判别卷积神经网络的手写字符识别模型
2023-11-27屈喜文胡冕军
屈喜文,吴 响,胡冕军,黄 俊
安徽工业大学 计算机科学与技术学院,安徽 马鞍山243000
根据输入数据的类型,手写字符识别可分为联机手写字符识别和离线手写字符识别两种。联机手写字符识别的数据是坐标序列,通常被应用于人机交互设备中,例如手写板、智能手机、平板电脑等。离线手写字符识别的处理对象是图像类数据,已经被广泛应用于银行支票识别、字体识别、信函分拣、各类统计数据表格处理以及手写文稿识别。目前诗歌、手写文本等的识别也可被分割为字符,然后结合语义上下文进行识别,因此手写字符识别有广泛的应用价值。手写字符识别的研究已经持续多年,并且取得了很多卓越的研究成果[1-3],近年来深度学习在联机/离线手写字符识别领域展现出了明显的优势[3-4]。
在离线手写字符识别方面,Yang 等提出了原型卷积网络,为了使原型网络获取判别能力,结合多种原型学习损失函数(如最小分类误差损失函数、基于边缘的分类损失函数、基于距离的交叉熵损失函数以及一对多损失函数)设计了多种判别损失函数[5]。该卷积原型网络可以端到端联合训练卷积网络和每个类的优化原型,相较于softmax 损失函数,在公开的手写字符数据集上获得了更高的识别精度。文献[5]提出的判别损失函数相比softmax 损失函数显著提高了模型判别能力,但是在参数优化过程中softmax 求导更为方便,模型更容易收敛。
在联机手写字符识别方面,卷积神经网络的输入是图像,而联机手写字符是由坐标序列构成,因此基于卷积神经网络的模型需要先将坐标序列转换为图像,如转换为八方向特征模式图[6]。而坐标序列到图像的转换往往要结合具体领域知识挖掘上下文信息[7-9],转换过程难免造成信息丢失。另外,现有的基于卷积神经网络的模型在增加卷积层后往往会因为参数膨胀而导致训练困难,识别精度下降。基于循环神经网络的模型擅长处理序列数据,可以端到端识别联机手写字符[10-11],避免了因为数据格式转换导致的信息损失。循环神经网络模型能够挖掘时序数据中上下文关系,但是缺乏获取字符宏观结构信息的能力,由于网络结构限制,也不能识别离线手写字符。相对于循环神经网络,卷积神经网络模型既可以识别离线手写字符,也可以识别在线手写字符,更擅长学习字符的宏观结构信息,结合具体领域知识和数据格式变换技术,卷积神经网络在联机手写字符识别方面有望进一步提高识别精度。另一方面,现有的应用于手写字符识别的深度模型,不管是基于卷积神经网络的模型,还是基于循环神经网络的模型,一般是使用softmax 损失函数进行训练。softmax 损失函数缺乏从不同类样本中学习判别信息的能力[9-10]。手写字符中存在大量的相似字,它们之间的差别很小,需要采用更强判别能力的分类模型进行识别。
