基于改进YOLO-Pose 的复杂环境下拖拉机驾驶员关键点检测
2023-11-26徐红梅李亚林张文杰赵亚兵
徐红梅,杨 浩,李亚林,张文杰,赵亚兵,吴 擎
(1. 华中农业大学工学院,武汉 430070;2. 农业农村部长江中下游农业装备重点实验室,武汉 430070)
0 引言
目前,中国农业发展模式已逐步由细碎化的小田种植过渡到大规模、机械化的大田作业形式,且随着更多强农惠农政策的出台,大量的拖拉机投入到农业生产中。由于拖拉机作业频次高、强度大、范围广,致使基层一线农业安全生产形势严峻,安全监督管理亟待加强。复杂的作业环境、机械整体性能趋于老化以及驾驶员操作不规范、疲劳驾驶等原因使得拖拉机作业存在较大的安全隐患。据统计,2021 年全国累计农机事故220 起,死亡46 人,受伤76 人,直接经济损失达499.6 万元[1],受制于农机化监管机构职责有限,难以有效应对拖拉机安全生产管理中的种种挑战,严重影响农民的生命与财产安全。为此,开发针对农机作业人员的智能驾驶辅助系统,有助于提升驾驶员的自我保护意识,进一步减轻或避免农机生产中的安全隐患。驾驶员的驾驶姿态和操纵行为对行车安全具有重要影响,驾驶员骨骼关键点检测是进行姿态识别、异常行为分析的前提,是实现智能安全驾驶的关键技术[2],它不仅为驾驶员行为识别提供了理论依据,也为驾驶员状态跟踪与安全监测提供了一定的参考。
传统的人体姿态估计方法通过建立人体模型或手工设计特征来设计人体部件检测器,该方法受图像背景、光照、遮挡等的影响较大,并且对于多维特征的选择主观性较强,不能很好地适应人体部件的复杂性和环境的变化,具有较大的局限性[3-4]。而基于深度学习的检测方法通过构建强表征能力的神经网络来获取丰富的图像特征信息,具有优秀的非线性映射特性和强大的自学习能力,摆脱了对模型结构设计的依赖,已成为当前人体姿态估计的主流方法。
目前国内外基于深度学习的人体姿态估计方法已取得较大进展。NEWELL 等[5]提出了一种基于编码器和解码器的堆叠沙漏型卷积神经网络SHN(stacked hourglass networks),通过端到端的堆叠多个沙漏结构,有效地捕获和整合跨尺度信息,提高了单个关键点的检测精度。SUN 等[6]提出了一种高分辨率网络HRNet,通过并行连接多个不同分辨率的子网络,重复地执行多尺度融合策略,确保模型在每个分支都具有高分辨率特征,预测得到的热图在空间上更准确。CHENG 等[7]在高分辨率网络HRNet 的基础上提出了HigherHRNet 网络,在训练和推理阶段分别采用多分辨率监督和热图聚合策略,有效地解决了多人姿态估计中的尺度变化问题,提高了小目标的检测效果。YANG 等[8]针对多分辨率融合时不能有效地结合全局上下文信息,导致特征丢失的问题,提出了TransPose 网络,通过融入基于自注意力机制和多层感知器的Transformer 编码层迭代地从序列中捕获依赖项,有效地确定人体各部位之间的空间关系。XU 等[9]提出了一种纯Transformer 架构的人体姿态估计网络ViTPose,该网络采用普通和非分层的Vision Transformer 作为主干进行特征提取,最后通过一个轻量级解码器对特征图进行上采样并对热图进行回归来预测关键点,ViTPose 在MS COCO 数据集上获得了80.9%平均准确率的SOTA性能。
