利用空间-光谱双分支特征和动态选择的高光谱影像农作物分类
2023-11-26戴佩玉李卫国
戴佩玉,张 欣,毛 星,任 妮 ,李卫国
(1. 江苏省农业科学院,南京,210014;2. 农业农村部长三角智慧农业技术重点实验室,南京,210014)
0 引言
随着科学技术、硬件设备以及航天航空技术的快速发展,遥感技术以其不需要接触被测目标即可远距离获得光谱几何信息,不受恶劣地面条件限制等优势得广泛应用[1]。高光谱影像由于记录了连续的窄光谱波段,不仅能够表征地物的结构、纹理信息,还可以反演大量的光谱信息,在资源环境监测、地质勘测、农业产业分析和估产等方面获得广泛应用[2-4]。
高光谱影像农作物分类(hyperspectral image classification,HSIC)通过判别影像中每个像素对应的农作物及其他混淆地物类型标签获得地表结构分布,近年来受到越来越多的关注。如何从高维度的光谱通道中针对性地提取最具判别性的地物目标本征特征是高光谱影像分类的关键。传统的高光谱影像分类算法为了捕捉丰富的光谱信息,引入逻辑回归[5]、K邻近分类器[6]、距离分类器[7]、最大似然分类器[8]等进行相似性检测和分类,但是,由于忽略了对于空间信息的探索,随着影像的光谱维度不断增高,分类结果的Hughes 现象[9]明显。
考虑到高光谱数据“图谱合一”的特性,即不仅仅记录了丰富的光谱信息,也蕴含着大量的空间特征,光谱降维和空间、光谱联合特征提取技术相结合的高光谱分类算法逐渐发展起来,主成分分析(principal component analysis,PCA)、独立成分分析(independent components analysis,ICA)、线性判别分析(linear discriminant analysis,LDA)等[10-13]是最常用的光谱降维技术,空间特征提取过程中则多采用拓展形态学剖面[14](extended morphological profiles,EMP)、局部二值模式[15](local binary patterns,LBP)等技术,由于加入了空间特征[16],如Garbor 特征、差异形态学特征(differential morphological profile,DMP)、灰度共生矩阵(grey-level co-occurrence matrix,GLCM)等,这类算法的分类精度远高于传统方法,但“同物异谱,异物同谱”问题[17]仍然没有得到有效解决。
机器学习的发展使得支持向量机(support vector machine,SVM)、极限学习机(extreme learning machine,ELM)、随机森林(random forest,RF)、贝叶斯理论等逐渐在高光谱分类[18-21]领域崭露头角。然而这类算法中经验设计特征耗时耗力,参数阈值的选择依赖于多次试验和经验,算法的鲁棒性不强。能够自动提取经验设计特征中缺乏的浅、中、高层抽象语义特征的深度学习技术发展迅猛,深度置信网络(deep belief networks,DBN)、循环神经网络(recurrent neural network,RNN)、一维卷积神经网络(1D convolutional neural network,1D CNN)等[22-24]最先被引入高光谱分类领域,虽然分类结果较传统方法有很大的提升,但是这类方法在训练之前需要将高维高光谱影像处理成一维向量,导致空间、光谱结构性信息丢失。基于二维卷积神经网络(2D convolutional neural network,2D CNN)、三维卷积神经网络(3D convolutional neural network,3D CNN)[25-27]的分类算法由于可以捕捉目标丰富的高维特征,是近几年的研究热点。此外,空间特征和光谱特征的分别提取并融合的策略[28]被证明可以有效提升分类精度,成为目前基于深度学习的高光谱分类算法中主流的特征提取模块。
