姿态估计中注意图特征增强网络
2023-11-25任春贺杨大伟
任春贺,毛 琳,杨大伟
(大连民族大学 机电工程学院,辽宁 大连 116650)
2D人体姿态估计是指给定一张静态的RGB图像,准确地识别和定位出图像中的人体关键点(比如头,左手,右脚等)的位置,以便通过连接相邻关节可以恢复人体骨骼的姿态。在监控视频[1]场景中,常出现人体部分区域因姿态导致的关键点自遮挡或重叠的情况,从而导致在特征提取过程中被遮挡的部位丢失关键信息。由于无法准确地提取包含人体所有关键点的图像信息,这对人的动作行为监测带来了困难,可能无法及时阻止某些意外情况发生。这凸显了特征提取在解决人体姿态遮挡问题方面的不足。
国内外大量学者在提取特征方面采用两种方法来解决上述问题,一是添加有效的卷积器以增强特征表达,二是设计合理的注意力机制以改善特征效果。为了充分利用卷积神经网络(Convolutional Neural Network,CNN)[2]作为姿态估计的网络模型,可以通过添加卷积模块的方法对网络进行适当改进。Lin等人[3]提出了特征金字塔网络(feature pyramid networks,FPN),该网络虽能产生多尺度的特征表示,但因不同尺度特征之间冲突信息的存在,使得遮挡部位的关键点难以被检测,姿态估计精度不高;Szegedy等人[4]提出了多尺度融合网络,它能选择多层特征进行融合再进行预测,但由于有些尺度的特征语义信息缺乏丰富性,很难检测出人体遮挡部位的关键点;Dumoulin等人[5]提出了转置卷积网络。该网络虽然只执行了常规的卷积操作,但却能恢复特征图的空间分辨率。然而由于该卷积矩阵的稀疏性,会产生大量的冗余特征信息,难以检测遮挡部位的关键点;Newell等人[6]提出了堆叠沙漏网络(stacked hourglass networks,SHN),利用沙漏模块来处理和整合各个尺度的特征,但此模块通过堆叠会使得部分特征信息丢失,导致人体遮挡部位的部分关键点难以被检测;Yang等人[7]提出了一种轻量化的金字塔残差模块(Pyramid Residual Module,PRM)来代替沙漏模块来学习不同尺度上的特征,但随着层数的增加,很容易丢失原始特征信息,使得难以定位检测出被遮挡部位的人体关键点;Sun等人[8]提出了一种高分辨率网络HRNet,通过多尺度特征融合以获得更好的语义特征。但越多地融合特征,就会产生越多的信息冗余,可能会误导关键点定位和识别。另一种方法是通过在网络中引入注意力机制的方式让模型知道图像中不同局部信息的重要性。Max等人[9]提出了空间变换网络(Spatial Transformer Networks,STN),该网络引入了一个可学习的空间维度转换模块,使模型具有空间不变性,但它仅考虑局部区域的空间变换;Hu等人[10]提出了通道注意力网络SENet(Squeeze-and-Excitation Network),从通道维度上得到权重矩阵对特征进行重构,但它仅考虑通道方面的依赖性,没有充分利用空间信息,同时也忽略了使用最大池化操作进一步细化特征;Wang等人[11]提出了残差注意力网络(Residual Attention Network),它是兼顾通道抽象特征和空间位置特征信息的混合注意力机制,但其参数量和计算量较大。
