改进高分辨率网络的多目标动物姿态估计研究
2023-11-27徐贵冬
徐贵冬,徐 杨,2,邓 辉,莫 寒
1.贵州大学 大数据与信息工程学院,贵阳550025
2.贵阳铝镁设计研究院有限公司,贵阳550009
动物姿态估计在动物学、生物学等领域有着许多潜在应用,因而动物姿态估计相关工作受到了越来越多的关注[1]。动物姿态估计的研究在实际应用中,如动物行为理解[2]、野生动物保护[3]和动物园养殖管理[4]等领域都具有重要意义。而姿态估计作为计算机视觉的一项基本任务,在许多现场景中得到了应用,如动作识别[5]、行为理解[6]、人机交互[7]等。人体姿态估计也因拥有大规模标注数据和基准,如MPII 数据集[8]和COCO 数据集[9]等,成为热门研究内容,并出现了大量先进的人体姿态估计算法[10]。但是在动物姿态估计中,由于缺乏大规模的动物姿态标注数据集,导致现有方法在动物姿态估计上不能拥有很好的性能[11]。因此,针对动物姿态估计模型的进一步研究具有重要价值。
在目前的动物姿态估计相关研究中,主要通过联合使用合成动物数据集和真实动物数据集对模型进行训练[1,12],可以让动物姿态检测精度得到一定提升,但是在复杂遮挡的野外环境下,其检测性能会下降。估计多种动物的姿态是一个具有挑战性的计算机视觉问题:频繁的互动会导致遮挡,并使检测到的关键点与正确个体的关联复杂化;存在高度相似的动物,这些互动比典型的多人类场景更接近[13]。多目标动物姿态估计中存在的遮挡情况主要有自遮挡、重叠遮挡、环境遮挡以及密集接触遮挡等。因此,本文针对多目标动物姿态估计遮挡关键点检测展开研究。
最新公开的针对哺乳动物姿态估计的大规模基准数据集AP10K[14],包含大约1万张标记有姿态信息的哺乳动物图片,包括了23 个动物科和54 个物种。该数据集标注的关键点包括眼睛、鼻子、肩部、肘部、膝关节、爪子等,其中还包括多动物姿态和多动物互动的遮挡关键点标注等。通过使用该数据集可以更好地提升模型的泛化性能,同时可以验证模型多目标动物姿态估计性能以及在复杂环境下动物遮挡关键点的检测效果。
当前针对动物姿态估计的模型中,主要以检测某单一动物姿态为主,但是当存在遮挡和复杂环境时,检测效果下降[4,15]。Cao等人[11]提出了一种跨域自适应方法,将动物姿态知识和人类姿态先验知识转化为未标记的动物类别,通过共享空间的方式进行学习。Mu 等人[12]通过CAD 合成动物图像应对缺乏标记数据的限制,在未标记真实图像的合成数据上进行模型训练。Li等人[1]设计了一个多尺度域自适应模块,从合成数据中进行学习。Zhou 等人[16]基于图像模型的结构化上下文增强网络对鼠类进行姿态估计,用于鼠类行为分析。Lauer等人[13]通过构建姿态估计工具箱DeepLabCut,对多动物场景的动物进行跟踪。上述的动物姿态估计研究主要是通过联合使用合成数据集或针对某单一物种的无监督动物姿态估计,而在复杂多目标动物姿态估计背景下,其检测效果并不理想。
在人体姿态估计的相关研究中,Newell等人[17]提出的堆叠沙漏网络(stacked hourglass network,SHN),采用的是分辨率对称的网络结构,但是分辨率在恢复过程中会产生误差。Chen 等人[18]提出的级联金字塔网络(cascaded pyramid network,CPN),在人体遮挡关键点检测性能方面得到提升,但因缺乏关节结构中的细节信息,导致了对多尺度的姿态估计泛化性能下降。Xiao等人[19]提出的Simple Baseline网络,只在主干网络末端增加一些反卷积来进行热图预测,就能提高网络检测精度。Sun等人[20]提出的高分辨率网络(high resolution network,HRNet),通过使用并联方式将不同子网分辨率进行连接,然后进行反复多尺度特征融合,使得网络的整个过程都维持一个高分辨率,因而对细节特征敏感。之后Cheng等人[21]在HRNet网络基础上提出了HigherHRNet,通过加入多尺度监督和在网络末端增加反卷积模块提升特征图分辨率,从而在多人姿态中获得更好的检测效果。虽然人体姿态估计模型在单人或者多人的姿态估计上的表现不错,但是在迁移到动物姿态估计上时,其检测效果下降,这是因为多种动物互动过程中其姿态存在复杂行为和遮挡,导致模型检测效果下降。
