知识图谱技术及其在农业领域应用研究进展
2023-11-26穆维松刘天琪苗子溦冯建英
穆维松,刘天琪,苗子溦,冯建英
(中国农业大学信息与电气工程学院,北京 100083)
0 引言
知识图谱可以把复杂的知识领域通过数据挖掘、信息处理、知识计量和图形绘制显示出来,揭示知识领域的动态发展规律,为复杂问题的研究提供切实的、有价值的参考。知识图谱的构建技术已经在各个领域得到广泛应用并取得了较好的效果,如航空系统故障诊断[1]、地质灾害应急决策[2]、网络安全[3]等。随着现代信息技术的不断发展,知识图谱的规模也在进一步扩大,在智能搜索、智能问答、推荐算法等领域都得到了广泛应用[4]。在农业领域数据量积累越来越大、结构越来越复杂的大背景下,将知识图谱技术与农业相结合,可以将农业领域复杂的数据直观化,有助于对农业大数据进行深入的关联分析,解决农业领域内数据分散、多样、孤岛化、数据价值利用不高的问题。知识图谱把领域知识做了显性化沉淀和关联,利用原生图的特征支撑数据的价值挖掘与分析。
知识图谱构建关键技术是农业领域知识图谱研究的基础,农业知识图谱构建既须遵循知识图谱构建的通用技术,也须具有农业的特殊性。目前知识图谱在农业领域的应用尚不广泛,主要在农业专题文献计量研究、农业知识问答等方面,可拓展的方向仍有待挖掘,因此本文首先对知识图谱及其构建技术进行梳理,然后综述知识图谱在农业领域的应用方向,最后分析知识图谱在农业领域的研究趋势,以期为今后知识图谱在农业领域的研究方向提供参考。
1 知识图谱的构建模式
知识图谱是一种含有丰富语义信息的网络图,早在2012 年,为使搜索引擎更加精准和智能,Google 公司提出了知识图谱的概念及其含义,此后知识图谱成为了一大研究热点。知识图谱的构建模式主要有自顶向下、自底向上和自顶向下与自底向上结合3 种[5]。
自顶向下的构建模式需要先创建顶层知识库,然后从海量数据中抽取本体和实体信息,并将它们添加到最初创建的顶层知识库中。
自底向上的构建模式需要先对数据进行知识抽取,然后再将得到的实体、关系和属性经过实体对齐、语义融合、信息合并和知识加工等处理后,添加到知识图谱中[6-7]。以这两种模式构建知识图谱的流程如图1 所示。

图1 知识图谱的构建过程Fig.1 The construction process of knowledge graph
除了上述两种常用的知识图谱构建模式外,近年来有不少学者采用将二者结合的方式构建知识图谱,这种构建模式需要先在大量数据中构建出最基本的模式层,然后通过不断挖掘更有价值的知识更新模式层,最后设计模式层到数据层的映射,对实体进行填充,形成较为完整的知识图谱[8-9]。
表1 从知识图谱的构建模式、常用的应用领域、适用的数据量以及优缺点5 个方面归纳了知识图谱3 种构建模式。

表1 知识图谱构建模式的比较Table 1 Comparison of knowledge graph construction modes
2 农业知识图谱构建的关键技术
农业知识图谱的构建由于其领域的特殊性与较强的专业性常常采用自顶向下与自底向上结合的构建模式,其中涉及到的关键技术主要有本体构建、知识抽取、知识融合、知识推理和知识图谱存储及可视化,因此本文重点对这5 种技术进行综述,旨在为农业知识图谱的构建研究提供有效参考。