通用的人体姿态估计研究已取得较大进展,但针对车载用途尤其是拖拉机驾驶员的姿态估计却鲜有研究。CHUN[10]等提出了一种新型卷积神经网络架构NADSNet,采用具有多个检测头的特征金字塔网络FPN 实现驾驶员和前排乘客的姿态估计和安全带检测。BORGHI[11]等设计了名为POSEidon 的回归神经网络,其由三个独立的卷积层和一个融合层,用于深度图像中驾驶员头部和肩部的姿态估计。YUEN[12]等在OpenPose 模型的基础上,引入了一种快速卷积神经网络方法,用于全身关节估计,该方法可在多个驾驶员和乘客上以40 帧/s 的速度实时运行真实数据。拖拉机驾驶员姿态估计与汽车驾驶员姿态估计存在较大差异:拖拉机驾驶室四面多为双向透视玻璃[13],光照以及复杂背景的干扰易造成目标缺失和关键点的误检;其次,驾驶员灵活多变的肢体动作不仅增加各关节点之间分布的差异性和复杂度,也会由于关节点的自遮挡现象导致部分关节点特征信息缺失;操纵杆、踏板等部件的遮挡会损失图片中人体部分关节点特征信息,破坏各关节之间的关联关系,增加各个关节点在图片分布中的差异性。
综上所述,为解决农业作业下拖拉机驾驶员因外部环境及操纵过程中肢体自遮挡、他物遮挡所造成的关键点漏检、误检现象,提高复杂场景下拖拉机驾驶员关键点检测精度,本研究基于Swin Transformer 编码器、坐标注意力机制以及融合金字塔卷积的高效聚合网络RepGFPN 提出了一种基于改进YOLO-Pose 的拖拉机驾驶员-关键点联合检测方法,拟为驾驶员异常行为分析以及状态监测提供参考。
1 试验数据
1.1 数据采集与数据集
样本数据采集于华中农业大学工科试验基地,试验拖拉机型号为东方红LX804,为体现数据集的多样性,充分考虑实际检测时的复杂场景,分别选取大、中、小三种体型驾驶员为试验对象,采用尼康Z5 微单相机以图像格式采集数据,为增加数据集鲁棒性,分别选取早晨、下午、傍晚等各个正常耕作时间段,包括晴天、阴天、顺光、逆光等自然条件,拍摄多种操纵姿态以及具有多种遮挡情况的1 100 幅驾驶员图像作为样本数据集,分辨率统一为640×640(像素),保存为JPG 图像格式,并以8:2 的比例划分训练集和验证集。
本研究采用轻量级的图形标注软件Labelme 标注驾驶员姿态关键点,标注格式采用COCO 格式,共标注17 个人体关键点,分别为:鼻子、左眼、右眼、左耳、右耳、左肩、右肩、左肘、右肘、左手腕、右手腕、左臀、右臀、左膝、右膝、左脚踝、右脚踝,标签中每个keypoint 表示1 个关键点坐标,其由长度为3 的数组(x,y,v)表示,其中:x和y表示关键点的坐标值;v表示标识符,取值为0、1 和2,当v=0 时,表示图像中没有该关键点;v=1 时,表示该关键点存在,但是被遮挡;v=2 时,表示该关键点在图像中存在并可见。每幅图像需框选驾驶员主体并标注该个体对应的17 个关键点,关键点标注样例如图1 所示。

图1 驾驶员骨骼关键点标注样例Fig.1 Annotation example of keypoints of driver’s skeleton
1.2 数据增强
为提升模型鲁棒性及泛化能力,避免过拟合现象,本研究采用多种在线数据增强方式,具体包括:随机裁剪、随机翻转、HSV 色域变换、Mosaic 以及Mixup 增强方式。其中,随机裁剪表示将原图按一定概率进行随机裁剪;随机翻转表示对原图沿边缘水平或垂直方向按一定概率随机翻转;HSV 色域变换表示对原图色调、饱和度以及亮度进行随机调整;Mosaic 增强方式通过随机选择四幅图像进行随机裁剪,并拼接成一幅新图像;Mixup 表示将随机的两幅图像按一定比例混合。各图像增强效果示意图如图2 所示。

图2 各图像增强效果示意图Fig.2 Diagram of each image enhancement effect
2 驾驶员姿态关键点检测方法
2.1 YOLO-Pose 关键点检测算法
现有的关键点检测方法主要分为自顶向下和自底向上两类[14]。两阶段的自顶向下方法需预先构建人体检测器,再分别对单个个体进行2D 姿态估计,其复杂的网络结构使得模型无法满足实时要求。而自底向上的方法虽然提供了恒定的运行时间,但其需要额外的后处理来提升检测性能。