虽然基于深度学习的高光谱影像分类方法不断发展,分类精度不断提升,但仍存在以下问题亟待解决:1)在特征提取过程中,传统深度学习算法对于输入特征邻域内的所有像素点等权计算,特征邻域内的空间关联性和局部相似性缺乏探索,对于颜色、结构和纹理等不同类别特征进行了融合处理,缺乏对于空间尺度上不同位置特征重要性的探究;2)虽然之前算法针对高光谱影像中的空间特征和光谱特征分别进行捕捉,但是高维特征的提取往往会产生较多冗余,缺乏对特征的有效筛选;3)在特征约束的过程中,传统深度学习算法往往将时空特征融合,采用单一的特征约束方式进行损失计算,缺乏在空间、光谱不同角度进行分类结果的反馈,融合特征的全面性有待商榷。
针对上述问题,本文提出一种空间-光谱特征动态选择的高光谱影像农作物分类算法(hyperspectral images classification based on spatial-spectral dual branches and dynamic feature selection strategy,DBDS),设计了空间、光谱双分支结构,分别进行空间、光谱特征的提取,以减少2 类特征之间的相互干扰,并且在对应分支中结合空间注意力机制、通道注意力机制模块,进行更具代表性特征的筛选;利用可以进行空间特征交互的门控卷积替换传统卷积层,捕捉不同位置特征之间的差异性进行加权计算,从空间维度对有效位置特征进行筛选;从不同的特征角度,对空间、光谱特征以及联合特征进行多输出损失计算和交叉约束。
1 试验数据
1.1 WHU-HI 开源数据集
本文选取开源高光谱分类数据集WHU-HI 数据集中的Longkou、Hanchuan(http://rsidea.whu.edu.cn/resource_sharing.htm)开展试验。影像均为中国湖北省包含不同作物类型的农业区,由无人机搭载的Headwall Nano-Hyperspec 传感器获取。与星载和机载高光谱平台相比,无人机高光谱系统可以获取高空间分辨率的高光谱图像,避免由于空间分辨率不足造成的混合像元现象对分类精度的影响。
HanChuan 数据集影像由Leica Aibot X6 无人机搭载传感器在距离地面250 m 处拍摄获得,大小为1 217×303,光谱范围400~1 000 nm,划分为274 个波段,共包含16 种地物类别:草莓、豇豆、大豆、水芹菜、西瓜、高粱以及混淆地物草坪、绿地等,空间分辨率约0.109 m;LongKou 数据集由大疆DJI Matrice 600 Pro 无人机搭载传感器在距离地面500 m 处拍摄获得,影像尺寸550×400 像素,光谱范围为400~1 000 nm,划分为270 个波段,共包含9 种地物类别:玉米、棉花、芝麻、大豆、水稻以及混淆目标等,空间分辨率约0.463 m。类别具体情况如表1 所示,其中样本点数量为该数据集高光谱影像中归属于不同地物类型的像素点数。

表1 WHU-HI 数据集标签及样本数量Table 1 Number of labels and samples on WHU-HI dataset
1.2 JAAS 高光谱农作物分类数据集