Liu等人[22]提出了极化自注意(polarized self-attention,PSA)模块,通过联合使用通道注意力机制和空间注意力机制,在姿态估计任务上达到了当前最优的性能。Pan 等人[23]提出了一个混合卷积ACmix,将自注意和卷积通过共享1×1卷积的方式聚合,在下游任务中取得了不错的成绩。
基于上述研究,当前在二维动物姿态估计任务中,不仅缺少相应的动物姿态估计模型,而且在多目标动物姿态估计中存在各类遮挡情况,会导致动物姿态关键点的检测效果不佳。因此针对以上问题,本文以高分辨率网络HRNet为基础网络,通过引入PSA注意力和ACmix模块,提出一种能够检测多目标动物姿态中各类遮挡关键点的姿态估计网络PAENet。首先,本文提出了一种融合自注意机制的瓶颈模块ACmixneck,用以替换高分辨率网络中的瓶颈模块,新的瓶颈模块ACmixneck能够在大尺度特征提取中有效提取动物姿态中关键点特征。然后,结合PSA 注意力模块重新设计基础模块PSAsblock,能够在网络的不同分辨率分支中挖掘到更加细腻的特征,从而捕捉被遮挡的关键点。最后,重新设计网络输出的特征融合方式并加入反卷积模块,进一步提高网络的热图预测准确率。
1 相关工作
1.1 高分辨率网络
高分辨率网络(HRNet)改变以往串联网络的模式,采用并行多分辨率分支的方式来获取强语义信息和精确的位置信息。最重要的是,HRNet网络能够从头到尾保持高分辨率,不同分支信息的交互可以弥补通道数减少带来的信息损耗。该网络作为各种任务中的基础网络,在语义分割、目标检测和姿态估计中均有很好的表现。因此,本文采用HRNet作为多目标动物姿态估计的基础框架。
HRNet 网络共有4 个阶段。第一个阶段主要维持一个高分辨率,从第二个阶段开始,每个阶段分出一个低分辨率子网,新增的低分辨子网分辨率是上一阶段分辨率的一半,通道数是原来的两倍。图1为多分辨率卷积组。然后,各阶段进行重复多尺度特征融合。图2为第三阶段的多尺度分辨率特征融合。因此,使用高分辨率网络在关键点检测精度、计算复杂度和参数效率等方面都具有一定优势。

图1 多分辨率卷积组Fig.1 Multi-resolution convolution group
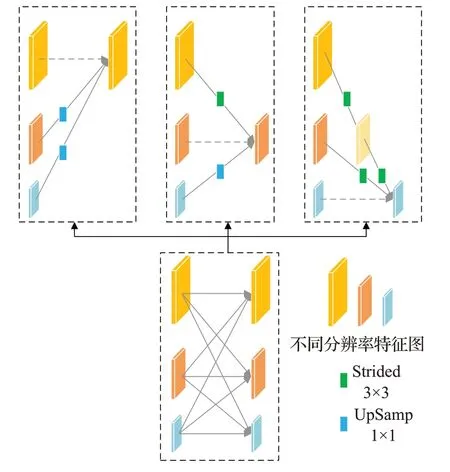
图2 第三阶段的多尺度特征融合Fig.2 Multi-scale feature fusion in the third stage
1.2 ACmix混合卷积
传统卷积核提取局部特征在卷积神经网络中一直是一项优秀的技术,而随着注意力机制的发展,通过将自注意力机制不断融合到卷积神经网络中,能够帮助网络提高性能。ACmix 混合卷积的提出者通过巧妙的范式将自注意力机制和卷积融合,让它同时拥有自注意和卷积优点的同时具有最小的计算开销[23]。图3为ACmix混合卷积结构。

图3 ACmix混合卷积结构Fig.3 ACmix convolution structure
1.3 注意力机制
类似人类的视觉关注点,将注意力关注在图像中最重要的区域而忽略不相关部分的方法称为注意力机制。由于注意力机制近年来的快速发展,基于注意力的模型获得了越来越多的关注[24]。Hu 等人[25]率先进行了通道关注,它的核心是一个挤压和激励(squeeze-andexcitation,SE)模块,用于收集全局信息,捕获信道关系和提高表示能力。但是,它在挤压模块中全局平均池化过于简单,无法捕获复杂的全局信息。通过结合通道注意力和空间注意力,可以自适应地选择重要的对象和区域[26]。为了增强信息通道和重要区域,Woo等人[27]提出了CBAM(convolutional block attention module)模块,将通道注意和空间注意串联在一起。为了提高计算效率,它解耦了通道注意图和空间注意图以提高计算效率,并通过引入全局池化来利用空间全局信息。然而,在通道和空间注意机制方面仍有改进的空间。极化自注意力PSA的提出,在通道分辨率和空间分辨率与低参数量之间达到平衡的同时,通过在注意力机制中加入非线性,使得拟合的输出更加细腻[22]。
