基于改进遗传算法的计算卸载算法
2023-11-23李政祥田锦
李政祥,田锦
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.金陵科技学院 网络与通信工程学院,江苏 南京 211169)
随着无线通信和人工智能的快速发展,在物联网时代,车辆变得更加互联和智能[1-2].接踵而至的就是移动互联网及物联网流量需求的指数爆炸式增长,用户会对信道的带宽、时延、可靠性等网络指标有更深的要求,一些计算比较复杂或者数据比较大的任务对设备提出了更多的需求.在针对一些大型的密集型任务时,往往会出现掉电严重和执行速度慢等问题.随着这些新技术和新思想的产生,车辆的资源受限与计算资源需求增长之间的矛盾也随之而来.
计算卸载是一种将计算任务从终端设备卸载到云服务器或边缘服务器的技术,可以提供更好的计算性能和用户体验.随着移动设备的普及和计算任务的复杂化,计算卸载算法的研究变得尤为重要.传统的计算卸载算法通常采用启发式算法或基于规则的方法进行任务的分配和调度.但是,这些方法往往依赖于经验和静态的策略,没有办法及时针对环境动态的变化.为了解决这个问题,相关研究人员开始利用一些优化算法尝试解决计算卸载的问题.遗传算法就是一种优化算法,这个算法通过克隆自然的选择、遗传的交叉和变异等操作,对计算卸载中的解进行优化.基于改进遗传算法的计算卸载算法寻找更有效的解和卸载策略,来提高计算任务的分配和调度性能.这种改进包括寻找一个合适的适应度函数、卸载策略和引入多目标优化策略等.
研究基于改进遗传算法的计算卸载算法,可以利用合理的卸载策略对任务进行卸载,并且提高任务的效率和性能,减少终端设备的能耗,给用户提供良好的使用体验.这是一个具有挑战性的研究领域,目前有越来越多的研究者在这一方面进行探索和研究.如文献[3]引入自适应控制参数的策略,根据每一代的适应度动态调整算法的参数,加速算法的收敛速度.文献[4]结合粒子群优化算法和遗传算法计算卸载问题,通过改进交叉和变异算子的设计,增加算法的多样性和搜索能力,提高了算法的效果.文献[5]采用自适应调整的方法,自动优化算法的参数,避免了手动选择参数的困扰,并提高了算法的性能.文献[6]提出了一种混合遗传算法与粒子群优化算法相结合的方法,以加快算法的收敛速度.文献[7-9]考虑了设备卸载决策和资源的分配,将所有能耗以最小化消耗为目标进行卸载.文献[10-11]通过衡量所有任务卸载的计算时间,将任务块最小化,减少卸载时延.
此外,算法的调度策略也会导致计算的迭代次数增加、收敛速度过慢、能耗增加、时延增大等问题.为了解决计算卸载中时延的问题,本文提出了一种改进遗传算法的计算任务卸载算法,改进的遗传算法旨在处理算法收敛速度慢的问题.在这个基础上,引入纵横交叉算法改进和优化边缘计算的任务卸载问题.纵横交叉算法是通过水平交叉和垂直交叉对边缘计算任务卸载的解进行改进和优化.该算法利用了纵向和横向的交叉操作来提高了解的质量.水平交叉和垂直交叉的结合能够更好地优化计算任务的分配和调度,进一步提高算法的性能和效率[12].
1 系统模型
1.1 系统场景
在一条只能单向通行的公路上按照每隔一定距离布置n个边缘服务器(Edge Server,ES)在该模型中,设边缘服务器之间的距离为d,假设车辆在该道路上正常匀速行驶,且车辆的基本信息可以发送到道路的边缘服务器上面,具体的系统场景如图1所示.
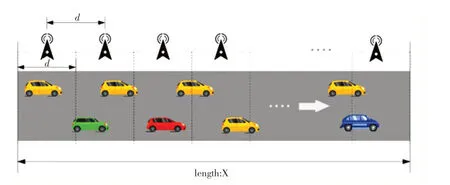
图1 系统场景
在本方案中,车辆任务可以在车辆自身或者路边的边缘服务器上进行处理,当任务数据量过大或者车辆本身的资源不够的时候,会将任务传输给路边基站或者附近空闲车辆处理,经过计算再返回给车辆.在这个过程中消耗的时间比较长,会有很严重的能量损耗.因此本文考虑将计算任务进行分块处理,当车辆行驶过程中,在不影响任务完成的情况下,将任务块分发给路侧附近的边缘服务器,等结果计算出来之后再返回车辆.随着车辆的行驶,未完成的任务块可以在之后距离车辆近的边缘服务器进行卸载,直到完成任务计算.该方案充分利用边缘服务器为车辆任务提供适时计算服务.
