基于弱监督数据集的猪只图像实例分割
2023-11-23王海燕江烨皓马云龙刘小磊
王海燕 江烨皓 黎 煊 马云龙 刘小磊
(1.华中农业大学深圳营养与健康研究院, 深圳 518000; 2.中国农业科学院深圳农业基因组研究所, 深圳 518000;3.华中农业大学信息学院, 武汉 430070; 4.岭南现代农业科学与技术广东省实验室深圳分中心, 深圳 518000;5.农业农村部智慧养殖技术重点实验室, 武汉 430070; 6.农业动物遗传育种与繁殖教育部重点实验室, 武汉 430070)
0 引言
随着生猪养殖规模增大,现代化养殖技术对其帮助越发重要。利用人工智能技术丰富我国智慧农场解决方案,研发生猪养殖过程中的猪只信息智能感知、个体精准饲喂、养殖环境智能调控等核心技术与装备,正成为推动我国生猪养殖业健康发展的关键因素[1-3]。近年来,深度学习的兴起不断推动计算机视觉技术发展,研究者将深度学习引入到猪场猪只个体识别跟踪、姿态行为分类及体尺体重测量等任务中,取得了令人满意的效果[4-13]。
在猪只计数、行为识别、体重体尺测量等任务中,首要任务都是将猪只从图像中分割出来。目前,以深度学习为基础的图像实例分割正逐渐取代传统的机器学习前景背景分离算法,被应用到多数研究中。李丹等[14]通过训练神经网络模型,分割得到图像中猪只的面积以识别猪只爬跨行为;胡云鸽等[15]通过人工标注1 900幅图像制作数据集,在Mask R-CNN[16]中的特征金字塔[17](Feature pyramid network, FPN)模块,使用轮廓边缘特征连接高层特征,极大提升了猪只边缘模糊目标识别的效果,并且能够满足单栏饲养密度为1.03~1.32头/m2的养殖场的猪只盘点需求。上述研究证明,图像实例分割在智能化养殖产业所起的作用越发重要。
由于需要对图像的深层语义信息进行提取并预测,因此实例分割不仅需要大量的图像用于神经网络训练,还需要训练样本拥有像素级别的掩码信息(需要进行精细的标注)。而在猪只图像实例分割任务中,制作一个强监督(像素级标注)的数据集相当耗费人力,特别是图像中猪只个数多、产生堆叠、光照、噪声等因素影响,都会对精细标注效率产生影响[18]。因此,摆脱对高质量数据集的需求,正在成为分割领域研究的重点工作之一。当前,已有研究人员提出弱监督学习的概念[19],通过使用弱监督数据集,即采取粗糙标注的方式制作的数据集,通过改变神经网络对特征信息的处理模式,减少图像实例分割对像素级信息的过分依赖。国内现在已有针对农业领域使用弱监督学习方法的研究,赵亚楠等[20]提出基于边界框掩码的深度卷积神经网络,通过引入伪标签生产模块,用低成本的弱标签实现玉米植株图像实例分割;黄亮等[21]结合RGB波段最大差异法,实现对无人遥感灯盏花的弱监督实例分割。上述研究方案在节约数据集标注成本的同时,还取得了较高的精度,这也证明了弱监督图像实例分割在猪只养殖等智能化农业领域具有很大的研究和应用价值。