2 本文模型
2.1 PAENet模型
本文以HRNet 网络为基础框架进行改进,提出了PAENet网络模型。网络共有4个阶段:首先通过两个标准3×3 卷积将图像分辨率降为原来的1/4,将该分辨率作为第一阶段的分辨率并保持到网络最后输出。然后从第二个阶段开始,每个阶段渐进式分出一个低分辨率子网,新增的低分辨子网的分辨率是上一阶段分辨率的一半,通道数相应变为上一阶段的2倍。PAENet网络结构如图4 所示。网络整体分辨率在4 个阶段中逐步下降,可以避免快速降低分辨率过程中导致动物姿态的细节信息大量丢失的情况。
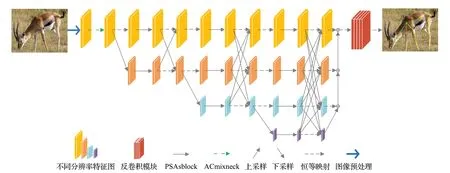
图4 PAENet网络结构Fig.4 PAENet network structure
网络第一阶段中通道数首先从3 变为64,将4 块ACmixneck用于初步特征提取并将通道由64变为256。第二、三、四阶段均使用4 块PSAsblock 充分提取特征,相应的通道数变为32、64、128 和256,图像分辨率相应变成最初的1/4、1/8、1/16和1/32。在网络的每一个分支特征提取后都要跨分支进行多尺度特征融合,使得每个分支都能与其他网络分支的特征信息进行交换。在网络的第四阶段特征提取完成后,将该阶段的3个低分辨率分支的特征图依次进行双线性上采样,然后与最高分辨率的特征图进行融合。最后将融合后的特征输入到反卷积模块,进而实现多目标动物姿态关键点的估计。
2.2 ACmixneck模块
本文提出了如图5 所示的ACmixneck 模块,作为PAENet 中的瓶颈模块,它主要由两个1×1 普通卷积和一个3×3ACmix 混合卷积构成。ACmixneck 模块在几乎不增加计算开销的同时,还能带来一定的性能提升。

图5 ACmixneck模块Fig.5 ACmixneck module
ACmix能够同时享有自注意力和卷积的优点,同时与纯卷积或自注意相比,具有最小的计算开销。如图6(a)所示,一个传统卷积核大小为k×k的卷积,可以分解为k2个单独的1×1卷积[23],因此ACmix模块的结构主要分两个阶段:
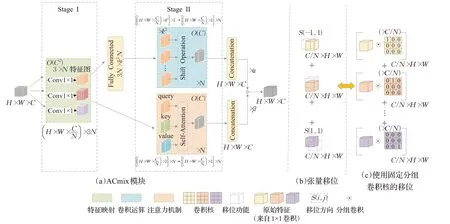
图6 ACmix结构Fig.6 ACmix structure
第一阶段:用3个1×1卷积对输入特征图进行投影,获得一组丰富的中间特征;
第二阶段:按照不同的范式对中间特征进行重用和聚合,即分别以自注意力机制和卷积的方式进行聚合,然后将两个路径的特征进行聚合作为最终的输出。
在第一阶段中,两个模块共享了相同的1×1卷积操作,因此只执行了一次特征图的投影,且主要的计算开销也在第一阶段中。而在第二阶段的聚合操作中都是轻量级的,并没有获得额外的学习参数。这样ACmix模块能够在结合两个模块优点的同时,有效避免了采用两次计算带来的开销。
图6(a)的自注意力机制部分,中间特征进行了N组聚合,每组聚合包括3 个特征片段和1 个聚合后的特征。对应的3 个特征映射作为查询(query)、键(key)和值(value),遵循传统的多头自注意模块的映射方式。设标准N头自注意模块的输入和输出对应像素张量(i,j)。注意力机制部分的输出表达如式(1):
对于式(4),可以通过Shift 操作来进行简化,Shift操作(f,Δx,Δy)定义为式(5):
其中,Δx、Δy分别表示水平位移和垂直位移,其移位方向对应于图6(b)中s(i,j)的张量移位方向。因此式(4)可以改写为式(6):