为验证本文算法的稳定性,构建了一套JAAS(Jiangsu academy of agricultural sciences,江苏省农业科学院)高光谱农作物分类数据集,数据于2023 年6 月12 日在江苏省南京市六合区江苏省农业科学院蔬菜示范基地,由大疆DJI Matrice 600 Pro 无人机搭载Pika L 传感器,在距离地面100 m 处采集,航拍区域及部分数据采集对象见图1。

图1 航拍区域及部分作物Fig.1 Aerial photography area and partial crop situation
经POS 数据解析、航线数据分割边界确立、几何校正、地理配准、拼接、高光谱超立方体、辐射校正、反射率影像生成等预处理后,高光谱影像像素尺寸为1 746×1 772 像素,光谱范围为400~1 000 nm,划为150个波段,空间分辨率为0.1 m,共包含花生、苘麻、西瓜、冬瓜、苦瓜、毛豆、裸土、道路和杂草9 种地物类别。
2 模型构建
2.1 基于空间-光谱特征动态选择的高光谱农作物分类框架
基于空间-光谱特征动态选择的高光谱影像分类流程见图2。整个流程包括4 个阶段:数据预处理、空间-光谱特征联合提取、高层语义特征融合、多尺度输出约束。
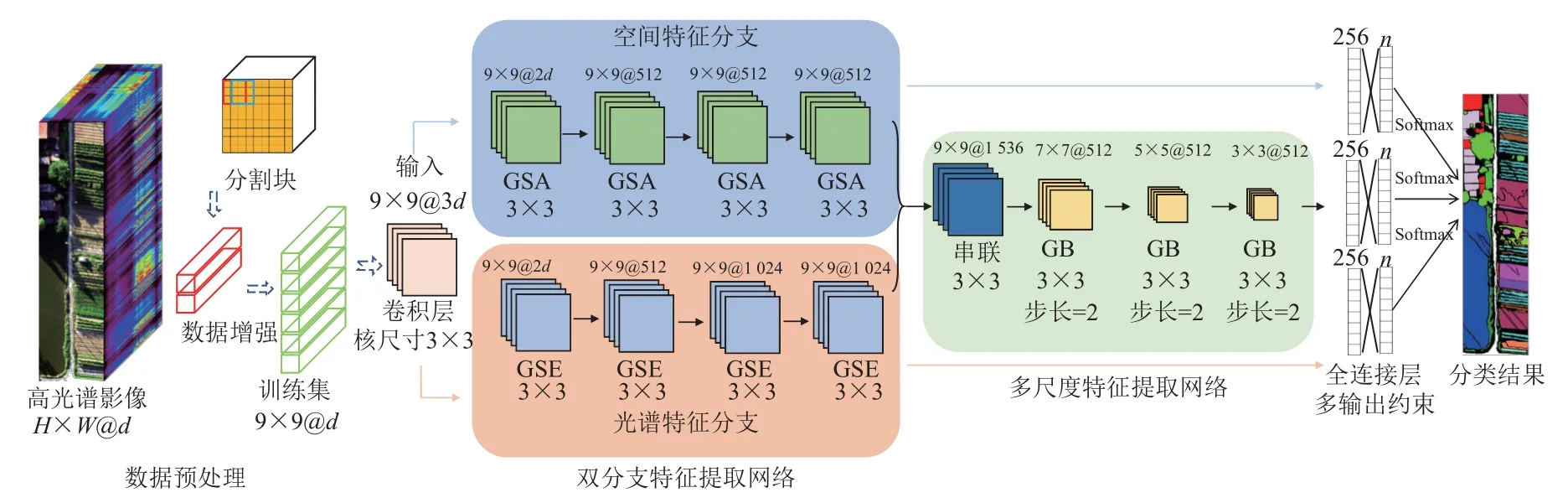
图2 基于空间-光谱特征动态选择的高光谱影像农作物分类流程Fig.2 Hyperspectral image crop classification process based on dynamic selection of spatial and spectral features
首先,由于高光谱影像数据量较大,在进行模型训练的过程中,考虑到计算机的算力性能,一般需要先进行分块操作。因此在数据预处理部分,本文首先设定好窗口大小,通过zero-padding 操作进行原始高光谱影像尺寸调整,利用滑窗完成块的分割,生成基于块的数据集(如图3 所示)。同时由于高光谱影像数据量级和覆盖范围之间相互限制,成像范围相对较小,为了防止训练过程中出现由于训练样本不够而导致的过拟合现象,对分块得到的数据进行数据增强,包括随机尺度缩放、裁剪、翻转和随机旋转等。
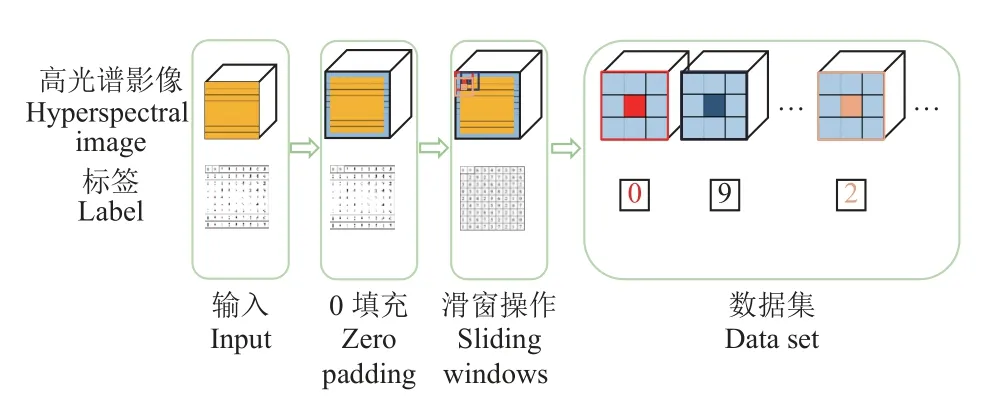
图3 高光谱影像分块操作示例Fig.3 Example of slice operation for hyperspectral images
其次,为了有效提取空间和光谱特征,避免两者之间的相互干扰,采用独立对称的双分支特征提取结构,同时进行空间和光谱的特征提取,每个分支包含4 个特征提取模块。为了提取特征的多尺度信息,设计了多尺度特征提取分支,对空间特征和光谱特征进行有效融合后,利用不同步长实现多尺度特征提取。
最后,从空间、光谱和多尺度联合特征3 个角度,利用softmax 激活函数分别进行分类结果的预测,结合categorical cross-entropy 多类交叉熵损失函数计算与标签之间的差异,实现多输出特征交叉验证和有效的反向传播训练。
2.2 空间特征动态选择策略
普通卷积层在进行特征提取时认为感受野内每个位置的像素重要性相同,进行等权重操作。但是在分类任务中,由于地物类别的差异,局部邻域每个位置的特征相似性和差异性需要考虑,当邻域内某个位置的地物类型和中心像素的地物类型差异很大时,它的特征对于最后的分类判别作用很小,因此为了防止下一层特征之间的计算干扰,给无用特征赋值一个较小的权重进行抑制是有必要的。
为了对提取到的特征进行空间上的位置筛选,本文选取门控卷积[29]替代传统卷积层,在特征提取之后,针对每个通道和空间位置,自适应学习动态特征选择机制,有效区分颜色、结构和纹理等不同种类特征的同时,抑制特征提取过程中的噪声。具体计算式如下:
