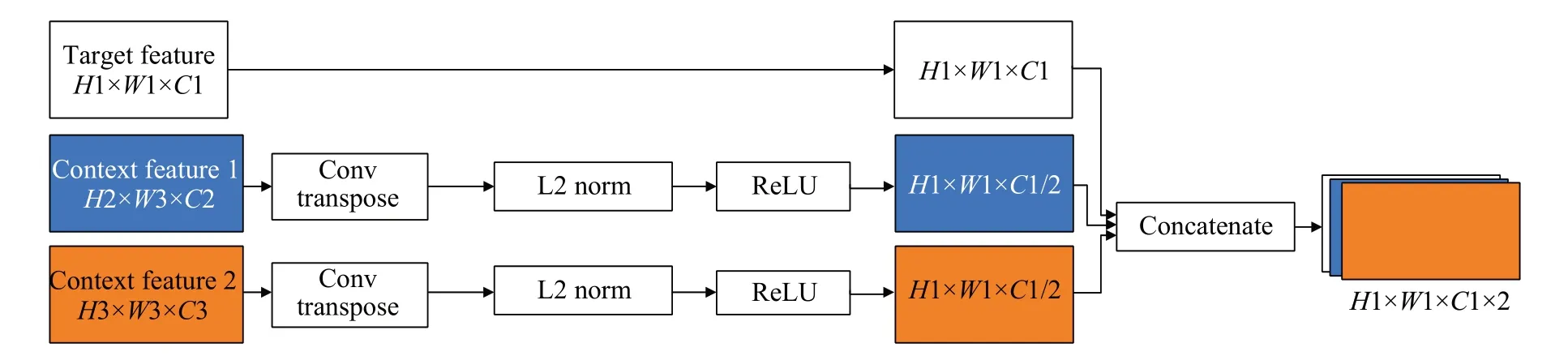
图4 特征连接Fig.4 Feature connection
1.1.3 深层特征融合
在计算机视觉应用中,输入数据集中的图像在经过基础网络处理后,输出的图像尺寸会变小。这是由于在VGG 基础网络上会将一张图像划分为多个候选框,导致目标检测时可能会存在漏检的情况。由于浅层特征表达能力不强,需要用到上采样方法,常用的上采样方法是反卷积,以此来提升分辨率。深层特征图的感受野较小,语义信息表征能力弱[14],为了提高检测的准确性,将图2中的深层特征层Conv9_2和Conv10_2,Conv10_2和Conv11_2 通过DM(deconvolutional module)模块进行深度特征融合,使用目标的上下文信息也可以指导定位区域的选择,从而提高准确率,如图5 所示。将其中一个Conv10_2层先进行2×2×256的反卷积操作,3×3×256的卷积层再进行归一化操作BN(batch normalization),添加BN 是为了起到缓冲的作用,保证网络的稳定性[15]。Conv9_2经过3×3×256的卷积和BN,再经过ReLU(rectified linear unit)激活函数、卷积操作、BN,将不同层的特征图通过元素对应点积(element-wise-product),通过ReLU 完成得到特征细节信息更多的新特征图,使用DM 模块进行深层特征融合,在不影响小目标检测精度的前提下不改变特征层的大小,再使用RFB 模块增大感受野。利用Inception的多分支结构,即使用膨胀率为[1,3,5,7]这种组合使得采样点交错,解决信息丢失的问题,不会对部分点重复采样,同时有利于学习更多的局部信息,可以更好地获得实例细节处的边界特征[16]。感受野越大,改进网络输出的特征强度越好,对于大目标的检测性能也就越好。
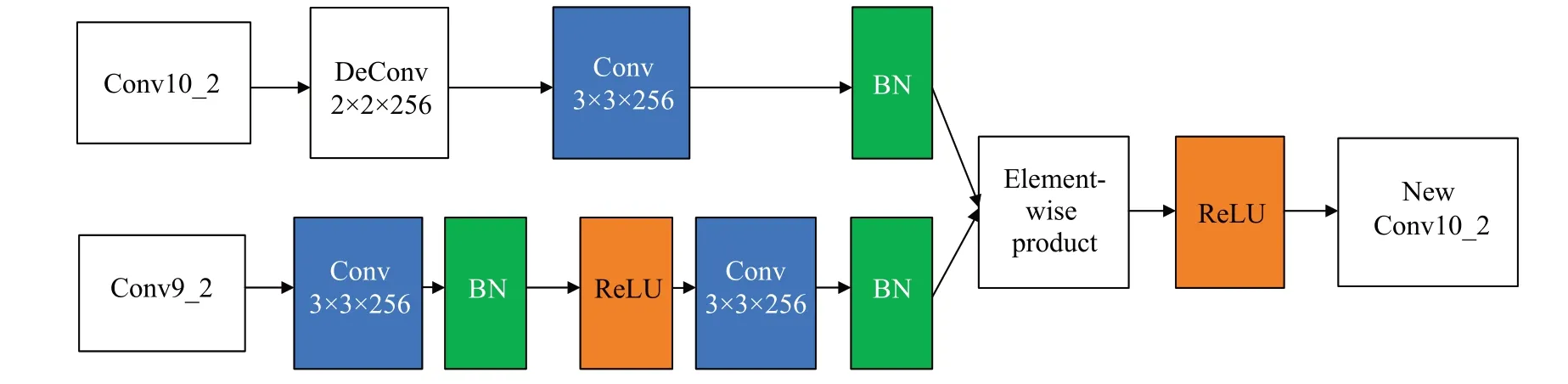
图5 DM模块Fig.5 DM module
1.1.4 RFB特征融合