综上,在人体姿态估计任务中,本文以深度残差网络ResNet-50作为特征提取主干网络,提出一种结合混合注意力机制的姿态估计特征增强网络(Pose Estimation Attention Feature Enhancement Network,PEANet)。该网络是将混合注意力模块插入到ResNet-50主干网络的每个Bottleneck Block层中,在减少网络的部分复杂度和参数的同时提高了姿态估计的精确度,以解决人体姿态关键点自遮挡的问题。
1 PEANet注意图特征增强网络
1.1 关键点自遮挡问题分析
关键点自遮挡是指因人体姿态具有多变性,如可能呈现站立、行走、半蹲、正坐等姿态,导致自身的一部分关键点遮挡住另一部分关键点。这种遮挡容易造成人体重要部位特征信息的缺失,导致人体关键点预测信息不完整,在姿态估计任务中出现关键点的漏检,从而降低姿态估计性能。在现实生活中,若能提升因自遮挡现象而造成姿态估计不准确的网络性能,就能较准确地识别出图像或视频中行人的动作,在很大程度上及时阻止意外的发生。因此,针对此问题进行深入的研究具有重大意义。
由于原主干网络只采用卷积模块进行特征提取操作,没能对特定的特征进行筛选,浪费了大量的计算资源。因此,本文提出对主干网络的每个Bottleneck Block层添加注意力,这样既能执行特征提取操作,又能根据需求筛选出具有有效信息的特征图。
本文选择注意力机制来解决关键点的自遮挡问题。注意力机制可以对人体关键点的空间关系进行建模,生成的注意力图只依赖图像特征,可以关注不同的目标区域。通道注意力利用卷积模块学习特征图各中各个特征通道的重要程度,虽然不同的通道可获取不同的特征图,但由于自遮挡的存在,有的通道实际上生成的是具有无效信息的特征图,此时可通过通道权重的比例调节,重新分配特征图在通道上对遮挡的分析能力,以舍弃具有干扰信息的特征图;在空间上有时也会存在自遮挡的现象,此时可再利用空间注意力的特点,使网络更加关注图像中起决定作用的区域而忽略无关紧要的区域,通过空间注意图进而确定那些被忽略的关键点。
以Poseur[12]为研究对象,经过图像处理后人体姿态关键点自遮挡的效果示意图如图1。其中,实心点代表人体部位的关键点,用线条将关键点连接起来是为了描绘出人体姿态,椭圆圈用于标识预测错误的位置,矩形框用于标识预测正确的位置。图1a~1c分别为原图、错误检测图和正确检测图。第一行图片是男人在滑板上冲浪的姿态,因半蹲姿态本身造成的自遮挡,导致其左膝盖关键点识别错误;第二行图片是小男孩打棒球的姿态,因屈膝姿态本身造成的自遮挡,导致右肘关键点识别错误。

a)原图 b)错误检测图 c)正确检测图图1 关键点自遮挡现象示意图
关键点自遮挡也会对其他关键点的预测产生负面影响,本文引入的注意力机制可使生成图像的细节更丰富,加强网络对人体关键点的关注,进而增强网络对关键点自遮挡的处理能力。
1.2 注意力机制
注意力机制源于对人类视觉的研究,通常分为:通道注意力[10]和空间注意力[13]。它是通过权重参数分配来决定哪些是需要关注的重要特征信息,从而有效选择信息。为了更好地增加人体姿态关键点信息的权重,注意力机制被引入到本文的网络架构中。
通道注意力机制可以在保留每个通道平均特征的同时突出其主要特征,忽略无用特征,使得网络更加关注人体姿态的关键点位置。该注意力主要是将特征图在空间维度上进行压缩,通过两种池化得到不同的特征映射,最终经过元素级运算得到通道级特征。