2.1 农业本体构建
农业知识图谱对农业知识的专业度和精确度要求较高,需要在构建知识图谱时构建抽象的模式层,因此本体的构建对于农业知识图谱尤为重要[12]。本体的构建方法主要有两种,分别是人工构建方法和使用计算机辅助的半自动构建方法,其中人工构建方法中典型的构建方法主要有Uschold 法、多伦多虚拟企业本体评价法(toronto virtual enterprise,TOVE)、集成化计算机辅助制造定义方法(integrated computer-aided manufacturing definition,IDEF)、Methontology 法,半自动构建方法中典型的构建方法主要有七步法、五步循环法和循环获取法[13]。
人工构建方法由于其构建过程存在很大的主观性,本体之间容易出现概念偏差,不完全适用于知识结构复杂的农业领域,因此在进行农业本体构建时,半自动构建方法受到了许多研究者的关注[14]。以常用的七步法为例,构建领域本体时需要经过确定领域和范围、复用现有本体、列举专业术语、定义类和类层次结构、定义属性、定义约束、创建实例7 个步骤,清晰地规范了本体的构建流程。该方法在构建花卉病虫害[15]、茶叶[16]、农村金融[17]等农业领域本体时发挥了较好的作用。此外,农业本体构建技术的发展离不开强大的构建工具,Protégé软件[18]和OWL(ontology web language)本体描述语言[19]在农业领域最受欢迎。
2.2 农业知识抽取
知识抽取指的是从大量的数据中提取有用的知识并存储到知识图谱中,是构建知识图谱的前提。知识抽取的对象主要有结构化数据、半结构化数据和非结构化数据3 种,目前研究的重点是针对结构化数据和半结构化数据进行知识抽取[20]。知识抽取主要分为实体抽取、关系抽取和属性抽取3 个方面,早期知识抽取技术发展不成熟,人们主要采用人工编写的规则将农业实体存储到数据库中来实现农业知识的抽取,但这样基于规则的抽取方法对于本体关系复杂、知识结构不统一且数据种类庞大的农业知识来说效率低下,而且要求规则的制定人员具备较高的语言学知识水平。
针对上述问题,许多学者在进行农业知识抽取时融入了机器学习和深度学习模型,它们比基于规则的知识抽取方法表现出更好的性能。基于机器学习的知识抽取最早在2008 年应用到农业中,作者使用决策树学习并建立一套有效规则,实时抽取农田的作物、气候等信息,用于预测植物的状态[21]。但这种使用机器学习模型建立的规则仍需人工决策,于是研究者们把目光转向文本本身的机器学习模型,如最大熵模型[22](max entropy model,MEM)、隐马尔可夫模型[23](hidden Markov model,HMM)、支持向量机[24](support vector machine,SVM)和条件随机场模型[25](conditional random field,CRF)。目前应用最为广泛的是综合了MEM 和HMM 优点的CRF 模型[26]。但是只使用单一的机器学习模型进行知识抽取时需要研究者根据不同的领域为数据设计不同的特征,模型的性能并不理想,因此不少学者开始将深度学习与上述模型进行结合。