特征对应元素相加使用RFB模块,选择在Conv4_3和FC7 层添加RFB 模块,是因为浅层特征图感受野较小,有助于提高目标检测,插入深层特征图时,可以减少计算参数数量。在改进网络结构的基础上进行详述,如图6 所示,在Conv4_3 层获取的特征层大小是38×38×512。SSD 目标检测中会直接进行预测,而改进后的算法将一系列特征提取到FC7 层,然后对FC7 层进行卷积,得到19×19×256的特征,再通过38×38的上采样,卷积通道数为256,与Conv4_3 层通过38×38 卷积通道数为256进行一个堆叠,使用RFB模块来提高有效特征层的提取能力。通过一个rate=6的先验框,相比SSD的先验框,在增加了不同层之间特征映射关系的同时,也保留了相对完整的语义信息,提高了网络对目标的检验准确率。
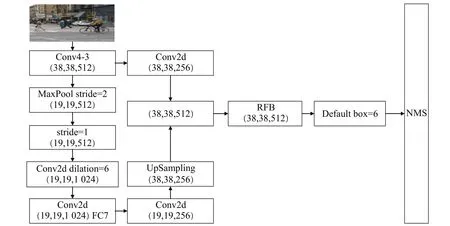
图6 RFB特征融合Fig.6 RFB feature fusion
1.2 模型训练设计
1.2.1 先验框设置
改进后网络模型训练的主要目的在于增加正样本和采用数据增强策略,其中先验框与SSD 网络相近似。300×300的输入会产生数千个先验框,按照传统的匹配方法,只有少数先验框可以与实际标签框重叠,这意味着负样本的数量会远大于正样本的数量。为了平衡样本,在所有先验框与真实标签框中设置一个交并比(intersection over union,IoU)。在目标检测过程中,通过前一个盒子和真实目标之间的匹配度交集来确定。先验框如果与真实标签框的重合率大于0.5,则记为正样本,否则为负样本。
对于每个网格点都存在若干个先验框,根据每个有效特征层的网格点来获取不同的先验框。由于目标大小不同以及形状各异,需要对每个特征图根据目标大小的不同,设置不同尺度的先验框。这里根据SSD算法设定的先验框规则来进行锚框选择。选择先验框尺寸的原则如下:
1.2.2 损失函数
损失函数由每个先验框的标签和坐标偏差来控制,通过反向传播算法来调整网络中的参数。具体而言,即通过将网络操作结果中的预测框坐标、类别置信度和先验框与目标结果进行比较来计算偏差。改进后的模型目标损失函数被定义为Confidence Loss(Lconf) 和Localization Loss(Lloc)的加权和,即:
其中,α是权重参数,通常默认为1,c为置信度,g为真框,l为预测框,Lconf为置信度损失,Lloc为位置损失,N为匹配的候选框数量。置信度损失是通过计算多类对象置信度的Softmax 损失获得的,该损失表示公式如下所示:
边界盒回归实际上就是调整预测盒的过程,得到的预测帧通常与待检测图像中的目标区域存在一定的误差。其中位置误差计算公式[17]如下:
其中,g=(gcx,gcy,gw,gh)表示真实位置,d=(dcx,dcy,dw,dh)表示候选框位置。
DSSD 网络模型有多尺度特征提取网络,但DSSD对不同尺度特征采用非歧视的方法,选择少数特征层进行预测,不考虑浅层和深层卷积层包含不同的局部细节,而且因网络层数更深导致训练难度增加。因此,DSSD 网络模型目标特征的检测能力不足。改进后的网络将验证集和训练集的比例设置为1∶9,随着训练网络的不断迭代,改进后的损失函数值迅速低于原始的损失函数值,并且最终逐渐降低。设置权重衰减系数为0.000 5,学习率为0.001。最后,通过非极大值抑制算法只保留重叠较少的预测框。当最大迭代次数达到20 000时,两个损失函数之间的距离达到最小值。从训练开始到损失收敛稳定的时间基本相同,改进后的网络模型收敛速度更快,如图7所示。
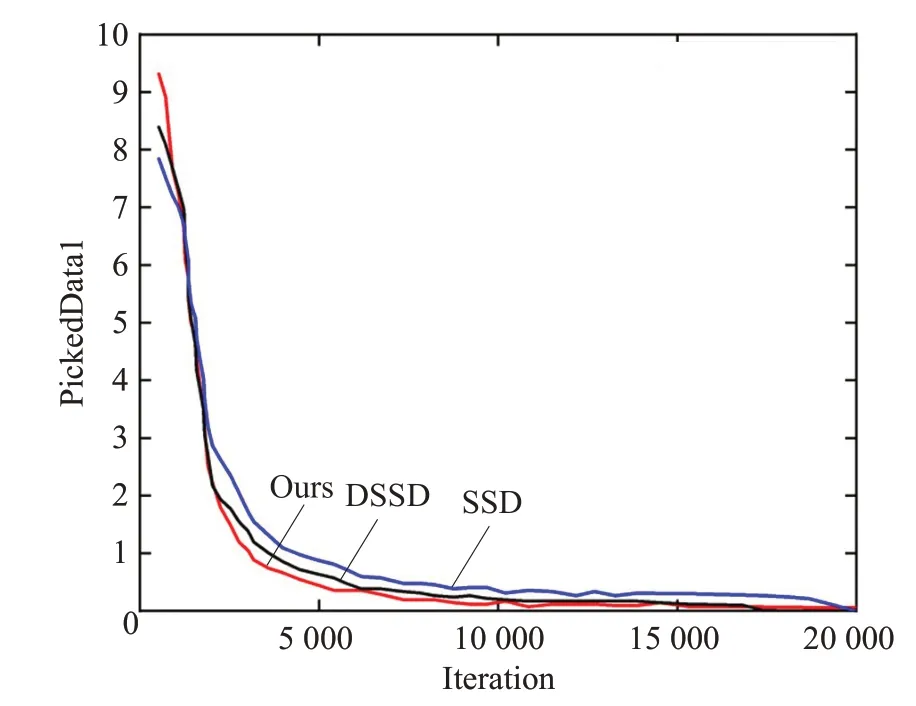
图7 改进前后损失曲线Fig.7 Loss curves before and after improvement
1.2.3 评估指标
为了比较算法模型的优劣,将测试的图像放入经过训练的网络中标记并测试结果。选择精度、召回率作为检测准确率的评价指标。评价指标的定义如下:
式中,TP 是正类预测为正类的数量,FP 是负类预测为正类的数量,FN 是实际正类预测为负类的数量。Precision 为查准率,是指预测正标签样本中的准确率。Recall为召回率,体现了预测为负样本中标签为正的程度。mAP是平均精度,其值越高,表示检测结果越好。
2 实验结果与分析
2.1 数据集与实验环境
PASCAL VOC 数据集[18]是开源的用于图像检测的数据集,包含2007和2012两个版本。本文选用VOC2007数据集中的图片在训练阶段设置验证集和训练集的比例为1∶9。选用CSV数据集和COCO2017数据集进行验证。实验中使用显卡为Nvidia RTX3090,软件为Pycharm,版本号Python=3.6,实验框架为Tensorflow1.13.1,在GPU环境下根据显卡配置对应的CUDA和CUDNN。
