结合显著特征筛选和ViT的面部表情识别方法
2023-11-27封红旗黄伟铠张登辉
封红旗,黄伟铠,张登辉
1.常州大学 计算机与人工智能学院,江苏 常州213100
2.浙江树人大学 信息科技学院,杭州310000
人脸面部表情是人类表达情感状态和意图最有力、最自然和最普遍的信号之一[1]。面部表情识别技术在社交机器人、医疗诊断、疲劳监测等人机交互领域有着非常广泛的应用[2]。目前异地独居人口日益增多[3],帮助他们获得情感慰藉是当前社会重点关注的问题。一些研究人员将研究重心倾注在情感交互机器人上,其原因为情感机器人能够从文字、语音、人脸面部特征等多方面理解人类情感状态并与之交互,从而能在人们独居生活中给予他们贴心的互动交流。然而在真实的人机交互过程中,人们通常会执行一系列动态行为(转头、行走、拿取物品、开关灯等),这可能会导致机器人通过摄像头捕捉到的面部图像受到遮挡、姿态变化、光照等因素影响,进而降低表情识别的准确率。
受Transformer 在计算机视觉领域成功应用的启发,本文提出了一种结合显著特征筛选和视觉转化器的优化模型(distinguishing feature filtering and vision transformer,DFFViT),通过筛选显著人脸面部特征并映射为特征单词序列,来更准确地描述在不利因素影响下的面部情感状态。首先,采用加权求和光照归一化方法(weighted sum illumination normalization,WSIN)削弱光照对表情识别的影响,并利用卷积神经网络来提取图像的面部特征。其次,采用显著特征筛选模块(distinguishing feature filtering,DFF)聚合面部的局部-全局上下文,过滤特征中的无效信息,筛选显著细节信息,提高表情识别性能。紧接着,通过切片、展平和投影操作,将二维特征映射为一维单词序列,并馈送到多层Transformer编码器(multi-layer transformer encoder,MTE)中加强面部特征之间的联系,从而提高模型的特征学习能力。最后,使用Softmax函数对学习结果进行表情预测。
1 相关工作
1.1 面部表情识别
人脸面部表情识别主要包括三个阶段[2]:人脸图像收集与检测、面部特征提取和表情识别。在真实环境下,面部图像会受到遮挡、姿态变化等因素的影响,因此准确提取面部特征是至关重要的环节。
卷积神经网络凭借强大的特征提取能力取代了传统方法,成为面部特征提取的主流方法之一。文献[4]提出了一种基于改进神经网络与支持向量机相结合的优化模型,与传统方法相比,具有良好的鲁棒性。文献[5]提出了一种改进的LeNet-5 卷积神经网络,将低层次特征和高层次特征相结合,取得了较好的性能。虽然研究人员使用卷积神经网络弥补了传统工程方法在面部表情特征提取上的缺点,但是当面部图像出现不确定因素时,该方法很难准确提取到反映真实面部表情的特征。
为此一些研究人员将注意力机制应用于网络模型中,使其能够关注面部图像中显著的特征。Li等人[6]提出了一种带有注意力机制的卷积神经网络(attention convolution neural network,ACNN),可以感知人脸的遮挡区域,并关注最具判别性的未遮挡区域。Wang等人[7]提出了区域注意网络(region attention networks,RAN),能够自适应地捕捉面部区域在遮挡和姿态变化中的重要性。Wang等人[8]提出了自修复网络(self-cure network,SCN),采用样本排序正则化和低权重样本的重标签机制,有效地抑制真实环境下面部表情识别的不确定性。上述研究虽然有效解决了遮挡、姿态等不利因素的影响,却忽略了模型的特征学习能力。