而式(6)中的移位操作通过使用如图6(c)中的分组卷积核快速实现,使用它取代了图6(b)中低效的张量移位。以Shift(f,-1,-1)为例,移位特性计算如式(7):
式中,c表示输入特征的每个通道。另一方面,如果将内核大小k=3 的卷积核表示为矩阵(8):
则相应的输出可表示为式(9):
因此,图6(c)中特定偏移方向使用的核权重可以等价于图6(b)中的简单张量位移,如式(7)。特别在移位计算过程中,通过使用多组卷积核的方式来匹配卷积和自注意力路径的输出通道,才能在聚合后与自注意力通道的输出进行融合。
最后,对于卷积通道,在对k2特征图进行式(6)的平移后,聚合为如式(10):
因此,图6(a)ACmix混合卷积的最后输出由两条路径的输出相加,并由两个可学习标量α和β进行控制,输出Fout如式(11):
2.3 PSAsblock模块
本文参考PSA 注意力机制[22]的原理,使用通道自注意和空间自注意串联得到的PSAs 模块,重新构建PAENet 中的基础模块PSAsblock,模块的结构如图7 所示。极化注意力机制相比较于其他注意力机制,优势主要在于保持了内部的高通道分辨率和高空间分辨率,减少了中间特征的损失。同时,PSA的两个通道中均加入非线性,使得拟合输出更具有细腻度,因此PSA 的通道注意力尽可能突出像素所属分类,更加关注通道维度的学习;其空间注意力通道尽可能检测出属于同一语义的像素位置,增强特征空间信息的感知。因此,通过加入PSAs模块,在增加少量的计算开销和计算量的前提下,能够有效提升网络对遮挡关键点的捕捉能力,提取更加细腻的特征。

图7 PSAsblock模块Fig.7 PSAsblock module
PSAs模块因为在通道维度和空间维度上保持高分辨率,所以保证了特征变化过程中的质量,而且在压缩维度的分支采用Softmax 函数增强注意力,最后采用Sigmoid 函数进行动态映射[22]。通道维度PSAs 模块结构如图8所示。输入张量X先经过通道自注意(channelonly self-attention),得到通道注意关注后,串联输出到空间自注意(spatial-only self-attention),最后输出为Z。
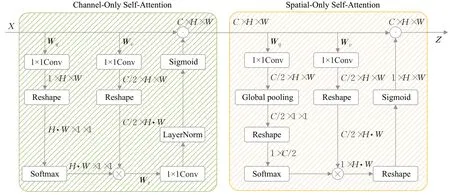
图8 PSAs模块结构Fig.8 PSAs module structure
图8 中,设通道自注意Ach(X)∈ℜC×1×1,其中C是通道数,通道自注意的权重计算公式如式(12):
其中,Wq、Wv和Wz分别表示1×1卷积,σ1和σ2是两个张量重塑算子,θ是通道卷积的中间参数,FSM(·) 是Softmax 运算,×表示矩阵点积运算。Wq、Wv和Wz的内部通道数为C/2,通道自注意先将输入X投影为q和v,其中对特征q进行压缩,然后使用Softmax函数进行特征信息增强。之后对特征q和特征v进行矩阵点积运算,得到中间特征z,再通过1×1 卷积将通道恢复到C通道,并使用Sigmoid函数保持输出在0-1之间,得到通道分支的输出Zch=Ach(X)⊙chX∈ℜC×H×W,这里⊙ch表示信道级乘法运算符,H和W表示高和宽。然后将通道分支输出到空间通道。
设空间自注意Asp(X)∈ℜ1×H×W,其中H和W分别是特征维度的高和宽,空间自注意通道的权重计算公式如式(13):
其中,Wq和Wv分别表示1×1 卷积,σ1、σ2和σ3是两个张量重塑算子,FSM(·)是Softmax运算,FGP(·)是全局池化操作,×表示矩阵点积运算。空间通道得到通道自注意的输出后,先通过两个1×1 卷积将特征投影为q和v。对于特征q,先进行空间维度压缩,然后进行全局池化,通过Softmax 函数对信息增强后与特征v进行点积运算,并恢复通道数为C,最后使用Sigmoid 函数保持输出在0-1 之间,得到空间注意分支的输出Zsp=Asp(X)⊙spX∈ℜC×H×W,这里⊙sp是一个空间乘法运算符。因此极化注意力PSAs的最终输出表示为式(14):
