基于混合神经网络的多模态方面级情感分析
2023-11-25于玉海孟佳娜
张 冲,于玉海,孟佳娜
(大连民族大学 计算机科学与工程学院,辽宁 大连 116650)
情感分析,也称意见挖掘,是指个人对许多话题表达的意见、情感和态度的分析。社会媒体的发展推动了信息发布形式的多样化,目前社交媒体用户除了用文本来表达自己的情感,也经常上传带有感伤或者高兴文字的图片,使推文更生动、更容易理解。方面级情感分析是细粒度情感分析,在方面级情感分析任务中,使用注意力机制可以有效提高分类效果。Ma等人[1]提出一种基于分层注意力机制的长短期记忆网络(Long-Short Term Memory,LSTM),同时将情感相关概念的常识性知识引入到深度神经网络端到端的训练中进行情感分类。Wang等人[2]提出MemNet模型,应用记忆网络的思想,通过上下文信息构建记忆网络,通过注意力机制捕获对方面情感倾向比较重要的信息,使用多层计算单元提取到更多的信息,进而提升模型的性能。引入图像描述生成方法[3],通过图像描述语句生成,增加语言模型可用的文本数量,然后通过图像生成的图像描述语句与目标方面词构建一个辅助句子,辅助句子与文本标题一同输入RoBERTa混合神经网络模型,将多模态交互应用于情感传递,最后利用自注意力机制对目标方面词对应的关键信息赋予不同权重,并把编码结果输入到情感分类器中进行多模态方面级情感分析。模型用Twitter-15/17数据集来评估,实验结果数据表明该模型具有效性。主要贡献如下:
(1)提出一种混合神经网络模型(Hybrid Neural Networks,HNNet),并引入图像描述生成方法准确提取图像信息,生成图像描述语句,更好应用到下游情感分析任务中。
(2)构建辅助句子与文本数据融合,弥补Twitter文本较短、包含信息量少,难以捕获重要信息等问题。
(3)融入注意力机制,使模型更好的关注到目标方面词所对应的句子关键信息上,从而有效地提高方面级情感分析的准确度。
1 相关研究方法
基于多模态方面级情感分析的新任务来源于两个研究方向,分别是方面级情感分析和多模态情感分析。
1.1 方面级情感分析
方面级情感分析的目的是识别文本句子在某一方面的情感极性。它的研究方法可以分为两大类:基于传统特征选择的方法和基于神经网络的方法。
基于特征情感分析方法通过对文本内容中出现情感词的概率进行编码来完成任务。情感词语检测[4]、统计模型[5]是典型的方法。情感词语检测是最常用的方法。统计模型是一个经过大规模标记语料库训练的分类器,用于识别单词的情感强度。
基于神经网络的方面级情感分析,也取得很好的效果。为了进一步处理多方位句和句法复杂的句子结构,Liu等人[6]提出了句子层面的内容注意力机制,从全局角度捕捉给定方面的重要信息,语境注意力机制同时考虑语境词的顺序及其相互关系。然而以往的研究并未考虑语法规则对语篇情感分析的影响,并且注意力机制也过于简单,难以从语境和目标中交互学习到重要的注意信息,所以Lu等人[7]提出一个交互规则注意网络IRAN用于方面级情感分析,这种交互可以捕捉到更多重要的信息。Du等人[8]指出现有的神经网络模型大多倾向于利用静态的集中操作或注意力机制来识别感伤词,不足以处理重叠的特征。与他们的工作不同,本文主要使用深度混合模型RoBERTa、双向长短期记忆网络(Bi-directional Long-Short Term Memory,Bi-LSTM)和自注意力机制进行方面级情感分析。
1.2 多模态情感分析
随着多种形式的用户生成内容(如文本、图像、语音或视频)在社交网站中的流行,情感分析已经不限于基于文本的分析。多模态情感分析是将文本和非文本信息整合到用户情感分析中的新兴研究领域。
文本-图像对是多模态数据最常见的形式。传统方法采用基于特征的方法进行多模态情感分析。如Borth等人[9]从图像中提取1 200对形容词-名词对作为图像的视觉特征进行分类,然后根据英语语法和拼写风格计算文本的情感得分生成文本特征。这些基于特征的方法在很大程度上依赖于费时费力的特征工程,未能建立视觉信息与文本信息之间的关系模型。随着深度学习技术的发展,一些基于神经网络的多模态情感分析模型被提出,Cai等人[10]利用基于卷积神经网络(Convolution Neural Network,CNN)从文本和图像中提取特征表示,并取得显著的进展。为了充分捕捉视觉语义信息,Xu等人[11]从图像中提取场景和物体特征,并利用这些视觉语义特征聚合文本情绪信息词,建模图像对文本的影响。Wang等人[12]从每个模态中提取特征,然后对跨模态关联进行建模,以获得更具有识别力的表示,以此在多任务框架中同时感知事件和情感。Yang等人[13]引入多通道图神经网络来学习基于数据集全局特征多模态表示,利用多头注意机制实现多模态深度融合预测图像-文本对的情感。
1.3 多模态方面级情感分析
多模态方面级情感分析属于细粒度的多模态情感分析任务。与基于纯文本的情感分析相比,多模态方面级情感分析主要从文本、视觉等不同情感信息中获取情感特征,这些方法的联合应用不仅可以提高情感表达的质量,还可以提高情感分析的分类精度。Xu等人[14]提出一种基于方面的多交互记忆网络,以及一个 Multi-ZOL多模态中文情感分析数据集,用于多模态情感分析。Wang等人[15]提出一种基于注意胶囊与多头注意力机制的网络模型,以及一个基于目标方面类别的多模态情感分析数据集用于模型评估。Yu等人[16]提出了一种多模态BERT架构,该架构将BERT用于跨模态交互以获得目标敏感的文本与视觉表示,利用多个自注意力层来实现多模态融合。Khan等人[3]将图像转换为标题,作为情感分类的辅助句子,并利用BERT进行情感分类。本文在图像处理部分引入图像转换为标题模块,在此基础上,进一步把文本与图像描述语句以句子对形式输入到混合神经网络模型进行方面级情感分类。
2 本文方法
2.1 问题定义
一组多模态样本,每个样本包含一个句子Si=(W1,W2,...,WL),其中L是单词数,句子旁边是一个图像Ii、一个目标方面Ti,对应的标签Yi∈{negative,neutral,positive},目的是学习一个函数F:(Ti,Si,Ii)→Yi。
2.2 总体模型图
本文提出一种基于多模态方面级情感分析的混合神经网络模型,总体模型如图1。首先对于图像利用图像描述生成器进行输入转换,将情感目标的标记与图像描述生成语句的标记连接起来,从而创建一个辅助句子,然后把辅助句子与文本以句子对形式输入预训练模型RoBERTa,获取文本特征表示,并将其输出作为Bi-LSTM神经网络的输入,利用Bi-LSTM对每个句子分别采用顺序和逆序计算得到两套不同的隐层表示,通过向量拼接得到最终的隐层表示。使用自注意力机制捕获文本重要语义特征,在输入序列中对标签结果影响大的特征分配较大权重,在提取到最终的文本特征向量之后,送到池化层、全连接层,最后利用softmax进行情感分类。
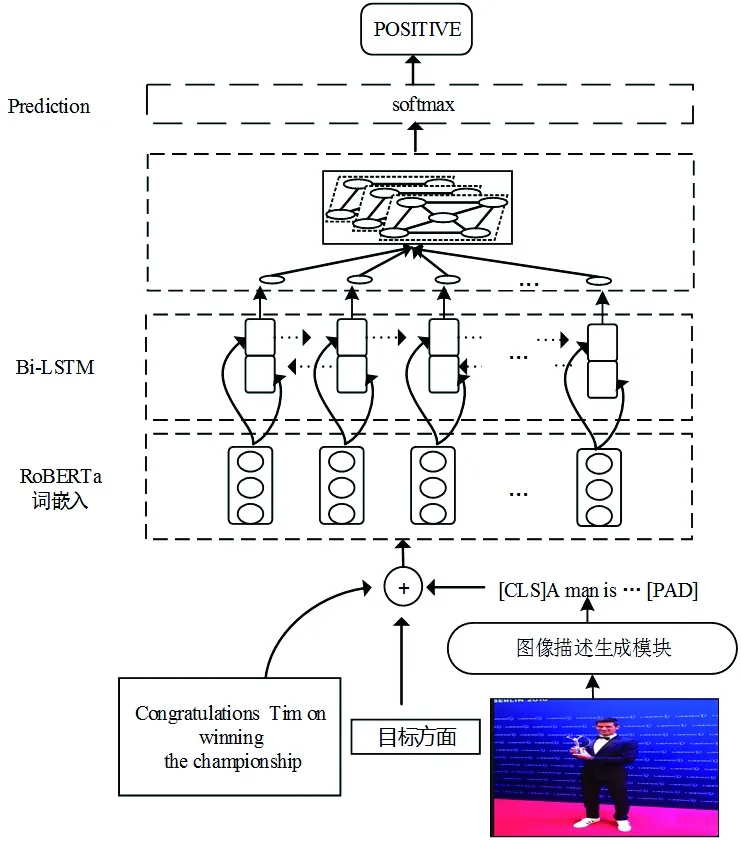
图1 总体模型图
模型由两部分组成。给定一个由目标方面、输入句子和图像组成的多模态输入样本mi=(Ti,Si,Ii),包含目标方面Ti、输入语句Si和图像Ii。首先将图像经过图像描述生成器进行转换,将图像Ii∈R3×W×H转换成输入空间中的一个元素Ii'∈N0L,3,W,H分别表示图像的通道数、宽度和高度。图像描述生成的最大输出长度为L。Ii',Si,Ti∈N0L,代表图像上下文、句子和目标方面存在于同一个空间N0L中。通过图像描述生成器和语言模型之间的共享标记器,将符号词映射到词汇表N0L里面,图像的自然语言描述语句Ii'∈N0L。利用图像的自然语言描述Ii',同目标方面语Ti构造一个辅助句Auxi,然后与输入语句Si构建句子对(Si,Auxi),在句子对分类模式中使用大规模预训练模型,通过混合神经网络模型得到目标方面语的情感预测。
2.3 图文信息融合
引入图像描述生成方法,给定输入图像,首先使用基于CNN骨干网络的ResNet101[17]生成一个特征映射图,然后通过固定的位置编码增强后传递到DETR[18]编码器层。最后利用Transformer解码器转换嵌入,使用解码器通过预测前馈网络预测输入图像的描述来生成非自回归文本。图像描述生成网络结构图如图2。利用图像的自然语言描述,与图像对应的目标方面语构造一个辅助句子,采用辅助问题[19]机制使文本与图像的自然语言描述进行融合。在辅助句分类方法中,将RoBERTa用于句子对分类模式,在句子对分类模式中,输入到RoBERTa的句子对形为