为了解决猪只图像实例分割中制作强监督数据集耗时耗力的问题,本文使用粗糙标注的方法构建弱监督数据集;从优化图像特征提取和处理过程,以此提升弱监督实例分割效果的角度出发,结合第2代可变形卷积、空间注意力机制和involution算子,提出新的特征提取骨干网络RdsiNet;通过使用Mask R-CNN分割模型进行训练,以验证RdsiNet网络改进的有效性;最后使用仅需边界框作为监督信息的BoxInst[22]弱监督实例分割模型训练数据集,以本文的RdsiNet作为特征提取骨干网络,在进一步验证RdsiNet有效性的同时,提升猪只的分割效果。
1 弱监督数据集构建及分析
1.1 数据集构建
弱监督实例分割(Weakly supervised instance segmentation)是一种使用较少的监督信息进行训练的实例分割方法。通常只需要图像级别的标签,而不需要每个像素的精确标注,根据标注方式的不同可以细分为无监督、粗监督、不完全监督等类型[23],分别对应无标注、粗糙标注和部分标注的数据集制作方法。考虑到猪舍猪只不断运动的特性,其分帧后得到的图像会带有猪只的行为信息,不同图像中同一猪只的空间信息对于实例分割神经网络模型有着重要的意义。因此,为了能为神经网络模型提供更有效的特征区域和空间信息,同时减少每幅图像的标注时间,本文采取粗糙的轮廓标注框作为数据集的标注方式。
LU等[24]针对猪只图像分割研究,制作了一个规模较大的数据集(包括训练集15 184幅图像,验证集1 898幅图像,测试集1 900幅图像);该数据集图像由公开的猪场监控视频分帧而成[25],本文对其进行筛选,选取其中10~18周龄且处于同一场景下的7头猪只的监控视频图像,共选出17 980幅猪只图像作为本文研究的原始数据。其后本文使用Labelme软件,对此原始数据所有图像进行基于弱监督的粗糙的轮廓标注(共标注17 980幅)。像素级标注要求标注框紧密贴合猪只身体轮廓,并且给不同的猪只打上专属的编号,每幅图像耗时约10 min。图1为本文采用的粗糙标注方式的标注效果,和逐像素方式相比,标注框不再呈现猪只背部的几何结构,而是以图1b所示的多边形直接覆盖猪只,每幅图像只需2 min就可以完成标注,比起逐像素方式工作效率提高了5倍,大大节约了标注时间成本。最后在进行神经网络模型训练之前将所有标注图像进行训练集、验证集、测试集的划分,划分比例为8∶1∶1,共得到训练集14 384幅图像、验证集1 798幅图像和测试集1 798幅图像。

图1 粗糙轮廓标注样式展示Fig.1 Display of rough contours annotation style
1.2 数据集分析
尽管粗糙的轮廓标注可以极大地节约数据集制作时间成本,但是其提供的低质量的真值标签,在实例分割神经网络训练过程中,会造成网络学习性能的下降。尤其在神经网络反向传播的过程中,一方面标注框同时包含分割实例和背景信息,会导致某些权重的梯度异常或是下降方向错乱,造成梯度稀疏、混淆等问题[25];另一方面,逐像素的标注框能为神经网络提供更多特征信息,而粗糙的标注框却无法做到,甚至会提供错误的特征信息,最终影响训练结果[26-28]。
2 猪只实例分割模型改进
2.1 特征提取主干网络改进
2.1.1引入第2代可变形卷积
因为粗监督数据集的标注框不贴合猪只,这会导致标注框内同时包含背景像素值和猪只的像素值,且这两种像素值差距较大,在神经网络反向传播过程中,会影响网络对猪只边缘信息的优化过程。为解决此问题,本文从特征提取角度出发引入可变形卷积,在特征提取过程中将更多的背景像素加入特征图中,扩大网络感受野。第1代可变形卷积由DAI等[29]提出,通过在传统卷积操作中引入偏移量概念,将传统卷积核由固定结构变为发散性结构,从而扩大特征提取的感受野,其特征值计算公式为