综上所述,为了在增加模型深度的同时尽可能控制模型参数数量,本文提出的模型分为编码器和解码两部分。编码器将原始数据转换为固定数量的特征图,避免了由于卷积层不断扩张堆叠造成参数剧增、难以训练的问题。为进一步提高模型的判别能力,本文提出了一种判别损失函数。该损失函数通过最小化每一个训练样本与其同类的优化原型的余弦距离获取判别信息。因为优化原型由最小化分类误差算法[12]学习得到,本身具有判别信息,所以判别损失函数训练模型时,其全连接层的输出特征向量向优化原型靠拢,从而提升了模型的判别能力。本文的主要贡献总结如下:
(1)提出了编码器与解码器组成的深度卷积神经网络模型,该模型有效增加了网络深度且易于训练;
(2)提出了一种判别损失函数,该函数保留了softmax易于收敛的优点,和softmax不同的是,该损失函数能够从不同类样本中获取判别信息;
(3)提出的判别卷积神经网络模型既适用于在线手写字符识别,也可用于离线手写字符识别。
1 判别卷积神经网络的手写字符识别流程
本文离线/联机手写字符识别算法流程如图1所示,包括预处理、提取八方向特征模式图、判别卷积神经网络几部分。对于离线手写字符,本文直接将原始数据作为模型输入。对于联机手写字符,本文使用八方向特征提取算法[6]将坐标序列转换为八方向特征模式图,然后输入神经网络模型。因此本文提出的模型既适用于联机手写字符识别,也适用于离线手写字符识别。
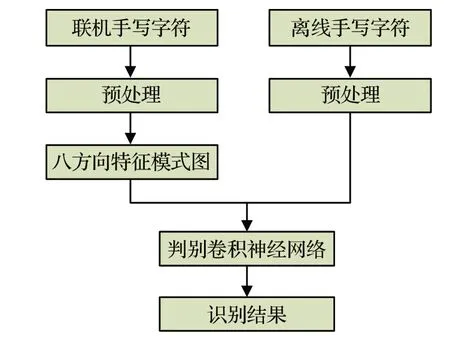
图1 算法流程Fig.1 Algorithm flow chart
1.1 预处理
由于不同书写者的书写风格各不相同,写出的同类字符有的高有的矮,有的宽有的窄,有的端正有的倾斜,这种类内的差异会降低分类器识别率,需要对原始数据进行预处理,以减少类内偏差。
对于联机手写字符本文采取的预处理步骤总结如下:(1)将原始坐标映射到64×64像素大小的图像上,并用点生成算法bresenham连接离散点。(2)采用非线性规范方法[13]使坐标点分布更加均衡。(3)经过上述步骤处理的字符轨迹可能包含一些重复点和断点,通过对比前后点的坐标,删除重复点,并使用bresenham算法连接断点。(4)对字符坐标序列重新采样,重采样间隔为2个坐标点。联机手写字符“徽”的预处理效果如图2所示,从左往右依次是原始字符和步骤(1)到(4)的处理结果。

图2 预处理示例Fig.2 Example of preprocessing
由于离线手写字符数据是图像,本文对于离线手写字符的预处理是将离线手写字符图像统一为固定大小图像,然后输入卷积网络进行识别。
1.2 提取八方向特征模式图
经过预处理后,本文采用八方向特征投影技术[6]将联机手写汉字坐标序列中连续两个点的方向矢量分解投影到八个方向上,每个方向对应一个方向模式图,方向模式图的大小为64×64。为了尽可能保存原始数据中的信息,本文对八方向特征模式图不经过滤波处理,直接将投影得到的八方向特征模式图作为卷积神经网络的输入。“安徽”两字的八方向模式图如图3所示,从左往右依次是原始字符及其相应的八个方向的特征模式图。