为此,Amir 等人提出了深度注意中心损失算法(deep attentive center loss,DACL),在深度度量学习方法中集成注意机制,自适应地选择显著特征,并增强特征学习的泛化能力。Ma 等人[10]提出了基于特征融合的视觉转化器(visual transformers with feature fusion,VTFF),通过聚合多分支特征以丰富面部特征的表达能力,并采用多层Transformer 编码器建立特征之间的联系,有效提高了模型的学习能力。
1.2 光照归一化
受光照条件的影响,不同图像的对比度可能会存在差异。因此,即便是同一个人表现出相同的面部表情,但在不稳定的光源环境下,识别结果也可能会产生较大的偏差[2]。为了削弱光照的影响,Ioannis 等人[11]提出了双向重光照(bidirectional relighting)算法,以最小化纹理之间的光照差异,该方法具有更少的约束条件,有助于更广泛地适用于一般光照归一化。Virendra等人[12]采用低频带离散余弦变换[13]和对数变换相结合,自适应地对图像进行光照归一化。相关研究表明,结合直方图均衡化的光照归一化可以获得更好的识别性能。但是对图像采用单一的直方图均衡化可能会导致图像的局部对比度过度增强,为此,本文采用文献[14]提出的直方图均衡化和线性变换加权求和的光照归一化方法。
1.3 注意力机制
注意力机制能够选择性地聚焦具有鉴别性的细节信息,是提高模型鲁棒性和识别性能的一个重要手段[15]。Woo 等人[15]提出了卷积块注意力模块(convolutional block attention module,CBAM),从通道和空间两个维度依次计算注意力权重,并通过权重对特征进行自适应细化。Hu 等人[16]提出了挤压与激励模块(squeeze-andexcitation,SE),通过显式建模卷积特征通道之间的相互依赖关系,从而提高模型的表达能力。Dai 等人[17]提出了多尺度通道注意力模块(multi-scale channel attention module,MS-CAM),利用注意力机制聚合局部特征和全局特征的上下文信息,并通过网络的学习使融合权重最优化,自适应地关注具有判别性的特征。但本文实验发现,将MS-CAM 模块应用于表情识别任务时会出现过拟合现象。
1.4 视觉转化器
Transformer[18]凭借优越的序列建模能力和全局信息感知能力,在自然语言处理领域得到广泛使用,越来越多的研究人员开始将Transformer应用到计算机视觉领域。Alexey等人[19]提出了视觉转化器(vision transformer,ViT),这是Transformer 第一次被应用于图像任务。研究人员在此基础上进行深入探索,从而衍生出了许多ViT 的变体。Wang 等人[20]提出了金字塔视觉转化器(pyramid vision transformer,PVT),能够将Transformer移植到各类密集预测任务。Wu等人[21]提出了卷积视觉转化器(convolution vision transformer,CVT),将ViT与卷积运算相结合,使卷积网络的特性和Transformer的优点得以融合。本文的DFFViT模型同样为ViT的变体,通过加入光照归一化和特征注意力模块,使其适用于人机交互场景下的表情识别任务。