(1)
式中p0——特征图中进行卷积的采样点
y(p0)——卷积输出的特征值
pn——采样点在卷积核范围内的偏移量
w(pn)——卷积核权重
x(p0+pn+Δpn)——加上偏移量后采样位置的特征值
R——卷积核感受野区域
尽管通过网络学习偏移量可以增大骨干网络的感受野,但网络同时也会通过可变形卷积学习许多无关信息,造成混乱。ZHU等[30]在第1代的基础上,提出了第2代可变形卷积操作,通过增加一个权重系数Δmpn,增大网络对于卷积操作的自由度,可以在学习中弱化或舍弃某些无关采样点权重,计算公式为
(2)
在神经网络学习的过程中,通过对Δmpn进行赋值,可以对学习到的特征值进行区分,将不需要的特征值舍去。
文献[31-32]为了解决传统卷积感受野不够导致对图像复杂信息提取能力差的问题,通过引入第2代可变形卷积操作,使得网络感受野和图像特征建立变化性关系,使其可以自适应地融合每个像素点相邻的相似结构信息,进而提高检测的准确率。因此,本文在骨干网络中使用第2代可变形卷积,可以使特征图包含更多背景信息,将网络感受野扩大以匹配粗监督标注框,减少错误信息带来的影响,网络通过不断地迭代和反向传播,可以提升最终分割效果。
2.1.2空间注意力机制模块
空间注意力机制由WOO等[33]提出,是一种模仿人眼视觉的一种处理机制。在图像处理中,空间注意力机制通过生成权值矩阵的方式,对主干网络所提取的不同特征赋予不同的权重,以此在众多信息中选取关键的部分。如图2所示,输入尺寸为H×W×C的特征图,通过最大池化和平均池化得到尺寸为H×W×1的两幅特征图,将这两幅特征图按照通道维度拼接,然后再使用7×7的卷积核和Sigmoid函数,得到权重矩阵Ms,计算公式为

图2 空间注意力机制Fig.2 Spatial attention mechanisms
Ms(F)=σ(f7×7([AvgPool(F),MaxPool(F)]))
(3)
式中F——输入的初始特征图
Ms(F)——空间注意力机制得到的权重矩阵
σ()——Sigmoid函数
AvgPool()——平均池化操作
MaxPool()——最大池化操作
将Ms与输入的特征图相乘,就为神经网络模型加入了空间注意力。
俞利新等[34]针对特征图提取过程中冗余信息过多的问题,通过引入空间注意力机制以减弱源图像中的冗余信息从而突出目标,并通过消融实验验证了该方法的有效性。基于此,本文在骨干网络中加入空间注意力机制,用于对特征通道中不同特征映射赋予权重,将强有用的特征映射值如猪只轮廓、纹理、颜色等,平均到每个通道特征图中,扩大其在网络中的影响因子。
2.1.3involution算子
对于图像实例分割任务而言,核心思想在于对深层的抽象特征进行语义预测。但是随着神经网络层数的加深,骨干网络会失去大量的空间信息,导致网络区分不同实例能力不足。尤其对本文所使用的弱监督数据集而言,其中猪只聚集、移动等场景较多,对分割产生的挑战很大。基于此问题,本文在骨干网络中引入LI等[35]提出的involution算子,区别于传统的特征提取方式,它将空间各异性和通道共享性作为设计出发点,杨洪刚等[36]为提升神经网络模型对细粒度图像的能力,使用involution算子提取了图像的底层语义信息和空间结构信息进行了特征融合,并验证了其有效性,其结构如图3所示。