图2 图像描述生成模块结构图
(1)
2.4 基于混合神经网络文本特征提取
本文所提出的模型是稳健优化的RoBERTa和BiLSTM的混合神经网络模型。该模型利用预训练的RoBERTa权重有效地将映射词嵌入空间中,然后将输出的词嵌入输入到BiLSTM以捕获显著的语义特征。
2.4.1 RoBERTa文本表示层
RoBERTa模型是双向编码器表示Transformers的扩展。BERT和RoBERTa都是属于Transformers系列,该系列是为序列到序列建模而开发的,以解决长期依赖问题。Transformer模型包括三个组件,即编码器、解码器和头。编码器将原始文本转换为稀疏索引编码。解码器将稀疏内容重新转换为上下文嵌入以进行更深入的训练。头部被用来包装转换器模型,以便上下文嵌入可用于下游任务。
BERT与现有的语言模型略有不同,它可以从句子两端学习上下文表示。对于标记部分,BERT使用30K的字符级字节对编码,相比之下,RoBERTa使用字节对编码(Byte-Pair Encoding,BPE)结合字符级和单词级表示,其词汇集更大,由50K子字单元组成。除此之外,RoBERTa模型通过训练更多数据、更长的序列和更长的时间来微调模型。RoBERTa基础层旨在创建有意义的词嵌入作为特征表示,以便后续层可以轻松地从词嵌入中捕获有用信息。
本文模型的文本表示层引入RoBERTa来获取文本的字向量表示,将文本离散的序列转换为计算机可识别的稠密向量。通过预训练模型RoBERTa获得的字向量组成的文本序列向量表示S为
(2)
2.4.2 双向长短期记忆网络层
LSTM模型能够存储先前的信息, 从而捕获给定输入中突出的远程依赖关系。使用BiLSTM对序进行处理,捕获文本的长期依赖特征,具体过程为
(3)
。
(4)