2 DFFViT模型
2.1 模型整体架构
DFFViT 模型的总体架构如图1(a)所示,给定一个大小为3×H×W的面部表情图像ImgORI,首先采用光照归一化方法得到光照适中图像ImgILL。紧接着采用在MS-Celeb-1M人脸数据集上预训练的ResNet18作为特征提取主干网,以此提取大小为的特征映射XILL,其中Cout为输出的通道数,DS为下采样的倍率,为了简化描述,定义。利用显著特征筛选模块聚合局部-全局上下文来关注大小为Cout×HDS×WDS的显著特征XF。将显著特征XF按特定大小切片成M个二维特征块,并通过线性投影映射为一维特征向量,在特征向量头部嵌入可学习的分类编码[class],同时添加可学习的位置编码Pos以保留位置信息,以此得到长度为M+1 的视觉单词序列,将单词序列馈送到多层Transformer 编码器,从而加强面部特征之间的联系。
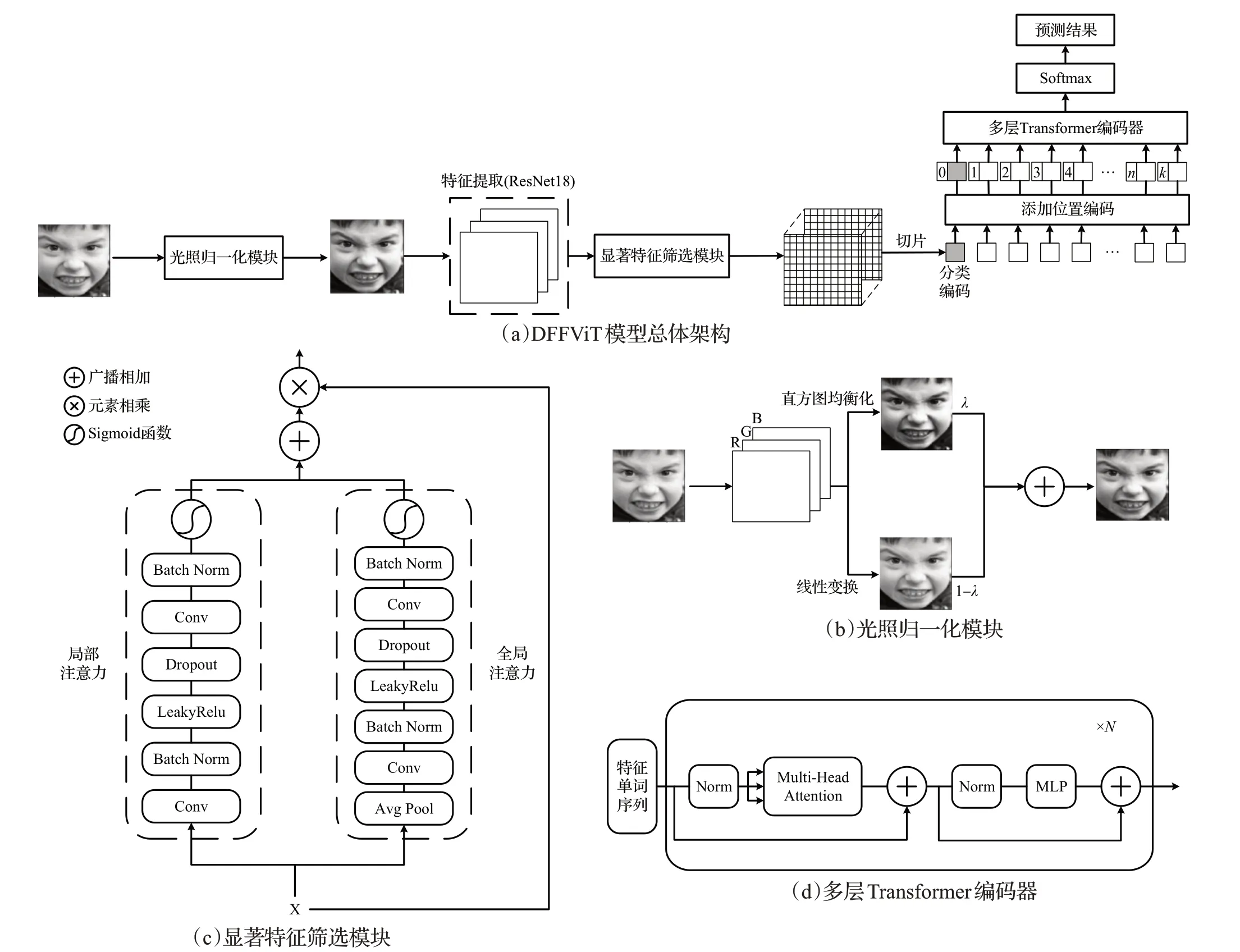
图1 DFFViT模型总体架构及模块Fig.1 Overall architecture and modules of DFFViT model
2.2 光照归一化模块
真实环境下摄像头捕捉的面部表情图像通常都会受到不同光照的影响,这可能会阻碍模型的训练。为得到光照适中的面部图像,本文采用了直方图均衡化[22]和线性变换(将最小和最大像素映射到区间[0,1])加权求和的归一化方法。如图1(b)所示,给定一个大小为3×H×W的面部表情图像ImgORI,首先分别获得直方图均衡化图像ImgHE和线性变换图像ImgHN,紧接着将ImgHE和ImgHN按适当的权重融合成光照适中图像ImgILL,具体可表示为:
式(1)中,δ表示权重因子,本文设置δ=0.5。三种光照归一化方法的效果如图2 所示。由图可见单独使用直方图均衡化会过度增强图像局部对比度,单独使用线性变换在个别图像上的效果并不理想。

图2 三种光照归一化方法的效果对比Fig.2 Comparison of effects of three illumination normalization methods
2.3 显著特征筛选模块
为了能够自适应地关注细微的表情变化和重要的面部特征,本文设计了DFF模块。该模块由局部注意力通道和全局注意力通道组成,模块整体结构如图1(c)所示。给定特征映射,经过双分支注意力通道可计算得到局部注意力权重Local(X)∈和全局注意力权重Global(X),具体可表示为:
式(2)(3)中,AP表示全局自适应平均池化,用于过滤无效面部信息;Conv1和Conv2表示逐点卷积(卷积核大小为1),以提取细节特征;BN表示批归一化处理;D表示Dropout层,用于抑制过拟合,在本文中设置dropout=0.3;ℜ 表示LeakyRelu 激活函数;σ表示Sigmoid 函数。将双分支注意力权重通过广播加法进行融合,得到局部-全局注意力权重LG(X),使用残差连接,筛选出显著特征。
DFF 模块可视化如图3 所示,可以看出未应用DFF模块时注意力分布较为分散,无法有效地关注具有辨别性的特征,而使用DFF模块后注意力集中于表情细微变化位置。

图3 DFF模块的注意力可视化Fig.3 Attention visualization with DFF module
2.4 多层Transformer编码器