通道注意力模块(Channel Attention Module,CAM)如图2。通道注意力机制可以表达为

图2 通道注意力模块结构图
FAvg1=AvgPool(F1) ,
(1)
FMax1=MaxPool(F1) ,
(2)
Mc=σ(MLP(FAvg1⊕FMax1)) ,
(3)
F2=Mc⊗F1。
(4)
其中,给定一个输入特征F1。首先将输入特征图分别经过平均池化和最大池化得到特征FAvg1、FMax1;然后将两个不同的特征图送入MLP得到不同的输出特征;接着将两个不同的输出特征进行元素级求和运算;再经过一个用σ表示的Sigmoid激活函数,得到通道注意力权重系数Mc;最后将输入特征F1与通道注意力权重系数Mc进行元素级相乘运算,得到输出后的通道注意力特征F2。
空间注意力机制主要关注图像中的人类区域,同时更加关注人类姿态的可见关键点位置。该注意力主要是将特征图在通道维度上进行压缩,通过两种池化将得到不同的特征映射先拼接再降维,最终经过元素级运算得到空间级特征。
空间注意力模块(Spatial Attention Module,SAM)如图3。空间注意力机制可以表达为

图3 空间注意力模块结构图
[FAvg2,FMax2]=AvgPool(F2)⊕MaxPool(F2),
(5)
Ms=σ(f3×3[FAvg2,FMax2]) ,
(6)
F3=Ms⊗F2。
(7)
其中,本模块的输入特征为通道注意力输出的特征F2。首先将输入特征图分别经过平均池化和最大池化得到特征FAvg2、FMax2;再将两个特征图在通道维度上进行拼接操作;然后将其输入到大小为3×3的卷积层f3×3中,对特征通道进行降维操作;再经过一个用σ表示的Sigmoid激活函数,得到空间注意力权重系数Ms;最后将输入特征F2与空间注意力权重系数Ms进行元素级相乘操作,得到输出增强后的空间注意力特征F3。
由于因人体姿态本身存在的关键点自遮挡现象,使得图像丢失部分关键特征信息,本文采取将通道注意力和空间注意力结合的特征增强方法,集成到CNN中,以捕获特征之间的通道和空间相关性,学习使用全局信息来选择性地强调信息丰富的特征,并抑制无关特征,从而加强CNN生成的表示,进而提高人体姿态估计网络处理自遮挡问题的性能。
1.3 特征增强方法
为解决人体姿态自遮挡的问题,本文引入轻量级的混合注意力机制CBAM模块[14]作为特征增强方法,以实现双重注意力的作用,进一步增强特征提取网络的表达能力。CBAM模块将通道注意力模块和空间注意力模块以串行的方式插入到ResNet-50每个Bottleneck Block层,能够满足本文理论需求。构造新残差注意力网络如图4。
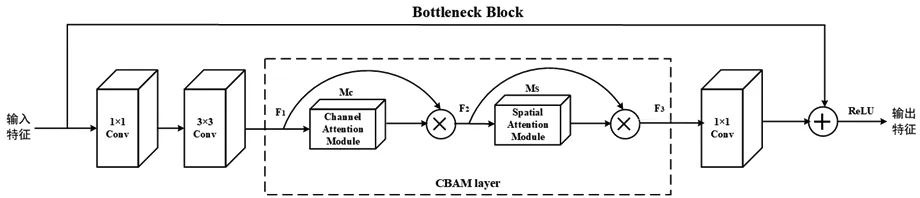
图4 残差注意力网络结构图
将CBAM模块放置在3×3卷积层之后,由于该卷积层拥有较少的通道,相应地该模块引入的参数量也减少了。通过这种改进,可以自适应地提取重要特征的同时抑制或忽视不必要的特征,增强CNN的特征提取能力和对自遮挡任务的适应能力。
1.4 PEANet网络
PEANet网络的基本思想是将残差注意力网络替代原始深度残差网络ResNet-50的每个Bottleneck Block层,作为新的主干网络处理输入图像。连接层中残差分支采用的卷积均增加了同时关注信道和空间关系的混合注意力机制模块,相比于SENet只关注通道注意力机制,可以取得更好的结果。采用注意图特征增强网络加强对深度信息的预测。输入图像经姿态估计主干网络得到增强的输出特征定义为