2.2 检测性能比较
在NMS 算法中,需要手动设置IoU 阈值,IoU 阈值的设置与网络模型的检测性能密切相关,在本文中设置此阈值为0.5。图8 表示SSD 和DSSD 以及本文算法的精度召回曲线图。P-R 曲线分别使用召回率和查准率作为水平和垂直坐标。当召回率为90%时,可以看出本文算法检测精度高于SSD和DSSD。
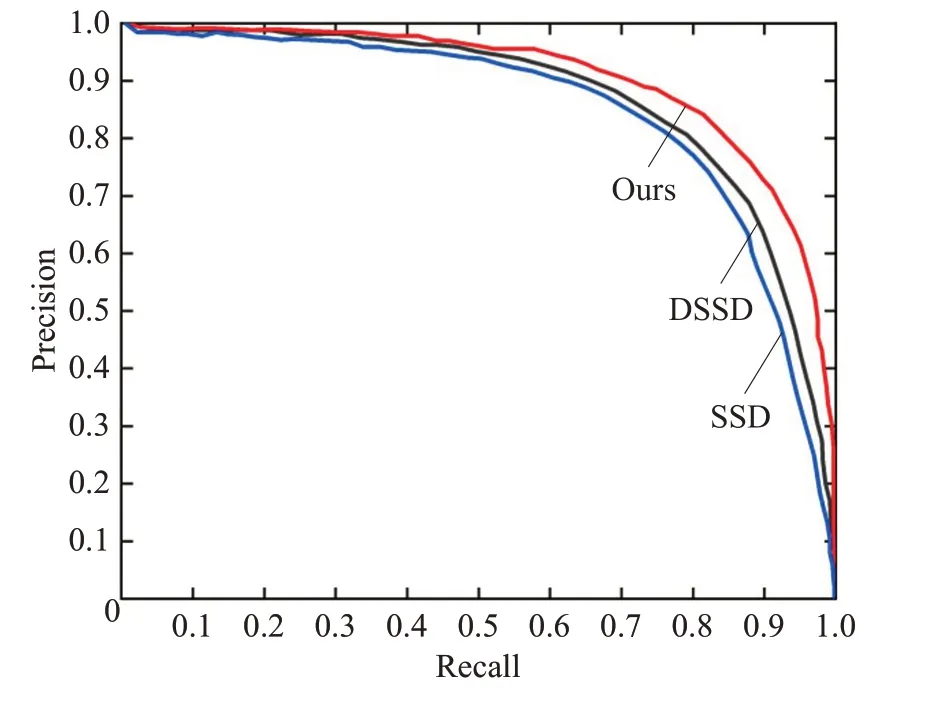
图8 改进前后精度召回曲线Fig.8 Precision-recall curves before and after improvement
为了验证改进后的算法精度与速度,将SSD、DSSD与改进后SSD算法进行比较,对输入图片进行处理得到300×300 像素大小的数据集。采用VOC2007、CSV 和COCO2017 数据集进行验证。同为单阶段目标检测算法的YOLOv4模型、YOLOv7模型、SSD模型、DSSD模型以及改进后算法在不同场景下对应的检测结果如图9、图10、图11、图12所示。

图9 VOC2007物体检测对比Fig.9 Comparison of VOC2007 object detection

图10 隐藏物体检测对比Fig.10 Comparison of shelter object detection

图11 夜间检测对比Fig.11 Comparison of night detection

图12 COCO2017小目标检测对比Fig.12 Comparison of COCO2017 small target detection
通过对比可以发现,本文模型相较于YOLO系列模型、DSSD模型、SSD模型可以更加精确地检测到复杂环境下的物体。第一列是YOLOv4[19]模型的检测效果,明显可以得到在COCO 数据集中模糊背景条件下检测效果较差。第二列是YOLOv7模型,2022年被YOLOv4的同一团队[20]提出,无论在VOC2007数据集还是在COCO数据集中相比第一列模型检测精度较高,尤其是在夜间检测精度上,但在COCO小目标数据集上检测效果不如本文算法。