BiLSTM(bidirectional long short-term memory)结合了向前和向后的LSTM,能够充分利用句子的上下文特征,提高标注的准确性,因此许多研究人员将其与CRF 模型进行结合,并在农业知识抽取领域取得了不错的成果。张海瑜等[27]使用BiLSTM-CRF 模型进行了粮食作物知识的抽取,解决了农业知识表达不规范和一物多词与多解的问题;于合龙等[28]使用BiLSTM-CRF 模型进行了水稻病虫害知识的抽取,解决了水稻病虫害知识检索的不确定性。由此可见,BiLSTM-CRF 模型较适用于结构复杂且命名难统一的农业知识提取任务;为解决知识抽取过程中长序列的语义稀释问题,程名等[29]在BiLSTM-CRF 模型的基础上融合了注意力机制,提高了渔业标准知识抽取的性能。
BiLSTM-CRF 模型对词嵌入的依赖较小,但无法表示多义词,因此部分学者开始在此基础上引入BERT(bidirectional encoder representations from transformers)模型。该模型能够将字符和句子进行预训练得到字向量,不仅包含了上下文信息,还能够很好地表征字句的含义,可以较好地解决农业文本中的一词多义问题,随后BERT-BiLSTM-CRF 模型成为了农业知识抽取领域的热门方向[30]。使用BERT-BiLSTM-CRF 模型进行农业知识抽取的流程是:首先通过BERT 获得输入语句的语义表示,生成字向量,然后通过BiLSTM 对字向量进行进一步的语义编码,最后通过CRF 输出最大概率标签序列。该模型于2020 年由吴赛赛等[31]用于作物病虫害知识抽取;任媛等[32]在该模型的基础上融合了注意力机制,实现了渔业标准定量指标知识抽取。目前,学者们将农业知识抽取的重点放在了如何更好地结合农业知识的特点上,韦紫君等[33]为解决农业实体名称较长导致的识别效果不理想的问题,在BERT-BiLSTM-CRF 模型的基础上引入实体级遮蔽策略,提高了农业知识抽取的性能;刘永波等[34]为解决茶叶语料库不完善、多源异构数据缺乏聚合能力的问题,使用全词掩码的BERT-WWM(whole word masking)替代原来的随机掩码BERT,提高了茶叶知识抽取的准确率;刘巨升等[35]提出的BERTCaBiLSTM 模型解决了水产动物疾病诊治实体嵌套问题,提高了知识抽取的质量。知识抽取技术在农业领域的发展如图2 所示。
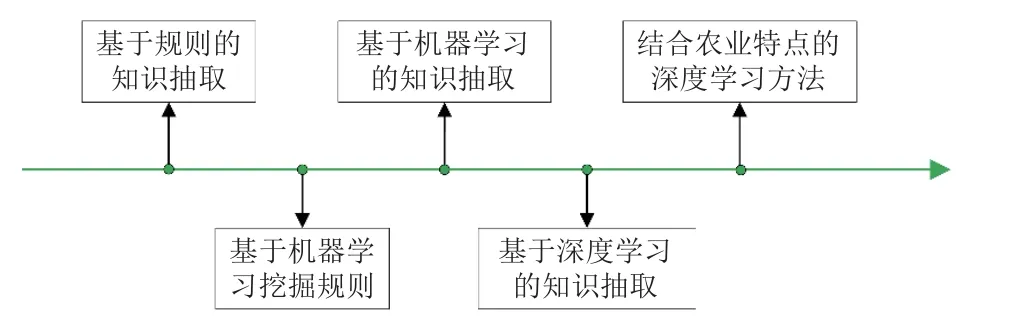
图2 知识抽取技术在农业领域的发展Fig.2 Development of knowledge extraction technology in agriculture
2.3 农业知识融合
知识融合建立在知识抽取的基础之上,指的是将不同来源、异构的数据在统一框架下进行整合,使其能够互相连通,目的是提高知识图谱的质量。由于领域的特殊性,农业知识的来源较为复杂且命名较难统一,因此存在质量参差不齐、一物多词等问题,所以对农业知识进行有机整合,判断实体的重复性是农业知识融合中的重难点。知识融合的关键技术主要有实体对齐、语义融合和信息合并3 个方面,其中实体对齐技术在农业领域的应用最广。
