一种基于梯度残差网络的红外与可见光图像融合算法
2023-11-22徐慧琳于波
徐慧琳,赵 鑫,于波
(安徽理工大学 人工智能学院,安徽 淮南 232001)
红外传感器通过捕获物体发出的热辐射信息成像,形成的红外图像基于辐射差异将目标与背景区分开,突出显著目标,但其容易忽略纹理信息并易受到噪声影响.可见光传感器通过捕获物体的反射光信息成像,形成的可见光图像通常包含丰富的纹理和结构信息,但其受限于光照条件[1].因此,将可见光图像与红外图像融合,有利于二者取长补短,获得更加完善的图像描述,并可用于高级视觉任务的预处理模块,例如目标检测[2]、目标跟踪[3]和语义分割[4].
近年来,深度学习以其强大的特征提取和表达能力主导了计算机视觉领域发展,图像融合领域的研究者探索了大量基于深度学习的算法.现有的基于深度学习的图像融合算法主要分为3类:基于自编码器(Auto encoder,AE)的图像融合框架、基于卷积神经网络(Convolutional neural network,CNN)的图像融合框架和基于生成对抗网络(Generative adversarial network,GAN)的图像融合框架.LIU等[5]在基于自编码器的融合框架中引入边缘引导的注意力机制,将特征学习模块与融合学习机制级联在一起.JIAN等[6]设计了一种具有残余块网络的对称AE网络,网络中卷积层生成的所有特征完全保留了每个级别的信息,都融合到最终结果中.俞利新等[7]设计了一种无监督端到端的AE 网络模型,图像特征提取模块采用结构重参数化方法,同时引入注意力机制,减小了冗余信息对融合结果的干扰.基于CNN 的图像融合框架算法依靠设计的网络结构实现特征提取、特征融合和图像重建.LIU等[8]提出一种基于网络架构搜索的图像融合方法,能够针对不同融合任务的特点,自适应地构造高效且有效的特征提取、特征融合以及图像重建网络.LI等[9]提出一种基于元学习的深度框架,该框架可以接受不同分辨率的源图像,并仅使用单个学习模型即可生成任意分辨率的融合图像.基于GAN 的图像融合框架通过判别器来迫使生成器生成的融合结果在概率分布上与目标分布趋于一致,从而实现特征提取、融合和图像重建[10].MA等[11]在FusionGAN 中首次将图像融合问题定义为生成器与判别器之间的对抗博弈,随后又提出利用双判别器维持不同模态间的信息平衡,并更好地约束融合结果的概率分布.在此基础上,LI等[12]将注意力机制注入基于GAN 的图像融合框架中,以促使生成器和判别器更关注那些重要区域.现有方法虽然可以生成融合结果较好的图像,但是在提取图像细粒度细节特征方面效果不佳.另一方面,现有算法在提高视觉质量和评估指标的同时忽略了满足高级视觉任务的需求.
针对上述问题本文提出一种用于红外和可见光图像的语义信息感知图像融合网络(Semantic information aware fusion network,SIAFusion).该网络基于CNN 框架,在特征提取阶段设计一组基于梯度的残差模块(Gradient residual block,GRB),该模块由主流部分和残差流部分组成.主流部分使用普通卷积操作提取图像浅层特征,针对红外图像和可见光图像的特性在残差流部分引入两种不同的梯度算子,有效提取红外图像边缘信息和可见光图像细粒度细节特征.为了使融合图像包含更多语义信息,通过引入一个用于构建语义损失的分割网络指导网络的训练.同时,本文建立了一个标准的夜间红外图像语义分割数据集——红外夜间语义分割数据集(Night infrared semantic dataset,NISD).
1 网络结构
1.1 SIAFusion网络架构
网络架构图如图1所示,SIAFusion网络架构由特征提取器和图像重建器两部分组成,红外图像与可见光图像同时输入网络,首先分别经过由一组卷积核大小为3×3的普通卷积层和两组GRB模块组成的特征提取器,其中考虑提取红外图像和可见光图像的特征不同,GRB模块被设计为两种,分别为GRB_VIS模块和GRB_INF模块.之后将提取的红外图像特征与可见光图像特征进行级联融合,并送入由三组卷积核大小为3×3的普通卷积层和一组卷积核大小为1×1的普通卷积层组成的图像重建器,实现特征聚合和图像重建.最后输出融合图像.