式中I为输入特征,Wg和Wf分别是门控特征和图像特征所对应卷积的权重,bg和bf是相应的偏置,·表示卷积操作,⊙为特征间的逐点相乘运算。φ为sigmoid 函数,∅是类似ReLU、Leaky ReLU和ELU 等的任意激活函数,本研究选取ReLU激活函数。∅计算每个感受野内的非线性特征,φ在学习到的门控特征基础上通过Sigmoid 激活函数计算 ∅所对应的值域为[0,1]的特征位置编码信息,也就是非线性特征空间位置上的权重,∅和 φ相乘得到经过筛选的特征。
针对不同感受野内迥异的地物信息,无论是特征提取还是空间上位置权重信息的学习,该过程无需任何特征经验设计和判别,仅通过卷积层及对应的激活函数,利用网络的正馈-反馈传播机制,结合标签进行损失计算和反向传播,进行参数的学习,不断优化提取到信息的准确性及不同感受野内每个点位对于最后分类的重要性,从而自适应地实现特征的空间上的有效动态筛选。
2.3 双分支特征提取结构
针对传统深度学习高光谱分类算法提取特征冗余的问题,本文提出一种独立对称的特征提取结构,分别进行空间特征和光谱特征的学习,在每个特征提取模块中,分别加入空间注意力机制和通道注意力机制[30],同时为了探究联合特征的多尺度信息,在进行空间特征和光谱特征的有效融合后,设计了多尺度特征网络。网络结构如图4 所示。
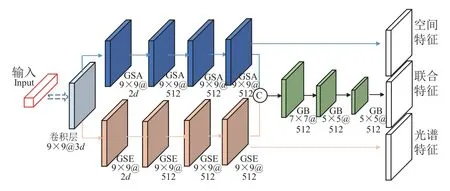
图4 双分支特征提取结构Fig.4 Double branch feature extraction structure
其中,空间特征提取分支由4 组连续堆叠的门控卷积空间特征提取模块(gated convolution block based spatial feature extraction module,GSA)构成,如图5 所示,每个GSA 模块内部由2 个门控卷积模块和一个空间注意力机制构成。空间注意力机制的引入主要为了从空间维度进行特征筛选,使得网络在特征提取过程中聚焦更有价值的局部信息,抑制无效位置信息,但是在空间注意力机制的实现过程中,空间尺寸为H×W的输入特征被列化为K×1(K为H与W的乘积)大小,邻域内像素间的空间相关性被忽略,门控卷积层则能很好地描述邻域内部的空间位置相关性进行特征筛选,有效弥补了空间注意力机制中出现的空间位置相关性模糊的问题。每个门控卷积模块由1 个卷积核大小为3×3、步长为1的门控卷积层(convolution layer)和1 个BN 层(batch normalization layer)组成。光谱特征提取分支由对称的4 组连续堆叠的门控卷积光谱特征提取模块(gated convolution block based spectral feature extraction module,GSE)构成,对应位置利用通道注意力机制进行光谱维度特征权重计算,使得光谱特征提取过程中注意力更多的集中在有意义的通道上,一定程度上抑制了无用通道的特征。多尺度特征提取分支中,在对空间特征和光谱特征利用串联层(concatenate)融合后,采用3 个由卷积核大小为3×3、步长为2 的门控卷积层和BN 层串联组成的门控卷积模块(gated convolution block,GB)进行多尺度特征的提取。
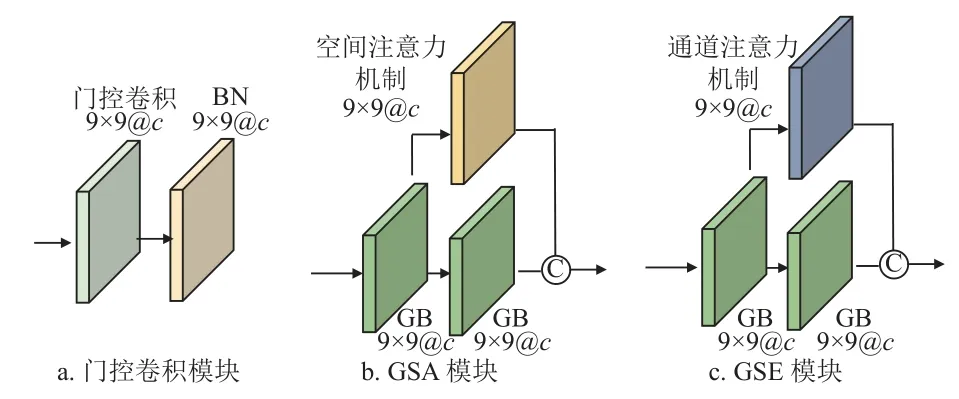
图5 特征提取模块Fig.5 Feature extraction module