第三列为SSD 模型,在VOC2007 中并没有检测到被遮挡的物体以及小目标,仍然存在漏检的问题,以及在COCO数据集中并没有检测到环境背景下的“person”。第四列为DSSD模型,检测小物体并不完整,尤其夜间检测性能并没有较大的提高。而且相比SSD算法模型,DSSD检测速度过度损耗,这是因为DSSD算法进行卷积特征和反卷积特征融合之前存在卷积特征计算的时间等待。而第五列为改进算法,在VOC2007数据集中看出完全可以检测到小物体,也没有出现误检状况,在COCO2017 数据集中不仅可以检测到所有的“bird”,对于背景影响下的“person”也可以完全检测到,并没有出现漏检的状况。本文算法检测速度达到了49.1 FPS,远高于DSSD 算法。通过特征融合来实现目标检测,与传统SSD、DSSD 算法相比,本文算法的目标检测精度与速度显著增强。
2.3 消融实验
为了检测三个模块提升检测精度的效果,分别将三个模块依次添加到网络中,测试数据集为PASCAL VOC2007,输入图像统一为300×300 的分辨率,训练方式如第1.3 节所述。将Conv4_3、FC7、Conv8_2 三个浅特征层进行特征连接,但并未加入深层特征层中的反卷积模块以及RFB 模块,根据图13(a)中的热力图[21]可以发现,已经可以检测到小目标,这是由于通过浅层特征连接将小目标特征信息进行增强,但是热力图中的亮度不够明显。热力图中的亮度越明显,则表示它的特征越强。特征连接的主要目的就是在浅层特征层提高对小目标的检测能力。在SSD 算法中小目标检测能力不足是因为对原图进行了缩放,导致可用的anchor 比较少。改进算法将前三层进行特征连接,使得浅层的感受野比较小,保留了图像的细节信息。从图13(b)中的热力图可以看出,在特征连接的基础上加入深层特征的反卷积融合成新的Conv9_2、新的Conv10_2,这样在增强感受野的同时而不会影响原来特征图尺寸的大小。从图13(b)中可以看出,在不影响小目标检测性能的同时可以增加一些中大目标的概率得分,因为图13(b)中明显大目标中心位置热力图分布定位面积较大。