其中,Conv表示输入通道为Cout,输出通道为Cf,卷积核与步长为(P,P)的卷积层,用于分割显著特征并进行可学习的线性映射;Flatten表示展平操作。在特征序列头部嵌入可学习的情感分类编码[class],同时为该序列中的每个特征单词添加可学习的位置编码Pos∈以保留其位置信息,该特征序列可表示为:
采用多层Transformer 编码器对特征序列Z0进行处理,加强面部特征之间的关联性,编码器整体结构如图1(d)所示,每层Transformer 编码器由多头自注意模块(multi-head attention,MHA)和多层感知器模块(multilayer perceptron,MLP)组成,在每个模块之前应用归一化,在每个模块之后加入残差连接,具体可表示为:
式(7)(8)(9)中k=1,2,…,N,表示在第k层经过MHA模块和残差连接后得到的面部特征序列,Zk表示在第k层经过MLP模块和残差连接后得到的面部特征序列,LN 表示归一化,ZN表示经过N层Transformer编码器后得到的面部特征序列。本文中设置多头数L=12,层数N=12。
最终,得到经过多层Transformer 编码器处理后的面部特征序列y,使用其头部的情感分类编码[class]以预测面部表情结果。
3 实验
3.1 数据集描述
RAF-DB[23]是真实世界的面部表情数据集,包含30 000张人脸面部图像,其中每张面部图像由40名训练有素的工作人员进行标注。RAF-DB 包含基本表情子集和复合表情子集,本实验只使用了具有6个基本情绪和1个中性情绪的基本表情子集,该集合涉及12 271个训练样本和3 068个验证样本。图4为RAD-DB数据集示例图像。

图4 RAF-DB数据集中7种表情示例图像Fig.4 7 kinds of facial expression images in RAF-DB dataset
FERPlus[24]是对FER2013数据集的扩展,包含28 709个训练样本和3 589 个验证样本,其中每张面部图像由10名工作人员进行投票标注,为了公平比较,采用多数投票策略为每张图像筛选标签(筛除unknown和非人脸图像)。图5为FERPlus数据集示例图像。

图5 FERPlus数据集8种表情示例图像Fig.5 8 kinds of facial expression images in FERPlus dataset
AffectNet[25]是目前最大的公共面部表情数据集,包含从互联网上收集的45万张面部图像。本实验选取由手工标注的具有8类基本情绪的图像,其中包含286 621个训练样本和4 000个验证样本。图6为AffectNet数据集示例图像。

图6 AffectNet数据集8种表情示例图像Fig.6 8 kinds of facial expression images in AffectNet dataset
3.2 实现细节
本文采用Pytorch 搭建深度学习模型,实验环境参数(软硬件配置)如表1所示。

表1 实验环境配置Table 1 Experimental environment configuration
本实验使用MTCNN 网络[26]定位面部图像中的人脸位置并裁剪,将裁剪后的图像大小调整为256×256。进行训练时,将人脸图像的大小随机裁剪为224×224,并进行随机水平翻转,进行测试时,将人脸图像的大小中心裁剪为224×224。