。
(5)
设每个单向LSTM的隐藏单元数为u,则BiLSTM的隐藏单元为T=2u,其输出H如公式(6)所示。
H=(h1,h2,h3,...,hT)。
(6)
2.5 自注意力机制层
自注意力机制是从众多信息中选择对当前任务目标更关键的信息,然后对需要重点关注的目标区域投入更多的注意力资源。用Bi-LSTM神经网络提取文本的全局特征之后,运用自注意力机制,选择性地对文本中关键的内容赋予更多的权重,利用上下文的语义关联信息可以有效弥补深度神经网络获取局部特征方面的不足。文本局部特征表示文本中部分内容之间的关联特征,例如在句子“这家饭店的烧烤特别美味,啤酒也很棒!”中,“烧烤”是一个显性的方面类别,与“特别”“美味”这样的词关系比较密切,就会给分配较大权重,而其余词的关联度小,分配相对较小权重,因为各个词对方面类别词的影响程度不同,所以为其分配的权重也不同。
引入注意力机制后,输入句子的映射矩阵为Q,K,V,可将输入句子的嵌入与对应的权值矩阵相乘进行初始化。
Q=WqI
,
(7)
K=WkI
,
(8)
V=WvI
。
(9)
式中,Wq,Wk,Wv为不同的向量空间,是可训练的参数,当对输入序列I经过多次变换得到不同的Q,K,V,可以得到I在不同子空间的特征以学习到不同的注意力特征。
用Q和K计算相似性,用softmax函数归一化处理为
A=KTQ
。
(10)
式中,K是进行训练之后的参数,KT为K的转置。
(11)