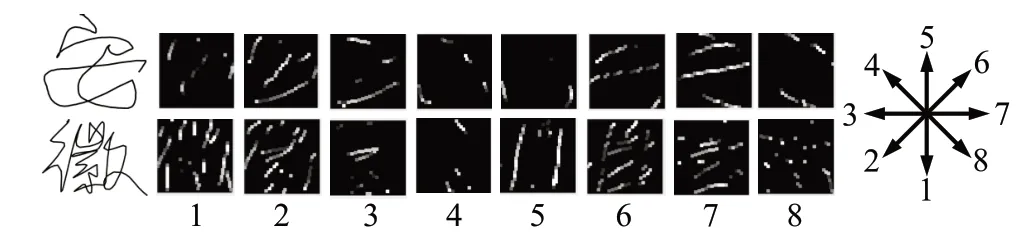
图3 八方向模式图示例Fig.3 Example of 8-directional pattern maps
1.3 卷积神经网络模型的搭建
本文提出的判别卷积神经网络模型如图4所示,由编码器和解码器两部分构成。对于联机手写字符输入是八方向特征模式图,对于离线手写字符输入是统一尺寸后的图像,网络的所有卷积层都使用批规范化[14]解决分布变化问题,并加速神经网络的训练。激活函数采用非线性Leaky-ReLU[15]。
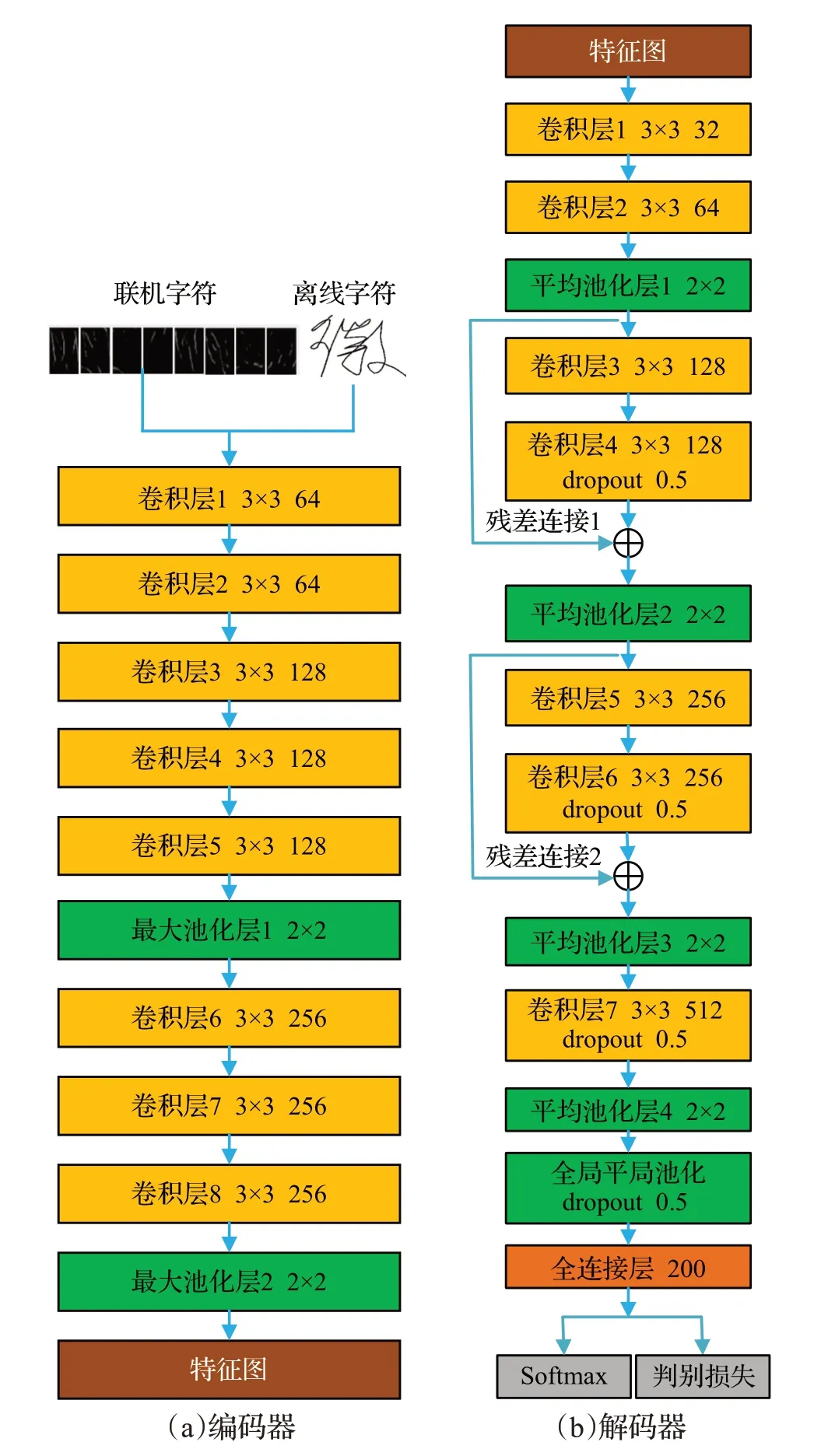
图4 判别卷积神经网络模型Fig.4 Discriminative convolutional neural network model
1.3.1 编码器
如图4(a)所示,编码网络共有8 个卷积层,所有卷积核的大小为3×3,步长为1,填充为1。在第5和第8卷积层之后使用最大池化,最大池化大小为2×2,步长为2。在编码网络,本文将特征图数量从输入的8张特征模式图或者离线字符的8张图像增加到256。将编码器输出特征图数量设置为256,并作为解码器的输入,从而避免了直接堆叠卷积层网络时特征图数量增加导致的参数剧增,有利于控制参数数量,增加网络深度。
1.3.2 解码器
解码网络如图4(b)所示,共有7 层卷积层,卷积层参数设置与编码网络相同。为了提高计算效率,从编码网络提取的特征图通过第一层卷积投影到32 张特征图,特征图数量从32增加到512。为提高网络模型对手写字符多变的笔划顺序和结构的鲁棒性,使用平均池化,平均池大小为2×2,步长为2。在全连接层前使用了全局平局池化[16]以兼顾手写字符的整体结构,减少参数数量。通过向解码网络中添加残差连接1和残差连接2以解决梯度消失问题,加快网络的训练速度[17]。在卷积层4、卷积层6、卷积层7以及全局池化层使用了dropout[18],dropout 的随机丢失率设置为0.5,以提高网络的泛化能力,防止过拟合。最后,使用softmax 层和判别softmax层进行分类。本文网络的训练步骤如下:先使用训练数据预训练图4所示卷积神经网络模型,之后去掉softmax层,将上述网络模型作为特征提取器,提取每个训练样本的特征,由于最后一个全连接层有200 个节点,提取的特征是200 维的向量。使用提取的特征向量和最小化分类误差算法[12]学习每个类的优化原型,然后最小化特征向量与优化原型之间的余弦距离再次训练网络模型。由于优化原型具有判别信息,判别的softmax 可以使深度神经网络获得判别能力,即同类之间更加紧缩,不同类之间更加分离。
1.4 判别损失函数
本文预训练时使用的softmax损失函数如下:
其中L表示损失,m表示批量训练时每一批样本的数量,s=1,2,…,m,ys=1,2,…,C,ys是样本xs的类标,C表示类别总数,bys和bj是偏置项,wj是对应于第j个类的模型参数,j=1,2,…,C。式(1)中的softmax 损失函数易于求导,在训练模型过程中易于收敛,但是该损失函数不具备从不同类样本中学习判别信息的能力。为了提高卷积神经网络的判别能力,本文提出了判别损失函数,具体如下:
其中τ为调节因子。式(2)中的dj可由下式求得:
其中qj是第j个类的优化原型。式(2)中的判别损失函数和softmax 损失函数相同之处在于易于求导,训练过程中,神经网络模型易于收敛。和softmax 损失函数不同之处在于最小化式(2)中判别损失函数时,dj也就相应最小化,即等价于最小化式(3)中表示的样本特征与优化原型之间的余弦距离。优化原型由最小化分类误差算法学习得到,具有判别信息,因此由该判别损失函数训练得到的模型也就具备了更强的判别能力。对比式(1)和式(2)可以看出,softmax损失函数中有权值,而判别损失函数中没有权值,因此判别损失函数比softmax损失函数节省存储空间。
1.5 最小化分类误差算法
最小化分类误差算法[12]是一种优化分类器参数,提高分类器判别能力的算法。该算法基于分类器分类规则定义了一个损失函数,并使用随机梯度下降法在给定训练集上最小化该损失函数,以寻求最佳分类器参数。特征提取器提取的特征向量xci∈R1×200,其中ci表示第c类的第i个样本,且c=1,2,…,C。K-NN分类器在K=1 时的分类规则为:
其中j=1,2,…,C,qj表示第j个类的优化原型。每个样本xci的分类损失可定义为:
其中qc是样本xci所属第c类的优化原型,qr是的最近对手类的优化原型,r=1,2,…,C且r≠c。的分类损失可写为:
其中ς是调节因子。优化目标函数为:
其中N表示训练样本总数,nc表示第c个类的训练样本数。本文通过随机梯度下降法求解式(7)中所有类的优化原型qc,c=1,2,…,C。由式(6)对类别原型qc和qr求偏导可得:
在随机梯度下降法求解过程中,因为样本xci仅仅涉及两个类的原型qc和qr,所以qc和qr可由式(9)更新:
其中σ(t)是学习率,t是迭代次数。将式(8)带入到式(9)得:
式(10)中σ(t)包含了调节因子ς。在本文后面的实验中,每个类的原型数量根据经验确定为1,每次迭代后的衰减率为σ(t+1)=0.95×σ(t),迭代终止条件为 |l0(t+1)-l0(t)|<0.001。通过本节所述优化算法即可学习得到每个类的优化原型。
2 实验结果与分析
2.1 数据集
本文在公共数据集IAHCC-UCAS2016[4]和MNIST[19]上进行实验。MNIST 是离线手写字符识别经典数据集,该数据集涉及0~9 共10 个类,分为训练集和测试集两部分,训练集有60 000个训练样本,测试集包含10 000个测试样本。