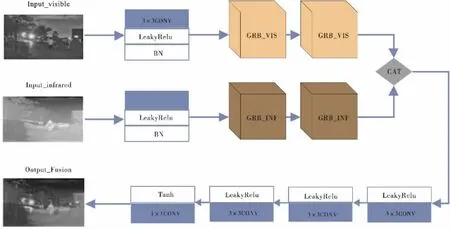
图1 SIAFusion网络结构图
1.2 特征提取器
为解决现有算法无法有效提取红外图像边缘信息和可见光图像细粒度细节特征的问题,本文构建了一组基于梯度的残差模块GRB,并将其部署在SIAFusion网络特征提取器中,该特征提取器由一组卷积核大小为3×3的LeakyRelu卷积层和两组GRB模块组成.
GRB模块由主流部分和残差流部分组成.主流部分布署了两组卷积核大小为3×3的LeakyRelu卷积层和一组卷积核大小为1×1的普通卷积层,用于提取图像浅层特征,残差流部分采用两种不同的梯度算子分别提取红外图像边缘信息和可见光图像细粒度细节特征.通过将主流和残差梯度流的输出逐元素相加,之后经过一组卷积核大小为1×1的普通卷积层消除通道差异,再与浅层特征进行拼接操作,最后作为特征提取器的输出.GRB模块的网络结构如图2所示.针对可见光图像采用Prewitt算子进行细粒度特征提取,针对红外图像采用Sobel算子进行边缘信息提取.

图2 GRB模块
GRB模块提取特征过程用公式可表示为:
其中,Fi表示GRB模块的输入特征,Conv(·)表示卷积运算,Convn(·)表示n级联卷积操作.在本文中,n设置为2,"表示梯度算子.在GRB_VIS模块中,残差流采用Prewitt算子作为梯度算子提取可见光图像特征图的边缘细节信息.在GRB_INF模块中,残差流采用Sobel算子作为梯度算子来提取红外图像特征图的细粒度细节信息.此外,表示逐元素求和操作.GRB模块将可学习的卷积特征与梯度大小信息聚合在一起.
特征提取器过程用公式可表示为:
其中,Fir和Fvi表示经过特征提取器后的细节特征,Iir和Ivi表示特征提取器的红外和可见光图像输入.
1.3 图像重建器
SIAFusion网络的图像重建器由三组串联的卷积核大小为3×3的普通卷积层和一组卷积核大小为1×1的普通卷积层组成.所有3×3卷积层均采用LeakyRelu函数作为激活函数,而1×1卷积层的激活函数为Tanh函数.经过特征提取器的红外图像特征与可见光图像特征首先通过级联策略进行融合,随后将融合后的特征输入图像重建器,完成特征聚合和图像融合.
融合操作用公式可表示为
其中,C(·)表示通道维度中的级联,Ff表示融合后的特征.
图像重建操作用公式可表示为
其中,RI(·)表示图像重建操作,If表示从融合特征Ff中恢复的融合图像.
1.4 损失函数
本文采用由TANG等[13]提出的内容损失(Content Loss)和语义损失(Semantic Loss)组成的联合损失策略约束融合网络.联合损失网络框架如图3所示,其中采用的图像分割网络为Bisenet轻量级语义分割网络[14].
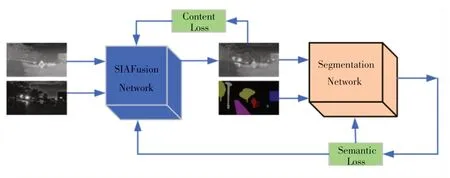
图3 联合损失网络框架
联合损失公式如下
其中,Lcontent表示内容损失,Lsemantic表示语义损失,β是表示语义损失重要性的超参数.
1.4.1 内容损失
内容损失由强度损失和纹理损失组成,公式如下所示
其中,Lintensity表示强度损失,约束融合图像的整体表现强度,Ltexture表示纹理损失,使融合图像包含更细粒度的纹理细节,α用以平衡强度损失和纹理损失.
强度损失用于衡量融合图像和源图像在像素级别的差异,公式如下
其中,H和W分别表示输入图像的高度和宽度,max(·)表示最大像素值选择策略,‖·‖1表示l1范数.