对V使用权重系数进行加权求和,得到输出h*为
h*=A′V。
(12)
2.6 Softmax分类层
本文采用一个全连接层作为输出网络进行情感分类。首先将注意力层的输出作为全连接层的输入,然后通过softmax函数对输出向量进行归一化处理,最后得到模型的输出向量为
y′=softmax(Wh*+b)。
(13)
式中,W为训练权重参数,b为偏置。
3 实验结果与分析
3.1 数据集
实验中所使用的Twitter-15和Twitter-17两个数据集是由多模态推文组成,其中每条多模态推文都包含文本、与推文一起发布的图像、推文中的目标以及每个目标的情感。每个目标都被赋予来自集合{negative,neutral,positive}的标签,任务是一个标准的多分类问题。数据集见表1~2。

表1 Twitter-15数据集基本统计数据

表2 Twitter-17数据集基本统计数据
3.2 参数设置
本实验中句子分词最大长度设置为100,批量处理数量batchsize设置为8,LSTM单元状态维度128,RoBERTa词向量的维度为768,Dropout与Epoches值分别为0.000 02和6,Twitter-15与Twitter-17的学习率值分别为0.1和0.5。具体参数设置如见表3。

表3 实验参数设置
3.3 实验结果
为了验证本文模型的有效性,将本文模型与经典的文本情感分析方法(ATAE-LSTM、MemNet、MGAN、RAM、EF-Net(text))和具有代表性的多模态情感分析方法(Res-MGAN、TomBERT、EF-Net、EF-CapTrBERT)进行对比分析。
3.3.1 基于文本数据的对比实验
ATAE-LSTM[2]:应用LSTM和连接过程来获得方面嵌入,并使其参与到注意力权重的计算中,当涉及到不同的方面时,参与不同部分的计算。
MGAN[20]:一种细粒度注意力机制,用来捕捉方面和上下文之间的词级交互,然后利用细粒度和粗粒度注意力机制来组成MGAN框架。
MemNet[21]:通过上下文信息构建记忆网络,通过注意力机制捕获对不同方面情感倾向较为重要的信息,使用多层计算单元提取到更多的信息,进而提升模型的性能。
RAM[22]:在Bi-LSTM的隐藏状态上构建记忆,并生成同样基于Bi-LSTM的方面表示,其多个注意层的输出与递归神经网络非线性结合,增强全局记忆抽象的表达能力。
EF-Net(text)[15]:基于多头注意力网络对文本信息进行处理进行情感分析。
HNNet(text):在本文模型上去除掉图像特征,只对文本信息方面级情感分析任务。
在基于文本数据的基线方法中,ATAE-LSTM表现不佳,因为没有通过平等对待方面和上下文单词来明确区分。比较结果见表4。与ATAE-LSTM相比,MemNet表现更好,在输入记忆跳跃处侧重方面记忆和单词记忆,利用多次记忆跳跃提取更深层次的注意表征。RAM结合了递归网络在考虑语境信息方面的优势,加入记忆信息的多重注意力机制,利用非线性组合,充分考虑所有记忆结果。EF-Net(text)利用注意力机制重点关注文本数据中有关方面的重点信息。HNNet(text)首先文本信息经过预训练模型RoBERTa获取词向量表示,然后通过Bi-LSTM提取上下文信息、最后利用自注意力机制重点关注文本数据中有关方面的重点信息,效果是最好的。