在农业知识融合过程中,为消除农业实体名称不一致或数据类型不同造成的冲突,早期研究者们通常会选择基于传统概率模型的对齐方法,即计算向量相似度的方法进行实体对齐研究。曹雨晴等[36]首先对不同来源的知识进行人工合并,然后再结合相似度对水稻粒型基因进行了实体对齐;陈瑞[37]使用索俊锋等[38]提出的农产品语义相似度计算方法对不同来源的网络农产品进行实体对齐。
虽然基于传统概率模型的实体对齐方法在农业知识融合中较为常见,但这类方法需要预先对大量的数据进行标记,处理大型数据时性能低下。有学者指出,实体对的匹配问题也可以转换为分类问题[39],因此在理论上机器学习和深度学习方法可以提高农业知识融合的效率。随后在其他领域,使用决策树、朴素贝叶斯、支持向量机等进行实体对齐研究的学者越来越多且取得了不错的成果[40-43]。目前使用深度学习方法中的词向量进行农业知识融合是最新的研究趋势。MOSHOU 等[44]提出一种融合词向量与语义余弦相似度的多模态农业实体对齐方法,可以将不同数据源中的实体对齐;QIN 等[45]提出一种融合TF-IDF 和余弦相似度的农业实体对齐方法,提升了农业知识检索的效率;郑泳智等[46]使用BERT 得到词向量并计算它们之间的余弦相似度,对荔枝和龙眼病虫害实体进行了对齐。但基于机器学习和深度学习的实体对齐方法往往忽略了实体之间隐含的语义特征,有时效果并不十分理想,因此不断有学者开始提出基于新技术的实体对齐方法。
知识表示学习可以将知识图谱中的实体进行低维的向量表示,然后把不同知识图谱的嵌入空间映射到同一个向量空间中,最后通过计算向量空间中实体间的距离进行实体对齐,相关技术主要有翻译模型[47]、图卷积网络[48]、图注意力网络[49]等。目前基于知识表示学习的实体对齐技术在农业领域的应用较少,因此未来农业知识融合相关的研究需要密切关注最前沿的新技术和新方法。
2.4 农业知识推理
知识推理指的是在已经抽取的实体和关系中去发现新的知识,从而丰富和扩充知识图谱。知识推理包括基于规则的知识推理、基于分布式表示特征的知识推理和基于深度学习的知识推理,起初基于规则的知识推理在农业领域中应用较为广泛,于2016 年由牟向伟等[50]应用到农业领域中,作者提出的基于描述逻辑的CC-HACCP模型,实现了农产品冷链知识推理;黄利斌[51]使用领域词汇的统计特征量化了农业词汇的相关性,并结合互信息法完成了农业语义推理;LIU 等[52]根据专家经验制定了番茄病害诊断规则库,并结合正向表示和推理模型完成了番茄病害的诊断。尽管基于规则的知识推理在农业领域中已有应用,但仍存在推理结果可解释性弱的问题,为了改进这一点,于合龙等[28]开创性地将专家置信度确定性因子CF 融合到农业知识推理中,提高了水稻病虫害诊断的确定性。