2.4 多输出交叉验证约束模块
在损失计算过程中,单一的特征约束仅在网络提取的最高层特征上进行了处理,在高光谱分类任务中,高层空间语义特征和光谱语义特征中也蕴含了丰富的信息,为了防止后续多尺度特征融合后丢失部分重要信息,探究不同特征对于分类结果的影响,本文设计了多输出交叉验证模块,将空间特征分支、光谱特征分支和多尺度特征分支的高层语义特征分别输入softmax 激活函数中进行分类,结合多类交叉熵损失函数(categorical cross-entropy)纳入损失计算,参与反向传播约束(如图6 所示)。
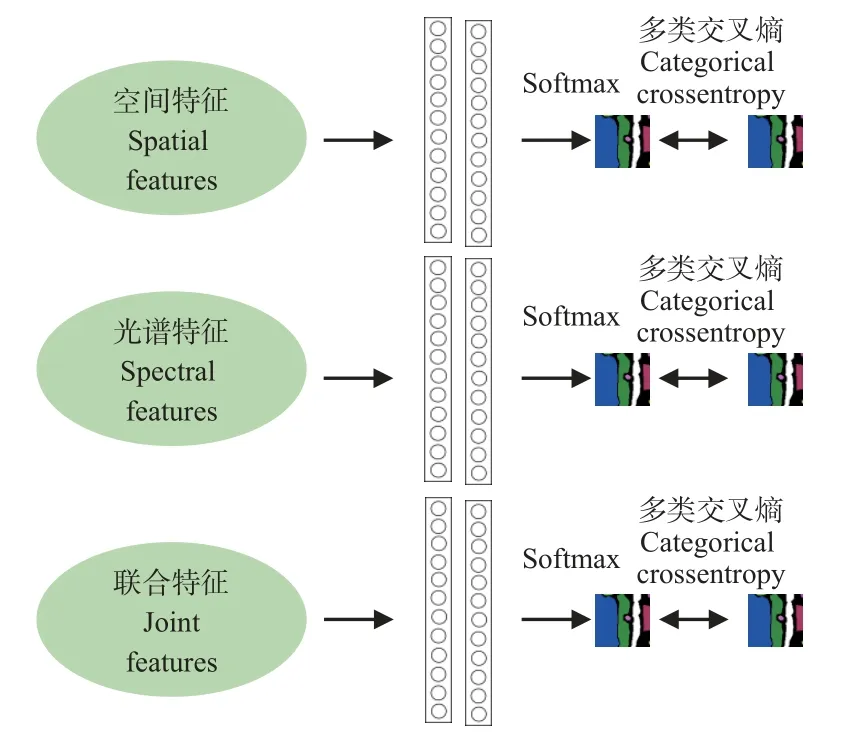
图6 多输出交叉约束模块Fig.6 Multi-output cross constraint module
2.5 模型训练
算法在Ubuntu 环境下基于python 语言和深度学习框架Keras 实现,显卡为NVIDIA tesla A100 40 G。在本文算法及对比算法的模型训练过程中,epoch 统一设置为100,batch_size 为256,经过分块操作后按照训练集:验证集:测试集=3:1:6 的比例进行试验数据的划分(如表2 所示)。测试模型选取训练过程中经过验证集交叉验证得到的最优模型。
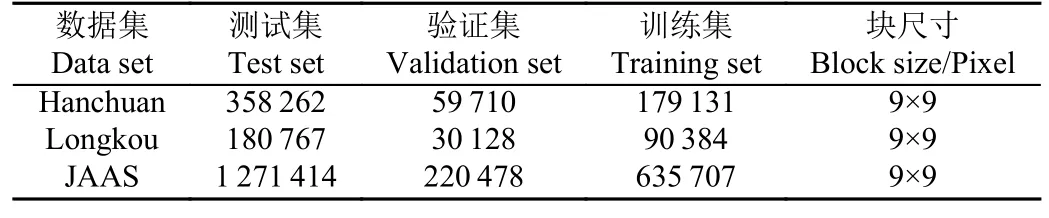
表2 试验数据分布Table 2 Distribution of experimental data
在试验结果精度评价部分,除了目视评价之外,选取准确率(precision)、召回率(recall)、f1 指数(f1-score)和总体精度(overall accuracy,OA)、Kappa 系数对分类结果进行定量评价。其中,准确率、召回率、f1 指数针对每一类地物的分类结果进行精度评价,准确率也称查准率,指分类为该类别的样本中真正为该类别的比例;召回率也称查全率,表示真正为该类别的样本中被正确分类为该类别的比例;f1 指数是综合考虑准确率和召回率的指标;OA 和Kappa 系数是从所有类别的角度进行分类精度评价的指标,验证多类别分类模型的稳定性,OA 指被正确分类的像元数占所有类别总像元的比例,Kappa 系数是基于混淆矩阵计算的分类结果一致性评价指标,同时对在测试集上测试时长进行了统计,以对比算法的效率。
对比算法选取基于二维卷积神经网络的高光谱分类算法CDCNN[31]、DCNN[32]、WCRN[33]以及基于三维卷积神经网络的高光谱分类算法DBDA[28]。
3 结果与分析
3.1 WHU-Hi-Hanchuan 数据集试验结果与分析
表3 给出了基于深度学习的不同高光谱分类算法在WHU-Hi-Hanchuan 数据集上的定量评价结果。WCRN与CDCNN 由于仅利用连续堆叠的卷积层捕捉高光谱影像的空间特征及局部高层语义特征,缺乏对不同层级特征的有效利用,对于光照阴影扭曲的地物信息识别困难,精度较低,OA 和Kappa 系数分别为96.38%、95.77%和97.86%、97.50%;DBDA 综合利用3D 卷积层和注意力机制模块实现空间-光谱联合特征的抽象提取,有效缓解了“同物异谱,异物同谱”造成的分类误差,但由于其对于空间-光谱特征进行了串联提取,缺乏有效筛选,在小样本目标的分类上仍然存在性能骤降的问题,例如西瓜、裸土(第6、13 类)等的f1 指数只有86.30%、91.07%,同时3D 卷积的引入增加了模型的计算量,使得其时间效率降低,测试集的预测时间为14 