2.4 特征融合方式
本文在特征提取的各网络分支中都进行了多尺度特征融合,这样每个网络分支都能跨分支地获得其他分支的信息。各阶段的特征融合方式分三种情况,相同分辨率的分支融合时不做处理,高分辨率分支到低分辨率分支特征图进行下采样以降低分辨率,对于低分辨到高分辨率的特征使用最近邻上采样方法提高分辨率,对于跨分支超过2的情况,则进行多次上采样或下采样将分辨率变化到对应维度。如图2第三阶段的融合方式所示。
在网络的输出层,受级联金字塔网络[18]特征融合方式的启发,对网络最后阶段所有分支的特征图,依次使用双线性上采样提高分辨率与上一分支的特征图进行融合,直到与最高分辨率的特征图融合得到最高分辨率的输出。如图4最后特征融合部分所示。
最后,将融合后的高分辨率输出通过一个反卷积模块,采用提升特征图分辨率的方式来提取更精细的特征。反卷积输出结构如图9所示。

图9 反卷积输出结构Fig.9 Deconvolution output structure
图9 中,输入特征先经过1×1 的卷积将通道进行转换,得到的结果再与输入特征在维度上进行特征拼接,然后使用一个卷积核大小为4×4的反卷积,将分辨率提升为原来的两倍,再使用4 层PSAsblock 模块进一步提取特征,最后使用卷积进行通道数转换,使网络的输出与输入的分辨率一致,从而进行动物姿态关键点的热图预测。
3 实验结果及分析
3.1 数据集介绍
本文选择AP10K数据集进行训练验证。AP10K数据集包括了23 科54 种动物,动物物种多样性是当前动物姿态数据集中涵盖最大的,同时还包括多动物姿态,多动物互动的遮挡关键点标注等。标注顺序如表1所示。

表1 AP10K数据集关键点标注Table 1 Key annotation on AP10K dataset
AP10K 数据集包括10 015 张动物姿态关键点标注图像,与定义人类姿态关键点相似,也定义了17个动物姿态的关键点。17个动物姿态关键点包括两只眼睛、一个鼻子、一个脖子、一条尾巴、两个肩膀、两个肘部、两个膝盖、两个臀部和四个爪子。
本文采用7∶1∶2的比例划分训练集、验证集和测试集,其中7 023 张图像用于训练,995 张图像用于验证,1 997张图像用于测试。同时,为测试模型的泛化性能,使用Animal-Pose数据集[11]进行了跨动物姿态数据集泛化性能测试。
3.2 评价指标
本文采用OKS(object keypoint similarity)[9]作为评价指标,其标准遵循人类和动物姿态估计中的规范[11,19],如式(15):
其中,di表示动物姿态预测的关键点与实际关键点之间的欧氏距离,s是目标尺寸,ki是归一化因子,δ(vi >0)表示关键点可见性大于0。OKS 取值在[0,1]之间,完美预测则OKS=1,误差过大则OKS=0。
OKS 评价标准中AP50表示OKS 为0.5 时的预测准确率,AP75表示OKS 为0.75 时的准确率,mAP 表示在OKS 为0.50,0.55,…,0.90,0.95 之间的所有预测关键点准确率的平均值,APM表示中尺寸物体检测关键点的准确率,APL表示大尺寸物体检测关键点的准确率。
3.3 实验环境及设置
本文实验使用的服务器系统为Ubuntu20.04LTS,CPU版本是i7-12700KF,显卡为NVIDIA GeForce RTX 3090Ti 且显存大小为24 GB。选择的深度学习框架是PyTorch1.8.0,Python版本是Python3.7。本文使用Adam优化器进行优化训练,训练周期为210,批量大小为30。初始学习率为5E-4,训练周期到190时调整为5E-5。
数据集中图片大小不一,因此采用图片预处理方式进行预处理。输入图片大小统一裁剪为256×256,然后通过随机翻转(-45°,45°)和随机缩放(-0.65,1.35)来做数据增强处理。
3.4 实验验证与分析