在特征连接的基础上,将反卷积模块加入深层特征中是为了提高它的感受野,而高层的特征图负责大目标检测,在加入特征连接以及反卷积的前提下加入RFB模块后,一方面可以减少计算量来提高检测效率,另一方面将Conv4_3和FC7层进行融合增强小目标检测,在浅层特征层中主要增强边缘信息。三层浅层信息的连接使小目标的语义信息位置信息增强,解决了整个场景下的局部信息不足问题,有助于提高各个目标分类的准确率,进而提高整体的检测精度。可以看出图13(c)中小目标上颜色变得明亮,而并没有影响大目标上的亮度。表1 为三种不同消融策略检测的精度对比,图13 为采用三种不同融合方法后分别经过NMS算法进行分类显示的热力图对比。

表1 消融实验对比Table 1 Comparison of ablation experiments

图13 热力图可视化Fig.13 Visualization of thermodynamic diagram
2.4 不同融合的消融分析
根据图2 所示选择融合的特征层(C),将不同特征图调整到相同的尺度以及对不同层的特征图进行融合。
其中,xi∈C表示需要融合的特征图,fi为融合前特征图变换函数,φf为不同特征图的融合函数。本节对不同的融合模块进行了消融实验分析。由表2可知,即使最差的融合方式也可以使SSD算法检测精度提升8.3个百分点。最好的融合方式是使用反卷积来调整特征图的尺度,以及通过RFB模块来减少不同特征层之间参数量的计算,然后通过特征连接融合不同特征图,该方法使得检测精度提升12.1个百分点。由图13和图14对比可知,使用不同的融合方法得到的检测精度也有所不同,在融合前同样使用RFB模块,再使用特征连接以及元素求和两种方法进行不同方式的融合,可以看出元素点积的方式比元素求和的方式在mAP 上略高0.8 个百分点。这是因为元素点积的方式可以突出特定区域的特征,对于小型目标检测更加有力,本文选用元素点积的方式来进行特征融合。
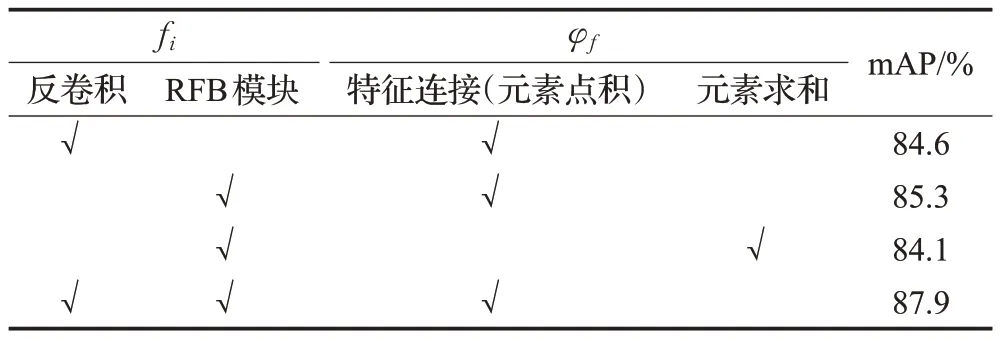
表2 不同融合方法的检测性能Table 2 Detection performance of different fusion methods

图14 不同融合的热力图可视化分析Fig.14 Visual analysis of different fused thermal diagrams