Y=H(X) 。
(8)
式中:X表示输入特征量;H表示主干网络中普通卷积和混合注意力操作;Y表示主干网络输出的增强特征图。PEANet网络结构图如图5。
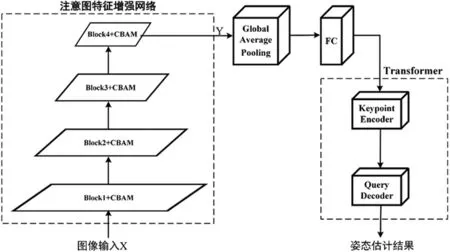
图5 PEANet网络结构图
PEANet的目的是在经过图像处理后的单人图像中预测人体关键点坐标。首先将结合通道注意力和空间注意力的混合注意力模块与现有的主干网络ResNet-50堆叠在一起,构成新的注意图特征增强网络。通过在每一层的局部感受野内融合空间和通道信息来构建信息特征,提高整个特征层次的空间编码质量来加强CNN的表征能力,自适应地重新校准通道和空间特征响应,提取多级特征映射;然后将增强后的输出特征送入全局平均池化(Global Average Pooling,GAP)层,可快速提取全局性的上下文信息,有利于减少大量参数,防止过拟合;再经过一个全连接(Fully-Connected,FC)层,通过主干网络输出获得密集的特征映射预测粗糙的关键点坐标;最后送入Transformer的关键点编码器和查询解码器网络中,以获得关键点的最终特征,每个特征被送入到线性层中,预测相应的关键点坐标,得到最终的姿态估计结果。
注意图特征增强网络输出的特征为Transformer网络提供更好的输入,有助于网络间的信息传递,从而解决因人体姿态产生的自遮挡问题,提高姿态估计网络对人体关键点的定位能力。
2 实验结果分析
2.1 实验设置
本实验的硬件配置为一张NVIDIA GeForce RTX 2070 Super显卡,在Ubuntu16.04操作系统中,使用Python编程语言,采用Pytorch 1.7.0版本的深度学习框架对网络模型进行训练和验证测试。采用COCO 2017公开数据集,其中针对人体姿态估计任务的每个人体目标标注17个关节点的信息。在仿真中使用COCO训练集中7 392张图片进行训练,使用COCO验证集中的1 250张图片进行验证和测试。在COCO数据集下,训练采用AdamW[15]优化器,批尺寸设置为4,迭代次数为325次,设置初始学习率为1.25e -4,衰减权重为1.25e -5。
2.2 评价指标
本文使用的是COCO 2017公开数据集,以关键点相似性(object keypoint similarity,OKS)[16]作为人体姿态估计的评价标准,它是通过计算人体关键点的位置距离来检测关键点的相似度。该指标定义为
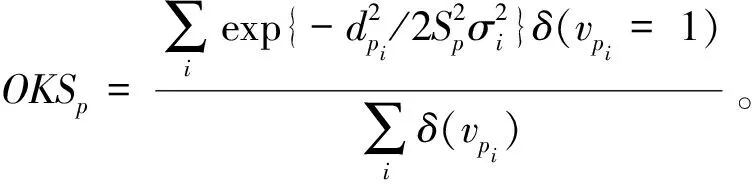
(9)
式中:p为真值人的ID;i为关键点的ID;dpi为每个人的真实关键点位置与预测关键点位置的欧氏距离;Sp为当前真值人所占面积的平方根;σi为第i个关键点的归一化因子;vpi为第p个人的第i个关键点是否可见;δ为克罗内克函数,满足两个自变量相等时取值为1,不满足时取值为0。
采用人体关节点预测的平均精度(average precision,AP)(OKS=0.50,0.55,…,0.95时10个预测关键点精度的均值)作为主要评价指标,以平均召回率(average recall,AR)(OKS=0.50,0.55,…,0.95时10个预测关键点召回率的均值)作为辅助评价指标。AP表示每个关键点在测试数据集上,检测结果的平均精度。当给定一个OKSp的阈值s时,算法精度(AP@s)可定义为