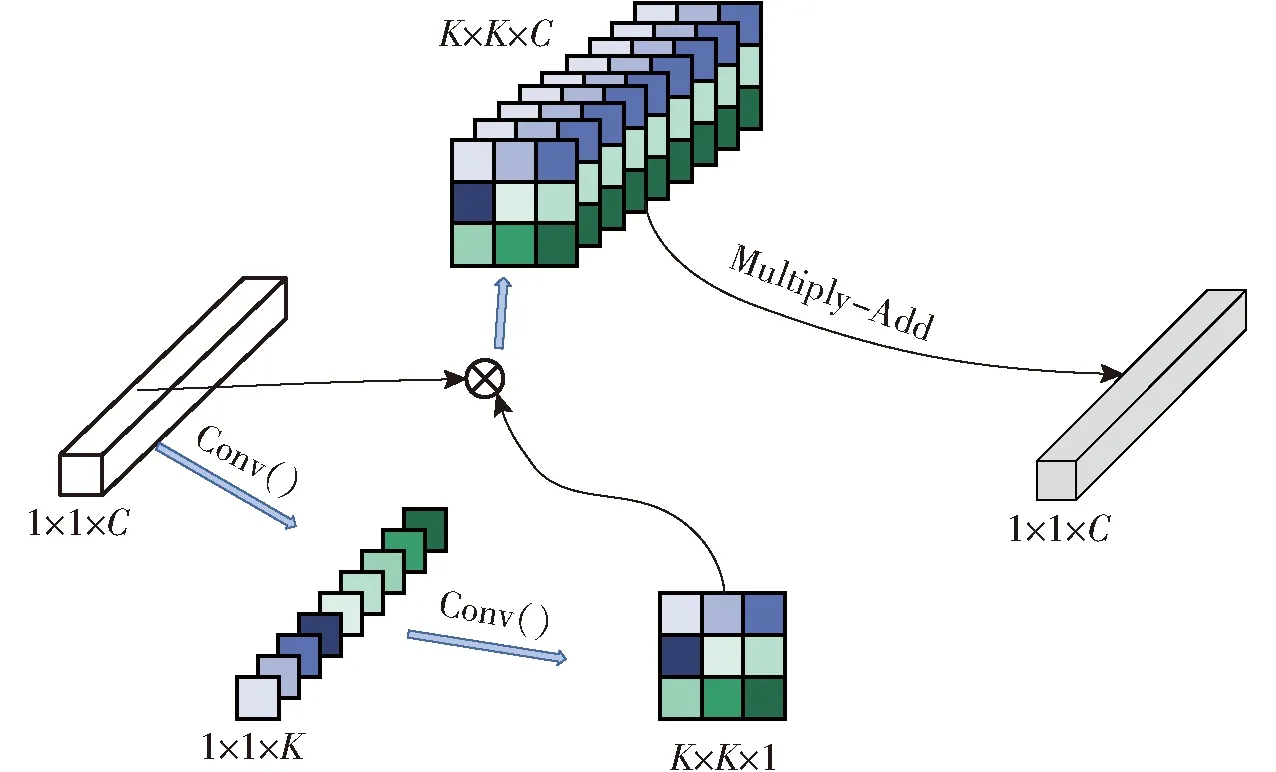
图3 involution算子提取特征模式图Fig.3 Feature pattern diagram extracted by involution operator
假设输入尺寸为H×W×C的特征图,对1×1×C的像素点的特征向量作下一步特征提取时,使用卷积操作先将其通道数C压缩至K2,再将获得的K2个通道数作为新的大小为K的卷积核;其后将初始的1×1×C特征向量在特征图中扩展至K×K大小的区域,与上一步中得到的卷积核相乘并相加,得到最终的结果。与卷积相比,involution算子对于具体空间位置的卷积核由该位置的特征向量决定,并且对不同的输出通道使用相同的卷积核,具有了空间特异性和通道共享性。
本文通过使用involution算子,不仅可以解决深层网络空间信息丢失的问题,还可以将深层的语义信息和特征通道中被赋予空间注意力的信息连接,加强网络对于猪只图像分割的学习,提升分割的精度。
2.1.4RdsiNet特征提取骨干网络结构
本文提出的RdsiNet骨干网络结构如图4所示,其中蓝色虚线框中展示了本文通过对传统残差块加入空间注意力机制和involution算子后得到的残差-空间注意力机制模块和残差-involution模块。参考ResNet-50[37]中3、4、6、3层的残差模块分布概念,在ResNet-50的残差结构后加入空间注意力机制,提出残差-空间注意力模块,作为新的特征提取模块,并且在Layer1中串联使用3块。在Layer 2和Layer 3中,将第2代可变形卷积加入残差-空间注意力模块,替代原本3×3卷积操作,分别使用4块和6块;最后,将ResNet-50残差模块中的3×3卷积操作替换为involution算子,构建残差-involution模块,在Layer 4中同样串联3个此模块。
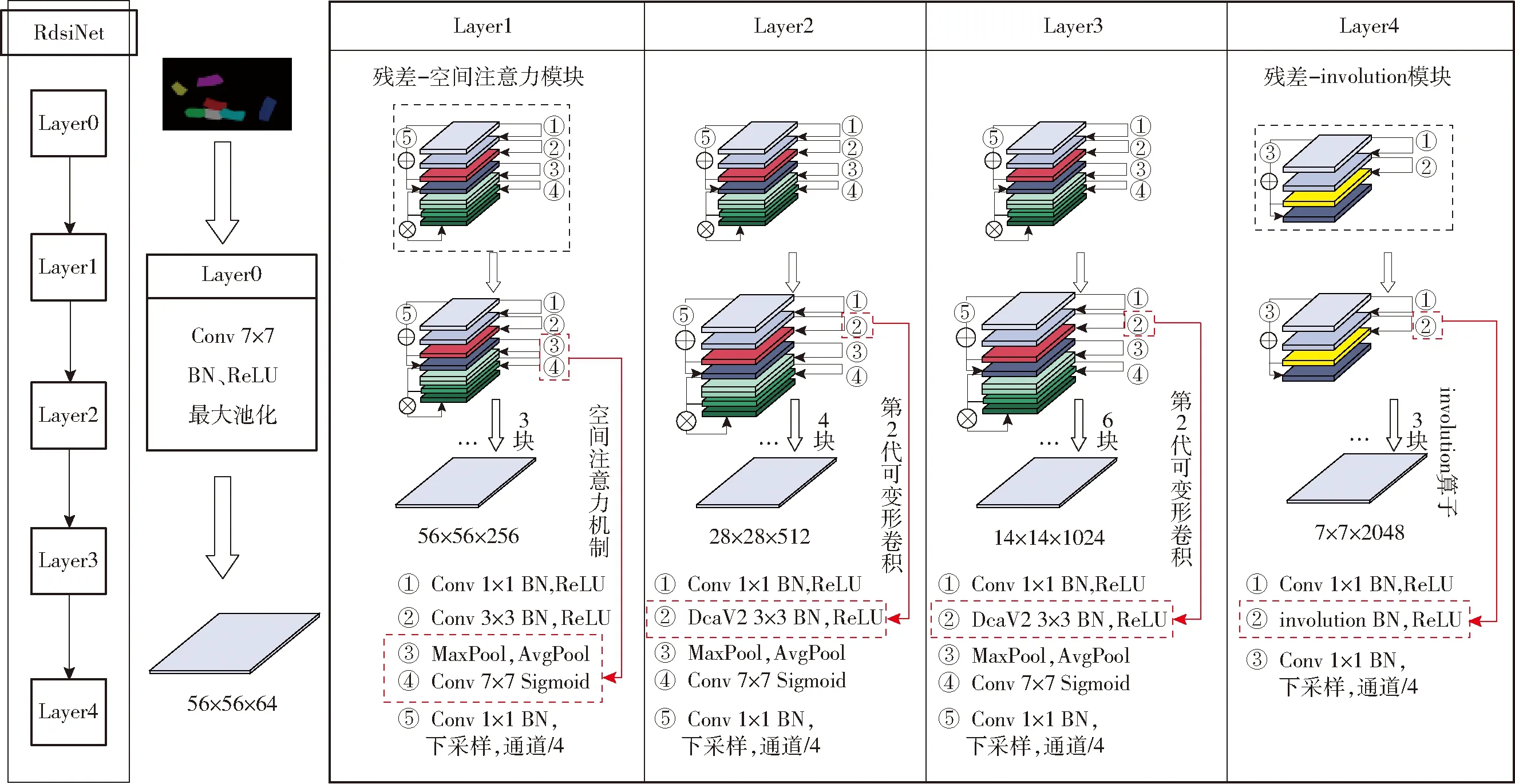
图4 RdsiNet骨干网络结构Fig.4 Structure of RdsiNet backbone network
2.2 实例分割网络模型
2.2.1实验分割模型选择
为验证RdsiNet骨干网络的有效性,本文选取两种实例分割模型进行训练:需要像素级掩码标注进行训练的Mask R-CNN;仅需要边界框标注进行训练的弱监督实例分割模型BoxInst。
由于本文标注的掩码标签(Mask label)无法为Mask R-CNN提供准确、高质量的掩码监督信息(Mask ground truth),因此最终的实例分割效果不如逐像素标注的效果,但另一方面,这也更能反映不同骨干网络对于猪只图像的特征提取能力,因此本文使用Mask R-CNN以验证本文所提RdsiNet骨干网络的有效性。
2.2.2Mask R-CNN分割模型