VOC2007数据集上每一类别的AP如表3所示。本文算法与SSD、DSSD 以及YOLO 系列经典目标检测算法进行比较,从表3 中可以看出,本文算法在检测精确度方面大幅度提升,其mAP 比DSSD 提高了6.6 个百分点,比SSD 提升了12.1 个百分点,比YOLOv7 算法提升了5.4个百分点。
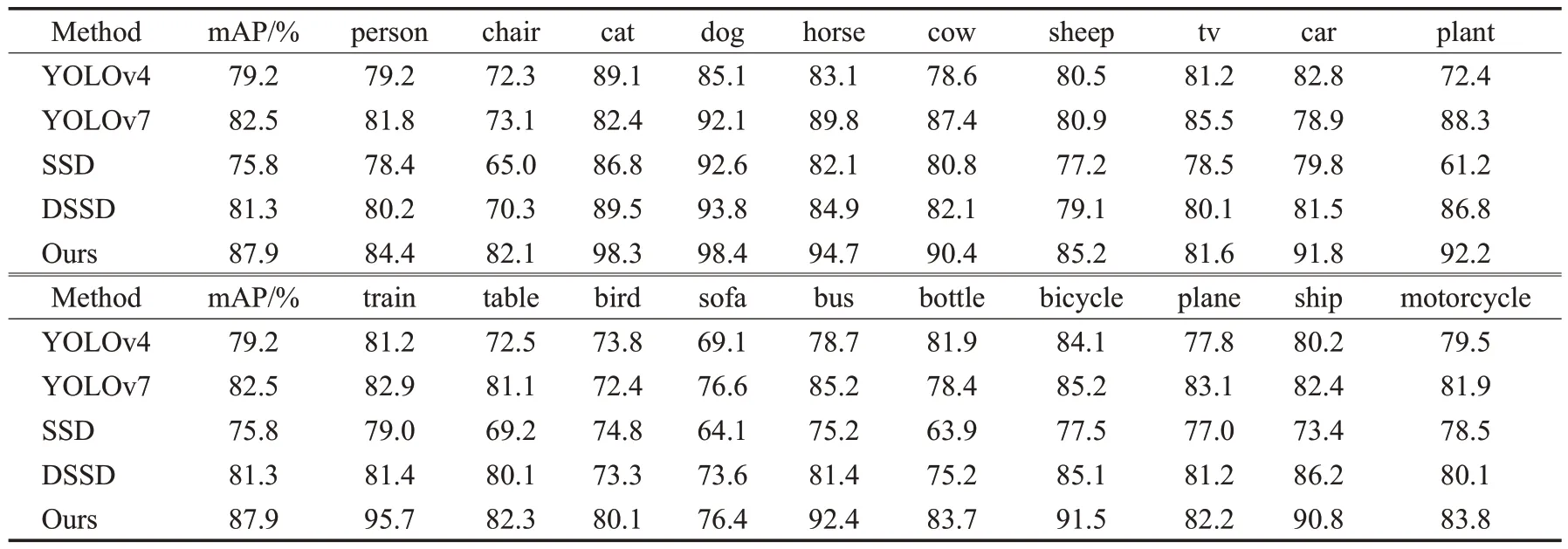
表3 VOC2007数据集中不同种类AP值Table 3 Different types of AP values in VOC2007 dataset
改进网络的评价指标除mAP 之外,还有检测图像中帧率的大小,如表4 所示。SSD300 检测图像速度为53.5 FPS,DSSD检测图像速度为9.2 FPS,本文检测图像速度为49.1 FPS。由表3 可知,改进后的算法在精度上得到较大的提升。同时从表4中可以看出,在精度大幅度提升的基础上,本文模型检测速度与SSD相比仅损耗4.4 FPS。综上,说明本文提出的改进算法不仅保证了检测速度,同时满足了高精度和高实时性。
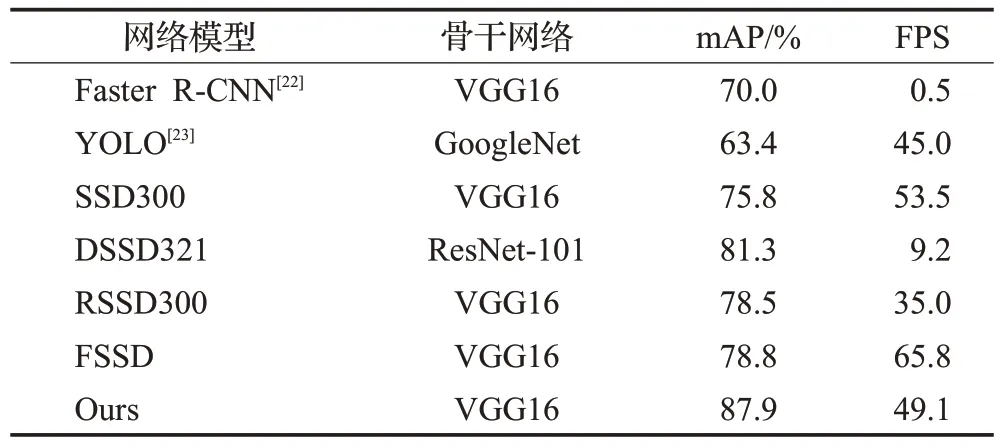
表4 模型之间FPS比较Table 4 FPS comparison between models
3 结束语
本文针对SSD 和DSSD 在复杂环境下目标检测效果差的问题,根据DSSD 算法的反卷积思想,通过加入RFB 模块提高感受野,加强语义信息的提取,使用特征连接将浅层特征图进行特征融合,在反卷积模块下将深层特征图进行融合,使用RFB模块减少参数计算量并进行再训练。该算法对复杂环境具有良好的鲁棒性和适应性,对于外界因素的影响具有较强的抗干扰能力。从实验结果来看,本文算法检测精度优于SSD 模型,在mAP 上比DSSD 提高了6.6 个百分点,比SSD 提升了12.1个百分点。在确保高精度的同时,也能够平衡检测速度,相比SSD检测帧率仅损耗4.4 FPS。
未来的工作中,考虑基于改进后的网络结构,结合NMS算法通过IoU进行评估。IoU存在一定缺陷,尝试将目标尺度以及距离引入IoU中,进一步提高目标检测的效果。