YOLO-Pose[15]网络的整体架构如图3 所示,其基于YOLOv5 目标检测算法,采用CSPDarkNet53 作为主干网络,PANet 作为颈部融合多尺度特征,其将Anchor 与姿态关键点相关联,一个Anchor 匹配一个目标,每个Anchor 囊括人体边界框以及2D 姿态信息,每个检测头包含两个解耦头分别用于边界框定位和关键点回归,目标边界框由{Cx,Cy,W,H,bconf,cconf}6 个元素确定,其中,Cx、Cy分别为边界框中心点横、纵坐标;W、H分别为边界框宽和高;bconf,cconf分别为边界框置信度和预测类别置信度。每个关键点由{x,y,c}3 个元素确定,其中,x、y和c分别表示关键点位置及类别置信度,对于每一个Anchor,将会关联人体17 个关键点的51 个元素和边界框6 个元素,故总体所需预测元素Pv定义为:
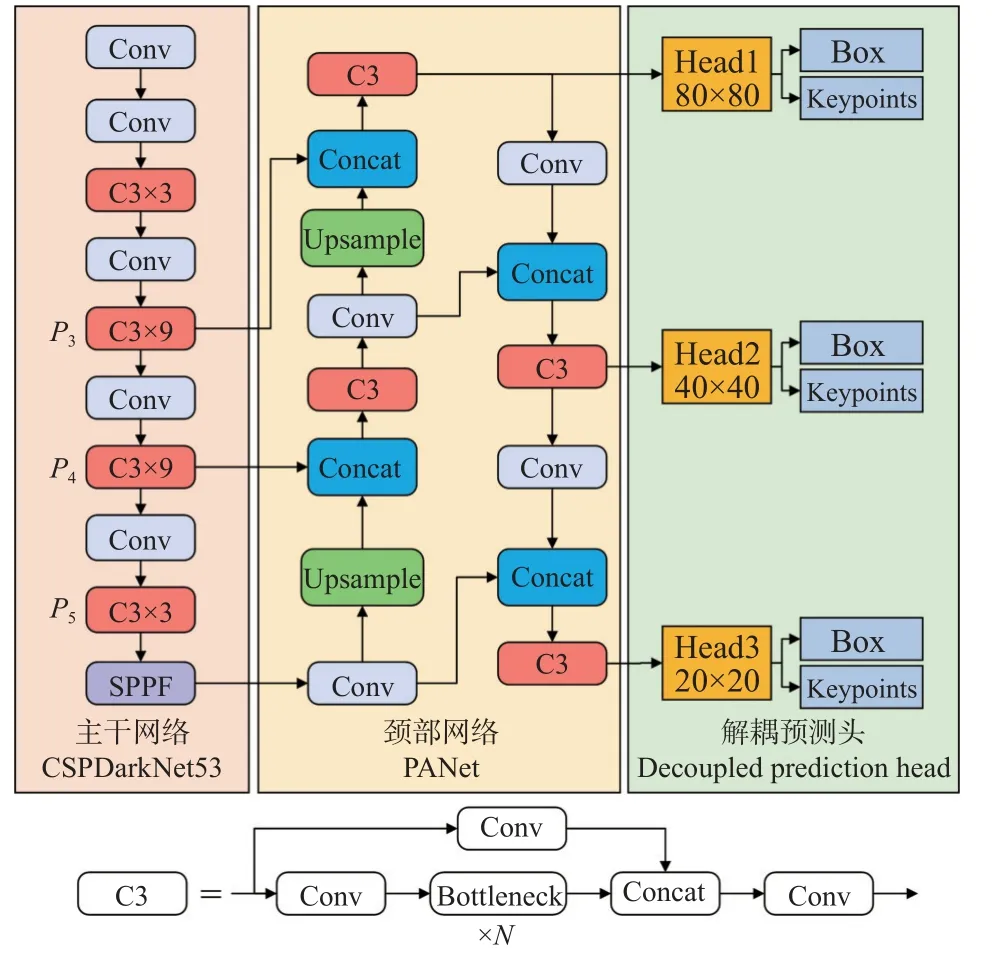
图3 YOLO-Pose 关键点检测网络Fig.3 YOLO-Pose keypoint detection network
在损失计算方面,YOLO-Pose 采用具有尺度不变性的目标关键点相似度Loks(object keypoint similarity)损失取代传统L1 损失来检测关键点,通过将IOU 损失的概念从边界框迁移至关键点,在构建损失函数的同时优化了指标本身,进一步提升了模型性能。Loks损失计算公式如下:
式中Nkpts表示关键点总数;dn表示第n个关键点的预测位置与真实位置间的欧式距离;kn表示第n个关键点的归一化因子;s表示当前目标的尺度因子;k表示与真实标注框匹配的锚框序号;i和j分别表示真实标注框中心点的横、纵坐标;vn表示第n个关键点是否可见;δ为冲激函数,表示只计算真实标注中可见关键点的Loks值。
关键点置信度损失为
式中LBCE表示二值交叉熵损失函数,通过二分类确定目标个体的关键点是否存在;表示第n个关键点的预测置信度。
总损失为
式中Lcls表示分类损失;Lbox表示边界框回归损失;λcls=0.5,λbox=0.05,λkpts=0.1,λkpts_conf=0.5,以上超参数的选择主要用于平衡不同尺度上的损失。
YOLO-Pose 关键点检测算法是一种基于无高斯热图的联合检测方法,利用端到端的思想,去除多个前向传播过程且无需复杂的后处理环节,一次性实现了目标检测与姿态估计任务。
2.2 改进YOLO-Pose 关键点检测模型
为解决农田作业环境下拖拉机驾驶员由于光照、背景以及遮挡导致的关键点漏检、误检和检测精度低等问题,本研究以具有四分支特征输出的YOLOv5s6-Pose 网络为基础模型,提出了一种融合Swin Transformer 编码器、高效层聚合网络、金字塔卷积以及坐标注意力机制的YOLO-Pose 驾驶员关键点检测算法。具体改进如下:1)在主干网络P6 层的C3 模块嵌入Swin Transformer 编码器,通过构建C3ST 模块显式地捕获各关键点之间的空间依赖关系,有效地挖掘全局上下文信息,解决由于不断下采样造成的特征缺失问题。2)采用嵌入金字塔卷积的高效层聚合网络RepGFPN 作为颈部,实现高层与底层信息的高效交互,并添加P6 输出分支,以适应不同尺度目标的检测。3)在关键点解耦头中嵌入坐标注意力机制,通过将位置信息编码到通道注意力中,增强网络对关键点位置的捕获能力。改进后的网络结构如图4 所示。
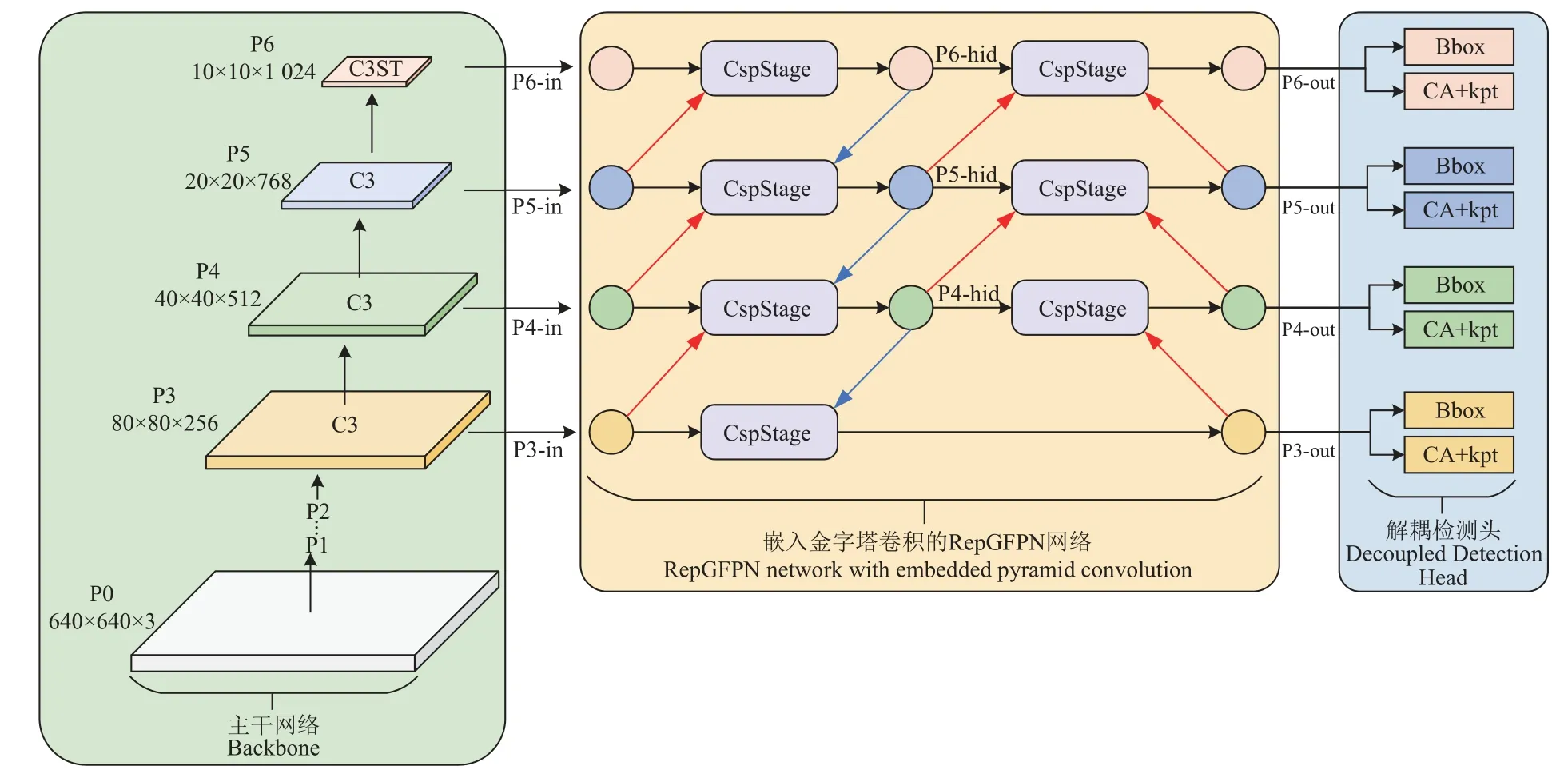
图4 改进YOLOv5s6-Pose 网络结构Fig.4 Improved YOLOv5s6-Pose network structure diagram
2.2.1 Swin Transformer 编码器