图5展示了本文使用的RdsiNet的设计结构和Mask R-CNN实例分割模型的训练过程。图5a是第2代可变形卷积的实现过程,其发散性的特征提取方式扩大了网络的感受野,用于Layer2和Layer3层。图5b是猪只的轮廓纹理特征图像,图5c是RdsiNet网络特征提取过程中不同特征通道的图像展示结果,通过将轮廓纹理特征矩阵平均加至不同的特征通道内,实现增加实例分割模型对猪只轮廓的注意力,用于Layer1、Layer2和Layer3层。图5d展示了由特征图上某一点像素的不同特征通道所生成的卷积核,将其与该像素相乘并相加,实现特征通道和图像像素的交互,用于最后一层(Layer4层)。
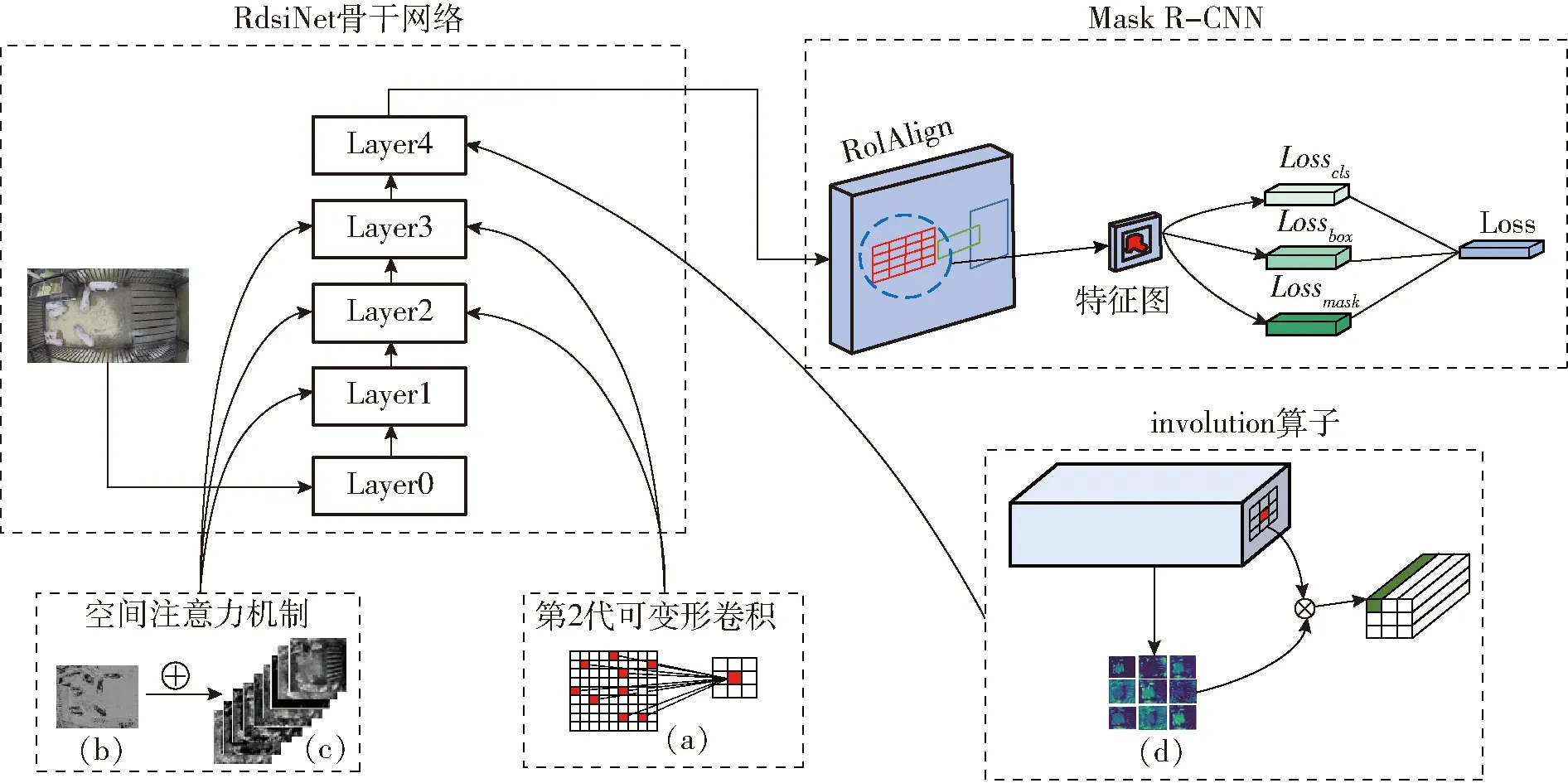
图5 Mask R-CNN分割模型训练框架Fig.5 Framework of Mask R-CNN
Mask R-CNN是一种基于像素级掩码标注的全监督实例分割模型,其分割模型步骤如图5所示,通过对RdsiNet提取的特征图进行感兴趣区域(ROI)和RoIAlign操作,在特征图上生成感兴趣空间并将其与输入图像像素区域对齐,之后对空间内物体进行类别、边界框和掩码的预测及损失函数(包括Losscls、Lossbox、Lossmask)的反向传播,最终经不断迭代完成训练。
2.2.3BoxInst分割模型
BoxInst是一种基于边界框标注(Bounding box)的弱监督实例分割模型,主要由骨干提取网络、FPN层、共享Head层(Controller Head)和Mask预测分支(Mask Branch)组成,其仅需使用边界框的标注(Box label)作为监督信息去训练实例分割网络。本文使用RdsiNet作为BoxInst特征提取骨干网络,并通过FPN加强对不同尺度实例的学习能力。而对于掩码预测部分,这个过程由2个分支组成,分别为共享的Head层和Mask预测分支。共享Head层用来预测实例及其最小外接框,Mask预测分支则用来对预测的外界框内所有像素进行前景背景预测,最终实现物体的分割。如图6所示,BoxInst采用动态卷积的思想对每一个实例编码,通过共享Head层,对不同尺度特征图进行实例预测,获取每个实例的类别及动态生成其Controller参数;而在Mask预测分支中,将FPN层得到的特征图和每个实例的相对位置相加输出为总特征图,将共享Head层得到的每个实例参数分别作用在总特征图上以生成不同的掩码预测区域,并预测其边界框和掩码。在获取实例边界框后,一方面通过对边界框的左上角和右下角顶点坐标值进行反向传播,如图6所示,提升边界框的精准度;另一方面计算其内部所有像素之间的相似性,引入如图6所示的相邻像素颜色相似度(pairwise)属性关系进一步约束前景、背景像素,并使用Lab色彩空间下颜色的相似度作为真实标签,对不同的像素进行聚类,最终实现不依靠标注的掩码监督信息实现实例分割;其中Lproj表示边界框两个顶点坐标的损失值,而Lpairwise表示掩码的损失值,其中边界框的损失值由数据集提供的边界框标注计算,而掩码损失值由模型迭代过程中通过学习到的像素间颜色关系计算得到。
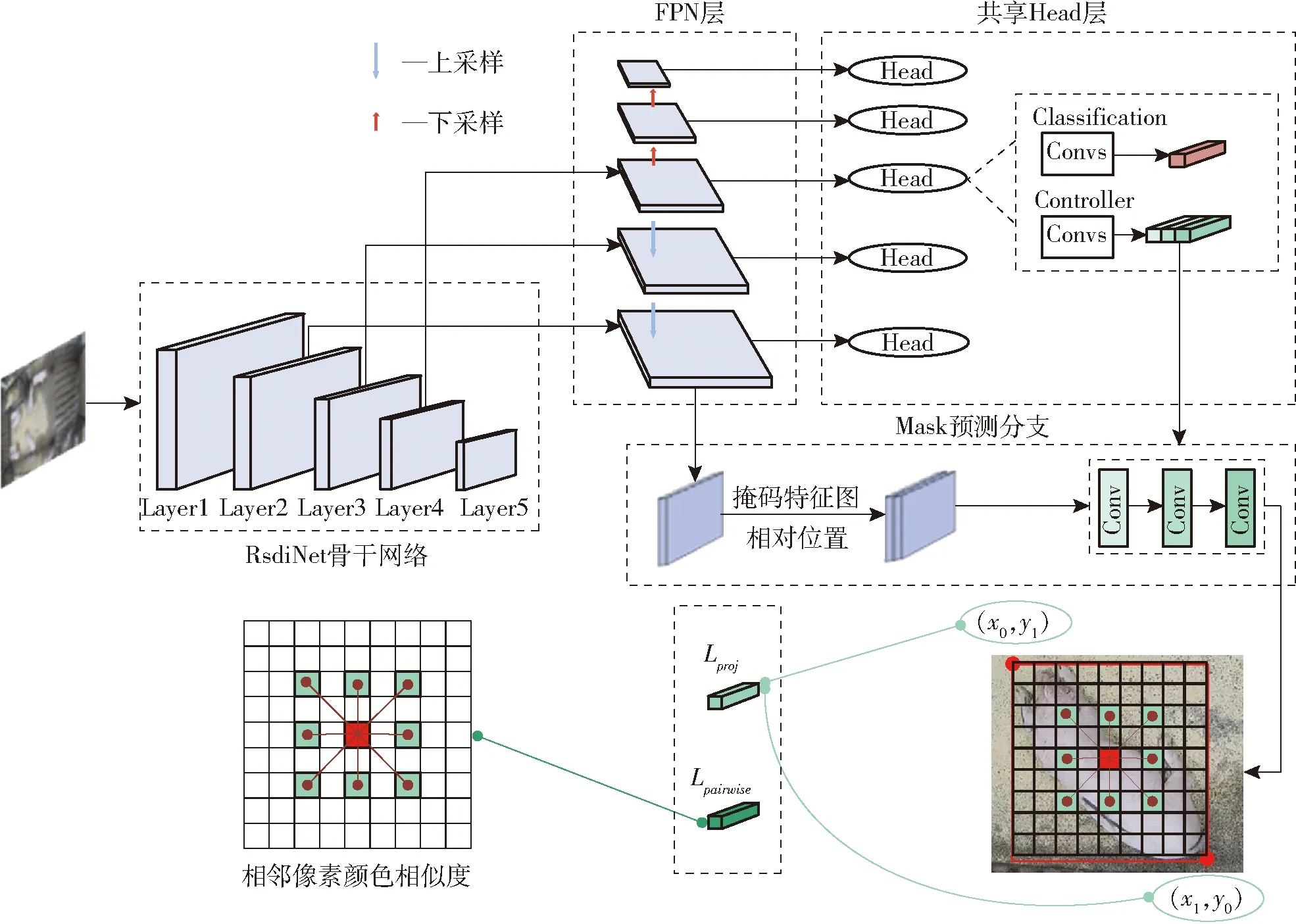
图6 本文BoxInst分割模型训练框架Fig.6 Framework of BoxInst segmentation model