为了评估本文方法的先进性和有效性,采用上述实验环境与参数,在AP10K数据集上进行实验,对比本文方法和其他先进姿态估计模型的实验结果。图10是热图训练的结果,通过热图回归的方式进行关键点预测,其中图像还进行了随机旋转、翻转和缩放,作为数据增强。

图10 热图预测结果Fig.10 Heat map prediction results
表2 为多种方法在AP10K 数据集上进行实验的结果,输入图片尺寸在数据预处理阶段均裁剪为256×256。通过对比以ResNet_50[28]和ResNet_101[28]为基础网络的SimpleBaseline[19]网络、堆叠沙漏网络SHN[17]、姿态估计网络HRT[29]中的HRFormer-B 网络,以及用于动物姿态估计的HRNet 网络[14],本文提出的PAENet 方法在mAP上的评估精度得到了较好的提升。可以发现,与用于动物姿态估计的HRNet_32 相比,本文PAENet_32 模型在参数量和计算量上只增加3.2×106和1.8 GFLOPs,但AP50提高了1.9 个百分点,AP75提高了2.8 个百分点,APL提高了2.2个百分点,APM提高了3.6个百分点,且平均精度mAP整体上提高了2.4个百分点。

表2 AP10K测试集上不同方法的实验结果对比Table 2 Comparison of experimental results of different methods on AP10K test set
通过实验结果可以发现,本文方法在改进后对中尺寸物体关键点检测准确率提升最为明显。因此,本文方法在仅增加少量计算复杂度的情况下,对动物姿态估计中的一些困难关键点的检测更具有优势。
表3 为本文方法在Animal-Pose 数据集[11]上进行的跨动物姿态数据集的泛化测试,同时对比了HRNet 网络。在跨动物姿态数据集实验中,本文首先在AP10K数据集上进行了训练,然后选择Animal-Pose 数据集中物种为狗(dog)的1 511张标注数据集上进行微调,最后分别在另外4个物种猫(cat)、羊(sheep)、马(horse)和牛(cow)上进行测试。由表3 可以看出,相比于HRNet 网络,本文方法在Animal-Pose 数据集的其余4 个物种上mAP均获得了更优秀的表现。

表3 PAENet跨动物姿态数据集评价结果Table 3 Evaluation results of PAENet trans-animal posture data
3.5 消融实验
本文消融实验选择在AP10K数据集上进行训练验证,以HRNet_32为基础,分别验证ACmixneck、PSAblock、ACmixneck+PSAblock和网络输出特征融合部分对HRNet的改进,从而验证PAENet 中各模块对动物姿态关键点预测精度的影响程度。实验结果如表4所示。

表4 消融实验结果Table 4 Results of ablation experiment
由表4 可以发现,在仅使用ACmixneck 模块时,在几乎不增加网络计算复杂度情况下,网络的平均精度mAP 提升了0.3 个百分点,而在仅使用PSAsblock 模块的情况下,虽然网络参数量增加了2.4×106,计算量增加了0.6 GFLOPs,但网络性能提升了1.6 个百分点。这主要是因为瓶颈模块中的混合卷积避免了重复的计算开销,只对特征进行初步提取,而PSAsblock 模块的通道注意力和空间注意力虽然增加了部分计算开销,但是对细节特征进行了更加细腻的提取。当同时使用ACmixneck模块和PSAsblock 模块的情况下,网络性能进一步提升了1.9 个百分点。而只使用改进特征融合部分时,因为融合阶段增加了一定计算量,所以相比于HRNet网络,计算量增加了1.4 GFLOPs,参数量仅增加8.0×105,但网络性能提升了0.6个百分点。最后在加入ACmixneck模块和PSAsblock模块后,网络特征融合部分发挥出更好的效果,网络仅增加少量计算复杂度的情况下,最终的mAP提升了2.4个百分点。