虽然知识推理技术在农业领域的应用已有一定的成效,但不可否认的是,对农业产生影响的因素较为复杂,在制定推理规则时困难较大,必要时需要考虑自然环境变化与气候对农作物的影响,若温度、光照或湿度稍有变化都可能导致推理结果出现较大的偏差,因此基于规则的知识推理只能在小范围内使用,难以进行扩展。相较之下基于分布式表示特征的知识推理和基于深度学习的知识推理更具优势,未来有望在农业知识推理这一构建环节得到广泛应用[53]。
基于分布式表示特征的知识推理主要包括翻译模型和语义匹配模型两个方面。基于翻译模型的知识推理使用基于距离的评分方法,在稀疏知识图谱上的推理结果表现较好,但这类模型往往容易忽略多跳知识,语义解释性较弱[54],最具代表性的就是基于Trans 系列的TransE[55]、TransH[56]、TransR[57]和TransD[58]模型,它们在原理上依次递进。目前,基于翻译模型的知识推理在农业领域的应用刚刚起步,于2021 年GUAN 等[59]将这一技术引入农业领域,作者使用TransR 对果树病虫害文本进行编码,提高了预测苹果树病虫害的准确率。基于语义匹配模型的知识推理使用基于相似度的评分方法,该方法通过匹配实体的潜在语义和向量空间表示中体现的关系来判断事实的合理性,语义解释性与翻译模型相比较强,但模型的复杂度较高[60],代表性模型有RESCAL[61]、DistMult[62]和HolE[63]等。
基于深度学习的知识推理可以自动获取特征,并将数据特征从原始空间映射到特征空间,进而实现知识推理,这种方法对特征较为敏感,能够很好地进行特征捕捉[64],常用的技术主要有图卷积模型[65]、循环神经网络[66](recurrent neural network,RNN)、卷积神经网络[67](convolutional neural network,CNN)、Transformer[68]等。
2.5 农业知识图谱存储及可视化
知识图谱只是对实体和关系进行了最基本的描述和存储,若要观察知识图谱中实体间的关系和变化规律则需要对知识图谱进行存储并可视化,帮助用户从不同的角度分析数据[69]。目前主流的可视化工具主要有Neo4j[70]、D3.js[71]、Gephi[72]、Echarts[73]、Cytoscape[74]、CiteSpace[75]等,其中CiteSpace 常用于农业专题文献计量研究,Neo4j在农业知识问答、农业资源推荐以及农业信息检索等方面的应用较多。
2.6 农业知识图谱构建关键技术比较
通过对农业知识图谱构建技术的梳理可以发现,本体构建和知识抽取在农业领域的研究较多且技术先进,而农业知识融合与农业知识推理环节的技术研究没有得到足够的重视,导致这两方面的技术发展缺乏创新性。随着农业知识量的增长,农业知识图谱也在不断膨胀,未来农业数据会更加复杂,如何发展农业知识图谱的构建技术以提升构建效率将会是该领域的一大挑战。本文将农业知识图谱构建过程中使用的关键技术及其未来的可发展方向总结如表2 所示。
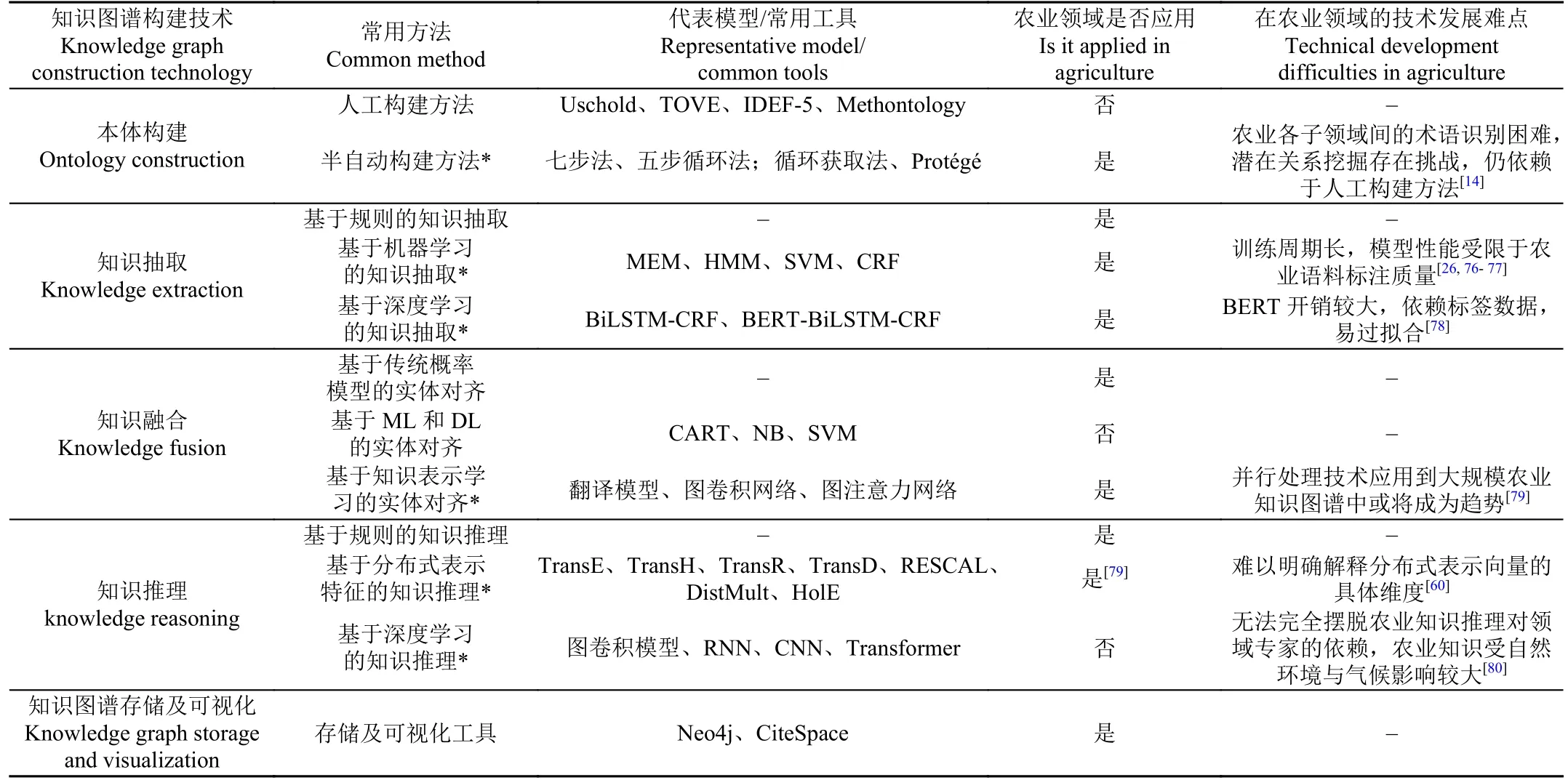
表2 农业知识图谱构建关键技术及其发展难点Table 2 Key technologies and development difficulties of agricultural knowledge graph