s;DCNN设计了一种双通道卷积网络,结合全局特征学习模块、多尺度特征融合模块有效捕捉融合高光谱影像中的抽象局部、非局部特征,不同样本量类别的分类结果显著提升,OA、Kappa 系数分别为98.41%、98.14%;与上述四种方法相比,本文提出的DBDS 算法具有更为优异的分类效果,在训练样本稀少的水芹菜和西瓜上,f1 指数分别可达98.91%和96.65%,其他训练样本充足的作物类别上,f1 指数达99%以上(草莓:99.60%,豇豆:99.10%,大豆:99.41%,高粱:99.71%),OA、Kappa系数分别为99.49%和99.41%,比DCNN 算法分别提升1.10%和1.29%,与利用3D 卷积层提取光谱特征的DBDA 相比,DBDS 中基于2D 卷积进行光谱特征提取的模块效果不遑多让,值得注意的是,DBDS 能够有效区分样本量稀少的复杂难区分地物,从而提高了影像的总体分类精度,证明了模型的稳健性与鲁棒性。
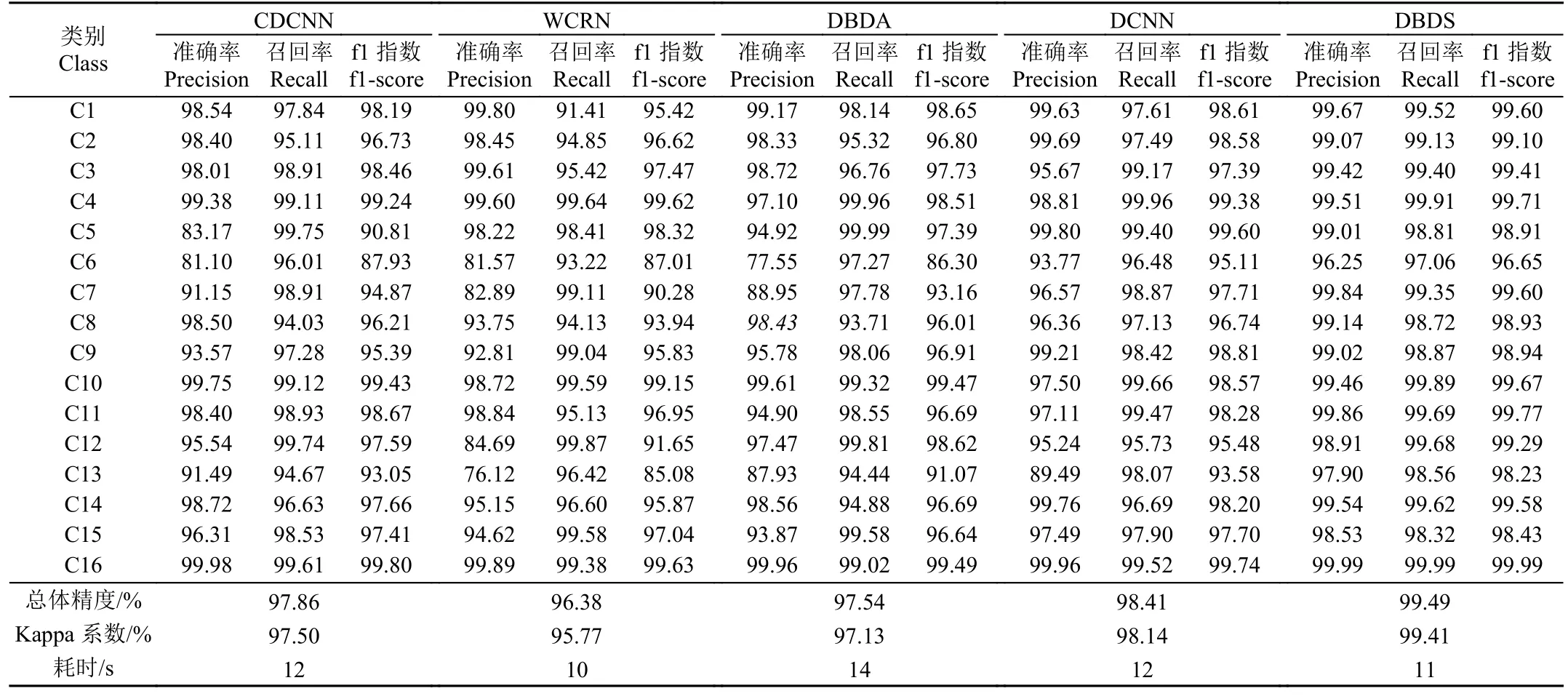
表3 不同算法在WHU-Hi-Hanchuan 数据集上的评价指标统计结果Table 3 Statistics of evaluation metrics for different algorithms on WHU-Hi-Hanchuan dataset(%)
图7 为WHU-Hi-Hanchuan 数据集上高光谱影像分类结果,直观展示了各类地物的分布信息。可以发现,CDCNN、WCRN、DBDA 的分类结果中存在明显的错分现象,DCNN 算法椒盐噪声严重,DBDS 的分类结果与真实标签最为接近,错检最少。
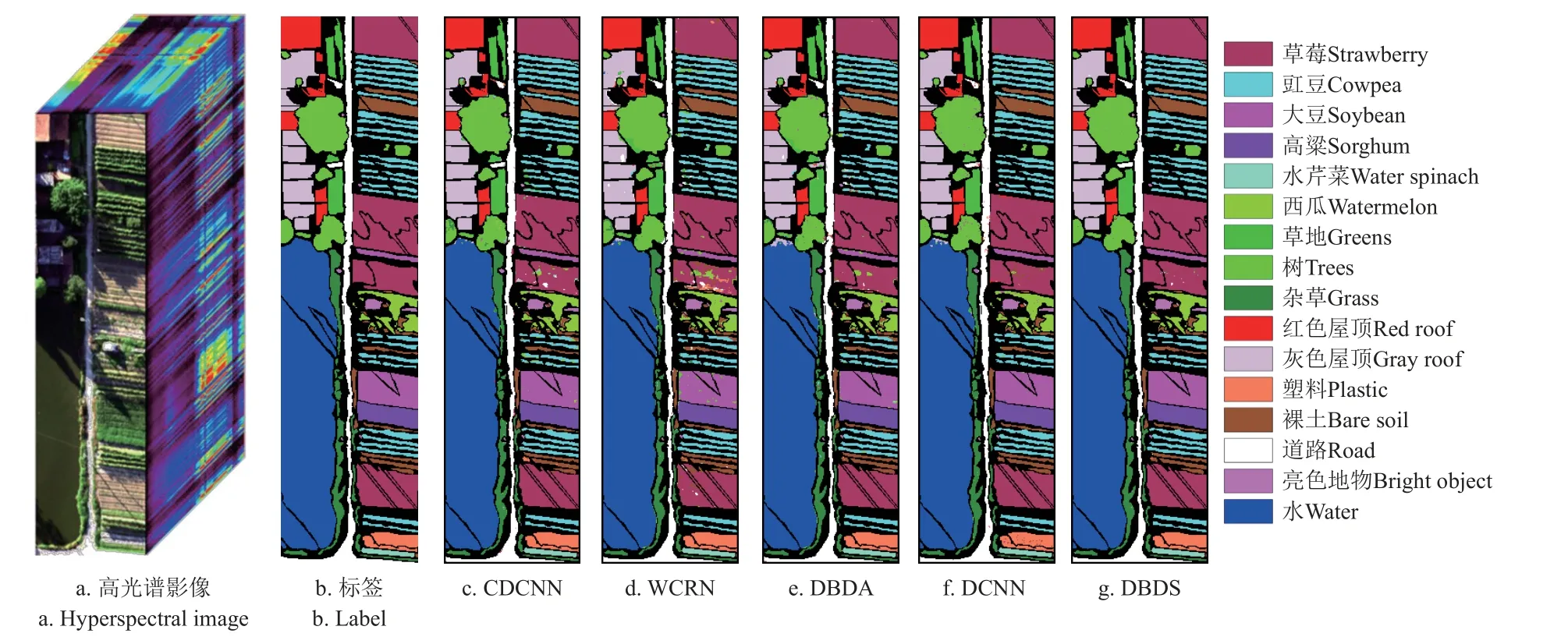
图7 不同算法在Hanchuan 数据集上的分类结果Fig.7 Classification results of different hyperspectral algorithms on Hanchuan dataset
3.2 WHU-Hi-Longkou 数据集试验结果与分析
表4 给出了在WHU-Hi-Longkou 数据集上的客观评价结果。DBDS 由于能够分别捕捉空间、光谱特征,并对高维信息进行有效筛选和融合,效果最佳,在各类地物目标的分类上均有较为优异的效果,玉米、棉花、芝麻、阔叶大豆、窄叶大豆、水稻的f1 指数可达99.94%、99.79%、99.65%、99.79%、98.55%、98.84%,总体的OA 和Kappa 系数分别为99.80%和99.74%;DCNN 注重对于全局、局部多尺度特征的有效利用,在多类地物混淆区域,能够获得较好的结果,但OA 和Kappa 系数较之DBDS 下降0.57%和0.76%;DBDA 中空间-光谱联合特征的捕捉和筛选使其分类精度尚可,但是时间效率较差,需要11 s,CDCNN 与WCRN 的效果最差,尤其是训练样本较少的窄叶大豆的分类上,f1 指数仅有90.19%和91.94%。
图8 为WHU-Hi-Longkou 数据及上的高光谱影像分类结果。
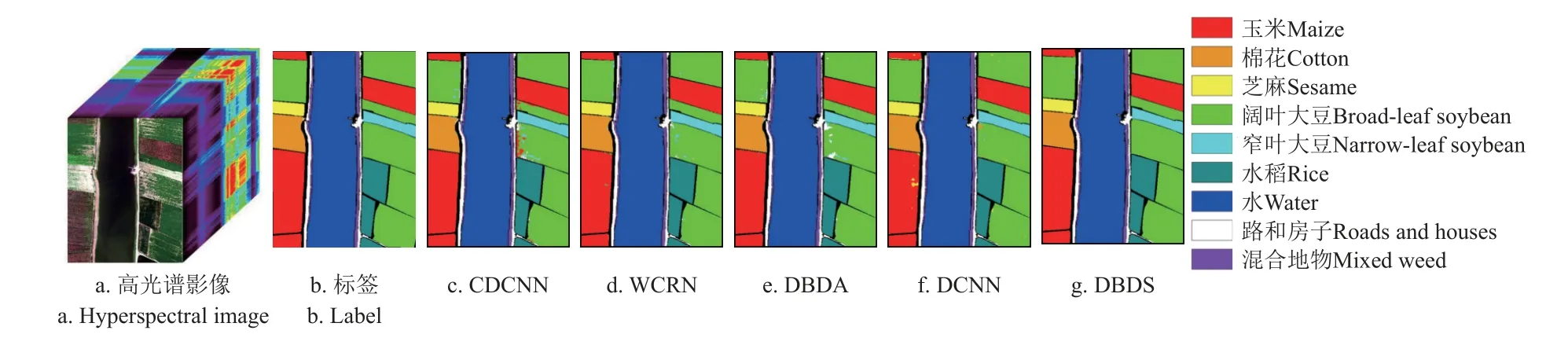
图8 不同算法在Longkou 数据集上的分类结果Fig.8 Classification results of different hyperspectral algorithms on WHU-Hi-Longkou dataset