IAHCC-UCAS2016 是一个空中手写汉字数据集,该数据集包含GB/T2312—1980 一级字库的3755 个字符类,另外还包含二级字库中的56个常用汉字,每个类有115 个样本。在IAHCC-UCAS2016 数据集上进行5折交叉验证,最终识别率为5次实验平均实验结果。
2.2 模型参数设置
本文所有的实验都是在RTX-2080ti 上进行,基于PyTorch 平台构建网络模型,使用平台的默认参数进行初始化。优化器使用Adam[20],最小批量设置为256,初始学习率设置为0.001。当训练集上的准确度不再增加或缓慢增加时,降低学习率(衰减率为0.1)。在优化原型学习阶段,式(10)中初始学习率σ(1)在MNIST 数据集上取0.05/nc,在空中手写数据集IAHCC-UCAS2016上取1/nc,nc表示第c个类的训练样本数量。本文通过实验选择调节因子τ。为快速找出合适的调节因子,在IAHCC-UCAS2016中选择前300个类进行实验。MNIST中使用训练数据进行实验,实验结果如图5 所示。从图5 可以看出MNIST 上调节因子在0.5 附近,IAHCCUCAS2016 上调节因子在12 附近能够达到更高的识别率。本文在两个数据集上调节因子分别取0.5和12.5。
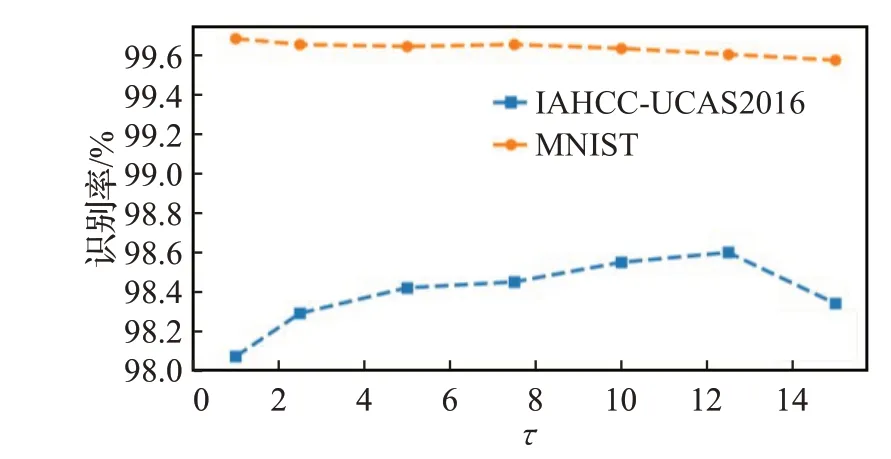
图5 不同调节因子在两种数据集上的识别率Fig.5 Recognition rate of different regulatory factors on two datasets
2.3 实验结果及分析
本文中计算识别准确率R的公式为:
其中Nt表示测试集中样本总数,Nc表示测试集中识别结果正确的样本数。
本文在两个数据集上比较了softmax损失函数和提出的判别损失函数的识别率,识别结果如表1所示。

表1 两种损失函数在不同数据集上的识别率Table 1 Recognition rate of two loss functions on different datasets 单位:%
从表1 中可以看出,提出的判别损失函数训练得到的模型在IAHCC-UCAS2016 数据集上的识别率比softmax 损失函数高1.04 个百分点。在MNIST 数据集上,在识别率高达99.5%以上的情况下,提出的判别损失函数仍然比softmax损失函数高出0.14个百分点。分析实验结果中使用softmax损失函数识别错误的字符可以发现,相似字的存在是影响识别精度进一步提高的主要因素,由于相似字之间的差异很小,如“己”和“已”,加上书写过程中连笔和省略等因素,导致写成的文字极难区分。空中手写数据集IAHCC-UCAS2016的相似字样本如图6 所示。判别损失函数通过将样本特征向优化原型收缩,从而加强了网络的判别能力,提高了对相似字的识别能力,从而获得了更高的识别率。从式(1)和式(2)中可以看出,softmax 需要存储权值,而提出的判别损失函数没有权值,因此softmax 比提出的损失函数多消耗0.01 MB的存储空间。