3 知识图谱在农业领域的应用
知识图谱在电商产品推荐、图书情报和搜索引擎等领域得到了广泛应用,但在农业领域的研究相对滞后,现有研究主要集中于农业专题文献计量研究、农业信息检索、农业知识问答和农业信息资源推荐4 个方面,如图3 所示。
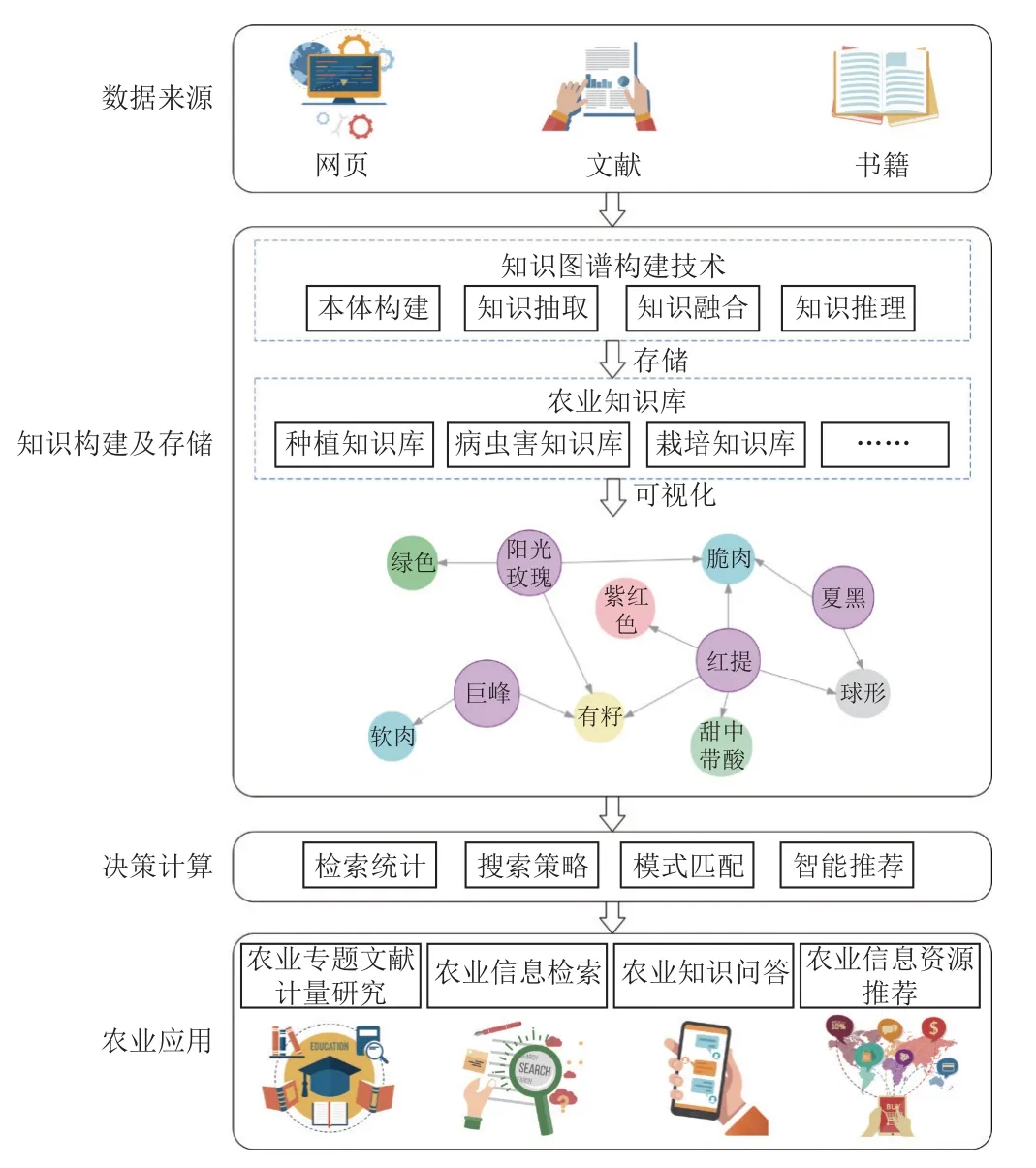
图3 知识图谱在农业领域的应用Fig.3 Application of knowledge graph in agriculture
3.1 农业专题文献计量研究
在知识图谱最初兴起之时,学者们专注于将知识图谱作为分析农业专题文献的工具,用它来发现农业领域的研究主题和技术热点,便于为农业发展方向的实践和探索提供参考和指导意见。周丽霞[81]用CiteSpace 对CSSCI 数据库中与农业规模经营领域的发展历史相关的文献进行了分析并发现,适度规模经营有助于农业持续发展,谁来经营、经营多少以及如何实现是农业规模经营领域的三大要点。林伟君等[82]使用CiteSpace 对中国知网数据库中与智慧农业相关的文献进行分析,发现我国智慧农业的前沿研究热点是无线传感器网络、互联网+以及物联网等,这些技术已经应用到病虫害防控、农业遥感等领域。SONG 等[83]使用CiteSpace 对Web of Science数据库中与农业电子商务研究现状相关的文献进行了分析,认为农业电子商务的模式和用户满意度在农业电子商务未来的研究中需要重视。在农业专题文献计量分析中,CiteSpace 常被用来实现学科领域的共现分析,梳理领域发展态势。
3.2 农业信息检索
随着知识图谱构建技术的不断进步,以信息搜索为主的普惠型信息服务开始逐渐面向农业经营主体,包括农业信息检索、农业知识问答、农业信息资源推荐等。使用知识图谱构建的农业领域信息检索系统可以将农业知识规范化,避免知识零散和歧义带来的问题。早期的农业信息检索研究严重依赖于人工数据标注,现在则多采用深度学习方法识别农业实体,如张海瑜等[27]提出一种基于语义知识图谱的农业知识智能检索方法,首先人工构建农业本体,然后使用BiLSTM-CRF 模型抽取农作物别名,最后使用Neo4j 进行知识存储,实现了农业知识的规范分类,解决了农业知识一物多词的问题;于婷婷[84]为实现农作物信息的存储检索设计了农作物知识图谱,作者首先实现了从农业科学叙词表到农作物本体的转换,然后使用BERT-BiLSTM-CRF 模型进行农作物知识抽取,最后用Neo4j 进行知识存储;沈利言[85]为提高水稻栽培技术的传播效率构建了水稻栽培方案知识图谱,作者首先参考多种数据来源人工构建了草莓知识本体,然后融合注意力机制和BiLSTM 模型进行知识抽取,最后用Neo4j 图数据库存储水稻知识图谱并实现了可视化水稻栽培方案检索。
3.3 农业知识问答