如图7 所示,每隔100 批次获取AffectNet数据集训练样本的分布情况,并随机展示其中的5 次分布结果,图中X轴表示样本批次,Y轴表示样本数量。由图7(a)可以看出AffectNet 数据集的训练样本分布极度不平衡,因此采用Pytorch 提供的加权随机过采样策略(weighted random sampler)来平衡训练样本,处理后的结果如图7(b)所示,样本分布与处理前相比得到了极大改善,削弱了样本分布不平衡带来的不利影响。
采用ResNet18 作为主干网络,在MS-Celeb-1M 人脸识别数据集上进行预训练,并使用最后一个池化层提取所需的面部特征,多层Transformer 编码器加载在ImageNet21K 数据集上预训练权重。在所有的数据集上,批量大小设置为32,学习率初始化为0.000 5,采用余弦退火学习率衰减策略,学习率衰减周期设置为5,训练总轮次设置为50。使用AdamW优化网络模型,权重衰减值设置为0.000 1,并利用交叉熵损失函数对模型进行评估,实验参数设置如表2所示。

表2 实验参数Table 2 Experimental parameters
3.3 实验结果与分析
DFFViT 模型在RAF-DB、FERPlus 和AffectNet 面部表情数据集上得到的各类别表情识别结果和识别准确率曲线如图8、图9所示。
图8所示的3个混淆矩阵,表明DFFViT模型在3个面部表情数据集上取得的各类表情识别准确率。其中RAF-DB 有7 种表情类别,FERPlus 和AffectNet 有8 种表情类别。X轴表示面部表情的预测标签,Y轴表示面部表情的真实标签,矩阵的主对角线表示各类表情的识别精度,其余位置表示各类表情误判率。由图8可以看出,3个数据集上恐惧和惊讶是容易混淆的,其误判率分别为12.2%、16.7%、13.8%,这是因为恐惧和惊讶有着相似的面部变化,会导致有许多重叠的面部特征,使得网络难以学习。FERPlus数据集上轻视(31.2%)的识别准确率偏低且易被误判为中性(50.0%)。主要原因是轻视大多表现为嘴角上扬,轻微挑眉,面部变化不明显,从而不易与中性表情区分。导致上述情况的另一个原因是FERPlus数据集中相应表情样本数量较少。
由图9直观显示,本文提出的DFFViT模型在3个公共面部表情数据集上分别取得了88.36%、89.13%和62.08%的识别准确率。其中X轴表示训练迭代轮次,Y轴表示表情识别准确率(RAF-DB 和FERPlus 采用总体精度评估模型,AffectNet采用平均分类精度评估模型)。
基于在RAF-DB、FERPlus 和AffectNet 面部表情数据集上取得的识别准确率,本文将DFFViT 模型与其他几种方法进行了对比,结果如表3所示。其中gACNN[6]没有FERPlus数据集的实验数据,对应位置用“—”标记,最优的识别结果以粗体标记。DFFViT模型在RAF-DB上达到了88.36%的识别准确率,比SCN[8]和VTFF[10]分别提升了1.33 个百分点和0.22 个百分点。本文提出的DFFViT模型在FERPlus数据集上取得了89.13%的识别准确率,与RAN和VTFF相比分别提升了0.58个百分点和0.32个百分点。上述结果说明了DFFViT模型在小规模数据集上具有良好的性能。DFFViT模型在AffectNet数据集上得到了62.08%的识别准确率,较VTFF提高了0.23 个百分点,该结论表明DFFViT 对大规模数据集同样具有良好的泛化能力。