图6 数据集IAHCC-UCAS2016中样本示例Fig.6 Sample examples in IAHCC-UCAS2016 dataset
本文将提出的模型与相似模型以及近几年出现的高性能分类器进行了对比。表2 和表3 分别是本文模型和其他模型在数据集MNIST 和IAHCC-UCAS2016上的对比结果。

表2 不同方法在数据集MNIST上的识别率Table 2 Recognition accuracy of different methods on MNIST dataset 单位:%
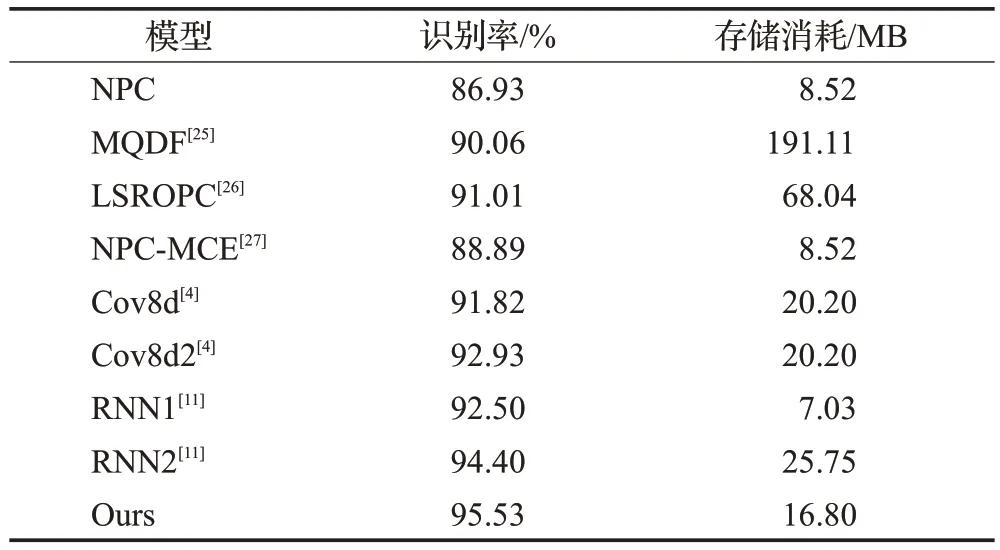
表3 在IAHCC-UCAS2016上不同方法的性能比较Table 3 Performance comparison of different methods on IAHCC-UCAS2016 dataset
从表2 和表3 中可以看出,本文模型在两个数据集IAHCC-UCAS2016和MNIST上均获得了最高的识别精度,识别率分别达到了95.53%和99.73%,从而证明了本文模型既适用于离线字符识别,也适用于联机手写字符识别。
相较于经典的传统模型MQDF[25]和LSROPC[26],本文模型识别率提高了4.5个百分点以上。由于神经网络模型对于各个类实现了参数共享,而MQDF和LSROPC等传统方法各个类的分类参数是独立的,因此本文模型存储消耗仅16.8 MB,远小于MQDF 的191.11 MB 和LSROPC 的68.04 MB。相比较应用于空中手写汉字识别的卷积神经网络模型Cov8d[4]和循环神经网络模型RNN1[11],本文模型在识别精度上分别提高了3.71 个百分点和3.03 个百分点。相对于使用了样本增强技术的卷积神经网络模型Cov8d2[4]和使用了分类器组合技术的循环网络模型RNN2[11],本文模型不仅识别率分别提高了2.60个百分点和1.13个百分点,并且存储消耗也更小。
3 结束语
针对现有的基于卷积神经网络的手写字符识别模型在卷积层堆叠过程中造成参数剧增和精度下降问题,本文提出了一种结合解码器和编码器的卷积神经网络模型。该模型通过控制解码器输出特征图数量,避免了模型参数因为网络深度增加而剧增的问题。为进一步提高模型判别能力,本文提出了一种判别损失函数。实验结果表明,提出的判别损失函数比softmax 损失函数可以有效提高识别精度。与现有的手写字符识别模型相比,本文提出的判别卷积神经网络模型在联机/离线手写字符识别上获得了更高的识别精度。
但是本文提出的模型仍然需要结合领域知识将联机手写字符的坐标序列转换为图像,这种转换不可避免地造成了信息损失。在保证识别精度情况下,不经过数据格式转换,通过改变卷积核尺寸,端到端识别联机手写字符的卷积神经网络模型将是进一步的研究方向。