(10)
式中:p为真值人的ID;δ为克罗内克函数;s为阈值;OKSp为式(9)中所求数值,通常在[0,1]的范围内。当OKSp大于设定阈值s时,表示预测的人体关键点正确,否则预测错误。
2.3 仿真结果与分析
采用COCO 2017数据集进行了实验仿真验证,处理模型的输入图像尺寸均为256×192,以便于与其他方法进行对比。在相同的输入图像尺寸、迭代周期和学习率下,对比了PEANet与其他三种姿态估计网络模型的实验结果。实验结果对比结果见表1。
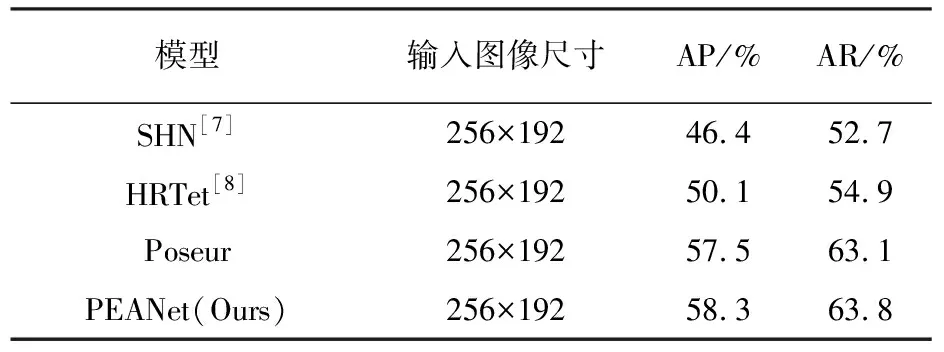
表1 实验结果对比
通过在原网络中插入CBAM模块,可以使PEANet更加关注与人体姿态相关的特征。其中,通道注意力模块可以自动学习每个通道的重要性,使网络更加关注对姿态估计有贡献的通道,抑制对无关信息的响应;空间注意力模块可以自适应地调整网络对不同空间位置的关注程度,使网络更加关注对姿态估计有贡献的区域,提高对关键点的定位精度。通过表1的仿真结果表明,本文提出网络模型PEANet在主要评估指标上相比于原网络模型均有一定的提升,平均精度(AP)提升了0.8%,平均召回率(AR)提升了0.7%,均取得了较好的准确度。因此,可以说明本文在网络结构设计中加入用于增强卷积神经网络性能的混合注意力机制的有效性,效果提升显著。本文引用的模块能够自适应地调整网络对不同通道和空间位置的关注程度,使网络更加适应不同姿态的变化和复杂背景的干扰,有利于提升关键点自遮挡的姿态估计精度[17]。
2.4 可视化结果
为四种网络模型在人体姿态估计实验中可视化的预测结果如图6。为便于观察姿态关键点的定位,本文已对输入图像进行适当的图像处理。
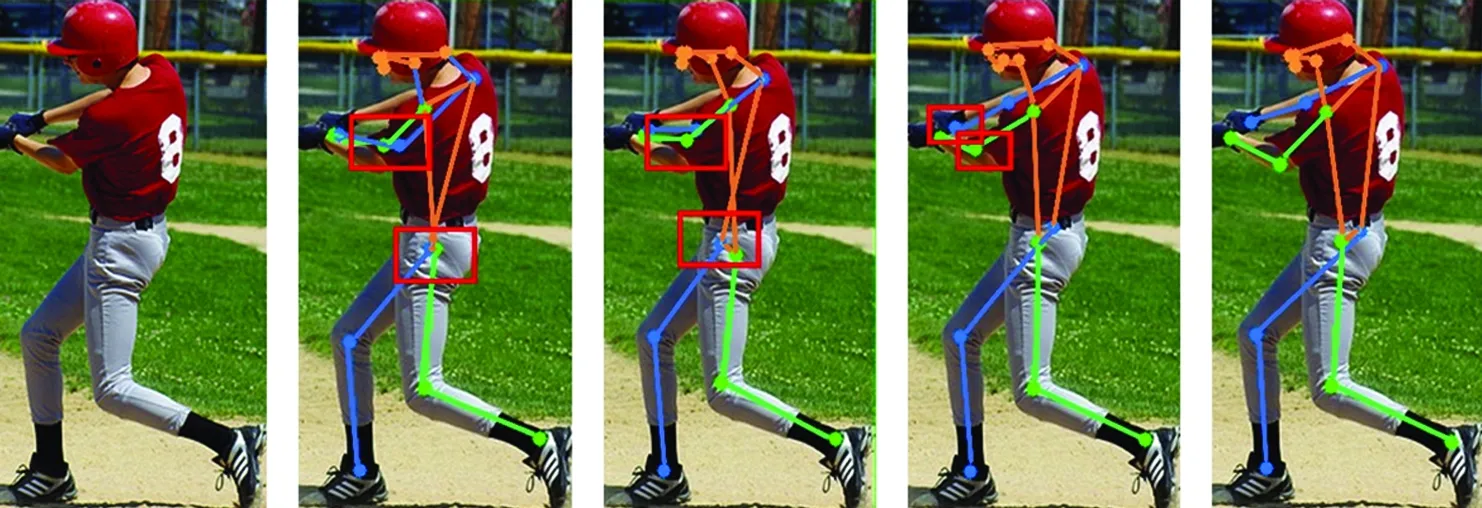
a)原图 b)ShuffleNetv2 c)MobileNetv2 d)Poseur e)PEANet图6 在四种网络模型下的可视化对比
其中图6a为输入原图,图6b~6e分别为SHN、HRTet、Poseur和PEANet模型下输出的姿态,这四种网络模型均为同一数据集和同一输入图像尺寸下的测试结果。从图6b和图6c中可以明显看出,这名棒球运动员在遮挡的右臂和右腿部位均存在关键点误检的现象(用方框表示)。同样对比图6d和图6e的姿态可视化结果,也可以明显地看出本文所提方法在人体关键点识别的准确性上更优于原方法。因此,相较于其他三种方法,当2D人体图像出现关键点自遮挡的现象时,利用本文方法能够较为准确地检测出关键点的位置,可以提高人体姿态识别的准确性。
3 结 语
针对姿态估计网络中因人体姿态本身导致关键点自遮挡问题,提出注意图特征增强网络。在主干网络的每个Bottleneck层添加混合注意力机制,既能通过通道注意模块帮助网络更好地捕捉到重要的特征通道,以增强遮挡目标的特征表达,又能通过空间注意模块帮助网络更好地对重要空间位置特征的关注,以助于遮挡部位的特征恢复和目标定位,进而能够提取更加准确的深度特征图。与原网络模型相比,本文所提网络提高了姿态关键点定位的准确性,对2D人体姿态关键点的检测有显著提升能力,能够获取到较好的姿态估计结果,适用于家庭监护和天眼监控等应用场景。