Swin Transformer 编码器是构建Swin Transformer[16]网络的核心组件,其由基于窗口的多头自注意力机制(windows multi-head self-attention,W-MSA)和基于移位窗口的自注意力机制(shifted windows multi-head selfattention,SW-MSA)堆叠而成,每个MSA 和MLP 模块[17]前应用层归一化(layer normalization,LN)和残差连接,其中,MLP(multi-layer perceptron)为嵌入GELU激活函数的多层感知器结构。
为解决网络在不断下采样过程中而导致的全局特征缺失问题,本文将Swin Transformer 编码器嵌入主干网络P6 检测层的C3 模块中,构建C3ST 模块,其结构如图5 所示。

图5 C3ST 模块结构示意图Fig.5 Schematic diagram of C3ST module structure
C3ST 模块将输入特征图分成若干个子窗口,在独立的子窗口内进行自注意力计算,并采用如图6 所示的移位窗口自注意力计算方式来学习跨窗口的交互信息,使用掩码机制隔绝原特征图中不相邻区域像素点之间无效的信息交流[18],弥补了传统ViT[19]架构对于密集预测和高分辨率视觉问题的缺陷,在提升运算效率的同时能够有效地捕获全局依赖关系,增强全局建模能力。自注意力计算式如下:
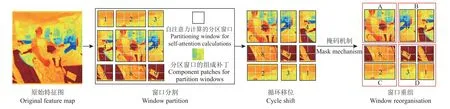
图6 移位窗口自注意力计算原理示意图Fig.6 Schematic diagram of the shift window self-attention calculation principle
式中Q、K、V由输入特征矩阵线性变化所得,QKT为不同特征矩阵信息交互过程,采用点积运算来计算不同特征之间的相似度,dk为输入通道序列的数量,除以以防止梯度激增,B为相对位置编码,取自偏置矩阵
2.2.2 高效层聚合网络RepGFPN
YOLO-Pose 在颈部采用PANet 融合多尺度特征映射,通过增加额外的自底向上路径,利用低层中准确的定位信息来增强整个特征层次,从而缩短高层和低层特征之间的信息路径[20],但这种自底向上的路径设计缺乏高层语义信息和低层空间信息的交互,导致多尺度检测效果欠佳。
针对上述问题,本研究采用具有跳连结构和跨尺度连接的高效层聚合网络RepGFPN[21]作为颈部,并额外增加P6 检测层以适应主干网络的多尺度输出。RepGFPN在GFPN[22]的基础上改进而来,GFPN 通过Queen Fusion 模块接受更多节点输入,增强了特征复用及特征表达能力,但其在不同尺度上共享统一通道数,存在特征冗余现象,且过多的节点堆叠导致运算效率降低,RepGFPN 从拓扑结构优化和融合方式优化两方面入手,通过对不同尺度特征使用不同的通道数以及采用具有重参数思想和层聚合连接的CspStage 模块融合来自相邻上下层以及同一层级的不同尺度特征,在不额外增加计算量的前提下,实现了更高的精度,融合模块CspStage 结构示意图如图7 所示。结构上,以P5 层为例,首先,P6-hid 经过2 倍上采样与P4-in、P5-in 融合得到中间节点P5-hid,其次,P4-out 经过2 倍下采样与P4-hid、P5-hid融合得到P5-out,同理可得P4-out、P6-out,最后,P4-hid 经过2 倍上采样与P3-in 融合得到P3-out。

图7 融合模块CspStage 及其组件Fig.7 Fusion module CspStage and its components
2.2.3 金字塔卷积
常规的卷积神经网络都采用内核较小的3×3 卷积用于特征提取,卷积核的大小与网络感受野呈正相关,即卷积核越大,感受野越大[23]。通常,卷积神经网络会采用具有多个小卷积核和下采样层的卷积链以逐步减小输入特征图大小并增加网络感受野以此获取更丰富的特征信息,然而,这不仅会增加参数量和计算复杂度,而且频繁的下采样会丢失细节信息,导致网络的识别性能下降。