1.2 计算卸载模型
设车辆v需要卸载的任务为M,车辆的集合是N={1,2,…,i,…,n},每个设备只能生成一个任务集Ti,并且每个任务具有以下属性集Si={di,ci,fi,resi,deadi,Ai},其中di表示任务的数据比特位大小,ci表示每字节需要的时钟周期数,fi表示本地设备的时钟频率,resi表示任务计算所需要的资源,deadi表示任务的截止时间,Ai表示任务的优先级,任务数据量越大,优先级越高,任务截止日期越早,优先级越高.任务优先级的数学定义如下:
1.2.1 本地处理
由于移动车辆具有计算能力,如果车辆有丰富的计算资源,则一些任务可以在本地进行处理[13],设本地处理任务的设备集为GL,如果任务Ti在本地执行,i∈GL,本地处理的任务时间只包括计算时间,不包括传输时间.因此任务Ti在本地处理所花费的时间tli大小为:
另外,将车辆i在一个时钟周期内所消耗的能量定义为,因此任务Ti在本地处理过程中所消耗的能量估计为:
1.2.2 边缘计算模型
如果本地移动设备没有足够的资源满足任务所需的资源量,则以计算卸载的形式将任务转移到时钟服务器.需要考虑三方面的时间消耗,第一是需要考虑车辆任务传输到路边边缘服务器的时间,第二是任务在边缘服务器上计算花费的时间,最后是边缘服务器将计算结果返回给车辆的时间.将在ES服务器上处理任务的数据集定义为GR,如果任务Ti被卸载到ES服务器上进行处理,那么i∈GR.
假设边缘网络由m个ES服务器组成,用集合M={1,2,…,j,…,m}表示,并且集合具有以下属性集S={cj,fj,resj,Bj},其中cj代表着ES服务器计算一个比特所需要的时钟周期数,fj表示ES服务器的时钟频率,resj表示ES服务器拥有的资源量,B表示ES服务器计算一个比特人物所需的处理时间,B值越小,说明ES服务器的计算能力越强,即优先级越高.B的定义如下:
接下来,就要考虑将优先级更高的任务卸载给计算能力更强的ES服务器.
在计算卸载过程中,需要一定的传输时间.根据香农定理,信息源的信息速率小于或者等于信道容量,那么,在理论上存在一种方法可使信息源的输出能够以任意小的差错概率通过信道传输[14].任务卸载到ES服务器时的最大上行传输速率定义为:
其中,B是车辆i和基站k之间的通信带宽,为车辆i的传输功率,h2为车辆i与基站k之间的无线信道增益,σ2表示边缘服务器k的噪声功率为卸载时的干扰功率.此时,传输时间为:
因此,将任务Ti卸载到ES服务器j执行所需的总时间如下:
除此之外,ES服务器j的能源消耗在一个时钟周期内被定义为,因此任务Ti卸载到ES服务器j上能量消耗的执行费用估计为:
处理一个任务的总时间包括传输时间和计算时间,返回时间忽略不计.因此处理任务的总时间Ttotal为:
处理所有任务的总能量消耗Etotal表示为:
2 改进的遗传算法
遗传算法在计算卸载问题中得到过广泛的应用.第一,通过适应度函数对每个个体的优劣程度进行评估,再根据评估结果指导后续群体中的个体进化,比如卸载响应的时间、卸载能耗等优化卸载策略.第二,遗传算法能够在解的范围内进行全方面搜索,特别是在一些复杂、参数较多的问题中.这种能力可以帮助车辆找到更好的卸载策略,从而降低能耗.但是现有的遗传卸载算法也存在一些不足.首先,在计算开销上,遗传算法需要在大量的群体上进行迭代,从而导致计算资源被浪费在大量的迭代计算上.其次,适应度函数的设计对遗传算法的效果也有很大的影响,在特定的情况需要选择特定的适应度函数来确定优秀结果的标准.最后,虽然遗传算法具有全局搜索的能力,但是算法在局部搜索方面的表现比较弱.所以在计算卸载的应用中,通过遗传算法得到的解可能只是局部解.
针对任务卸载会陷入局部解的情况,本文提出一种基于纵横交叉的改进遗传算法.传统的交叉操作只是在染色体周围相邻的位置进行交叉操作,改进的纵横交叉中引进了横向搜索,这样可以使染色体和任意位置进行互换,增加了可行解的多样性.传统的染色体只能在同一个染色体内进行基于互换组合操作,纵横交叉算法的引入使基因组合可以跨越多个染色体,这使得基因的组合更加灵活并有助于找到全局最优解.总的来说,将纵横交叉算法引入到遗传算法中可以增加解的多样性,以及有利于搜索全局最优解.图2为改进遗传算法流程图.