表3 DFFViT与其他先进方法的识别准确率比较Table 3 Comparison of recognition accuracy between DFFViT and other advanced methods 单位:%
3.4 消融实验
为验证DFFViT 模型中各模块的有效性,本实验采用控制变量法,在RAF-DB数据集上实验并进行识别性能对比,变量设置与实验数据如表4所示。其中最优的识别结果以粗体标记,编号a为基线方法(在MS-Celeb-1M数据集上预训练的ResNet18)。

表4 RAF-DB数据集上的消融实验Table 4 Ablation experiments on RAF-DB dataset
本文通过设置a、d、e、h 四组实验,来验证WSIN 模块的有效性。由(a,e)对比可知,仅添加WSIN模块时,识别准确率比基线方法提升了0.88个百分点。通过(d,h)对比可得,在已存在其他模块的基础上加入WSIN模块后,识别性能提升了0.13个百分点。该结果表明WSIN模块能够有效地中和对比度,最小化光照对面部图像的影响,对提高模型的识别准确率具有重要的作用。
本文通过设置a、b、j、h 四组实验,来检验DFF 模块的有效性。从(a,b)对比可以得出,通过DFF 模块关注原图显著特征时,性能较基线方法提高了1.24 个百分点。由(j,h)对照可知,当使用DFF 模块关注ILL 特征时,识别性能显著提升。实验结果显示DFF模块能够聚合局部-全局上下文信息,以关注面部显著特征,从而提升模型性能。
为评估多层Transformer 编码器的性能,设置a、b、c、d、f、h 六组实验。通过(a,c)对比可知,应用多层Transformer编码器后,识别性能比基线方法高出1.46个百分点。由(b,d)和(f,h)两两对照可得,识别准确率较采用多层Transformer 编码器前分别提高了0.84 个百分点和0.62 个百分点。由此得出结论,多层Transformer编码器能够有效地提高模型学习特征间联系的能力,对提升性能有极大的帮助。
多层Transformer 编码器包括N个相同的层,每层中有L个单头自注意力模块,为验证不同N和L对模型性能的影响,本实验在RAD-DB数据集上设置了五组不同N、L进行识别精度对比,变量设置与实验数据如表5所示,其中最优的识别结果以粗体标记。由(a,b,c)三组实验分析可知,适当地增加自注意力模块的头数能够更好地捕捉面部特征序列的深层表示,以取得更高的识别精度。由(c,d,e)三组实验分析可知,增加N的层数会导致识别性能下降,原因是层数的增加会使得参数量过于庞大,导致模型过拟合。
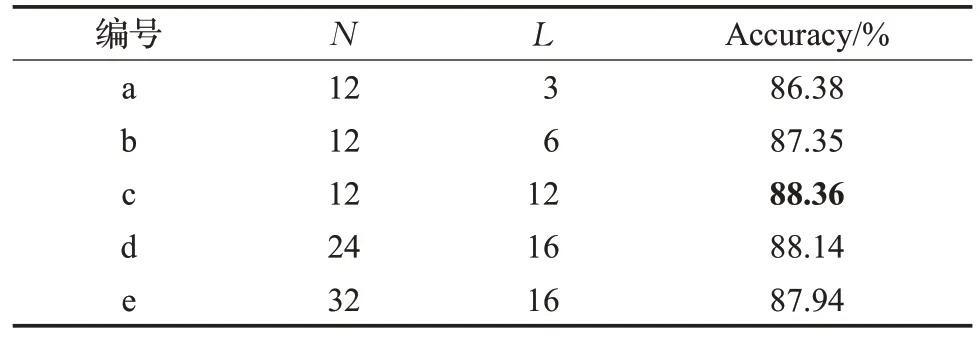
表5 RAF-DB数据集上的不同N 和L 的对比实验Table 5 Comparative experiments of different N and L on RAF-DB dataset
4 结束语
为解决真实的人机交互环境下面部图像受各种不确定因素影响而导致准确率降低的问题,本文提出了结合显著特征筛选和视觉转化器的面部表情识别模型。采用CNN 和显著特征筛选模块提取光照适中图的特征,并动态地聚合局部-全局上下文信息,以得到鉴别性更强的表情特征,并利用多层Transformer 编码器加强特征间的关联性,以提高识别性能。实验结果表明,该模型在三个公开的面部表情数据集上均取得较好的识别准确率。后续,将研究如何把本文所提出的模型进一步应用于情感交互机器人中。