金字塔卷积[24](pyramid convolution)包含n层不同核大小的金字塔结构,在金字塔卷积的每一层,内核包含不同的空间大小,从金字塔的底部到顶部逐渐增加内核大小,随着空间尺寸的增大,核的深度从第1 层减小到第n层,在逐步扩大感受野的同时使用不同的内核大小来捕获图像中多尺度的细节信息。同时,为了尽可能降低金字塔卷积的计算量并且在每个层级使用不同深度的内核,使用分组卷积将输入特征图分为不同的组,并为每个输入特征组独立应用内核[25],金字塔卷积及分组卷积结构示意图如图8 所示。
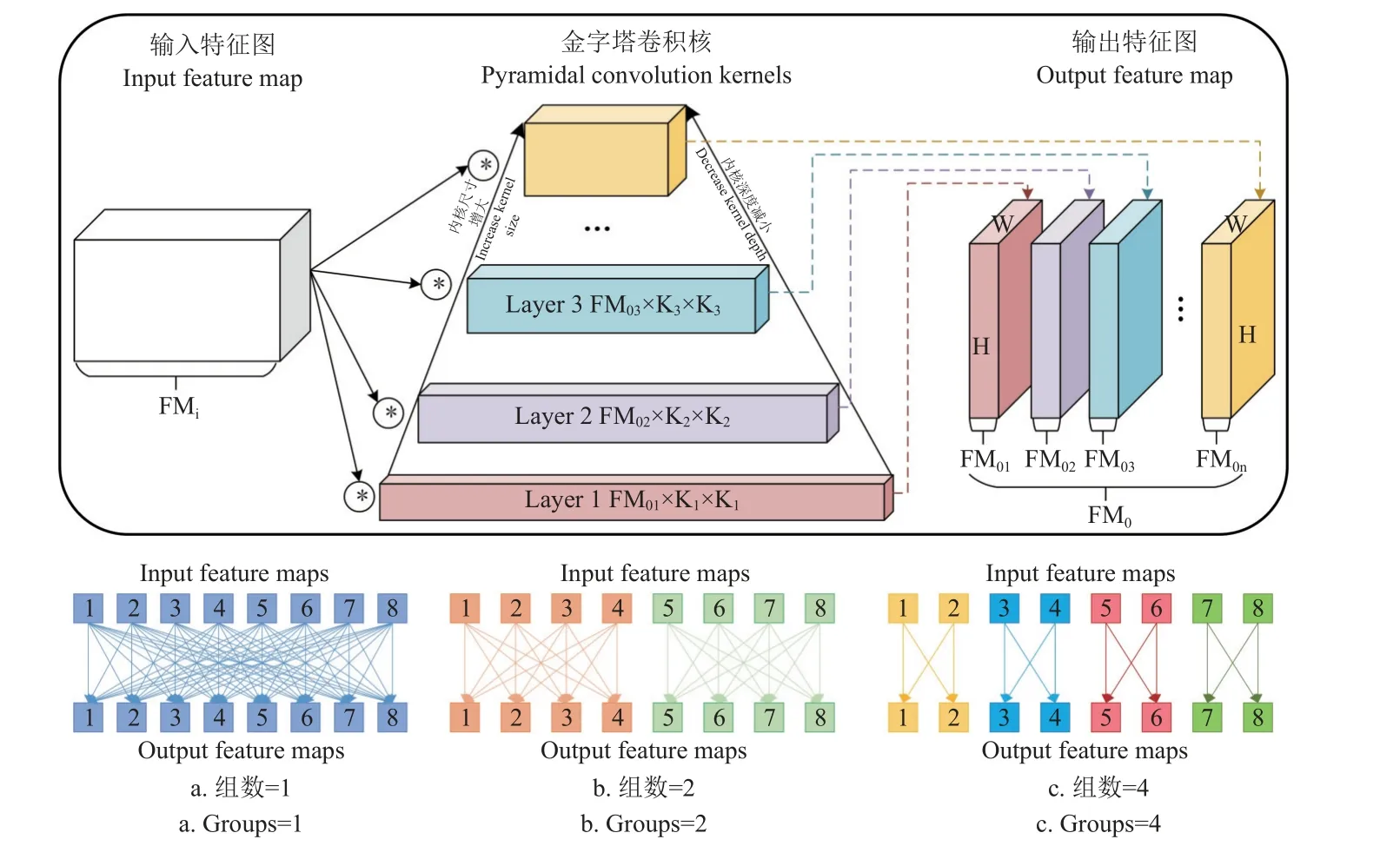
图8 金字塔卷积及分组卷积结构示意图Fig.8 Schematic diagram of pyramid convolution and group convolution structure
与标准卷积相比,金字塔卷积有以下几点优势:1)多尺度特征提取能力,由于金字塔卷积独特的核金字塔结构,其可以在不提高计算量的前提下,增大局部感受野,解决下采样过程中上下文信息丢失问题,增强不同尺度目标的特征提取能力;2)高效性和灵活性,通过设置不同的分组卷积组数和金字塔层数,使网络更具灵活性和可扩展性。
2.2.4 优化关键点解耦头
关键点检测是对位置信息高度敏感的任务[26],农业作业环境下驾驶员易受光照等外界因素影响,造成关键点漏检、误检现象。原始网络的关键点解耦头通过一个独立的2D 卷积分别在4 个尺度上进行预测,每个尺度分别对应3 个Anchor,每个Anchor 分别预测51 个特征向量,共计153 个特征向量。本文通过引入坐标注意力机制进一步优化关键点解耦头,以提高关键点定位精度。坐标注意力机制结构示意图如图9 所示。
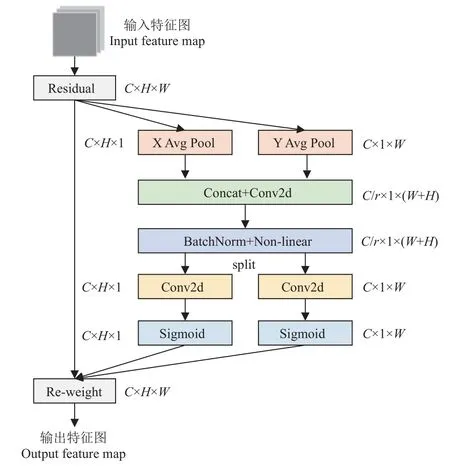
图9 坐标注意力机制结构示意图Fig.9 Schematic diagram of the structure of the coordinate attention mechanism
坐标注意力机制[27](coordinate attention mechanism,CA)通过将横向和纵向的位置信息编码到通道注意力中,使得网络不仅能够获取跨通道的信息,还能捕获方向感知和位置敏感的信息,其具体包括坐标位置嵌入和坐标注意力生成两个步骤,对于输入特征图X,首先使用池化核大小为(H,1)和(1,W)沿水平和垂直方向进行全局平均池化操作,分别得到在高度h和宽度w上第C通道的特征输出
式中xc为第C通道的输入;然后,将式(6)中获得的特征图进行维度拼接,并通过1×1 卷积、批量归一化和非线性激活函数进行特征转化,得到中间特征映射,如式(7)所示。
式中f∈RC/r×(H+W)为包含水平和垂直空间信息的中间特征,ξ为非线性激活函数,zh和 zw为拼接后的特征图在高度和宽度方向上的输出,r为缩减因子,R为实数集合,C为特征图通道数,F1表示核大小为1 的卷积操作。随后将f沿高度和宽度维度拆分为两个独立的特征张量fh∈RC/r×H、fw∈RC/r×W,另外使用两个1×1 卷积变换Fh和Fw使fh、fw与输入特征X通道数一致,再分别经过Sigmoid 激活函数 σ得到高度和宽度上的注意力权重gh、gw,如式(8)所示。
最后,将输入特征图X与权重gh、gw进行乘法加权操作,得到坐标注意力模块的输出Y∈RC×H×W,如式(9)所示。
式中xc和yc分别为特征图在第c通道的输入和输出,和分别为特征图在第c通道高度和宽度方向上的注意力权重。
本文在普通2D 卷积关键点解耦头前嵌入坐标注意力机制,增强网络在预测过程对关键点位置的敏感程度,使模型聚焦感兴趣区域,提高预测精度。