3 实验与结果分析
3.1 实验环境
本文基于Mmdetection框架进行实验,使用的核心计算显卡为2块GeForce GTX 2080Ti,显存为22 GB,显卡驱动CUDA版本为10.1,Python版本为3.7.13,Pytorch版本为1.7.1,mmcv版本为1.5.0,mmdet版本为2.25.2。
3.2 实验参数设置
实验过程中模型训练轮数为12轮,学习率设为0.001,采用AdamW优化器,权重衰减(weight_decay)设为0.05。
3.3 模型训练损失值曲线
Loss函数是评价模型性能的主要指标之一,其可以反映模型训练过程中的稳定性和衡量模型。图7为使用RdsiNet作为特征提取网络的Mask R-CNN和BoxInst的loss函数曲线,可以看出,随着训练轮数的增加,两种模型损失值都呈现平稳下降趋势,且曲线平滑,在迭代了10 000次后逐渐趋于收敛,这表明RdsiNet骨干提取网络设计合理,训练时间和成本可控,具有较强的鲁棒性。
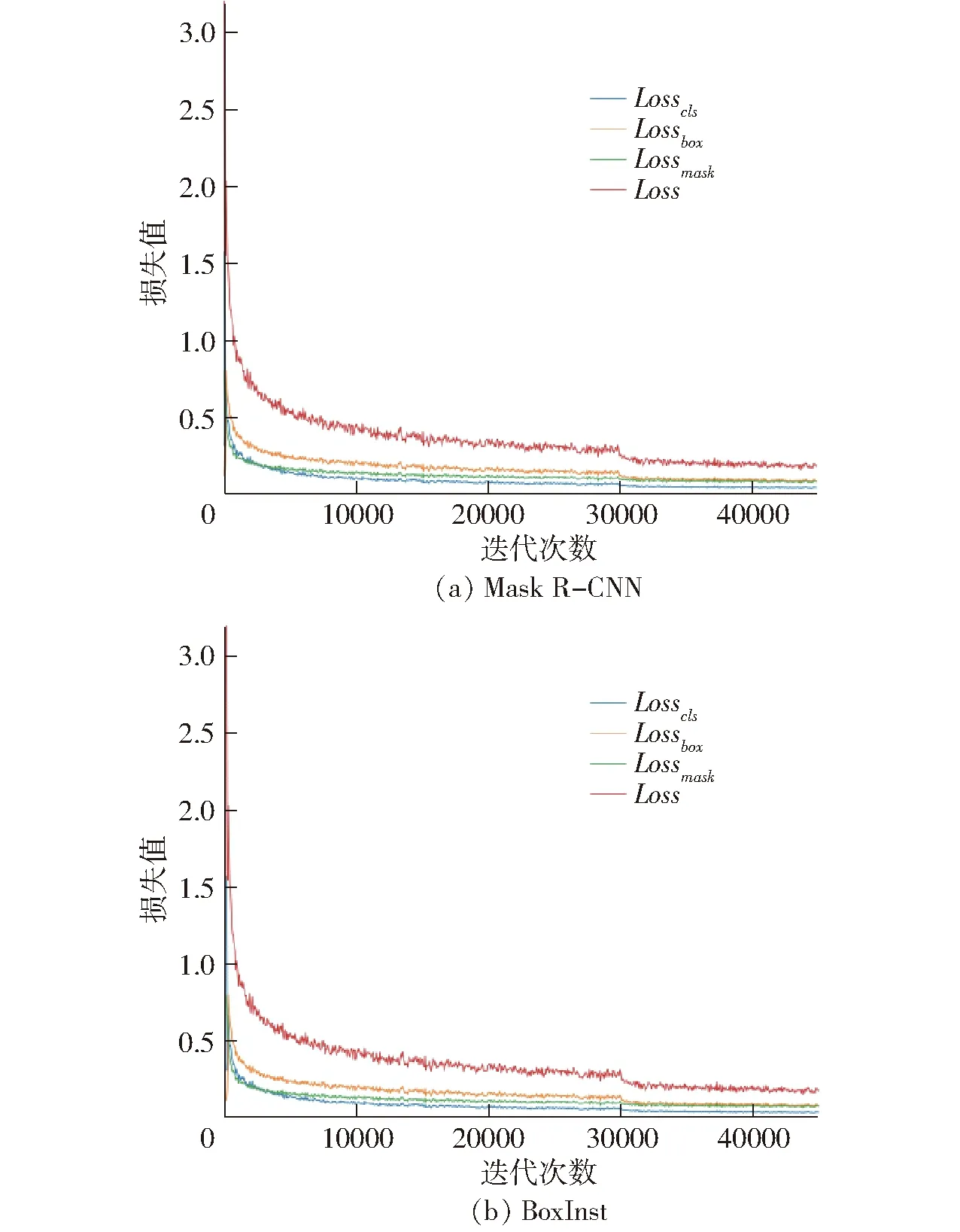
图7 Mask R-CNN和BoxInst训练Loss曲线Fig.7 Loss curve graphs of Mask R-CNN and BoxInst
3.4 模型训练结果
3.4.1Mask R-CNN训练结果
对于Mask R-CNN实例分割模型,本文分别使用ResNet-50、GCNet[38]、RegNet[39]、ResNeSt[40]、CotNet[41]和提出的RdsiNet骨干网络进行实验,实验结果如表1所示。在实验效果评估中,使用mAPBbox和mAPSemg评价回归的边界框和猪只分割精度。
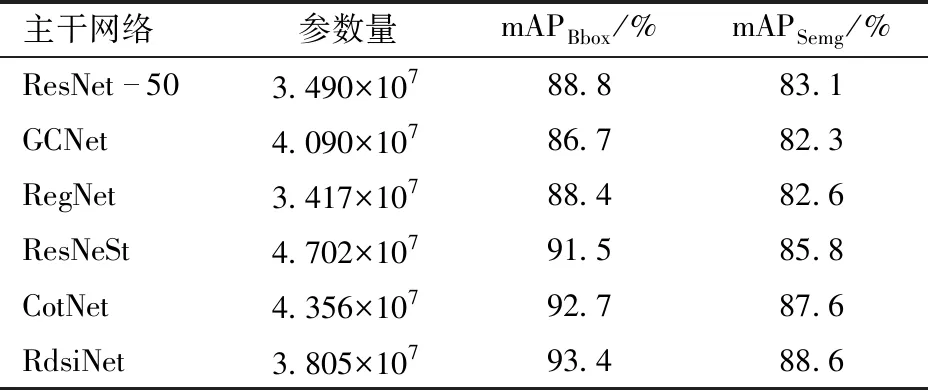
表1 不同骨干网络训练结果对比Tab.1 Comparison of different backbone network training results
平均精度均值(mAP)指所有类的平均精度(AP)的平均值,用来衡量多类别目标检测效果。表1显示,本文改进后的骨干网络具有最高的mAPBbox和mAPSemg值,分别为93.4%和88.6%。同GCNet、ResNeSt和CotNet相比,以更少的参数获得了更好的实例分割效果,而对比ResNet-50,在小幅提升参数量的情况下,mAPBbox和mAPSemg获得了较大的增益,体现了RdsiNet骨干网络的优越性。
3.4.2Mask R-CNN分割模型测试图像
为进一步验证RdsiNet的效果,本文分别使用参数量低于4×107的4种骨干网络进行模型分割效果测试,图8为在猪只扎堆、粘连等条件下,ResNet-50、GCNet、RegNet和RdsiNet骨干网络在Mask R-CNN分割模型下的图像测试效果。对比 4种骨干网络下图像分割效果可以看出,ResNet-50、GCNet、RegNet对于猪只聚集情况,均无法准确提取有效空间信息,以辅助分割模型判别猪只实例个数及空间位置,造成大量错检等问题;而本文所提出的RdsiNet网络,明显具有更强的特征提取能力,且可以准确判断聚集条件下猪只实例个数,主要体现在特征提取和处理的过程中:扩大感受野、为特征信息添加注意力、将深层语义信息和通道特征交互连接,可以更好地定位图像实例,增强分割模型对图像的学习能力。