图2 改进遗传算法流程
2.1 初始化
种群由M条染色体组成,每条染色体对应一种卸载策略.设将车辆的一个任务当作一条染色体,染色体上的每个基因对应着一个子任务,通过对基因的编码,使用0、1和2来分别表示子任务在本地执行、在边缘服务器端执行和在云端执行.
2.2 适应度函数
在达尔文进化论中,适应度指的是生物的个体适应环境和繁衍后代的能力.适应度函数是用来评价个体好坏的标准,函数的值越大,个体越容易在进化中被保留适应度函数.因为时延越小,速度越快,性能越好,因此取式(9)的倒数作为适应度函数fit.该函数是计算卸载消耗能耗的倒数,值越小说明能耗消耗越大,当值越大的时候,说明个体在进化中更趋向成功,属于优秀个体.
2.3 选择
在选择阶段,染色体进行重组,通过交叉和变异的操作产生下一代种群.这个操作是基于轮盘赌的方法,选择用于重组的概率为1.
2.4 纵横交叉
交叉操作就是将两个染色体,进行交叉组合,以产生更高质量的后代.纵横交叉(Crisscrossoptimization algorithm,CSO)是一种基于种群的随机搜索算法.纵横交叉通过两种不同的交叉方式来解决一般智能算法中存在的局部最优问题.纵横交叉包括横向交叉和纵向交叉.染色体的基因通过交叉会产生新的染色体,每次交叉操作得到的解称为中庸解(MShc,MSvc).为了更好地结合这两种交叉方式,引入竞争算子,使得它们能够有机地结合在一起.
2.4.1 横向交叉操作
横向交叉是指在纵横交叉算法的横向搜索阶段,通过利用当前最优解,将其传递给相邻的子问题,以促进全局最优解的发现.具体而言,在每个子问题中,纵向搜索阶段会找到该子问题的一个局部最优解.然后通过横向交叉,将局部最优解传递给相邻的子问题,作为相邻子问题进行横向搜索的起点.
横向交叉的方式如下,假设父代个体粒子X(i)和X(j)的第d维进行横向交叉,则它们产生子代的公式如下:
在上述公式中,r1和r2表示[0,1]之间的随机数,c1和c2是[-1,1]之间的随机数,X(i,d)和X(j,d)分别是父代种群中个体粒子X(i)和X(j)的第d维子代;MShc(i,d)和MShc(j,d)分别是X(i,d)和X(j,d)通过横向交叉产生的第d维子代.
在纵横交叉算法中,横向交叉操作是通过将不同个体粒子的记忆项和群体认知项结合起来,生成新的中庸解,这个过程涉及一些参数和计算步骤,有如下的解释:r1为惯性权重因子,表示个体粒子对自身记忆项的重视程度.r1×X(i,d)代表个体粒子X(i)的记忆项,即个体粒子在当前状态下的最优值,这个项体现了个体对自身经验的重要性.(1-r1)表示个体粒子对群体认知项的重视程度.(1-r1)×X(j,d)代表个体粒子X(j)的群体认知项,即个体粒子之间相互影响的信息,这个项体现了个体之间的相互学习和合作.c1为 学习 因子,用于调节个体粒子和群体认知项之间的差异.c1×(X(i,d)-X(j,d))可以增大搜索区间,在边缘寻优这个项帮助个体粒子探索更广泛的解空间.
横向交叉操作完成后,得到的中庸解MShc(i,d)和MShc(j,d)需要与父代粒子X(i)和X(j)的适应度进行比较.只有适应度更好的中庸解才会被保留下来,成为占优解DShc,并参与下一次迭代.
2.4.2 纵向交叉操作
纵向交叉是纵横交叉算法中的一种操作,它是针对一个粒子的两个不同维度进行的算数交叉.由于不同维度的取值范围可能不同,所以在进行交叉之前需要对这两个维度进行归一化处理.为了解决已经陷入维度局部最优而停滞的问题,同时又不破坏另一个维度的信息,纵向交叉操作每次只产生一个子代粒子,并且只对其中一个维度进行更新.
假定粒子X(i)的第d1维和第d2维是参与纵相交叉,根据公式(14)产生中庸解MSvc(i,d1)
式中,r∈[0,1];MSvc(i,d1)是个体粒子X(i)的第d1维和第d2维通过纵向交叉产生的第d1维后代.