3 试验方法及结果
3.1 试验环境与参数设置
本研究试验平台基于Windows10 的64 位操作系统,12 th Gen Intel® Core™ i7-12700KF、3.6 GHz 处理器和NVIDIA GeForce RTX 3 070 Ti 显卡,显存大小8 GB,GPU 加速库为CUDA11.6 和CUDNN8.2,Python 版本为3.7.12,深度学习框架为PyTorch1.12.0。
试验采用随机梯度下降法(stochastic gradient descent,SGD)作为优化器对网络进行优化,为保持模型深层的稳定性,训练采用warm up 策略,在前3 轮内采用0.000 1 的学习率进行预热训练,之后恢复到初始学习率,学习率调整方式采用余弦退火学习率衰减策略,初始学习率设为0.01,最终学习率设为0.002,权重衰减系数设为0.000 5,动量因子设为0.937,共迭代300 轮。训练时将输入图像分辨率统一调整为640×640 大小,批次大小为16,所有试验均使用在COCO 数据集上训练得的预训练权重进行迁移学习。
3.2 评价指标
试验采用MS COCO 官方给定的基于目标关键点相似度Loks(object keypoint similarity)验证标准的平均准确率均值作为评价指标。其中,Loks表示为:
式中i为标注的关键点编号;为检测到的关键点位置与真实关键点位置的欧式距离的平方;s2为检测到的人体在图像中所占的面积;ki为用来控制关键点类别i的衰减常数;δ为冲激函数,表示只计算真实标注中可见关键点的Loks值;vi表示第i个关键点的可见性(vi>0 表示关键点可见)。
在目标检测方面,本研究采用准确率(Precision)和召回率(Recall)作为评价指标。在关键点检测方面,采用mAP0.5和mAP0.5:0.95作为评价指标,其中mAP0.5表示Loks阈值为0.5 时的检测精度,mAP0.5:0.95表示Loks分别为0.50,0.55,…,0.90,0.95 时的平均检测精度。采用单张图片的测试速度作为评价模型推理速度的指标,同时采用参数量作为模型大小的评价指标。训练集和验证集目标关键点相似度损失以及训练集各项指标精度曲线如图10 所示,由图10 可知,当模型迭代300 次时,各项损失趋于平缓且达到最小,其中训练集损失为0.158,验证集损失为0.0073,此时各项精度指标均达到最优。
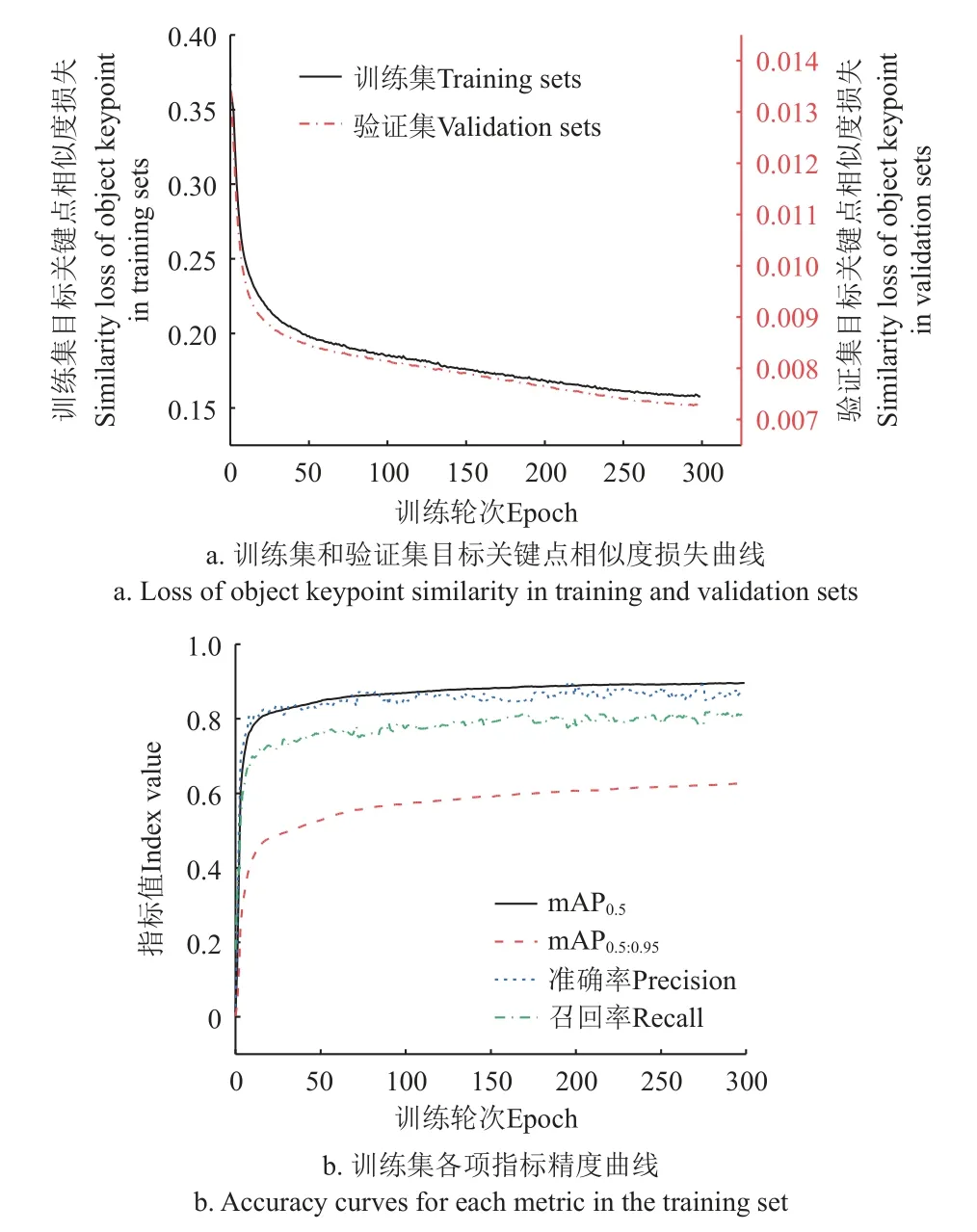
图10 改进YOLO-Pose 模型训练过程Fig.10 Training process of the improved YOLO-Pose model
3.3 消融试验
为验证各个改进模块对模型整体性能的影响,本研究设计消融试验,试验结果如表1 所示。
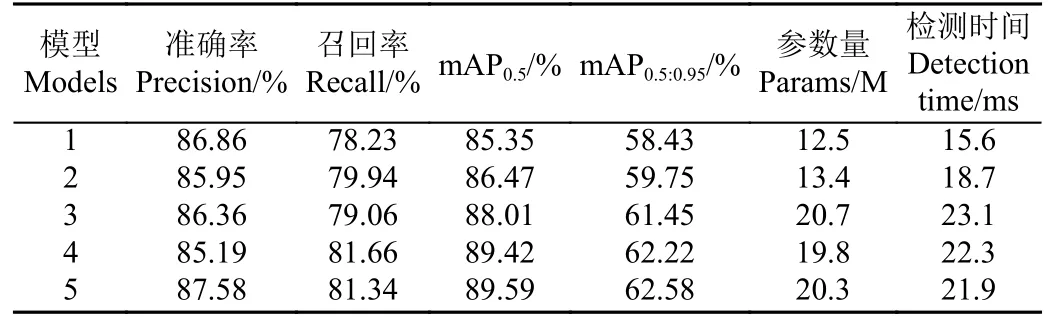
表1 不同改进策略消融试验结果Table 1 Results of ablation experiments with different modification strategies
分析表1 可知,改进后的YOLO-Pose 驾驶员-关键点联合检测算法较原始模型在各项指标上均有提升。目标检测方面,改进后的模型准确率为87.58%,召回率为81.34%,较原始模型分别提升了0.72 和3.11 个百分点。关键点检测方面,mAP0.5和mAP0.5:0.95为89.59%和62.58%,较原始模型分别提升了4.24 和4.15 个百分点,单张图片检测时间为21.9 ms,满足实时检测的要求。当在主干网络顶层引入C3ST 模块时,由于Swin Transformer 编码器独特的跨窗口自注意力计算和相对位置编码机制,增强了模型对空间位置信息的感知,提升了全局建模能力,有助于遮挡情况下关键点的有效检测。