可以发现,一味强调通过加深网络层来提取高维特征的方法CDCNN、WCRN 缺乏对于高光谱数据本质特征的有效利用,分类结果中存在较多的错分区域,DBDA与DCNN 通过不同的侧重点对于空间-光谱联合特征进行了有益的探索,分类效果明显提升,错分点明显减少,同时DCNN 中的局部/非局部特征的捕捉有效区分了复杂目标,分类边缘完整,DBDS 由于引入对于特征提取与筛选研究,效果最佳。
3.3 JAAS 数据集试验结果与分析
表5 给出了JAAS 数据集上不同算法分类结果的客观评价。由于研究范围较之前两个数据集较大,在JAAS 数据集上各算法之间的精度差异明显,WCRN 和CDCNN 在对花生的判别中,f1 指数分别只有88.65%和86.06%,WCRN 在训练样本充足的苦瓜的提取中,f1 指数仅83.29%;结合3D 卷积实现光谱维度特征补充的DBDA 效果提升明显,OA 和Kappa 较之CDCNN 分别提升了2.73%和3.40%,但是由于计算量增大,其分类时间也增加了6 s;DBDS 无论是在时间效率还是在分类精度上优势明显,OA 和Kappa 系数分别为99.35%和99.20%,且各类地物f1 指数均在98%以上。

表5 不同算法在JAAS 数据集上的评价指标统计结果Table 5 Statistics of evaluation metrics for different algorithms on JAAS dataset(%)
图9 为JAAS 数据集上各算法的分类结果图。CDCNN、WCRN 的分类结果椒盐噪声明显。

图9 不同算法在JAAS 数据集上的分类结果Fig.9 Classification results of different hyperspectral algorithms on JAAS dataset
WCRN 中冬瓜错分为西瓜的现象明显,DCNN 与DBDA 的分类结果较好,地物类型复杂区域的误分现象仍然存在,DBDS 分类结果完整,与标签数据最为接近。
3.4 网络消融试验分析
为进一步研究DBDS 中空间特征动态选择策略、双分支特征提取结构、多输出交叉验证约束模块的作用,在WHU-Hi-Hanchuan 数据集上开展消融试验。表6 给出了不同模块下高光谱分类结果的客观评价,DBDS_w/o_MO 表示在DBDS 的基础上去除多输出交叉验证模块,DBDS_w/o_gated 为整个网络仅使用普通卷积层进行特征提取的算法,DBDS_w/o_spatial、DBDS_w/o_spectral分别代表只提取光谱特征和空间特征的网络结构。
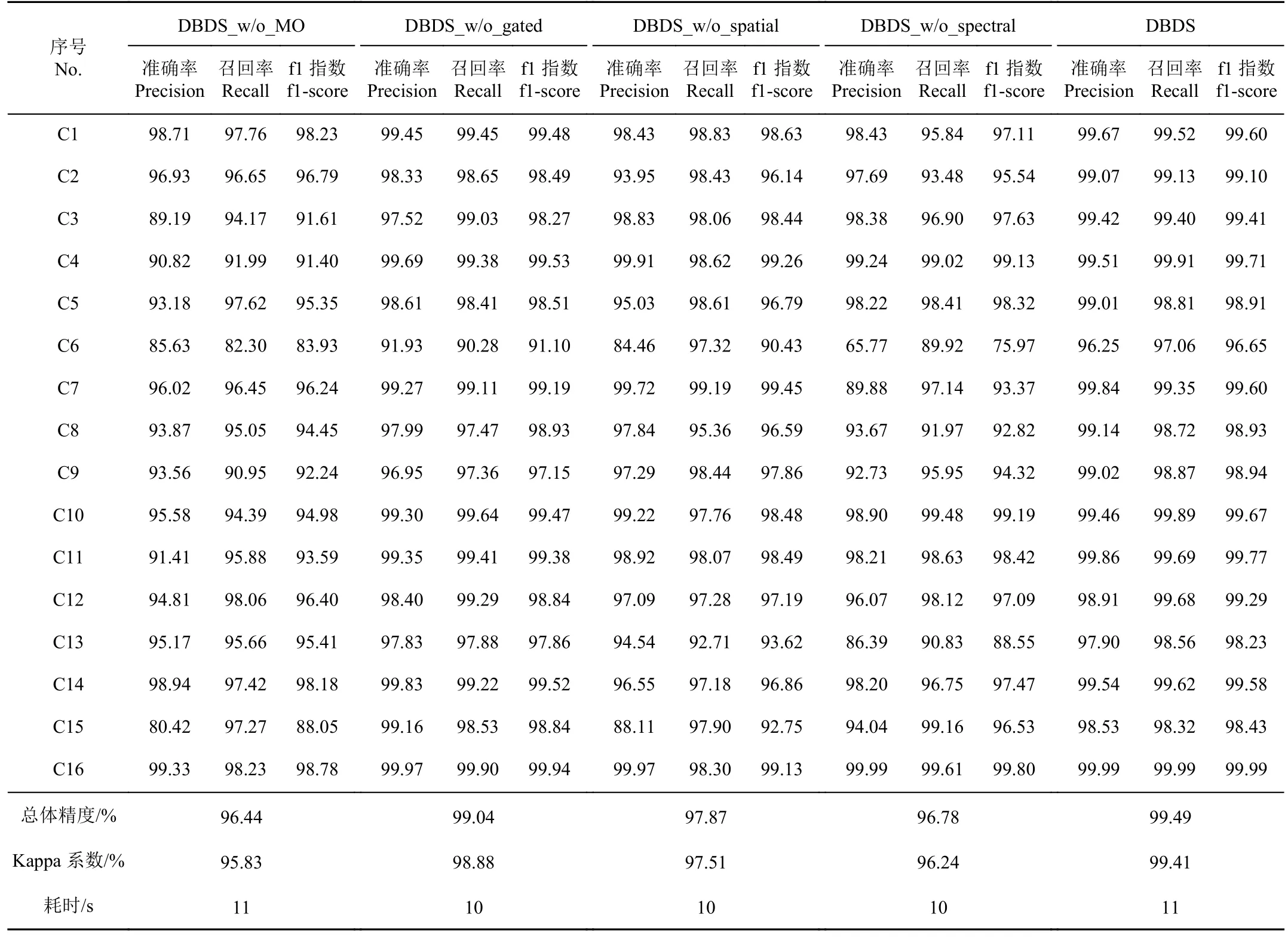
表6 不同改进的高光谱分类算法在WHU-Hi-Hanchuan 数据集上的评价指标统计结果Table 6 Statistics of evaluation metrics for different improved hyperspectral classification algorithms on WHU-Hi-Hanchuan dataset %
结果显示:1)多输出交叉验证模块通过在空间、光谱、联合结果上的有效约束,对高光谱分类任务的影响最大,在同等网络参数量级的情况下OA 和Kappa 分别提升了3.16%和3.74%;2)空间特征的有效提取对于分类任务而言也是至关重要的,对比DBDS_w/o_spatial 的结果,DBDS 的OA 和Kappa 分别有着1.66%和1.95%的提升;3)利用2D 卷积模块提取得到的光谱特征对于分类结果也有不俗的正向促进作用,对比仅着重提取高光谱数据空间特征的DBDS_w/o_spectral,DBDS 的OA和Kappa 有着2.80%、3.29%的提升;4)无论从各类地物的精度还是总体OA、Kappa 指标上来看,引入的门控卷积通过对特征的空间维度有效筛选实现了高光谱分类任务的精度提升。