图8 Mask R-CNN模型中4种骨干网络分割效果对比Fig.8 Comparison of segmentation effects of four backbone networks of Mask R-CNN
3.4.3BoxInst训练结果
由于Mask R-CNN必须依靠像素级的掩码信息进行反向传播,才能得到优秀的实例分割效果,3.4.2节同样说明了尽管RdsiNet骨干网络改善了特征提取的过程,但最终测试图像中掩码仍较为粗糙。基于此,考虑到本文制作的数据集可以提供准确的边界框信息,因此再次使用仅需边界框作为监督信息的BoxInst实例分割模型训练此数据集。
表2展示了基于BoxInst分割模型,ResNet-50和RdsiNet骨干网络的参数,由于BoxInst只使用边界框作为监督信息,因此测试数据集中只计算mAPBbox来衡量模型的性能。如表2所示,RdsiNet的mAPBbox较ResNet-50提升2.2个百分点,达到89.6%,这说明使用RdsiNet骨干网络的BoxInst对于边界框的预测更加精准。

表2 2种骨干网络训练结果对比Tab.2 Comparison of results by using two backbone networks
为进一步测试BoxInst分割模型的分割效果,本文在测试集中随机抽取了50幅图像,进行了像素级掩码标注,将标注掩码作为真值,同模型预测的掩码求不同阈值下的交并比,以此计算mAPSemg。计算结果如表2所示,RdsiNet的mAPSemg为95.2%,远高于ResNet的76.7%,这体现了BoxInst分割模型下,RdsiNet不仅分割效果更好,且具有更好的鲁棒性。
3.4.4BoxInst分割模型测试图像
图9展示了BoxInst弱监督实例分割模型在ResNet-50和RdsiNet骨干网络下最终的测试图像,可以明显看出,BoxInst分割模型在RdsiNet骨干网络下具有更好的分割效果,其掩码不仅紧密地贴近猪只轮廓,呈现明显的猪只几何形状,而且在猪只移动的不同场景下依旧可以完美分割。而ResNet-50的图像分割效果出现较多问题,包括掩码过度覆盖、猪只漏检等,这说明本文所提出的RdsiNet骨干网络对于提升弱监督实例分割效果具有很大的作用。

图9 BoxInst下两种骨干网络分割效果对比Fig.9 Comparison of segmentation effects of two backbone networks of BoxInst
3.5 消融实验
3.5.1实验结果对比
本文使用ResNet-50骨干网络、添加空间注意力机制和第2代可变形卷积操作的ResNet-50网络以及本文提出的RdsiNet骨干网络,在Mask R-CNN分割模型上进行消融实验,表3是消融实验的结果。上述3种网络分别表示为ResNet-50、ResNet-50+SPA+DCN和RdsiNet。如表3所示,空间注意力机制和第2代可变形卷积对图像实例分割效果的提升具有重要作用,额外增加involution算子之后的RdsiNet骨干网络相比较原始的ResNet-50,mAPBbox和mAPSemg提升4.2、4.8个百分点,总计达到93.4%和88.6%。实验结果表明involution算子不仅可以提升模型的性能,还可以大幅降低网络参数。表3中的数据表明,本文提出的骨干网络在提升分割精度的同时,还将参数量控制在合理范围内,以较低的代价换取了更好的性能。