当更换颈部网络为RepGFPN 时,增强了不同尺度特征的高效融合,对密集关键点的预测有显著提升,但参数量和检测时间也有大幅增加,原因在于RepGFPN 网络跨尺度的连接方式使得模型层数加深,预测过程前向传播时间显著增加。当使用金字塔卷积替换RepGFPN 中普通的3×3 卷积后,模型的参数量有小幅降低,且检测精度有了一定提升,分析原因可知,金字塔卷积中采用了不同的内核大小和分组数,在增大感受野的同时利用组卷积的思想有效地降低了模型参数量。最后,添加坐标注意力机制进一步优化关键点解耦头,通过将位置信息编码到通道注意力中,提高网络对于关键点位置的敏感程度,检测精度有了进一步提升。综上,改进后的模型在参数量和检测时间上虽然有所增加,但检测精度有了较大的提升。
为了更直观体现改进后模型的有效性,选取暗光条件、轻度遮挡和重度遮挡三种驾驶情景,对检测结果进行可视化。分析图11a 可知,在暗光条件和轻度遮挡情况下驾驶员手腕、手肘以及右耳存在关键点漏检现象,重度遮挡情况下驾驶员手腕、右膝以及右踝存在误检现象,而改进后的网络在上述各场景下都具有良好的检测效果。

图11 改进前后模型检测效果对比Fig.11 Comparison of model detection results before and after improvement
3.4 Swin Transformer 编码器窗口大小对模型的影响
Swin Transformer 编码器通过划分非重叠的窗口来执行自注意力计算,在保证全局建模能力的同时提高了运算效率。为探究不同窗口大小对模型的影响,固定自注意力计算头数,分别设置窗口大小为4、8、16 进行对比试验,结果如表2 所示,分析可知:1)窗口划分大小对模型参数量无影响。2)模型浮点运算量随窗口大小的增大逐渐升高,且窗口越大,运算量提升约明显。3)关于平均准确率mAP 值,随着窗口大小不断增加,mAP0.5和mAP0.5:0.95均有所提升,其中,mAP0.5分别提高0.85和0.26 个百分点,mAP0.5:0.95分别提高1.19 和0.27 个百分点,窗口大小设置为16 相比窗口大小设置为8 时提升效果不明显。综合各项指标,当窗口大小设置为8 时,模型综合性能更优。
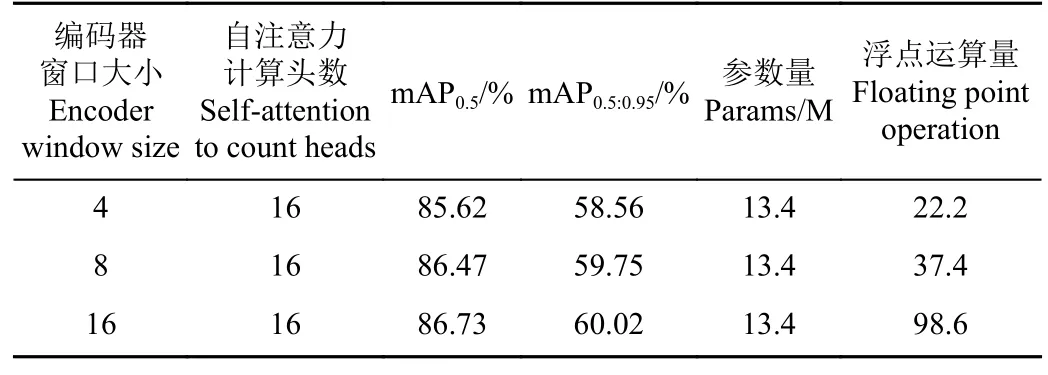
表2 编码器窗口大小对模型的影响Table 2 Effect of encoder window size on the model
3.5 不同金字塔卷积层数对模型的影响
为验证设置不同金字塔卷积层数时对模型性能的影响,分别设置层数为1、2、3、4 进行试验,结果如表3。其中,当层数设置为1 时,即为标准3×3 卷积,此时模型参数量最少,浮点运算量最低,随着金字塔层数的增加,平均准确率均呈上升趋势,且模型参数量和浮点运算量逐渐减小,当设置金字塔卷积层数为4 时,模型准确率达到最优,mAP0.5和mAP0.5:0.95分别为87.64%和60.28%,相比原始网络分别提升2.29、1.85 个百分点,说明融入金字塔卷积对模型精度产生了积极影响。分析原因可知,金字塔在特征提取方面较普通卷积有明显优势,其通过逐层增大卷积内核的方式来增大网络感受野,避免了细节信息的缺失,在每个卷积核组中又分别使用不同大小的内核来适应不同尺度目标,并设置不同组数来避免参数量的陡增,结果表明,融入金字塔卷积在少量增加模型复杂度的前提下能有效地提升模型检测精度。

表3 金字塔卷积层数对模型性能影响对比Table 3 Comparison of the impact of the number of pyramid convolution layers on model performance
3.6 不同检测模型对比试验