纹理损失用于使融合图像包含更细粒度的纹理信息,公式如下
其中,"表示Sobel算子,|·|表示绝对值运算.
1.4.2 语义损失
通过在训练过程中引入语义分割网络,利用语义损失充分提升融合图像的语义信息.语义损失由主要语义损失和辅助语义损失组成,公式如下
其中,Lmain表示主要语义损失,Laux表示辅助语义损失,λ用于平衡主要损失和辅助损失.
主要语义损失公式如下
其中,Lso∈H×W×C表示从语义标签转换来的独热向量,Is∈(1,C)H×W表示语义分割网络输出结果,H、W和C分别表示图像高度、宽度和语义标签类别数量.
辅助语义损失公式如下
其中,Isa∈H×W×C表示语义分割网络辅助分割结果.
2 数据集
本文建立了一个夜间红外图像语义分割数据集NISD,包括人、建筑物、门、树、道路、自行车、路灯、交通锥和背景9个语义标签.NISD 数据集包括1055对红外和可见光图像.所使用的数据集划分为训练集和测试集,其中训练集包含929对图像,测试集包含126对图像.
数据集部分图片展示如图4所示.
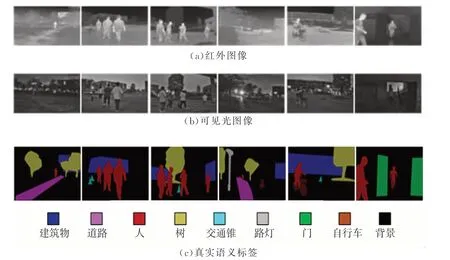
图4 NISD 数据集部分图像展示
本文采用HIKVISION 热成像双光谱半球摄像机(DS-2TD1217-3/PA)在夜间场景下的不同视角以及不同遮挡度等条件下获取数据集.标注工具为开源标注工具labelme,在标注完所有图片后,进行第二轮检查,剔除不标准的图片,最终筛选出1055张可用且标注良好的标签图.各类标签数量如图5所示.
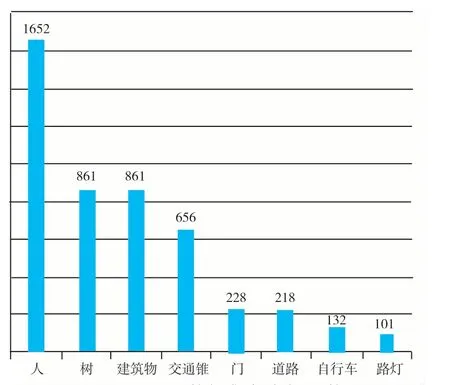
图5 NISD 数据集各类标签数量
3 实验内容
3.1 参数设置
本文算法基于PyTorch框架,实验硬件配置如表1所示.

表1 实验硬件配置
图像融合网络训练初始学习率设置为0.001,训练轮次设置为10,采用梯度下降优化算法,动量和权重衰减分别设置为0.9和0.0002.块大小设置为2,输入图像的大小缩放为1024×1024.
3.2 评价指标
本文选择3 个评价指标来评估网络性能:均方误差(Mean Square Error,MSE)、峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、平均梯度(Average Gradient,AG)[15].
MSE用于衡量融合图像和理想参考图像之间的差异,MSE越小融合图像质量越好.计算公式如下
其中,n表示样本数量,xi表示第i个样本的预测值,yi是模型对第i个样本的标注值.
PSNR 是融合图像中峰值功率与噪声功率的比值,反映融合过程中的失真情况.PSNR 越大,说明融合图像与源图像越接近,即融合产生的误差越小.计算公式如下
其中,F表示融合图像.
AG主要反映图像中细节的区别和纹理变化.通常情况下,AG越大,图像的清晰度越高,融合质量越好.计算公式如下
其中,F表示融合图像,M和N分别表示图的宽和高。
3.3 融合性能结果与比较
为测试网络性能,选取30组红外和可见光图像进行融合实验,并将融合结果与其他3种基于深度学习的图像融合算法的实验结果进行比较,其他3 种算法分别为基于GAN 网络的图像融合算法FusionGAN、基于CNN 框架的NestFuse[16]网络和SeAFusion网络.表2列举了本文算法与以上3种算法的性能比较.