从以上的实验结果中可以看到,通过使用本文提出的ACmixneck 模块和PSAsblock 模块可以增强动物姿态估计网络对通道信息和空间信息的关注,同时对于本文改进的特征融合部分,可以充分利用低分辨率网络分支中提取的特征信息,从而提升网络的预测精度,在复杂的动物姿态估计中取得不错的成绩。
为进一步验证极化注意力机制PSAs中不同通道注意力对本文模型的影响效果,以及对比不同注意力模块之间的差距,分别在PSAsblock 中添加PSA 空间注意力、PSA 通道注意力、CBAM 注意力以及PSAs 注意力,在HRNet 网络中进行定量消融实验。实验结果如表5所示。
从表5 中可以发现,和PSAsblock 模块中不添加注意力相比,单独添加PSA 空间注意力和通道注意力,模型精度分别提升0.3 个百分点和0.7 个百分点。表明PSAs 中不同通道对模型性能都有一定的性能提升,这得益于PSAs中各通道注意力对动物姿态关键点特征进行了有效学习。其次,当串联PSA通道注意力和空间注意力,也即是使用PSAs 模块后,相较于单通道,仅增加少量计算量的情况下,网络精度提升了1.6 个百分点。实验表明,相比于使用PSA单通道的方法,使用PSAs模块对动物姿态关键特征关注更好。而添加CBAM模块后,相比于不添加注意力的网络精度提升0.9 个百分点。但采用PSAs 模块比采用CBAM 模块,在网络仅增加2.2×106参数量和0.6 GFLOPs 计算量的情况下,精度提升了0.7 个百分点。这是因为PSAs 模块在空间和通道维度上都保持内部的高分辨率,保证了特征变化过程中的质量,减少了特征信息的损失。实验结果表明,采用PSAs模块可以有效提升网络模型的预测精度。
3.6 可视化实验分析
图11为本文方法和HRNet方法在AP10K测试集中的部分结果展示。图11(a)~(d)是多目标动物姿态中不同程度遮挡下的可视化结果。可以发现,在无遮挡的情况下中,HRNet方法和本文方法都能够准确检测出多目标动物姿态的关键点。但在遮挡比较严重的情况下,如图11(c)和(d)中的一些远景遮挡和小目标检测中,本文方法的检测性能比HRNet方法更优、更有优势。图11(e)~(h)是单目标动物姿态不同程度自遮挡或环境遮挡的可视化结果。同样,在无遮挡或轻微遮挡的情况下,可以发现本文方法和HRNet 方法检测效果均表现良好。但在一些复杂的环境遮挡和复杂的姿势中,如在图11(f)熊猫的髋部、图11(g)狮子的尾根和图11(h)黑猩猩的髋部和尾根,和HRNet方法检测错误或检测不到的关键点相比,本文方法都进行了正确检测。因此本文方法在一些复杂环境下,具有更好的检测性能。
图12是本文方法直接在Animal-Pose数据集上5个物种的部分可视化结果。从图12可视化结果中可以看出,除了严重遮挡的情况,在一些半身遮挡或者自遮挡的情况下,本文方法在跨数据集检测中都能够准确检测被遮挡的关键点。

图12 本文方法在Animal-Pose数据集上各物种可视化结果结果Fig.12 Visualization results of each species of this paper method on Animal-Pose dataset
4 结束语
本文以高分辨率网络HRNet 为基础网络进行优化改进,提出的ACmixneck 瓶颈模块和PSAsblock 基础模块通过融入通道注意力及空间注意力机制,有效增强了网络在多目标动物姿态估计中遮挡关键点的特征提取能力,同时优化了网络输出的特征融合方式,使得高分辨率网络的低分辨率分支中的细节特征得以充分利用。在AP10K 大型动物姿态数据集上的实验结果表明,相比当前用于动物姿态估计的HRNet,本文方法的mAP综合评价指标提高了2.4个百分点,有效改善了网络在复杂的多目标动物姿态中细节特征的提取能力。但是本文所做工作仍有待改进,比如在不牺牲模型预测准确度的情况下降低网络模型的参数量和运算复杂度,这些将是接下来需要进一步研究的内容。