式(14)中的第一项是粒子X(i)的第d1维的记忆项,第二项是粒子X(i)的第d1维和第d2维相互影响,通过惯性权重因子r结合在一起.然后,将中庸解MSvc(i,d1)与父代粒子X(i)的适应度进行比较,较好的解将被保留下来作为占优解DSvc,并参与下一次迭代.通过这种方式,纵向交叉操作在保留粒子当前最优值的同时,还能够引入其他维度的信息,有助于增加搜索的多样性和全局探索的能力.同时,通过适应度的比较,只有更好的解才能被保留下来,以提高算法的收敛性和优化效果.
2.5 变异
变异的目的是防止遗传物质的丢失,维持多样性的重要机制交叉并不能保证进入新的搜索空间,因此通过变异的随机变化有助于这两种交叉方式有机地结合起来:每次交叉操作之后都会进入竞争算子与父代进行竞争,只有比父代更优秀的粒子才会被保留下来进入下次迭代,得出的解称为占优解(DShc,DSvc).
在算法迭代多次之后,算法会将适应度不好的染色体淘汰,剩下的染色体留下来作为这一阶段的最优解.这些解的适应度值可以达到预先设置的适应度,以此来当作该部分的卸载方案.
3 仿真与评估
本章对于提出的基于纵横交错的遗传算法(Genetic Algorithm,简称GA)算法性能进行了仿真实验.
3.1 参数设置
仿真实验主要考虑车辆在进行计算任务是否需要计算卸载,以下为该实验的参数.

表1 实验参数
3.2 实验结果和分析
在本次实验中,local表示任务在本地执行,没有边缘设备的参与;GA 表示通过遗传算法对计算任务进行卸载处理;im-GA 表示通过改进过的GA 算法对计算任务进行卸载处理.
3.2.1 迭代次数对实验的影响
通过不同次数的迭代,可以判断适应度的收敛过程.实验通过在[0,50]进行次数迭代.随着迭代次数的增加,通过基于遗传算法进行卸载的算法,个体适应度随着迭代次数的增加而增加,通过改进遗传算法的卸载算法,个体适应度值逐渐趋向于收敛,由此可以得出结论:当迭代次数在30~50时,求解精度更准确,得到的实验结果会更好,如图3所示.
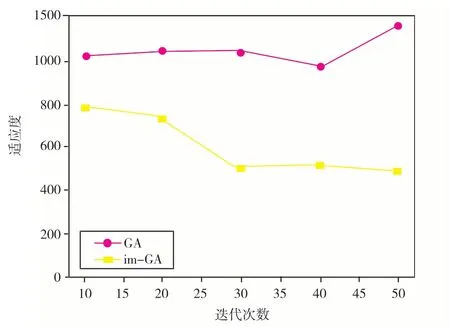
图3 迭代次数对适应度的影响
3.2.2 计算任务的数量对实验的影响
通过对本地卸载、遗传卸载和改进遗传卸载的比较,在不同的任务数量时,适应度的值会随着任务量的增大而增大,通过实验比较,在任务数量增加时,任务的适应度在im-GA 算法中表现最优,本地卸载算法中适应度呈线性增加,与所要求的低适应度不符;遗传算法中适应度增长变快.这说明改进的遗传算法在针对任务数量巨大的情况下有优越性,如图4所示.

图4 任务数量对适应度的影响
3.2.3 传输数据大小对实验的影响
本节仿真了任务传输数据大小不同时对实验造成的影响.当任务卸载策略相同的时候,数据传输越大,传输时间就会越长,整个任务的执行就会变得越久.同样的传输能耗也越大.本地计算、GA 和改进GA 在相同情况下对比,如图5所示.
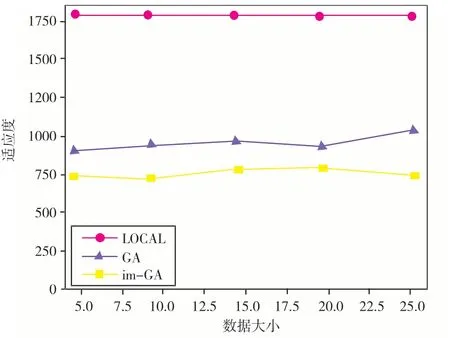
图5 传输数据大小对适应度的影响
4 结论
为了解决移动边缘计算中传统的计算卸载资源不足的问题,本文提出一种新的基于纵横交叉的遗传卸载算法.实验开始对任务进行编码、计算适应度、选择、交叉、变异操作计算任务调度问题,使得任务可以一部分在车辆自身卸载,一部分可以在ES服务器上进行计算然后返回.通过对迭代次数、任务量、任务大小等参数的对比,可以看出本文算法在适应度收敛方面有显著的提升.