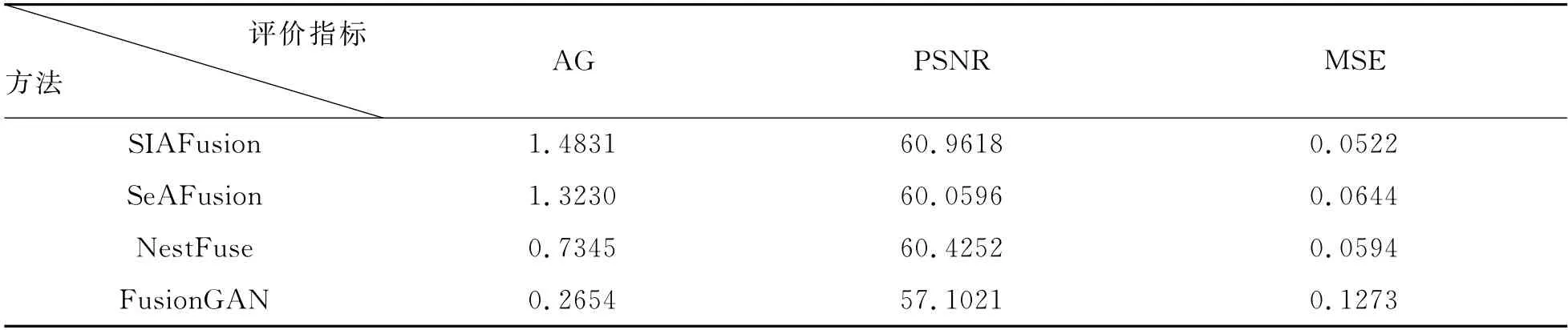
表2 融合性能比较数据表
表2给出了4种算法对测试集中30组图像融合得到的3个客观评价指标的平均值,在不同算法中,评价指标AG 和PSNR 值越大越好,评价指标MSE 值越小越好.从表2可看出,本文提出的算法在3个指标值上均取得了最好的结果,进一步验证本文算法提取的红外图像细粒度特征和可见光图像边缘信息均比其他3种算法更有效.
图6展示了部分测试集中的可见光图像(a)与红外图像(b).可以看出,(a)相较于(b)包含更丰富的纹理和结构信息,而(b)相较于(a)则包含更突出的目标信息.(c)、(d)和(e)分别为NestFuse、SeAFusion和SIAFusion 3种网络将(a)和(b)进行融合后的输出图像,可以看出本文所提出的SIAFusion算法相较于其他算法可以输出更清晰的融合图像,更多地保留了(a)中的纹理信息以及(b)中的目标信息和细粒度特征,同时融合了高级视觉任务所需要的更多特征.

图6 测试集结果比较
3.4 分割性能结果与比较
本文采用Deeplabv3+语义分割模型测试生成的融合图像分割性能[17].语义分割性能测试训练集和测试集的划分与本文融合网络数据集划分保持一致.首先,使用3种图像融合网络SIAFusion、NestFuse和SeAFusion将NISD 数据集中的红外图像和可见光图像进行融合,生成3种融合图像数据集;其次,将NISD 中的红外图像数据集、可见光图像数据集以及经过算法生成的3种融合图像数据集送入语义分割网络中训练并测试.
分割性能评价指标选取了语义分割目前常用的MIOU、MPA 及PA[18],表3给出了5种图像经过Deeplabv3+分割后得到的3个评价指标值.可以看出,采用本文网络生成的融合图像经语义分割网络分割后测得的所有评价指标均为最好.相较于其他2种图像融合算法,本文提出的算法包含更多的语义信息,可以有效提升图像细粒度细节特征方面的融合效果,满足高级视觉任务的需求.
4 总结
针对现有图像融合算法在提取图像细粒度细节特征方面效果不佳以及难以满足高级视觉任务需求的问题,本文基于卷积神经网络的基础框架提出了一种语义信息感知图像算法,在该算法中设计了一种基于梯度的残差模块GRB,可有效提取红外图像边缘信息和可见光图像细粒度细节特征,满足高级视觉任务的需求.