图10 为不同改进的网络结构的目视评价结果。从目视效果上看,虽然每种方法均能大致将各类农作物有效区分,但多特征联合约束模块的缺失导致分类结果的椒盐噪声现象严重,门控卷积的引入可以有效缓解冗余特征造成的错分问题,空间-光谱联合特征的有效提取可以大幅提升分类精度,尤其是光谱特征。
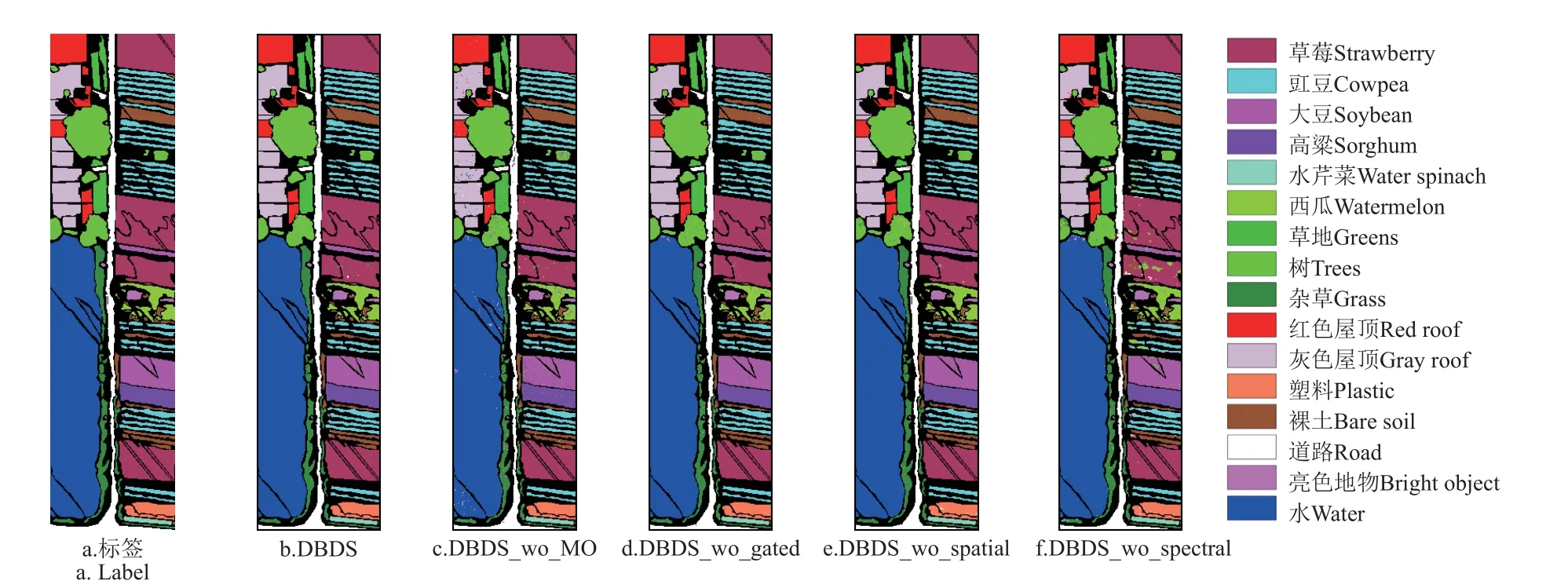
图10 不同改进网络在WHU-Hi-Hanchuan 数据集上的分类结果Fig.10 Cassification results of different improved networks on WHU-Hi-Hanchuan dataset
4 结论
为了解决传统高光谱分类算法中空间-光谱联合特征提取不够有效、冗余特征筛选能力不足、模型约束过于单一等问题,本研究设计了一种基于空间-光谱特征动态选择的高光谱影像分类算法(DBDS)。对于空间维度的特征冗余,选取门控卷积及GSA 模块中的空间注意力模块实现逐像素重要特征的筛选;门控卷积利用卷积层与不同的激活函数,分别学习感受野下的特征及其对应的位置权重信息(门信息),很好的从邻域内部空间位置相关性的角度出发进行空间特征的筛选;空间注意力机制则从特征整体的角度出发,结合最大池化和平均池化操作,逐点计算实现像素级的权重计算;两者相结合,在网络反向传播机制的基础上,不断更新卷积层及池化层中的参数,自适应学习最优解,实现特征在空间位置上的有效筛选。针对光谱维度的特征冗余,选取GSE 模块中的通道注意力模块,将特征的空间信息作为一个整体,仅关注通道维度的差异,通过计算每个通道的平均值和最大值,进行通道上特征的加权计算,增加有效特征层的权重,降低相关性较低的特征权重。整个空间-光谱特征筛选过程完全通过网络反馈的损失进行权重调整计算,无需任何人工干预,从而有效实现空间-光谱特征的动态选择。在JAAS 高光谱数据集和开源数据集WHUHi 的LongKou、HanChuan 上进行试验,得出如下结论:
1)与主流基于高光谱影像的作物分类方法相比,本文提出的DBDS 算法无论在时间效率还是精度上均有明显优势。在JAAS 数据集上,检测时间为21 s,各类作物的分类精度均在98%以上,总体精度达99.35%,Kappa 系数达 99.20%,分别比 CDCNN、WCRN、DBDA、DCNN 高4.91%和6.12%、6.82%和8.53%、2.12%和2.63%、2.04%和2.54%。
2)空间-光谱特征的有效提取及筛选较好的解决了小样本复杂难区分地物分类中模型退化的问题。在WHUHi-Hanchuan 数据集中,着重光谱信息提取的DBDA 算法在样本充足的作物分类任务中有着不错的效果,草莓、豇豆、大豆、高粱的f1 指数分别为99.60%、99.10%、99.41%、99.71%,但在小样本目标的分类上模型退化问题严重,西瓜、裸土的f1 指数仅86.30%、91.07%,通过空间和光谱特征的有效提取和利用,本文提出的DBDS 算法在有效提升各类作物的识别精度的同时,西瓜、裸土的f1 指数达96.65%和98.23%。
本文提出的DBDS 算法实现了在样本不均衡、地物类型复杂多样区域的高精度、高时效农作物精细分类,基于2D 卷积的空间-光谱特征有效提取与利用可以在较少参数计算量的基础上,达到与基于3D 卷积高光谱分类算法相媲美的精度,对于更高精度、效率的农作物精细分类研究具有一定的指导意义,也为其他基于高光谱数据的目标识别任务提供了参考。