为了进一步验证改进后的模型对驾驶员关键点的检测效果,本研究选取当前主流基于热力图回归的关键点检测网络进行对比试验,对比的检测算法有:Hourglass[28],HRNet-W32[29]以及DEKR[30],试验结果如表4 所示。
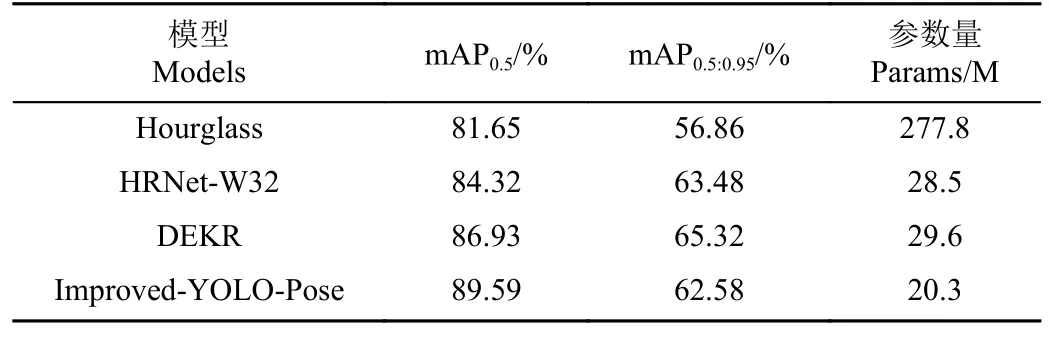
表4 不同检测模型性能对比Table 4 Performance comparison of different detection models
由表4 可知,改进后的YOLO-Pose 驾驶员关键点检测算法mAP0.5达到最优,较Hourglass、HRNet-W32 以及DEKR 分别高出7.94、5.27、2.66 个百分点,且模型大小分别减少了257.5、8.2、9.3 M。DEKR 网络的mAP0.5:0.95最高,较改进YOLO-Pose 高2.74 个百分点,其次为HRNet-W32,较改进YOLO-Pose 高0.9 个百分点,分析原因可知,HRNet 采用多分辨率子网的并行连接方式,通过执行重复的多尺度融合,使得网络在整个过程都保持高分辨率表征,预测得到的关键点热图在空间上更精确,DEKR 采用自适应卷积和多分支独立回归结构,每个关键点的回归单独对应一个分支,二者在泛化性方面表现更好,但其在参数量方面均高于改进后的YOLOPose 算法,综合考虑检测精度与模型轻量化程度,改进后的YOLO-Pose 驾驶员关键点检测算法表现出最好的检测性能。
为更加直观的反映各模型在实际场景下的检测效果,选取不同自然场景下驾驶员操纵图像,包括暗光、轻度遮挡和重度遮挡等难检测情形,并使用类激活热力图对输出层进行可视化分析,各模型检测结果如图12 所示。
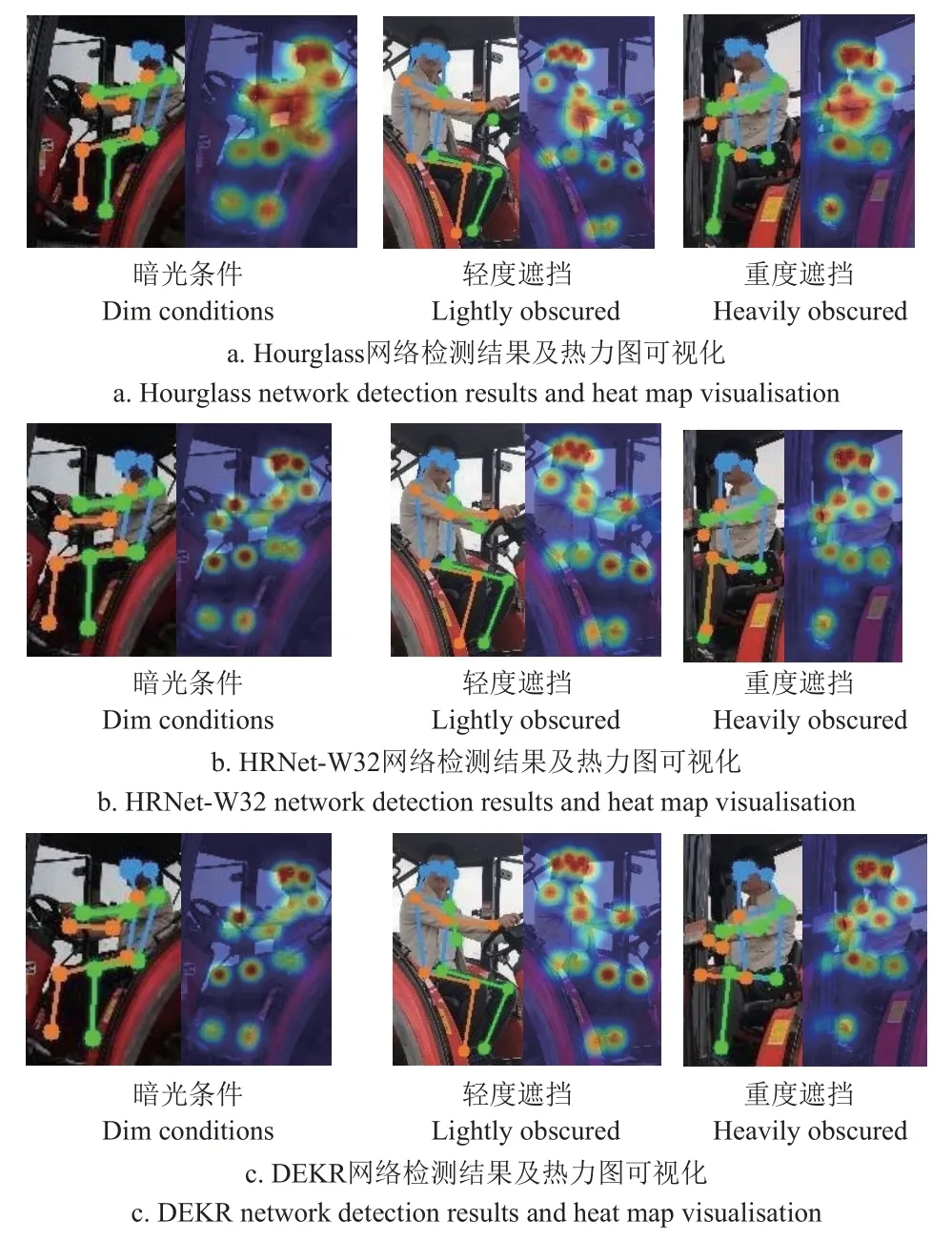
图12 不同网络模型检测效果示例Fig.12 Example of the detection effect of different network models
由图12 可知,在暗光条件下,Hourglass、HRNet-W32、DEKR 和改进的YOLO-Pose 关键点检测算法均表现出良好的检测效果,在轻度遮挡和重度遮挡状况下,Hourglass、HRNet-W32 和DEKR 存在关键点定位不准以及漏检现象,而改进后的YOLO-Pose 检测算法在上述复杂场景下依然保持较高的精度和鲁棒性,其通过隐式学习各关键点之间的空间位置关系,即使处于重度遮挡情况也能有效地捕获各关键点的位置信息。
4 结论
针对农田作业环境下拖拉机驾驶员因外界因素干扰而导致的关键点漏检、误检及定位精度低的问题,本文提出了一种基于YOLO-Pose 模型改进的驾驶员关键点检测算法,通过在自制的驾驶员数据集上进行训练和测试,验证了该算法的有效性。通过在主干网络顶层引入C3ST 模块,显式地捕捉各关键点之间的空间关系,对遮挡状况下关键点的预测有积极的影响。采用融合金字塔卷积的RepGFPN 网络作为颈部网络,有效地缓解了多尺度检测效果欠佳的问题。通过嵌入坐标注意力机制优化关键点解耦头,使模型在预测过程更加关注目标主体位置。结果表明,改进后的模型相比原模型mAP0.5(基于目标关键点相似度阈值为0.5 时的检测精度)和mAP0.5:0.95(基于目标关键点相似度阈值为0.5,0.55,···,0.95 时的检测精度)分别提升了4.24 和4.15 个百分点。
本文所提出的模型较当前主流的关键点检测网络综合效果更优,能够有效地改善模型在复杂场景下的检测效果,尤其是驾驶员存在自遮挡和他物遮挡的情形,可为农田作业环境下驾驶员的行为识别和状态监测提供一定的理论依据。但本文方法也存在不足之处,模型在检测精度提高的同时伴随着参数量增大、检测速度变慢的情况,后续工作可从轻量化角度入手,在保证检测精度的前提下进一步压缩模型体积,提高在小型设备上的部署与应用。