表3 消融实验骨干网络结果对比Tab.3 Comparison of backbone performance in ablation experiments
3.5.2类激活图
由于神经网络具有不可解释性,因此很难从正向推导的方式去判定不同特征提取方式的作用。但特征图的权重可以认为是被卷积核过滤后而保留的有效信息,其值越大,表明特征越有效,对网络预测结果越重要。基于此,本文使用Grad-CAM[42]对输入图像生成类激活的热力图,如图10所示,颜色越深红的地方表示值越大,其值越大,表明特征越有效,表示原始图像对应区域对网络的响应越高、贡献越大,对网络预测结果越重要。对比消融实验中3个骨干网络的类激活图,可以看出增加了第2代可变形卷积核空间注意力机制后,网络感受野明显增大,但无法做到对猪只有效范围的提取精度;而增加了involution算子的RdsiNet网络不仅具有更大的感受野,而且其红色范围更加准确,进一步证明了其对有效特征提取的准确度较高。

图10 3种骨干网络类激活图Fig.10 Heatmaps of three backbone networks
4 结论
(1)提出使用弱监督学习的方法进行猪只图像实例分割,制作粗糙轮廓标注的弱监督数据集,解决了逐像素标注数据集过程中具有的时间成本高、效率低、标注难等问题。同时,为解决弱监督会造成网络学习性能下降的问题,使用第2代可变卷积、空间注意力机制和involution算子搭建RdsiNet特征提取骨干网络,在对图像进行特征提取和处理的过程中,扩大网络感受野、加强重要特征信息和解决深层网络空间信息丢失问题,并且将骨干网络深层中提取出来的抽象语义信息和特征映射相连接,优化了猪只图像实例分割的效果。通过消融实验验证了RdsiNet骨干网络在弱监督数据集上的有效性。
(2)基于Mask R-CNN分割模型,将ResNet-50、GCNet、RegNet、ResNeSt、CotNet和本文提出的RdsiNet骨干网络做对比实验,RdsiNet取得了最高的mAPBbox和mAPSemg,分别为93.4%和88.6%,比ResNet-50分别提高5.6、5.5个百分点。在分割测试图像方面中,RdsiNet同样具有最好的表现,尤其在猪只堆叠、模糊的情况下, RdsiNet比ResNet-50具有更好的空间位置特征提取能力;最后通过使用消融实验和类激活图进一步验证了RdsiNet构建的合理性和有效性。
(3)为进一步改善分割效果,使用基于边界框作为监督信息的BoxInst实例分割模型,分别使用ResNet-50和RdsiNet骨干网络进行训练。对比之下,RdsiNet不仅有更高的mAPBbox和mAPSemg,且具有更好的分割效果,同样表明了RdsiNet在图像特征提取过程中的优势,可以为猪只体重预测、个体识别跟踪等任务提供参考。