使用知识图谱技术构建面向具体农业任务的问答系统有助于帮助农户快速、精准地解决某些领域内的专业问题。最初农业知识问答系统通过计算实体相似度实现,需要匹配大量的农业知识问答库,效率较低。现在随着知识融合与知识推理技术在农业中的不断发展,农业知识问答系统具有了一定的扩展能力。李岩[86]首先使用Protégé工具构建了禽畜疾病防治本体,然后使用基于规则的知识抽取方法从网页中人工抽取知识并使用Neo4j对知识进行存储,最后设计并实现了禽畜疾病领域问答系统使用,为禽畜疾病的重要技术提供了支撑;周子豪[87]提出了一种实体关系联合抽取模型BERT-LCM-Tea 用于进行茶叶知识抽取,解决了茶叶实体间关系重叠问题,然后作者又提出了CBOW-TransE 模型用于茶叶知识融合,最后使用Neo4j 存储茶叶知识,实现了茶叶知识问答系统,该系统能够帮助茶农梳理茶叶种植和培育的专业知识,为制茶企业提供辅助决策。王宇航等[76]将文本转换为字符和词对的序列,在此基础上改进了BERTBiLSTM-CRF 模型并进行农业知识抽取,然后用Neo4j存储,实现了农业自动问答系统,该系统能够高效高质量地整合农业知识应用。在农业知识问答中,知识抽取作为构建知识图谱必不可少的步骤在该应用领域最为常用,Neo4j 图数据库由于其查询高效的优势常被用作存储知识。
3.4 农业信息资源推荐
基于知识图谱进行农业领域的信息资源推荐可以有效筛选冗余信息,为用户快速推荐符合其个性化需求的产品。最初的农业信息资源推荐以分析语义为主,如郭伟光[69]针对用户难以快速找到其偏好农产品的问题设计了农产品推荐系统,作者首先使用Protégé工具构建了农产品本体,然后经过语义查询和分析为用户推荐其感兴趣的农产品。后来随着基于知识图谱的个性化推荐算法的发展,学者们开始根据用户的个性化需求、偏好和个人特征为其进行推荐,如孙琳[88]针对农户搜寻有效信息效率底下的问题设计了基于知识图谱的农业在线信息资源推荐系统,使用融合注意力机制的BiLSTM 模型抽取非结构化农业知识,并将用户对知识图谱中实体的偏好程度融合到推荐算法中,实现农业信息的个性化推荐;戈为溪等[89]首先使用PairRE 模型获取实体和关系的向量表示,然后通过知识推理得到具体的施肥方案,最后根据相似的方案为农户推荐精确的施肥量。
3.5 知识图谱在农业领域应用的比较
知识图谱在农业领域应用的比较如表3 所示,可以看出,本体构建、知识抽取和知识图谱存储及可视化技术最为常用,但知识融合、知识推理在农业应用领域使用较少,这表明农业知识图谱在构建过程中不够规范、完整,因此农业知识图谱应结合农业知识特点重点关注构建技术的发展与创新。
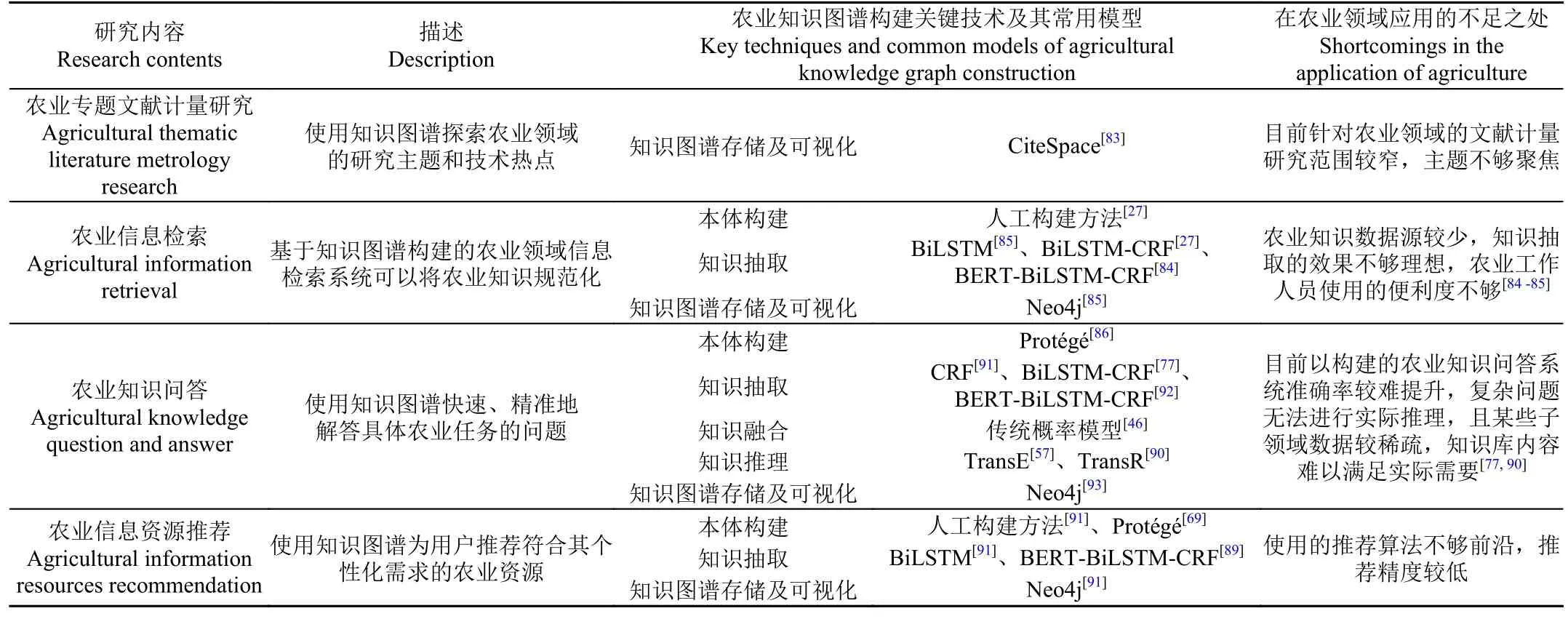
表3 知识图谱在农业领域应用的比较Table 3 Comparison of knowledge graph applications in agriculture
4 结论与展望
4.1 结论
本文通过梳理知识图谱技术在农业领域的应用研究进展,总结了知识图谱的构建模式、农业知识图谱构建的核心技术的发展过程、现状和局限性,并综述了当前知识图谱在农业领域的应用场景。主要结论如下:
1)在农业知识图谱的构建技术中,知识抽取技术已经发展较为成熟,以BERT-BiLSTM-CRF 为代表的模型得到了广泛应用,然而知识融合与知识推理在农业知识图谱的构建过程中缺乏重视,使用的方法较为落后。随着农业知识数据量的增长,未来的农业数据会更加复杂,为了提升农业知识图谱构建的效率,在农业知识融合阶段可以参考知识表示学习方法,丰富农业实体之间隐含的语义特征;在农业知识推理阶段可以参考基于分布式表示特征的方法和基于深度学习的方法,挖掘隐藏的农业实体间的关系。