表4 HNNet模型与文本数据基线方法的比较结果 %
3.3.2 基于多模态数据的对比实验
Res-MGAN:采用ResNet的最大池化层与MGAN的隐藏层简单拼接起来进行多模态情感分类。
EF-Net[15]:基于多头注意力的网络和 ResNet-152分别处理文本和图像,捕捉多模态输入之间的交互。
TomBERT[16]:一种面向目标的多模态 BERT(TomBERT)架构,可以有效地捕捉模态内和模态间的动态表示。
EF-CapTrBERT[3]:将图像转换为标题,作为情感分类的辅助句子,利用BERT进行情感分析。
VLPMABSA[23]:一种基于多模态方面的情感分析的特定任务的视觉语言预训练框架。
基于多模态数据的方法中,Res-MGAN结果是最低的,因为它对文本和图像信息内容只进行简单的拼接见表5。与Res-MGAN相比,EF-Net表现更好,EF-Net利用一种注意力胶囊和多头注意融合网络对文本和图像进行提取,促进多模态数据间交互。TomBERT和EF-CapTrBERT比EF-Net取得了更好的效果,TomBERT使用ResNet结合目标方面提取图像特征,目标注意力机制在目标和图像之间进行匹配,以获得目标敏感的视觉表示,BERT提取文本句子特征,然后利用多头注意力机制分配高注意力权重到与目标密切相关的图像区域。EF-CapTrBERT利用输入空间中的翻译将图像翻译成文本,使用BERT进行情感分析,效果优于TomBERT。本文模型HNNet在图像转换为自然语言描述之后,描述语句与文本信息融合丰富了信息,利用预训练模型RoBERTa和Bi-LSTM更好的提取信息,然后利用自注意力机制,给目标方面关系密切的词更大的权重,最后进行情感分析,在两个数据集上的结果几乎比具有视觉语言预训练任务的VLP-MABSA模型效果好。

表5 HNNet模型与多模态数据基线方法的比较结果 %
从表4~5可以看出,本文模型在文本与图像描述语句结合之后的效果比仅单文本的效果要好,也证明构建辅助句子进行融合可以弥补文本较短、包含信息量少,难以捕获重要信息等问题。
3.3.3 单模态与多模态实验结果分析
单模态实验仅使用数据集中的文本数据,多模态实验使用数据集中的文本以及图像数据。将本文单模态数据实验结果与多模态数据实验结果进行联合分析,实验结果对比如图3~4。

图3 Twitter-15数据集情感分析准确率与F1值对比

图4 Twitter-17数据集情感分析准确率与F1值对比
结果表明,在传统的基于方面的情感分析任务中引入图像模态数据是非常有效的。在单模态数据实验中,HNNet(text)模型比其它单模态模型的效果有了一定的提升,但是相对于多模态数据效果不理想。相比于单模态数据,多模态数据之间的相互依赖、相互补充的特点,克服单一模态信息鲁棒性差,表达片面的缺点,所以效果更优。HNNet模型与最新的多模态方面级情感分析方法相比,在Twitter-15数据集上准确率提升了0.18%,F1值提升了1.36%。在Twitter-17数据集上F1值提升了0.46%。
3.3.4 消融实验
为了验证本文的预训练模型RoBERTa、BiLSTM以及自注意力机制Attention的有效性,在使用预训练模型RoBERTa的HNNet模型的基础上设计一系列的变体进行相关实验。
HNNet w/o Att:在HNNet模型的基础上去掉自注意力机制模块。
HNNet w/o BiLSTM:在HNNet模型的基础上去掉BiLSTM模块。
HNNet w/o BiLSTM Att:在HNNet模型的基础上去掉BiLSTM模块和自注意力机制模块。
HNNet(BERT):把HNNet模型中的预训练模型RoBERTa换成BERT。
消融实验比较结果见表6。把HNNet模型中的预训练模型RoBERTa换成BERT,说明在本实验中RoBERTa比BERT具有更强大的嵌入能力,更全面地生成文本向量。在去除模型中其他模块之后,结果有所下降,表明加入BiLSTM神经网络提取全局特征,运用自注意力机制,选择性对文本中关键内容赋予更多权重的有效性。

表6 消融实验比较结果 %
4 结 语
文章提出了一种面向多模态方面级情感分析的混合神经网络模型。首先,使用图像描述生成器对图像进行输入转换,生成图像描述辅助句。然后,将这个辅助句与相应的文本进行融合,通过整合上下文和图像信息来增强目标方面的表示。同时利用自注意力机制来捕获目标方面对应的文本中的重要语义特征,从而显著提高多模态方面级情感分析的准确性。在多模态方面级情感数据集Twitter-15/17中对提出的模型HNNet进行评估。实验结果表明,本文提出的混合神经网络模型优于基线方法,验证该模型在多模态方面级情感分析任务中的有效性。未来,考虑在方面级情感分析与多模态情感分析的交叉领域中引入文本图像关系检测模块,以更好地控制视觉信息的正确利用,从而提高准确率。