2)目前知识图谱在农业领域的应用场景主要集中于农业专题文献计量研究、农业知识问答、农业信息资源推荐和农业信息检索等方面,但知识图谱在这些场景中的应用仍存在一些不足,表现为:农业专题文献计量研究的范围较窄,无法从多个数据源同时获取信息;农业信息检索的效果不够理想,对于农业工作人员来说使用的便利度不够;农业知识问答无法对复杂问题进行实际推理,难以满足实际需要;农业信息资源推荐使用的算法较为落后,推荐精度较低。这些实际应用上的缺陷仍需改进,知识图谱技术在农业领域的应用还有很大发展空间。
4.2 展望
知识图谱中包含的信息形式多样且多源异构,含有丰富的语义关系,将知识图谱相关技术应用于农业领域,有助于更深入地挖掘和表示农业领域的知识关联和规律。结合知识图谱技术的发展趋势、目前知识图谱农业应用的不足和未来农业发展对知识图谱技术的要求,本文认为未来应关注以下几方面的研究。
1)基于知识图谱的农产品电商推荐
目前,推荐算法已经在各类电商平台广泛应用,但这些推荐算法大多基于用户的浏览、购买等历史记录进行相似性推荐,面临用户-物品评分矩阵稀疏性和冷启动等问题,导致推荐结果不准确,为解决上述问题,研究者们尝试将知识图谱作为辅助信息融入到传统推荐算法中从而提升算法的性能,知识图谱可以在不受用户-物品评分矩阵稀疏性影响的同时,为传统推荐算法的结果提供可解释性。
但当考虑将基于知识图谱的推荐算法应用于农产品电商推荐时,难度仍然较大。目前针对农产品知识图谱的研究较为匮乏,农产品的品种较为多样且特征区分度不够明显,许多新品种对于多数消费者来说更是闻所未闻,直接将推荐算法用于农产品推荐难以满足农业工作者的需求。电商农产品知识图谱构建中的实体和关系抽取都需要考虑农产品的特殊性,电商农产品推荐算法的精准性也会是研究的难点。
2)动态农业知识图谱的构建
知识图谱中的实体和关系在现实世界中具有时效性,构建动态的知识图谱有利于根据真实环境的变化实时更新知识挖掘的结果,实现更为精准的推荐或检索。动态农业知识图谱可以为农户提供最新的技术和相关信息,有助于农户和农业相关技术人员对农业任务进行及时调整。但是构建动态农业知识图谱的过程中必须考虑到农业实体的特殊性,在这类知识图谱中不仅知识是变化的,甚至节点的数量也会根据实际情况(如农作物不同生长期等)有所变化,因此时序动态知识表示学习相关算法如何去适应农业实体特点将会是构建动态农业知识图谱的一大挑战。
3)跨领域知识图谱的构建与关联
目前知识图谱在构建过程中往往抽取的是同一领域中的实体信息,如何实现跨领域、跨来源的实体抽取成为了一大难题。构建农业范围内的跨领域知识图谱可以将育种、种植、浇灌、病虫害防治、物流、销售等过程融合在一起,避免单一领域知识图谱的局限性,考虑不同流程之间的影响和相互关系,实现多维度的推荐和检索任务,提供更全面的推荐和检索结果。但是目前跨领域知识图谱的研究尚未成熟,如何应用到农业领域也是将来一个较大的挑战。
